Scala集合类型详解
Scala集合
Scala提供了一套很好的集合实现,提供了一些集合类型的抽象。
Scala 集合分为可变的和不可变的集合。
可变集合可以在适当的地方被更新或扩展。这意味着你可以修改,添加,移除一个集合的元素。而不可变集合类永远不会改变。不过,你仍然可以模拟添加,移除或更新操作。但是这些操作将在每一种情况下都返回一个新的集合,同时使原来的集合不发生改变。
集合中基本结构:
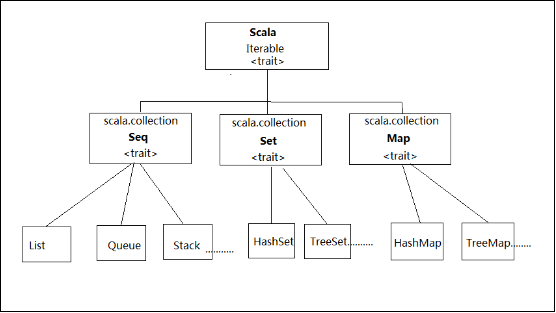
几种常用集合类型示例:
- // 定义整型 List
- val x = List(1, 2, 3, 4)
- // 定义 Set
- var x = Set(1, 3, 5, 7)
- // 定义 Map
- val x = Map("one" -> 1, "two" -> 2, "three" -> 3)
- // 创建两个不同类型元素的元组
- val x = (10, "Runoob")
- // 定义 Option
- val x: Option[Int] = Some(5)
Scala List(列表)
Scala 列表类似于数组,它们所有元素的类型都相同,但是它们也有所不同:列表是不可变的,值一旦被定义了就不能改变,其次列表 具有递归的结构(也就是链接表结构)而数组不是。
列表的元素类型 T 可以写成 List[T]。例如,以下列出了多种类型的列表:
- // 字符串列表
- val site: List[String] = List("Sina", "Google", "Baidu")
- // 整型列表
- val nums: List[Int] = List(1, 2, 3, 4)
- // 空列表
- val empty: List[Nothing] = List()
- // 二维列表
- val dim: List[List[Int]] =
- List(
- List(1, 0, 0),
- List(0, 1, 0),
- List(0, 0, 1)
- )
构造列表的两个基本单位是 Nil 和 ::
Nil 也可以表示为一个空列表。
以上实例我们可以写成如下所示:(::)符号连接顺序是从右到左
- // 字符串列表
- val site = "Sina" :: ("Google" :: ("Baidu" :: Nil))
- // 整型列表
- val nums = 1 :: (2 :: (3 :: (4 :: Nil)))
- // 空列表
- val empty = Nil
- // 二维列表
- val dim = (1 :: (0 :: (0 :: Nil))) ::
- (0 :: (1 :: (0 :: Nil))) ::
- (0 :: (0 :: (1 :: Nil))) :: Nil
基本操作
Scala列表有三个基本操作:
- head 返回列表第一个元素
- tail 返回一个列表,包含除了第一元素之外的其他元素:(是一个列表或者Nil)
- isEmpty 在列表为空时返回true
对于Scala列表的任何操作都可以使用这三个基本操作来表达。代码示例如下:
- val site = "Sina" :: ("Google" :: ("Baidu" :: Nil))
- val nums = Nil
- //打印测试head、tail、isEmpty功能
- println(site.head)
- println(site.tail)
- println(site.isEmpty)
- println(nums.isEmpty)
打印结果为:
- Sina
- List(Google, Baidu)
- false
- true
连接列表
你可以使用 ::: 、 List.:::() 或 List.concat() 方法来连接两个或多个列表。
代码示例如下:
- val site1 = "Sina" :: ("Google" :: ("Baidu" :: Nil))
- val site2 = "Facebook" :: ("Taobao" :: Nil)
- // 使用 ::: 运算符
- var combine = site1 ::: site2
- println( "site1 ::: site2 : " + combine )
- // 使用 list.:::() 方法,注意:结果为site2列表元素在前,site1在后
- combine = site1.:::(site2)
- println( "site1.:::(site2) : " + combine )
- // 使用 concat 方法
- combine = List.concat(site1, site2)
- println( "List.concat(site1, site2) : " + combine )
- }
打印结果:
- site1 ::: site2 : List(Sina, Google, Baidu, Facebook, Taobao)
