java web 开发三剑客 -------电子书
Internet,人们通常称为因特网,是当今世界上覆盖面最大和应用最广泛的网络。根据英语构词法,Internet是Inter + net,Inter-作为前缀在英语中表示“在一起,交互”,由此可知Internet的目的是让各个net交互。所以,Internet实质上是将世界上各个国家、各个网络运营商的多个网络相互连接构成的一个全球范围内的统一网,使各个网络之间能够相互到达。各个国家和运营商构建网络采用的底层技术和实现可能各不相同,但只要采用统一的上层协议(TCP/IP)就可以通过Internet相互通信。
为了使各个网络中的主机能够相互访问,Internet为每个主机分配一个地址,称为IP地址,IPv4①的IP地址是32位二进制数字,通常人们用4个0~255的数字表示,例如:127.0.0.1,称为“点分十进制”表示法。图1.1是Internet物理结构的示意图。
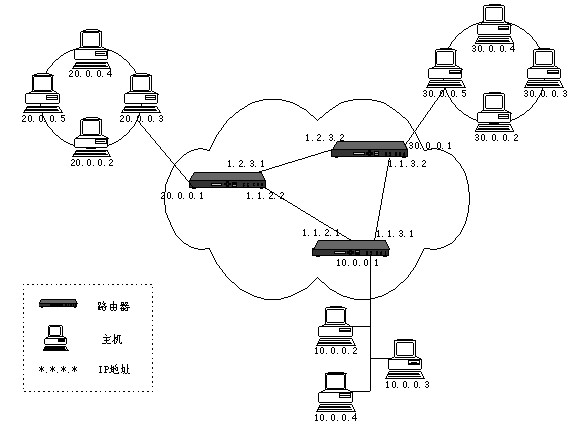
图1.1 Internet物理结构示意图
Internet物理结构如图1.1所示,它将若干个子网通过路由器连接起来,这些子网可以具有不同类型的网络结构,但子网中的每个主机必须拥有全局唯一的IP地址;路由器是用于转发子网之间数据的设备,路由器上有若干个端口,每个端口拥有一个IP地址,一个端口可以连接一个子网。Internet上的数据可以从一个主机发送到另外一个主机,数据以数据包的形式传送;源主机在发送数据包时会在数据包前面加上目的主机的IP地址,路由器通过识别IP地址将数据包发送到适当的子网中;当数据在子网中传播时,拥有该IP地址的主机就会接收该数据包。很多计算机网络教材都使用邮政寄信的例子形象地说明了这个Internet中数据包的传送过程。
Internet底层的组织和传输原理是很复杂的,感兴趣的读者可以选择相关的计算机网络教材进行深入学习。但作为开发Web应用的软件工程师,通常只是从Internet的应用层面考虑Internet的原理;从应用层面的角度考虑,可以认为Internet是连接所有主机的一个庞大的网络体系,每个主机拥有一个IP地址,主机之间通过IP地址相互传递信息和数据。Web应用实质上是一种特殊的应用,它可以在Internet的主机之间相互交流具有预定义格式的信息和数据。
典型的Web应用是B/S模式(浏览器/服务器模式),即Internet上的两台主机,一台充当服务器,另一台充当客户机,客户机通过本机的浏览器与服务器进行通信,如图1.2所示。
在图1.2中,客户机向服务器发出请求,服务器接收并处理请求,然后将对该请求的响应传送给客户机。以访问希赛网主页为例,读者在浏览器中键入希赛网的主页地址“www.csai.cn”,回车后浏览器就会向希赛网的服务器发送一个请求并且将自己的IP地址连同请求一块发送,该请求要求浏览希赛网的主页,希赛网的服务器接收到该请求并且取出客户机的IP地址,然后将希赛网的主页作为数据包发出,并且以客户机的IP地址作为目的地址。当数据包传送到客户机后,读者的浏览器就可以显示希赛网的主页了。
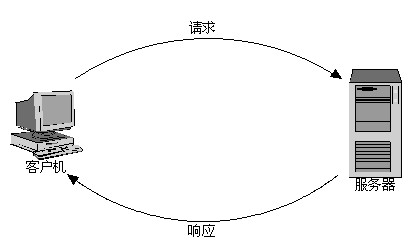
图1.2 B/S模式示意图
通常Web应用是运行在服务器中的一个应用程序,在上例中希赛网Web服务器中处理客户机响应的程序就是一个典型的Web应用;接收请求、分析请求、构造响应、发送响应都是由该Web应用完成的,这几项工作也是大多数Web应用的主要工作。所谓接收请求就是监听服务器的特定端口,当有请求到达端口时就读取该请求,这通常都是由Web容器(例如Tomcat)完成的;所谓分析请求就是解析收到的请求,从中获得请求的内容;所谓构造响应就是根据客户的请求,在进行适当的动作后,构造适当的响应数据;所谓发送响应就是将构造好的响应数据发送给客户机,这通常也是由Web容器自动完成的。所以,Web应用的核心就是如何分析请求、完成相应动作并构造响应。而这其中的分析请求和构造响应都是与Internet的一种传输协议——HTTP——紧密相关的,因为它规定了Web应用中的数据在网络中的传输方式和传输格式。
① IPv4是IP的第4版,很长时间以来该IP版本一直是Internet中使用的标准版本,但随着Internet的发展和扩大,IPv4开始展现出一些弊端,所以开始出现IPv6,并将替代IPv4。IPv6的IP地址是128位二进制数字。
HTTP的全称是HyperText Transfer Protocal,即超文本传输协议。它是Internet的应用层协议,它定义了客户机的浏览器与服务器的Web应用之间如何进行通信,以及通信时用于传递数据的数据包的格式等内容。目前使用的HTTP是HTTP1.1版。
HTTP是采用请求/响应模式的无状态协议。客户机浏览器和服务器Web应用采用HTTP协议进行通信时,通信由浏览器发起;浏览器向Web应用发送一个请求,Web应用接收并处理该请求,然后向浏览器发回响应。在请求/响应过程中,Web应用不保存与任何一个客户机通信的状态,它只对到来的当前请求进行处理,处理完返回对应于该请求的响应;任何两个请求的处理都是独立的,无论这两个请求是来自同一个客户机还是不同的客户机。
图1.3为Web服务器同时响应多个客户机浏览器请求的示意图。当同时有多个客户机向同一个Web应用发出请求时,Web服务器就为每一个请求创建一个服务进程/线程用以处理这一请求;即使是同一个客户机发送的两个请求,Web服务器也会创建两个服务进程/线程用于处理两个请求。
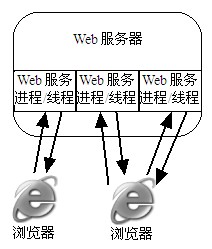
图1.3 Web服务器与客户浏览器交互示意图
通过以上对HTTP通信方式的介绍可以发现,HTTP请求和HTTP响应在HTTP通信中起到了至关重要的作用,因为浏览器和Web应用之间的所有通信都是依靠请求和响应完成的。一个典型的HTTP请求消息的内容如下:
GET / HTTP/1.1
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/x-shockwave-flash, application/vnd. ms-excel, application/vnd.ms-powerpoint, application/msword, */*
Accept-Language: zh-cn
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)
Host: www.csai.cn
…
该消息用于请求http://www.csai.cn的主页。对请求的响应消息如下(HTML页面内容部分用“…”省略):
HTTP/1.1 200 OK
Server: Microsoft-IIS/5.0
Content-Location: http://www.csai.cn/index.htm
Date: Mon, 24 Dec 2007 08:31:08 GMT
Content-Type: text/html
Accept-Ranges: bytes
Last-Modified: Mon, 24 Dec 2007 02:48:20 GMT
Content-Length: 60744
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/ xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" lang="zh-CN">
<head>
<title>希赛网_中国IT技术门户_为企业和IT技术人员提供最全面的服务平台</title>
…
</body>
</html>
这一对请求/响应消息是使用IE浏览器访问希赛主页时产生的HTTP消息流。在IE的地址栏中键入希赛网主页的地址http://www.csai.cn,单击回车后,IE浏览器便会将这一段请求消息以文本的形式发送出去,经过网络传递到希赛网的Web服务器上,Web服务器经过分析发现该客户端请求的是希赛网的主页,于是将希赛网的主页放在响应消息中发送回客户机的浏览器。下面对HTTP请求和响应消息分别进行详细介绍。
HTTP请求消息由Request-Line(请求行)、Header Field(头域)和Message-Body(消息体)组成,如图1.4所示。

图1.4 HTTP请求消息格式
Request-Line在HTTP请求消息的第一行,一般格式是:
Request-Line = Method[SP]Request-URI[SP]HTTP-Version CRLF
其中Method称为HTTP方法(HTTP Method),它表示该请求所要进行的操作类型;Request-URI称为请求URI,它表示与该请求有关的Web服务器中的资源定位符;HTTP-Version表示该请求使用的HTTP协议的版本号,一般是HTTP/1.0或HTTP/1.1,目前使用的HTTP版本大部分都是HTTP/1.1。[SP]表示空格,CRLF表示回车换行,它们都是格式信息,用于分隔各部分信息。例如:
GET /index.htm HTTP/1.1
就是一个典型的Request-Line,其中GET是HTTP方法、/index.htm是Request-URI、HTTP/1.1是HTTP版本号。
头域紧跟在Request-Line的后面,每个域一行,本节后面部分将会详细介绍头域。消息体在头域后面,与头域隔一个空行,不过并不是所有HTTP请求消息都有消息体,有些就没有消息体,这是由该HTTP请求消息的HTTP方法类型决定的。
1.HTTP方法
HTTP请求消息通过使用不同的HTTP方法来向接收到请求的主机说明其请求所期望执行的操作。HTTP/1.1总共定义了OPTIONS、GET、HEAD、POST、PUT、DELETE、TRACE和CONNECT八种HTTP方法,其中GET方法和POST方法是最常见的也是使用最多的HTTP方法,其他方法使用得很少,甚至有些方法在很多服务器中都会被屏蔽或者忽略,所以本书将只重点针对GET方法和POST方法进行详细介绍。
平时读者在上网浏览网页时基本上都是用GET方法,GET方法向服务器申请请求URI指定的资源。请求URI可能指向的是一个服务器Web路径下的一个文件,接收到请求后Web服务器会将该文件的内容作为HTTP响应的内容返回给浏览器;请求URI也可能指向一个数据处理过程(比如一个Servlet),那么Web服务器会执行该过程并将该过程执行结束后向客户端反馈的结果信息加入到HTTP响应中返回。可见在使用GET方法进行的请求响应过程中,数据流向主要是从服务器向客户机,所以GET请求消息的消息体通常不包含任何内容。一般在如下场景会使用GET方法:
在浏览器中键入网页地址,从Web服务器上获取网页中的所有内容,例如HTML、图片、Flash、JavaScript等。请求每一项内容时都会将一个GET请求提交给服务器,然后服务器会处理每一个请求并将请求的内容作为响应返回给浏览器。
单击网页上的一个图片链接打开一个图片。浏览器会将图片的URI构造成一个请求消息,并将请求消息提交给服务器,服务器接收到请求消息,解析请求URI,然后将URI指向的图片返回给浏览器。
POST方法则恰好与GET方法相反,POST方法主要用于向服务器提交数据内容;所以一般来说,POST消息的消息体中会包含提交的数据内容。POST消息中请求URI也可以是一个文件位置或者数据处理过程,假如指向的是一个文件位置,那么Web服务器会将POST消息体中携带的数据作为一个文件保存在指定的位置;如果指向的是一个数据处理过程,那么Web服务器会将POST消息体中携带的数据传递给该数据处理过程,并启动该数据处理过程对数据进行处理。通常POST方法会被使用到如下场景:
提交登录信息。当输入完用户名和密码、单击登录按钮时,浏览器就会将登录信息(用户名和密码,为了安全起见,很多系统会对密码加密)作为POST消息的消息体提交给Web服务器。
在论坛中发帖子。帖子的标题和内容会作为POST消息的消息体提交给Web服务器。
发送E-mail。E-mail的各项信息(发件人、收件人、抄送、密送、标题、正文等)会组织成一定的格式,然后作为POST消息的消息体提交给Web服务器。
2.Request-URI
Request-URI称为请求URI,它是一个不含空白字符的字符串,符合URI(资源定位符)的格式规范,表示Web服务器上的一个资源位置,可以是以下四种格式:
Request-URI = "*" | absoluteURI | abs_path | authority
* 表示该Request-URI并不指向某个特定的位置,说明该HTTP请求消息所请求的操作是针对整个Web服务器、而不是针对某个特定资源的。当然并不是所有的HTTP方法都能够使用 * 作为Request-URI,只有某些特定的HTTP方法才可以,比如OPTIONS。
absoluteURI是一个用绝对形式表示的URI,即以协议开头的URI,比如:“http://www.csai.cn/image/bg.png”,这种表示形式单独就能指定一个唯一的网络资源位置。
abs_path是一个用相对形式表示的URI,但它必须是一个Web服务器上的绝对路径,必须以一个 / 开头,例如:/image/bg.png。这种表示形式指定了一个从Web服务器根目录开始的相对路径。Web服务器根目录是服务器设置的所有Web资源的顶层目录。假设,域名为“csai.cn”的Web服务器设置的根目录是“D:\webroot”,那么URL“http://www.csai.cn/index.htm”就是请求Web服务器上的文件“D:\webroot\index.htm”。可见,使用abs_path的Request-URI只是指定了Web服务器内部的路径,并没有指定Web服务器的主机地址,所以它不能单独用于指定一个网络位置。用这种Request-URI的HTTP请求消息都会有一个名为Host的头域,它的值就用于指定一个主机的地址,比如:Host头域值为“www.csai.cn”,Request-URI为“/image/bg.png”的HTTP请求消息所指定资源位置也是“http://www.csai.cn/image/bg.png”。
authority仅能被用于CONNECT方法。
