Glide缓存流程
本文首发于 vivo互联网技术 微信公众号
链接:https://mp.weixin.qq.com/s/cPLkefpEb3w12-uoiqzTig
作者:连凌能
Android上图片加载的解决方案有多种,但是官方认可的是Glide。Glide提供简洁易用的api,整个框架也方便扩展,比如可以替换网络请求库,同时也提供了完备的缓存机制,应用层不需要自己去管理图片的缓存与获取,框架会分成内存缓存,文件缓存和远程缓存。本文不会从简单的使用着手,会把重点放在缓存机制的分析上。
一、综述
开始之前,关于Glide缓存请先思考几个问题:
Glide有几级缓存?
Glide内存缓存之间是什么关系?
Glide本地文件IO和网络请求是一个线程吗?如果不是,怎么实现线程切换?
Glide网络请求回来后数据直接返回给用户还是先存再返回?
加载开始入口从Engine.load()开始,先看下对这个方法的注释,
会先检查(Active Resources),如果有就直接返回,Active Resources没有被引用的资源会放入Memory Cache,如果Active Resources没有,会往下走。
检查Memory Cache中是否有需要的资源,如果有就返回,Memory Cache中没有就继续往下走。
检查当前在运行中的job中是否有改资源的下载,有就在现有的job中直接添加callback返回,不重复下载,当然前提是计算得到的key是一致的,如果还是没有,就会构造一个新的job开始新的工作。
* Starts a load for the given arguments.
*
* <p>Must be called on the main thread.
*
* <p>The flow for any request is as follows:
* <ul>
* <li>Check the current set of actively used resources, return the active resource if
* present, and move any newly inactive resources into the memory cache.</li>
* <li>Check the memory cache and provide the cached resource if present.</li>
* <li>Check the current set of in progress loads and add the cb to the in progress load if
* one is present.</li>
* <li>Start a new load.</li>
* </ul>

ok, find the source code.
二、内存缓存
public <R> LoadStatus load(
GlideContext glideContext,
Object model,
Key signature,
int width,
int height,
Class<?> resourceClass,
Class<R> transcodeClass,
Priority priority,
DiskCacheStrategy diskCacheStrategy,
Map<Class<?>, Transformation<?>> transformations,
boolean isTransformationRequired,
boolean isScaleOnlyOrNoTransform,
Options options,
boolean isMemoryCacheable,
boolean useUnlimitedSourceExecutorPool,
boolean useAnimationPool,
boolean onlyRetrieveFromCache,
ResourceCallback cb) {
Util.assertMainThread();
long startTime = VERBOSE_IS_LOGGABLE ? LogTime.getLogTime() : 0;
EngineKey key = keyFactory.buildKey(model, signature, width, height, transformations,
resourceClass, transcodeClass, options);
// focus 1
EngineResource<?> active = loadFromActiveResources(key, isMemoryCacheable);
if (active != null) {
cb.onResourceReady(active, DataSource.MEMORY_CACHE);
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Loaded resource from active resources", startTime, key);
}
return null;
}
// focus 2
EngineResource<?> cached = loadFromCache(key, isMemoryCacheable);
if (cached != null) {
cb.onResourceReady(cached, DataSource.MEMORY_CACHE);
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Loaded resource from cache", startTime, key);
}
return null;
}
// focus 3
EngineJob<?> current = jobs.get(key, onlyRetrieveFromCache);
if (current != null) {
current.addCallback(cb);
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Added to existing load", startTime, key);
}
return new LoadStatus(cb, current);
}
EngineJob<R> engineJob =
engineJobFactory.build(
key,
isMemoryCacheable,
useUnlimitedSourceExecutorPool,
useAnimationPool,
onlyRetrieveFromCache);
DecodeJob<R> decodeJob =
decodeJobFactory.build(
glideContext,
model,
key,
signature,
width,
height,
resourceClass,
transcodeClass,
priority,
diskCacheStrategy,
transformations,
isTransformationRequired,
isScaleOnlyOrNoTransform,
onlyRetrieveFromCache,
options,
engineJob);
jobs.put(key, engineJob);
engineJob.addCallback(cb);
// focus 4
engineJob.start(decodeJob);
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Started new load", startTime, key);
}
return new LoadStatus(cb, engineJob);
}
先看到 focus 1,这一步会从 ActiveResources 中加载资源,首先判断是否使用内存缓存,否的话返回null;否则到 ActiveResources 中取数据:
// Engine.java
@Nullable
private EngineResource<?> loadFromActiveResources(Key key, boolean isMemoryCacheable) {
if (!isMemoryCacheable) {
return null;
}
EngineResource<?> active = activeResources.get(key);
if (active != null) {
active.acquire();
}
return active;
}
接下来看下ActiveResources, 其实是用过弱引用保存使用过的资源。
final class ActiveResources {
...
