深度学习Bible学习笔记:第七章 深度学习中的正则化
一、正则化介绍
问题:为什么要正则化?
NFL(没有免费的午餐)定理:
没有一种ML算法总是比别的好
好算法和坏算法的期望值相同,甚至最优算法跟随机猜测一样
前提:所有问题等概率出现且同等重要
实际并非如此,具体情况具体分析,把当前问题解决好就行了
不要指望找到放之四海而皆准的万能算法!
方差和偏差:
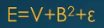
过拟合与欠拟合:
训练集和测试集
机器学习目标:
特定任务上表现良好的算法
泛化能力强-->验证集上的误差小,训练集上的误差不大(不必追求完美,否则可能会导致过拟合)即可。
如何提升泛化能力:
(1)数据
数据和特征是上限,而模型和算法只是在逼近这个上限而已
预处理:离散化、异常值、缺失值等
特征选择
特征提取:pca
构造新的数据:平移不变性
(2)模型
数据中加入噪音
正则化项:减少泛化误差(非训练误差)
集成方法
几种训练情形:
(1)不管真实数据的生成过程---欠拟合,偏差大
(2)匹配真实数据的生成过程---刚刚好
(3)不止真实数据的生成过程,还包含其他生成过程---过拟合,方差大
正则的目标:
从(3)--->(2),偏差换方差,提升泛化能力
注:
永远不知道训练出来的模型是否包含数据生成过程!
深度学习应用领域极为复杂,图像、语音、文本等,生成过程难以琢磨
事实上,最好的模型总是适当正则化的大型模型
正则化是不要的!!!
XTX不一定可逆(奇异),导致无法求逆(PCA)
解决:加正则,XTX--->XTX+αI(一定可逆),说明:α--阿尔法,I--大写的i,即单位阵。
大多数正则化能保证欠定(不可逆)问题的迭代方法收敛
注:伪逆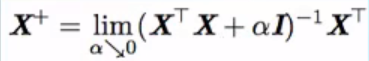
二、深度网络正则化
深度网络中的正则化策略有哪些?——传统ML方法的扩展
方法:
增加硬约束(参数范数惩罚):限制参数,如L1,L2
增加软约束(约束范数惩罚):惩罚目标函数
集成方法
其他
约束和惩罚的目的
植入先验知识
偏好简单模型
三、参数范数惩罚
从线性模型说起:
形式:y=Wx+b
W:两变量间的相互作用——重点关注
b:单变量——容易欠拟合,次要
仿射变换=线性变换+平移变换
参数范数惩罚:
通常只惩罚权重W,不管b——b是单变量,且容易过拟合
θ=(W;b)≈(W)
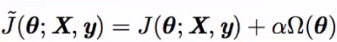
α是惩罚力度,Ω是正则项。
最常见,L2参数范数惩罚:
权重衰减(weight decay)
岭回归,Tikhonov正则
形式:
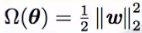
效果:
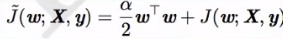
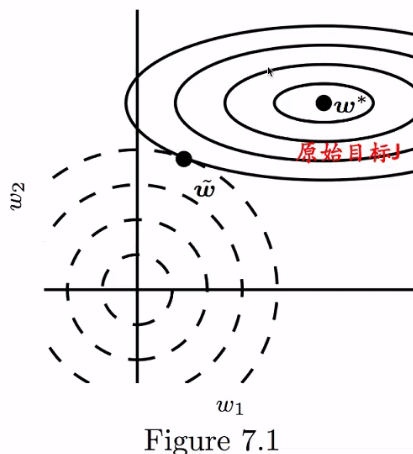
正则项Ω挤占原始目标J的空间,逼迫J
权重接近于原点(或任意点)
详细推导过程见P142-P143
L2正则能让算法“感知”到较高方差的输入x
线性缩放每个wi
L1参数范数惩罚:LASSO
形式:
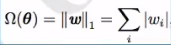
效果:
L1与L2大不一样:线性缩放wi-->增加wi同号的常数
某些wi=0,产生稀疏解,常用于特征选择
除了L1,稀疏解的其他方法?
