论文阅读 | Transformer-XL: Attentive Language Models beyond a Fixed-Length Context
0 简述
Transformer最大的问题:在语言建模时的设置受到固定长度上下文的限制。
本文提出的Transformer-XL,使学习不再仅仅依赖于定长,且不破坏时间的相关性。
Transformer-XL包含segment-level 循环机制和positional编码框架。不仅可以捕捉长时依赖,还可以解决上下文断片问题 fragmentation problem。可以学到比RNNs长80%的依赖,比vanilla Transformers长450%。在长短序列上都取得了更好的结果。与vanilla Transformer相比,Transformer-XL的另一个优势是它可以被用于单词级和字符级的语言建模。
以下均以Transformer为基础, 回顾Transformer:
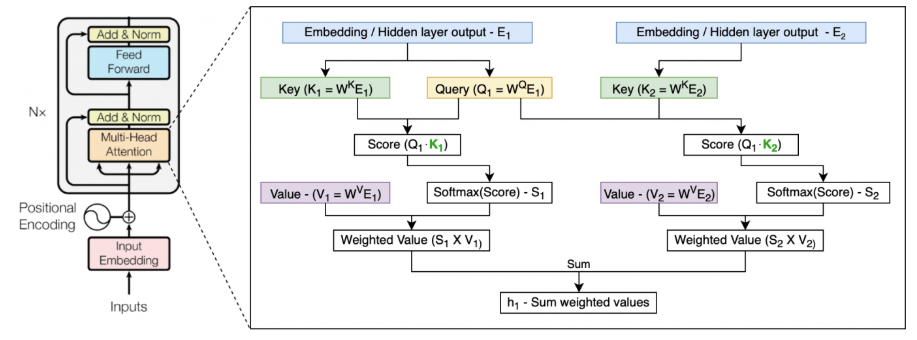
1 vanilla Transformer
Transformer-XL基于该模型改进。该模型基于Transformer,根据之前的字符预测片段中的下一个字符:例如,使用x1 x2 ... xn-1 预测字符xn,xn之后的序列被mask。
论文中,使用64层模型,并仅限于处理512个字符(定长)这种相对较短的输入,因此,它将输入分成段,分别从每个段中进行学习,如下图所示。在测试阶段如需处理较长的输入,该模型会在每一步中将输入向右移动一个字符,以此实现对单个字符的预测。
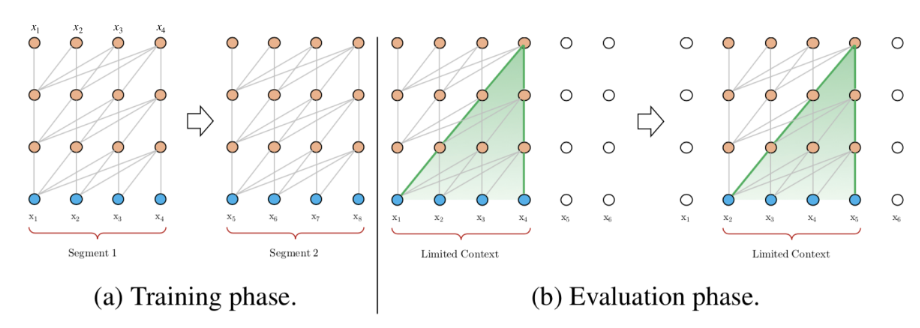
该模型在常用的数据集如enwik8和text8上的表现比RNN模型要好,但它仍有以下3个缺点:
a. 上下文长度受限:字符之间的最大依赖距离受输入长度的限制,模型看不到出现在几个句子之前的单词。
b. 上下文碎片:对于长度超过512个字符的文本,都是从头开始单独训练的。段与段之间没有上下文依赖性,会让训练效率低下,也会影响模型的性能。
c. 推理速度慢:在测试阶段,每次预测下一个单词,都需要重新构建一遍上下文,并从头开始计算,这样的计算速度非常慢。
2 Transformer-XL:循环机制
与vanilla Transformer的基本思路一样,Transformer-XL仍然是使用分段的方式进行建模,但其与vanilla Transformer的本质不同是在于引入了段与段之间的循环机制,使得当前段在建模的时候能够利用之前段的信息来实现长期依赖性。如下图所示:
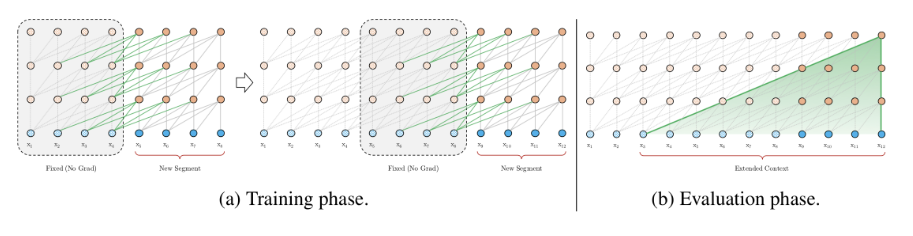
在训练阶段,处理后面的段时,每个隐藏层都会接收两个输入:
- 该段的前面隐藏层的输出,与vanilla Transformer相同(上图的灰色线)。
- 前面段的隐藏层的输出(上图的绿色线),可以使模型创建长期依赖关系。
这两个输入会被拼接,然后用于计算当前段的Key和Value矩阵。对于某个段的某一层的具体计算公式如下:
其中,τ表示第几段,n表示第几层,h表示隐层的输出。SG(⋅)表示停止计算梯度,[hu∘hv]表示在长度维度上的两个隐层的拼接,W是模型参数。乍一看与Transformer中的计算公式很像,唯一关键的不同就在于Key和Value矩阵的计算上,即knτ+1和vnτ+1,它们基于的是扩展后的上下文隐层状态h˜n−1τ+1进行计算,hn−1τ是之前段的缓存。
原则上只要GPU内存允许,该方法可以利用前面更多段的信息,测试阶段也可以获得更长的依赖。
在测试阶段,与vanilla Transformer相比,其速度也会更快。在vanilla Transformer中,一次只能前进一个step,并且需要重新构建段,并全部从头开始计算;而在Transformer-XL中,每次可以前进一整个段,并利用之前段的数据来预测当前段的输出。
3 Transformer-XL:相对位置编码
