高维数据的高速近期邻算法FLANN
版权声明:本文为博主原创文章,未经博主同意不得转载。 https://blog.csdn.net/jinxueliu31/article/details/37768995
高维数据的高速近期邻算法FLANN
1. 简单介绍
在计算机视觉和机器学习中,对于一个高维特征,找到训练数据中的近期邻计算代价是昂贵的。对于高维特征,眼下来说最有效的方法是 the randomized k-d forest和the priority search k-means tree,而对于二值特征的匹配 multiple hierarchical clusteringtrees则比LSH方法更加有效。
眼下来说。fast library for approximate nearest neighbors (FLANN)库能够较好地解决这些问题。
2. 高速近似NN匹配(FAST APPROXIMATE NN MATCHING)
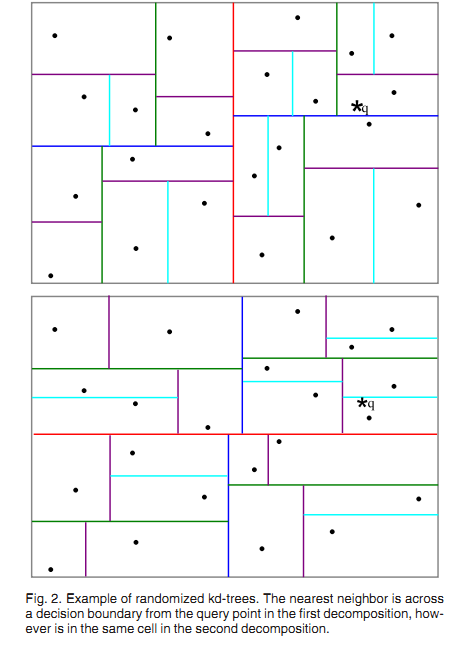
2.1 随机k-d树算法(The Randomized k-d TreeAlgorithm)
a. Classick-d tree
找出数据集中方差最高的维度,利用这个维度的数值将数据划分为两个部分,对每一个子集反复同样的过程。
參考http://www.cnblogs.com/eyeszjwang/articles/2429382.html。
b. Randomizedk-d tree
建立多棵随机k-d树。从具有最高方差的N_d维中随机选取若干维度,用来做划分。在对随机k-d森林进行搜索时候。全部的随机k-d树将共享一个优先队列。
添加树的数量能加快搜索速度。但因为内存负载的问题。树的数量仅仅能控制在一定范围内,比方20,假设超过一定范围,那么搜索速度不会添加甚至会减慢。
2.2 优先搜索k-means树算法(The Priority Search K-MeansTree Algorithm)
随机k-d森林在很多情形下都非常有效,可是对于须要高精度的情形,优先搜索k-means树更加有效。 K-means tree 利用了数据固有的结构信息,它依据数据的全部维度进行聚类,而随机k-d tree一次仅仅利用了一个维度进行划分。
2.2.1 算法描写叙述
算法1 建立优先搜索k-means tree:
(1) 建立一个层次化的k-means 树;
(2) 每一个层次的聚类中心,作为树的节点;
(3) 当某个cluster内的点数量小于K时。那么这些数据节点将做为叶子节点。

算法2 在优先搜索k-means tree中进行搜索:
(1) 从根节点N開始检索。
(2) 假设是N叶子节点则将同层次的叶子节点都添加到搜索结果中。count += |N|。
(3) 假设N不是叶子节点。则将它的子节点与query Q比較。找出近期的那个节点Cq。同层次的其它节点添加到优先队列中。
(4) 对Cq节点进行递归搜索;
(5) 假设优先队列不为空且 count<L。那么从取优先队列的第一个元素赋值给N,然后反复步骤(1)。

聚类的个数K,也称为branching factor 是个非常基本的參数。
建树的时间复杂度 = O( ndKI ( log(n)/log(K) )) n为数据点的总个数,I为K-means的迭代次数。搜索的时间复杂度 = O( L/K * Kd * ( log(n)/(log(K) ) ) = O(Ld ( log(n)/(log(K) ) )。
2.3 层次聚类树 (The Hierarchical ClusteringTree)
层次聚类树採用k-medoids的聚类方法。而不是k-means。
即它的聚类中心总是输入数据的某个点,可是在本算法中,并没有像k-medoids聚类算法那样去最小化方差求聚类中心,而是直接从输入数据中随机选取聚类中心点,这个方案在建立树时更加简单有效,同一时候又保持多棵树之间的独立性。
同一时候建立多棵树,在搜索阶段并行地搜索它们能大大提高搜索性能(归功于随机地选择聚类中心。而不须要多次迭代去获得更好的聚类中心)。建立多棵随机树的方法对k-d tree也十分有效,但对于k-means tree却不适用。


