037 对于HIVE架构的理解
0.发展
在hive公布源代码之后
公司又公布了presto,这个比较快,是基于内存的。
impala:3s处理1PB数据。
1.Hive 能做什么,与 MapReduce 相比优势在哪里
关于hive这个工具,hive学习成本低,入手快,对于熟悉sql语法的人来说,操作简单,熟悉。
其实,还有一个,就是统一的数据管理,可与impala/spark等共享元数据。
2.为什么说 Hive 是 Hadoop 数据仓库,从【数据存储和分析】方 面理解
对于有固定格式的文件,使用HIVE把他存储到HDFS上,然后使用hive操作这些数据,语句执行依赖hadoop,这就是hive的由来。
所以说,Hive是建立在hadoop之上的。
下面具体说明一下:
1.hive构建在Hadoop之上,所有的数据存储在hadoop中hdfs上。
2.分析数据查询数据都是讲任务转化为底层的MapReduce模板,在hadoop上运行。
3.执行的程序可以在yarn上运行。
正是因为hive是hadoop的数据仓库,所以,也有了hive的其他特点:
1.优势在于处理大数据
2.Hive适合离线情况,所以延迟情况比较大。
3.扩张性较好,可以自定义数据类型
3.hive补充
将结构化的结构映射成表。
本质,将SQL转换成mapreduce,也算是hadoop的客户端,不干事情。
4. Hive 架构,分为三个部分来理解,最好通过画图理解
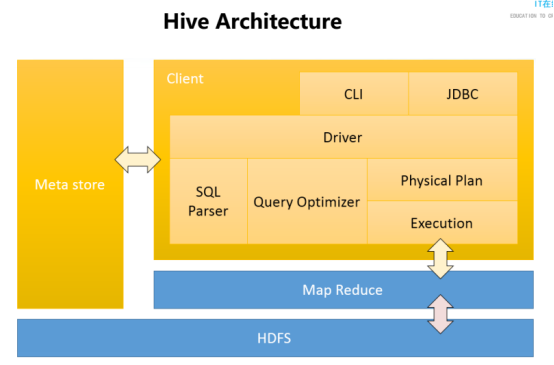
Hive分为Meta store,HDFS,Client三部分。
1.Meta srore 是元数据,默认存储在derby数据库,建议修改配置时修改。
2.HDFS,说明hive的数据存储在很多粉丝上。
3.Client:用户的接口是Cli。通过JDBC链接Driver驱动。
Sql parser是SQL解析器
Query optimizer是优化器。
Physical plan是物理计划。
一步步执行,生成的物理计划,存储在HDFS 上,并随后有mapreduce调用执行。
5.扩展性与灵活性
比较好,因为支持UDF,自定义存储格式。
同时,可以扩展集群规模。
6.总结
构建在hadoop之上的数据仓库
使用HQL作为查询接口,使用HBase存储,使用mapreduce进行计算。
037 对于HIVE架构的理解的更多相关文章
- 对于HIVE架构的理解
1.Hive 能做什么,与 MapReduce 相比优势在哪里 关于hive这个工具,hive学习成本低,入手快,对于熟悉sql语法的人来说,操作简单,熟悉. 2.为什么说 Hive 是 Hadoo ...
- SQL SERVER 2005/2008 中关于架构的理解(二)
本文上接SQL SERVER 2005/2008 中关于架构的理解(一) 架构的作用与示例 用户与架构(schema)分开,让数据库内各对象不再绑在某个用户账号上,可以解决SQL SERVE ...
- SQL SERVER 2005/2008 中关于架构的理解(一)
SQL SERVER 2005/2008 中关于架构的理解(一) 在一次的实际工作中碰到以下情况,在 SQL SERVER 2008中,新建了一个新用户去访问几张由其他用户创建的表,但是无法进行查询, ...
- 关于ASP.NET或VS2005 搭建三层架构的理解
最近想学习ASP.NET建网站,关于ASP.NET或VS2005 搭建三层架构的理解,网上摘录了一些资料,对于第(2)点的讲解让我理解印象深刻,如下: (1)为何使用N层架构? 因为每一层都可以在仅仅 ...
- 【转】Linux 概念架构的理解
转:http://mp.weixin.qq.com/s?__biz=MzA3NDcyMTQyNQ==&mid=400583492&idx=1&sn=3b18c463dcc451 ...
- Hive之 hive架构
Hive架构图 主要分为以下几个部分: 用户接口,包括 命令行CLI,Client,Web界面WUI,JDBC/ODBC接口等 中间件:包括thrift接口和JDBC/ODBC的服务端,用于整合Hiv ...
- 【转】SQL SERVER 2005/2008 中关于架构的理解
在一次的实际工作中碰到以下情况,在 SQL SERVER 2008中,新建了一个新用户去访问几张由其他用户创建的表,但是无法进行查询,提示“对象名'CustomEntry' 无效.”.当带上了架构名称 ...
- Hive架构
Hive组织数据包含四种层次:DataBase --> Table --> Partition --> Bucket,对应在HDFS上都是文件夹形式. 数据库和数据仓库的区别: 1) ...
- hive学习(一)hive架构及hive3.1.1三种方式部署安装
1.hive简介 logo 是一个身体像蜜蜂,头是大象的家伙,相当可爱. Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据.它架构在Hadoop之上,总归为大数据,并使得查询和分析方便 ...
随机推荐
- nmap扫描出现tcpwrapped
FAQ tcpwrapped From SecWiki Jump to: navigation, search What does "tcpwrapped" mean? tcpwr ...
- Linux - DDOS检测
netstat netstat -na #显示所有连接到服务器的活跃的网络连接 netstat -an | grep : | sort # 只显示连接到80段口的活跃的网络连接,80是http端口, ...
- Java EE之Struts2-2.5配置
开学以来,已经三周了.Java EE却不太走心,于是,这几日空杯心态,重新学习.复习了Java SE和Java Web开发技术,然后入手Struts2.为了使用最新版本的Structs2,我去官网下载 ...
- Java SE之Java工作原理
在Java中引入了虚拟机的概念,即在机器和编译程序之间加入了一层抽象的虚拟的机器.这台虚拟的机器在任何平台上都提供给编译程序一个的共同的接口.编译程序只需要面向虚拟机,生成虚拟机能够理解的代码,然后 ...
- hashMap之jdk1.7和jdk1.8
参考链接: http://allenwu.itscoder.com/hashmap-analyse https://tech.meituan.com/java-hashmap.html
- SVG2PNG(前台和后台将SVG转换为PNG)--amcharts导出png
在项目中用到了amcharts,amcharts图标统计插件是利用SVG实现的,其自带下载png功能,但是不支持IE以下浏览器.因此研究了SVG转换为png,最终实现的效果是将amcharts生成一张 ...
- DNS详解: A记录,子域名,CNAME别名,PTR,MX,TXT,SRV,TTL
DNS DNS,Domain Name System或者Domain Name Service(域名系统或者域名服务).域名系统为Internet上的主机分配域名地址和IP地址.由于网络中的计算机都必 ...
- SQL表链接
- activiti 基础
一:activiti 入门 作者:fenng 商丘 工作流(Workflow) 就是业务过程的部分或整体在计算机应用环境下的自动化主要解决的是"使在多个参与者之间按照某种定义的规则传递文档, ...
- CentOS中在/etc/rc.local添加开机自启动项启动失败
应项目要求需要在开机的时候启动自己的Agent程序,想当然的直接就往/etc/rc.local当中添加启动命令,结果重启之后发现什么都没有发生....一开始还以为是Python路径的问题,结果改成绝对 ...