private final Handler mainHandler = new Handler(Looper.getMainLooper(), new Callback() {
@Override
public boolean handleMessage(Message msg) {
if (msg.what == MSG_CLEAN_REF) {
cleanupActiveReference((ResourceWeakReference) msg.obj);
return true;
}
return false;
}
});
@VisibleForTesting
final Map<Key, ResourceWeakReference> activeEngineResources = new HashMap<>();
...
}
成功取到数据后回调类型也是内存缓存:
EngineResource<?> cached = loadFromCache(key, isMemoryCacheable);
if (cached != null) {
cb.onResourceReady(cached, DataSource.MEMORY_CACHE);
return null;
}
接着回到Engine.load()中继续看到focus 2,如果在cache中找到就是remove掉,然后返回EngineResource,其中需要EngineResource进行acquire一下,这个后面再看,然后会把资源移到ActiveResources中,也就是上面提到的缓存:
// Engine.java
private final MemoryCache cache;
private EngineResource<?> loadFromCache(Key key, boolean isMemoryCacheable) {
if (!isMemoryCacheable) {
return null;
}
EngineResource<?> cached = getEngineResourceFromCache(key);
if (cached != null) {
cached.acquire();
activeResources.activate(key, cached);
}
return cached;
}
private EngineResource<?> getEngineResourceFromCache(Key key) {
Resource<?> cached = cache.remove(key);
final EngineResource<?> result;
if (cached == null) {
result = null;
} else if (cached instanceof EngineResource) {
// Save an object allocation if we've cached an EngineResource (the typical case).
result = (EngineResource<?>) cached;
} else {
result = new EngineResource<>(cached, true /*isMemoryCacheable*/, true /*isRecyclable*/);
}
return result;
}
其中cache是MemoryCache接口的实现,如果没设置,默认在build的时候是LruResourceCache, 也就是熟悉的LRU Cache:
// GlideBuilder.java
if (memoryCache == null) {
memoryCache = new LruResourceCache(memorySizeCalculator.getMemoryCacheSize());
}
再看下EngineResource,主要是对资源增加了引用计数的功能:
// EngineResource.java
private final boolean isCacheable;
private final boolean isRecyclable;
private ResourceListener listener;
private Key key;
private int acquired;
private boolean isRecycled;
private final Resource<Z> resource;
interface ResourceListener {
void onResourceReleased(Key key, EngineResource<?> resource);
}
EngineResource(Resource<Z> toWrap, boolean isCacheable, boolean isRecyclable) {
resource = Preconditions.checkNotNull(toWrap);
this.isCacheable = isCacheable;
this.isRecyclable = isRecyclable;
}
void setResourceListener(Key key, ResourceListener listener) {
this.key = key;
this.listener = listener;
}
Resource<Z> getResource() {
return resource;
}
boolean isCacheable() {
return isCacheable;
}
@NonNull
@Override
public Class<Z> getResourceClass() {
return resource.getResourceClass();
}
@NonNull
@Override
public Z get() {
return resource.get();
}
@Override
public int getSize() {
return resource.getSize();
}
@Override
public void recycle() {
if (acquired > 0) {
throw new IllegalStateException("Cannot recycle a resource while it is still acquired");
}
if (isRecycled) {
throw new IllegalStateException("Cannot recycle a resource that has already been recycled");
}
isRecycled = true;
if (isRecyclable) {
resource.recycle();
}
}
void acquire() {
if (isRecycled) {
