【基础算法-ST表】入门 -C++
前言
学了树状数组看到ST表模板跃跃欲试的时候发现完全没思路,因为给出的查询的时间实在太短了!几乎是需要完成O(1)查询。所以ST表到底是什么神仙算法能够做到这么快的查询?
ST表
ST表是一个用来解决RMQ问题(区间最值问题)的有效算法。
它的功能也很简单。
O(nlogn)预处理,O(1)查询区间最值。
其他好像真还没什么用了
算法
ST表利用的是倍增的思路来实现的。
怎么说呢,ST表确实很神奇。
拿最大值来说吧...
我们用f[i][j]表示第i个数开始的\(2^j\)个数中的最大值。
p.s. 下面的图是这个大佬画的
转移的时候我们可以把当前区间拆成两个区间并分别取最大值(注意这里的编号是从1开始的)
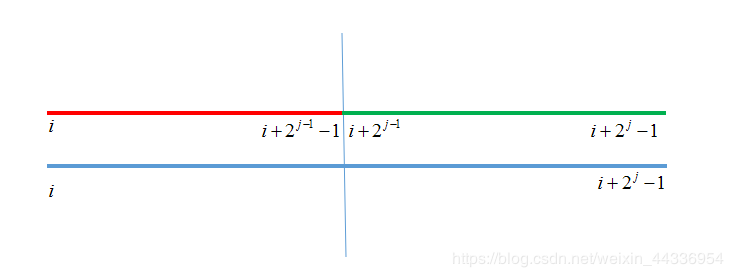
查询也比较简单;
首先要计算\(log_2\)(区间长度)
然后分别查询左右段店,保证覆盖整个区间。
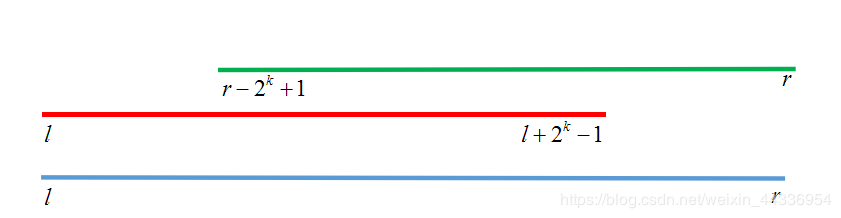
p.s因为我们需要找到一个点x使得\(x+2^k-1=r\),然后移项就可以得到\(x=r-2^k+1\),所以把x作为从右端点查询的区间的左端点,也就是\(r-2^k+1\)。
代码
代码就比较好理解了...
#include<bits/stdc++.h>
using namespace std;
inline int read()
{
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9'){
if(ch=='-')
f=-1;
ch=getchar();
}
while(ch>='0'&&ch<='9'){
x=(x<<1)+(x<<3)+(ch^48);
ch=getchar();
}
return x*f;
}
int f[100001][40],b,n,m,p,l,r;
int main()
{
n=read(),m=read();
for(int i=1;i<=n;i++)
f[i][0]=read();
b=(int)(log(n)/log(2));
for(int j=1;j<=b;j++)
for(int i=1;i<=n-(1<<j)+1;i++)
f[i][j]=max(f[i][j-1],f[i+(1<<(j-1))][j-1]);
for(int i=1;i<=m;i++)
{
l=read(),r=read();
p=(int)(log(r-l+1)/log(2));
printf("%d\n",max(f[l][p],f[r-(1<<p)+1][p]));
}
return 0;
}
ov.
【基础算法-ST表】入门 -C++的更多相关文章
- 线段树(two value)与树状数组(RMQ算法st表)
士兵杀敌(三) 时间限制:2000 ms | 内存限制:65535 KB 难度:5 描述 南将军统率着N个士兵,士兵分别编号为1~N,南将军经常爱拿某一段编号内杀敌数最高的人与杀敌数最低的人进行比 ...
- ST表入门学习poj3264 hdu5443 hdu5289 codeforces round #361 div2D
ST算法介绍:[转自http://blog.csdn.net/insistgogo/article/details/9929103] 作用:ST算法是用来求解给定区间RMQ的最值,本文以最小值为例 方 ...
- 浅谈ST表
发现自己学的一直都是假的ST表QWQ. ST表 ST表的功能很简单 它是解决RMQ问题(区间最值问题)的一种强有力的工具 它可以做到$O(nlogn)$预处理,$O(1)$查询最值 算法 ST表是利用 ...
