day12Flume、azkaban、sqoop
1.PS:Hive中好少有update这个方法,因为他主要是用来批量数据的处理分析。
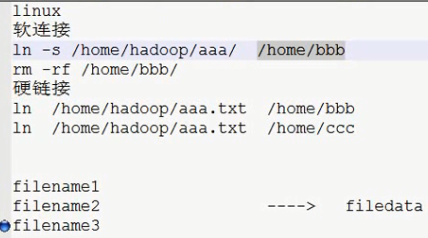
2.PS:软连接和硬连接的区别
软连接就是我们普通和Windows系统一样的快捷方式,她也是一个文件
硬连接就是他是一个inode,对文件会有引用,删除这个快捷方式不会删除文件。
3.pig其实和hive一样,只不过hive有自己的语法,pig还要专门学习他的东西,通用性不太强。
--------------------------------------------------------------------------------------------------------
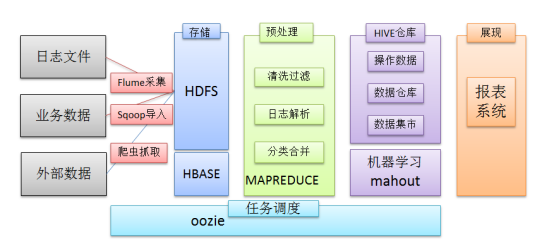
PS:这是过几天要写的一个项目:
首先对日志文件进行收集,使用flume,第二部进行数据清理;传入hive库;进入mysql,最好进行数据展示

---------------------------------------------------------------------------------------------------

1.1.2 运行机制
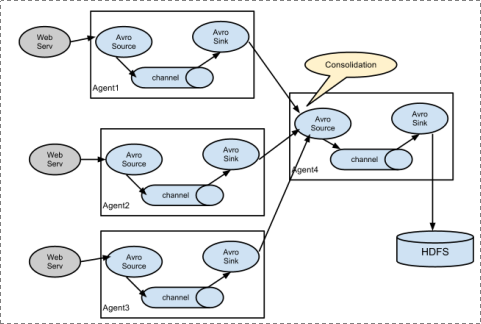
1、 Flume分布式系统中最核心的角色是agent,flume采集系统就是由一个个agent所连接起来形成
2、 每一个agent相当于一个数据传递员,内部有三个组件:
a) Source:采集源,用于跟数据源对接,以获取数据
b) Sink:下沉地,采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据
c) Channel:angent内部的数据传输通道,用于从source将数据传递到sink
PS:一个agent就是一个进程
1. 简单结构 :单个agent采集数据

2. 复杂结构:多级agent之间串联
-----------------------------------
1.2.1 Flume的安装部署
1、Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境
上传安装包到数据源所在节点上
然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz
然后进入flume的目录,修改conf下的flume-env.sh,在里面配置JAVA_HOME
2、根据数据采集的需求配置采集方案,描述在配置文件中(文件名可任意自定义)
3、指定采集方案配置文件,在相应的节点上启动flume agent
---------Step-演示将采集到数据显示到控制台上
1.解压文件到apps中
2.到conf文件下,创建配置测试文件,不同的文件不一样
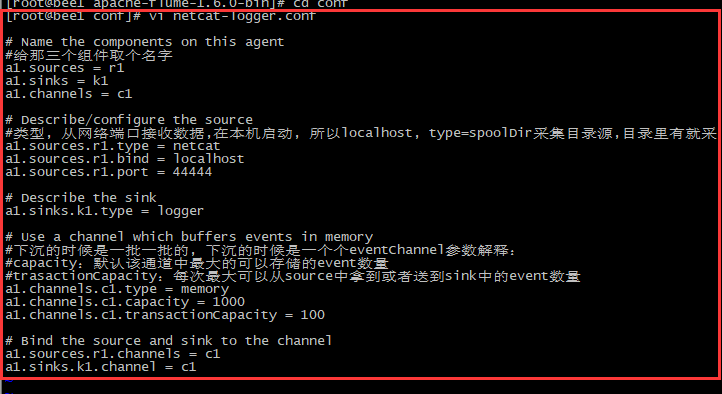
2 、 启动agent去采集数据
|
bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console |
-c conf 指定flume自身的配置文件所在目录
-f conf/netcat-logger.con 指定我们所描述的采集方案
-n a1 指定我们这个agent的名字