Student-t先验导出的惩罚
KL散度惩罚
注:不同于L1惩罚参数,惩罚激活单元
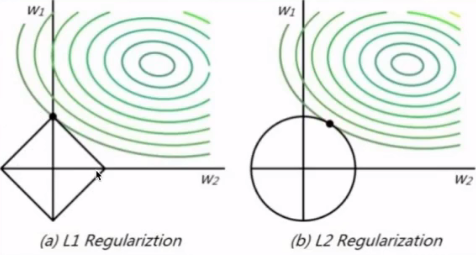
约束范数惩罚:
本质:约束问题--> 无约束问题
形式:
参数范数惩罚:
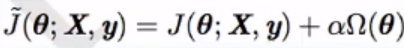
约束范数惩罚:
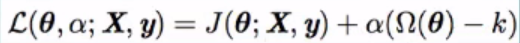
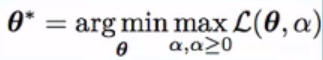

五、数据增强
提升泛化能力的最好办法:
数据增强:创造假数据
方法:
(1)数据造假:平移、旋转、缩放——不能改变类别
图像,语音
(2)注入噪声
输入层≈权重参数惩罚
隐含层:去噪编码器、dropout
权重:RNN
输出层:标签平滑(反例)
softmax永远无法真正预测0或1,需要做平滑,防止走极端
噪声鲁棒性:
注入噪声远比简单收缩参数强大,特别是加入隐含层
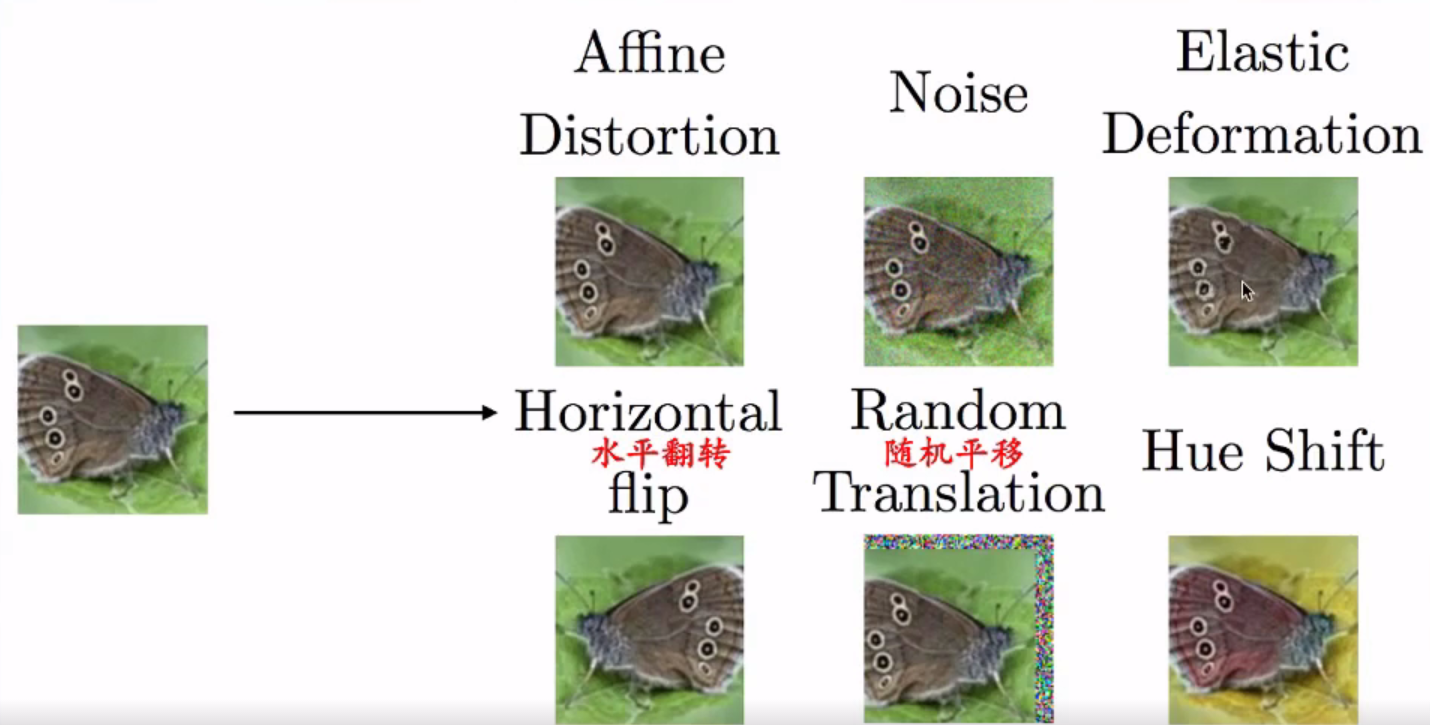
六、早停止
问题
随着时间推移,训练集误差逐渐减少,而验证集误差再次上升
能不能在转折点处提前终止呢?
