Hadoop自学系列集(三) ---- Hadoop安装
这节就开始讲述Hadoop的安装吧。在这之前先配置下SSH免密码登录,为什么需要配置这个呢?大家都知道Hadoop集群中可能有几十台机器甚至是上千台机器,而每次启动Hadoop都需要输入密码才能够登录到每台机器的DataNode上的,所以为了避免后期繁琐的操作,一般都会配置SSH免密码登录。
注:笔者使用的远程连接工具是XShell,很好用的一款远程连接工具,推荐大家使用,还可以安装一下xftp文件传输工具,方便于将自己电脑上的软件拷贝到虚拟机中,xftp和Xshell是可以配套使用的。
配置SSH免密码登录,首先需要有SSH的支持,当然,在第一篇中的安装CentOS系统中是会自己安装上SSH的,为了节省时间这里就不说了。不清楚是否有没有安装SSH的可以使用ssh -version进行验证,如果出现与下图相似的信息就代表已经安装了SSH了.

下面开始看看如何配置SSH免密码登录吧。
首先输入ssh localhost,验证在为配置前是无法通过ssh连接本机的
下面在用户目录下(笔者使用的是root用户,所以是/root目录,普通用户的文件夹是在/home,目录下与用户名相同的目录)ls -a ,可以看见有一个隐藏的文件夹.ssh,如果没有的话可以自行创建。然后输入一下命令,出现如下图示:
ssh-keygen -t dsa -P '' -f /root/.ssh/id_dsa

这里解释一下命令的含义(注意区分大小写):ssh-keygen代表生成密钥;-t表示生成密钥的类型;-P提供密语;-f指定生成的文件.这个命令执行完毕后会在.ssh文件夹下生成两个文件,分别是id_dsa、id_dsa.pub,这是SSH的一对私钥和公钥,就像是钥匙和锁。下一步将id_dsa.pub追加到授权的key中,键入一下命令:
cat /root/.ssh/id_dsa.pub >> /root/.ssh/authorized_keys
此时,免密码登录本机就配置完成了,下面再次输入ssh localhost进行验证,出现下图所示信息代表配置成功了
ssh localhost

看上图所示,第一次登录会询问我们是否继续连接,输入yes,第二次就无需询问直接进入了。
以上所述只是本机ssh登录,那么如何让另外三个虚拟机也能无密码访问呢?答案很简单,我们只需要输入一下命令将本机的SSH公钥copy到其他三台虚拟机上并输入相应虚拟机的的密码即可。
ssh-copy-id -i /root/.ssh/id_dsa.pub root@hadoop.slave1
#提示输入hadoop.slave1的密码
ssh-copy-id -i /root/.ssh/id_dsa.pub root@hadoop.slave2
#提示输入hadoop.slave2的密码
ssh-copy-id -i /root/.ssh/id_dsa.pub root@hadoop.slave3
#提示输入hadoop.slave3的密码
再验证一下吧,进入hadoop.slave1,输入ssh hadoop.master,此时会询问是否连接,输入yes后会要求输入hadoop.master的密码,完成后再次输入ssh hadoop.master就可以免密码登录了,剩余的两台虚拟机重复以上步骤就可以了。这样slave1,slave2,slave3就可以免密码登录master了,但是master还不能免密码登录slave1,slave2,slave3,分别进入另外三台虚拟机重复以上步骤就可以了。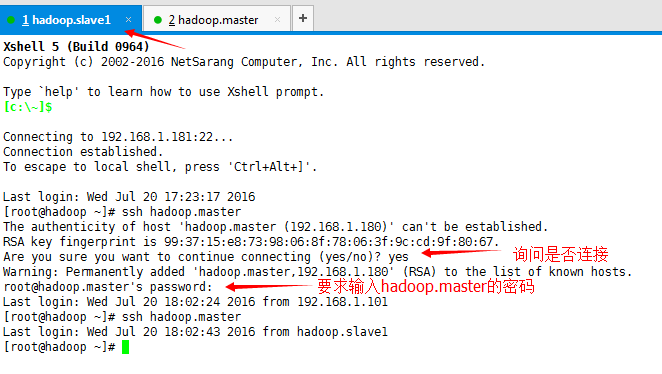
配置完成了,我们开始学习Hadoop的安装吧
