【图的遍历】广度优先遍历(DFS)、深度优先遍历(BFS)及其应用
无向图满足约束条件的路径
•【目的】:掌握深度优先遍历算法在求解图路径搜索问题的应用
【内容】:编写一个程序,设计相关算法,从无向图G中找出满足如下条件的所有路径:
(1)给定起点u和终点v。
(2)给定一组必经点,即输出的路径必须包含这些点。
(3)给定一组必避点,即输出的路径必须不能包含这些点。
【来源】:《数据结构教程(第五版)》李春葆著,图实验11。
代码:
#include<stdio.h>
#include<malloc.h>
#define MAXV 20
typedef struct ANode
{
int adjvex;
struct ANode *nextarc;
} ArcNode; typedef struct
{
ArcNode *adjlist[MAXV];
int n1, e1;
} AdjGraph; int visited[MAXV];
int v1[MAXV], v2[MAXV], n, m; // v1为必过点集合, v2为必避点集合;n为必过点的个数, m为必避点个数
int count = ; //路径个数 void CreateAdj(AdjGraph *&G, int A[MAXV][MAXV], int n1, int e1)
{
int i, j;
ArcNode *p;
G = (AdjGraph*)malloc(sizeof(AdjGraph));
for (i = ; i < n1; ++i)
G->adjlist[i] = NULL;
for (i = ; i < n1; ++i)
for (j = n1; j >= ; --j)
if (A[i][j] == )
{
p = (ArcNode*)malloc(sizeof(ArcNode));
p->adjvex = j;
p->nextarc = G->adjlist[i];
G->adjlist[i] = p;
}
G->n1 = n1;
G->e1 = e1;
} bool comp(int path[MAXV], int d)
{
int flag1 = , f1, flag2 = , f2, j;
for (int i = ; i < n; ++i)
{
f1 = ;
for (j = ; j <= d; ++j)
if (path[j] == v1[i])
{
f1 = ;
break;
}
flag1 += f1;
} for (int i = ; i < m; ++i)
{
f2 = ;
for (j = ; j <= d; ++j)
if (path[j] == v2[i])
{
f2 = ;
break;
}
flag2 += f2;
} if (flag1 == && flag2 == )
return true;
else
return false;
} void findpath(AdjGraph *G, int u, int v, int d, int path[MAXV])
{
int i;
ArcNode *p;
visited[u] = ;
++d; path[d] = u;
if (u == v && comp(path, d))
{
printf("路径%d:", ++count);
printf("%d", path[]);
for (i = ; i <= d; ++i)
printf("->%d ", path[i]);
printf("\n");
}
p = G->adjlist[u];
while (p != NULL)
{
if (visited[p->adjvex] == )
findpath(G, p->adjvex, v, d, path);
p = p->nextarc;
}
visited[u] = ;
} int main()
{
AdjGraph *G;
int u, v; // u为起点,v为终点
int path[MAXV];
int A[MAXV][MAXV] = {
{, , , , , , , , , , , , , , },
{, , , , , , , , , , , , , , },
{, , , , , , , , , , , , , , },
{, , , , , , , , , , , , , , },
{, , , , , , , , , , , , , , },
{, , , , , , , , , , , , , , },
{, , , , , , , , , , , , , , },
{, , , , , , , , , , , , , , },
{, , , , , , , , , , , , , , },
{, , , , , , , , , , , , , , },
{, , , , , , , , , , , , , , },
{, , , , , , , , , , , , , , },
{, , , , , , , , , , , , , , },
{, , , , , , , , , , , , , , },
{, , , , , , , , , , , , , , } };
CreateAdj(G, A, , );
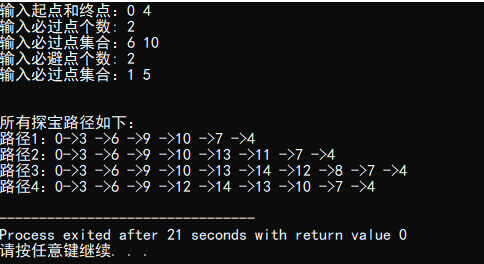
printf("输入起点和终点:");
scanf("%d %d", &u, &v);
printf("输入必过点个数: ");
scanf("%d", &n);