- site1.:::(site2) : List(Facebook, Taobao, Sina, Google, Baidu)
- List.concat(site1, site2) : List(Sina, Google, Baidu, Facebook, Taobao)
List.fill()
我们可以使用 List.fill() 方法来创建一个指定重复数量的元素列表:
- val site = List.fill(3)("Baidu") // 重复 Runoob 3次
- println( "site : " + site )
- val num = List.fill(10)(2) // 重复元素 2, 10 次
- println( "num : " + num )
打印结果为:
- site : List(Baidu, Baidu, Baidu)
- num : List(2, 2, 2, 2, 2, 2, 2, 2, 2, 2)
List.tabulate()
List.tabulate() 方法是通过给定的函数来创建列表。
方法的第一个参数为元素的数量,可以是二维的,第二个参数为指定的函数,我们通过指定的函数计算结果并返回值插入到列表中,起始值为 0,实例如下:
- // 通过给定的函数创建 5 个元素
- val squares = List.tabulate(6)(n => n * n)
- println( "一维 : " + squares )
- // 创建二维列表
- val mul = List.tabulate( 4,5 )( _ * _ )
- println( "二维 : " + mul )
打印结果为:
- 一维 : List(0, 1, 4, 9, 16, 25)
- 二维 : List(List(0, 0, 0, 0, 0), List(0, 1, 2, 3, 4), List(0, 2, 4, 6, 8), List(0, 3, 6, 9, 12))
List.reverse
List.reverse 用于将列表的顺序反转,实例如下:
- val site = "Sina" :: ("Google" :: ("Baidu" :: Nil))
- println( "反转前 : " + site )
- println( "反转前 : " + site.reverse )
打印结果为:
- 反转前 : List(Sina, Google, Baidu)
- 反转前 : List(Baidu, Google, Sina)
列表缓存(ListBuffer)
List类能够提供对列表头部,而非尾部的快速访问。如果需要向结尾添加对象,则需要先对表头前缀元素方式反向构造列表,完成之后再调用reverse。
上述问题另一种解决方式就是使用ListBuffer,这可以避免reverse操作。ListBuffer是可变对象,它可以更高效的通过添加元素来构建列表。
使用ListBuffer替代List另一个理由是避免栈溢出风险。
ListBuffer使用示例:
- val buf: ListBuffer[Int] = new ListBuffer[Int]
- //往后添加
- buf += 1
- buf += 2
- //前缀添加
- val buf2 = 3 +: buf
- println(buf2.toString())
- //ListBuffer转List
- println(buf2.toList.toString())
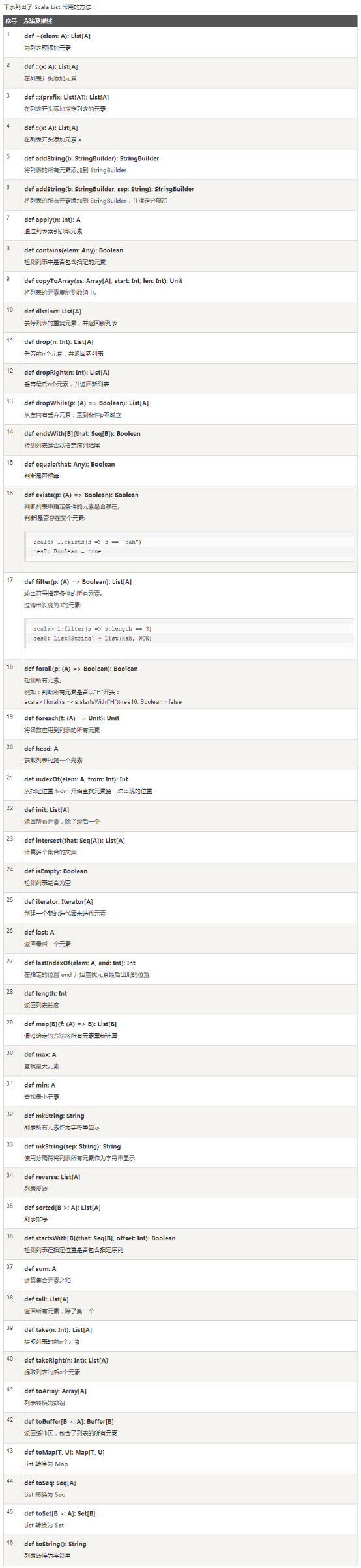
List常用方法
- 参考底部附录:
Scala队列和栈
队列
如果你需要先进先出序列,你可以使用Queue(队列)。Scala集合提供了可变和不可变的Queue。
不可变Queue代码示例:
- //使用伴生对象创建一个queue
- val que = Queue[Int]()
- //使用enqueue为不可变队列添加元素
- val que1 = que.enqueue(1)
- //往队列添加多个元素,把集合作为enqueue的参数
- val que2 = que1.enqueue(List(2,3,4,5))
- //从队列头部移除元素,使用dequeue
- //第一个参数为头部移除的元素,第二个参数为剩下的队列
- val (elem1,que3) = que2.dequeue
- //打印移除的元素
- println(elem1)
- //打印剩下的队列
- println(que3)
打印结果为:
- 1
- Queue(2, 3, 4, 5)
可变Queue代码示例:
- //使用伴生对象创建一个可变queue
- var que = scala.collection.mutable.Queue[String]()
- //使用 += 符号添加单个元素
- que += "A"
- //使用 ++= 符号添加多个元素