throw new IllegalStateException("Cannot acquire a recycled resource");
}
if (!Looper.getMainLooper().equals(Looper.myLooper())) {
throw new IllegalThreadStateException("Must call acquire on the main thread");
}
++acquired;
}
void release() {
if (acquired <= 0) {
throw new IllegalStateException("Cannot release a recycled or not yet acquired resource");
}
if (!Looper.getMainLooper().equals(Looper.myLooper())) {
throw new IllegalThreadStateException("Must call release on the main thread");
}
if (--acquired == 0) {
listener.onResourceReleased(key, this);
}
}
在release后会判断引用计数是否为0,如果是0就会回调onResourceReleased,在这里就是Engine,然后会把资源从ActiveResources中移除,资源默认是可缓存的,因此会把资源放到LruCache中。
// Engine.java
@Override
public void onResourceReleased(Key cacheKey, EngineResource<?> resource) {
Util.assertMainThread();
activeResources.deactivate(cacheKey);
if (resource.isCacheable()) {
cache.put(cacheKey, resource);
} else {
resourceRecycler.recycle(resource);
}
}
// ActiveResources.java
void activate(Key key, EngineResource<?> resource) {
ResourceWeakReference toPut =
new ResourceWeakReference(
key,
resource,
getReferenceQueue(),
isActiveResourceRetentionAllowed);
ResourceWeakReference removed = activeEngineResources.put(key, toPut);
if (removed != null) {
removed.reset();
}
}
void deactivate(Key key) {
ResourceWeakReference removed = activeEngineResources.remove(key);
if (removed != null) {
removed.reset();
}
}
如果是回收呢,看看上面的EngineResource,如果引用计数为0并且还没与回收,就会调用真正的Resource.recycle(),看其中的一个BitmapResource是怎么回收的,就是放到Bitmap池中,也是用的LRU Cache,这个和今天的主题不相关,就不继续往下拓展。
// BitmapResource.java
@Override
public void recycle() {
bitmapPool.put(bitmap);
}
思路再拉到Engine.load()的流程中,接下来该看focus 3,这里再贴一下代码,如果job已经在运行了,那么直接添加一个回调后返回LoadStatus,这个可以允许用户取消任务:
// Engine.java
EngineJob<?> current = jobs.get(key, onlyRetrieveFromCache);
if (current != null) {
current.addCallback(cb);
if (VERBOSE_IS_LOGGABLE) {
logWithTimeAndKey("Added to existing load", startTime, key);
}
return new LoadStatus(cb, current);
}
// LoadStatus
public static class LoadStatus {
private final EngineJob<?> engineJob;
private final ResourceCallback cb;
LoadStatus(ResourceCallback cb, EngineJob<?> engineJob) {
this.cb = cb;
this.engineJob = engineJob;
}
public void cancel() {
engineJob.removeCallback(cb);
}
}
接着往下看到focus 4, 到这里就需要创建后台任务去拉取磁盘文件或者发起网络请求。
三、磁盘缓存
// Engine.java
EngineJob<R> engineJob =
engineJobFactory.build(
key,
isMemoryCacheable,
useUnlimitedSourceExecutorPool,
useAnimationPool,
onlyRetrieveFromCache);
DecodeJob<R> decodeJob =
decodeJobFactory.build(
glideContext,
model,
key,
signature,
width,
height,
resourceClass,
transcodeClass,
priority,
diskCacheStrategy,
transformations,
isTransformationRequired,
isScaleOnlyOrNoTransform,
onlyRetrieveFromCache,
options,
engineJob);
jobs.put(key, engineJob);
engineJob.addCallback(cb);
engineJob.start(decodeJob);
return new LoadStatus(cb, engineJob);
先构造两个job,一个是EngineJob,另外一个DecodeJob,其中DecodeJob会根据需要解码的资源来源分成下面几个阶段:
// DecodeJob.java
/**
* Where we're trying to decode data from.