HTTP响应消息是Web服务器在处理完HTTP请求消息后返回给客户机浏览器的消息,它也由状态行、头域和消息体组成,如图1.5所示:

图1.5 HTTP响应消息格式
状态行的一般格式如下:
Status-Line = HTTP-Version[SP]Status-Code[SP]Reason-Phrase CRLF
其中,HTTP-Version、SP和CRLF的意义与请求消息中的一样。Status-Code是响应状态码,它是3位十进制数,HTTP/1.1预定义了很多状态码,用于表示服务器处理请求的状态;Reason-Phrase是一个简短的文字,它对响应码进行文字性说明。Status-Code根据首位数字的不同可分为如下五大类:
1.1xx:信息响应类,表示接收到请求并且继续处理。例如“100 Continue”表示服务器已接收并开始处理请求,要求客户机继续发送请求的剩余部分,如果请求已被发送完全,客户机可以忽略该消息。
2.2xx:处理成功响应类,表示动作被成功接收、理解和接受。例如“200 OK”表示请求的操作已成功完成,对于GET请求则表示请求的资源已附在响应消息中,对于POST请求则表示提交的内容已被处理。
3.3xx:重定向响应类,为了完成指定的动作,必须接受进一步处理。例如“301 Moved Permanently”表示请求的资源已被永久移往另外一个URI,往后对该资源的请求应该都替换成新的URI,新的URI将由响应消息的Location头域说明;“302 Found”表示请求应该暂时被重定向为另外一个URI,以后对该资源的请求应该还是使用当前的URI。
4.4xx:客户端错误类,客户请求包含语法错误或者是不能被正确执行。例如“400 Bad Request”表示客户端提交的请求无法被服务器理解,客户端需要对请求重新改动后再提交请求;“403 Forbidden”表示服务器已理解客户端的请求,但是服务器拒绝执行客户端请求的操作;“404 Not Found”表示客户端请求中Request-URI指定的资源位置不存在。
5.5xx:服务端错误类,服务器不能正确执行一个正确的请求。例如“500 Internal Server Error”表示服务器遭遇一个非预期错误而导致无法完成请求的操作。
如前面所述,在HTTP请求消息和响应消息中都包含Header Field,这些头域用于说明一些辅助信息,以便于丰富客户机和服务器之间的通信。有些头域用于说明一些通用信息,称为General Header Field(通用头域),即可以用于请求消息也可以用于响应消息;有些头域只被用于请求消息,称为Request Header Field(请求头域);有些头域只被用于响应消息,称为Response Header Field(响应头域);有些头域用于说明传输内容的信息,它们可以被用于请求消息也可以被用于响应消息。整个头域由多条头域项组成,每条头域项占一行。头域项的一般格式为:
Field-Name: Field -Value
其中Field -Name是头域名,Field -Value是头域值。
1.General Header Field
这类头域既可以出现在请求消息中也可以出现在响应消息中,它们只描述了传递消息的一些属性,而不能用于描述传送文件的信息。常见的有如下几种。
Cache-Control:用于指定一种缓冲机制,这种缓冲机制在整个请求/响应过程中必须被遵守。该头域中指定的缓冲机制将覆盖默认的缓冲机制。例如:
Cache-Control: no-cache
Date:表示消息生成时的日期时间,该域所使用的日期格式必须符合HTTP日期格式,例如:
Date: Tue, 13 Nov 2007 08:12:31 GMT
Pragma:用于指定一些实现相关的参数,在HTTP协议中并没有规定该头域所携带参数的意义,例如:
Pragma: “string”
其中“string”表示一个由引号括起的字符串,各种对HTTP协议的不同实现(例如不同的浏览器和服务器)可以利用该头域定义用于传递特定信息的一系列字符串。
Transfer-Encoding:如果该头域被指定,那就说明消息体采用了所指定的传输类型进行传输。例如最常见的:
Transfer-Encoding: chunked
表示消息体采用分块传输的方式进行传输。
2.Request Header Field
这类头域只出现在请求消息中,它们通常被客户机用于向服务器传递一些客户机的信息或者请求消息的信息。常见的有如下几种。
Accept:可以被用来说明客户机浏览器能够接受的媒体格式,例如:
Accept: text/html, text/plain, image/*
表示客户机浏览器接受HTML和纯文本以及各种图片格式。
Accept-Charset:可以被用来说明客户机浏览器能够接受的字符编码方式,例如:
Accept-Charset: iso-8859-1, gb2312
表示客户机浏览器接受的字符编码格式有ISO—8859—1(也就是ASCII编码)和gb2312(一种简体中文编码)。
Accept-Encoding:可以被用来说明客户机浏览器能够接受的内容编码方法,通常用来指定内容的压缩方法,例如:
Accept-Encoding: gzip, identity
表示客户机浏览器接受gzip压缩方式和不压缩。
Accept-Language:可以被用来说明客户机浏览器能够接受的语言,例如:
Accept-Language: zh-CN
表示客户机浏览器接受简体中文。
From:表示提交该请求的终端用户的电子邮件,例如:
From: user@company.com
表示提交该请求的终端用户的电子邮件地址为user@company.com。
Host:指示Internet上的一个主机和端口号,主机通常是域名或者IP地址,例如:
Host: www.csai.cn
表示该请求访问的主机的域名为www.csai.cn。
If-Match:如果HTTP请求中含有该头域或者后面将要提到的If-ModifiedSince,If-None-Match,If-Range和If-Unmodified-Since头域时,那么该请求就变成了“条件请求”,即只有满足上述描述的条件时请求的操作才要被执行,这样可以减少不必要的资源浪费。该域的值是一个匹配字符串,如果该匹配字符串匹配成功则执行操作,否则不执行操作。在匹配字符串中*表示任意。例如:
If-Match: *
表示匹配任何资源。
If-None-Match:意义与If-Match恰好相反,表示匹配不成功则执行,否则不执行。
If-Modified-Since:值是一个日期,表示请求的资源如果从给定的日期后修改过则执行操作,否则不执行。例如
If-Modified-Since: Tue, 13 Nov 2007 08:12:31 GMT
表示:如果请求的文件在2007-11-13 08:12:31后被更改过,则执行操作。
If-Unmodified-Since:意义与If-Modified-Since恰好相反,表示:请求的资源如果从给定的日期后没有被修改过则执行操作,否则不执行。
If-Range:假如客户机的缓冲池中已有了资源实体的一部分,而期望获得剩余部分,则客户机的请求可以使用该头域。它表示:“如果指定的资源实体没有被更改则将缺少的发给我,否则发给我整个资源实体”。
Max-Forwards:在TRACE和OPTIONS方法中使用,用于限制消息在网络中传播的跳数,即消息被代理或者网关转发的次数,以此来限制消息的生命期。
Range:用于指定一个范围,它表示请求的资源实体的范围,可以使用字节数指定。If-Range需要的范围就是通过该头域指定的。
Referer:客户机用该域告诉服务器,请求中的Request-URI是如何获得的。例如
Referer: http://www.csai.cn/index.htm
表示当前请求资源的URI是从页面http://www.csai.cn/index.htm中获得的。
User-Agent:可以被用来说明客户机浏览器的型号,例如
Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)
表示客户机是使用Mozilla/4.0兼容浏览器、IE6.0等。
3.Response Header Field
这类头域只出现在响应消息中,它们通常被服务器用于向客户机传递一些服务器的信息或者响应消息的信息。常见的有以下几类。
Accept-Ranges:服务器用于指示它所接受的Range类型,比如
Accept-Ranges: bytes
表示服务器接受以byte形式指示的Range。
Accept-Ranges: none
表示服务器不接受任何形式的Range。
Age:顾名思义,在响应消息中该头域表示响应消息的“年龄”,也就是服务器估计的该响应消息产生后的时间长度。
Location:当响应消息的响应码为3xx时,该头域会被响应消息用于指示重定向后新的URL。
Retry-After:通常用于响应码为503的响应消息,503响应消息表示服务器当前不可用,该头域估计了一个服务器不可用的时间。头域值可以是一个HTTP日期或者是一个数字。例如:
Retry-After: Tue, 13 Nov 2007 08:12:31 GMT
表示服务器在2007-11-13 08:12:31之前不可用,请在该时间以后重试。
Retry-After: 120
表示服务器当前不可用,请在120秒后重试。
Server:表示运行在服务器上用于处理请求的软件的信息。
4.Entity Header Field
该类头域描述了消息体中携带的数据的元数据(即对数据的长度、类型、修改时间等属性的描述信息),请求消息和响应消息中都可以包含这类头域。常见的有以下几类。
Allow:表示Request-URI指定的资源实体所支持的HTTP方法列表,在响应码为405的响应消息中必须包含该头域。例如:
Allow: GET, HEAD, PUT
表示Request-URI指定的资源实体仅支持GET、HEAD和PUT三种HTTP方法。
Content-Encoding:指示消息内容的编码方法,通常指示内容的压缩算法。例如:
Content-Encoding: gzip
表示消息中数据采用gzip算法编码。
Content-Language:表示消息内容所采用的自然语言。例如:
Content-Language: en
表示消息体中数据表示的内容是英文的。
Content-Length:表示消息长度。头域值是十进制数,表示字节数。例如:
Content-Length: 2353
表示消息体中数据的长度为2353字节。
Content-Location:表示除了Request-URI指定的位置外,其他可以访问到消息内容的位置。
Content-MD5:表示消息体中数据的MD5校验码,用来实现端到端的消息完整性检查。
Content-Range:当传递的数据是整个资源实体的一部分时,用该域说明当前传递的数据是资源实体的哪一部分。例如:
Content-Range: 0-500/1023
表示资源实体总共范围为0-1023,而当前传递的是0-500。
Content-Type:指示消息体中内容的媒体格式。例如:
Content-Type: text/html; charset=iso-8859-1
表示消息体中携带的内容是HTML文档,它的媒体格式是text大类中的HTML子类,文档的字符编码是ISO—8859—1;
Expires:指定了一个日期,表示消息体中的内容在该日期之前有效,过了该日期则消息内容就过时了。
Last-Modified:表示消息中携带的内容实体的最后修改时间。
HTTP协议规定了如何在客户机浏览器和服务器Web应用之间交换信息和传送数据,但是并没有定义交换数据的格式以及浏览器在获取数据后如何按照数据创建者的意愿有效地显示数据。假如所有交换的数据都只是二进制数的文件,那么HTTP就和文件传输没什么区别了,而且现在的Web也就不会如此绚丽多彩了。正是HTML的出现,才使得Web逐渐发展得像现在这样的丰富多彩。
HTML的全称是HyperText Markup Language,即超文本标记语言。它是一种规范,这个规范定义了一系列标记以及这些标记的结构。浏览器可以将任何符合该规范的文档(通常为HTML或HTML文档)进行解析并且按照HTML文档的结构进行格式化展示。客户机浏览器和Web服务器可以通过互相交换HTML文档实现具有丰富格式信息的数据传送。如下是一个HTML文档的简单框架:
示例1.1
<html>
<head>
<title>这是HTML标题</title>
</head>
<body>
这是HTML内容
</body>
</html>
HTML文档使用一系列标签将文本组织成特定的结构,并且可以通过特定的标签使得文档在浏览器中展示时可以引入丰富的颜色、图片、字体等信息。HTML文档的结构是由标签包含关系标示的一种层次结构,顶层标签是<html>。
读者可以将编写的HTML文档保存到本地硬盘(后缀名为.htm或者.html),然后使用浏览器打开就可以看到HTML展示出来的效果。对于示例1.1中所示的HTML文档,读者可以将其保存为test.htm,然后用浏览器打开该文件,就可以看到如图1.6所示的效果:
HTML文档的内容通过一系列标签进行格式化,如示例1.1所示,<html>、<head>、</head>、</body>等都是HTML标签。HTML标签分为开始标签和结束标签,开始标签由一对尖括号括起来,尖括号中的文字是标签的名称,结束标签与开始标签有相同的名称,并且在左尖括号和标签名称之间加了一个 / ;HTML中的大部分标签都是成对的,例如<html>和</html>、<head>和</head>;一对标签之间可以包含文字也可以包含其他标签。另外,有一种特殊的写法<tag/>,就是将 / 写在右尖括号的前面,这是<tag></tag>的简写形式,它表示<tag>标签中不包含任何内容。
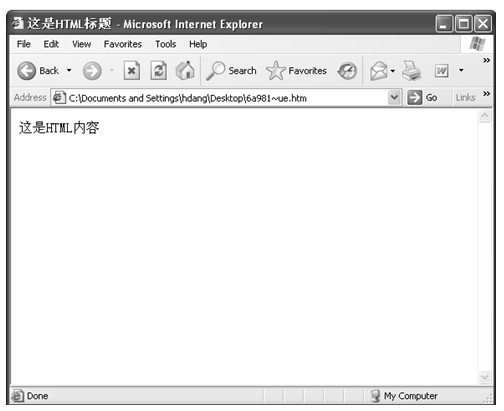
图1.6 test.htm页面效果
HTML标签除了可以组织内容之外,大多数的HTML标签还可以定义一系列的属性用于补充说明标签的一些附加信息,属性都写在开始标签中,例如:
<body bgcolor="red">
...
