Oracle redo/undo 原理理解
一. 什么是redo(用于重做数据)
redo也就是重做日志文件(redo log file),Oracle维护着两类重做日志文件:在线(online)重做日志文件和归档(archived)重做日志文件。这两类重做日志文件都用于恢复;其主要目的是,万一实例失败或介质失败,它们能够恢复数据。
由于数据库缓冲,对磁盘数据的更新不是实时的,但是对redo日志的更新会在commit之后确切发生。 如果在事务提交之后,磁盘数据更新之前,系统发生故障,比如断电,系统重启之后会将那些已经写入redo,但是没有更新到磁盘的数据进行重做,这样系统就恢复到故障点之前了。
redo日志默认3组,循环写入,第一组(每个组所有成员同时写入同样的信息)满了,切换到第二个,第二个满了切换到第三个,当所有组都写满之后,日志进程再次开始写第一个,后面的数据覆盖前面的数据,即为非归档模式。 鉴于redo如此重要,需要将已写满的日志归档,即复制redo内容到其他地方,即开启归档日志模式,但是会影响系统性能(生产环境建议开启归档,因为生产数据安全性第一)。
二. 什么是undo(用于回滚数据)
从概念上讲,undo正好与redo相对。你对数据执行修改时,数据库会生成undo信息,也就是说被修改的元数据存到undo中,这样万一你执行的事务或语句由于某种原因失败了,或者如果你用一条ROLLBACK语句请求回滚,就可以利用这些undo信息将数据放回到修改前的样子。redo用于在失败时重放事务(即恢复事务),undo则用于取消一条语句或一组语句的作用。
undo保存在undo表空间中,且包含在redo日志中。 当执行DML操作时,旧数据会写入undo中。 事务回滚,未提交时,rollback,把undo中的旧数据重新写回数据段中;已提交时,进行闪回(flashback)操作 ,大多都是基于undo数据实现的。读一致性:用户检索数据时,ORACLE总是使用户只能看到被提交过的数据(当前事务中的其他语句可以看到未提交的数据),或者特定时间点的数据(select语句时间点)。当某个用户在此查询点之后修改了数据,此查询读到这个数据时,就是通过在undo中读取来实现的。 oracle使用scn来实现读一致性,系统变化号(SCN)是一个数据结构,它定义了一个给定时刻提交的数据库版本,SCN可以被认为是oracle的逻辑时钟,每一次提交数值都要增加。
三. 对undo段的一个误解
通常对undo有一个误解,认为undo用于数据库物理地恢复到执行语句或事务之前的样子,但实际上并非如此。数据库只是逻辑地恢复到原来的样子,所有修改都被逻辑地取消,但是数据结构以及数据库块本身在回滚后可能大不相同。(比如一个插入操作,新分配了一些数据块。后来事务失败,插入操作全部回滚,新分配的一些数据块还是存在的)
原因在于:在所有多用户系统中,可能会有数十、数百甚至数千个并发事务。数据库的主要功能之一就是协调对数据的并发访问。也许我们的事务在修改一些块,而一般来讲往往会有许多其他的事务也在修改这些块。因此,不能简单地将一个块放回到我们的事务开始前的样子,这样会撤销其他人 (其他事务)的工作!
例如,假设我们的事务执行了一个INSERT语句,这条语句导致分配一个新区段(也就是说,导致表的空间增大)。通过执行这个INSET,我们将得到一个新的块,格式化这个块以便使用,并在其中放上一些数据。此时,可能出现另外某个事务,它也向这个块中插入数据。如果要回滚我们的事务,显然不能取消对这个块的格式化和空间分配。因此,Oracle回滚时,它实际上会做与先前逻辑上相反的工作。对于每个INSERT,Oracle会完成一个DELETE。对于每个DELETE,Oracle会执行一个INSERT。对于每个UPDATE,Oracle则会执行一个“反UPDATE“,或者执行另一个UPDATE将修改前的行放回去。
所以有一种异常情况就很容易解释了,一个表明明只有1000行左右的数据,一条select * from table 语句可能需要耗时1,2分钟。这张表应该是经常进行新增删除操作的表,比如我新增了1000万行数据,然后又将这些数据删除。对这个表进行全表扫描的时候,仍然会去扫描这1000万行以前所占用的那些数据块,看看里面是否包含数据。也就是oracle里面所说的高水平线(HWM),这些数据块都增加到了高水平线下面,oracle会扫描所有高水平线下的数据块。