*/
private enum Stage {
/** The initial stage. */
INITIALIZE,
/** Decode from a cached resource. */
RESOURCE_CACHE,
/** Decode from cached source data. */
DATA_CACHE,
/** Decode from retrieved source. */
SOURCE,
/** Encoding transformed resources after a successful load. */
ENCODE,
/** No more viable stages. */
FINISHED,
}
在构造DecodeJob时会把状态置为INITIALIZE。
构造完两个 Job 后会调用 EngineJob.start(DecodeJob),首先会调用getNextStage来确定下一个阶段,这里面跟DiskCacheStrategy这个传入的磁盘缓存策略有关。
磁盘策略有下面几种:
**ALL: **缓存原始数据和转换后的数据
**NONE: **不缓存
**DATA: **原始数据,未经过解码或者转换
**RESOURCE: **缓存经过解码的数据
**AUTOMATIC(默认):**根据`EncodeStrategy`和`DataSource`等条件自动选择合适的缓存方
默认的AUTOMATIC方式是允许解码缓存的RESOURCE:
public static final DiskCacheStrategy AUTOMATIC = new DiskCacheStrategy() {
@Override
public boolean isDataCacheable(DataSource dataSource) {
return dataSource == DataSource.REMOTE;
}
@Override
public boolean isResourceCacheable(boolean isFromAlternateCacheKey, DataSource dataSource,
EncodeStrategy encodeStrategy) {
return ((isFromAlternateCacheKey && dataSource == DataSource.DATA_DISK_CACHE)
|| dataSource == DataSource.LOCAL)
&& encodeStrategy == EncodeStrategy.TRANSFORMED;
}
@Override
public boolean decodeCachedResource() {
return true;
}
@Override
public boolean decodeCachedData() {
return true;
}
};
所以在 getNextStage 会先返回Stage.RESOURCE_CACHE,然后在start中会返回diskCacheExecutor,然后开始执行DecodeJob:
// EngineJob.java
public void start(DecodeJob<R> decodeJob) {
this.decodeJob = decodeJob;
GlideExecutor executor = decodeJob.willDecodeFromCache()
? diskCacheExecutor
: getActiveSourceExecutor();
executor.execute(decodeJob);
}
// DecodeJob.java
boolean willDecodeFromCache() {
Stage firstStage = getNextStage(Stage.INITIALIZE);
return firstStage == Stage.RESOURCE_CACHE || firstStage == Stage.DATA_CACHE;
}
private Stage getNextStage(Stage current) {
switch (current) {
case INITIALIZE:
return diskCacheStrategy.decodeCachedResource()
? Stage.RESOURCE_CACHE : getNextStage(Stage.RESOURCE_CACHE);
case RESOURCE_CACHE:
return diskCacheStrategy.decodeCachedData()
? Stage.DATA_CACHE : getNextStage(Stage.DATA_CACHE);
case DATA_CACHE:
// Skip loading from source if the user opted to only retrieve the resource from cache.
return onlyRetrieveFromCache ? Stage.FINISHED : Stage.SOURCE;
case SOURCE:
case FINISHED:
return Stage.FINISHED;
default:
throw new IllegalArgumentException("Unrecognized stage: " + current);
}
}
DecodeJob会回调run()开始执行, run()中调用runWrapped执行工作,这里runReason还是RunReason.INITIALIZE ,根据前面的分析指导这里会获得一个ResourceCacheGenerator,然后调用runGenerators:
// DecodeJob.java
private void runWrapped() {
switch (runReason) {
case INITIALIZE:
stage = getNextStage(Stage.INITIALIZE);
currentGenerator = getNextGenerator();
runGenerators();
break;
case SWITCH_TO_SOURCE_SERVICE:
runGenerators();
break;
case DECODE_DATA:
decodeFromRetrievedData();
break;
default:
throw new IllegalStateException("Unrecognized run reason: " + runReason);
}
}
private DataFetcherGenerator getNextGenerator() {
switch (stage) {
case RESOURCE_CACHE:
return new ResourceCacheGenerator(decodeHelper, this);
case DATA_CACHE:
return new DataCacheGenerator(decodeHelper, this);
case SOURCE:
return new SourceGenerator(decodeHelper, this);
case FINISHED:
return null;
default:
throw new IllegalStateException("Unrecognized stage: " + stage);
}
}
在 runGenerators 中,会调用 startNext,目前currentGenerator是ResourceCacheGenerator, 那么就是调用它的startNext方法:
// DecodeJob.java
private void runGenerators() {
currentThread = Thread.currentThread();
startFetchTime = LogTime.getLogTime();
boolean isStarted = false;
while (!isCancelled && currentGenerator != null
&& !(isStarted = currentGenerator.startNext())) {
stage = getNextStage(stage);
currentGenerator = getNextGenerator();
if (stage == Stage.SOURCE) {
reschedule();
return;
}
}
// We've run out of stages and generators, give up.
