基于SpringBoot从零构建博客网站 - 开发文章详情页面
文章详情页面是博客系统中最为重要的页面,登录用户与游客都可以浏览文章详情页面,只不过只有登录用户才能进行其它的一些操作,比如评论、点赞和收藏等等。
本次的开发任务只是将文章详情页面展示出来,至于一些收藏、点赞、评论以及统计相关的功能后续慢慢加上。
1、后台核心代码
加载出文章的详情页面的核心代码如下:
/**
* 加载出文章详情页面
*
* @param articleId
* @param model
* @param session
* @return
*/
@RequestMapping(value = "/p/{articleId}", method = RequestMethod.GET)
public String view(@PathVariable("articleId") String articleId, Model model, HttpSession session) {
// 根据ID获取文章信息
Article article = articleService.getById(articleId);
// 获取用户信息
User user = userService.getById(article.getUserId());
if (!StringUtils.isEmpty(article.getGroupId())) {
// 获取专栏信息
Group group = groupService.getById(article.getGroupId());
article.setGroupName(group.getName());
}
// 获取文章标签信息
List<Tag> tags = tagService.queryByArticleId(articleId);
// 获取该用户更多的文章信息
Wrapper<Article> queryWrapper = new QueryWrapper<Article>().lambda().eq(Article::getUserId, user.getUserId()).eq(Article::getStatus, Article.STATUS_SUCCESS).ne(Article::getArticleId, articleId).orderByDesc(Article::getPublishTime);
List<Article> moreArticles = articleService.queryForLimit(queryWrapper, 6);
// 获取推荐的文章信息
List<Article> likeArticles = null;
if (tags != null && !tags.isEmpty()) {
// 根据标签来获取类似的文章
List<String> tagStrs = new ArrayList<String>();
tags.stream().forEach(tag -> tagStrs.add(tag.getTag()));
Map<String, Object> params = new HashMap<String, Object>();
params.put("status", Article.STATUS_SUCCESS);
params.put("articleId", articleId);
likeArticles = articleService.queryForLimitByTags(params, tagStrs, 10);
} else {
// 获取最新的文章信息
Wrapper<Article> likeWrapper = new QueryWrapper<Article>().lambda().eq(Article::getStatus, Article.STATUS_SUCCESS).ne(Article::getArticleId, articleId).orderByDesc(Article::getPublishTime);
