Hadoop单机模式/伪分布式模式/完全分布式模式
一、Hadoop的三种运行模式(启动模式)
一.单机(非分布式)模式
这种模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统。
- 默认情况下,Hadoop即处于该模式,用于开发和调式。
- 不对配置文件进行修改。
- 使用本地文件系统,而不是分布式文件系统。
- Hadoop不会启动NameNode、DataNode、JobTracker、TaskTracker等守护进程,Map()和Reduce()任务作为同一个进程的不同部分来执行的。
- 用于对MapReduce程序的逻辑进行调试,确保程序的正确。
二.伪分布式运行模式
请注意分布式运行中的这几个结点的区别:
- 从分布式存储的角度来说,集群中的结点由一个NameNode和若干个DataNode组成,另有一个SecondaryNameNode作为NameNode的备份。
- 从分布式应用的角度来说,集群中的结点由一个JobTracker和若干个TaskTracker组成,JobTracker负责任务的调度,TaskTracker负责并行执行任务。TaskTracker必须运行在DataNode上,这样便于数据的本地计算。JobTracker和NameNode则无须在同一台机器上。一个机器上,既当namenode,又当datanode,或者说既 是jobtracker,又是tasktracker。没有所谓的在多台机器上进行真正的分布式计算,故称为"伪分布式"。、
- Hadoop的守护进程运行在本机机器,模拟一个小规模的集群。
- 在一台主机模拟多主机。
- Hadoop启动NameNode、DataNode、JobTracker、TaskTracker这些守护进程都在同一台机器上运行,是相互独立的Java进程。