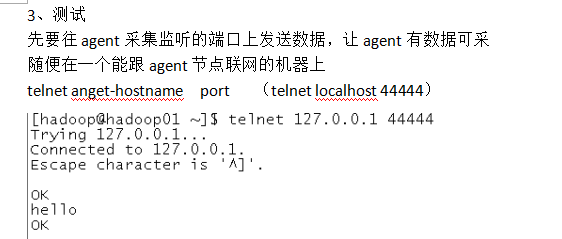

TelNet就行输入,测试;这里数据和显示不在一起,现实生活中不会是这样的

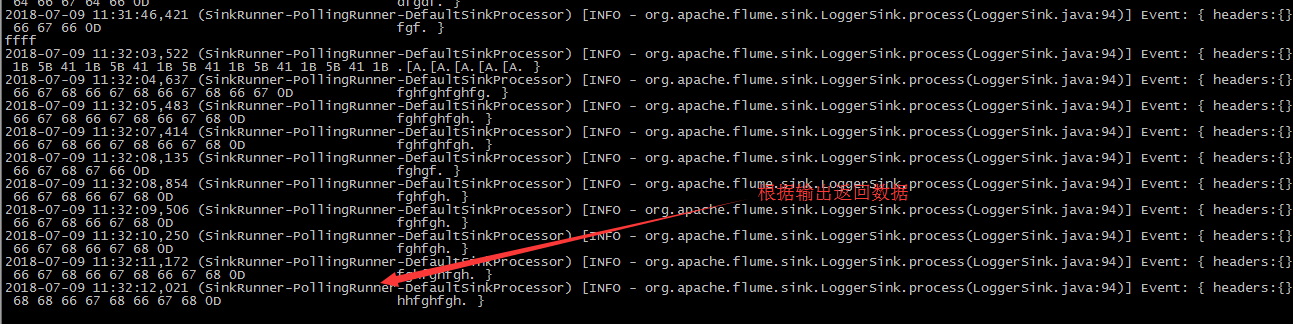
-------------------------监视文件夹方法
1.先创建一个文件夹

2.在conf中创建文件
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # Describe/configure the source
#监听目录,spoolDir指定目录, fileHeader要不要给文件夹前坠名
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/hadoop/flumespool
a1.sources.r1.fileHeader = true # Describe the sink
a1.sinks.k1.type = logger # Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3.监视文件夹
启动命令:
bin/flume-ng agent -c ./conf -f ./conf/spool-logger.conf -n a1 -Dflume.root.logger=INFO,console
---------------------------------------------------------------
测试:
1.往/home/hadoop/flumeSpool放文件(mv ././xxxFile /home/hadoop/flumeSpool),但是不要在里面生成文件

2. 移入文件以后,根据移入的文件 响应的文件中的内容


PS:将数据移入后会自动变为completed,会监视文件夹的数据。最好是将生成的数据放入文件夹,文件夹的名字不能重名
------------------------------------------多级Agent串联

PS:具体的操作我没有去实现,主要就是
1.将bee1的flume配置发给bee2,分别配置 相印的配置文件,
2.不停的在配置文件中指定的位置打印 数据
3.然后在bee2中出结果
工作流调度器azkaban----------------他是一种服务

2.1.3 常见工作流调度系统
市面上目前有许多工作流调度器
在hadoop领域,常见的工作流调度器有Oozie, Azkaban,Cascading,Hamake等

-----------------------------------------------Azkaban 配置步骤
1.创建一个azkaban的文件夹,解压文件


2.azkaban脚本导入
将解压后的mysql 脚本,导入到mysql中:
进入mysql
mysql> create database azkaban;
mysql> use azkaban;
Database changed
mysql> source /home/hadoop/azkaban-2.5.0/create-all-sql-2.5.0.sql;