</body>
表示将该HTML页面的背景色设置为红色。
HTML规范中定义了许多标签以及标签所能够定义的属性,有些标签用于说明一种格式信息,比如<br>、<p>等;有些标签用于说明一定的动作信息,比如<a>等;另一些标签用于插入指定的对象,比如<img>等。下面将对HTML中一些常用的标签及其常用的属性进行介绍。
1.页面标签
示例1.1给出了一个HTML文档的基本结构,其中用<html>、<head>、<title>和<body>规定了文档的整体结构,<head>标签中是头部信息,其中可以定义一些辅助信息,这些信息不会显示在浏览器页面的正文中,例如<title>定义了页面的标题,它显示在浏览器的标题栏上。<body>标签中的内容是HTML文档的主体,需要显示在浏览器页面正文中的内容全部写在该标签中。
<head>中除了可以包含<title>外,还可以包含其他的标签,其中常见的有以下两种。
link:可以用于链接一些其他文档,最常见的是使用该标签链接样式表(Style Sheet),例如:
<link rel="stylesheet" type="text/css" href="theme.css" />
表示链接theme.css,用它定义的样式作为本页的格式。样式表中定义了一系列文档中使用的样式格式,例如文字的颜色、字体、大小,页面的宽度等。
meta:用于定义页面的一些元数据信息,最常见的是使用该标签定义页面的媒体格式和字符编码方式,例如:
<meta http-equiv="Content-Type" content="text/html;charset=iso-8859-1">
表示该页面的类型是text/html,字符编码格式是ISO—8859—1。
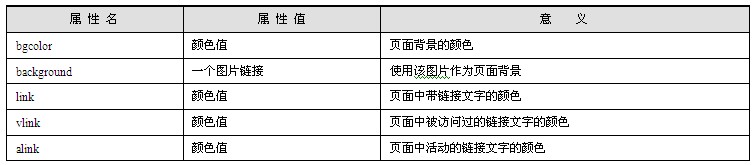
<body>标签的内容包含了html文档所要显示的绝大多数内容,所有需要在浏览器页面正文中显示的内容都必须定义在该标签中;而且,<body>标签的属性也可以用于规定整个页面的展示方式。<body>标签常见的属性如表1.1所示。
表1.1 body标签属性
2.格式标签
在HTML文件中文字的位置、文字之间的回车换行和空格等都不会被最终显示到浏览器上,要控制HTML文档中的文字最终如何在浏览器中布局,需要使用HTML的格式标签。HTML定义了丰富的用于定义格式的标签,例如,<p>、<br>等。
(1)文字的控制
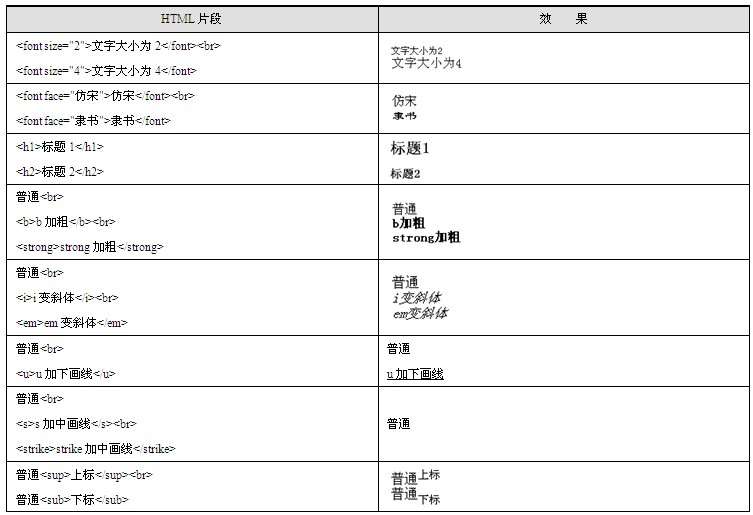
文字有很多属性可以设置,例如大小、颜色、字体、是否加粗、是否斜体等。HTML中提供了一个通用的标签用于设置文字的属性,即<font>,也有一些标签可以方便地设置文字的一种属性,例如<hx>(一系列标签<h1>、<h2>、<h3>、…的总称)可以方便地定义不同大小的文字。
<font>标签是一个用于设置文字字体的通用方法,它通过不同属性来设置文字的不同方面:size属性用于设置文字的大小、face属性用于设置字体、color属性用于设置文字的颜色;
<hx>标签是一组标签的总称,x可以是1、2、3、…它们都表示页面的标题,不同的x表示的标题级别不一样,x越大级别越低,所包含文字的字体也会越小;每个标题占一行。
<b>和<strong>标签表示将文字加粗;
<i>和<em>标签表示将文字变成斜体;
<u>标签表示给文字加下画线;
<s>和<strike>标签都表示给文字加一个中画线;
<sup>标签表示将文字作为上角标;
<sub>标签表示将文字作为下角标。
各种控制文字的标签示例如表1.2所示。
表1.2 各种控制文字的标签示例
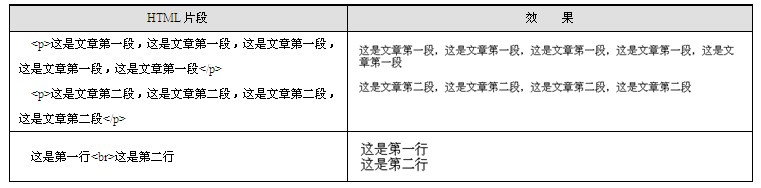
(2)行的控制
<p>表示在该标签中的文字形成一个单独的段落,通常段落与段落之间有一个空行;
<br>表示换行,即该标签之前是一行,该标签之后是另外一行,如表1.3所示
表1.3 控制行的标签示例
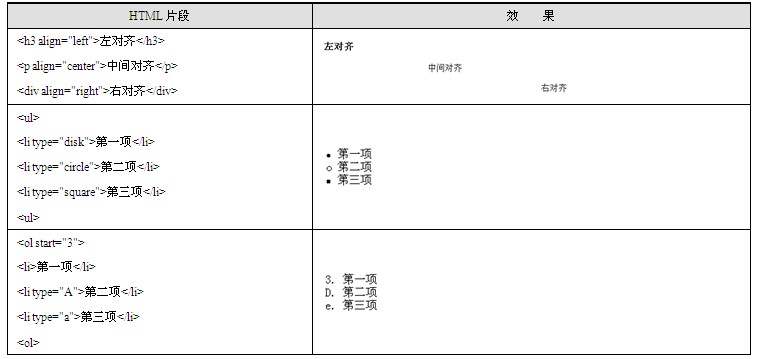
(3)布局的控制
假如只能控制行,那得到的页面将只能像文本文件一样非常枯燥,HTML提供了更多的标签以及标签的属性用于定义丰富的布局格式。
align属性通常用于规定标签内容的对齐方式,<hx>、<p>、<div>标签都有该属性,可以通过将该属性的值指定为center、left或right以用于将内容居中、居左或居右对齐。
列表是一种经常使用的布局方式,HTML的<ul>标签用于定义无序的列表,<ol>标签用于定义有序的列表。<li>表示列表的一项,而且可以通过定义<li>标签的start属性指定有序列表的起始序号,定义<li> 标签的type属性指定序号的形状。
除此之外,HTML还有一个标签<pre>可以定义预格式化的文本,即该标签内的文字将不按HTML规范进行解析,而是将其中的内容原封不动、保持格式显示在浏览器中,如表1.4所示。
表1.4 控制布局的标签示例

3.表格
表格是HTML中使用最多也是最重要的一种技巧,通常大部分网页设计师用表格控制页面内容在整个页面中的分布,并且可以通过使用嵌套的表格将页面进行任意的划分。表格都用顶层标签<table>进行定义,<th>标签用于定义表头,<tr>标签用于定义一行,<td>标签用于定义一行中的一列,如表1.5所示。
表1.5 控制表格的标签示例
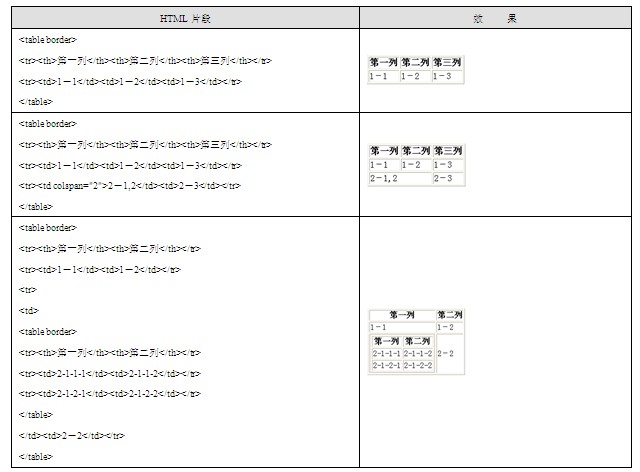
4.表单
表单在HTML中是非常重要的,它提供了一系列可以展现在浏览器中并且能够提供交互的功能组件,例如:文本框、密码框、文本域、按钮等。可以使用表格来组织表单中的组件,如表1.6所示。
表1.6 表单示例


Form标签的action属性指向一个链接,当表单被提交时就会链接到该链接所指向的地址。button类型、reset类型和submit类型的input组件都是按钮,button按钮是普通的按钮,reset按钮可以将表单中的内容清空,submit按钮可以提交表单。
5.其他
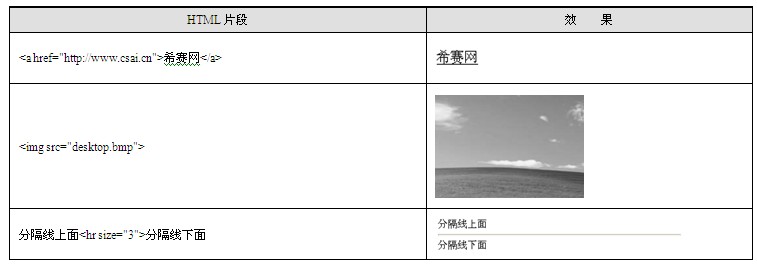
除了以上介绍的这些标签外,HTML还有许多很重要和很常用的标签,例如:
<a>标签主要用于定义一个超链接,其href属性用于指定超链接的地址;
<img>标签用于在网页中以链接的方式加入一个图片,其src属性用于指定待链接图片的位置;
<hr>标签可以在页面上加一个水平的分隔线,如表1.7所示。
表1.7 其他标签示例
HTML有很多的标签,大部分标签也都定义了很多的属性,熟悉掌握它们对于Web应用开发是非常重要的。本章由于篇幅有限只能介绍非常有限的内容,希望读者在学习完本节后自己再收集一些资料自行学习。
读者可能在平时上网、阅读某些Internet方面的资料或者在一些可以开发Web应用的开发语言中已经不止一次地看到过Cookie和Session这两个概念,因为这两个概念在Web中确实起到了举足轻重的作用。正如前面在介绍HTTP协议时提到的,HTTP协议是无状态协议,协议本身不会保存任何对方的状态信息,但是在许多时候服务器会希望保存一些必要的客户端信息或者希望能够在客户端保存一些信息,以便在客户端下次访问时携带上这些信息。这就是Cookie机制和Session机制出现的原因。这两种技术都不是HTTP协议规定的内容,但是它们被广泛使用于Web系统中。
Cookie是Web服务器要求客户机浏览器保存在客户机本地的一个非常小的文本文件,该文件的内容由服务器指定;同时服务器还指定了一个URL集合,当浏览器下次访问这些URL中的任何一个时都会携带上Cookie中的内容。Cookie中的内容实质上是一系列属性,属性由属性名和属性值组成,属性名和属性值都是由Web服务器指定的。
Cookie的实现非常简单,却有着旺盛的生命力和广泛的应用。一个简单应用Cookie的例子是页面可以记录用户登录名:当用户登录某网站时,会输入用户名和密码,当用户登录成功后,Web服务器会将用户的登录名使用Set-Cookie头域设置到客户机本地硬盘,并要求客户机在用户下一次打开登录页面时携带用户的登录名信息,Web服务器就可以取出用户的登录名信息并且将其设置到用户名输入框中。这个过程的HTTP消息序列如表1.8所示。
表1.8 Cookie工作过程
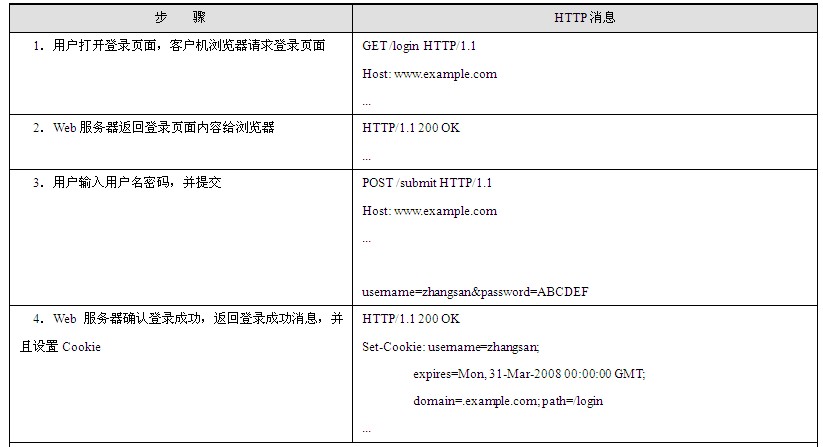

在这个例子中,最关键的就是第4步中的Set-Cookie头域和第6步的Cookie头域。第4步中服务器告诉客户机浏览器要将username=zhangsan这么一 个名值对记录到本地Cookie中,第6步浏览器在下次访问该网页时将该名值对携带在HTTP消息中以便于服务器获得该信息。在Set-Cookie头域的值中,除了定义需要携带的属性信息外,还定义了expires属性、domain属性和path属性。其中expires表示过期时间,即表示这个Cookie设置到该日期以后就无效了。domain属性和path属性合起来规定了一系列URL,即只要访问的URL的域名是example.com,Request-URI是以/login开始的话,那么就将该Cookie携带在HTTP请求头中。
考虑一个简单的情形:邮件服务器中每个用户的邮件内容应该是受密码保护的,在没有使用正确的用户名和密码登录后是不能访问的。用户的邮箱中有许多资源,例如邮件列表、邮件内容、通讯录等,由于每个资源都应该受密码保护,所以用户在每一次请求任何一个资源时都必须输入用户名和密码,否则别人就有可能通过构造该资源的URL访问到该资源。这是因为HTTP是无状态协议,一次请求中的登录信息无法被其他请求使用。但是,如此频繁的输入用户名和密码对于用户来说是无法容忍的。
这种情形在Web应用中是普遍存在的,因为有很多Web应用都需要身份验证。Session机制是一种服务器端的机制,它可以解决上面提到的情形:当用户登录成功时,服务器通过一种特殊的算法生成一个不会重复并且很难找到规律的字符串,称为Session ID,并且将Session ID保存在本地Session ID库中(使用一种类似于散列表的结构来保存信息),同时通过某种机制将Session ID告诉给客户机;当服务器接收到任何访问受保护资源的请求时,只需要查看请求中是否已携带Session ID并且检查携带的Session ID是否已在Session ID库中存在,假如存在则表示该客户机已成功登录,否则拒绝该请求。
1.Session ID的传递方式
Session ID是Session机制的关键,只有通过将Session ID在服务器和客户机之间传递才能够实现Session的作用。Session ID最常用的传递方式是利用Cookie进行传递。
当用户登录成功后,服务器将Session ID作为一个Cookie的属性发送给客户机,并且适当设置domain和path,使得客户机在访问需要受密码保护的资源时都携带上该Cookie属性。例如:
...
Set-Cookie: sessionid=ByOK3vjFD75aPnrF7C2HmdnV6QZcEbzWoWiBYEnLerjQ99
zWpBng!-a; expires: Mon, 31-Mar-2008 00:00:00 GMT; domain: example.com;
path: /mail
...
...
Cookie: sessionid=ByOK3vjFD75aPnrF7C2HmdnV6QZcEbzWoWiBYEnLerjQ99
zWpBng!-a
...