- que ++= List("B","C","D")
- //使用dequeue移除头部元素
- val a = que.dequeue
- //打印移除的元素
- println(a)
- //打印队列中剩下的元素
- print(que)
打印结果:
- A
- Queue(B, C, D)
栈
如果需要的是后进先出,你可以使用Stack,它同样在Scala的集合中有可变和不可变版本。元素的推入使用push,弹出用pop,只获取栈顶元素而不移除可以使用top。
可变栈示例:
- //使用Stack类的伴生对象创建Stack对象
- var stack = scala.collection.mutable.Stack[Int]()
- //往栈stack中压如元素
- stack.push(1)
- stack.push(2)
- stack.push(3)
- //打印查看栈内元素
- println(stack)
- //获取栈顶元素的值
- val tval = stack.top
- println("栈顶元素为 : " + tval)
- //移除栈顶元素
- val pval = stack.pop()
- println("移除的栈顶元素为 : " + pval)
- //打印移除栈顶元素后,剩下的栈内元素
- println(stack)
打印结果:
- Stack(3, 2, 1)
- 栈顶元素为 : 3
- 移除的栈顶元素为 : 3
- Stack(2, 1)
队列和栈常用操作
- 参考底部附录:
Scala Set(集)
- Scala Set(集)是没有重复的对象集合,所有的元素都是唯一的。
- Scala 集合分为可变的和不可变的集合。
- 默认情况下,Scala 使用的是不可变集合,如果想使用可变集合,需引用 scala.collection.mutable.Set 包。
- 默认引用 scala.collection.immutable.Set。
不可变集合实例如下:
- val set = Set(1,2,3)
- println(set.getClass.getName) //
- println(set.exists(_ % 2 == 0)) //true
- println(set.drop(1)) //Set(2,3)
打印结果为:
- scala.collection.immutable.Set$Set3
- true
- Set(2, 3)
如果需要使用可变集合需要引入 scala.collection.mutable.Set:
- import scala.collection.mutable.Set // 可以在任何地方引入 可变集合
- val mutableSet = Set(1,2,3)
- println(mutableSet.getClass.getName) // scala.collection.mutable.HashSet
- //往集合内添加元素4
- mutableSet.add(4)
- //删除值为1的元素
- mutableSet.remove(1)
- //添加元素5
- mutableSet += 5
- //删除值为3的元素
- mutableSet -= 3
- println(mutableSet) // Set(5, 3, 4)
- val another = mutableSet.toSet
- println(another.getClass.getName) // scala.collection.immutable.Set
注意: 虽然可变Set和不可变Set都有添加或删除元素的操作,但是有一个非常大的差别。对不可变Set进行操作,会产生一个新的set,原来的set并没有改变,这与List一样。 而对可变Set进行操作,改变的是该Set本身,与ListBuffer类似。
Set集合基本操作
Scala Set集合有三个基本操作:
- head 返回集合第一个元素
- tail 返回一个集合,包含除了第一元素之外的其他元素
- isEmpty 在集合为空时返回true
对于Scala集合的任何操作都可以使用这三个基本操作来表达。
代码示例如下:
- val site = Set("Sina", "Google", "Baidu")
- val nums: Set[Int] = Set()
- println( "head : " + site.head )
- println( "tail : " + site.tail )
- println( "isEmpty : " + site.isEmpty )
- println( "isEmpty : " + nums.isEmpty )
打印结果为:
- head : Sina
- tail : Set(Google, Baidu)
- isEmpty : false
- isEmpty : true
连接集合