- ST表学习笔记
ST表是一种利用DP思想求解最值的倍增算法 ST表常用于解决RMQ问题,即求解区间最值问题 接下来以求最大值为例分步讲解一下ST表的建立过程: 1.定义 f[i][j]表示[i,i+2j-1]这个长度 ...
- 浅谈 倍增/ST表
命题描述 给定一个长度为 \(n\) 的序列,\(m\) 次询问区间最大值 分析 上面的问题肯定可以暴力对吧. 但暴力肯定不是最优对吧,所以我们直接就不考虑了... 于是引入:倍增 首先,倍增是个什么 ...
- hrbustoj 1545:基础数据结构——顺序表(2)(数据结构,顺序表的实现及基本操作,入门题)
基础数据结构——顺序表(2) Time Limit: 1000 MS Memory Limit: 10240 K Total Submit: 355(143 users) Total Accep ...
- 贝叶斯公式由浅入深大讲解—AI基础算法入门
1 贝叶斯方法 长久以来,人们对一件事情发生或不发生的概率,只有固定的0和1,即要么发生,要么不发生,从来不会去考虑某件事情发生的概率有多大,不发生的概率又是多大.而且概率虽然未知,但最起码是一个确定 ...
- LCA 算法(一)ST表
介绍一种解决最近公共祖先的在线算法,st表,它是建立在线性中的rmq问题之上. 代码: //LCA: DFS+ST(RMQ) #include<cstdio> #include&l ...
- 贝叶斯公式由浅入深大讲解—AI基础算法入门【转】
本文转载自:https://www.cnblogs.com/zhoulujun/p/8893393.html 1 贝叶斯方法 长久以来,人们对一件事情发生或不发生的概率,只有固定的0和1,即要么发生, ...
随机推荐
- WEBservice的浏览器及元素的常用函数及变量整理总结 (selenium )
由于网页自动化要操作浏览器以及浏览器页面元素,这里笔者就将浏览器及页面元素常用的函数及变量整理总结一下,以供读者在编写网页自动化测试时查阅. from selenium import webdrive ...
- Linux (x86) Exploit 开发系列教程之二(整数溢出)
(1)漏洞代码 //vuln.c #include <stdio.h> #include <string.h> #include <stdlib.h> void s ...
- TZOJ1294吃糖果
#include<stdio.h> int main() { ],mi,i,max,s; scanf("%d",&t); while(t--) { scanf( ...
- 设计Qt风格的C++API
在奇趣(Trolltech),为了改进Qt的开发体验,我们做了大量的研究.这篇文章里,我打算分享一些我们的发现,以及一些我们在设计Qt4时用到的原则,并且展示如何把这些原则应用到你的代码里. 优秀AP ...
- [Vue]导航守卫:全局的、单个路由独享的、组件级的
正如其名,vue-router 提供的导航守卫主要用来通过跳转或取消的方式守卫导航.有多种机会植入路由导航过程中:全局的, 单个路由独享的, 或者组件级的. 记住参数或查询的改变并不会触发进入/离开的 ...
- (一)Redis之简介和windows下安装radis
一.简介 1.1 关于nosql 介绍Redis之前,先了解下NoSQL (Not noly SQL)不仅仅是SQL, 属于非关系型数据库:Redis就属于非关系型数据库, 传统的Mysql ,ora ...
- python 练习:函数1
习题: 定义一个方法 func,该func可以引入任意多的整型参数,结果返回其中最大与最小的值. def func(**args): return max(args),min(args) 定义一个方法 ...
- SQL 不同服务器数据库操作
https://www.cnblogs.com/lusunqing/p/3660190.html --创建远程链接服务器 execute sys.sp_addlinkedserver @server= ...
- CentOS下 .Net Core 1.0 升级到 3.0 遇到的一个小问题
之前.net core 1.0的安装方式,不是用yum方式安装的,所以,在用yum安装3.0之后,用dotnet --version还是1.0的版本,想起了之前 做过链接映射dotnet目录,删除之前 ...
- Linux命令(1)grep
开发过程中,与测试运维中 逐渐学习 运维常用的Linux 命令: 转自https://www.cnblogs.com/peida/archive/2012/12/17/2821195.html Lin ...