早停止
当验证集误差在指定步数内没有改进,就停止
有效,简单,高效的超参选择算法
训练步数是唯一跑一次就能尝试很多值的超参
第二轮训练策略(验证集)
(1)再次初始化模型,使用所有数据再次训练
使用第一轮步数
(2)保持第一轮参数,使用全部数据继续训练
避免重新训练高成本,但表现没那么好,不保证终止
早停止为何有正则化效果?
表象:验证集误差曲线呈U型
本质:将参数空间限制在初始参数θ0的小邻域内(εt)
εt等效于权重衰减系数的倒数
相当于L2正则,但更具优势
自动确定正则化的正确量
七、参数绑定和参数共享
参数范数惩罚:
对偏离0(或固定区域)的参数进行惩罚,使用参数彼此接近
一种方式,还有吗?
参数共享:
强迫某些参数相等
优势:只有参数子集需要存储,节省内存。如CNN
八、集成方法
集成方法:
集合几个模型降低泛化误差的技术
模型平均:强大可靠
kaggle比赛中前三甲基本都是集成方法
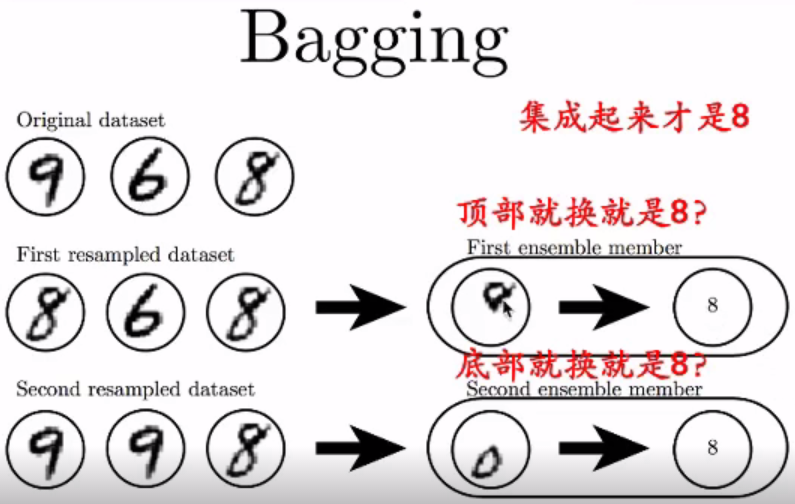
Bagging:
有放回抽样,覆盖2/3
多个网络的集成
偏差换方差
Boosting:
单个网络的集成
方差换偏差
Dropout:
集成大量深层网络的bagging方法
多个弱模型组成一个强模型
施加到隐含层的掩掩码噪声
一般5-10个网络,太多会很难处理
示例:
2个输入,1个输出,2个隐含层
一共24=64种情形
问题:大部分没有输入,输入到输出的路径
网络越宽,这种问题概率越来越小
注:
不同于bagging,模型独立
dropout所有模型共享参数
推断:对所有成员累计投票做预测
效果:
Dropout比其他标准正则化方法更有效
权重衰减、过滤器范数约束、稀疏激活
可以跟其他形式正则一起使用
优点:
计算量小
不限制模型和训练过程
注:
随机性对dropout方法不必要,也不充分
九、对抗训练
人类不易察觉对抗样本与原始样本的差异,但网络可以
小扰动导致数据点流行变化

再次附上:
深度学习Bible学习笔记:第七章 深度学习中的正则化的更多相关文章
- Programming In Scala笔记-第七章、Scala中的控制结构
所谓的内建控制结构是指编程语言中可以使用的一些代码控制语法,如Scala中的if, while, for, try, match, 以及函数调用等.需要注意的是,Scala几乎所有的内建控制结构都会返 ...
- JVM学习笔记-第七章-虚拟机类加载机制
JVM学习笔记-第七章-虚拟机类加载机制 7.1 概述 Java虚拟机描述类的数据从Class文件加载到内存,并对数据进行校验.转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这个过程被 ...