3. 參考文献
(1) ScalableNearest Neighbor Algorithms for High Dimensional Data. Marius Muja, Member,IEEE and David G. Lowe, Member, IEEE.
(2) OptimisedKD-trees for fast image descriptor matching. Chanop Silpa-Anan, Richard Hartley.
(3) FastMatching of Binary Features. Marius Muja and David G. Lowe.
高维数据的高速近期邻算法FLANN的更多相关文章
- 机器学习实践之K-近邻算法实践学习
关于本文说明,本人原博客地址位于http://blog.csdn.net/qq_37608890,本文来自笔者于2017年12月04日 22:54:26所撰写内容(http://blog.csdn.n ...
- Python机器学习笔记 K-近邻算法
K近邻(KNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一. 所谓K最近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表.KNN算法的 ...
- [转]Python3《机器学习实战》学习笔记(一):k-近邻算法(史诗级干货长文)
转自http://blog.csdn.net/c406495762/article/details/75172850 版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[-] 一 简 ...
- 秒懂机器学习---k-近邻算法实战
秒懂机器学习---k-近邻算法实战 一.总结 一句话总结: k临近算法的核心就是:将训练数据映射成k维空间中的点 1.k临近算法怎么解决实际问题? 构建多维空间:每个特征是一维,合起来组成了一个多维空 ...
- 机器学习——k-近邻算法
k-近邻算法(kNN)采用测量不同特征值之间的距离方法进行分类. 优点:精度高.对异常值不敏感.无数据输入假定 缺点:计算复杂度高.空间复杂度高 使用数据范围:数值型和标称型 工作原理:存在一个样本数 ...
- 第二章:k-近邻算法
本章内容k-近邻分类算法从文本文件中解析和导人数据 使用Matplotlib创建扩散图归一化数值 2.1 k-近邻算法概述简单地说,k-近邻算法采用测量不同特征值之间的距离方法进行分类.
- 机器学习算法一:K-近邻算法
最近在<机器学习实战>里学习了一些基本的算法,对于一个纯新手我也在网上找了写资料,下面就我在书上所看的加上在其他博客上的内容做一个总结,博客请参照http://www.cnblogs.co ...
- k-近邻算法概述
2.1 k-近邻算法概述 k-近邻算法采用测量不同特征值之间的距离方法进行分类. 优点:精度高.对异常值不敏感.无数据输入假定. 确定:计算复杂度高.空间复杂度高. 适用数据范围:数值型和标称型. 工 ...
- 机器学习实战笔记-k-近邻算法
机器学习实战笔记-k-近邻算法 目录 1. k-近邻算法概述 2. 示例:使用k-近邻算法改进约会网站的配对效果 3. 示例:手写识别系统 4. 小结 本章介绍了<机器学习实战>这本书中的 ...
随机推荐
- Bootstrap--思维导图
Bootstrap--思维导图
- 2.15 C++常量指针this
参考: http://www.weixueyuan.net/view/6346.html 总结: 在每一个成员函数中都包含一个常量指针,我们称其为this指针,该指针指向调用本函数的对象,其值为该对象 ...
- HDU 2602 Bone Collectors(背包问题,模版)
Bone Collector Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)To ...
- 数据库别名AS区别
Oracle之别名小结 MySQL表别名.字段别名注意事项 字段别名:可加 as ,也可以不加,可以加单|双引号,也可以不加: 表别名:可加 as ,也可以不加,但是一定不能加单|双引号! Orac ...
- python生产者消费者模型优点
生产者消费者模型:解耦,通过队列降低耦合,支持并发,生产者和消费者是两个独立的并发体,他们之间使用缓存区作为桥梁连接,生产者指望里丢数据,就可以生产下一个数据了,消费者从中拿数据,这样就不会阻塞,影响 ...
- python 递归进阶操作方法
递归 在函数内部,可以调用其他函数; 如果一个函数在内部调用自身本身,这个函数就是递归函数. 例如,我们来计算阶乘: n! = 1 x 2 x 3 x ... x n, 用函数f1(n)表示,可以看出 ...
- python day05--字典
一.字典结构 {key:valu} 注意: key必须是不可变(可哈希)的. value没有要求.可以保存任意类型的数据. dic = {123: 456, True: 999, "id&q ...
- [JetBrains注册] 利用教育邮箱注册JetBrains产品(pycharm、idea等)的方法
我们在使用JetBrains的一些产品时,大多使用网上的一些key去注册或者pojie的,但是由于提供这些key的服务器并不能保证稳定可用,所以可能一段时间我们使用的ide又需要重新pojie. 这里 ...
- ubuntu16.04系统安装
0x1镜像下载 (1)下载地址http://cn.ubuntu.com/download/ 0x2 安装 (1)打开vmware,创建新的虚拟机 (2)选择自定义安装 (3)直接下一步,选择稍后安装系 ...
- 【一题多解】Python 字符串逆序
https://blog.csdn.net/seetheworld518/article/details/46756639 https://blog.csdn.net/together_cz/arti ...