Hadoop的安装
1.下载Hadoop安装包,笔者学习使用的是Hadoop1.2.1。提供一下下载地址吧: http://apache.fayea.com/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz。
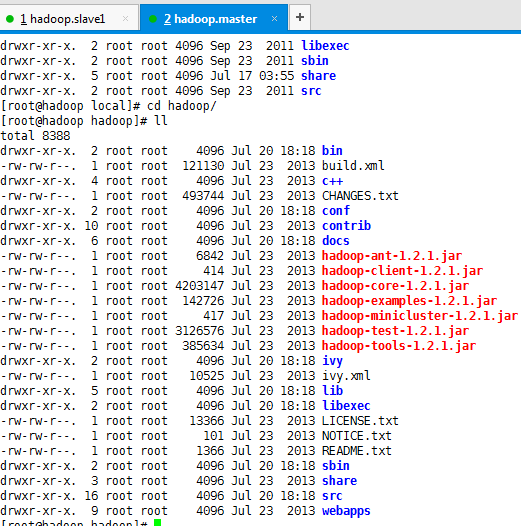
2.创建/usr/local目录,进入此目录,下载安装包后解压,解压后出出现一个hadoop-1.2.1的文件夹,修改目录名为hadoop,进入该文件夹,目录结构如下图所示
#进入/usr/local
cd /usr/local
#下载hadoop安装包
wget http://apache.fayea.com/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
#等待下载完毕.....
#解压刚下载好的安装包(解压完后安装包可以删除,但建议备份到其他目录下)
tar -zxvf hadoop-1.2.1.tar.gz
mv hadoop-1.2.1 hadoop
cd hadoop
#查看结构
ll
3.下一步我们配置一下环境变量,在/etc目录下新建一个hadoop目录,后期将hadoop相关配置文件放在该目录下,直接使用该目录下的配置文件,然后编辑/etc/profile文件,追加如下配置并保存,输入source /etc/profile使配置立即生效:
#set hadoop environment
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$PATH ##保存修改后执行
source /etc/profile
4.怎么看是否安装成功呢?现在是单机模式,直接进入/usr/local/hadoop/bin目录中执行start-all.sh命令,过程中会询问是否连接,直接输入yes
cd /usr/local/hadoop/bin
./start-all.sh
5.使用jps命令查看hadoop进程是否启动成功,如下图所示:
6.因为现在是单机模式,NameNode和JobTracker没有启动,现在就使用hadoop fs -ls查看是否安装成功:
hadoop fs -ls

如上图所示,显示的是当前所在目录的目录结构,这样就说明安装成功了.重复以上步骤,为其他三台虚拟机也安装上吧!!
截止以上步骤,Hadoop的安装已经完成了。在下一篇我们在讲如何进行hadoop的集群配置吧!敬请期待哦!
大家支持一下,记得关注!觉得还行的话也可以推荐一下,谢谢!!!
Hadoop自学系列集(三) ---- Hadoop安装的更多相关文章
- Hadoop自学系列集(四) ---- Hadoop集群
久等了,近期公司比较忙,学习的时间都没有啊,到今日才有时间呢!!!好了,下面就跟着笔者开始配置Hadoop集群吧. hosts文件和SSH免密码登录配置好了之后,现在进入Hadoop安装目录,修改一些 ...
- Hadoop自学系列集(二) ---- CentOS下安装JDK
上篇我们讲述了如何使用VMware安装CentOS系统,接下来就看如何安装我们最为熟悉的jdk吧!安装前先看看系统上有没有安装过jdk,输入java -version,如果查询出了其他版本的jdk版本 ...
- Hadoop自学系列集(一) ---- 使用VMware安装CentOS
1.概述 笔者的学习环境--在VMware虚拟机下安装四个CentOS系统(搭建Hadoop集群用),其中一个为Master,三个为Slave,Master作为Hadoop集群中的NameNode, ...
