Java 数据持久化系列之JDBC
前段时间小冰在工作中遇到了一系列关于数据持久化的问题,在排查问题时发现自己对 Java 后端的数据持久化框架的原理都不太了解,只有不断试错,因此走了很多弯路。于是下定决心,集中精力学习了持久化相关框架的原理和实现,总结出这个系列。
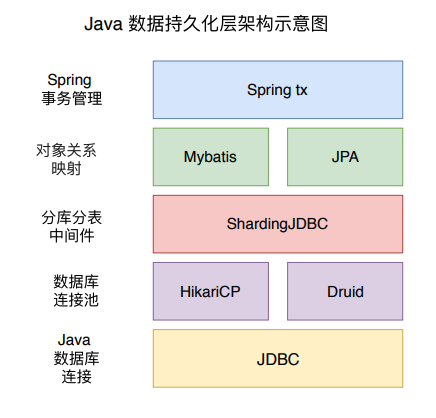
上图是我根据相关源码和网上资料总结的有关 Java 数据持久化的架构图(只代表本人想法,如有问题,欢迎留言指出)。最下层就是今天要讲的 JDBC,上一层是数据库连接池层,包括 HikariCP 和 Druid等;再上一层是分库分表中间件,比如说 ShardingJDBC;再向上是对象关系映射层,也就是 ORM,包括 Mybatis 和 JPA;最上边是 Spring 的事务管理。
本系列的文章会依次讲解图中各个开源框架的基础使用,然后描述其原理和代码实现,最后会着重分析它们之间是如何相互集成和配合的。
废话不多说,我们先来看 JDBC。
JDBC 定义
JDBC是Java Database Connectivity的简称,它定义了一套访问数据库的规范和接口。但它自身不参与数据库访问的实现。因此对于目前存在的数据库(譬如Mysql、Oracle)来说,要么数据库制造商本身提供这些规范与接口的实现,要么社区提供这些实现。
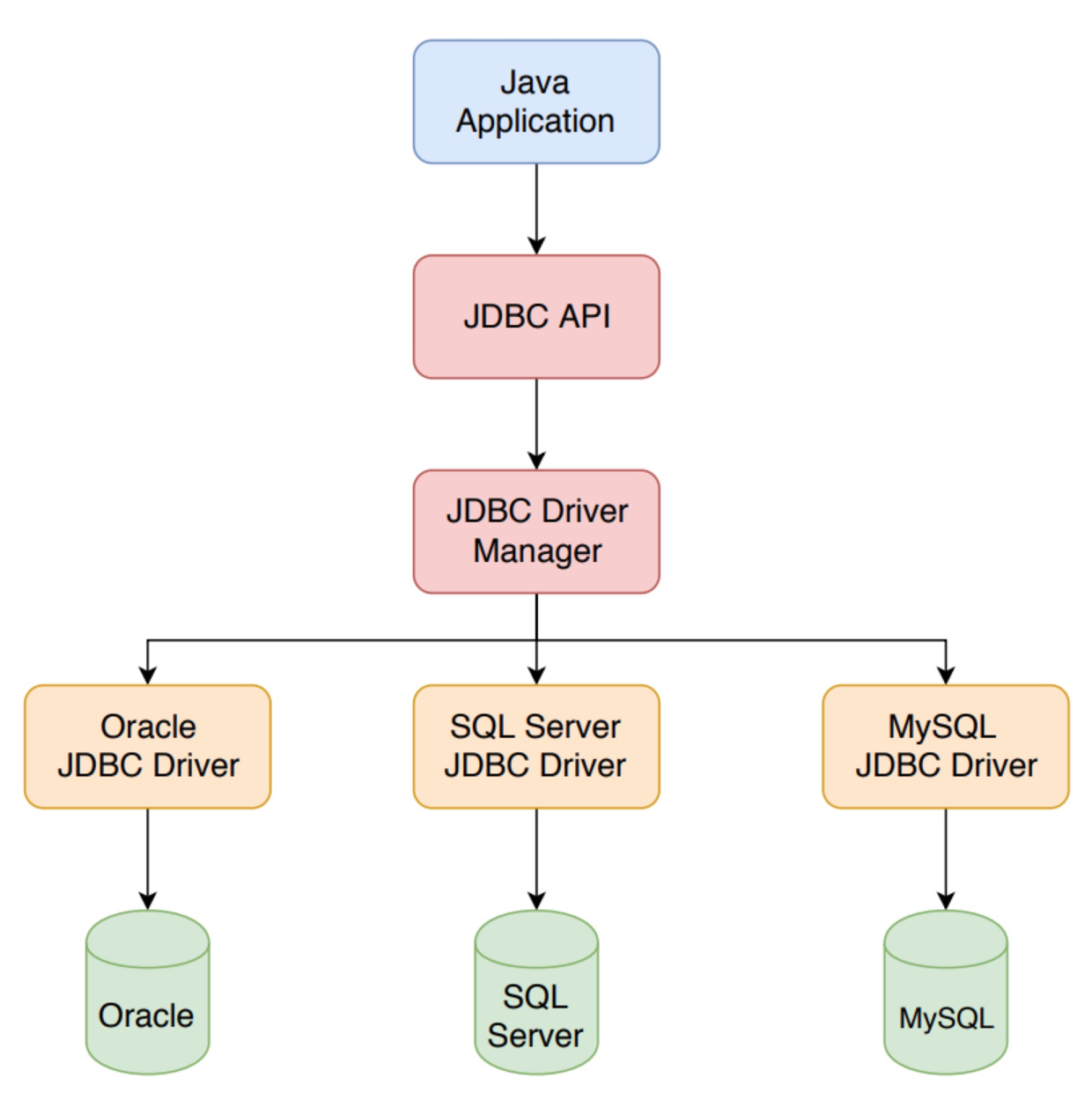
如上图所示,Java 程序只依赖于 JDBC API,通过 DriverManager 来获取驱动,并且针对不同的数据库可以使用不同的驱动。这是典型的桥接的设计模式,把抽象 Abstraction 与行为实现Implementation 分离开来,从而可以保持各部分的独立性以及应对他们的功能扩展。
JDBC 基础代码示例
单纯使用 JDBC 的代码逻辑十分简单,我们就以最为常用的MySQL 为例,展示一下使用 JDBC 来建立数据库连接、执行查询语句和遍历结果的过程。
public static void connectionTest(){
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try {
// 1. 加载并注册 MySQL 的驱动
Class.forName("com.mysql.cj.jdbc.Driver").newInstance();
// 2. 根据特定的数据库连接URL,返回与此URL的所匹配的数据库驱动对象
Driver driver = DriverManager.getDriver(URL);
// 3. 传入参数,比如说用户名和密码
Properties props = new Properties();
props.put("user", USER_NAME);
props.put("password", PASSWORD);
// 4. 使用数据库驱动创建数据库连接 Connection
connection = driver.connect(URL, props);
// 5. 从数据库连接 connection 中获得 Statement 对象
statement = connection.createStatement();
// 6. 执行 sql 语句,返回结果
resultSet = statement.executeQuery("select * from activity");
// 7. 处理结果,取出数据
while(resultSet.next())
{
System.out.println(resultSet.getString(2));
}
.....