你可以使用 ++ 运算符或 Set.++() 方法来连接两个集合。如果元素有重复的就会移除重复的元素。实例如下:
- val site1 = Set("Sina", "Google", "Baidu")
- val site2 = Set("Faceboook", "Taobao")
- // ++ 作为运算符使用
- var site = site1 ++ site2
- println( "site1 ++ site2 : " + site )
- // ++ 作为方法使用
- site = site1.++(site2)
- println( "site1.++(site2) : " + site )
打印结果为:
- site1 ++ site2 : Set(Faceboook, Taobao, Sina, Google, Baidu)
- site1.++(site2) : Set(Faceboook, Taobao, Sina, Google, Baidu)
查找集合中最大与最小元素
你可以使用 Set.min 方法来查找集合中的最小元素,使用 Set.max 方法查找集合中的最大元素。实例如下:
- val num = Set(5,6,9,20,30,45)
- // 查找集合中最大与最小元素
- println( "Set(5,6,9,20,30,45) 最小元素是 : " + num.min )
- println( "Set(5,6,9,20,30,45) 最大元素是 : " + num.max )
打印结果为:
- Set(5,6,9,20,30,45) 最小元素是 : 5
- Set(5,6,9,20,30,45) 最大元素是 : 45
交集
你可以使用 Set.& 方法或 Set.intersect 方法来查看两个集合的交集元素。实例如下:
- val num1 = Set(5,6,9,20,30,45)
- val num2 = Set(50,60,9,20,35,55)
- // 交集
- println( "num1.&(num2) : " + num1.&(num2) )
- println( "num1.intersect(num2) : " + num1.intersect(num2) )
打印结果为:
- num1.&(num2) : Set(20, 9)
- num1.intersect(num2) : Set(20, 9)
Scala Set 常用方法
- 参考底部附录:
Scala Map(映射)
- Map(映射)是一种可迭代的键值对(key/value)结构。
- 所有的值都可以通过键来获取。
- Map 中的键都是唯一的。
- Map 也叫哈希表(Hash tables)。
- Map 有两种类型,可变与不可变,区别在于可变对象可以修改它,而不可变对象不可以。
- 默认情况下 Scala 使用不可变 Map。如果你需要使用可变集合,你需要显式的引入 import scala.collection.mutable.Map 类
- 在 Scala 中 你可以同时使用可变与不可变 Map,不可变的直接使用 Map,可变的使用 mutable.Map。
以下实例演示了不可变 Map 的应用:
- // 空哈希表,键为字符串,值为整型
- var A:Map[Char,Int] = Map()
- // Map 键值对演示
- val lang= Map("Java" -> "Oracle", "C#" -> "Microsoft")
- 或者
- val lang= Map(("Java","Oracle"), ("C#" , "Microsoft"))
定义 Map 时,需要为键值对定义类型。如果需要添加 key-value 对,可以使用 + 号,如下所示:
A += ('t' ->10 )
Map 基本操作
Scala Map 几种基本操作:keys、values、isEmpty、赋值(可变映射)
代码示例:
Keys:
- val lang = Map("Java" -> "Oracle",
- "C#" -> "Microsoft",
- "Swift" -> "Apple")
- Values:
- val nums: Map[Int, Int] = Map()
- println( "lang 中的键为 : " + lang.keys )
- println( "lang 中的值为 : " + lang.values )
isEmpty:
- println( "lang 是否为空 : " + lang.isEmpty )
- println( "nums 是否为空 : " + nums.isEmpty )
keys和isEmpty的打印结果为:
- lang 中的键为 : Set(Java, C#, Swift)
- lang 中的值为 : MapLike(Oracle, Microsoft, Apple)
- lang 是否为空 : false
- nums 是否为空 : true
赋值:
- var lang= scala.collection.mutable.Map("Java" -> "Oracle", "C#" -> "Microsoft")
- lang("Java") = "sun"
- println(lang)
打印结果为:
Map(C# -> Microsoft, Java -> sun)
Map 合并
你可以使用 ++ 运算符或 Map.++() 方法来连接两个 Map,Map 合并时会移除重复的 key。以下演示了两个 Map 合并的实例:
- val lang =Map("Java" -> "Oracle",
- "C#" -> "Microsoft",
- "Swift" -> "Apple")
- val color = Map("blue" -> "#0033FF",
- "yellow" -> "#FFFF00",
- "red" -> "#FF0000")
- // ++ 作为运算符
- var colors = lang ++ color
- println( "lang ++ colors : " + colors )
- // ++ 作为方法
- colors = lang.++(colors)
- println( "lang.++(colors)) : " + colors )
打印结果为:
- lang ++ colors : Map(blue -> #0033FF, C# -> Microsoft, yellow -> #FFFF00, Java -> Oracle, red -> #FF0000, Swift -> Apple)
- lang.++(colors)) : Map(blue -> #0033FF, C# -> Microsoft, yellow -> #FFFF00, Java -> Oracle, red -> #FF0000, Swift -> Apple)
输出 Map 的 keys 和 values
以下通过 foreach 循环输出 Map 中的 keys 和 values:
- val lang =Map("Java" -> "Oracle",
- "C#" -> "Microsoft",
- "Swift" -> "Apple")
- lang.keys.foreach{ i =>
- print( "Key = " + i )
- println("\tValue = " + lang(i) )}
打印结果为:
- Key = JavaValue = Oracle
- Key = C#Value = Microsoft
- Key = SwiftValue = Apple
查看 Map 中是否存在指定的 Key
你可以使用 Map.contains 方法来查看 Map 中是否存在指定的 Key。实例如下:
- val lang =Map("Java" -> "Oracle",
- "C#" -> "Microsoft",
- "Swift" -> "Apple")
- if(lang.contains("Swift")) {
- println(lang("Swift")+"创造了 Swift 语言")
- }
打印结果为:
Apple创造了 Swift 语言
迭代映射
- val lang = Map("Java" -> "Oracle", "C#" -> "Microsoft")
- for ((k, v) <- lang) {
- println(k + " : " + v)
- }
打印结果为:
- Java : Oracle
- C# : Microsoft
映射中K,V反转
- val lang = Map("Java" -> "Oracle", "C#" -> "Microsoft")
- val lang2 = for ((k, v) <- lang) yield (v, k)
- for ((k, v) <- lang2) {
- println(k + " : " + v)
- }
打印结果为:
- Oracle : Java
- Microsoft : C#
已排序映射
- //按照key的字典顺序排序。
- val scores = scala.collection.immutable.SortedMap(("Bob", 8), ("Alice", 21), ("Fred", 17), ("Cindy", 15))
- scores.foreach(person => println(person._1 + " : " + person._2))
打印结果为:
- Alice : 21
- Bob : 8
- Cindy : 15
- Fred : 17
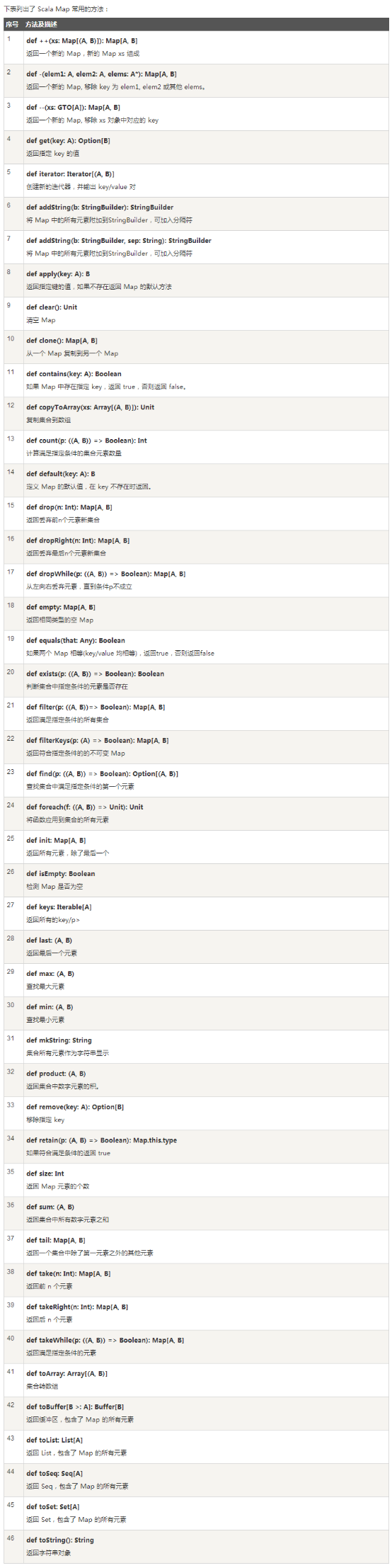
Scala Map常用方法
- 参考底部附录:
Scala Tuple(元组)
与列表一样,元组也是不可变的,但与列表不同的是元组可以包含不同类型的元素。
