关于adaboost分类器
我花了将近一周的时间,才算搞懂了adaboost的原理。这根骨头终究还是被我啃下来了。
Adaboost是boosting系的解决方案,类似的是bagging系,bagging系是另外一个话题,还没有深入研究。Adaboost是boosting系非常流行的算法。但凡是介绍boosting的书籍无不介绍Adaboosting,也是因为其学习效果很好。
Adaboost首先要建立一个概念:
弱分类器,也成为基础分类器,就是分类能力不是特别强,正确概率略高于50%的那种,比如只有一层的决策树。boosting的原理就是整合弱分类器,使其联合起来变成一种"强分类器"。
在Adaboost中,就是通过训练出多个弱分类器,然后为他们赋权重;最后形成了一组弱分类器+权重的模型,
那么,关键来了怎么选择弱分类器,怎么来分配权重?据说弱分类器可以是svm,可以是逻辑回归;但是我看到资料和描述都是以决策树为蓝本的。
要想要搞懂adaboost,还要搞懂他的两个层级的权重,第一个权重是上面我们讲到的分类器的权重,成为alpha,是一个浮点型的值;
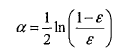
另外一个是样本权重,称之为D,是一个列向量,和每个样本对应。首先讲一下样本权重,在一个分类器训练出来之后,将会重新设置样本权重,首个分类器他的样本权重是一样的,都是1/sample_count,然后每每次训练完,都会调整这个这个样本权重,为什么?我们继续沿用决策树说事。调整的策略就是增大预测错误的样本的权重,为什么?样本权重只有一个作用,就是计算错误权重,错误权重errorWeight=D.T * errorArr,errorArr是预测错误的列向量,预测正确的样本对应值0,预测错误的为1,样本权重D就是做件事情,那么对于决策树模型而言,本轮某个特征判断错了,那么样本其实就上了黑名单,用数学表示就是这个这个样本的权重将会增加,

样本权重增加导致了什么?其实不会导致什么,即使说明了某个样本的错误比重要增加。所谓错误权重,都是判断错误,如果历史某个样本已经判读出错过一次,那么这个样本如果再错,它的错误权重就要增加,这种权重的改变(D中元素wi的总和不变,保持为1),将会导致weighterror值更加有意义,判定最小weighterror也会更加准确。如果判断对了,会相应的减小样本的权重。
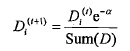
两层的权重介绍完了,基本算法也就明了了。
下面即使就两层权重来说明一下两层算法。内层的算法是遍历样本中的每个特征,然后再从特征值的最小值开始尝试进行分类,逐渐按照等量增加特征值不断地尝试分类一直达到最大值,走完了一轮特征,换下一个特征,在逐次增加特征值...计算下来每次尝试的错误权重,记录下来最小的错误权重的信息,信息包括:特征列索引,特征值以及逻辑比较(大于还是小于),当把所有的特征跑完一遍,到此,一个分类器就横空出世了,设么是分类器?本质就是最小错误权重的信息,就是分类器。
# 分类,满足指定取值范围的分类为-1,不满足的为1
def stumpClassifier(dataMat, dim, threshValue, inequal):
#print("stumpClassifier-dataMat: ")
#print(dataMat)
retArr = ones((shape(dataMat)[0], 1))
if(inequal=="lt"):
retArr[dataMat[:,dim]<=threshValue] = -1
else:
retArr[dataMat[:,dim]>threshValue] = -1
return retArr # 返回一个弱分类器,本质上就是一个一层决策树,这棵树包括:
# 1.错误权重最低的区分特征以及特征值信息
# 2.最小错误权重
# 3.最小错误权重对应的预测分类
def buildstump(dataArr, labelArr, D):
datamat = mat(dataArr)
labelmat = mat(labelArr).T
m,n = shape(datamat)
errorArr = mat(zeros((m,1)))
beststump = {}
bestClassEst = mat(zeros((m, 1)))
minError = inf
numstep = 10.0 # 这里设置了一个float类型
# 遍历每一列,寻求最分度最大的特征(维度)自己特征值
for i in range(n):
minvalue = datamat[:,i].min()
maxvalue = datamat[:,i].max()
stepsize = (maxvalue - minvalue)/numstep
for j in range(-1, int(numstep) + 1):
for ineq in ["lt", "gt"]:
threshValue = minvalue + int(j) * stepsize
predictValue = stumpClassifier(datamat, i, threshValue, ineq)
errorArr = mat(ones((m, 1))) # 一个列向量
# 这里设置分类正确的矩阵值为0,这样在参与计算错误权重的时候,正确分类就不参与计算,只有错误分类错误的样本才会参与计算
errorArr[predictValue==labelmat] = 0
# 这里注意,虽然是行向量和列向量相乘结果是累加值,但是形式还是一个矩阵,结果获取方需要通过float等函数进行处理
# D在初始化的时候是1/m,之后将会根据学习情况,提高错误样本的权重,减少正确样本点的权重
weightError = D.T * errorArr
#print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshValue, ineq, weightError))
if(weightError < minError):
minError = weightError
bestClassEst = predictValue.copy()
beststump["dim"] = i
beststump["threshVal"] = threshValue
beststump["ineq"] = ineq return beststump, minError, bestClassEst
作为外层算法,是一个循环调用内层算法的过程,每当获得了一个分类器,都要为他计算权重,权重alpha的计算公式上面已经给出,总之和最小错误权重有关系,错误权重越小,分类器的权重越高,说明是优质分类器(相对的),反之亦然;然后就是累加权重alpha*预测值classEst,累加的目标就是sign和真实的分类器一致,注意是符号一致,真实分类器只有-1,1两种值。如果一致了,退出循环;不一致,说明还要再引入分类器,此时再来计算D值(参见上文公式),然后基于D值再来调用内层算法。
这样不断获得分类器,直到分类一致(或者循环次数达到指定次数)。外层算分目的是获取到一组分类器,这组分类器是经过训练,实现了全来一遍,就可以保证累加权重预测值之和的符号(sign)和真实的分类一致。
from numpy import multiply
from numpy import exp
from numpy import zeros
from numpy import log # adaboost本质其实就是将多个分类器按照训练的权重进行整合,每个分类器都提供了区分度最高的特征以及特征值区分范围(包括值以及lt/gt)
# 在使用的时候因为是二元分类,所以每个分类器都是关注自己的识别出来的关键特征来进行分类,最后通过权重来进行整合。demo中的数据因为特征
# 比较少,所以三轮下来就OK了,如果是多特征的需要更多分类器来进行是别的。
def adaboostTransDS(dataArr, labelArr, itNum=41):
dataMat = mat(dataArr)
m = shape(dataMat)[0]
D = mat(ones((m, 1))/m)
weakClassArr=[]
aggClassEst=mat(zeros((m,1)))
for i in range(itNum):
# classESt代表的是本轮学习中,错误率最低的样本预测分类情况
# 获取一个分类器
bestStump, error, classEst = buildstump(dataMat, labelArr, D)
# 计算该分类器的alpha值,注意这里必须要通过float进行强壮,否则alpha将会是矩阵值形式,无法参与后续的计算。具体原因参见buildstump
# 注意alpha是分类器级别的权重,D则是分类器中样本的权重;而且error越小,alpha越大,分类器的权重也越大
alpha = float(0.5 * log((1 - error)/ max(error, 1e-16)))
bestStump["alpha"] = alpha
# 添加该分类器的信息
weakClassArr.append(bestStump) # 计算下一个分类器中样本的D值(权重),D值是
labelMat = mat(labelArr).T
alphaLabel = -1 * alpha * labelMat
# labelMat和classEst要么-1,要么1,这里的乘法就是要解决一个问题:判断正确的是-alpha,判断错误的是alpha,这个逻辑是
# 根据D的公式来的,通过这个符号实现如果是判断正确,则减轻权重,判断错误则家中权重;
# 之所以要加重错误列的权重是为了让下一个分类器注意了,如果下一个分类器还是在此特征上面预测错误,那么错误权重会增加,这个
# 特征就作为最小错误权重(weihterror)特征出现的可能性就降低了。
expon = multiply((-1)*alpha * labelMat, classEst)