除了Cookie的方式,也可以通过URL来传递Session ID。当用户登录成功后,服务器将在每个需要访问受密码保护资源的URL中都加入Session ID,例如:
http://www.example.com/mail?sessionid=ByOK3vjFD75aPnrF7C2HmdnV6QZcEbzWoWiBYEnLerjQ99zWpBng!-a
2.Session ID的过期
关于Session ID过期的问题,常常会有一种误解:“只要关闭浏览器,Session就消失了”。其实简单考虑就可以明白这是一种误解,Session是一种服务器机制,Session ID是由服务器生成并且保存在服务器本地的,对于任何一个携带Session ID的请求,只要携带的Session ID在服务器本地的Session ID库中存在,就可以访问受保护的资源,也就是说明Session ID是有效的。可见,Session ID是否过期与客户机并没有任何关系,而只与服务器本地的Session ID库中有哪些Session ID有关,Session ID库中不存在的Session ID视为无效;而当客户机关闭浏览器时通常并不会通知服务器,所以服务器也不会主动删除该Session ID。恰恰是由于关闭浏览器不会导致Session被删除,故服务器才需要为Session设置一个失效时间,当服务器发现客户端停止活动的时间超过这个失效时间时,就会把对应的Session ID删除。
Session的本意是“会话”的意思,会话表示一组顺序而且相互关联的对话过程。HTTP是无状态协议,假如将HTTP的一次请求/响应过程看作是一次对话,那么无状态就表示每一次对话和其他对话之间都是没有关联的,即本次对话时已经忘记了上次对话的情况甚至已经忘记了以前是否对话过。所以,引入Session机制让Web服务器与一个客户端的交流过程更像是一个对话。
本章简单介绍了一些基本的Web技术,主要包括Web的基石——HTTP协议和HTML,以及Web应用中经常遇到的两个概念:Cookie和Session。
HTTP协议是建立在请求/响应机制基础上的一种Internet应用层协议,它规定了客户机浏览器和Web服务器的通信模式,以及通信中所使用的HTTP请求消息和HTTP响应消息的格式;HTML是一种格式化的超文本表示语言,它通过定义一些标签可以在浏览器中展示丰富多彩的网页内容;Cookie是Web服务器在客户机本地保存的一个小的文本文件,并且可以在访问适当的Web页面时携带返回给Web服务器;Session是一种服务器机制,它向客户机发送一个Session ID并且要求客户机在访问特定资源时携带该Session ID,以此来甄别客户机请求的合法性。
把Web应用带向动态化的第一个技术就是CGI,即通用网关接口(Common Gateway Interface)。它是外部程序和Web服务器之间的标准编程接口,在物理上它是一段运行在Web服务器上的程序。与静态的Web应用不同,当客户端请求一个CGI程序时,CGI会执行一个程序,并且执行结束后根据执行的结果将适当的信息反馈给客户机。准确地说,CGI不是一种编程语言,而是一种接口,它定义了一种Web服务器与其他编程语言的接口。CGI程序可以用很多语言编写,比如:C++、Perl等。不过,在创建动态的Web页面时CGI也存在一些安全方面的问题。这是因为采用CGI将允许别人在你的系统上执行程序,大多数情况下这可能没有问题,但是别有用心的用户则很可能会利用这一点让系统运行你本来不想运行的程序。
CGI的访问模式如图2.1所示:
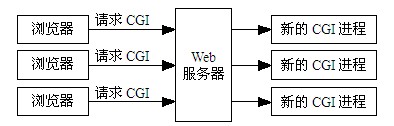
图2.1 CGI访问模式示意图
CGI应用是一个独立的模块,它接受来自Web服务器的请求,对收到的数据进行处理,然后把处理结果返回给服务器,这种结果通常是HTML文档,最后服务器把返回的处理结果返回给浏览器。
尽管CGI将Web应用从静态带进了动态,但它不仅存在上面提到的安全问题,而且在工作方式上也有许多有待改进的地方。根据上面对CGI工作模式的介绍可以发现:
每当收到CGI请求时,Web服务器都需要建立一个新的进程。这将导致响应时间变慢,因为对于一个进程来说,服务器必须创建新的地址空间并进行初始化。多数服务器的配置只能运行有限数量的进程,用户可能面临进程空间耗尽的问题。如果服务器进程空间达到极限,将无法再处理客户机新的请求。
尽管CGI几乎可以用任何语言实现,但最常用的与平台无关的语言是Perl。Perl在正文处理方面是非常强的,但对于每个请求,它都要求服务器启动新的解释程序,这将占用较长的时间才能开始编译代码直至耗尽可能的进程和资源。
CGI在服务器上完全是以独立进程的方式运行的,如果客户机向CGI程序提交一个请求,在Web服务器响应之前该CGI程序又停止了,此时浏览器没有办法知道能够发生什么情况,它只能在那里等待直至超时出现。
在Java问世一年以后,Sun引入了Servlet。Servlet是CGI的替代品,也是Java进军Web开发领域的第一款技术。Servlet完全基于Java实现,提供了对整个Java应用编程接口(API)的完全访问和一个用于处理Web应用的完备的库。一个Servlet是运行于Servlet容器中的Java对象,与CGI不同的是,Servlet为每个请求启动一个单独的线程进行响应,从而大大的节约了空间和时间,处理过程如图2.2所示:
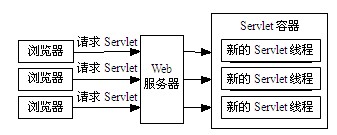
图2.2 Servlet访问模式示意图
Servlet与CGI相比具有如下优势。
有效性:Servlet的初始化代码仅在Web服务器第一次加载时执行一次。一旦加载了Servlet,在处理新的请求时,只需调用一个新的服务方法;与处理每个请求都要全部加载一个完整的可执行程序相比,这是一种相当有效的技术。
稳定性:Servlet能够维护每个请求的状态,一旦加载了Servlet,它即驻留在内存中,对收到的请求提供服务。
可移植性:Servlet是用Java开发的,因而它是可移植的,继承了Java“一次编写,到处运行”的优势。
健壮性:由于Java提供了定义完善的异常处理层次以供错误处理,故Servlet较为健壮。它还有垃圾收集器,可用于防止内存溢出等问题。
可扩充性:Servlet能够通过继承现有对象开发新的对象,从而简化了新的Servlet对象的开发过程。
Servlet的运行需要Servlet容器作为环境,Servlet只是一种特殊的Java对象,将Servlet部署到Servlet容器中后,Servlet容器负责在适当的时候创建Servlet、调用Servlet对象和销毁Servlet。每个Servlet对象都定义了三个方法,分别用于在被创建、被调用和被销毁时执行。每个Servlet在被部署到Servlet容器中时都配置了URL映射模式,如果到服务器的某个请求的URL与某个Servlet的映射模式相匹配,则该请求就会被分发到该Servlet。Servlet的核心方法是一个service()方法,当有请求被分发到该Servlet时service()方法就会被执行。
在Servlet执行期间,有关请求和Web应用的属性等在处理中可能会用到的信息都可以通过Servlet提供的API获得,例如请求的URL、请求消息的头域信息和Web应用的上下文路径等。同时,对该请求的响应消息的有关内容和属性也可以通过Servlet的API在Servlet中进行设置,例如响应的编码方式、响应消息的头域信息等。
从Servlet的功能和设计的角度讲,Servlet不仅仅可以用来处理HTTP请求和响应,它还可以用来处理其他协议的请求和响应消息。但不可否认Servlet发挥作用最大的领域还是在Web应用中处理HTTP的请求和响应。
JSP技术
JSP的全称是JavaServer Pages,它是基于Java的动态页面技术,它可用于创建跨平台和跨Web服务器的动态网页。JSP是除Servlet之外的又一个Java Web开发的关键技术。
JSP也需要运行于JSP容器中,但是与Servlet不同的是,
JSP与HTML一样是JSP以单独的文件形式存在的。
JSP文件的内容非常类似于一个HTML文件,它在HTML文件中通过特殊的标签将Java代码添加到其中。
JSP文件直接存在于Web应用的Web目录中,客户端的请求URL直接指向该JSP文件,当JSP容器发现客户端正在请求某个JSP文件时它就对该JSP文件进行解析,运行其中的Java代码,并将执行完后生成的HTML内容返回给客户端。一个简单的JSP文件内容如下:
示例2.1
<%@ page language="java" contentType="text/html; charset=GBK" pageEncoding="GBK"%>
<%@ page import="java.util.Date;"%>
<HTML>
<HEAD>
<TITLE>提示</TITLE>
</HEAD>
<BODY>
现在时间是:<% = new Date().toString() %> !
</BODY>
</HTML>
在有客户端请求该JSP文件,该文件通过Java代码获取当前的系统时间,将该时间放在HTML文件的适当位置,并将生成的HTML文件返回给客户端,所以客户端获得的页面会包含当前的时间,如图2.3所示。
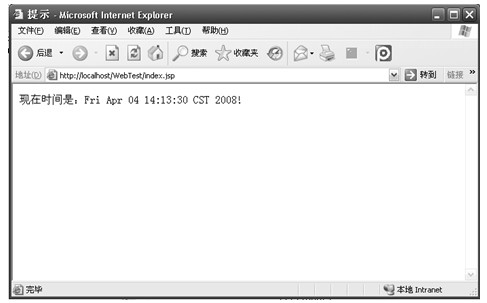
图2.3 访问JSP文件示例
JSP与Servlet一样,可以根据客户端的请求提供动态的响应内容,而且JSP也可以访问到有关请求、Web应用等相关的信息,以及设置响应消息的相关内容。
不仅如此,JSP在返回HTML作为响应内容时要比Servlet更方便。假如,服务器要向客户端返回如下的HTML页面作为提示信息:
<HTML>
<HEAD>
<TITLE>提示</TITLE>
</HEAD>
<BODY>
您请求的页面出现错误!
</BODY>
</HTML>
由于Servlet是纯Java对象,Servlet的内容也只能严格按照Java的语法书写,所以在输出HTML文档时,Servlet必须使用输出流的print()方法和println()方法将HTML文档的内容输出到响应消息中,如下所示:
pw.println("<HTML>");
pw.println("<HEAD>");
pw.println("<TITLE>提示</TITLE>");
pw.println("</HEAD>");
pw.println("<BODY>");
pw.println("<H1>页内标题</H1>");
pw.println("</BODY>");
pw.println("</HTML>");
而如果使用JSP,那么只需要将HTML文件的内容直接作为到JSP文件的内容就可以了,JSP文件的内容如下:
<%@ page language="java" contentType="text/html; charset=GBK" pageEncoding="GBK"%>
<HTML>
<HEAD>
<TITLE>提示</TITLE>
</HEAD>
<BODY>
您请求的页面出现错误!