元组的值是通过将单个的值包含在圆括号中构成的。例如:
- //元组中定义了三个元素,对应的类型分别为[Int, Double, java.lang.String]。
- val tuple1 = (1, 5.20, "Spark")
- //或者
- val tuple2 = new Tuple3(1,5.20,"Spark")
我们可以使用 tuple1._1 访问第一个元素, tuple1._2 访问第二个元素,如下所示:
- //元组中定义了三个元素,对应的类型分别为[Int, Double, java.lang.String]。
- val tuple1 = (1, 5.20, "Spark")
- println(tuple1._1 + " : " + tuple1._2 + " : " + tuple1._3)
打印结果为:
1 : 5.2 : Spark
迭代元组
你可以使用 Tuple.productIterator() 方法来迭代输出元组的所有元素:
- //元组中定义了三个元素,对应的类型分别为[Int, Double, java.lang.String]。
- val tuple1 = (1, 5.20, "Spark")
- tuple1.productIterator.foreach{i => println("value : " + i)}
打印结果为:
- value : 1
- value : 5.2
- value : Spark
元组转为字符串
你可以使用 Tuple.toString() 方法将元组的所有元素组合成一个字符串,实例如下:
- //元组中定义了三个元素,对应的类型分别为[Int, Double, java.lang.String]。
- val tuple1 = (1, 5.20, "Spark")
- println(tuple1.toString())
打印结果为:
(1,5.2,Spark)
元素交换
你可以使用 Tuple.swap 方法来交换元组的元素。如下实例:
- //元组中定义了两个元素,对应的类型分别为[Int, java.lang.String]。
- val tuple1 = (1, "Spark")
- //注意:swap函数只能用于两个元素元组
- println(tuple1.swap)
打印结果为:
(Spark,1)
使用模式匹配获取元组
代码示例:
- val t = (1, 3.14, "Fred")
- val (first, second, third) = t
- println(first + " : " + second + " : " + third)
打印结果:
1 : 3.14 : Fred
拉链操作
- val num = Array(1, 2, 3)
- val str = Array("first", "second", "third")
- val com = num.zip(str).toMap
- println(com(1)+" : "+com(2)+" : "+com(3))
打印结果为:
first : second : third
元组常用方法
- 参考底部附录:
Scala Option(选项)
Scala Option(选项)类型用来表示一个值是可选的(有值或无值)。
Option[T] 是一个类型为 T 的可选值的容器: 如果值存在, Option[T] 就是一个 Some[T] ,如果不存在, Option[T] 就是对象 None 。
代码示例:
- val myMap: Map[String, String] = Map("key1" -> "value")
- val value1: Option[String] = myMap.get("key1")
- val value2: Option[String] = myMap.get("key2")
- println(value1) // Some("value1")
- println(value2) // None
打印结果为:
- Some(value)
- None
Option 有两个子类别,一个是 Some,一个是 None,当他回传 Some 的时候,代表这个函式成功地给了你一个 String,而你可以透过 get() 这个函式拿到那个 String,如果他返回的是 None,则代表没有字符串可以给你。
通过模式匹配来输出匹配值。
代码示例:
- val lang =Map("Java" -> "Oracle",
- "C#" -> "Microsoft",
- "Swift" -> "Apple")
- println(show(lang.get("Swift")))
- println(show(lang.get("Scala")))
- def show(x:Option[String]) = x match {
- case Some(s) => s
- case None => "?"
- }
打印结果为:
- Apple
- ?