四. redo与undo如何协作保证数据完整与安全性
以一个例子来说明一下(一个事务包含一组sql语句):
insert
into t(x,y) values(1,1);
update t set x = x+1 where x = 1;
delete from t where x = 2;
1.INSERT
对于第一条INSERT INTO 语句,redo和undo都会生成。所生成的undo信息足以使INSERT“消失“。INSERT INTOT生成的redo信息则足以让这个插入”再次发生“。
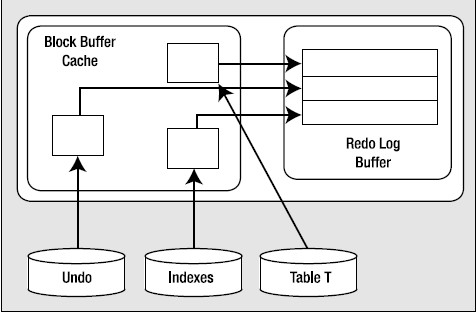
这里缓存了一些已修改的undo块、索引块和表数据块。这些块得到重做日志缓冲区中相应条目的“保护“。
假想场景一:系统现在崩溃
系统现在崩溃是没什么关系的。SGA会被清空,但是我们并不需要SGA里的任何内容。重启动时就好像这个事务从来没有发生过一样。没有将任何已修改的块刷新输出到磁盘,也没有任何redo刷新输出到磁盘。我们不需要这些undo或redo信息来实现实例失败恢复。
假想场景二:缓冲区缓存现在已满
在这种情况下,DBWR必须留出空间,要把已修改的块从缓存刷新输出。如果是这样,DBWR首先要求LGWR将保护这些数据库块的redo条目刷新输出。DBWR将任何有修改的块写至磁盘之前,LGWR必须先刷新输出与这些块相关的redo信息。这是有道理的——如果我们要刷新输出表T中已修改的块,但没有刷新输出与undo块关联的redo条目,倘若系统失败了,此时就会有一个已修改的表T块,而没有与之相关的redo信息。在写出这些块之前需要先刷新输出重做日志缓存区,这样就能重做(重做)所有必要的修改,将SGA放回到现在的状态,从而能发生回滚。(也就是任何一条修改记录持久化到数据文件的时候,必须先把它对应的redo条目持久化到磁盘文件,以保证这个过程的可逆性。你可能会问,redo不是前滚吗,可逆应该是回滚,怎么跟redo有关系呢?其实是redo段里面包含了undo段的信息)
2.UPDATE
UPDATE所带来的工作与INSERT大体一样。不过UPDATE生成的undo量更大;由于存在更新,所以需要保存一些“前“映像。系统状态如下图所示。

块缓冲区缓存中会有更多新的undo段块。为了撤销这个更新,如果必要,已修改的数据库表和索引块也会放在缓存中。我们还生成了更多的重做日志缓存区条目。下面假设前面的插入语句生成了一些重做日志,其中有些重做日志已经刷新输出到磁盘上,有些还放在缓存中。
假想场景一:系统现在崩溃
启动时,oracle会去读取重做日志文件,会发现有一些redo文件对应的修改记录还没有持久化到数据文件。然后发现这些redo文件是一个事务里面的,于是得回滚这个事务。步骤如下:
a. 根据redo文件,进行数据前滚,会在内存中构造出undo块、已修改的表块,以及已修改的索引块。
b. 根据undo块进行数据回滚,回滚到插入前的数据状态。
3.DELETE
同样,DELETE会生成undo,块将被修改,并把redo发送到重做日志缓冲区。这与前面没有太大的不同。实际上,它与UPDATE如此类似,所以我们不再啰嗦,直接来介绍COMMIT。
4.COMMIT
在此,Oracle会把重做日志缓冲区刷新输出到磁盘。
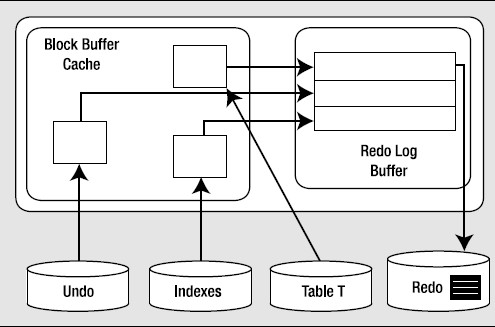
假设目前已修改的块放在缓冲区缓存中;有一些块已经刷新输出到磁盘上,有一些还没有。但是如果重做这个事务所需的全部redo都安全地存放在磁盘上,那么修改就是永久的了,即使有一些修改的块还没有刷新输出到磁盘上。(commit并不是把所有的修改持久化到了数据文件,而是所有的redo文件持久化到磁盘文件,只要所有的重做日志文件持久化到磁盘,这些修改就是永久的了。)如果从数据文件直接读取数据,可能会看到块还是事务发生前的样子,因为很有可能DBWR还没有(从缓冲区缓存)写出这些块。这没有关系,如果出现失败,可以利用重做日志文件来得到最新的块。
Oracle redo/undo 原理理解的更多相关文章
- [Oracle] Redo&Undo梳理
Oracle Redo&undo Oracle中的redo和undo是关键技术的核心, 诸如实例恢复, 介质恢复, DataGuard, 闪回机制等都是给予redo和undo的, 所以很有必要 ...