- Android群英传笔记——第七章:Android动画机制和使用技巧
Android群英传笔记--第七章:Android动画机制和使用技巧 想来,最 近忙的不可开交,都把看书给冷落了,还有好几本没有看完呢,速度得加快了 今天看了第七章,Android动画效果一直是人家中 ...
- [Python学习笔记][第七章Python文件操作]
2016/1/30学习内容 第七章 Python文件操作 文本文件 文本文件存储的是常规字符串,通常每行以换行符'\n'结尾. 二进制文件 二进制文件把对象内容以字节串(bytes)进行存储,无法用笔 ...
- o'Reill的SVG精髓(第二版)学习笔记——第七章
第七章:路径 所有描述轮廓的数据都放在<path>元素的d属性中(d是data的缩写).路径数据包括单个字符的命令,比如M表示moveto,L表示lineto.接着是该命令的坐标信息. 7 ...
- C++ primer plus读书笔记——第2章 开始学习C++
第2章 开始学习C++ 1. endl确保程序继续运行前刷新输出(将其立即显示在屏幕上),而使用"\n"不提供这样的保证,这意味着在有些系统中,有时可能在您输入信息后才会出现提示. ...
- Getting Started With Hazelcast 读书笔记(第七章)
第七章 部署策略 Hazelcast具有适应性,能根据不同的架构和应用进行特定的部署配置,每个应用可以根据具体情况选择最优的配置: 数据与应用紧密结合的模式(重点,of就是这种) 胖客户端模式(最好用 ...
- 《图解HTTP》阅读笔记--第七章---确保WEB安全的HTTPS
第七章.确保WEB安全的HTTPSHTTP的缺点:通信使用明文(不加密),内容可能会被窃听 解决---加密处理: //将通信加密 :通过SSL(安全套接层)---HTTPS(超文本传输安全协议)--- ...
- GAN实战笔记——第七章半监督生成对抗网络(SGAN)
半监督生成对抗网络 一.SGAN简介 半监督学习(semi-supervised learning)是GAN在实际应用中最有前途的领域之一,与监督学习(数据集中的每个样本有一个标签)和无监督学习(不使 ...
随机推荐
- PLSQL Developer 连接Linux 下Oracle的安装与配置
一.下载 下载地址:http://www.oracle.com/technetwork/database/features/instant-client/index-097480.html 这是Ora ...
- Unity5天空盒小黑点问题
unity5打开的时候有时候天空盒基本上全是小黑点,原因我现在不知道,以后再补充. 解决办法: 打开windows--lighting选项.然后双击skybox里面的材质,右边会显示当前天空盒的材质界 ...
- jackson的自动检测机制
jackson允许使用任意的构造方法或工厂方法来构造实例 使用@JsonAutoDetect(作用在类上)来开启/禁止自动检测 fieldVisibility:字段的可见级别 ANY:任何级别的字段都 ...
- 【JUC】CopyOnWriteArrayList
写入时复制(CopyOnWrite) 什么是CopyOnWrite容器 CopyOnWrite容器即写时复制的容器.通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进 ...
- Pool多进程示例
利用Pool类多进程实现批量主机管理 #!/usr/bin/python # -*- coding: UTF-8 -*- # Author: standby # Time: 2017-03-02 # ...
- 5W2H分析法
- Spring第一个helloWorld
Spring 简介: 轻量级:Spring是非侵入性的-基于Spring开发的应用中的对象可以不依赖于Spring的API 依赖注入(DI—dependdency injection.IOC) 面向切 ...
- Wannafly挑战赛21 E 未来城市规划
传送门 题目中给的信息很难直接维护,但是可以考虑一条边对答案的贡献 在以\(x\)为根的子树里,如果一条边\(i\)的权值为\(w_i\),这条边深度更深的端点为\(to_i\),那么这条边对这个子树 ...
- 【文件】使用jacob将word转换成pdf格式
使用jacob将word转换成pdf格式 1.需要安装word2007或以上版本,若安装07版本学确保该版本已安装2downbank0204MicrosoftSaveasPDF_ XPS,否则安装 ...
- Problem F Plug It In!
题目链接:https://cn.vjudge.net/contest/245468#problem/F 大意:给你插座和电器的对应关系,有多个电器对应一个插座的情况,但是一个插座只能供一个电器使用,现 ...