- 在这种模式下,Hadoop使用的是分布式文件系统,各个作业也是由JobTraker服务,来管理的独立进程。在单机模式之上增加了代码调试功能,允许检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。类似于完全分布式模式,因此,这种模式常用来开发测试Hadoop程序的执行是否正确。
- 修改3个配置文件:core-site.xml(Hadoop集群的特性,作用于全部进程及客户端)、hdfs-site.xml(配置HDFS集群的工作属性)、mapred-site.xml(配置MapReduce集群的属性)
- 格式化文件系统
三.完全分布式模式
真正的分布式,由3个及以上的实体机或者虚拟机组件的机群。
- Hadoop的守护进程运行在一个集群上。
- Hadoop的守护进程运行在由多台主机搭建的集群上,是真正的生产环境。
- 在所有的主机上安装JDK和Hadoop,组成相互连通的网络。
- 在主机间设置SSH免密码登录,把各从节点生成的公钥添加到主节点的信任列表。
- 修改3个配置文件:core-site.xml、hdfs-site.xml、mapred-site.xml,指定NameNode和JobTraker的位置和端口,设置文件的副本等参数。
- 格式化文件系统
二、搭建Hadoop伪分布式集群
一.安装JDK,并配置环境变量
JAVA_HOME = C:\ProgramData\Java\jdk1.8.0_211
Path = %JAVA_HOME%\bin
二.安装hadoop
1)解压hadoop安装包
2)添加Hadoop环境变量(HADOOP_HOME、Path)
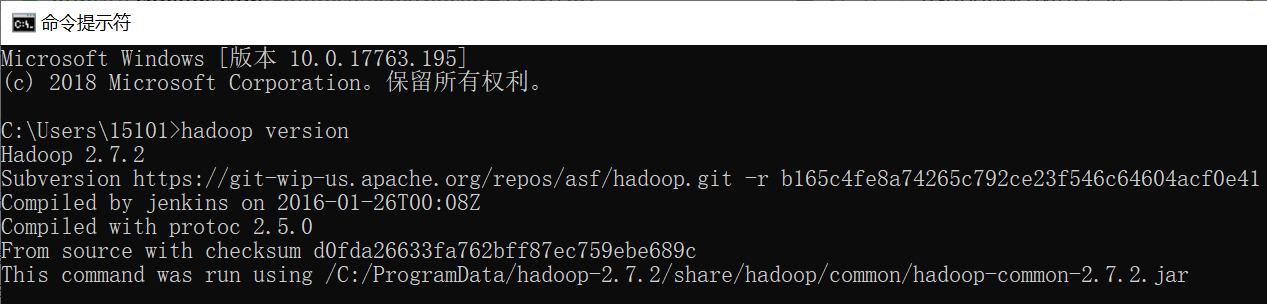
3)使用hadoop version命令测试是否配置成功
三.配置hadoop
1)在Hadoop安装路径(C:\ProgramData\hadoop-2.7.2\)下创建workplace目录,创建temp、nodename和datanode目录,用来保存数据