likeArticles = articleService.queryForLimit(queryWrapper, 10);
}
model.addAttribute("article", article);
model.addAttribute("user", user);
model.addAttribute("tags", tags);
model.addAttribute("moreArticles", moreArticles);
model.addAttribute("likeArticles", likeArticles);
return Const.BASE_INDEX_PAGE + "blog/article/view";
}
里面核心逻辑为:
- 获取文章内容
- 获取文章的标签
- 获取该用户的更多文章列表
- 根据标签查询出相关的文章,作为推荐文章列表
其实里面有一些统计相关的逻辑暂时没有加上,后续会加上。
2、前台核心代码
由于文章是通过editor.md工具完成的,所以前台文章展示也是要借助editor.md来完成,核心代码如下:
<div class="note-cont">
<div id="article-content">
<textarea id="article-content-textarea" style="display:none;">${article.content}</textarea>
</div>
</div>
首先文章内容像上面的代码一样放置于html中,同时当页面加载时需要执行如下的js代码,即:
$(function() {
editormd.markdownToHTML("article-content", {
htmlDecode : "style,script,iframe", // you can filter tags decode
emoji : true,
taskList : true,
tex : true, // 默认不解析
flowChart : true, // 默认不解析
sequenceDiagram : true, // 默认不解析
});
});
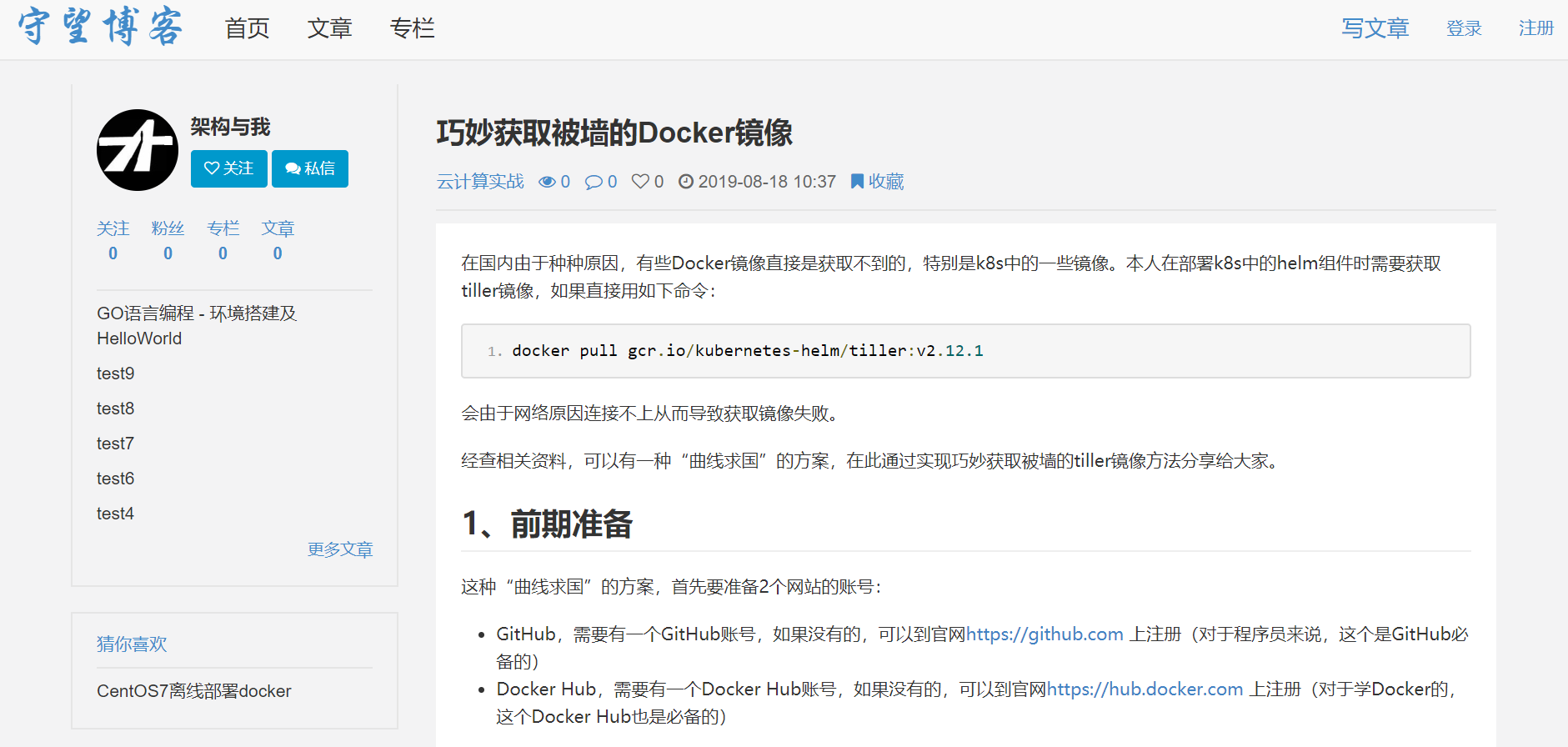
页面效果如下:
关注我
以你最方便的方式关注我:
微信公众号:

基于SpringBoot从零构建博客网站 - 开发文章详情页面的更多相关文章
- 基于SpringBoot从零构建博客网站 - 开发设置主页标识和修改个人信息功能
由于守望博客系统中支持由用户自己设置个人主页的URL的后半段,所以必须要用户设置该标识的功能,而且是用户注册登录之后自动弹出的页面,如果用户没有设置该标识,其它的操作是不能够操作的,同时要求主页标识只 ...
- 基于SpringBoot从零构建博客网站 - 确定需求和表结构
要确定一个系统的需求,首先需要明确该系统的用户有哪些,然后针对每一类用户,确定其需求.对于博客网站来说,用户有3大类,分别是: 作者,也即是注册用户 游客,也即非注册用户 管理员,网站维护人员 那么从 ...
- 基于SpringBoot从零构建博客网站 - 技术选型和整合开发环境
技术选型和整合开发环境 1.技术选型 博客网站是基于SpringBoot整合其它模块而开发的,那么每个模块选择的技术如下: SpringBoot版本选择目前较新的2.1.1.RELEASE版本 持久化 ...
- 基于SpringBoot从零构建博客网站 - 新增创建、修改、删除专栏功能
守望博客是支持创建专栏的功能,即可以将一系列相关的文章归档到专栏中,方便用户管理和查阅文章.这里主要讲解专栏的创建.修改和删除功能,至于专栏还涉及其它的功能,例如关注专栏等后续会穿插着介绍. 1.创建 ...