if ((stage == Stage.FINISHED || isCancelled) && !isStarted) {
notifyFailed();
}
}
看下ResourceCacheGenerator.startNext(), 这里面就是重点逻辑了,首先从Registry中获取支持资源类型的ModelLoader(其中ModelLoader是在构造Glide的时候传进去), 然后从ModelLoader中构造LoadData,接着就能拿到DataFetcher,(关于ModelLoader/LoadData/DataFetcher之间的关系不在本次范围内,后面有机会再另写)通过它的loadData方法加载数据:
@Override
public boolean startNext() {
List<Key> sourceIds = helper.getCacheKeys();
if (sourceIds.isEmpty()) {
return false;
}
List<Class<?>> resourceClasses = helper.getRegisteredResourceClasses();
if (resourceClasses.isEmpty()) {
if (File.class.equals(helper.getTranscodeClass())) {
return false;
}
}
while (modelLoaders == null || !hasNextModelLoader()) {
resourceClassIndex++;
if (resourceClassIndex >= resourceClasses.size()) {
sourceIdIndex++;
if (sourceIdIndex >= sourceIds.size()) {
return false;
}
resourceClassIndex = 0;
}
Key sourceId = sourceIds.get(sourceIdIndex);
Class<?> resourceClass = resourceClasses.get(resourceClassIndex);
Transformation<?> transformation = helper.getTransformation(resourceClass);
currentKey =
new ResourceCacheKey(// NOPMD AvoidInstantiatingObjectsInLoops
helper.getArrayPool(),
sourceId,
helper.getSignature(),
helper.getWidth(),
helper.getHeight(),
transformation,
resourceClass,
helper.getOptions());
cacheFile = helper.getDiskCache().get(currentKey);
if (cacheFile != null) {
sourceKey = sourceId;
modelLoaders = helper.getModelLoaders(cacheFile);
modelLoaderIndex = 0;
}
}
loadData = null;
boolean started = false;
while (!started && hasNextModelLoader()) {
ModelLoader<File, ?> modelLoader = modelLoaders.get(modelLoaderIndex++);
loadData = modelLoader.buildLoadData(cacheFile,
helper.getWidth(), helper.getHeight(), helper.getOptions());
if (loadData != null && helper.hasLoadPath(loadData.fetcher.getDataClass())) {
started = true;
loadData.fetcher.loadData(helper.getPriority(), this);
}
}
return started;
}
如果在Resource中找不到需要的资源,那么startNext就会返回false,在runGenerators中就会进入循环体内:
接着会重复上面执行getNextStage,由于现在Stage已经是RESOURCE_CACHE,所以接下来会返回DataCacheGenerator,执行逻辑和上面的ResourceCacheGenerator是一样的,如果还是没有找到需要的,进入循环体内。
此时getNextStage会根据用于是否设置只从磁盘中获取资源,如果是就会通知失败,回调onLoadFailed;如果不是就设置当前Stage为Stage.SOURCE,接着往下走。
状态就会进入循环内部的if条件逻辑里面,调用reschedule。
在reschedule把runReason设置成SWITCH_TO_SOURCE_SERVICE,然后通过callback回调。
DecodeJob中的callback是EngineJob传递过来的,所以现在返回到EngineJob。
在EngineJob中通过getActiveSourceExecutor切换到网络线程池中,执行DecodeJob,下面就准备开始发起网络请求。
四、网络缓存
在Stage.SOURCE阶段,通过getNextGenerator返回的是SourceGenerator,所以目前的currentGenerator就是它。
流程还是一样的,SourceGenerator还是调用startNext方法,获取到对应的DataFetcher,这里其实是HttpUrlFetcher,发起网络请求。
// DecodeJob.java
private void runGenerators() {
...
while (!isCancelled && currentGenerator != null
&& !(isStarted = currentGenerator.startNext())) {
stage = getNextStage(stage);
currentGenerator = getNextGenerator();
if (stage == Stage.SOURCE) {
reschedule();
return;
}
}
...
