【转】Apache Kylin 2.0为大数据带来交互式的BI
本文转载自:【技术帖】Apache Kylin 2.0为大数据带来交互式的BI
编者注:Kyligence的联合创始人兼CEO Luke Han在上做题为“”的演讲。
基于Hadoop的SQL一直在被持续地改进,但是一个查询等几分钟到几小时还是非常正常。在这篇博文里,将会介绍开源的分布式分析引擎Apache Kylin,尤其会重点介绍它是如何以数量级加速大数据查询,以及在2.0版里面为交互式BI所提供的新特性,包括对雪花模型的支持和流式建立数据立方。
Apache Kylin是什么?
Kylin是一个在Hadoop上的OLAP引擎。如图1所示,Kylin位于Hadoop之上,向上层的应用提供了基于标准SQL接口的关系型数据。
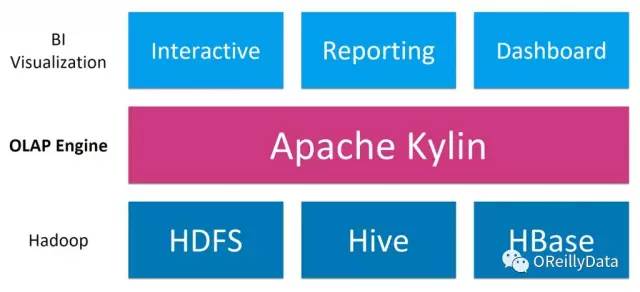
图1 Apache Kylin的位置。图片由Yang Li友情提供
Kylin可以处理大数据集,从查询延迟上讲是很快的,这也是它和其他基于Hadoop的SQL的区别。比如,我们所知道的使用Kylin的最大的生产系统实例是在今日头条,一个中国的新闻推送应用。头条有一个包含3万亿条记录的表,Kylin对它的平均查询响应时间低于1秒。下一节我们会讨论Kylin是怎么实现这么快的查询。
Kylin引擎的另一个特点是它可以支持复杂的数据模型。例如,太平洋保险(CPIC,中国的一个保险集团公司)有一个多达60维的模型。 Kylin提供标准的JDBC / ODBC / RestAPI接口,可实现与任何SQL应用程序的连接。
Kyligence还开发了一个,展示了使用10亿条航班记录的BI体验。你可以查看这里来了解。比如,在旧金山国际机场过去20年里延误最久的航班是哪个。(使用用户名“analyst”和密码“analyst”登录,选择“airline_cube”,拖放维度和事实数据来查询这个数据集)
一个零售业场景:展示Kylin的速度
Kylin比传统的基于Hadoop的SQL要快,是因为它采用了预计算来在SQL执行前先行一步。例如,设想一个零售业务场景,你需要处理非常多的订单,每个订单包含多个商品。如果想知道订单取消和退货造成的影响,一个分析人员可能需要写一个查询来在某个时间段内按照“returnflas(退货标记)”和“orderstatus(订单状态)”来汇总收入进行汇报,如图2 所示。图里面显示了这个查询被编译成的关系表达式,也叫执行计划。

图2 一个典型的OLAP查询的时间复杂度。图片由Yang Li友情提供
从这个执行计划可以很容易地看出,这个执行的时间复杂度至少是O(N),这里N是表里的总行数,因为每行都要至少被访问一次。同时我们假定要关联的表都已经很好地被分区和索引过了,因此花费比较大的关联操作也可以在线性的时间复杂度上完成,但在实际场景里这种情况是不大可能的。
这个O(N)的时间复杂度并不好,因为这意味着如果数据量增长十倍,则查询时间也会慢10倍。现在一个查询需要花1秒钟,那么以后随着数据的增长,这个时间会变成10秒甚至是100秒。我们想要的是无论数据量大小,这个查询时间都是固定不变的。
Kylin的解决方法是预计算。整体思路是,如果我们提前知道查询的模式,我们就能预先计算出整个执行的一部分。在上面这个例子里,就是预先计算Aggregate、Join和表扫描操作。生成的结果是一个立方体理论里的数据立方(或者可以把它叫做“实例化的总结表”,如果这样听起来觉得更好的话)。
如图3所示,最初的执行计划就被转换成了基于数据立方之上。这个数据立方体包含了按照“returnflag(退货标记)”、“orderstatus(订单状态)”和“date(日期)”进行汇总的记录。因为退货标记和订单状态是一个固定的数量,而日期范围被限定在3年(大概1000天)。这就意味着这个数据立方体里的行数最多就是“标记数×状态数×天数”,对O定义的时间复杂度来说就是一个常量。这个新的执行计划将会保证不管源数据有多大都有一个固定的执行时间。这就我们想要的效果!
