Spark应用HanLP对中文语料进行文本挖掘--聚类详解教程
软件:IDEA2014、Maven、HanLP、JDK;
用到的知识:HanLP、Spark TF-IDF、Spark kmeans、Spark mapPartition;
用到的数据集:http://www.threedweb.cn/thread-1288-1-1.html(不需要下载,已经包含在工程里面);
工程下载:https://github.com/fansy1990/hanlp-test 。
1、问题描述
现在有一个中文文本数据集,这个数据集已经对其中的文本做了分类,如下:
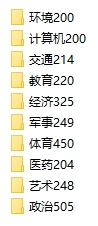
其中每个文件夹中含有个数不等的文件,比如环境有200个,艺术有248个;同时,每个文件的内容基本上就是一些新闻报道或者中文描述,如下:
现在需要做的就是,把这些文档进行聚类,看其和原始给定的类别的重合度有多少,这样也可以反过来验证我们聚类算法的正确度。
2.、解决思路:
2.1 文本预处理:
1. 由于文件的编码是GBK的,读取到Spark中全部是乱码,所以先使用Java把代码转为UTF8编码;
2. 由于文本存在多个文件中(大概2k多),使用Spark的wholeTextFile读取速度太慢,所以考虑把这些文件全部合并为一个文件,这时又结合1.的转变编码,所以在转变编码的时候就直接把所有的数据存入同一个文件中;
其存储的格式为: 每行: 文件名.txt\t文件内容
如: 41.txt 【 日 期 】199601....
这样子的话,就可以通过.txt\t 来对每行文本进行分割,得到其文件名以及文件内容,这里每行其实就是一个文件了。
2.2 分词
分词直接采用HanLP的分词来做,HanLP这里选择两种:Standard和NLP(还有一种就是HighSpeed,但是这个木有用户自定义词典,所以前期考虑先用两种),具体参考:https://github.com/hankcs/HanLP ;
2.3 词转换为词向量
在Kmeans算法中,一个样本需要使用数值类型,所以需要把文本转为数值向量形式,这里在Spark中有两种方式。其一,是使用TF-IDF;其二,使用Word2Vec。这里暂时使用了TF-IDF算法来进行,这个算法需要提供一个numFeatures,这个值越大其效果也越好,但是相应的计算时间也越长,后面也可以通过实验验证。
2.4 使用每个文档的词向量进行聚类建模
在进行聚类建模的时候,需要提供一个初始的聚类个数,这里面设置为10,因为我们的数据是有10个分组的。但是在实际的情况下,一般这个值是需要通过实验来验证得到的。
2.5 对聚类后的结果进行评估
这里面采用的思路是:
1. 得到聚类模型后,对原始数据进行分类,得到原始文件名和预测的分类id的二元组(fileName,predictId);
2. 针对(fileName,predictId),得到(fileNameFirstChar ,fileNameFirstChar.toInt - predictId)的值,这里需要注意的是fileNameFirstChar其实就是代表这个文件的原始所属类别了。
3. 这里有一个一般假设,就是使用kmeans模型预测得到的结果大多数是正确的,所以fileNameFirstChar.toInt-predictId得到的众数其实就是分类的正确的个数了(这里可能比较难以理解,后面会有个小李子来说明这个问题);
4. 得到每个实际类别的预测的正确率后就可以去平均预测率了。
5. 改变numFeatuers的值,看下是否numFeatures设置的比较大,其正确率也会比较大?
3、具体步骤:
3.1 开发环境--Maven
首先第一步,当然是开发环境了,因为用到了Spark和HanLP,所以需要在pom.xml中加入这两个依赖:
1. <!-- 中文分词框架 -->
2.<dependency>
3.<groupId>com.hankcs</groupId>
4.<artifactId>hanlp</artifactId>
5.<version>${hanlp.version}</version>
6.</dependency>
7.<!-- Spark dependencies -->
8.<dependency>
9.<groupId>org.apache.spark</groupId>
10.<artifactId>spark-core_2.10</artifactId>
11.<version>${spark.version}</version>
12.</dependency>
13.<dependency>
14.<groupId>org.apache.spark</groupId>
15.<artifactId>spark-mllib_2.10</artifactId>
16.<version>${spark.version}</version>
17.</dependency>
其版本为:
<hanlp.version>portable-1.3.4</hanlp.version>、 <spark.version>1.6.0-cdh5.7.3</spark.version>。
3.2 文件转为UTF-8编码及存储到一个文件
这部分内容可以直接参考:src/main/java/demo02_transform_encoding.TransformEncodingToOne 这里的实现,因为是Java基本的操作,这里就不加以分析了。
3.3 Scala调用HanLP进行中文分词
Scala调用HanLP进行分词和Java的是一样的,同时,因为这里有些词语格式不正常,所以把这些特殊的词语添加到自定义词典中,其示例如下:
1.import com.hankcs.hanlp.dictionary.CustomDictionary
2.import com.hankcs.hanlp.dictionary.stopword.CoreStopWordDictionary
3.import com.hankcs.hanlp.tokenizer.StandardTokenizer
4.import scala.collection.JavaConversions._
5./**
6.* Scala 分词测试
7.* Created by fansy on 2017/8/25.