2)修改C:\ProgramData\hadoop-2.7.2\etc\hadoop下5个配置文件
- hadoop-env.sh
export JAVA_HOME=${JAVA_HOME}
改为:
export JAVA_HOME=C:\ProgramData\Java\jdk1..0_211
- core-site.xml(localhost为主节点所在主机的ip,而9000为端口)
<property>
<name>hadoop.tmp.dir</name>
<value>C:\ProgramData\hadoop-2.7.\workplace\temp</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>C:\ProgramData\hadoop-2.7.\workplace\namenode</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
- hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.data.dir</name>
<value>C:\ProgramData\hadoop-2.7.\workplace\datanode</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>C:\ProgramData\hadoop-2.7.\workplace\namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>C:\ProgramData\hadoop-2.7.\workplace\datanode</value>
</property>
</configuration>
- mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9001</value>
</property>
</configuration>
- yarn-site.xml
<configuration>
<!-- 指定reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value></value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value></value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value></value>
</property>
</configuration>
3)启动Hadoop集群
1、格式化Hdfs
cd C:\ProgramData\hadoop-2.7.\bin
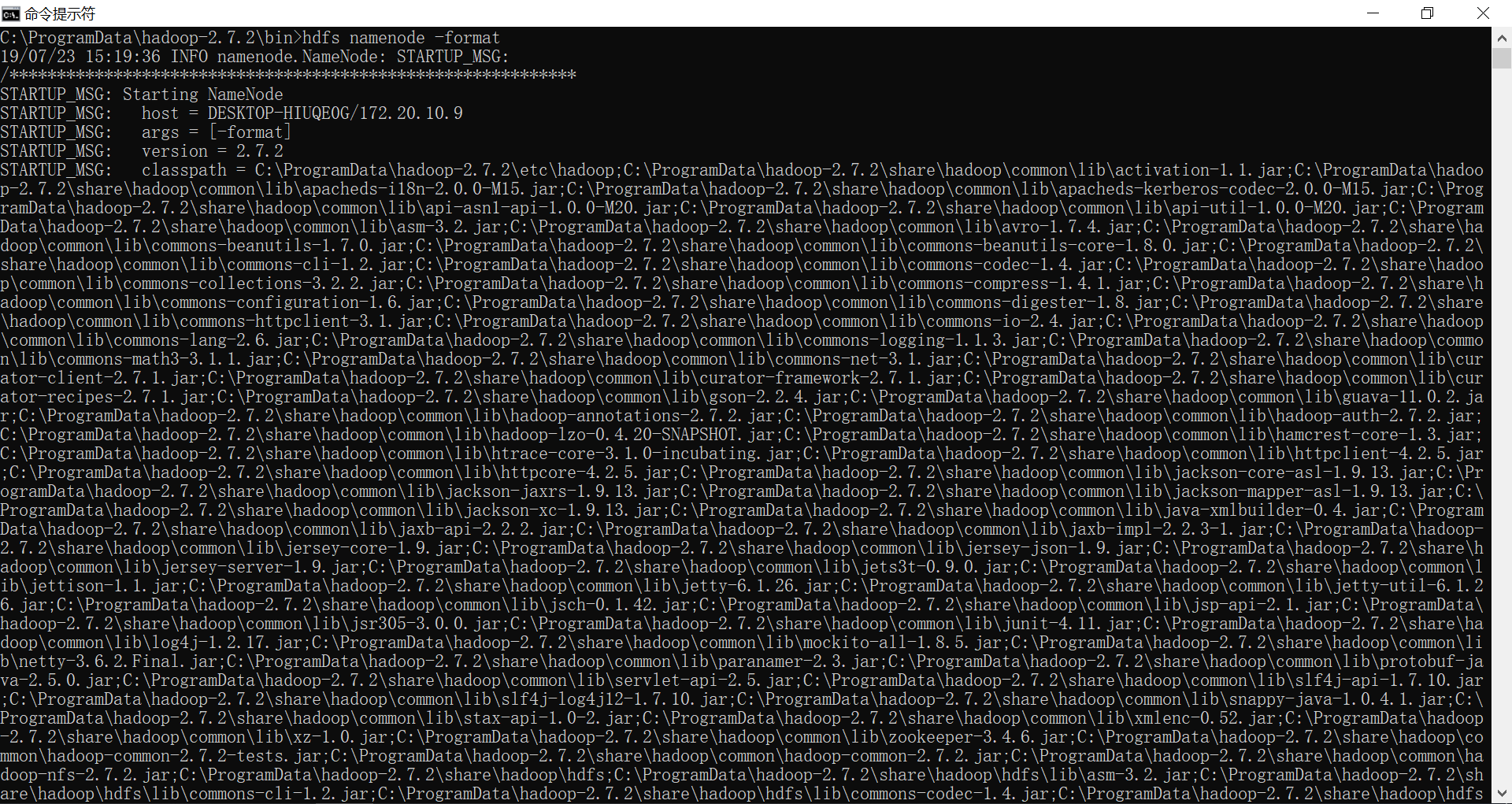
C:\ProgramData\hadoop-2.7.\bin>hdfs namenode -format(hadoop namenode -format)
2、进入Hadoop sbin目录,启动start-all.cmd(结束命令stop-all.cmd),输入jps查看java进程
cd C:\ProgramData\hadoop-2.7.\sbin
C:\ProgramData\hadoop-2.7.2\sbin>start-all.cmd
C:\ProgramData\hadoop-2.7.2\sbin>jps
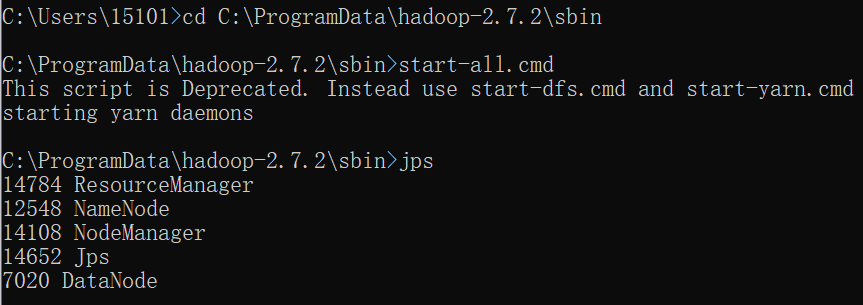
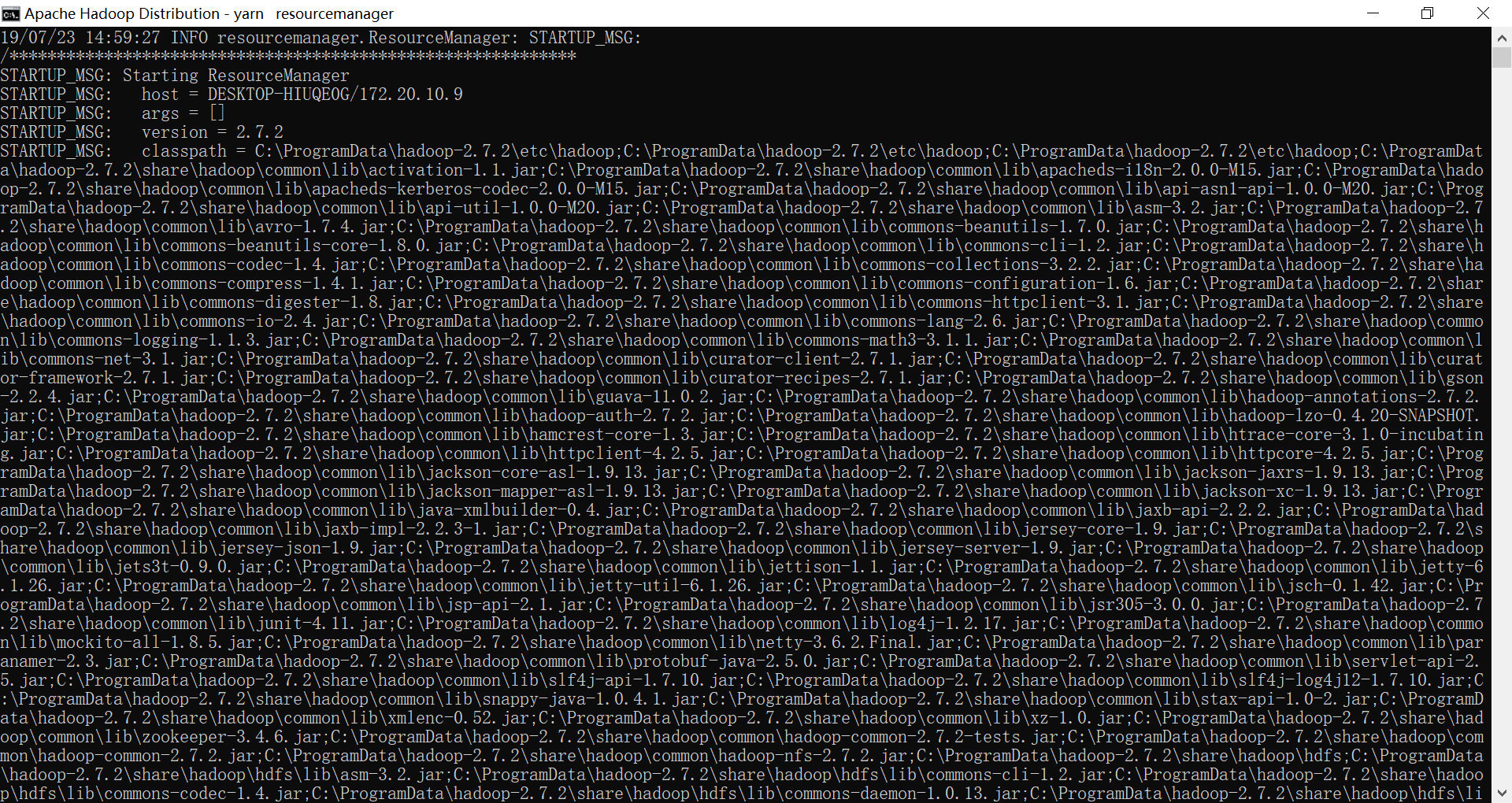
同时,会跳出4个窗口



问题:Diagnostics: Failed to setup local dir C:\ProgramData\hadoop-2.7.\workplace\temp\nm-local-dir, which was marked as good.