3.创建SSL配置(因为传输协议使用的是https,所以需要这一步操作)
参考地址: http://docs.codehaus.org/display/JETTY/How+to+configure+SSL
命令: keytool -keystore keystore -alias jetty -genkey -keyalg RSA
运行此命令后,会提示输入当前生成 keystor的密码及相应信息,输入的密码请劳记,信息如下:
输入keystore密码:
再次输入新密码:
您的名字与姓氏是什么?
[Unknown]:
您的组织单位名称是什么?
[Unknown]:
您的组织名称是什么?
[Unknown]:
您所在的城市或区域名称是什么?
[Unknown]:
您所在的州或省份名称是什么?
[Unknown]:
该单位的两字母国家代码是什么
[Unknown]: CN
CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=CN 正确吗?
[否]: y
输入<jetty>的主密码
(如果和 keystore 密码相同,按回车):
再次输入新密码:
完成上述工作后,将在当前目录生成 keystore 证书文件,将keystore 考贝到 azkaban web服务器根目录中.如:cp keystore azkaban/server
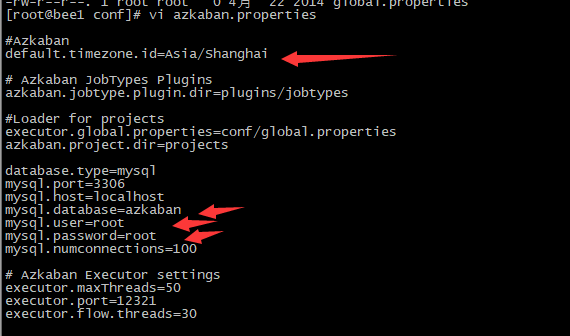
4. 配置文件--------------------统一时间
注:先配置好服务器节点上的时区
1、先生成时区配置文件Asia/Shanghai,用交互式命令 tzselect 即可
2、拷贝该时区文件,覆盖系统本地时区配置
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
然后对所有的机器执行该操作

3.修改配置文件,下面是配置邮件地址,复制收发邮件。暂时先不配
--------------------------------------------------------------------
PS:这里是修改Server的配置