8.*/
9.object SegmentDemo {
10.def main(args: Array[String]) {
11.val sentense = "41,【 日 期 】19960104 【 版 号 】1 【 标 题 】合巢芜高速公路巢芜段竣工 【 作 者 】彭建中 【 正 文 】 安徽合(肥)巢(湖)芜(湖)高速公路巢芜段日前竣工通车并投入营运。合巢芜 高速公路是国家规划的京福综合运输网的重要干线路段,是交通部确定1995年建成 的全国10条重点公路之一。该条高速公路正线长88公里。(彭建中)"
12.CustomDictionary.add("日 期")
13.CustomDictionary.add("版 号")
14.CustomDictionary.add("标 题")
15.CustomDictionary.add("作 者")
16.CustomDictionary.add("正 文")
17.val list = StandardTokenizer.segment(sentense)
18.CoreStopWordDictionary.apply(list)
19.println(list.map(x => x.word.replaceAll(" ","")).mkString(","))
20.}
21.}
运行完成后,即可得到分词的结果,如下:

考虑到使用方便,这里把分词封装成一个函数:
1./**
2.* String 分词
3.* @param sentense
4.* @return
5.*/
6.def transform(sentense:String):List[String] ={
7.val list = StandardTokenizer.segment(sentense)
8.CoreStopWordDictionary.apply(list)
9.list.map(x => x.word.replaceAll(" ","")).toList
10.}
11.}
输入即是一个中文的文本,输出就是分词的结果,同时去掉了一些常用的停用词。
3.4 求TF-IDF
在Spark里面求TF-IDF,可以直接调用Spark内置的算法模块即可,同时在Spark的该算法模块中还对求得的结果进行了维度变换(可以理解为特征选择或“降维”,当然这里的降维可能是提升维度)。代码如下:
1.val docs = sc.textFile(input_data).map{x => val t = x.split(".txt\t");(t(0),transform(t(1)))}
2..toDF("fileName", "sentence_words")
3.
4.// 3. 求TF
5.println("calculating TF ...")
6.val hashingTF = new HashingTF()
7..setInputCol("sentence_words").setOutputCol("rawFeatures").setNumFeatures(numFeatures)
8.val featurizedData = hashingTF.transform(docs)
9.
10.// 4. 求IDF
11.println("calculating IDF ...")
12.val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
13.val idfModel = idf.fit(featurizedData)
14.val rescaledData = idfModel.transform(featurizedData).cache()
变量docs是一个DataFrame[fileName, sentence_words] ,经过HashingTF后,变成了变量 featurizedData ,同样是一个DataFrame[fileName,sentence_words, rawFeatures]。这里通过setInputCol以及SetOutputCol可以设置输入以及输出列名(列名是针对DataFrame来说的,不知道的可以看下DataFrame的API)。
接着,经过IDF模型,得到变量 rescaledData ,其DataFrame[fileName,sentence_words, rawFeatures, features] 。
执行结果为:

3.5 建立KMeans模型
直接参考官网给定例子即可:
1.println("creating kmeans model ...")
2.val kmeans = new KMeans().setK(k).setSeed(1L)
3.val model = kmeans.fit(rescaledData)
4.// Evaluate clustering by computing Within Set Sum of Squared Errors.
5.println("calculating wssse ...")