</BODY>
</HTML>
JSP文件也能处理动态内容,而且在向客户反馈HTML文档时非常方便;但由于JSP把Java代码和HTML内容放在同一个文件中,假如其中用于内容处理的Java代码过多的话,那么JSP文件的内容就会过于庞杂,格式也会比较混乱,不利于开发和维护。
既然JSP文件具有页面展现方面的优势,那就让JSP只负责展现方面的工作,而将Servlet负责控制流程,再实现Java对象或JavaBean以负责数据的建模和持久化,这便是Struts技术的核心思想。
Struts技术的架构采用了著名的MVC模式。MVC是Model-View-Controller的简称,即把一个应用的输入、处理、输出流程按照Model、View、Controller的方式进行分离,这样一个应用被分成三个层——业务逻辑层、表示层、控制层。
视图(View)属于表示层,它代表与用户交互的界面,在基于HTTP协议的开发技术中视图层都是基于HTML的技术。MVC中的视图仅限于向用户展现模型中的数据和接收用户的交互信息。视图不具备任何与业务模型或业务流程相关的知识,只需要负责展现获得的数据和将接收到的用户交互信息提交给控制器。
模型(Model)属于业务逻辑层,它用于实现具体的业务逻辑、状态管理的功能。模型包括业务模型和数据模型两种:业务模型负责业务流程/状态的处理和业务规则的制定,数据模型是对对象的数据持久化。MVC并没有提供模型的设计方法,而只是规定应该组织管理这些模型,以便于模型的重构和复用。
控制器(Controller)属于控制层,接收来自视图的用户请求,将请求转换为数据模型的命令传递给模型。控制器就是一个分发器,根据用户请求选择模型和视图。控制层并不做任何的数据处理。
模型、视图与控制器的分离,使得一个模型可以对应多个视图。如果用户通过某个视图的控制器改变了模型的数据,所有其他依赖于这些数据的视图都会反映这些变化。因此,无论何时发生了何种数据变化,无论控制器选择任何视图,视图都会从模型获得最新的更新。模型、视图、控制器三者之间的关系和各自的主要功能,如图2.4所示。
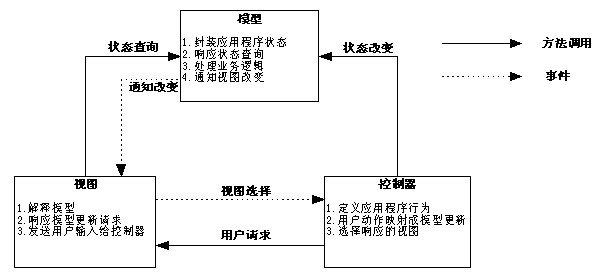
图2.4 模型-视图-控制器交互示意图
Struts是一个基于Sun J2EE平台的MVC框架,主要是采用Servlet和JSP技术实现的。它是Apache软件基金会旗下Jakarta项目组的一部分,其官方网站是http://struts.apache.org/。由于Struts能充分满足应用开发的需求,简单易用,敏捷迅速,故在Web开发中颇受关注。Struts把Servlet、JSP、自定义标签和消息资源(message resources)整合到一个统一的框架中,开发人员利用其进行开发时不用再自己编码实现全套MVC模式,极大地节省了时间。
Struts开发了一套MVC框架,程序员在使用Struts开发Web应用时根据具体应用的需求实现不同的模型、视图和控制器,然后通过一些配置文件将这些内容装载到Struts框架中。所以Struts主要包含如下四个部分。
1.模型(Model):Struts使用定义的Action类及程序员通过继承Action实现的子类完成模型的工作。程序员在Action的子类中实现业务逻辑和操作数据模型。
2.视图(View):视图由JSP文件实现。除了JSP定义的内容外,Struts还提供了一整套JSP定制标签库,利用它们可以快速建立应用系统的界面。
3.控制器(Controller):本质上是一个Servlet,根据程序员定义的请求映射关系将客户端请求转发到相应的Action类。
4.配置文件及其解析工具包:Struts通过许多XML文件和properties文件对应用系统进行配置,其中包括定义请求映射关系的struts-config.xml文件,还有描述国际化应用中用户提示信息的配置文件等。
虽然Struts为Java Web开发提供了一种崭新的方式,但是随着Struts的不断发展和新技术的不断出现,Struts也暴露出了一些问题。经过将Struts与另一个著名的项目WebWork相结合,产生了Struts2。
Struts2的体系与Struts体系的差别非常大,因为Struts2使用了WebWork的设计核心,而不是Struts的设计核心。Struts2中大量使用拦截器(技术上采用Servlet Filter)来处理用户的请求,其体系结构图如图2.5所示。
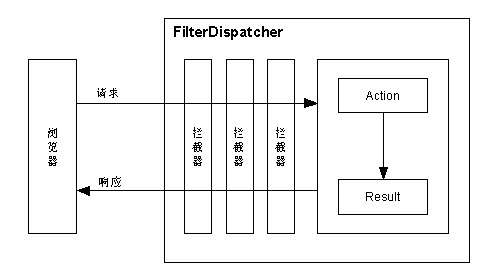
图2.5 Struts2体系结构图
Struts2的处理流程大致如下:
(1)浏览器发送一个请求;
(2)核心控制器FilterDispatcher根据请求调用合适的Action;
(3)拦截器链自动对请求应用通用功能,如验证等;
(4)调用Action的execute方法,该execute方法根据请求的参数来执行一定的操作;
(5)Action的execute方法处理的结果将被输出到浏览器中,支持多种形式的视图。
Struts和Struts2在Java Web开发领域中取得了非常大的成功,现在有许多Java Web开发团队在使用这两种技术开发Web系统。
“工欲善其事,必先利其器”。对于程序员来说,好的开发工具可以极大地提高开发效率。而且,基于Servlet和JSP技术的Web系统也必须在对Servlet和JSP技术提供支持的Web服务器中进行开发。所以,学习常用的Java Web开发工具是学习Java Web开发技术的必修课。
Tomcat是最流行的开源Servlet/JSP容器,是最适合于初学者使用的基于Java技术的Web服务器;Eclipse是最流行的开源集成开发环境,也是基于Java技术实现的。Tomcat和Eclipse的组合是进行Java Web开发最有效的工具集。
在前面介绍Servlet和JSP技术时都提到了,Servlet需要在Servlet容器中运行,而JSP也需要在JSP容器中运行。而且,如果需要Servlet和JSP能应用到Web应用中,还必须将JSP和Servlet部署到Web服务器上。传统的Web服务器(例如Apache)并不能对JSP和Servlet提供支持,所以将JSP技术、Servlet技术以及基于这两种技术实现的其他Java Web技术(例如Struts技术)应用于实际Web应用中的方法只有如下两种:
(1)实现能够支持JSP和Servlet的Web服务器;
(2)实现JSP和Servlet容器并将其与Web服务器相结合。
Tomcat正是Apache基金会针对JSP和Servlet标准实现的标准的JSP/Servlet容器,而且以上提到的两种方式它都支持。Tomcat是Apache基金会Jakarta项目中的一个核心项目,是一个免费的开源项目。Tomcat由Apache,Sun和其他一些公司及个人共同开发而成,由于有Sun的参与和支持,所以最新的Servlet和JSP规范总能在Tomcat中得到体现。
Tomcat不仅仅是一个Servlet容器,它也具有传统的Web服务器的功能:处理HTML页面。与Apache相比,它处理静态HTML的能力不如Apache。但Tomcat提供了一种与Apache集成的途径,通过与Apache集成,可以让Apache处理静态Web内容,而让Tomcat处理JSP和Servlet。这种集成只需要在Apache和Tomcat中进行简单配置即可。
Tomcat中的应用程序是一个Web应用目录或一个WAR(Web Archive)文件。WAR是Sun提出的一种Web应用程序格式,它与JAR类似,也是一个压缩包,压缩包的内部结构符合一个Web应用的目录结构。通常,Web应用的根目录下除了包含诸如HTML和JSP等Web对象文件及其目录外,还会包含一个特殊的目录WEB-INF;在WEB-INF目录下通常有一个web.xml文件、一个lib目录和一个classes目录,web.xml是这个应用的配置文件、lib目录包含一些库文件、classes目录则包含已编译好的class文件,库文件和class文件中在应用中需要使用的Servlet类和JSP/Servlet所依赖的其他类(如JavaBean)。
Tomcat提供了很多种将Web应用部署到其中的途径,其中最简单的可以直接将WAR文件或者Web应用根目录复制到Tomcat的webapp目录下,Tomcat就会自动检测该Web应用,对WAR文件解压,并将Web应用部署到Tomcat中。
Tomcat通过“服务→虚拟主机→应用”的层次将提供的所有功能分成多个层次和级别进行组织和管理。一个Tomcat服务器可以部署多个服务,每个服务可以配置多个虚拟主机,每个虚拟主机可以部署多个应用。这样的结构便于将一个服务器的各种功能进行分类和分层管理。
Eclipse是一个开放源代码的、基于Java开发的可扩展插件式开发平台。Eclipse本身并不提供任何可被直接使用的功能,它只是一个框架和一组服务,用于通过插件组件构建开发环境。但是,Eclipse框架提供了一个完善的插件结构,它提供给其他开发人员充分的发挥空间,开发人员可以开发出任何符合Eclipse插件结构的插件,这个插件可以是用于完成任何功能的插件。而且向Eclipse中添加插件的方式也非常方便。将插件添加到Eclipse中后,插件可以与Eclipse完全结合成为一个完整的开发工具。现在,在开源网站上可以找到的比较成熟和流行的各种Eclipse插件很多,例如:用于开发C/C++应用的C/C++开发插件(C/C++ Development Tooling,CDT);用于开发Perl应用的Perl开发插件(Eclipse Perl Integration,EPIC)等。
除此之外,Eclipse在其发布时还附带了一个标准的插件集,其中包括用于开发Java应用的插件集(Java Development Tooling,JDT)和用于开发Eclipse插件的插件集(Plug-in Development Tooling,PDT)。JDT提供了对开发Java工程的强大支持,包括:工程和Java类新建向导、Java工程管理、编辑Java文件时的内容帮助和智能感应、对Java类的重构支持,等等。PDT提供了对开发Eclipse插件的支持,通过PDT程序员可以在Eclipse中开发插件工程,并且其中也提供了丰富的插件开发支持功能。
Eclipse灵活的插件结构为Eclipse的发展奠定了基础,也吸引了大量的开发人员和企业参加到Eclipse插件的开发行列。甚至,很多公司直接对Eclipse开发框架进行改造,大量加入自己的插件,将Eclipse变成另外一套新的开发环境。
Eclipse的Web开发工具插件集对Eclipse在开发Web工程方面提供了非常大的扩充,使得Eclipse可以作为一个功能完善的Web应用开发环境。在安装了Web开发工具插件集后,Eclipse在原来的基础上又提供了对以下几个方面的支持。
Web对象和J2EE对象创建向导。
开发Web对象和J2EE对象的工具,包括:开发HTML,CSS,JSP,Web服务,JavaScript,XML等对象的支持。
提供一个通用服务器的扩展点用于将通用服务器添加到Eclipse中。
提供运行/调试Web应用的工具。
本章从CGI技术讲起,分别介绍了Java Web开发中最基础的Servlet技术和JSP技术以及Java Web开发中最流行的Struts技术。Servlet是运行于Servlet容器中Java对象,它为每个请求启动一个单独的线程进行响应,Servlet与传统的CGI技术相比,在有效性、稳定性、可移植性、健壮性和可扩充性方面具有优势。Servlet虽然在处理请求方面具有很大的优势,但是在向客户端反馈HTML响应页面方面却略显不足,JSP提供了内嵌于HTML页面的结构语法,将动态处理请求的能力与反馈响应页面的灵活性结合了起来;但如果将复杂的处理过程全部放到JSP页面中,就会使JSP页面显得非常冗长而且难于维护。Struts技术以MVC模式为基础,结合Servlet强大的处理HTTP请求和响应的能力以及JSP强大的页面展现能力,构建了一种Java Web开发的MVC框架,在Java Web开发领域得到了广泛的应用。
Tomcat是应用最普遍的Servlet/JSP容器,它既可以作为单独的Web服务器也可以与其他传统的Web服务器结合使用以提供处理Servlet和JSP的能力。Eclipse是基于全插件结构的通用集成开发环境,通过向Eclipse中添加不同的插件可以使Eclipse具备开发不同类型系统的能力;另外,Eclipse的Web开发插件集还为Eclipse增加了开发Web项目和J2EE项目的能力。
选择一个好的集成开发环境会极大地提高系统开发的效率。Eclipse是一款基于Java开发的可扩展插件式开发平台。Eclipse以其优秀的架构和附带的Java开发插件已经成为Java开发领域最流行的集成开发环境;而且Eclipse是开源代码,可以免费获得。Eclipse的Web开发插件集又在Web开发和J2EE开发方面为Eclipse提供了非常大的扩充,使得Eclipse足以成为功能完备的Java Web开发环境。
本章将首先对Eclipse进行简单介绍,介绍Eclipse的发展和架构;然后介绍包含Web开发插件集的Eclipse(WTP - Eclipse)的功能及如何下载和安装。
Eclipse是一个开放源代码的、基于Java开发的可扩展插件式开发平台。Eclipse本身只是一个框架和一组服务,用于通过插件组件构建开发环境。而且,Eclipse自身附带了一个标准的插件集,其中包括用于开发Java应用的开发工具(Java Development Tooling,JDT)。
大多数用户只是将Eclipse当作Java集成开发环境(Integrated Development Environment,IDE) 来使用,但实际上Eclipse的功能远不止于此。Eclipse还支持通过安装C/C++开发插件(C/C++ Development Tooling,CDT)开发C/C++应用、通过安装Perl开发插件(Eclipse Perl Integration,EPIC)开发Perl应用、……而且它们都是免费的。不仅如此,Eclipse和JDT一样,自身还附带了一个插件开发环境(Plug-in Development Environment,PDE),利用这个组件程序员可以自己开发任何与Eclipse无缝集成的插件,可以让Eclipse开发环境做任何自己希望的事情。甚至,很多公司直接对Eclipse开发框架进行改造,加入自己的插件,使Eclipse变成另外一套新的开发环境,例如,Adobe的Flex Builder。
20世纪90年代中期,几大商业开发环境之间都进行过激烈的竞争,其中也包括基于Java的集成开发环境。而当时IBM公司的开发工具Visual Age for Java却面临着一个问题,因为它和IBM的另外一个集成开发环境WebSphere Studio 很难集成到一起,而且底层的技术比较脆弱,很难进一步发展,无法满足业界应用开发的需求。因此,在1998 年,IBM成立了一个项目开发小组开始探索下一代开发工具技术,并且在2000年他们决定给新一代开发工具项目命名为Eclipse。
Eclipse项目的开发人员意识到:Eclipse要吸引开发人员、发展起一个强大而又充满活力的商业合作伙伴社区并且吸引大量活跃的第三方系统这一点非常重要,而采用开放源码的授权和运作模式则是一个非常有效的途径。于是,2001年12月,IBM将价值4千万美元的Eclipse源码捐赠给开源社区;同时联合八家公司成立了Eclipse协会(Eclipse Consortium),每个公司都作为协会的成员公司,主要任务是支持并促进 Eclipse 开源项目。但到2003年,IBM又意识到这种会员模式很难进一步扩展,有些事务操作起来很困难,主要是因为Eclipse协会不是一个法律上的实体;此外有些业界成员不愿加入,因为他们认为Eclipse的真正领导者还是IBM。因此IBM决定创建一个独立于IBM的Eclipse,于是 IBM 与其他成员公司合作起草了管理条例,准备成立Eclipse基金会(Eclipse Foundation)。2004年初,Eclipse基金会正式成立。Eclipse基金会由若干会员组成,会员大多是业界的大公司或者学校、科研机构等。Eclipse的开发和维护都由Eclipse基金会负责,今后发展方向也由Eclipse基金会的会员共同决定。Eclipse基金会共有四种类型的会员:Associate Members、Add-in Provider Members、Strategic Members、Committer Members。其中Strategic Members对于Eclipse的发展起着最重要的作用,他们为Eclipse基金会提供开发人员和开发资金,同时也决定Eclipse的发展方向和开发计划。截至作者写作本书,Eclipse的Strategic Members有20个,包括:BEA、Borland、IBM、Intel、Motorola、Nokia、ORACLE、SAP、Sybase等。
读者可能会感到不解,Eclipse既然是开源软件,任何公司都无法从Eclipse中获得利润,IBM为什么会愿意将花费如此大成本的软件捐赠出来作为开源项目呢?其他这些公司又为什么会愿意在Eclipse项目上花费人力和资金呢?这是因为,随着Eclipse的开源,越来越多的公司加入到Eclipse基金会、越来越多的开发人员转向使用Eclipse,IBM和Eclipse基金会的会员公司可以开发出大量基于Eclipse的插件,Eclipse是免费的,但是这些插件是收费的,会员公司可以通过出售插件来赚取利润,所以Eclipse 的所有成员公司大部分都是商业软件提供商。
最初,Eclipse并没有在开发人员中被广泛地使用,直到2003年3月Eclipse 2.1发布后才立刻引起了轰动,下载的人蜂拥而至。后来在Eclipse基金会的领导下,Eclipse 3.x相继发布,Eclipse也真正成为了一个成熟、优秀的集成开发环境。越来越多的成员加入Eclipse协会和越来越多的第三方插件的发布使得Eclipse的发展越来越快。
WTP是Eclipse基金会组织的一个Eclipse一级项目,它起始于IBM Rational WebSphere项目和ObjectWeb Lomboz项目的贡献,主要目的是开发一个Eclipse插件,提供一个丰富而且集成良好的工具集合用于简化复杂Web应用和J2EE应用的开发。WTP工程向其使用者声明了三个主要关注点:
性能:WTP将是非常精简的,它将在不影响任何功能的情况下最小化内存的使用。
易用性:WTP将非常易于使用,需要很少的预备知识,能够为所有开发人员创建完善的应用提供支持。
质量:WTP将是商业级产品,它的API将达到平台级质量。
WTP 包含两个子项目:Web标准工具(Web Standard Tools,WST)和J2EE标准工具(J2EE Standard Tools,JST)。WST工程的目的是为任何基于Eclipse的开发环境提供开发Web应用的公共基础设施。JST工程则是提供对开发J2EE技术相关应用(例如JSP和EJB)的支持。
WTP对Eclipse的扩展包括:
提供创建Web对象和J2EE对象的向导:提供了创建Web工程、J2EE工程以及各种Web对象和J2EE对象的向导。支持的工程有静态/动态Web工程、EMF(Eclipse Modeling Framework)工程、EJB(Enterprise Java Bean)工程、各种J2EE工程、JPA(Java Persistence API)工程等;支持的对象有:HTML、CSS、JavaScript、JSP、Servlet、XML、SQL文件、Web服务对象、EJB对象、多种EMF Model等。
提供开发Web对象和J2EE对象的工具:提供开发Web表现层、业务层和数据层应用以及开发服务器端发布程序的工具,包括为标准语言(例如,HTML,CSS,JSP,Web服务,JavaScript,XML等)提供的编辑器、代码验证器和文档生成器。
提供服务器工具:提供一个通用服务器的扩展点用于将通用服务器添加到工作空间中,以及启动和停止服务器。它用一些服务器扩展了Eclipse平台,将这些服务器作为首选执行环境,包括Web服务器、J2EE服务器以及数据库服务器。
提供运行/调试Web应用的工具:支持在目标服务器环境下发布、运行、启动和停止Web应用代码。
提供基本的数据工具:具有浏览数据库和对数据库执行SQL查询的能力。
还包括一个TCP/IP监视服务器用于调试HTTP消息通信,尤其是由Web服务生成的SOAP消息。
这个工程的最终目标就是提供高度可复用和可扩展的工具,便于开发者创建可持续提升性能的应用。
WTP是Eclipse的一级子项目,它以Eclipse插件的形式出现。所谓WTP-Eclipse是指已经安装了WTP插件的Eclipse,除了增加WTP扩展的相关功能外,其他与普通发布的Eclipse是一样的。在不至于产生混淆的情况下,下面提到的Eclipse都指安装了WTP插件的Eclipse,即WTP-Eclipse。在Eclipse的官方网站中有WTP的主页,链接地址是:http://www.eclipse.org/webtools,页面如图3.2所示:
图3.2 WTP官方主页
在作者写作本书时,WTP最新的Release版本是2.0.1,所以本书就以WTP 2.0.1为参考版本进行介绍。单击WTP 2.0.1进入WTP 2.0.1的主页面,如图3.3所示。
图3.3 WTP 2.0.1主页
单击页面中部的“Download”链接进入下载页面,如图3.4所示。
图3.4 WTP下载页面
如图3.4所示,顶部的“Release Build: R-2.0.1-20070926042742”是该下载版本的版本号,下面是日期,从图中可以发现WTP 2.0.1是2007年9月26日发布的。
在下载页面中分了好几栏,第一栏“Required Prerequisites”是指安装WTP插件的前提,即在安装WTP前需要提前安装的环境和插件;第二栏“Web Tools Platform All-In-One Packages”是指将所有内容整合成一个包的下载方式,即包括Eclipse平台、各种前提插件和WTP插件,这就是本节前面提到的WTP-Eclipse。这里提供了针对三种不同操作系统的下载链接,对于Windows用户就单击第一种平台后面的下载链接。单击下载链接后会进入镜像选择页面,如图3.5所示。
图3.5 镜像选择页面
本页面列出了所有可以下载的镜像站点,同时页面也自动选择了一个最优下载链接,如图中黑框所示,通常选择该镜像就可以了。单击该链接直接下载,下载获得的文件是一个zip文件,文件名开始是“wtp-all-in-one-sdk”,接着是版本号,最后是应用平台,例如:wtp-all-in-one-sdk-R-2.0.1-20070926042742- win32.zip。
将下载的zip文件解压到本地文件系统,根目录的内容如图3.6所示。

图3.6 Eclipse根目录
双击eclipse.exe既可以打开Eclipse开发环境。
【注意】
运行Eclipse时系统中必须已经正确安装并配置了JDK,假如系统中的JDK没有正确安装和配置,Eclipse在启动时会弹出错误对话框。
Eclipse正确启动后会弹出欢迎菜单,如图3.7所示。
图3.7 Eclipse欢迎界面
欢迎界面在第一次启动Eclipse时自动出现,以后再启动时不会自动出现,但是读者可以通过Eclipse菜单Help → Welcome打开。
欢迎界面上提供了一些图标使用户可以方便地开始学习Eclipse,图标从左向右依次为:
Overview: Get an overview of the features.