在Transformer中,一个重要的地方在于其考虑了序列的位置信息。在分段的情况下,如果仅仅对于每个段仍直接使用Transformer中的位置编码,即每个不同段在同一个位置上的表示使用相同的位置编码,就会出现问题。比如,第i−2段和第i−1段的第一个位置将具有相同的位置编码,但它们对于第i段的建模重要性显然并不相同(例如第i−2段中的第一个位置重要性可能要低一些)。因此,需要对这种位置进行区分。
论文对于这个问题,提出了一种新的位置编码的方式,即会根据词之间的相对距离而非像Transformer中的绝对位置进行编码。在Transformer中,第一层的计算查询qTi和键kj之间的attention分数的方式为:
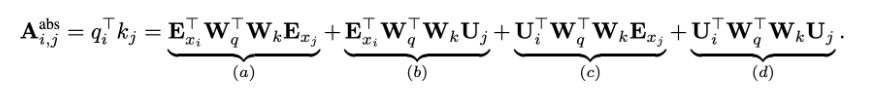
其中,Exi是词i的embedding,Exj是词j的embedding,Ui和Uj是位置向量,该公式实际上是(Wq(Exi + Ui)) T · (Wk(Exj + Uj))的展开,就是Transformer中的标准格式。
在Transformer-XL中,对上述的attention计算方式进行了变换,转为相对位置的计算,而且不仅仅在第一层这么计算,在每一层都是这样计算。

对比来看,主要有三点变化:
在(b)和(d)这两项中,将所有绝对位置向量Uj都转为相对位置向量Ri−j,与Transformer一样,这是一个固定的编码向量,不需要学习。
在(c)这一项中,将查询的UTiWTq 向量转为一个需要学习的参数向量u,因为在考虑相对位置的时候,不需要查询的绝对位置i,因此对于任意的i,都可以采用同样的向量。同理,在(d)这一项中,也将查询的UTiWTq向量转为另一个需要学习的参数向量v。
将键的权重变换矩阵Wk转为Wk,E和Wk,R,分别作为content-based key vectors和location-based key vectors。
* 从另一个角度来解读这个公式的话,可以将attention的计算分为如下四个部分:
- 基于内容的“寻址”,即没有添加原始位置编码的原始分数。
- 基于内容的位置偏置,即相对于当前内容的位置偏差。
- 全局的内容偏置,用于衡量key的重要性。
- 全局的位置偏置,根据query和key之间的距离调整重要性。
4 Transformer-XL:整体计算公式
结合上面两个创新点,将Transformer-XL模型的整体计算公式整理如下,这里考虑一个N层的只有一个注意力头的模型:




5 总结
1. 模型特点
在 AI-Rfou 等人提出的vanilla Transformer上做了两点创新:
- 引入循环机制(Recurrence Mechanism)
- 相对位置编码(Relative Positional Encoding)
2. 优点
- 在几种不同的数据集(大/小,字符级别/单词级别等)均实现了最先进的语言建模结果。
- 结合了深度学习的两个重要概念——循环机制和注意力机制,允许模型学习长期依赖性,且可能可以扩展到需要该能力的其他深度学习领域,例如音频分析(如每秒16k样本的语音数据)等。
- 在inference阶段非常快,比之前最先进的利用Transformer模型进行语言建模的方法快300~1800倍。
- 有详尽的源码!含TensorFlow和PyTorch版本的,并且有TensorFlow预训练好的模型及各个数据集上详尽的超参数设置。
3. 不足
- 尚未在具体的NLP任务如情感分析、QA等上应用。
- 没有给出与其他的基于Transformer的模型,如BERT等,对比有何优势。
- 在Github源码中提到,目前的sota结果是在TPU大集群上训练得出,对于我等渣机器党就只能玩玩base模式了。
论文阅读 | Transformer-XL: Attentive Language Models beyond a Fixed-Length Context的更多相关文章
- 【论文阅读】HydraPlus-Net: Attentive Deep Features for Pedestrian Analysis
转载请注明出处:https://www.cnblogs.com/White-xzx/ 原文地址:https://arxiv.org/abs/1709.09930 Github: https://git ...