解决:文件权限问题,用管理员模式运行cmd即可解决
3、WEB UI浏览
HDFS和YARN ResourceManager各自提供了Web接口,通过这些接口可查看HDFS集群和YARN集群的状态信息
- Web方式查看Mapreduce Job http://localhost:8088

Web方式查看文件系统 http://localhost:50070/


四、测试Hadoop集群
1)测试文件上传下载功能
cd C:\ProgramData\hadoop-2.7.\bin
# 创建目录Demo
C:\ProgramData\hadoop-2.7.\bin>hdfs dfs -mkdir /Demo
# 查看创建情况
C:\ProgramData\hadoop-2.7.\bin>hdfs dfs -ls /

# 上传文件
C:\ProgramData\hadoop-2.7.\bin>hdfs dfs -put C:\Projects\HelloWorld\HelloWorld.py /Demo
# 查看
C:\ProgramData\hadoop-2.7.\bin>hdfs dfs -ls /Demo

# 下载文件
C:\ProgramData\hadoop-2.7.2\bin>hdfs dfs -get /Demo/HelloWorld.py C:\Projects

2)Yarn集群的操作-提交任务/作业-计算PI值(自带)
yarn jar C:\ProgramData\hadoop-2.7.\share\hadoop\mapreduce\hadoop-mapreduce-examples-2.7..jar pi