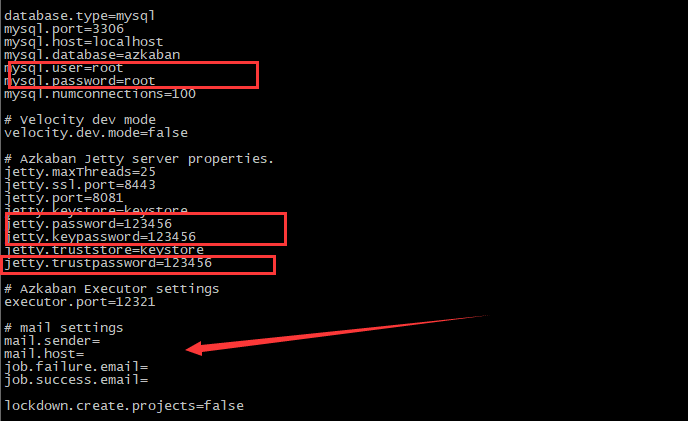
PS:web服务器的配置

PS:修改excutor
启动
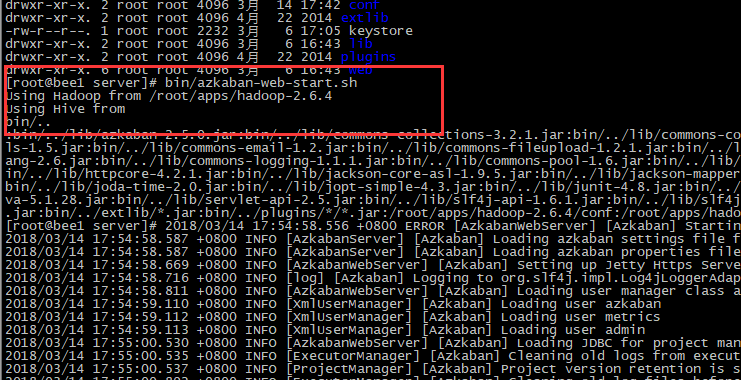
web服务器
在azkaban web服务器目录下执行启动命令
bin/azkaban-web-start.sh
注:在web服务器根目录运行
或者启动到后台
nohup bin/azkaban-web-start.sh 1>/tmp/azstd.out 2>/tmp/azerr.out &
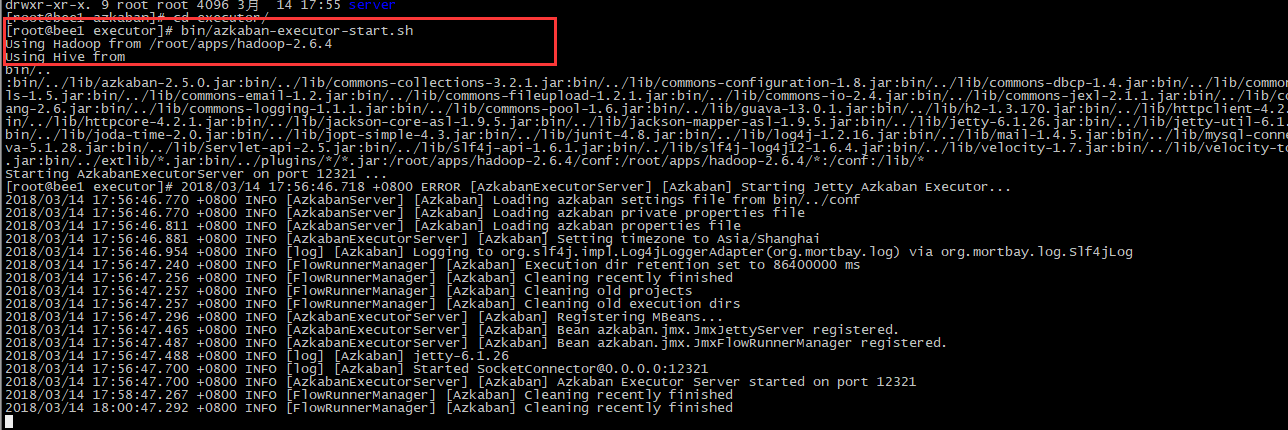
执行服务器
在执行服务器目录下执行启动命令
bin/azkaban-executor-start.sh
注:只能要执行服务器根目录运行
启动完成后,在浏览器(建议使用谷歌浏览器)中输入https://服务器IP地址:8443 ,即可访问azkaban服务了.在登录中输入刚才新的户用名及密码(admin),点击 login.
--------------------------------------------------------------------------------------------------------------------------------
2.4 Azkaban实战
PS:因为Azkaba最好执行command命令,因为jar包不太常用
Azkaba内置的任务类型支持command、java
Command类型单一job示例
1、创建job描述文件
vi command.job
|
#command.job type=command command=echo 'hello' |
2、将job资源文件打包成zip文件
zip command.job

3、通过azkaban的web管理平台创建project并上传job压缩包
首先创建project
上传zip包
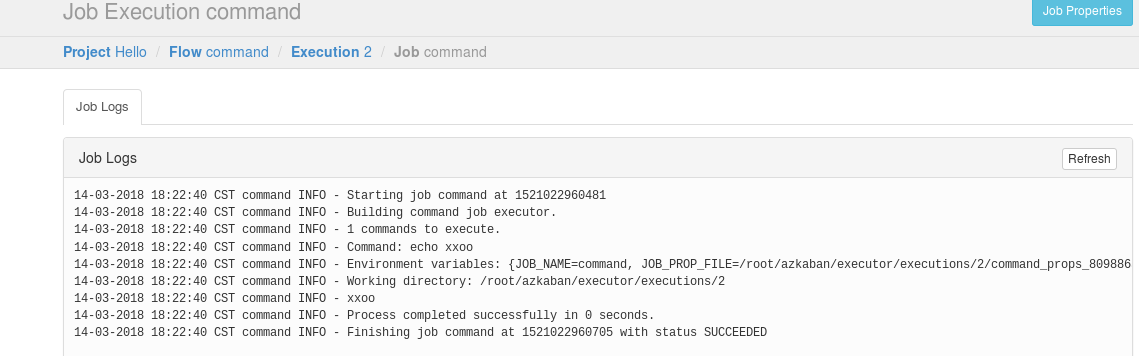
4、启动执行该job
PS:在执行命令之前,也有调度执行,还是立即执行。为了测试,我们选择立即执行。