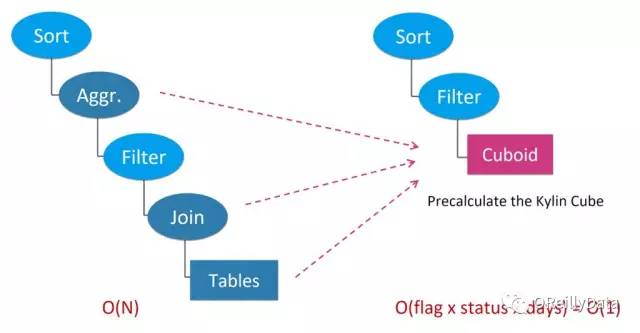
图3 通过预计算实现从O(N)到O(1)。图片由Yang Li友情提供Kylin的架构一览
如我们所见,Kylin是一个依赖于预计算的系统。其核心是基于经典的立方体理论,并发展成一个大数据上的SQL解决方案(见图4)。它使用模型和立方体概念来定义预计算的空间。构建引擎从数据源载入数据,并在使用MapReduce或Spark的分布式系统上进行预计算。被计算出来的立方体被存储在HBase里。当一个查询来到时,Kylin把它编译成一个关系表达式,找到匹配的模型,并基于预计算好的数据立方体而不是原始数据执行这个表达式。
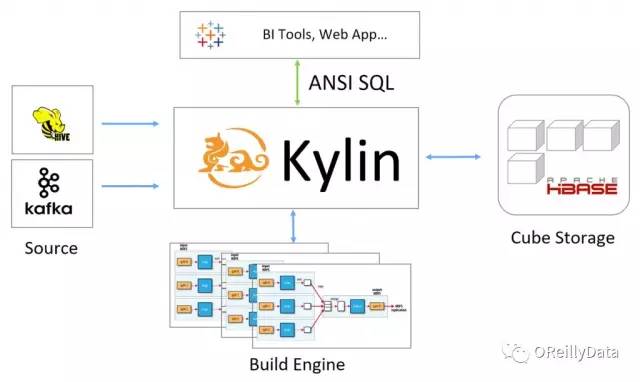
图4 Apache Kylin的架构。图片由Yang Li友情提供
这里的关键就是建模。如果你对数据以及分析的需求有非常好的理解,你是可以用正确的模型和立方体定义来找到正确的预计算。接着,绝大多数(如果不是全部)的查询都可以被转化成对此立方体的查询。如图5所示,执行时间复杂度可以被降低到O(1),从而获得非常快的查询速度,无论原始数据有多大。
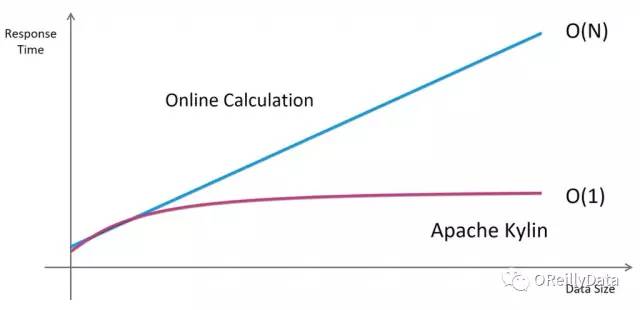
图5 O(N)和O(1)的对比。图片由Yang Li友情提供(延展阅读: ) Kylin 2.0的特性
对雪花模型的支持和TPC-H基准测试
Kylin 2.0引入了对元数据建模的增强,并且可以支持开箱即用的雪花模型。为了演示建模和SQL能力上的改进,我们进行了用Kylin 2.0运行TPC-H查询的基准测试。
需要注意的是,这里的目标并不是想与其他人的TPC-H结果进行比较。一方面,根据TPC-H规范,不允许在表之间进行预先计算,因此在这个意义上,Kylin不能算是有效的TPC-H系统。另一方面,我们还没有对这些查询进行性能调优。改善的空间还是很大的。
根据相同的零售场景,让我们快速查看一些有趣的TPC-H查询。图6是TPC-H查询07。SQL里面的字太小,可能看不清楚,但它给出了查询的复杂性的粗略感觉。该图是执行计划,强调了预计算(白色)与在线计算(蓝色)的部分。很容易看出,大部分关系运算符是预先计算的。剩下的Sort / Proj / Filter在很少的记录上工作,因此查询可以超快。在相同的硬件和相同的数据集上,Kylin用了0.17秒完成,而Hive + Tez对此查询运行了35.23秒。这显示了预计算所带来的差异。

图6 TPC-H的查询07。图片由Yang Li友情提供