对Eclipse开发环境的简单介绍。分别提供了对Eclipse基本概念、团队开发支持、Java开发、插件开发的介绍。每部分都会链接到Eclipse帮助。读者可以在这里学习Eclipse的基本概念和基础知识,作为Eclipse开发的起步。
What’s new: Find out what is new.
这里介绍了Eclipse当前版本的新特性,包括Eclipse平台的新特性、Java开发工具的新特性和插件开发的新特性;介绍了如何将以前旧版本的Eclipse工程代码迁移到新版本的开发环境下工作;还提供了在线更新和加入Eclipse社区的链接。
Samples: Try out the samples.
提供了一些使用Eclipse的样例,包括使用Workbench、Java开发工具的样例以及一些SWT的样例。不过,这些样例都需要在线下载。
Tutorials: Get through tutorials.
这里提供了大量的向导,指导用户开始使用Eclipse的各个模块,包括:创建Java Hello World应用、创建SWT Hello World应用、创建一个Eclipse插件、创建RCP(Rich Client Platform)应用、以及如何利用CVS进行团队开发,等等。
Workbench: Go to the Workbench.
关闭欢迎页面进入开发界面。
Eclipse的开发界面如图3.8所示。
图3.8 Eclipse的开发界面
本章对Eclipse进行了简单的介绍,包括Eclipse的历史和Eclipse的架构,并且引导读者逐步下载和安装WTP-Eclipse。
最早Eclipse是IBM的一个内部项目,为了Eclipse的发展,2001年IBM将Eclipse捐赠给开源社区,并且联合业内的公司组成了Eclipse基金会。Eclipse基金会负责Eclipse的开发和维护工作。Eclipse是全插件结构,除了运行时环境外其他全部以插件的形式加入Eclipse开发环境中,Eclipse自带的插件有工作空间、工作台、CVS、JDT、PDT等。
WTP是Eclipse的一级子工程,它提供了Eclipse支持开发Web应用和J2EE应用的能力。WTP-Eclipse是安装了WTP插件的Eclipse,它可以从Eclipse官方网站的WTP主页上下载。
本章将简单介绍Eclipse集成开发环境,包括Eclipse的界面、Eclipse的常用配置以及Eclipse插件。在这一章读者将了解到:
什么是视图和透视图,它们的区别是什么;
Eclipse都有哪些菜单以及每个菜单项的作用;
如何查看和设置Eclipse中的快捷键;
如何配置Eclipse的常用功能,如Clean up、代码模板、代码格式化;
如何配置Eclipse的Web开发插件集;
安装Eclipse插件的常用方式。
Eclipse作为一种集成开发环境,它可以让程序员在它的开发环境中完成基本上所有程序开发的工作,熟练地掌握Eclipse开发界面的组织可以提高程序开发的效率。同其他大多数集成开发环境一样,Eclipse的界面也是一个整体窗口式开发界面。
在开发Java应用时典型的界面布局图如图4.1所示。
图4.1为编辑Java程序时的Eclipse界面,也是Java程序员最常用的界面布局方式。从该图中可以发现,该界面分为七个部分:菜单栏、快捷图标栏、透视图选择栏、浏览区、文件编辑区、提纲显示区和辅助显示区。
与其他集成开发环境不同的是Eclipse的界面并不是一成不变的,它提供了灵活组织界面布置的方式。Eclipse中每一个用于显示特定内容的窗口称为视图(View),如图4.1所示,浏览区有Package Explorer视图、Hierarchy视图,辅助显示区有Problems视图、Javadoc视图和Declaration视图,提纲显示区有Outline视图。Eclipse提供了许多种视图,而且不同的插件还可以定义不同的视图添加到Eclipse中。除此之外,Eclipse还可以通过定义不同的透视图(Perspective)对视图按不同的布局进行组织以适应不同的开发场景。不同的透视图可以定义不同的窗口布局模式以及在各窗口中显示不同的视图。图4.1中所示的界面风格是Eclipse自带的Java透视图。其中每个视图的位置是Eclipse默认的位置,其中浏览器、提纲显示区和辅助显示区中的视图可以在这几个区之间被随意拖动。
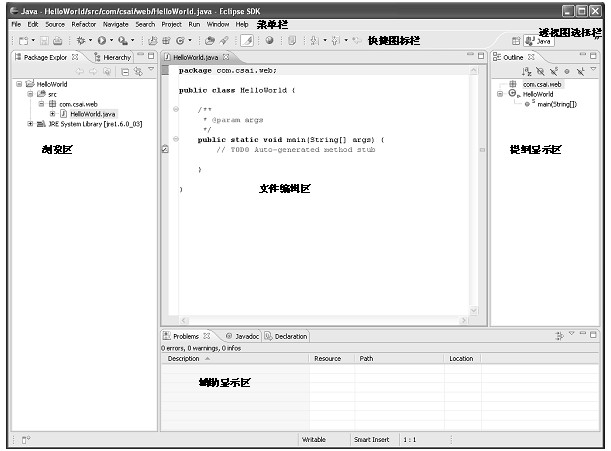
图4.1 Eclipse界面布局图
在本书所介绍的WTP-Eclipse中总共提供了几十种不同的视图,它们都可以通过Window → Show View菜单打开,如图4.2所示。

图4.2 视图选择图示
如图4.2所示,子菜单中列出了一些常用的视图。单击Other...菜单项可以打开当前Eclipse支持的所有视图,它们被分类组织,如图4.3所示。
图4.3 选择视图对话框
不同的视图具有不同的格式,用于显示不同的内容。常用的视图有以下七种。
(1)Package Explorer:包浏览器视图,该视图以树状结构显示当前所有已打开工程的包内容,每个工程作为一个树的根节点,工程节点下面按照工程中的目录结构显示工程中的包、源代码、引入的库等资源。需要注意的是这个视图中不显示工程中编译输出的文件。
(2)Navigator:导航视图,该视图与Package Explorer类似,也是以树状结构显示工程中的内容,但是该视图显示的是工程目录中的原始文件目录结构,不区分文件是否是编译输出的,都显示。
(3)Outline:文件大纲视图,该视图显示当前编辑文件的内容大纲。典型地,当编辑Java代码时,显示当前Java文件中的类以及类中定义的属性域和方法域;当编辑HTML文件时,显示当前HTML文件中的标签层次结构。
(4)Problems:问题视图,该视图显示当前工作空间中打开的工程中所有的编译错误和警告。
(5)Console:工作台视图,该视图是程序运行时的标准输入/输出窗口。
(6)Ant:Ant视图,该视图对工作空间中的Ant构建脚本进行管理和运行。
(7)Search:搜索视图,该视图在调用搜索功能时会自动打开,它用于显示搜索的结果。
透视图定义了在Eclipse界面上对视图的不同组织方式,程序员可以通过Window → Open Perspective菜单项选择不同的透视图,如图4.4的a)图所示:
Open Perspective菜单项的子菜单项提供了三种最常用的透视图,单击Other...子菜单项可以打开当前Eclipse支持的所有透视图,如图4.4的b)图所示。
a)选择透视图菜单
b)选择透视图对话框
图4.4 透视图切换
每一种透视图定义了一套视图的显示和组织模式,不同的透视图用于不同的开发情景。例如:Java透视图用于编辑Java代码、Debug透视图用于调试程序、Java Browsing透视图用于浏览Java代码、Plug-in Development透视图用于开发插件应用、Java EE透视图用于开发J2EE应用、JPA Development透视图用于开发JPA应用等。前面图示的Eclipse界面是Java透视图下的Eclipse界面,如图4.5所示为Debug透视图下的Eclipse界面。
图4.5 Debug透视图
除此之外,Eclipse还支持用户自定制的Perspective,用户可以通过Window的子菜单Customize Perspective...和Save Perspective As...自己定制和保存透视图,并且这些自定义透视图也可以通过Open Perspective菜单打开。
Eclipse 3.3.1的菜单栏有十个一级菜单项:File、Edit、Source、Refactor、Navigate、Search、Project、Run、Window和Help。
1.File菜单
File菜单如图4.6所示。
New菜单项用于新建对象,包括文件对象或者概念对象。例如,Project…用于新建任何一种Eclipse支持的工程,包括Java工程、Web工程、J2EE工程等;Package用于新建一个Java包;Class用于新建一个Java类,同时新建与类名同名的文件。在这里没有列出的对象可以通过单击Other…菜单项打开选择框。Open File…菜单项用于打开本地文件系统中的某个文件。
图4.6 File菜单
Close菜单项关闭当前编辑文件;Close All菜单项关闭打开的所有文件。
Save菜单项用于保存当前编辑文件;Save As…会打开一个文件选择窗口,用于将当前编辑文件保存为另一个文件;Save All菜单项用于保存打开的所有文件;Revert菜单项用于取消当前编辑文件的所有最新编辑内容,将其内容恢复到上一个保存点。
Move…和Rename…菜单项都只有当浏览区中某个文件对象(包括文件、目录和Java包等)被选中时才能使用,Move…是移动文件对象,即将该文件对象移动到另一个目录或Java包中;Rename…是重命名文件对象;这里需要说明的是,当执行Move…和Rename…操作的是Java对象时,Eclipse会自动更改工程中对该对象的相关应用,使完成操作后工程中不会出现引用错误;Refresh菜单项刷新当前选中对象及其包含的对象,使之与文件系统中的实际内容保持一致,而且当Java对象被刷新时Eclipse会重新对该对象进行编译,通常当工程中的文件在Eclipse外被更新后就需要使用该菜单刷新被更新的对象。Convert Line Delimiters to…菜单项用于更改在编辑文件时使用的换行符,可以将换行符保持与Windows风格、Linux风格或MacOS 9风格一致,默认是Windows风格。
Print…用于打印当前编辑文件。
Switch Workspace…用于切换工作空间。Eclipse用工作空间来管理工程集,一个工作空间中可以包含许多工程,一个工作空间在文件系统中是一个独立的文件夹。浏览区展示的即为当前工作空间中的所有工程。
Inport…用于将不同形式和不同位置的文件内容导入到工作空间中,最常用的有导入已存在的Eclipse工程、导入本地文件系统中的文件到工程中、从CVS导入工程、从Jar文件导入、从War文件导入,等等。Export…用于将工作空间中的内容导出,最常用的有导出为Jar文件、导出为War文件、导出Java文档等。
Properties打开当前编辑文件的文件属性,包括:文件位置、文件大小、文件编码等。
Exit则退出Eclipse开发环境。
另外,File菜单还会提供一些最近访问文件的快捷链接。
2.Edit菜单
Edit菜单如图4.7所示。

图4.7 Edit菜单
Edit菜单主要提供了一些与编辑文件内容相关的操作或设置,具体的菜单项如下。
Undo菜单项用于撤销对上一次的操作,通常菜单上会显示上一次操作的动作。Redo菜单项只有在进行了Undo操作后才能使用,表示重新再做一遍上一次的操作。
Cut/Copy/Paste菜单项的功能和通常所了解的意义是一致的,它们分别表示对选中文字进行剪切、复制和粘贴。Copy Qualified Name菜单项表示复制当前选中或光标所在位置的元素的全名,即包括元素的包全路径和所在类的信息,例如在一个包com.csai.web中的HelloWorld类的main(String[] arg)方法中定义了一个对象s,那么当光标在s上单击该菜单项就会将com.csai.web.HelloWorld.main(String[]).s复制到剪切板中。
Delete菜单项用于删除选中的内容或选中的文件对象。Select All用于选中文件中的所有内容或者浏览区的所有文件对象。Expand Selection To提供了一些方便的方法用于扩充当前选择以包含文件中的一些代码元素,比如增加前面或后面的一条语句、扩充选择以包含当前大括号包围的整个代码块,等等。
Find / Replace…菜单项打开一个搜索工具窗口,用于在当前编辑文件中搜索指定文本。Find Next和Find Previous分别是向后和向前搜索当前搜索串。Incremental Find Next或Incremental Find Previous打开增量搜索模式,在打开该模式后键入待查找内容,查找内容就会出现在状态栏,并且Eclipse会在当前编辑文件中增量式查找并标记与键入内容匹配的第一个位置;当选择Incremental Find Next菜单项时进入向后增量查找模式,当选择Incremental Find Previous菜单项时进入向前增量查找模式。
Add Bookmark…菜单项用于在当前光标所在行或当前选中文本的第一行添加一个书签,便于以后定位。Add Task…菜单项用于在当前光标所在行或当前选中文本的第一行添加一个用于定义的任务。
Smart Insert Mode是一个状态菜单项,用于打开和关闭智能插入模式,当智能插入模式关闭后,Eclipse编辑器的一些智能编辑功能(例如智能缩进、括号自动补齐等)就会被禁用。