PS:后面还有一些例子,没有做。
PS:如果提交文件以后,执行的什么都是正确的,就是 运行错误,可能文件格式没有保存成UTF-8
----------------------------------------------------------------------------------------------------------------------------------------------------
3. sqoop数据迁移
3.1 概述
sqoop是apache旗下一款“Hadoop和关系数据库服务器之间传送数据”的工具。
导入数据:MySQL,Oracle导入数据到Hadoop的HDFS、HIVE、HBASE等数据存储系统;
导出数据:从Hadoop的文件系统中导出数据到关系数据库
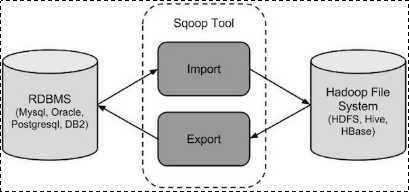
3.2 工作机制
将导入或导出命令翻译成mapreduce程序来实现
在翻译出的mapreduce中主要是对inputformat和outputformat进行定制
3.3 sqoop实战及原理
3.3.1 sqoop安装
安装sqoop的前提是已经具备java和hadoop的环境
1、下载并解压

PS: 解压并修改文件夹名

PS:到sqoop文件夹下修改 配置文件的名字
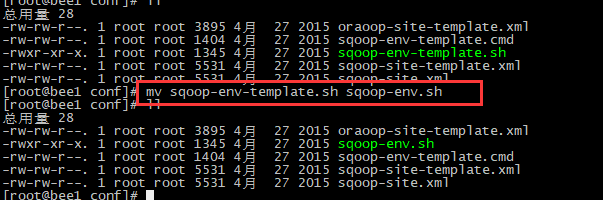
PS:编辑sqoop-env.sh
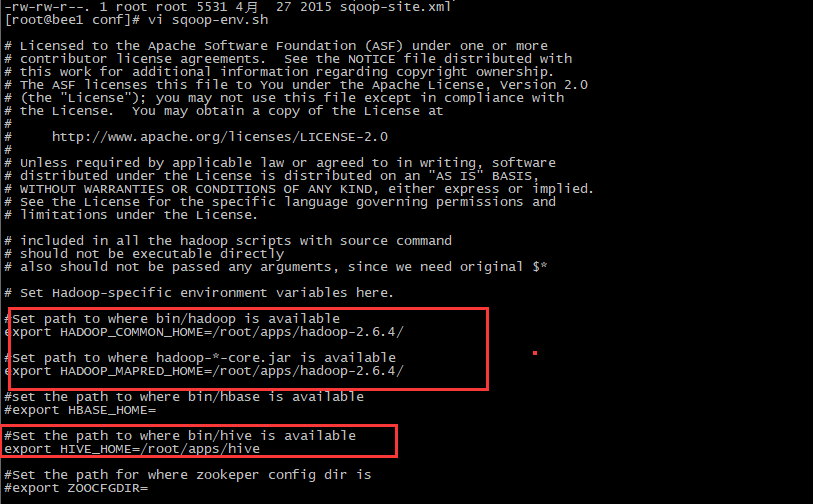
PS:从hive中拷贝文件,然后启动

PS:导入数据,从mysql导入hdfs;