D = multiply(D ,exp(expon))
# D是如何保证D集合的值之和是1的呢?因为D/D.sum(),就像1/6,2/6,3/6之和为1的道理一样的
D = D/D.sum()
print("alpha is: " + str(alpha))
#print("D is: ")
#print(D)
print("classEst:")
print(classEst)
# 计算Error值,这里其实是累加每个分类器的预测值,直到他们的累加值的符号和目标分类目标一致,所以错误率并不是每个分类器的错误率
# 而是分类器的分类预估*alpha的累加列向量vs原始分类列向量的错误率。
# 之类classEst是由-1和1组成,所以是带有符号的
aggClassEst += alpha * classEst
#print("aggClassEst")
#print(aggClassEst)
errorMat = sign(aggClassEst) != labelMat
#print("errorMat")
#print(errorMat)
aggErrors = multiply(errorMat, ones((m,1)))
errorRate = aggErrors.sum() / m
print("error rate: %f" % errorRate) if(errorRate == 0.0):
break return weakClassArr
有了这组分类器,即adaboost classifieies,那么就可以进行分类了。
首先是获取训练数据集,然后通过外层算法获取到adaboost classifieies(组分类器),这个是训练过程;获得了组分类器之后,在获取测试数据集,然后遍历分类器,让每个分类器都对这批测试数据进行分类,每个分类器都会使用自己最好的分类方式(权重错误最低)来进行分类,即根据指定的特征,利用指定特征值进行比较分类;得到的分类结果(-1,1集合)将会乘以他们的权重(alpha),成为权重分类向量(weightClassEst);然后将各个分类器的权重分类向量进行累加(aggClassEst),最后取aggClassEst的符号作为分类结果。到此,分类结束。
def adaClassifier(dataToClass, classifierArr):
dataTestMat = mat(dataToClass)
print("handler dataset is: ")
print(dataTestMat)
classifer_count = shape(classifierArr)[0]
data_count = shape(dataTestMat)[0]
aggClassEst = mat(zeros((data_count, 1)))
for i in range(classifer_count):
classifier = classifierArr[i]
print(classifier)
classEst = stumpClassifier(dataTestMat, classifier["dim"], classifier["threshVal"], classifier["ineq"])
aggClassEst += classifier["alpha"]*classEst
print("aggClassEst")
print(aggClassEst)
return sign(aggClassEst) # 开始分类
dataMat, labelArr = loadSimpData()
classifierArr = adaboostTransDS(dataMat, labelArr, 9)
adaClassifier([[0,0],[5,5]], classifierArr)
关于adaboost分类器的更多相关文章
- 使用OpenCV训练Haar like+Adaboost分类器的常见问题
<FAQ:OpenCV Haartraining>——使用OpenCV训练Haar like+Adaboost分类器的常见问题 最近使用OpenCV训练Haar like+Adaboost ...
- OpenCV学习记录(二):自己训练haar特征的adaboost分类器进行人脸识别 标签: 脸部识别opencv 2017-07-03 21:38 26人阅读
上一篇文章中介绍了如何使用OpenCV自带的haar分类器进行人脸识别(点我打开). 这次我试着自己去训练一个haar分类器,前后花了两天,最后总算是训练完了.不过效果并不是特别理想,由于我是在自己的 ...
- 6-8 adaboost分类器2
重点分析了Adaboost它的分类结构,以及如何使用Adaboost.这一节课讲解Adaboost分类器它训练的步骤以及训练好之后的XML文件的文件结构.所以这节课的核心是Adaboost分类器它的训 ...