问题: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.SafeModeException): Cannot create directory /user//QuasiMonteCarlo_1563868759312_1960410989/in. Name node is in safe mode.
解决:没有关闭安全模式,直接强制离开安全模式即可
hdfs dfsadmin -safemode leave



3)Hadoop集群的操作-提交任务/作业-Wordcount(自带)
1、创建word.txt

2、上传word.txt到Hdfs
hadoop fs -put C:\Projects\WordCount\word.txt /Demo/word.txt
3、进到mapreduce,运行wordcount
hadoop jar C:\ProgramData\hadoop-2.7.\share\hadoop\mapreduce\hadoop-mapreduce-examples-2.7..jar wordcount \Demo \output
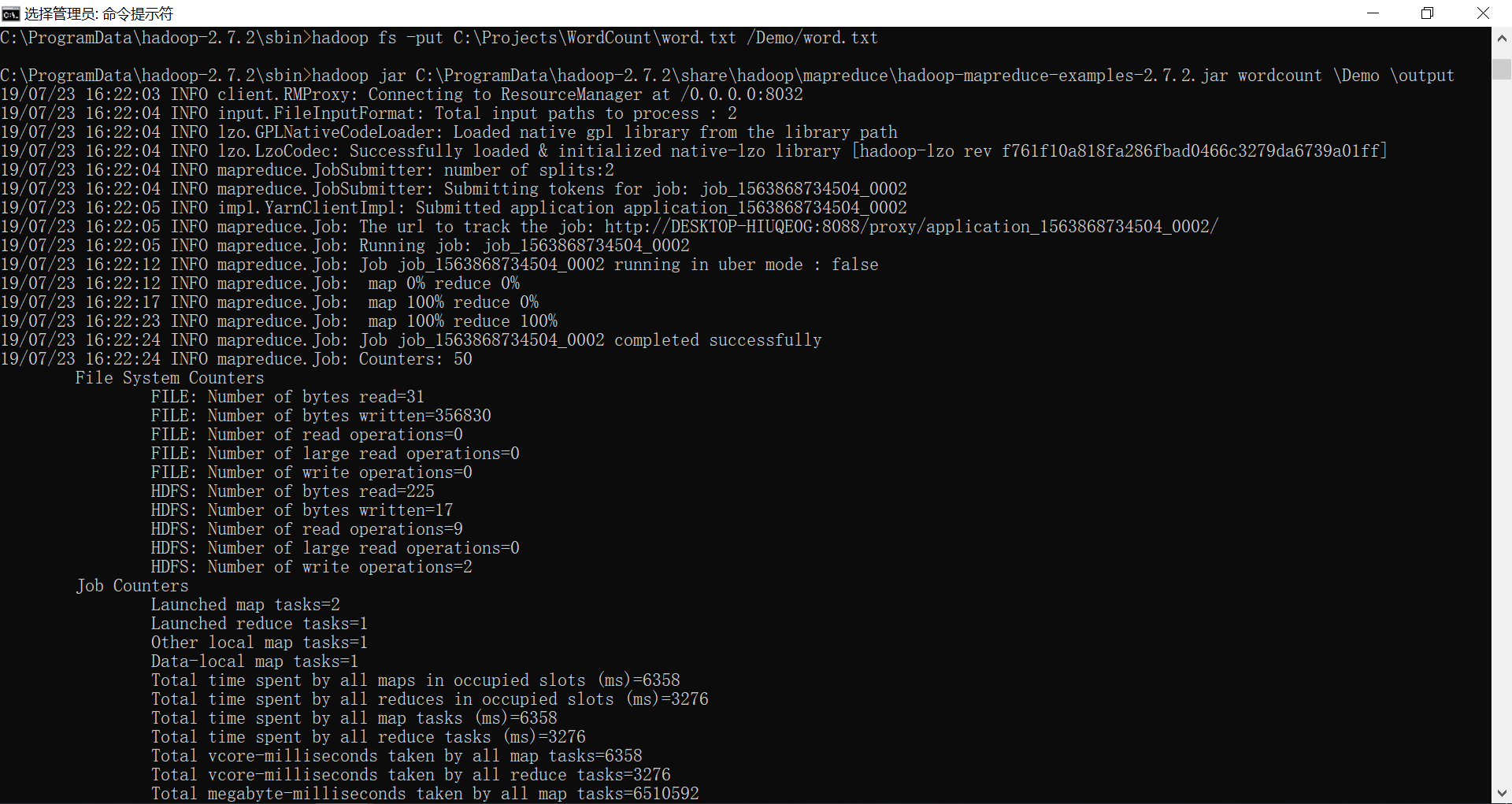
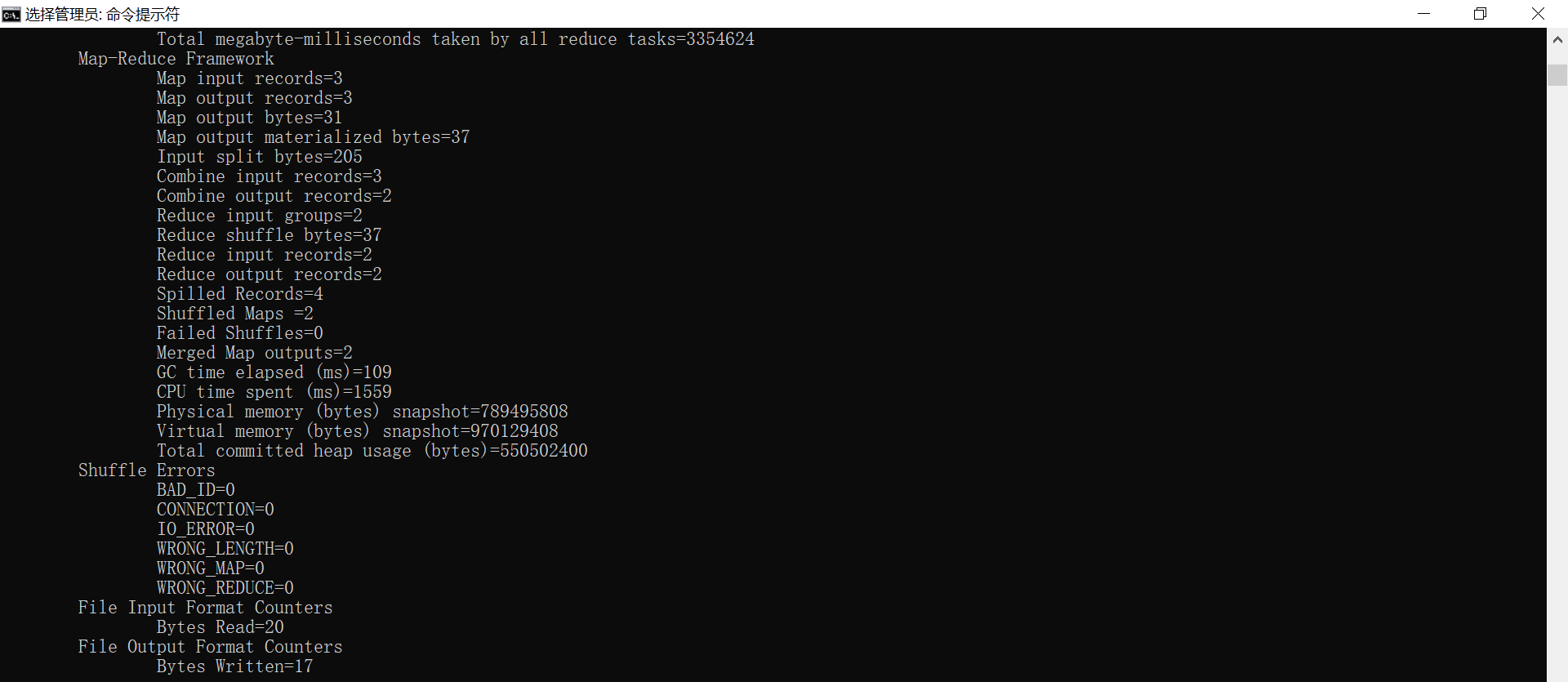
4、查看词频统计结果
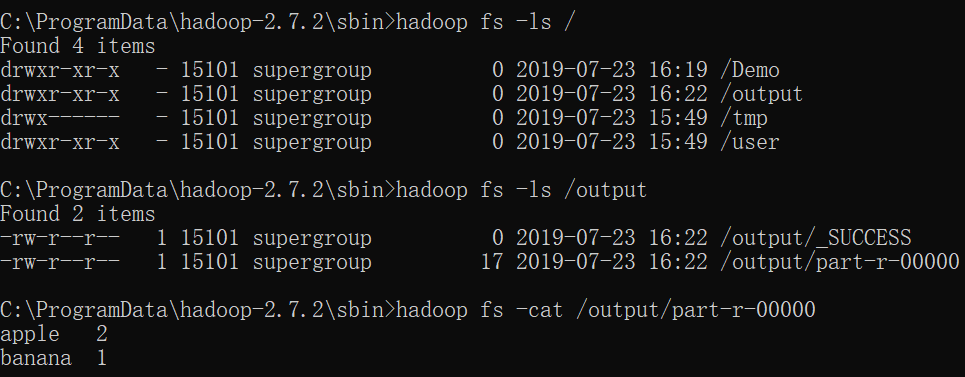
# 查看整个文件目录
hadoop fs -ls /
# 查看Demo目录下结构
hadoop fs -ls /output
# 查看output内容
hadoop fs -cat /output/part-r-00000

4)Browsing HDFS(http://localhost:50070/explorer.html# --> Utilities --> Browse the file system)

可以下载分布式文件系统上的word.txt

Hadoop单机模式/伪分布式模式/完全分布式模式的更多相关文章
- Hadoop单机和伪分布式安装
本教程为单机版+伪分布式的Hadoop,安装过程写的有些简单,只作为笔记方便自己研究Hadoop用. 环境 操作系统 Centos 6.5_64bit 本机名称 hadoop001 本机IP ...
- Hadoop单机、伪分布式、分布式集群搭建
JDK安装 设置hostname [root@bigdata111 ~]# vi /etc/hostname 设置机器hosts [root@bigdata111 ~]# vi /etc/hosts ...
- Hadoop三种安装模式:单机模式,伪分布式,真正分布式
Hadoop三种安装模式:单机模式,伪分布式,真正分布式 一 单机模式standalone单 机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守 ...
- hadoop 单机模式 伪分布式 完全分布式区别
1.单机(非分布式)模式 这种模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统,一般仅用于本地MR程序的调试 2.伪分布式运行模式 这种模式也是在一台单机上运行,但用不同的 ...