图7所示的TPC-H查询11是另一个例子。这个查询有四个子查询,比前一个更复杂。 其执行计划包括两个分支,每个分支从预先计算的立方体载入数据。 分支结果再连接起来,这是一个复杂的在线计算。随着在线计算部分的增加,预计算的部分减少,Kylin的运行时间更长:3.42秒。 然而,完全在线计算的Hive + Tez仍然要慢一点,运行时间为15.87秒。
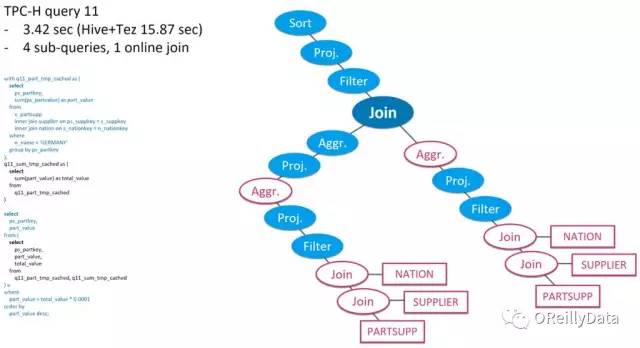
图7 TPC-H的查询11。图片由Yang Li友情提供
(有关Kylin和TPC-H的更多详细信息,请参阅此链接包含可以在你自己的环境中重复基准测试的步骤,以及我们在两个不同Hadoop集群中测试的所有TPC-H查询的性能结果。)
为近实时分析准备的流式立方体
预先计算给ETL流程增加了额外的时间,这在实时场景中会成为一个问题。为了解决这个问题,Kylin现在支持增量加载新添加的数据,而不会影响历史数据。 已有RestAPI可用于自动触发增量构建。每日构建一次是最常见的,现在更频繁的数据加载也是可行的。
从1.6版开始,Kylin可以直接从Kafka获取数据,并进行近乎实时的数据分析。使用基于内存的立方体算法,微型增量构建可以在几分钟内完成。生成的结果是许多小的立方体分片,可以给查询提供实时的结果。
为了展示这个特性是如何运作的,我们构建了一个来实时分析Twitter消息。它运行在一个八个节点的AWS集群上,有三个Kafka broker。输入是一个Twitter样本源,每秒有超过10K条消息。立方体的平均复杂度是:九个维度和三个测量数据。增量构建是每两分钟触发一次,并在三分钟内完成。总体而言,系统在实时性上有五分钟的延迟。
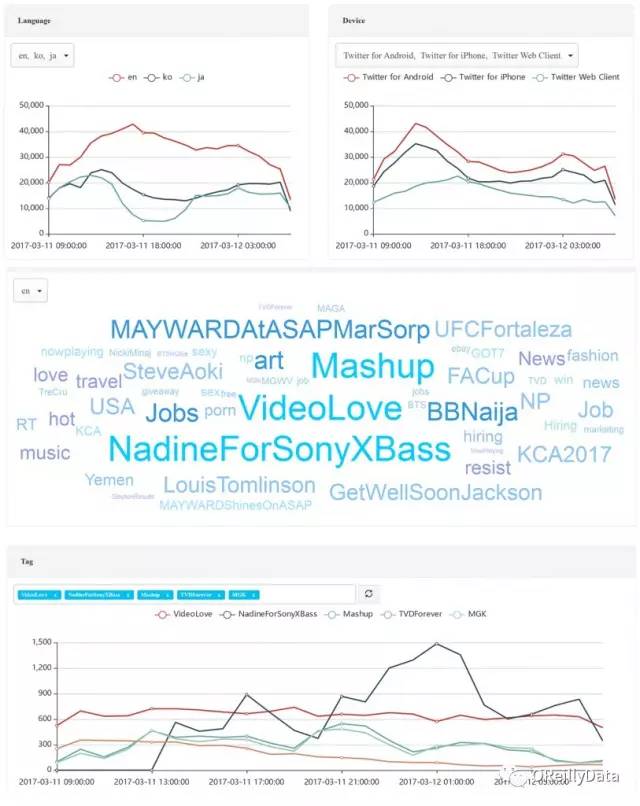
图8 近实时的Twitter分析。图片由Yang Li友情提供
该演示按照语言和设备维度显示了Twitter消息的趋势。在图8中可以看到,美国白天的英文消息量上升,而亚洲语言的消息量在夜间下降。演示里还有一个标签云,用以显示最新的热门话题。在标签云下面是最热门标签的趋势。所有图表都是实时到最近五分钟。
总结
Apache Kylin是Hadoop上一个流行的OLAP引擎。通过使用预计算技术,它可以使SQL对大数据的查询速度有数量级的加快,并使交互式BI和其他在线应用程序能够直接在大数据上运行。