}finally{
// 8.关闭链接,释放资源 按照JDBC的规范,使用完成后管理链接,
// 释放资源,释放顺序应该是: ResultSet ->Statement ->Connection
resultSet.close();
statement.close();
connection.close();
}
}
代码中有详细的注释描述每一步的过程,相信大家也都对这段代码十分熟悉。
唯一要提醒的是使用完之后的资源释放顺序。按照 JDBC 规范,应该依次释放 ResultSet,Statement 和 Connection。当然这只是规范,很多开源框架都没有严格的执行,但是 HikariCP却严格准守了,它可以带来很多优势,这些会在之后的文章中讲解。
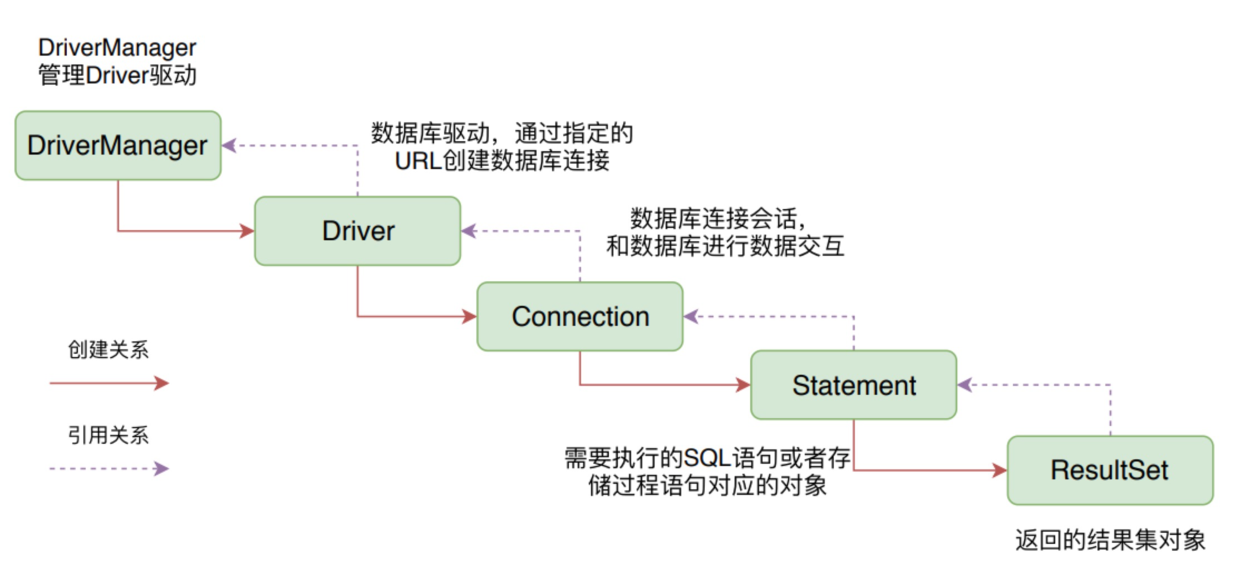
上图是 JDBC 中核心的 5 个类或者接口的关系,它们分别是 DriverManager、Driver、Connection、Statement 和 ResultSet。
DriverManager 负责管理数据库驱动程序,根据 URL 获取与之匹配的 Driver 具体实现。Driver 则负责处理与具体数据库的通信细节,根据 URL 创建数据库连接 Connection。
Connection 表示与数据库的一个连接会话,可以和数据库进行数据交互。Statement 是需要执行的 SQL 语句或者存储过程语句对应的实体,可以执行对应的 SQL 语句。ResultSet 则是 Statement 执行后获得的结果集对象,可以使用迭代器从中遍历数据。
不同数据库的驱动都会实现各自的 Driver、Connection、Statement 和 ResultSet。而更为重要的是,众多数据库连接池和分库分表框架也都是实现了自己的 Connection、Statement 和 ResultSet,比如说 HikariCP、Druid 和 ShardingJDBC。我们接下来会经常看到它们的身影。
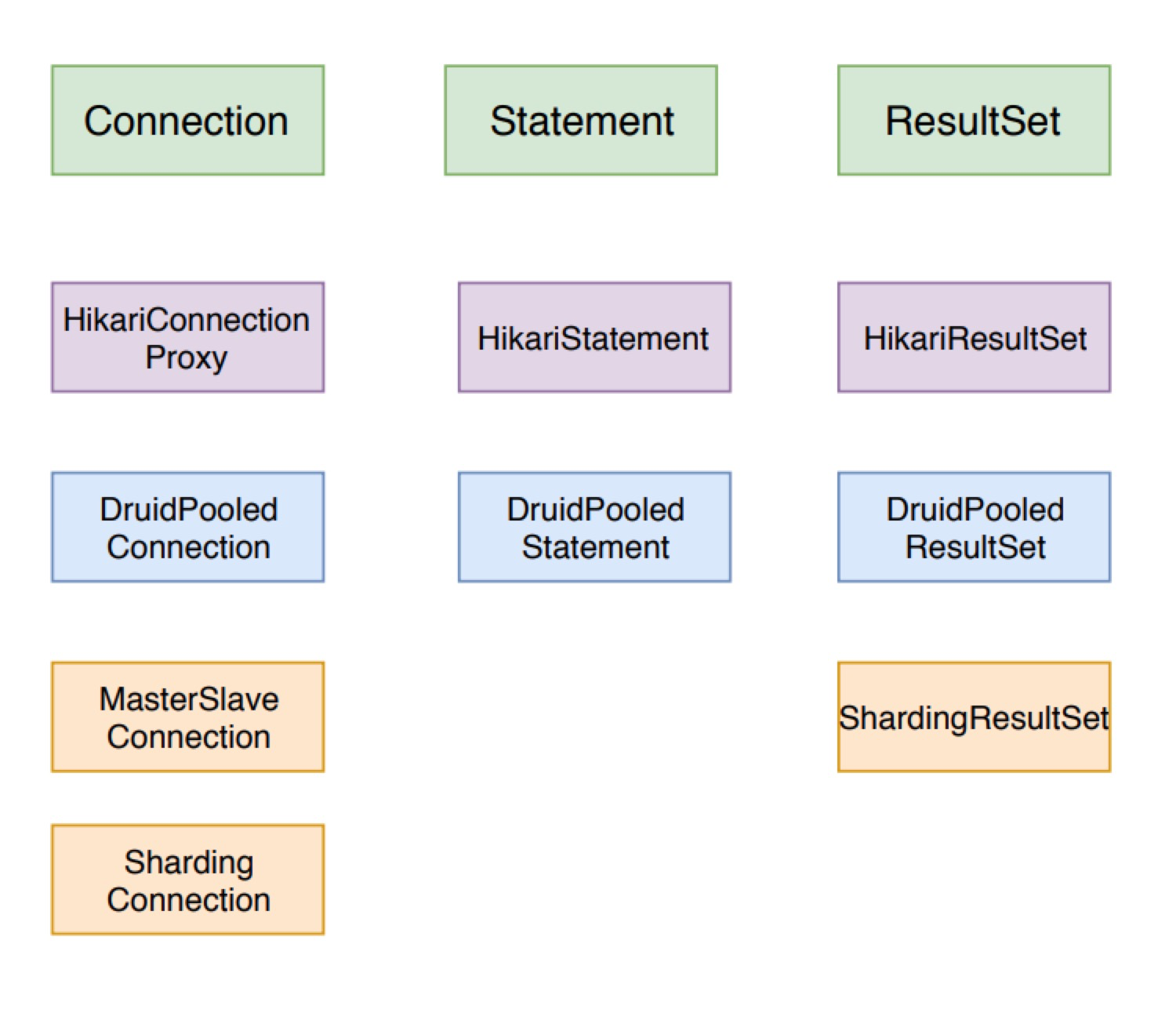
接下来,我们依次看一下这几个类及其涉及的操作的原理和源码实现。
载入 Driver 实现
可以直接使用 Class#forName的方式来载入驱动实现,或者在 JDBC 4.0 后则基于 SPI 机制来导入驱动实现,通过在 META-INF/services/java.sql.Driver 文件中指定实现类的方式来导入驱动实现,下面我们就来看一下两种方式的实现原理。
Class#forName 作用是要求 JVM 查找并加载指定的类,如果在类中有静态初始化器的话,JVM 会执行该类的静态代码段。加载具体 Driver 实现时,就会执行 Driver 中的静态代码段,将该 Driver 实现注册到 DriverManager 中。我们来看一下 MySQL 对应 Driver 的具体代码。它就是直接调用了 DriverManager的 registerDriver 方法将自己注册到其维护的驱动列表中。