6.val WSSSE = model.computeCost(rescaledData)
7.println(s"Within Set Sum of Squared Errors = $WSSSE")
这里有计算cost值的,但是这个值评估不是很准确,比如我numFeature设置为2000的话,那么这个值就很大,但是其实其正确率会比较大的。
3.6 模型评估
这里的模型评估直接使用一个小李子来说明:比如,现在有这样的数据:

其中,1开头,2开头和4开头的属于同一类文档,后面的0,3,2,1等,代表这个文档被模型分类的结果,那么可以很容易的看出针对1开头的文档,
其分类正确的有4个,其中("123.txt",3)以及(“126.txt”,1)是分类错误的结果,这是因为,在这个类别中预测的结果中0是最多的,所以0是和1开头的文档对应起来的,这也就是前面的假设。
1. 把同一类文档分到同一个partition中;
1.val data = sc.parallelize(t)
2.val file_index = data.map(_._1.charAt(0)).distinct.zipWithIndex().collect().toMap
3.println(file_index)
4.val partitionData = data.partitionBy(MyPartitioner(file_index))
这里的file_index,是对不同类的文档进行编号,这个编号就对应每个partition,看MyPartitioner的实现:
1.case class MyPartitioner(file_index:Map[Char,Long]) extends Partitioner
2.override def getPartition(key: Any): Int = key match {
3.case _ => file_index.getOrElse(key.toString.charAt(0),0L).toInt
4.}
5..override def numPartitions: Int = file_index.size
6.}
2. 针对每个partition进行整合操作:
在整合每个partition之前,我们先看下我们自定义的MyPartitioner是否在正常工作,可以打印下结果:
1.val tt = partitionData.mapPartitionsWithIndex((index: Int, it: Iterator[(String,Int)]) => it.toList.map(x => (index,x)).toIterator)
2.tt.collect().foreach(println(_))
运行如下:

其中第一列代表每个partition的id,第二列是数据,发现其数据确实是按照预期进行处理的;接着可以针对每个partition进行数据整合:
1.// firstCharInFileName , firstCharInFileName - predictType
2.val combined = partitionData.map(x =>( (x._1.charAt(0), Integer.parseInt(x._1.charAt(0)+"") - x._2),1) )
3..mapPartitions{f => var aMap = Map[(Char,Int),Int]();
4.for(t <- f){
5.if (aMap.contains(t._1)){
6.aMap = aMap.updated(t._1,aMap.getOrElse(t._1,0)+1)
7.}else{
8.aMap = aMap + t
9.}
10.}
11.val aList = aMap.toList
12.val total= aList.map(_._2).sum
13.val total_right = aList.map(_._2).max
14.List((aList.head._1._1,total,total_right)).toIterator
15.// aMap.toIterator //打印各个partition的总结
16. }
在整合之前先执行一个map操作,把数据变成((fileNameFirstChar, fileNameFirstChar.toInt - predictId), 1),其中fileNameFirstChar代表文件的第一个字符,其实也就是文件的所属实际类别,后面的fileNameFirstChar.toInt-predictId 其实就是判断预测的结果是否对了,这个值的众数就是预测对的;最后一个值代码前面的这个键值对出现的次数,其实就是统计属于某个类别的实际文件个数以及预测对的文件个数,分别对应上面的total和total_right变量;输出结果为:
(4,6,3)
(1,6,4)
(2,6,4)
发现其打印的结果是正确的,第一列代表文件名开头,第二个代表属于这个文件的个数,第三列代表预测正确的个数
这里需要注意的是,这里因为文本的实际类别和文件名是一致的,所以才可以这样处理,如果实际数据的话,那么mapPartitions函数需要更改。
3. 针对数据结果进行统计:
最后只需要进行简单的计算即可:
1.for(re <- result ){
2.println("文档"+re._1+"开头的 文档总数:"+ re._2+",分类正确的有:"+re._3+",分类正确率是:"+(re._3*100.0/re._2)+"%")
3.}
4.val averageRate = result.map(_._3).sum *100.0 / result.map(_._2).sum
5.println("平均正确率为:"+averageRate+"%")
输出结果为:

4. 实验
设置不同的numFeature,比如使用200和2000,其对比结果为:
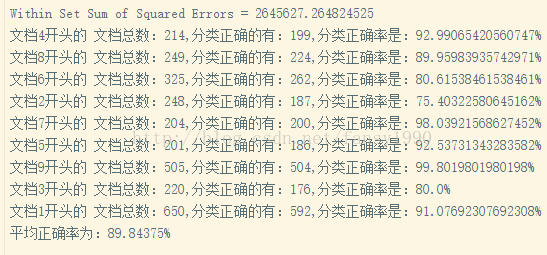

所以设置numFeatures值越大,其准确率也越高,不过计算也比较复杂。
5. 总结
1. HanLP的使用相对比较简单,这里只使用了分词及停用词,感谢开源;
2. Spark里面的TF-IDF以及Word2Vector使用比较简单,不过使用这个需要先分词;
3. 这里是在IDEA里面运行的,如果使用Spark-submit的提交方式,那么需要把hanpl的jar包加入,这个有待验证
文章来源于fansy1990的博客
Spark应用HanLP对中文语料进行文本挖掘--聚类详解教程的更多相关文章
- Spark Streaming揭秘 Day28 在集成开发环境中详解Spark Streaming的运行日志内幕
Spark Streaming揭秘 Day28 在集成开发环境中详解Spark Streaming的运行日志内幕 今天会逐行解析一下SparkStreaming运行的日志,运行的是WordCountO ...