- 基于SpringBoot从零构建博客网站 - 设计可扩展上传模块和开发修改头像密码功能
上传模块在web开发中是很常见的功能也是很重要的功能,在web应用中需要上传的可以是图片.pdf.压缩包等其它类型的文件,同时对于图片可能需要回显,对于其它文件要能够支持下载等.在守望博客系统中对于上 ...
- 基于SpringBoot从零构建博客网站 - 集成editor.md开发发布文章功能
发布文章功能里面最重要的就是需要集成富文本编辑器,目前富文本编辑器有很多,例如ueditor,CKEditor.editor.md等.这里守望博客里面是集成的editor.md,因为editor.md ...
- 基于SpringBoot从零构建博客网站 - 分页显示文章列表功能
显示文章列表一般都是采用分页显示,比如每页10篇文章显示.这样就不用每次就将所有的文章查询出来,而且当文章数量特别多的时候,如果一次性查询出来很容易出现OOM异常. 后台的分页插件采用的是mybati ...
- 基于SpringBoot从零构建博客网站 - 整合ehcache和开发注册登录功能
对于程序中一些字典信息.配置信息应该在程序启动时加载到缓存中,用时先到缓存中取,如果没有命中,再到数据库中获取同时放到缓存中,这样做可以减轻数据库层的压力.目前暂时先整合ehcache缓存,同时预留了 ...
- 基于SpringBoot从零构建博客网站 - 整合lombok和mybatis-plus提高开发效率
在上一章节中<技术选型和整合开发环境>,确定了开发的技术,但是如果直接这样用的话,可能开发效率会不高,为了提高开发的效率,这里再整合lombok和mybatis-plus两个组件. 1.l ...
随机推荐
- JDK、JRE、JVM之间的区别和联系
JDK : Java Development ToolKit(Java开发工具包).JDK是整个JAVA的核心,包括了Java运行环境(Java Runtime Envirnment),一堆Java工 ...
- 1、JAVA的小白之路
大学的时光过得很快,转眼我已经大二了,在大一时,学习了C\C++,对于语言有一定基础,在未来的道路上,我需要攒足干劲,积累足够的知识和技能,去走上社会. 我的第一任大学班主任告诉我:“作为程序员,你至 ...
- java学习-NIO(四)Selector
这一节我们将探索选择器(selectors).选择器提供选择执行已经就绪的任务的能力,这使得多元 I/O 成为可能.就像在第一章中描述的那样,就绪选择和多元执行使得单线程能够有效率地同时管理多个 I/ ...
- 单机版ZooKeeper的安装教程
之前一直没有时间去整理,现在抽出几分钟时间整理以下,有问题的在评论区留言即可. 前期准备JDK环境(ZK需要jdk进行编译,本文以jdk1.8.0_211为例).Linux系统(本文以Centos7为 ...
- Windows下的bat原来可以为我们做很多
用了windows系统这么多年了,对bat也不是很了解.最近研究了一下bat的用法.这里就大概列举一下自己的用法 参考网址 基本命令 echo echo我们可以理解成程序中的输出,和我们Java的Sy ...
- 常用maven 命令
重新依赖:mvn package -U -DskipTest=true; 在本地安装jar包:mvn install 清除产生的项目:mvn clean 运行测试:mvn test 上传到私服:mvn ...
- 最小环-Floyd
floyd求最小环 在Floyd的同时,顺便算出最小环. Floyd算法 :k<=n:k++) { :i<k:i++) :j<k:j++) if(d[i][j]+m[i][k]+m[ ...
- javascript——原型与继承
一.什么是继承? 继承是面向对象语言的一个重要概念.许多面向对象语言都支持两种继承方式:接口继承和实现继承:接口继承只继承方法签名,而实现继承则继承实际的方法.由于函数没有签名,所以ECMAScrip ...
- DC-2靶机渗透
靶场下载链接: Download: http://www.five86.com/downloads/DC-2.zip Download (Mirror): https://download.vulnh ...
- 轻松pick移动开发第一篇,flex布局
一.什么是flex布局 首先提问一个问题,一般童鞋都会让子元素水平居中,那么怎么让子元素垂直居中呢?这里就要用到我们的flex布局了. 1.flex 是 flexible Box 的缩写,意为&quo ...