}
@Override
public void reschedule() {
runReason = RunReason.SWITCH_TO_SOURCE_SERVICE;
callback.reschedule(this);
}
// EngineJob.java
@Override
public void reschedule(DecodeJob<?> job) {
getActiveSourceExecutor().execute(job);
}
先缓一缓,本文其实到了上面已经可以结束了,Glide涉及到的五级缓存都已经涉及到了,是真的就可以结束了吗?不是的,网络请求回来和缓存还有关系吗?接着看到HttpUrlFetcher,下载成功后回调onDataReady,其中callback是SourceGenerator:
// HttpUrlFetcher.java
@Override
public void loadData(@NonNull Priority priority,
@NonNull DataCallback<? super InputStream> callback) {
long startTime = LogTime.getLogTime();
try {
InputStream result = loadDataWithRedirects(glideUrl.toURL(), 0, null, glideUrl.getHeaders());
callback.onDataReady(result);
} catch (IOException e) {
if (Log.isLoggable(TAG, Log.DEBUG)) {
Log.d(TAG, "Failed to load data for url", e);
}
callback.onLoadFailed(e);
} finally {
if (Log.isLoggable(TAG, Log.VERBOSE)) {
Log.v(TAG, "Finished http url fetcher fetch in " + LogTime.getElapsedMillis(startTime));
}
}
}
// EngineJob.java
@Override
public void reschedule(DecodeJob<?> job) {
getActiveSourceExecutor().execute(job);
}
正常情况会进入if判断逻辑里面,赋值dataToCache,然后回调cb.reschedule,而cb就是DecodeJob构造SourceGenerator的时候传入,cb是DecodeJob。
// SourceGenerator.java
@Override
public void onDataReady(Object data) {
DiskCacheStrategy diskCacheStrategy = helper.getDiskCacheStrategy();
if (data != null && diskCacheStrategy.isDataCacheable(loadData.fetcher.getDataSource())) {
dataToCache = data;
cb.reschedule();
} else {
cb.onDataFetcherReady(loadData.sourceKey, data, loadData.fetcher,
loadData.fetcher.getDataSource(), originalKey);
}
}
DecodeJob在reschedule回调EngineJob,最后还是回到SourceGenerator中的startNext()逻辑。
// DecodeJob.java
private DataFetcherGenerator getNextGenerator() {
switch (stage) {
case RESOURCE_CACHE:
return new ResourceCacheGenerator(decodeHelper, this);
case DATA_CACHE:
return new DataCacheGenerator(decodeHelper, this);
case SOURCE:
return new SourceGenerator(decodeHelper, this);
case FINISHED:
return null;
default:
throw new IllegalStateException("Unrecognized stage: " + stage);
}
}
@Override
public void reschedule() {
runReason = RunReason.SWITCH_TO_SOURCE_SERVICE;
callback.reschedule(this);
}
和第一次进来的逻辑不一样,现在dataToCache != null,进入第一个if逻辑。
在逻辑里面调用cacheData,逻辑很明显,保持数据到本地,然后会构造一个DataCacheGenerator。
而DataCacheGenerator前面已经分析过了,就是用来加载本地原始数据的,这回会加载成功,返回true。
// SourceGenerator.java
@Override
public boolean startNext() {
if (dataToCache != null) {
Object data = dataToCache;
dataToCache = null;
cacheData(data);
}
if (sourceCacheGenerator != null && sourceCacheGenerator.startNext()) {
return true;
}
...
}
private void cacheData(Object dataToCache) {
long startTime = LogTime.getLogTime();
try {
Encoder<Object> encoder = helper.getSourceEncoder(dataToCache);
DataCacheWriter<Object> writer =
new DataCacheWriter<>(encoder, dataToCache, helper.getOptions());
originalKey = new DataCacheKey(loadData.sourceKey, helper.getSignature());
helper.getDiskCache().put(originalKey, writer);
} finally {
loadData.fetcher.cleanup();
}
sourceCacheGenerator =
new DataCacheGenerator(Collections.singletonList(loadData.sourceKey), helper, this);
}
接下来就是一系列的回调了:
DataCacheGenerator的startNext逻辑里面会给DataFetcher传递自身作为callback,在加载本地数据成功后回调onDataReady。
// DataCacheGenerator
@Override
public boolean startNext() {
...
loadData = null;
boolean started = false;
while (!started && hasNextModelLoader()) {
...