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
public Driver() throws SQLException {
}
static {
// 直接调用 DriverManager的 registerDriver 将自己注册到其中
DriverManager.registerDriver(new Driver());
}
}
SPI 机制使用 ServiceLoader 类来提供服务发现机制,动态地为某个接口寻找服务实现。当服务的提供者提供了服务接口的一种实现之后,必须根据 SPI 约定在 META-INF/services 目录下创建一个以服务接口命名的文件,在该文件中写入实现该服务接口的具体实现类。当服务调用 ServiceLoader 的 load 方法的时候,ServiceLoader 能够通过约定的目录找到指定的文件,并装载实例化,完成服务的发现。
DriverManager 中的 loadInitialDrivers 方法会使用 ServiceLoader 的 load 方法加载目前项目路径下的所有 Driver 实现。
public class DriverManager {
// 程序中已经注册的Driver具体实现信息列表。registerDriver类就是将Driver加入到这个列表
private final static CopyOnWriteArrayList<DriverInfo> registeredDrivers = new CopyOnWriteArrayList<>();
// 使用ServiceLoader 加载具体的jdbc driver实现
static {
loadInitialDrivers();
}
private static void loadInitialDrivers() {
// 省略了异常处理
// 获得系统属性 jdbc.drivers 配置的值
String drivers = AccessController.doPrivileged(new PrivilegedAction<String>() {
public String run() {
return System.getProperty("jdbc.drivers");
}
});
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
// 通过 ServiceLoader 获取到Driver的具体实现类,然后加载这些类,会调用其静态代码块
while(driversIterator.hasNext()) {
driversIterator.next();
}
return null;
}
});
String[] driversList = drivers.split(":");
// for 循环加载系统属性中的Driver类。