------------------------------------自己修改查找数据库进行sqoop

bin/sqoop import \
--connect jdbc:mysql://localhost:3306/azkaban \
--username root \
--password root \
--table project_files \
--m 1
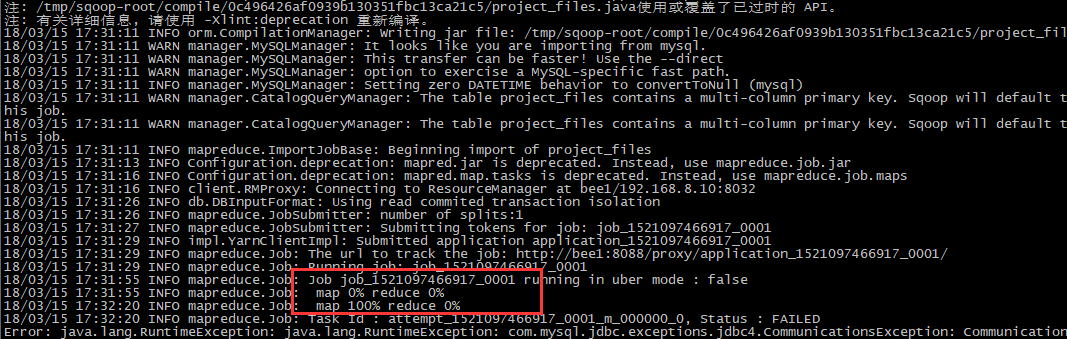

---------------------
PS:如果没有指定数据的位置,那么导入的数据就放在其就默认放在HADOOP_HOME/bin/hadoop (导入:从mysql到hdfs)
为了验证在HDFS导入的数据,请使用以下命令查看导入的数据
|
$ HADOOP_HOME/bin/hadoop fs -cat /user/hadoop/emp/part-m-00000 |
-------------------------------------------
3.5 Sqoop的数据导出(需要在mysql端手动的创建库表)
将数据从HDFS导出到RDBMS数据库
导出前,目标表必须存在于目标数据库中。
u 默认操作是从将文件中的数据使用INSERT语句插入到表中
u 更新模式下,是生成UPDATE语句更新表数据
语法
以下是export命令语法。
|
$ sqoop export (generic-args) (export-args) |
示例
数据是在HDFS 中“EMP/”目录的emp_data文件中。所述emp_data如下:
|
1201, gopal, manager, 50000, TP 1202, manisha, preader, 50000, TP 1203, kalil, php dev, 30000, AC 1204, prasanth, php dev, 30000, AC 1205, kranthi, admin, 20000, TP 1206, satish p, grp des, 20000, GR |
1、首先需要手动创建mysql中的目标表
|
$ mysql mysql> USE db; mysql> CREATE TABLE employee ( id INT NOT NULL PRIMARY KEY, name VARCHAR(20), deg VARCHAR(20), salary INT, dept VARCHAR(10)); |
2、然后执行导出命令
|
bin/sqoop export \ --connect jdbc:mysql://hdp-node-01:3306/test \ --username root \ --password root \ --table employee \ --export-dir /user/hadoop/emp/ |
3、验证表mysql命令行。
|
mysql>select * from employee; 如果给定的数据存储成功,那么可以找到数据在如下的employee表。 +------+--------------+-------------+-------------------+--------+ | Id | Name | Designation | Salary | Dept | +------+--------------+-------------+-------------------+--------+ | 1201 | gopal | manager | 50000 | TP | | 1202 | manisha | preader | 50000 | TP | | 1203 | kalil | php dev | 30000 | AC | | 1204 | prasanth | php dev | 30000 | AC | | 1205 | kranthi | admin | 20000 | TP | | 1206 | satish p | grp des | 20000 | GR | +------+--------------+-------------+-------------------+--------+ |