Show Tooltip Description菜单项显示当前光标位置对象的快捷描述,与鼠标悬停在该位置时出现的提示一样。
Content Assist菜单项提供对当前编辑位置进行内容帮助,即程序员在输入某名称时只需要输入部分内容,然后激活内容帮助,编辑器就会弹出一个候选输入内容的列表供程序员选择;Word Completion菜单项提供对当前编辑字符串的自动补全。Quick Fix菜单项可以提供自动修复当前编辑文件中错误的方法列表供程序员选择;当编辑文件中有错误时,编辑器会在对应位置的代码下标红;当光标在标红位置时使用该菜单项即可获得Eclipse建议的用于解决该问题的一系列方案,程序员在选择了某建议方案后编辑器就会按照选择的方案自动修复该错误。
Set Encoding…菜单项用于在编辑文本内容的文件时,显示和设置当前文本的字符编码。
3.Source菜单
Source菜单如图4.8所示。
Source菜单提供了与源代码编辑相关的操作,包括源代码自动生成、源代码格式整理等,特别是提供了自动生成一些固定用途Java代码段的功能。
Toggle Comment菜单项注释光标所在行或选中的所有行,即在行前加 //。Add Block Comment菜单项表示当一个代码块被选中时变为可用,它用于注释一个代码块,即用/*…*/注释代码块。Remove Block Comment菜单项用于删除一个注释的代码块,是Add Block Comment的逆操作。 Generate Element Comment菜单项用于为光标所在的代码对象添加注释模板,例如方法或类,添加的模板根据代码对象的不同格式会有不同。
Shift Right 、Shift Left和Correct Indentation菜单项都用于调整代码的缩进。Shift Right将光标所在行或选中的所有行的缩进向右调整一格,Shift Left则刚好相反。Correct Indentation按照代码的层次结构调整光标所在行或者选中行的缩进格式。Format菜单项根据Code Formatter preference的设置对选中的所有代码进行格式化,如果没有选择任何代码则对整个文件中的代码进行格式化。Format Element对光标所在的最内层一个代码块进行格式化。

图4.8 Source菜单
Add Import菜单项为当前选择的对象添加Import声明;如果代码中有某个使用的类型没有添加Import声明,编辑器会自动在该位置下标红,将光标放在没有添加Import声明的类型上然后使用该菜单就会自动添加该类型的Import声明;如果可能添加的类型不唯一,则Eclipse会弹出一个备选列表供程序员选择。Organize Imports菜单项对Import声明进行重新组织,包括添加需要的Import声明、删除不需要的Import声明、按照Organize Imports preference的设置将所有的Import语句进行排序和规整。 Sort Members菜单项根据Member Sort Order preference的设置对成员进行排序,使成员按规定顺序排列。Clean up菜单项根据Clean Up preference的设置对代码进行清理。
【注意】
Eclipse开发环境的设置界面可以使用菜单Window → Preferences打开,这里可以设置Eclipse编辑器的属性和插件的属性。所有Java相关的设置都是JDT插件的属性,Code Formatter preference、Organize Imports preference和Clean Up preference都在Java设置中的Code Style中进行设置。Member Sort Order preference在Java设置中的Appearance中进行设置。其中Code Formatter preference设置是比较常用的设置,它可以定义Java代码的编码风格(比如if语句的左括号是否与if处在同一行、赋值语句的=前是否留空格、每行代码的最大长度等),定义好后在编辑代码时程序员只需要使用该菜单项就可以格式化代码,使代码保持与用户设置的格式一致,使程序员编写的所有代码保持一种风格,而且Java开发团队也可以通过共享代码格式的设置使团队中所有程序员编写的代码保持一致的风格。关于Eclipse中的常用设置会在本章后面部分进行介绍。
Override/Implement Methods…菜单项打开Override Method对话框,提供快捷途径以重写父类或父接口中的方法。Generate Getter and Setter…菜单项打开Generate Getters and Setters对话框,提供快捷途径为类的属性成员生成get和set方法。Generate Delegate Methods…菜单项打开Generate Delegate Methods对话框,提供快捷方式为类的方法(包括从父类继承的方法)创建代理方法。Generate hashCode() and equals()…菜单项打开Generate hashCode() and equals()对话框,提供快捷途径为类创建hashCode()方法和equals()方法。Generate Constructor using Fields…菜单项打开Generate Constructor using Fields对话框,提供快捷途径为类创建构造函数,而且生成的构造函数可以包含参数用于初始化指定的类属性成员。Generate Constructor from Superclass…打开Generate Constructor from Superclass对话框,提供快捷途径为类生成与父类构造函数具有相同参数的构造函数,并且在构造函数体内调用父类的构造函数。
Surround With菜单项提供快捷方式为选定的代码块增加包围的语句,例如:用try/catch块包围选定代码块、将代码块放置在if语句中。
Externalize Strings菜单项打开外部化字符串(Externalize String)向导,该向导提供快捷途径将代码中的所有字符串通过配置文件读入,并且自动生成配置文件和读取配置文件的类;当代码需要国际化时使用该方法可以很方便地提供支持字符串国际化的程序框架。Find Broken Externalized Strings菜单项在指定的属性文件、包、工程或工程集中寻找损坏的外部化字符串。
4.Refactor菜单
Refactor菜单如图4.9所示。
Refactor是“重构”的意思,重构是一种重新组织代码以使代码更容易理解和更容易扩展的技术;重构技术定义了一系列改变代码组织方式和展示方式的步骤。Eclipse在这个版本中加强了对重构技术的支持,该菜单中的菜单项提供了对多种重构步骤的支持。
5.Navigate菜单
Navigate菜单如图4.10所示。
Navigate菜单提供了一些方便的方法用于在工程中的类之间、文件中的行之间、各编辑点之间切换,以及打开文件等功能。常用的有:
Go Into菜单项表示进入选中的目录。Go To菜单项提供将焦点在浏览区或文件代码内跳转的功能,例如:Go To→Type…子菜单打开Go To Type对话框,键入类型(类、接口等)名可以将浏览区的焦点跳转到指定的类型;Go To→Next Member子菜单将光标在文件编辑区中跳转到类的下一个成员的位置。
当光标处在某个变量位置或选中某个变量时,Open Declaration菜单项跳转到该变量的声明处(可能在一个文件内也可能在另外一个文件中)。当光标处在某个类名的位置或选中某个类名时,Open Type Hierarchy菜单项打开Hierarchy视图,视图中将显示该类的继承层次结构。
Open Type菜单项打开Open Type对话框,在该对话框中输入类型名,可以在文件编辑区打开指定的类型,该类型可以是工作空间中或当前类路径中存在的类或者接口。Open Type in Hierarchy…菜单项打开Open Type in Hierarchy对话框,在该对话框中输入类型名,可以在Hierarchy视图中展示指定类型的类继承层次结构。Open Resource…菜单项打开Open Resource对话框,在该对话框中输入文件名可以在文件编辑区打开任意类型的文件,该文件可以是工作空间中或当前类路径中可以搜索到的任意文件。
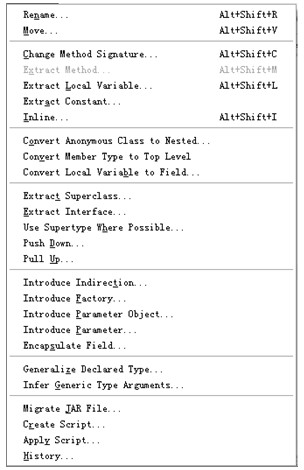
图4.9 Refactor菜单
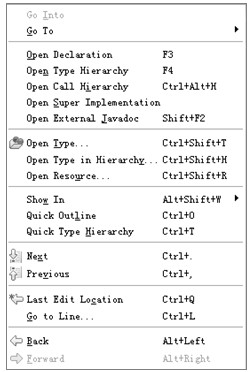
图4.10 Navigate菜单
Show In菜单项可以展示光标所在的方法或类在浏览区中的位置,可以在包浏览器中展示也可以在导航视图中展示。Quick Outline菜单项打开当前编辑文件的内容结构对话框,并且可以通过在对话框中输入成员名将焦点切换到该成员。Quick Type Hierarchy菜单项打开当前编辑文件的继承层次结构对话框。Last Edit Location菜单项将光标和焦点跳转到上一个编辑位置。Go To Line…菜单项打开Go To Line对话框,在对话框中输入行号即可跳转到指定行。
Back菜单项跳转到前一个编辑点,与Last Edit Location菜单项不同的是,该菜单项可以不断地往前面的编辑点跳转。Forward菜单项只有当使用过Back菜单项后才可用,它跳转到后一个编辑点,与Back相反。
6.Search菜单
Search菜单如图4.11所示。
Search菜单提供了在工作空间中的强大搜索功能。常用的菜单项如下。
Search…菜单项打开通用搜索对话框,该对话框提供了文件搜索、Java搜索和插件搜索,文件搜索可以搜索任意字符串并且可以指定待搜索的文件类型;Java搜索提供对Java类型、Java包、Java域、Java方法和Java构造函数的搜索;插件搜索提供对插件、插件Fragment和扩展点的搜索。另外,这三种搜索模式都可以指定待搜索的范围,包括:工作空间、工程、工程集等。File…菜单项提供了打开文件搜索的快捷方式。Java…菜单项提供了打开Java搜索的快捷方式。
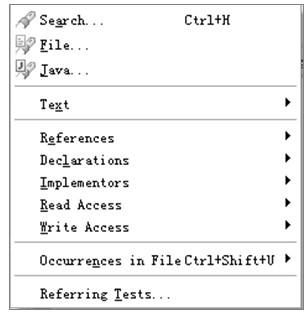
图4.11 Search菜单
Text菜单项包括Workspace、Project、File和Working Set…子菜单项,分别表示在工作空间、工程、当前文件和工程集合中搜索光标所在字符串或选中的字符串。
References子菜单项也包括以上四个子菜单项,表示搜索选择字符串的所有引用。Declarations子菜单项表示搜索选择字符串的所有声明。当选择的内容是一个接口时,Implementors子菜单项表示搜索选定接口的所有实现。Read Access子菜单项表示搜索对选定变量读访问的位置。Write Access子菜单项表示搜索对选定变量写访问的位置。
Occurrences in File菜单项在当前文件中搜索选定Java元素的所有出现。
Referring Tests…菜单项搜索所有引用了选定Java元素的JUnit单元测试。
7.Project菜单
Project菜单如图4.12所示。

图4.12 Project菜单
Project菜单提供了查看工程信息和一些对工程和工程集的操作,其具体的菜单项如下。
Open Project和Close Project菜单项只有当选中浏览区的某个工程时才可用。Open Project当选中已关闭的工程时可用,它将打开选中的工程。Close Project当选中打开的工程时可用,它将关闭选中的工程。
Build All、Build Project和Build Working Set的子菜单项只有当Build Automatically菜单项没有被选中时才可用。Build Automatically菜单项表示自动对工程构建,被选中时Eclipse会在适当的时候自动对工程进行构建。当自动构建被关闭后,才需要手动激发构建动作。Build All菜单项激发对所有已打开工程进行构建;Build Project菜单项激发对选中工程进行构建;Build Working Set菜单项激发对设置的工作集进行构建,其子菜单项打开工作集设置对话框。Clean...菜单项清除工程中的构建结果,即将所有的编译输出清除,典型的就是清除所有的class文件;该菜单项打开Clean对话框用于选择待清除的工程或者清除全部工程。
Generate Javadoc...菜单项打开Generate Javadoc对话框,用于为工程中的代码生成Javadoc文档。Convert to a Dynamic Web project...菜单项只有当一个静态Web工程被选中时才可用,它将静态Web工程转换为动态Web工程,实际上就是将静态Web工程的目录结构和配置换成一个典型的动态Web工程的目录结构和配置。