getOrElse() 方法
你可以使用 getOrElse() 方法来获取元组中存在的元素或者使用其默认的值,实例如下:
- val a:Option[Int] = Some(5)
- val b:Option[Int] = Some(7)
- val c:Option[Int] = None
- println("a.getOrElse(0): " + a.getOrElse(0) )
- println("b.getOrElse(1): " + b.getOrElse(1) )
- println("c.getOrElse(10): " + c.getOrElse(10))
打印结果为:
- a.getOrElse(0): 5
- b.getOrElse(1): 7
- c.getOrElse(10): 10
isEmpty() 方法
你可以使用 isEmpty() 方法来检测元组中的元素是否为 None,实例如下:
- val a:Option[Int] = Some(5)
- val b:Option[Int] = None
- println("a.isEmpty: " + a.isEmpty )
- println("b.isEmpty: " + b.isEmpty )
打印结果为:
- a.isEmpty: false
- b.isEmpty: true
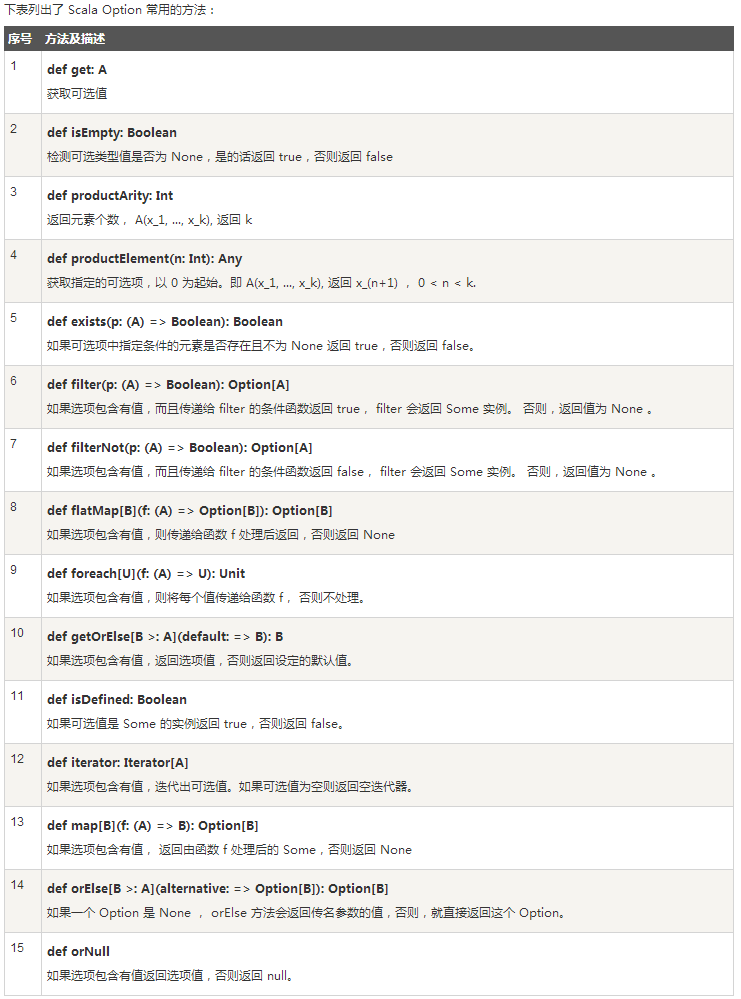
Scala Option 常用方法
- 参考底部附录:
Scala Iterator(迭代器)
- Scala Iterator(迭代器)不是一个集合,它是一种用于访问集合的方法。
- 迭代器 it 的两个基本操作是 next 和 hasNext。
- 调用 it.next() 会返回迭代器的下一个元素,并且更新迭代器的状态。
- 调用 it.hasNext() 用于检测集合中是否还有元素。
让迭代器 it 逐个返回所有元素最简单的方法是使用 while 循环:
- val it = Iterator("Baidu", "Google", "Tencent", "Taobao")
- while (it.hasNext){
- println(it.next())
- }
打印结果为:
- Baidu
- Google
- Tencent
- Taobao
查找最大与最小元素
你可以使用 it.min 和 it.max 方法从迭代器中查找最大与最小元素,实例如下:
- val ita = Iterator(20, 40, 2, 50, 69, 90)
- val itb = Iterator(20, 40, 2, 50, 69, 90)
- println("最大元素是:" + ita.max)
- println("最小元素是:" + itb.min)
执行结果为:
- 最大元素是:90
- 最小元素是:2
获取迭代器的长度
你可以使用 it.size 或 it.length 方法来查看迭代器中的元素个数。实例如下:
- val ita = Iterator(20, 40, 2, 50, 69, 90)
- val itb = Iterator(20, 40, 2, 50, 69, 90)
- println("ita.size : " + ita.size)
- println("itb.length : " + itb.length)
打印结果为:
- ita.size : 6
- itb.length : 6
Scala Iterator 常用方法
- 参考底部附录:
附录:
List常用方法
队列和栈常用操作
Scala Set 常用方法

Scala Map常用方法
元组常用方法
Scala Option 常用方法
Scala Iterator 常用方法

Scala集合类型详解的更多相关文章
- JAVA集合类型详解
一.前言 作为java面试的常客[集合类型]是永恒的话题:在开发中,主要了解具体的使用,没有太多的去关注具体的理论说明,掌握那几种常用的集合类型貌似也就够使用了:导致这一些集合类型的理论有可能经常的忘 ...