Kylin 2.0是最新版本,可以下载。新版本的特性包括:Hadoop上的小于秒级的SQL延迟; 雪花模型的支持和成熟的SQL功能; 流式立方体用于近实时分析; 内置时间/窗口/百分位数功能;和可以将构建时间缩短一半的Spark构建立方体。
相关资料:
This article originally appeared in English: "".

Yang Li
Yang Li是Kyligence的联合创始人兼CTO,以及Apache Kylin项目的联合创立者和PMC成员。 作为Kylin的技术主管和架构师,Yang专注于大数据分析、并行计算、数据索引、关系代数、近似算法等技术。他曾任eBay分析数据基础设施部高级架构师。他还是IBM InfoSphere BigInsights的技术领导者。在此期间,他负责BigInsights这一基于Hadoop的开源平台,并获得了IBM杰出技术成就奖。他曾经是摩根士丹利的副总裁,负责全球监管报表基础架构。
(文章转载自OReillyData)
7月12-15日, 由O'Reilly和Cloudera共同举办的全球顶尖的数据盛会Strata Data Conference
"Apache and Apache Kylin are either registered trademarks or trademarks of The Apache Software Foundation in the US and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks."
【转】Apache Kylin 2.0为大数据带来交互式的BI的更多相关文章
- 【转】使用Apache Kylin搭建企业级开源大数据分析平台
http://www.thebigdata.cn/JieJueFangAn/30143.html 本篇文章整理自史少锋4月23日在『1024大数据技术峰会』上的分享实录:使用Apache Kylin搭 ...
- 使用Apache Kylin搭建企业级开源大数据分析平台
转:http://www.thebigdata.cn/JieJueFangAn/30143.html 我先做一个简单介绍我叫史少锋,我曾经在IBM.eBay做过大数据.云架构的开发,现在是Kylige ...
- Apache Kylin v3.0.0-alpha 发布
Apache Kylin v3.0.0-alpha 发布 Apr 19, 2019 • Shaofeng Shi 近日 Apache Kylin 社区很高兴地宣布,Apache Kylin v3.0. ...