- 6-7 adaboost分类器1
如何利用特征来区分目标,进行阈值判决.adaboost分类器它的优点在于前一个基本分类器分出的样本,在下一个分类器中会得到加强.加强后全体的样本那么再次进行整个训练.加强后的全体样本再次被用来训练下一 ...
- 使用 AdaBoost 元算法提高分类器性能
前言 有人认为 AdaBoost 是最好的监督学习的方式. 某种程度上因为它是元算法,也就是说它会是几种分类器的组合.这就好比对于一个问题能够咨询多个 "专家" 的意见了. 组合的 ...
- 第九篇:使用 AdaBoost 元算法提高分类器性能
前言 有人认为 AdaBoost 是最好的监督学习的方式. 某种程度上因为它是元算法,也就是说它会是几种分类器的组合.这就好比对于一个问题能够咨询多个 "专家" 的意见了. 组合的 ...
- 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第7章 - 利用AdaBoost元算法提高分类性能. 核心思想 在使用某个特定的算法是, ...
- 【原】训练自己haar-like特征分类器并识别物体(2)
在上一篇文章中,我介绍了<训练自己的haar-like特征分类器并识别物体>的前两个步骤: 1.准备训练样本图片,包括正例及反例样本 2.生成样本描述文件 3.训练样本 4.目标识别 == ...
- Real Adaboost总结
Real Adaboost分类器是对经典Adaboost分类器的扩展和提升,经典Adaboost分类器的每个弱分类器仅输出{1,0}或{+1,-1},分类能力较弱,Real Adaboost的每个弱分 ...
随机推荐
- day 30 客户端获取cmd 命令的步骤
import subprocessimport structimport jsonfrom socket import *server=socket(AF_INET,SOCK_STREAM)serve ...
- 【转】Delphi 10.3关于相机该注意的细节
感谢移动信息化专家提供的方法,他的ChinaCock组件是相当的专业,感兴趣可以加入qq群223717588.
- scrapy-CrawlSpider的rules使用规则
1.allow设置规则的方法:要能够限制在我们想要的url上面.不要跟其他的url产生相同的正则表达式即可: 2.什么情况下使用follow:如果在爬取页面的时候,需要将满足当前条件的url再进行跟进 ...
- 线程简述(Thread)
线程: 进程是一个正在运行的程序,例如电脑上现在在运行的qq,浏览器,电脑管家,这些都是进程 线程就是每一个进程中的一个执行单元,每一个进程至少一个线程,可以有多个线程,例如浏览器上每一个打开的网页都 ...
- js- caller、 callee
caller 返回一个对函数的引用,该函数调用了当前函数. functionName.caller functionName对象 是所执行函数的名称. 说明 对于函数来说 ...
- LOD,听起来很牛逼的样子
<!DOCTYPE html> <html lang="en"> <head> <title>three.js webgl - le ...
- spark-streaming first insight
一. Spark Streaming 构建在Spark core API之上,具备可伸缩,高吞吐,可容错的流处理模块. 1)支持多种数据源,如Kafka,Flume,Socket,文件等: Basic ...
- PHP目前比较常见的五大运行模式SAPI(转)
运行模式 关于PHP目前比较常见的五大运行模式: 1)CGI(通用网关接口/ Common Gateway Interface) 2)FastCGI(常驻型CGI / Long-Live CGI) 3 ...
- 【计算机视觉】欧拉角Pitch/Yaw/Roll
Pitch: 俯仰角: Yaw: 偏航角或者航向角: Roll: 横摆角或者翻滚角: 这几个角度是这样定义的,至于坐标系不同,则对应不同的XYZ轴及其方向: 1. https://en.wikiped ...
- 百练6247-过滤多余的空格-2015正式B题
B:过滤多余的空格 总时间限制: 1000ms 内存限制: 65536kB 描述 一个句子中也许有多个连续空格,过滤掉多余的空格,只留下一个空格. 输入 一行,一个字符串(长度不超过200),句子的 ...