- C#进阶系列——WebApi 接口返回值不困惑:返回值类型详解
前言:已经有一个月没写点什么了,感觉心里空落落的.今天再来篇干货,想要学习Webapi的园友们速速动起来,跟着博主一起来学习吧.之前分享过一篇 C#进阶系列——WebApi接口传参不再困惑:传参详解 ...
- Java集合中List,Set以及Map等集合体系详解
转载请注明出处:Java集合中List,Set以及Map等集合体系详解(史上最全) 概述: List , Set, Map都是接口,前两个继承至collection接口,Map为独立接口 Set下有H ...
- (转)C# WebApi 接口返回值不困惑:返回值类型详解
原文地址:http://www.cnblogs.com/landeanfen/p/5501487.html 正文 前言:已经有一个月没写点什么了,感觉心里空落落的.今天再来篇干货,想要学习Webapi ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- (转)MySQL字段类型详解
MySQL字段类型详解 原文:http://www.cnblogs.com/100thMountain/p/4692842.html MySQL支持大量的列类型,它可以被分为3类:数字类型.日期和时间 ...
- [转]C#进阶系列——WebApi 接口返回值不困惑:返回值类型详解
本文转自:http://www.cnblogs.com/landeanfen/p/5501487.html 阅读目录 一.void无返回值 二.IHttpActionResult 1.Json(T c ...
- Mybatis----resultMap类型详解
Mybatis----resultMap类型详解 这篇文章主要给大家介绍了关于Mybatis中强大的resultMap功能的相关资料,文中通过示例代码介绍的非常详细,对大家学习或者使用Mybatis具 ...
- MySQL中tinytext、text、mediumtext和longtext等各个类型详解
转: MySQL中tinytext.text.mediumtext和longtext等各个类型详解 2018年06月13日 08:55:24 youcijibi 阅读数 26900更多 个人分类: 每 ...
随机推荐
- Windows 10下使用WMware 12 安装Ubuntu16.04,安装过程(附全过程图)
序言:菜鸡的我又开始瞎搞Ubuntu了 首先在网下下载VMware 12 正常安装即可 关于产品密匙问题:5A02H-AU243-TZJ49-GTC7K-3C61N (这是我在网上找的密匙,反正自己是 ...
- 构建工具(build tool)简述
一.什么是构建工具 构建工具是一个把源代码生成可执行应用程序的过程自动化的程序(例如Android app生成apk).构建包括编译.连接跟把代码打包成可用的或可执行的形式. 基本上构建的自动化是编写 ...
- 【vue】遇到的问题
[一]项目编译的时候报错 npm install npm WARN @mtfe/thrift@2.3.7 requires a peer of thrift@0.11.0 but none is in ...
- BZOJ3730 震波 和 BZOJ4372 烁烁的游戏
"震波"题意 F.A.Qs Home Discuss ProblemSet Status Ranklist Contest 入门OJ ModifyUser autoint Log ...
- webpack中hash、chunkhash、contenthash区别
webpack中对于输出文件名可以有三种hash值: 1. hash 2. chunkhash 3. contenthash 这三者有什么区别呢? hash 如果都使用hash的话,因为这是工程级别的 ...
- WCF- 契约Contract(ServiceContract、OperationContract、DataContract、ServiceKnownType和DataMember)(转)
示例 1.服务 IPersonManager.cs using System; using System.Collections.Generic; using System.Linq; using S ...
- centos7 添加第三方源
第三方源下载地址: http://repoforge.org/use/ 选择合适自己包 我选择的是EL7的 wget 下载这个包 接着使用rpm -ivh 包名 确认是否添加成功 ls /etc/yu ...
- linux后台运行之&和nohup区别,模拟后台守护进程
先来看一下&的使用 root@BP:~# cat test.sh #!/bin/bash while true do echo "linux">/dev/null d ...
- JDBC事务的处理-----模拟银行转账业务
定义: 数据库事务(简称:事务)是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成. 概要: 一个数据库事务通常包含了一个序列的对数据库的读/写操作.它的存在包含有以下两个目的: ...
- tailor multi fragment && cutom-amd script demo 说明
tailor 官方demo 中提供了一个multi fragment 的demo,这个比较简单,就是使用不同的 后端server 做为fragment ,然后使用 html tag 进行加载就可以了. ...