- 论文阅读:Deep Attentive Tracking via Reciprocative Learning
Deep Attentive Tracking via Reciprocative Learning 2018-11-14 13:30:36 Paper: https://arxiv.org/abs/ ...
- BERT 论文阅读笔记
BERT 论文阅读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 由 @快刀切草莓君 ...
- Deep Reinforcement Learning for Dialogue Generation 论文阅读
本文来自李纪为博士的论文 Deep Reinforcement Learning for Dialogue Generation. 1,概述 当前在闲聊机器人中的主要技术框架都是seq2seq模型.但 ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
- 【论文阅读】Motion Planning through policy search
想着CSDN还是不适合做论文类的笔记,那里就当做技术/系统笔记区,博客园就专心搞看论文的笔记和一些想法好了,[]以后中框号中间的都算作是自己的内心OS 有时候可能是问题,有时候可能是自问自答,毕竟是笔 ...
随机推荐
- Mysql 双主--keepalived
简介 编辑 Keepalived的作用是检测服务器的状态,如果有一台web服务器宕机,或工作出现故障,Keepalived将检测到,并将有故障的服务器从系统中剔除,同时使用其他服务器代替该服务器的工作 ...
- VS下字符串与数组互相装换
1.分割字符串IdStr为int数组Ids int[] Ids = Array.ConvertAll<string, int>(IdStr.Trim().Split(','), deleg ...
- Comet OJ - Contest #7
传送门 \(A\) 咕咕咕 int main(){ for(scanf("%d",&T);T;--T){ scanf("%d%d",&l,&am ...
- (转)实验文档5:企业级kubernetes容器云自动化运维平台
部署对象式存储minio 运维主机HDSS7-200.host.com上: 准备docker镜像 镜像下载地址 复制 12345678910111213141516 [root@hdss7-200 ~ ...
- gulp4配置多页面项目编译打包
又开始公司的新项目了... 那当我们拿到公司新项目的时候我们需要做些什么呢? 下面就来分享一下我的工作步骤吧(仅使用于初学者,大神勿见怪- -,有不好的地方希望指出,十分感谢) 1. 整版浏览 这是一 ...
- Codeforces Round #591 (Div. 2, based on Technocup 2020 Elimination Round 1)
Virtual participate 的,D题不会做,打了1:30就打不动了,过了ABCE. A - CME 题意:? 题解:? void test_case() { int n; scanf(&q ...
- Spring Cloud Gateway(三):网关处理器
1.Spring Cloud Gateway 源码解析概述 API网关作为后端服务的统一入口,可提供请求路由.协议转换.安全认证.服务鉴权.流量控制.日志监控等服务.那么当请求到达网关时,网关都做了哪 ...
- ios兼容
border-radius在ios的兼容:-webkit-appearance:none; 加上这个属性,可以保证安卓和ios的圆角一致 上传图片,这段没有代码没有管图片拍摄的方位, var _th ...
- CodeForces 787 题解
A题,因为数据范围很小,所以只要暴力即可,如果能相遇一定范围不大,如果范围很大还没相遇一定是不会相遇的了.正解应当是用扩展欧几里得计算这个方程的整数解,再想办法看看有没有正整数解才是. B题,只要看懂 ...
- TCP和UDP并实现socket的简单通信
http://www.cnblogs.com/IPrograming/archive/2012/10/15/CSharp_Socket_4.html http://www.cnblogs.com/do ...