- 从 Airflow 到 Apache DolphinScheduler,有赞大数据开发平台的调度系统演进
点击上方 蓝字关注我们 作者 | 宋哲琦 ✎ 编 者 按 在不久前的 Apache DolphinScheduler Meetup 2021 上,有赞大数据开发平台负责人 宋哲琦 带来了平台调度系统 ...
- CentOS7部署CDH6.0.1大数据平台
Cloudera’s Distribution Including Apache Hadoop,简称“CDH”,基于Web的用户界面,支持大多数Hadoop组件,包括HDFS.MapReduce.Hi ...
- 开源分布式计算引擎 & 开源搜索引擎 Iveely 0.5.0 为大数据而生
Iveely Computing 产生背景 08年的时候,我开始接触搜索引擎,当时遇到的第一个难题就是大数据实时并发处理,当时实验室的机器我们可以随便用,至少二三十台机器,可以,却没有程序可以将这些机 ...
- 大数据时代的新BI系统架构发展趋势
商业智能(BI,Business Intelligence).它是一套完整的解决方式,用来将企业中现有的数据进行有效的整合,高速准确的提供报表并提出决策根据.帮助企业做出明智的业务经营决策. ...
- 民生银行十五年的数据体系建设,深入解读阿拉丁大数据生态圈、人人BI 是如何养成的?【转】
早在今年的上半年我应邀参加了由 Smartbi 主办的一个小型数据分析交流活动,在活动现场第一次了解到了民生银行的阿拉丁项目.由于时间关系,嘉宾现场分享的内容非常有限.凭着多年对行业研究和对解决方案的 ...
- 大数据时代,银行BI应用的方案探讨
大数据被誉为21世纪发展创造的新动力,BI(商业智能)成为当下最热门的数据应用方案.据资料显示:当前中国大数据IT投资最高的为五个行业中,互联网最高.其次是电信.金融.政府和医疗.而在金融行业中,银行 ...
随机推荐
- 27-1-LTDC-DMA2D—液晶显示简介
1.显示器简介 (1).显示器属于计算机的 I/O 设备,即输入输出设备.它是一种将特定电子信息输出到屏幕上再反射到人眼的显示工具. (2).液晶是一种介于固体和液体之间的特殊物质,它是一种有机化合物 ...
- (1.4)mysql sql mode 设置与使用
关键词: mysql sql mode 1.查阅 mysql> mysql> show variables like 'sql_mode%';+---------------+------ ...
- mysql主从调优
mysql主从同步调优 常用选项 适用于Master服务器 binlog-do-db=name 设置Master对哪些库记日志 binlog-ignore-db=name 设置Master对哪些库不记 ...
- 【CART与GBDT】
一.CART(分类回归树) 1.思想: 一种采用基尼信息增益作为划分属性的二叉决策树.基尼指数越小,表示纯度越高. 2.回归: 每个节点都有一个预测值,预测值等于属于该节点的所有样例的 ...
- IE无法安装Activex控件
由于无法验证发行者,所以windows已经阻止此软件,如要安装未签名的activex控件,按如下步骤: 1.打开Internet Explorer---菜单栏点“工具”---Internet选项--安 ...
- NYOJ 会场安排问题
#include<iostream> #include<stdio.h> #include<string.h> #include<queue> #inc ...
- LigerUI子父窗口之间传参问题
在父窗口自定义一个参数,该参数为一个方法,然后在子窗口使用 var dialog = frameElement.dialog; //调用页面的dialog对象(ligerui对象)该对象,取得父窗口定 ...
- seller vue配置路径相对路径【组件 只写简单路径】
在[webpack.base.conf.js]配置 'components': path.resolve(__dirname, '../src/components')
- 微信小程序--修改data数组或对象里面的值
1.初始data数据 Page({ data:{ code:'1234', reward:[{ name:"艾伦" ...
- 【Tools】-NO.4.Tools.1.VM.1.001-【VMware Workstation PRO 12 Install CentOS 7.1】-
1.0.0 Summary Tittle:[Tools]-NO.4.Tools.1.VM.1.001-[VMware Workstation PRO 12 Install CentOS 7.1]- S ...