- Oracle redo undo
通常对undo有一个误解,认为undo用于数据库物理地恢复到执行语句或事务之前的样子,但实际上并非如此.数据库只是逻辑地恢复到原来的样子,所有修改都被逻辑地取消,但是数据结构以及数据库块本身在回滚后可 ...
- [转]undo log与redo log原理分析
数据库通常借助日志来实现事务,常见的有undo log.redo log,undo/redo log都能保证事务特性,这里主要是原子性和持久性,即事务相关的操作,要么全做,要么不做,并且修改的数据能得 ...
- Innodb 实现高并发、redo/undo MVCC原理
一.并发控制 因为并发情况下有可能出现不同线程对同一资源进行变动,所以必须要对并发进行控制以保证数据的同一与安全. 可以参考CPython解释器中的GIL全局解释器锁,所以说python中没有 ...
- Oracle redo与undo
Undo and redo Oracle最重要的两部分数据,undo 与redo,redo(重做信息)是oracle在线(或归档)重做日志文件中记录的信息,可以利用redo重放事务信息,undo(撤销 ...
- 一分钟理解Redo Undo
数据库中有一种特殊的"日志文件"叫 Redo(重做) Undo(撤销),传统意义上的日志文件是记录系统运行状态的,主要用于系统工程师或者程序员排错.而 Reod/Undo 文件是数 ...
- Oracle特殊恢复原理与实战(DSI系列)
1.深入浅出Oracle(DSI系列Ⅰ) 2.Oracle特殊恢复原理与实战(DSI系列Ⅱ) 3.Oracle SQL Tuning(DSI系列Ⅲ)即将开设 4.Oracle DB Performan ...
- Oracle Redo Log 机制 小结(转载)
Oracle 的Redo 机制DB的一个重要机制,理解这个机制对DBA来说也是非常重要,之前的Blog里也林林散散的写了一些,前些日子看老白日记里也有说明,所以结合老白日记里的内容,对oracle 的 ...
- [转帖]万字详解Oracle架构、原理、进程,学会世间再无复杂架构
万字详解Oracle架构.原理.进程,学会世间再无复杂架构 http://www.itpub.net/2019/04/24/1694/ 里面的图特别好 数据和云 2019-04-24 09:11:59 ...
随机推荐
- 20165321 实验三 敏捷开发与XP实践
任务1: 要求: 参考 http://www.cnblogs.com/rocedu/p/6371315.html#SECCODESTANDARD 安装alibaba 插件,解决代码中的规范问题. 在I ...
- fill和memset的区别
https://blog.csdn.net/xs18952904/article/details/75195412 memset只能初始化成为0或者-1,其他都要用fill来完成. #include& ...
- unittest多线程生成报告-----BeautifulReport
原文地址https://www.cnblogs.com/yoyoketang/p/8404204.html 前言 selenium多线程跑用例,这个前面一篇已经解决了,如何生成一个测试报告这个是难点, ...
- Serveral effective linux commands
1. 统计当前文件夹下文件个数(不包括子目录下文件): $ ls -l | grep "^-" | wc -l 2. 统计当前文件夹下文件个数(包括子目录下文件): $ ls -l ...
- centos7安装Amber16 && AmberTools
Centos7 安装amber16 1.准备下载好的amber(Amber16.tar.bz2)及tools(AmberTools16.tar.bz2)安装包: $ cd MySoftware_hom ...
- Appium基础(二)demo
具体配置,请看上一篇 一.启动Android模拟 Start 打开如下界面:这个过程可能会有些慢,黑屏等等,请耐心等待 二.appium配置 1.点机器人图标 PlatformVersion 选19, ...
- mongodb中直接根据某个字段更新另外一个字段值
表:tblCard 要更新的字段:tPAFlow 值字段: pFlow 过滤 条件:{"lCycle":2} db.tblCard.find({"lCycle" ...
- 执行字符串或注释代码段的方法(eval、exec、execfile)
eval:计算字符串中的表达式exec:执行字符串中的语句execfile:用来执行一个文件 需注意的是,exec是一个语句,而eval()和execfile()则是内建built-in函数. 1 2 ...
- Django 一对一,一对多,多对多 操作、常用方法
几对几的模型结构的使用场景为:一般根据业务需求,同一业务,需要向相关联的多表插入删除数据时,会用到. 一对一: 创建一个用户表 class Users(models.Model): username ...
- hive-drop-import-delims选项对oracle的clob无效
工作过程中发现了用sqoop将oracle中的数据导入到hive时,会因为oracle中类型为clob的字段中存在换行时,会造成hive的数据错位.即使加上了 --hive-drop-import-d ...