printf("输入必过点集合:");
for (int i = ; i < n; ++i)
scanf("%d", &v1[i]);
printf("输入必避点个数: ");
scanf("%d", &m);
printf("输入必过点集合:");
for (int i = ; i < m; ++i)
scanf("%d", &v2[i]);
printf("\n\n所有探宝路径如下:\n");
findpath(G, u, v, -, path);
return ;
}
运行结果:
用图搜索方法求解迷宫问题
•【目的】:深入掌握图遍历算法在求解实际问题中的运用
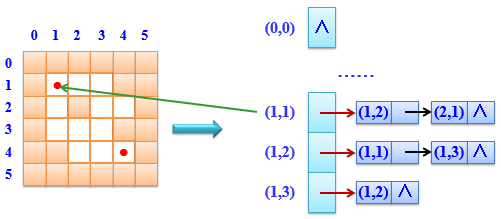
【内容】:编写一个程序,完成如下功能:
(1) 建立迷宫对应的邻接表
(2) 采用深度优先遍历算法输出从入口(1, 1)到出口(M,N)的所有迷宫路径
【来源】:《数据结构教程(第五版)》李春葆著,图实验14。
代码:
#include<stdio.h>
#include<malloc.h>
#define MAXV 20
#define N 4
#define M 4
typedef struct ANode
{
int i, j; // i为横坐标, j为纵坐标
struct ANode *nextarc;
} ArcNode; typedef struct
{
ArcNode *mg[N + ][M + ];
} AdjGraph; typedef struct
{
int i;
int j;
} Box; typedef struct
{
Box data[MAXV];
int length;
} Path; int visited[N + ][M + ] = { }; void CreateAdj(AdjGraph *&G, int A[N + ][M + ], int n, int m)
{
int i, j, k, i1, j1;
ArcNode *p;
G = (AdjGraph *)malloc(sizeof(AdjGraph));
for (i = ; i < n + ; ++i)
for (j = ; j < m + ; ++j)
G->mg[i][j] = NULL;
for (i = ; i <= n; ++i)
for (j = ; j <= m; ++j)
if (A[i][j] == )
{
k = ;
while (k <= )
{
switch (k)
{
case : i1 = i - ; j1 = j; break;
case : i1 = i; j1 = j + ; break;
case : i1 = i + ; j1 = j; break;
case : i1 = i; j = j - ; break;
}
++k;
if (A[i1][j1] == )
{
p = (ArcNode*)malloc(sizeof(ArcNode));
p->i = i1;
p->j = j1;
p->nextarc = G->mg[i][j];
G->mg[i][j] = p;
}
}
}
} void findpath(AdjGraph *G, int x1, int y1, int xe, int ye, Path pa)
{
ArcNode *p;
++pa.length;
pa.data[pa.length].i = x1;
pa.data[pa.length].j = y1;
visited[x1][y1] = ;
if (xe == x1 && ye == y1)
{
for (int u = ; u <= pa.length; ++u)
printf(" (%d, %d) ", pa.data[u].i, pa.data[u].j);
} p = G->mg[x1][y1];
while (p != NULL)
{ if (visited[p->i][p->j] == )
findpath(G, p->i, p->j, N, M, pa);
p = p->nextarc;
}
visited[x1][y1] = ;
} int main()
{
AdjGraph *G;
Path pa;
int A[N + ][M + ] = {
{ , , , , , },{ , , , , , },
{ , , , , , },{ , , , , , },
{ , , , , , },{ , , , , , } };
CreateAdj(G, A, N, M);
pa.length = -;
findpath(G, , , N, M, pa);
return ;
}
求解两个动物之间通信最少翻译问题
•【目的】:掌握广度优先遍历算法在求解实际问题中的运用
【内容】:编写一个程序,完成如下功能:
据美国动物分类学家欧内斯特-迈尔推算,世界上有超过100万种动物,各种动物有自己的语言。假设动物A只能与动物B通信,所以,动物A、C之间通信需要动物B来当翻译。问两个动物之间项目通信至少需要多少个翻译。
测试文本文件test.txt中第一行包含两个整数n(2<= n <= 200)、m(1 <= m <= 300),其中n代表动物的数量,动物编号从0开始,n个动物编号为0 ~ n-1,m表示可以相互通信动物数,接下来的m行中包含两个数字分别代表两种动物可以相互通信,在接下来包含一个整数k(k <= 20),代表查询的数量,每个查询,输出这两个动物彼此同喜至少需要多少个翻译,若它们之间无法通过翻译来通信,输出-1.