- golang 自学系列(三)—— if,for,channel
golang 自学系列(三)-- if,for,channel 一般情况下,if 语句跟大多数语言的 if 判断语句一样,根据一个 boolean 表达式结果来执行两个分支逻辑. 但凡总是有例外,go ...
- hadoop单机and集群模式安装
最近在学习hadoop,第一步当然是亲手装一下hadoop了. 下面记录我hadoop安装的过程: 注意: 1,首先明确hadoop的安装是一个非常简单的过程,装hadoop的主要工作都在配置文件上, ...
- Hadoop自学笔记(三)MapReduce简单介绍
1. MapReduce Architecture MapReduce是一套可编程的框架,大部分MapReduce的工作都能够用Pig或者Hive完毕.可是还是要了解MapReduce本身是怎样工作的 ...
- 第十二章 Ganglia监控Hadoop及Hbase集群性能(安装配置)
1 Ganglia简介 Ganglia 是 UC Berkeley 发起的一个开源监视项目,设计用于测量数以千计的节点.每台计算机都运行一个收集和发送度量数据(如处理器速度.内存使用量等)的名为 gm ...
- Hadoop概念学习系列之为什么hadoop/spark执行作业时,输出路径必须要不存在?(三十九)
很多人只会,但没深入体会和想为什么要这样? 拿Hadoop来说,当然,spark也一样的道理. 输出路径由Hadoop自己创建,实际的结果文件遵守part-nnnn的约定. 如何指定一个已有目录作为H ...
- Hadoop笔记系列 一 用Hadoop进行分布式数据处理(1)
学习资料参考地址: 1.http://blog.csdn.net/zhoudaxia/article/details/8801769 1.先说说什么是Hadoop? 个人理解:一个分布式文件存储系统+ ...
随机推荐
- 信鸽推送在springboot中出现jar包冲突问题
错误提示 : java.lang.NoSuchMethodError: org.json.JSONObject.put(Ljava/lang/String;Ljava/util/Collection; ...
- Laravel --- 部署Laravel项目到vps主要步骤以及遇到的问题记录
买了一个国外的vps,然后搭建环境并且跑了下laravel,折腾了一天半左右,遇到的问题和操作在此记录下: 1.我把本地的代码用git方式上传到github,然后在vps用git下载代码,步骤如下 - ...
- sed命令和find命令的结合的使用
linux中查找当前目录及其子目录下的所有test.txt文件,并将文件中的oldboy替换成oldgirl 首先查找出当前目录及其子目录下的所有的test.txt文件 [root@zxl zxl]# ...
- FPM
https://github.com/pangudashu/php7-internal/blob/master/1/fpm.md
- Git及基础命令的介绍以及如何向本地仓库添加文件
在介绍Git的使用之前,我们得要先来了解一下Git.那么什么是Git? Git是一个版本管理工具(VCS),具有以下的特点: 分布式版本控制: 多个开发人员协调工作: 有效监听谁做的修改: 本地及远程 ...
- springboot-redis-crda example
springboot-redis-crda example 1. 从 https://github.com/XLuffyStory/springboot-redis-crdu 拿到源码之后,导入到ST ...
- Linux搭建基于BIND的DNS服务器
Linux搭建基于BIND的DNS服务器 实验目标: 通过本实验掌握基于Linux的DNS服务器搭建. 实验步骤: 1.安装BIND 2.防火墙放通DNS服务 3.编辑BIND的主配置文件 4.编 ...
- [apue] dup2的正确打开方式
管道与重定向常常需要使用dup与dup2复制句柄,其中dup2又较为常用,但是使用dup2有几个小坑需要注意. int dup2(int oldfd, int newfd); man手册页上是这样讲的 ...
- eclipse中一个项目引用另一个项目,运行报:java.lang.NoClassDefFoundError
项目右击-properties-Java Build Path -Porjects-add.选中了某个项目. 项目用tomcat启动时,报错:java.lang.NoClassDefFoundErro ...
- 跟我学SpringCloud | 第十一篇:使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
SpringCloud系列教程 | 第十一篇:使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪 Springboot: 2.1.6.RELEASE SpringCloud: ...