for (String aDriver : driversList) {
println("DriverManager.Initialize: loading " + aDriver);
Class.forName(aDriver, true,
ClassLoader.getSystemClassLoader());
}
}
}
比如说,项目引用了 MySQL 的 jar包 mysql-connector-java,在这个 jar 包的 META-INF/services 文件夹下有一个叫 java.sql.Driver 的文件,文件的内容为 com.mysql.cj.jdbc.Driver。而 ServiceLoader 的 load 方法找到这个文件夹下的文件,读取文件的内容,然后加载出文件内容所指定的 Driver 实现。而正如之前所分析的,这个 Driver 类被加载时,会调用 DriverManager 的 registerDriver 方法,从而完成了驱动的加载。
Connection、Statement 和 ResultSet
当程序加载完具体驱动实现后,接下来就是建立与数据库的连接,执行 SQL 语句并且处理返回结果了,其过程如下图所示。
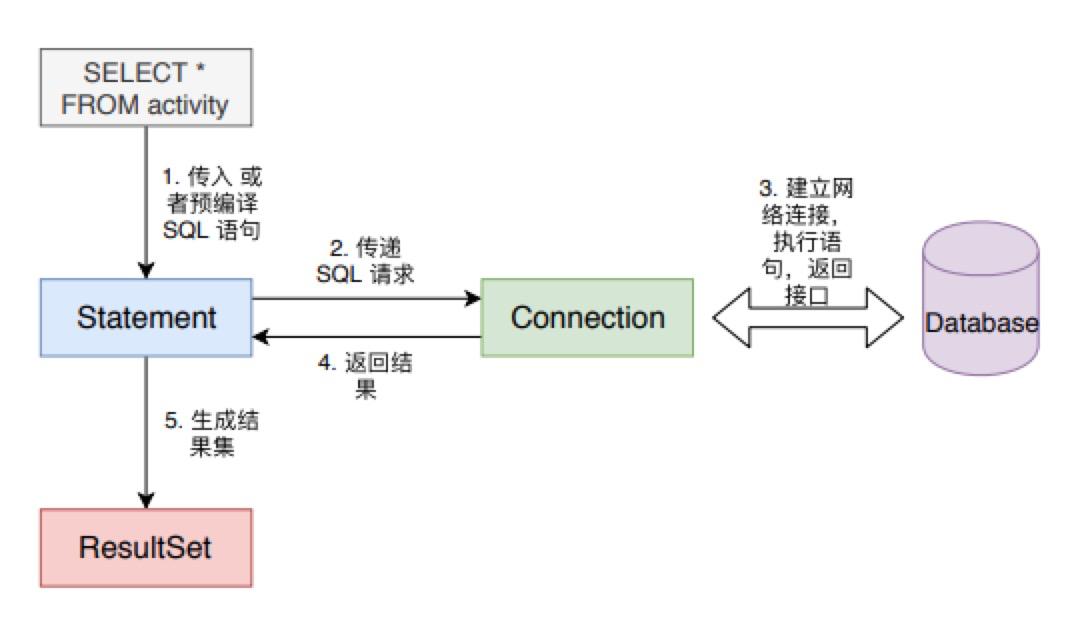
建立 Connection
创建 Connection 连接对象,可以使用 Driver 的 connect 方法,也可以使用 DriverManager 提供的 getConnection 方法,此方法通过 url 自动匹配对应的驱动 Driver 实例,然后还是调用对应的 connect 方法返回 Connection 对象实例。
建立 Connection 会涉及到与数据库进行网络请求等大量费时的操作,为了提升性能,往往都会引入数据库连接池,也就是说复用 Connection,免去每次都创建 Connection 所消耗的时间和系统资源。
Connection 默认情况下,对于创建的 Statement 执行的 SQL 语句都是自动提交事务的,即在 Statement 语句执行完后,自动执行 commit 操作,将事务提交,结果影响到物理数据库。为了满足更好地事务控制需求,我们也可以手动地控制事务,手动地在Statement 的 SQL 语句执行后进行 commit 或者rollback。
connection = driver.connect(URL, props);
// 将自动提交关闭
connection.setAutoCommit(false); statement = connection.createStatement();
statement.execute("INSERT INTO activity (activity_id, activity_name, product_id, start_time, end_time, total, status, sec_speed, buy_limit, buy_rate) VALUES (1, '香蕉大甩卖', 1, 530871061, 530872061, 20, 0, 1, 1, 0.20);");