输入样本 输出结果
1
【来源】:《数据结构教程(第五版)》李春葆著,图实验12。
【图的遍历】广度优先遍历(DFS)、深度优先遍历(BFS)及其应用的更多相关文章
- C++编程练习(9)----“图的存储结构以及图的遍历“(邻接矩阵、深度优先遍历、广度优先遍历)
图的存储结构 1)邻接矩阵 用两个数组来表示图,一个一维数组存储图中顶点信息,一个二维数组(邻接矩阵)存储图中边或弧的信息. 2)邻接表 3)十字链表 4)邻接多重表 5)边集数组 本文只用代码实现用 ...
- (原创)不过如此的 DFS 深度优先遍历
DFS 深度优先遍历 DFS算法用于遍历图结构,旨在遍历每一个结点,顾名思义,这种方法把遍历的重点放在深度上,什么意思呢?就是在访问过的结点做标记的前提下,一条路走到天黑,我们都知道当每一个结点都有很 ...
- HDU 4707 Pet(DFS(深度优先搜索)+BFS(广度优先搜索))
Pet Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Submissio ...
- BFS广度优先 vs DFS深度优先 for Binary Tree
https://www.geeksforgeeks.org/bfs-vs-dfs-binary-tree/ What are BFS and DFS for Binary Tree? A Tree i ...
- 图文详解两种算法:深度优先遍历(DFS)和广度优先遍历(BFS)
参考网址:图文详解两种算法:深度优先遍历(DFS)和广度优先遍历(BFS) - 51CTO.COM 深度优先遍历(Depth First Search, 简称 DFS) 与广度优先遍历(Breath ...
- 图的存储,搜索,遍历,广度优先算法和深度优先算法,最小生成树-Java实现
1)用邻接矩阵方式进行图的存储.如果一个图有n个节点,则可以用n*n的二维数组来存储图中的各个节点关系. 对上面图中各个节点分别编号,ABCDEF分别设置为012345.那么AB AC AD 关系可以 ...
- Java实现DFS深度优先查找
1 问题描述 深度优先查找(depth-first search,DFS)可以从任意顶点开始访问图的顶点,然后把该顶点标记为已访问.在每次迭代的时候,该算法紧接着处理与当前顶点邻接的未访问顶点.这个过 ...
- 图的深度优先遍历(DFS)和广度优先遍历(BFS)
body, table{font-family: 微软雅黑; font-size: 13.5pt} table{border-collapse: collapse; border: solid gra ...
- 图的深度优先遍历(DFS)和广度优先遍历(BFS)算法分析
1. 深度优先遍历 深度优先遍历(Depth First Search)的主要思想是: 1.首先以一个未被访问过的顶点作为起始顶点,沿当前顶点的边走到未访问过的顶点: 2.当没有未访问过的顶点时,则回 ...
随机推荐
- Hbase记录-Hbase介绍
Hbase是什么 HBase是一种构建在HDFS之上的分布式.面向列的存储系统,适用于实时读写.随机访问超大规模数据的集群. HBase的特点 大:一个表可以有上亿行,上百万列. 面向列:面向列表(簇 ...
- 循环屏障CyclicBarrier以及和CountDownLatch的区别
CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier).它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门, ...
- 5. SprigBoot自动配置原理
配置文件到底能写什么?怎么写? 都可以在SpringBoot的官方文档中找到: 配置文件能配置的属性参照 1.自动配置原理: 1).SpringBoot启动的时候加载主配置类,开启了自动配置功 ...
- sock_ntop.c
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <netinet/in ...
- Dom4j工具类源码解析
话不多说,上源码: package com.changeyd.utils;import java.io.File;import java.io.FileNotFoundException;import ...
- 20155330 2016-2017-2 《Java程序设计》第六周学习总结
20155330 2016-2017-2 <Java程序设计>第六周学习总结 教材学习内容总结 学习目标 理解流与IO 理解InputStream/OutPutStream的继承架构 理解 ...
- C# print2flash3文件转化
1.下载print2flash3 并且安装print2flash3 2.转换工具类 (1)需要导入using Print2Flash3; 这个程序集 using System; using Syste ...
- QMouseEvent鼠标事件
Qt中的QMouseEvent一般只涉及鼠标左键或右键的单击.释放等操作,而对鼠标滚轮的响应则通过QWheeEvent来处理
- Mybatis进阶学习笔记——关系查询——一对一查询
用户和订单的需求 通过查询订单,查询用户,就是一对一查询 (1)自定义JavaBean(常用,推荐使用) <select id="queryOrderUser" result ...
- python3爬虫二
1.获取列表页文章url集合: scrapy shell http://blog.jobbole.com/all-posts/ response.css('div.post-meta a.archiv ...