- 2.hadoop基本配置,本地模式,伪分布式搭建
2. Hadoop三种集群方式 1. 三种集群方式 本地模式 hdfs dfs -ls / 不需要启动任何进程 伪分布式 所有进程跑在一个机器上 完全分布式 每个机器运行不同的进程 2. 服务器基本配 ...
- 云计算课程实验之安装Hadoop及配置伪分布式模式的Hadoop
一.实验目的 1. 掌握Linux虚拟机的安装方法. 2. 掌握Hadoop的伪分布式安装方法. 二.实验内容 (一)Linux基本操作命令 Linux常用基本命令包括: ls,cd,mkdir,rm ...
- Ubuntu 14.04 (32位)上搭建Hadoop 2.5.1单机和伪分布式环境
引言 一直用的Ubuntu 32位系统(准备下次用Fedora,Ubuntu越来越不适合学习了),今天准备学习一下Hadoop,结果下载Apache官网上发布的最新的封装好的2.5.1版,配置完了根本 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
首先要了解一下Hadoop的运行模式: 单机模式(standalone) 单机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选 ...
- Hadoop:Hadoop单机伪分布式的安装和配置
http://blog.csdn.net/pipisorry/article/details/51623195 因为lz的linux系统已经安装好了很多开发环境,可能下面的步骤有遗漏. 之前是在doc ...
随机推荐
- IDEA的小技巧:1.Java代码不被识别2.目录下创建的文件夹所显示样式不是文件夹,而是"包"图标样式的问题
在Idea上面一个正常的代码结构是这个样子的,但是有的时候,比如说当我们直接在一个文件夹中随便的创建的时候就会出现一些问题,比如说想让某个地方为代码目录,某个地方为资源目录的时候,直接的创建目录是不成 ...
- TCP输出 之 tcp_write_xmit
概述 tcp_write_xmit函数完成对待发送数据的分段发送,过程中会遍历发送队列,进行窗口检查,需要TSO分段则分段,然后调用tcp_transmit_skb发送数据段: 源码分析 static ...
- rtmp 协议详解
1. handshake 1.1 概述 rtmp 连接从握手开始.它包含三个固定大小的块.客户端发送的三个块命名为 C0,C1,C2:服务端发送的三个块命名为 S0,S1,S2. 握手序列: 客户端通 ...
- js监听某个元素高度变化来改变父级iframe的高度
最近需要做一个iframe调用其他页面内容,这个iframe地址是可变化的,但是里面的内容高度不确定且里面内容高度可调整,所以需要通过监听iframe里面body的高度变化来调整iframe的高度. ...
- Fastadmin 后台表单,外键关键,步骤
1.在 public\assets\js\backend 目录中找到对应的js,修改 2.对应控制器中加上index()方法:开启关联查询 重点: protected $relationSearch ...
- dnSpy PE format ( Portable Executable File Format)
Portable Executable File Format PE Format 微软官方的 What is a .PE file in the .NET framework? [closed] ...
- Java-GC 垃圾收集器(HotSpot)
垃圾收集器为垃圾收集算法的具体实现,是执行垃圾收集算法的,是守护线程. HotSpot 虚拟机采用分代收集(JVM 规范并未对堆区进行划分),将堆分为年轻代和老年代,垃圾收集器也按照这样区分.不过已有 ...
- LeetCode 分类颜色
LeetCode 分类颜色 给定一个包含红色.白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色.白色.蓝色顺序排列. 此题中,我们使用整数 0. 1 和 ...
- springboot非web项目
使用CommandRunner @SpringBootApplication public class CrmApplication implements ApplicationRunner { @A ...
- 离线安装nuget包EPPlus
1先去https://www.nuget.org/packages/EPPlus/4.1.0下载,epplus.4.1.0.nupkg 2找到本地文件位置:H:\DOWNLOAD\ 3在vs的程序包管 ...