if (loadData != null && helper.hasLoadPath(loadData.fetcher.getDataClass())) {
started = true;
loadData.fetcher.loadData(helper.getPriority(), this);
}
}
return started;
}
@Override
public void onDataReady(Object data) {
cb.onDataFetcherReady(sourceKey, data, loadData.fetcher, DataSource.DATA_DISK_CACHE, sourceKey);
}
而cb现在是SourceGenerator传递过来,SourceGenerator再回调它自己的cb,是DecodeJob在构造它的时候传过来。
// SourceGenerator.java
@Override
public void onDataFetcherReady(Key sourceKey, Object data, DataFetcher<?> fetcher,
DataSource dataSource, Key attemptedKey) {
cb.onDataFetcherReady(sourceKey, data, fetcher, loadData.fetcher.getDataSource(), sourceKey);
}
// DecodeJob.java
@Override
public void onDataFetcherReady(Key sourceKey, Object data, DataFetcher<?> fetcher,
DataSource dataSource, Key attemptedKey) {
this.currentSourceKey = sourceKey;
this.currentData = data;
this.currentFetcher = fetcher;
this.currentDataSource = dataSource;
this.currentAttemptingKey = attemptedKey;
if (Thread.currentThread() != currentThread) {
runReason = RunReason.DECODE_DATA;
callback.reschedule(this);
} else {
try {
decodeFromRetrievedData();
} finally {
GlideTrace.endSection();
}
}
}
在上面SourceGenerator把DecodeJob切换到ActiveSourceExecutor线程中执行,还记得一开始DecodeJob是在哪启动的吗?在EngineJob中启动,然后是把DecodeJob放到diskCacheExecutor中执行。
// EngineJob.java
public void start(DecodeJob<R> decodeJob) {
this.decodeJob = decodeJob;
GlideExecutor executor = decodeJob.willDecodeFromCache()
? diskCacheExecutor
: getActiveSourceExecutor();
executor.execute(decodeJob);
}
所以上面在DecodeJob的onDataFetcherReady会走到第一个if逻辑里面,然后赋值runReason = RunReason.DECODE_DATA,再一次回调Engine.reschedule,将工作线程切换到ActiveSourceExecutor。
// Engine.java
@Override
public void reschedule(DecodeJob<?> job) {
// Even if the job is cancelled here, it still needs to be scheduled so that it can clean itself
// up.
getActiveSourceExecutor().execute(job);
}
//
然后还是走到DecodeJob, 现在会进入DECODE_DATA分支,在这里面会调用ResourceDecoder把数据解码:
private void runWrapped() {
switch (runReason) {
case INITIALIZE:
stage = getNextStage(Stage.INITIALIZE);
currentGenerator = getNextGenerator();
runGenerators();
break;
case SWITCH_TO_SOURCE_SERVICE:
runGenerators();
break;
case DECODE_DATA:
decodeFromRetrievedData();
break;
default:
throw new IllegalStateException("Unrecognized run reason: " + runReason);
}
}
解码成功后调用notifyComplete(result, dataSource);
private void notifyComplete(Resource<R> resource, DataSource dataSource) {
setNotifiedOrThrow();
callback.onResourceReady(resource, dataSource);
}
五、总结
现在回答一下开头的几个问题。
1、有几级缓存?五级,分别是什么?
活动资源 (Active Resources)
内存缓存 (Memory Cache)
资源类型(Resource Disk Cache)
原始数据 (Data Disk Cache)
网络缓存
2、Glide内存缓存之间是什么关系?
专门画了一幅图表明这个关系,言简意赅。
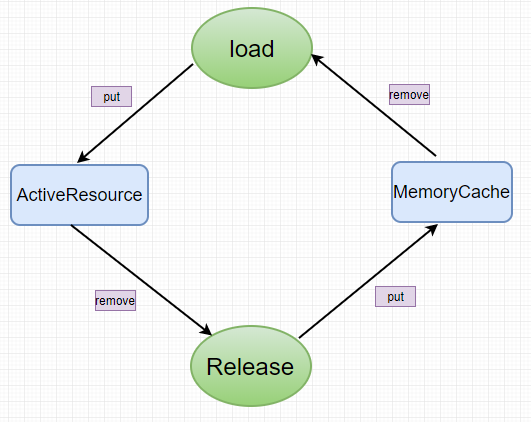
3、Glide本地文件IO和网络请求是一个线程吗?
明显不是,本地IO通过diskCacheExecutor,而网络IO通过ActiveSourceExecutor
4、Glide网络请求回来后数据直接返回给用户还是先存再返回?
不是直接返回给用户,会在SourceGenerator中构造一个DataCacheGenerator来取数据。
更多内容敬请关注 vivo 互联网技术 微信公众号

注:转载文章请先与微信号:labs2020 联系
Glide缓存流程的更多相关文章
- Glide缓存图片
是用Glide加载网络图片可以自动缓存到磁盘 添加依赖: implementation 'com.github.bumptech.glide:glide:4.9.0' implementation ' ...