- JSON创建键值对(key是中文或者数字)方式详解
JSON创建键值对(key是中文或者数字)方式详解 先准备好一个空的json对象 var obj = {}; 1. 最原始的方法 obj.name = 'zhangsan'; //这种方式很简单的添加 ...
- linux中文乱码问题及locale详解
一.修改系统默认语言及中文乱码问题记录系统默认使用语言的文件是/etc/sysconfig/i18n,如果默认安装的是中文的系统,i18n的内容如下: LANG="zh_CN.UTF-8&q ...
- 10.Spark Streaming源码分析:Receiver数据接收全过程详解
原创文章,转载请注明:转载自 听风居士博客(http://www.cnblogs.com/zhouyf/) 在上一篇中介绍了Receiver的整体架构和设计原理,本篇内容主要介绍Receiver在 ...
- Hanlp汉字转拼音使用python调用详解
1.hanlp简介 HanLP是一系列模型与算法组成的NLP工具包,由大快搜索主导并完全开源,目标是普及自然语言处理在生产环境中的应用.HanLP具备功能完善.性能高效.架构清晰.语料时新.可自定义的 ...
- jquery .post .get中文参数乱码解决方法详解
jquery默认的编码为utf-8,做项目时有时处于项目需要用到ajax提交中文参数,乱码问题就很头疼了,折腾了许久终于弄出来了.为了便于传输,我们首先将需要用到的参数用javascript自带的函数 ...
- SCWS中文分词,词典词性标注详解
SCWS中文分词词典条目多达26万条之巨,在整理的时候已经把很多明显不对的标注或词条清理了 ---- 附北大词性标注版本 ----Ag 形语素 形容词性语素.形容词代码为a,语素代码g前面置以A. a ...
- Spark Structured Streaming框架(3)之数据输出源详解
Spark Structured streaming API支持的输出源有:Console.Memory.File和Foreach.其中Console在前两篇博文中已有详述,而Memory使用非常简单 ...
- Spark Structured Streaming框架(2)之数据输入源详解
Spark Structured Streaming目前的2.1.0版本只支持输入源:File.kafka和socket. 1. Socket Socket方式是最简单的数据输入源,如Quick ex ...
随机推荐
- VB识别分隔符
strTypeEx = ReadIniFile("Type", "Type", App.Path & "\set.ini") str ...
- 微软Power BI 每月功能更新系列——5月Power BI 新功能学习
Power BI Desktop 5月份功能摘要 本月Power BI Desktop除了许多报表功能的更新,Power BI对条件格式进行了重大改进,可以对报表的任何字段(包括字符串和日期)进行条件 ...
- Spring 配置文件
<?xml version="1.0" encoding="UTF-8" ?> <beans> <bean id=...> ...
- php 怎样将有范围的ip转化为整型范围
php中将IP转换成整型的函数ip2long()容易出现问题,在IP比较大的情况下,会变成负数.如下: <?php $ip = "192.168.1.2"; $ip_n = ...
- 20165228 实验一 Java开发环境的熟悉
20165228 实验一 Java开发环境的熟悉 一.实验内容及步骤 (一)使用JDK编译.运行简单的Java程序 命令行下Java程序开发 1.用VrtualBox打开Linux虚拟机 2.使用Al ...
- Deinstall卸载RAC之Oracle软件及数据库+GI集群软件
Deinstall卸载Oracle软件及数据库+GI集群软件 1. 本篇文档应用场景: 需要安装新的ORACLE RAC产品,系统没有重装,需要对原环境中的RAC进行卸载: #本篇文档,在AIX 6. ...
- flask写入数据库
sqlalchemy是一个关系型数据库框架,它提供了高层的ORM 和底层的原生数据库的操作. sqlalchemy实际上是对数据库的抽象,通过python对象操作数据库,提高开发效率. 安装 flas ...
- SpringMVC整合Thymeleaf
Thymeleaf的介绍 进行JavaWeb开发时主要用到的是JSP,传统的JSP需要在页面中加入大量的JSTL标签,这些标签只能运行在服务器中,前端开发人员维护这些页面比较困难,页面加载速度也比较慢 ...
- JS字符串和正则总结
trim功能:去除字符串开始和结尾的空格. 中间空格不去掉~ 对输入字符串的处理,多输要先清除开头结尾空格,再处理 IE8不支持trim()方法. String总结:所有API都无法修改原字符串,都会 ...
- 【vue】vue使用Element组件时v-for循环里的表单项验证方法
转载至:https://www.jb51.net/article/142750.htm标题描述看起来有些复杂,有vue,Element,又有表单验证,还有v-for循环?是不是有点乱?不过我相信开发中 ...