// 执行后手动 commit
statement.getConnection().commit();
Statement
Statement 的功能在于根据传入的 SQL 语句,将传入 SQL 经过整理组合成数据库能够识别的执行语句(对于静态的 SQL 语句,不需要整理组合;而对于预编译SQL 语句和批量语句,则需要整理),然后传递 SQL 请求,之后会得到返回的结果。对于查询 SQL,结果会以 ResultSet 的形式返回。
当你创建了一个 Statement 对象之后,你可以用它的三个执行方法的任一方法来执行 SQL 语句。
- boolean execute(String SQL) : 如果 ResultSet 对象可以被检索,则返回的布尔值为 true ,否则返回 false 。当你需要使用真正的动态 SQL 时,可以使用这个方法来执行 SQL DDL 语句。
- int executeUpdate(String SQL) : 返回执行 SQL 语句影响的行的数目。使用该方法来执行 SQL 语句,是希望得到一些受影响的行的数目,例如,INSERT,UPDATE 或 DELETE 语句。
- ResultSet executeQuery(String SQL) : 返回一个 ResultSet 对象。当你希望得到一个结果集时使用该方法,就像你使用一个 SELECT 语句。
对于不同类型的 SQL 语句,Statement 有不同的接口与其对应。
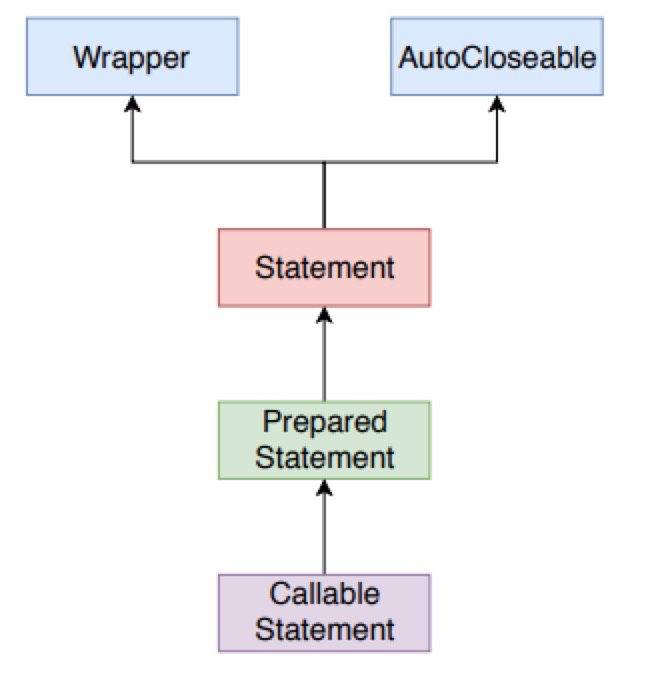
接口 | 介绍
-|-|
Statement | 适合运行静态 SQL 语句,不接受动态参数
PreparedStatement | 计划多次使用并且预先编译的 SQL 语句,接口需要传入额外的参数
CallableStatement | 用于访问数据库存储过程
Statement 主要用于执行静态SQL语句,即内容固定不变的SQL语句。Statement每执行一次都要对传入的SQL语句编译一次,效率较差。而 PreparedStatement则解决了这个问题,它会对 SQL 进行预编译,提高了执行效率。
PreparedStatement pstmt = null;
try {
String SQL = "Update activity SET activity_name = ? WHERE activity_id = ?";
pstmt = connection.prepareStatement(SQL);
pstmt.setString(1, "测试");
pstmt.setInt(2, 1);
pstmt.executeUpdate();
}
catch (SQLException e) {