- Nginx 接受上游缓存流程
L:101 这个指令主要是由上游服务器来决定是否缓存 详见博客Nginx 针对上游服务器缓存
- Glide生命周期原理
本文首发于 vivo互联网技术 微信公众号 链接:https://mp.weixin.qq.com/s/uTv44vJFFJI_l6b5YKSXYQ作者:连凌能 Android App中图片的展示是很 ...
- Android图片加载框架最全解析(三),深入探究Glide的缓存机制
在本系列的上一篇文章中,我带着大家一起阅读了一遍Glide的源码,初步了解了这个强大的图片加载框架的基本执行流程. 不过,上一篇文章只能说是比较粗略地阅读了Glide整个执行流程方面的源码,搞明白了G ...
- Android图片加载框架最全解析(二),从源码的角度理解Glide的执行流程
在本系列的上一篇文章中,我们学习了Glide的基本用法,体验了这个图片加载框架的强大功能,以及它非常简便的API.还没有看过上一篇文章的朋友,建议先去阅读 Android图片加载框架最全解析(一),G ...
- Universal-Image-Loader,android-Volley,Picasso、Fresco和Glide图片缓存库的联系与区别
Universal-Image-Loader,android-Volley,Picasso.Fresco和Glide五大Android开源组件加载网络图片比较 在Android中的加载网络图片是一件十 ...
- Android 图片加载库Glide 实战(二),占位符,缓存,转换自签名高级实战
http://blog.csdn.net/sk719887916/article/details/40073747 请尊重原创 : skay <Android 图片加载库Glide 实战(一), ...
- Glide Picasso Fresco UIL 图片框架 缓存 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- Glide清除缓存
Glide是谷歌推荐的一款加载图片的第三方框架,对内存优化更好,更省资源,他的众多好处,我就不一一描述了,有兴趣的朋友可以百度一下,介绍的还是挺详细的. 今天主要给大家介绍一下关于怎么获取Glide的 ...
随机推荐
- python探索微信朋友信息
一.itchat itchat是一个开源的微信个人号接口,这一次就用它来来玩玩. 在使用之前,先下载,老规矩通过 pip install itchat 即可安装. 想要获取朋友圈信息,只需要几行代码就 ...
- C#中提示:当前上下文中不存在名称“ConfigurationManager”
场景 想要在程序中获取App.config中设置的内容. 想要通过 ConfigurationManager.AppSettings[key]; 来进行获取,已经添加 using System.Con ...
- Ubuntu下交换CTRL与CAPSLOCK
1.编辑文件 keyboard sudo vim /etc/default/keyboard 2. 添加内容 XKBOPTIONS="ctrl:swapcaps" 3. reboo ...
- PlayJava SSM框架简介
SSM框架 SSM是Spring + Spring MVC + MyBatis的缩写,是一个继SSH之后目前比较主流的JavaEE框架,适用于搭建各种企业级应用系统. Spring Spring是一个 ...
- 墨者 - X-FORWARDED-FOR注入漏洞实战
X-FORWARDED-FOR 首先,X-Forwarded-For 是一个 HTTP 扩展头部.HTTP/1.1(RFC 2616)协议并没有对它的定义,它最开始是由 Squid 这个缓存代理软件引 ...
- Sqlite—锁机制
https://blog.csdn.net/zhangsheng_1992/article/details/52598396 https://blog.csdn.net/xiyangyang8110/ ...
- swoole加密可破解吗
程序的执行和加解密过程合二唯一,无论是内部开发人员和外部黑客攻击,即使拿到了数据和私钥和服务器的root权限,也无法解密还原数据. Swoole将加解密分成了3部分(程序+算法+私钥),缺一不可解密. ...
- Java题库——Chapter16 JavaFX UI组件和多媒体
Chapter 16 JavaFX UI Controls and Multimedia Section 16.2 Labeled and Label1. To create a label with ...
- 操作mysql第一次访问速度慢(远程)
最近在使用java操作远程的mysql数据库的时候,第一次请求非常的慢,而且极其容易引起系统的崩溃报错连接超时 下面就这个问题来解决下把 ------------------------------- ...
- 使用matplotlib库绘制函数图
函数如下: z = x^2 * y / (x^4 +y^2) 代码如下: import numpy as np import matplotlib.pyplot as plt import mpl_t ...