day12Flume、azkaban、sqoop的更多相关文章
- 第2节 azkaban调度:16、azkaban的介绍以及azkaban的soloserver的安装使用
2. 工作流调度器azkaban 2.1 概述 azkaban官网: https://azkaban.github.io/ 2.1.1为什么需要工作流调度系统 l 一个完整的数据分析系统通常都是由大 ...
- [sqoop1.99.7] sqoop入门-下载、安装、运行和常用命令
一.简介 Apache Sqoop is a tool designed for efficiently transferring data betweeen structured, semi-str ...
- [转]云计算之hadoop、hive、hue、oozie、sqoop、hbase、zookeeper环境搭建及配置文件
云计算之hadoop.hive.hue.oozie.sqoop.hbase.zookeeper环境搭建及配置文件已经托管到githubhttps://github.com/sxyx2008/clou ...
- sqoop导出到mysql中文乱码问题总结、utf8、gbk
sqoop导出到mysql中文乱码问题总结.utf8.gbk 今天使用sqoop1.4.5版本的(hadoop使用cdh5.4)因为乱码问题很是头痛半天.下面进行一一总结 命令: [root@sdzn ...
- sqoop命令,mysql导入到hdfs、hbase、hive
1.测试MySQL连接 bin/sqoop list-databases --connect jdbc:mysql://192.168.1.187:3306/trade_dev --username ...
- 第2节 azkaban调度:17、azkaban的两个服务模式的安装
2.3.3.azkaban两个服务模式安装 1.确认所需软件: Azkaban Web服务安装包 azkaban-web-server-0.1.0-SNAPSHOT.tar.gz Azkaban执行服 ...
- hadoop、hbase、hive、zookeeper版本对应关系
本文引用自:http://www.aboutyun.com/blog-61-62.html 最新版本: hadoop和hbase版本对应关系: Hbase Hadoop 0.92.0 1.0.0 ...
- Hadoop、Pig、Hive、Storm、NOSQL 学习资源收集
(一)hadoop 相关安装部署 1.hadoop在windows cygwin下的部署: http://lib.open-open.com/view/1333428291655 http://blo ...
- Hadoop集群中Hbase的介绍、安装、使用
导读 HBase – Hadoop Database,是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群. 一.Hbase ...
随机推荐
- ssh三大框架整合
spring+struts2+hibernate 参考1:数据库为oracle http://takeme.iteye.com/blog/1678268 参考2:数据库为mysql http://bl ...
- DBProxy 项目全解
转载自:https://github.com/Meituan-Dianping/DBProxy/blob/master/doc/USER_GUIDE.md#2 1 总体信息 1.1 关于 ...
- 每天CSS学习之text-overflow
text-overflow是CSS3的一个属性,其作用是当文本溢出包含它的元素时,应该裁剪还是将多余的字符用省略号来表示. 该属性一般和overflow:hidden属性一起使用. text-over ...
- PHP socket以及http、socket、tcp、udp
一.TCP/UDP/Socket TCP/IP(Transmission Control Protocol/Internet Protocol)即传输控制协议/网间协议,是一个工业标准的协议集,它是为 ...
- CreateThread和_beginthread区别及使用
CreateThread 是一个Win 32API 函数, _beginthread 是一个CRT(C Run-Time)函数, 他们都是实现多线城的创建的函数,而且他们拥有相同的使用方法,相同的参数 ...
- java动态代理的实现
1.首先定义一个委托类的接口Subject,应该必须是接口,而不能是抽象类.因为Proxy.newProxyInstance方法的第二个参数需要委托类实现的接口. public static Obje ...
- jsp连接java类出问题
问题:UserBean cannot be resolved to a type 解决: (1)jdk不匹配(或不存在) 项目指定的jdk为“jdk1.6.0_18”,而当前eclipse使用 ...
- background 的一些 小的细节: 1, 背景色覆盖范围: border+ width+ padding ;背景图覆盖范围: width + padding ; 2设置多个背景图片 ; 3) background-position定位百分比的计算方式: 4)background-clip 和 background-origin 的区别
1. background (background-color, background-image) 背景色覆盖范围: border+ width+ padding ;背景图覆盖范围: width ...
- <context:annotation-config/>和<mvc:annotation-driven/>及解决No mapping found for HTTP request with URI [/role/getRole] in DispatcherServlet with name 'springmvc-config'
1:什么时候使用<context:annotation-config> 当你使用@Autowired,@Required,@Resource,@PostConstruct,@PreDest ...
- 2019-03-01-day002-基础编码
01 昨日内容回顾 编译型: 一次性编译成二进制. 优点:质型速度快. 确定:开发效率低,不能跨平台. 解释型: 逐行解释,逐行运行. 优点:开发效率高,可以跨平台. 缺点:回字形效率低. pytho ...