}
finally {
pstmt.close();
}
}
除此之外, PreparedStatement 还可以预防 SQL 注入,因为 PreparedStatement 不允许在插入参数时改变 SQL 语句的逻辑结构。
PreparedStatement 传入任何数据不会和原 SQL 语句发生匹配关系,无需对输入的数据做过滤。如果用户将”or 1 = 1”传入赋值给占位符,下述SQL 语句将无法执行:select * from t where username = ? and password = ?。
ResultSet
当 Statement 查询 SQL 执行后,会得到 ResultSet 对象,ResultSet 对象是 SQL语句查询的结果集合。ResultSet 对从数据库返回的结果进行了封装,使用迭代器的模式可以逐条取出结果集中的记录。
while(resultSet.next()) {
System.out.println(resultSet.getString(2));
}
ResultSet 一般也建议使用完毕直接 close 掉,但是需要注意的是关闭 ResultSet 对象不关闭其持有的 Blob、Clob 或 NClob 对象。 Blob、Clob 或 NClob 对象在它们被创建的的事务期间会一直持有效,除非其 free 函数被调用。

参考
- https://blog.csdn.net/wl044090432/article/details/60768342
- https://blog.csdn.net/luanlouis/article/details/29850811
Java 数据持久化系列之JDBC的更多相关文章
- Java 数据持久化系列之池化技术
在上一篇文章<Java 数据持久化系列之JDBC>中,我们了解到使用 JDBC 创建 Connection 可以执行对应的SQL,但是创建 Connection 会消耗很多资源,所以 Ja ...
- Java 数据持久化系列之 HikariCP (一)
在上一篇<Java 数据持久化系列之池化技术>中,我们了解了池化技术,并使用 Apache-common-Pool2 实现了一个简单连接池,实验对比了它和 HikariCP.Druid 等 ...
- 数据持久化系列之Mysql
一.命令行操作 1.显示所有库: show databases; 2.要操作某个库,比如库名: db_book:use db_book; 3.查看表的基本结构,比如表名: t_book:desc t_ ...
- Java Web学习系列——Maven Web项目中集成使用Spring、MyBatis实现对MySQL的数据访问
本篇内容还是建立在上一篇Java Web学习系列——Maven Web项目中集成使用Spring基础之上,对之前的Maven Web项目进行升级改造,实现对MySQL的数据访问. 添加依赖Jar包 这 ...
- SpringBoot系列之JDBC数据访问
SpringBoot系列之JDBC数据访问 New->Project or Module->Spring Initializer 选择JDBC和mysql驱动,为了方便测试web等等也可以 ...
- Java EE数据持久化框架 • 【第1章 MyBatis入门】
全部章节 >>>> 本章目录 1.1 初识MyBatis 1.1.1 持久化技术介绍 1.1.2 MyBatis简介 1.1.2 Mybatis优点 1.1.3 利用Mav ...
- 大数据学习系列之三 ----- HBase Java Api 图文详解
版权声明: 作者:虚无境 博客园出处:http://www.cnblogs.com/xuwujing CSDN出处:http://blog.csdn.net/qazwsxpcm 个人博客出处:http ...
- Docker深入浅出系列 | 容器数据持久化
Docker深入浅出系列 | 容器数据持久化 Docker已经上市很多年,不是什么新鲜事物了,很多企业或者开发同学以前也不多不少有所接触,但是有实操经验的人不多,本系列教程主要偏重实战,尽量讲干货,会 ...
- Java EE数据持久化框架 • 【第6章 MyBatis插件开发】
全部章节 >>>> 本章目录 6.1 MyBatis拦截器接口 6.1.1 MyBais拦截器接口介绍 6.1.2 MyBais拦截器签名介绍 6.1.3 实践练习 6.2 ...
随机推荐
- C# 8.0 的默认接口方法
例子 直接看例子 有这样一个接口: 然后有三个它的实现类: 然后在main方法里面调用: 截至目前,程序都可以成功的编译和运行. IPerson接口变更 突然,我想对所有的人类添加一个新的特性,例如, ...
- Dotween 应用
dotween是做缓动比较简单实用的插件,下面就使用经验进行浅谈 1)通用方法:如下图官网截图所示,如果看不懂可以跳过,这是一个通用方法,前两个参数为委托类型,可以用lambda表达式,也可以直接写成 ...
- 两种unity双击事件
有时候需要用到双击事件,而unity未提供双击控件,在此提供两种双击事件方法,进攻参考: 1)此方法为通过unityevent来实现 首先新建image(或其他不带点击事件的控件),添加如下脚本,然后 ...
- django-数据库之连接数据库
1.连接数据库出现的一些问题 基本目录如下: 首先我们pip install pymysql 然后在项目中,进行配置settings.py: 然后在__init__.py中进行输入: 启动服务器: 报 ...
- vue-route动态路由
配置子路由: 路由的视图都需要使用view-router 子路由也可以嵌套路由使用: children来做嵌套如上图 使用location.页面name就可以做页面跳转 mounted:挂载,延迟跳转 ...
- SpringBoot与热部署整合(五)
一 Idea pom.xml <dependency> <groupId>org.springframework.boot</groupId> <artifa ...
- ArangoDB 界面介绍
目录: 安装并运行本地ArangoDB服务器 使用Web界面与之交互 BASHBOARD COLLECTIONS QUERIES GRAPHS SERVICES USERS LOGS 安装: 下载地址 ...
- mysql免安装包配置
最近在通过zip包配置mysql,mysql版本:5.7.13.配置过程中,踩了一些坑,下面做了一些简单的记录,配置的具体过程如下: 1.将mysql zip包解压,放到指定目录中,在系统环境变量中配 ...
- 你不知道的Canvas(二)
你不知道的Canvas(二) 一.色彩Colors 到目前为止,我们只看到过绘制内容的方法.如果我们想要给图形上色,有两个重要的属性可以做到:fillStyle 和 strokeStyle. fill ...
- vue学习笔记(一)入门
前言 随着前端不断的壮大,许多公司对于前端开发者的需求也越来越多了,作为一名优秀的前端工程师,如果连vue和react都不会的话,那真是out了,为什么那么说呢?这是我在招聘网站上截的一张图,十家公司 ...