Properties菜单项打开选中工程的属性,包括:该工程的路径、工程的编码、工程的Java构建类路径、工程的特殊编码格式规范等。在打开的属性窗口中可以查看和设置工程的这些属性。
8.Run菜单
Run菜单如图4.13所示。
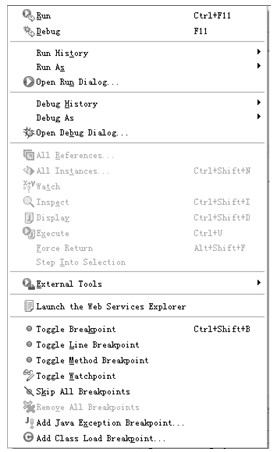
图4.13 Run菜单
Run菜单提供一些与运行和调试代码的菜单项,编辑状态和调试状态的菜单项会有不同,图4.13中展示的是编辑状态的Run菜单内容,常用的菜单项如下。
Run菜单项运行最近一次的运行记录,如果没有最近一次运行记录则弹出Run As对话框选择运行类型。Debug菜单项以调试模式运行最近一次的运行记录。
Run History菜单项的每一个子菜单项都是一条历史运行记录,选择任何一个子菜单项可以再次运行该运行记录。Run AS菜单项的子菜单项是当前文件的可运行类型(例如,Java应用、Java Applet、JUnit等),通过选择子菜单项可以将当前文件作为该种可运行类型运行。Open Run Dialog...菜单项打开Run对话框,在该对话框中可以新建和配置一条运行记录,例如:指定运行的main函数类、添加运行参数、指定运行的类路径、指定运行时的环境变量等。
Debug History菜单项和Debug As菜单项同Run History菜单项和Run As菜单项类似,只不过前者都是以调试模式启动运行的。Open Debug Dialog...菜单项打开Debug对话框用于新建和配置debug运行记录,这里的设置与Run对话框中的一样。
下面从All References...到Step Into Selection的一些列菜单项只在调试代码时才可用。All References...菜单项用一个弹出窗口展示当前虚拟机中所有对选中类型的引用。All Instances...菜单项用一个弹出窗口展示选中类型当前在虚拟机中的所有实例。Watch菜单项在Expression视图中展示选中变量(或表达式)的当前值。Inspect菜单项用弹出窗口展示选中变量(或表达式)的当前值。Display菜单项用弹出窗口展示选中变量(或表达式)的类型。Excute菜单项执行选中的表达式。Force Return菜单项在当前执行处强制返回正在执行的方法。
Toggle Breakpoint菜单项在光标所在位置添加/取消适当类型的断点,根据位置不同添加的断点类型不同。Toggle Line Breakpoint菜单项在光标所在位置添加/取消行断点。Toggle Method Breakpoint菜单项在光标所在位置添加/取消方法断点。Toggle Watchpoint菜单项为选中域添加观察点,即当该域被访问(包括修改和读取)时就会产生一个断点。Skip All Breakpoints菜单项是一个状态菜单项,一旦被选中则使所有断点失效(但不删除断点,当该菜单项被选掉时所有断点又会生效)。Remove All Breakpoint菜单项删除工程中的所有断点,该操作不可恢复。Add Java Exception Breakpoint...菜单项打开Add Java Exception Breakpoint对话框,在对话框中可以选择任意的异常类型(包括用户自定义的异常类型)并添加,那么当处于调试运行模式时每次在抛出该类型异常的位置就会产生一个断点。Add Class Load Breakpoint...菜单项打开Add Class Load Breakpoint对话框,在该对话框中选择一个Java类型可以为其添加类装载断点,即处在调试模式下当每次装载该类时产生一个断点。
9.Window菜单
Window菜单如图4.14所示。
Window菜单提供了一些打开/关闭界面窗口和对界面窗口进行设置的菜单。主要还提供了对透视图(Perspective)和视图(View)的管理和设置。透视图和视图是Java界面中的重要该面,视图表示一种界面窗口,用于显示特定的内容,例如浏览区的包浏览器(Package Explorer)是一种视图、提纲显示区的文件结构(Outline)是一种视图等。透视图是一种视图的组合方式,例如本节开始的Eclipse界面展示的是Java透视图,这是最常用的一种透视图。本章后面内容将会对透视图和视图进行详细介绍。
New Window菜单项重新打开一个Eclipse窗口。New Editor菜单项重新打开一个文件编辑窗口。
Open Perspective菜单项打开一个透视图,即在透视图选择区添加一个透视图。Show View菜单项打开一个视图。Customize Perspective...菜单项设置当前透视图。Save Perspective As...菜单项将当前透视图另存为一个透视图。Reset Perspective菜单项重置当前透视图为默认设置。Close Perspective菜单项关闭当前透视图。Close All Perspective菜单项关闭透视图选择区中所有已打开的透视图。
Navigation菜单项提供了一些界面窗口之间导航的功能,例如,通过输入名称快速打开一个视图或透视图、最大化/最小化视图或编辑器、前一个/后一个编辑器、前一个/后一个视图、前一个/后一个透视图,等等。
Working Sets菜单项可以新建/编辑/删除工作集。
Web Browser菜单项可以设置默认打开的浏览器。
Preferences...菜单项打开Preferences对话框,该对话框用于对Eclipse开发环境和Eclipse中安装的插件的设置。本章后面的内容会对其中常用的设置进行介绍。
10.Help菜单
Help菜单如图4.15所示。

图4.14 Window菜单
图4.15 Help菜单
Help菜单提供了一些辅助的帮助信息,其菜单项如下。
Welcome菜单项打开Eclipse的欢迎界面。
Help Contents菜单项打开Eclipse系统的帮助文档窗口。Search菜单项在Eclipse界面内打开帮助搜索视图,在其中可以通过关键字搜索帮助文档。Dynamic Help菜单项打开动态帮助视图,该视图根据程序员当前进行的动作动态地更新其中的帮助链接。
Key Assist...菜单项弹出对话框展示当前系统中配置的快捷键和对应动作的对应表。Tips and Tricks...菜单项提供快捷途径打开关于平台或Java编辑器的使用技巧帮助文档。Cheat Sheets...菜单项提供快捷途径打开一些便条(Cheat Sheet),其中主要提供了一些构建应用的向导。
Software Updates菜单项在线检查Eclipse官方网站上的更新信息,并且支持在线更新。
About Eclipse SDK菜单项打开关于Eclipse平台的简单信息,包括版本号、Build ID以及版权说明等信息。
Eclipse提供了强大的可配置功能,Eclipse开发平台和Eclipse插件提供的属性都可以通过方便的界面进行配置。用于配置Eclipse平台和插件的窗口可以通过Eclipse菜单的Window→Preferences...菜单项打开,配置窗口如图4.16所示。
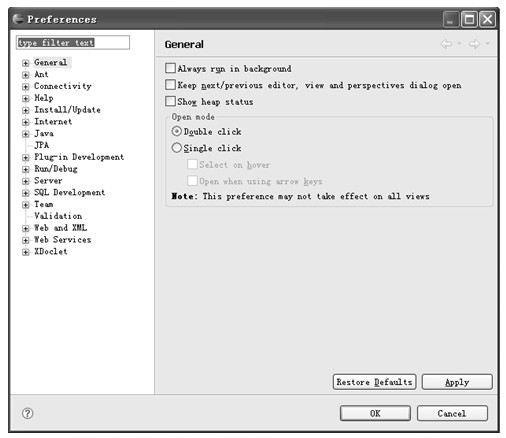
图4.16 Eclipse配置主窗口
如图4.16所示,Eclipse中几乎所有的可配置项和所有插件的可配置项都在Preferences对话框中进行设置。不带WTP插件的Eclipse只提供了Eclipse平台的设置以及Eclipse平台自带插件(如:Java开发插件和Plug-in开发插件等)的设置。本书介绍的WTP-Eclipse在这些设置的基础上又增加了WTP插件的设置,其中包括很多对Web开发工具的设置和J2EE开发工具的设置。本节将对其中比较常用的一些设置进行简单介绍,包括:Eclipse平台的设置、Java开发工具的设置、Web开发工具的设置等。
Eclipse开发平台为许多操作定义了快捷键,在前面介绍菜单时已经发现有些菜单项上已经标记了所使用的快捷键,而且通过Help→Key Assist...菜单可以打开所有当前已绑定了快捷键的命令以及其所使用的快捷键。Eclipse中快捷键的设置在Preferences对话框的General→Keys配置页中,如图4.17所示。
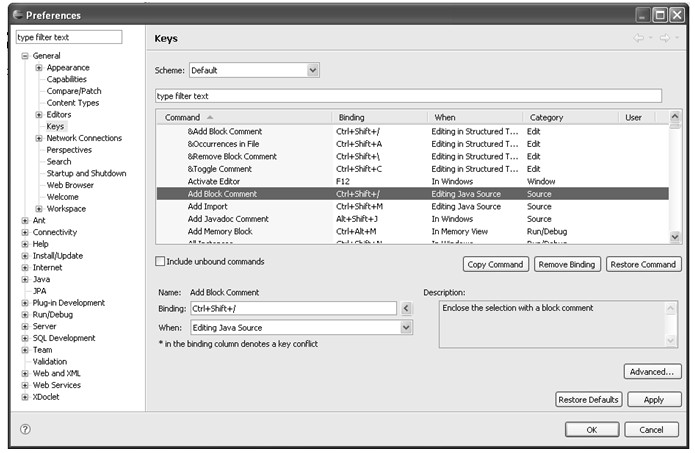
图4.17 快捷键配置项
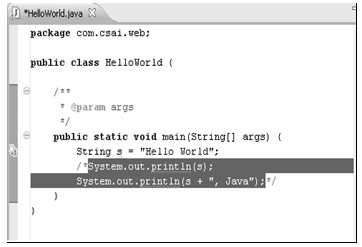
所有的命令与快捷键对应关系的定义都在图中的列表里,每一行定义了一条命令和快捷键的绑定记录。Command列表示命令,即快捷键所做的动作;Binding列就表示该命令所使用的快捷键;When列表示该快捷键在什么情况下激发该命令;Category列表示该命令动作的类型。以图4.17中选中的这条记录为例,命令为Add Block Comment(添加块注释),快捷键为Ctrl+Shift+/,激发条件是在Editing Java Source(编辑Java代码)时,命令动作的类型是Source(源代码)类型,因为该命令的行为与编辑源代码有关。该快捷键的效果如图4.18所示:
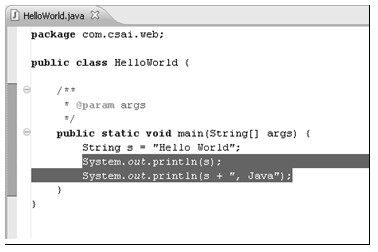
a)选中待注释代码块
b)按下快捷键后自动进行注释
图4.18 使用快捷键进行块注释
在编辑Java代码时,选中一段代码,如a)图所示,然后使用快捷键Ctrl+Shift+/,结果如b)图所示,即为选中的代码段加上了块注释。
在该快捷键配置窗口中,用户可以删除快捷键绑定、更改快捷键、复制新的快捷键、为没有绑定快捷键的命令绑定快捷键等操作,具体操作如下。
1.显示所有命令所对应的快捷键
默认状态下命令和快捷键的绑定列表中只显示已绑定了快捷键的命令,选中界面中的Include unbound commands可以打开没有绑定快捷键的命令。
2.查看命令描述
选中任何一条记录,未绑定快捷键记录或已绑定快捷键记录,在Description栏所显示的就是对该命令的描述。
3.删除快捷键的绑定
选中一条已绑定快捷键记录,单击Remove Binding按钮就可以删除该快捷键同该命令的绑定关系,将该记录变成一条未绑定快捷键记录。
4.修改绑定的快捷键
选中一条已绑定快捷键记录,删除Binding文本输入框中的内容,然后直接在键盘上按下想要设置的快捷键即可(注意不是输入快捷键的名称,而是直接按下快捷键,Eclipse会自动检测按下的键)。并且还可以在When输入框的下拉列表中选择新的快捷键应用场景。
5.为未绑定快捷键记录指定快捷键
选中一条未绑定快捷键记录,使用与修改绑定快捷键相同的方式在Binding输入框和When输出框中输入适当的内容。
6.复制命令
选中一条已绑定快捷键记录,单击Copy Binding按钮可以在选中记录下增加一条新的未绑定快捷键记录,并且该记录的命令和类型与选中记录相同。
7.恢复成默认设置
选中一个记录,单击Restore Command按钮可以将该命令的快捷键设置恢复为Eclipse的默认设置;单击界面右下角的Restore Defaults按钮可以将所有命令的快捷键设置恢复为Eclipse的默认设置。
在编写Java代码时,很多应用可能需要引入第三方的库(除自己编写的代码和Java提供的库之外的库),尤其是在使用J2EE编写Java Web应用时可能需要引入很多jar包。当需要引入的jar文件多了以后,程序员自己可能都很难记清楚所有jar文件的用途;而且在编写有些类型的应用时需要同时引入几个jar文件(比如,编写Struts2应用时需要同时引入struts2-core.jar、xwork.jar、struts2-api.jar等库文件),当这种库集合越来越多后程序员很难记住做某种应用需要用哪几个jar文件。Eclipse中提供了一个管理用户库的工具,程序员可以在这里定义用户库文件,然后在工程中直接加入该用户库就可以自动将用户库中包含的jar文件添加到工程的类路径中。
用户库在Preference对话框中的Java→Build Path→User Libraries中定义。界面如图4.19所示。
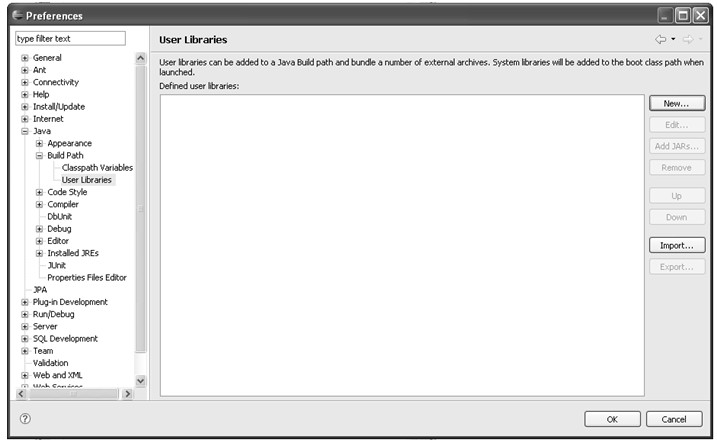
图4.19 用户库定义配置项
初始状态下中间的用户库列表是空的,因为默认是没有任何用户库定义的。单击New...按钮会弹出New User Library对话框,在对话框的User library name输入框中输入用户库的名称,确定后就可以在用户库列表中添加一个新的库,如图4.20所示。
在图4.20中,UserLib是新定义的用户库的名称,选中UserLib可以对其进行操作。Edit...按钮可以重命名用户库的名称;Add JARS...按钮打开文件选择对话框,从中选择jar文件或者zip文件添加到用户库中。Remove按钮可以删除该用户库。当有多个用户库在列表中时,Up按钮和Down按钮可以调整用户库中包含库文件的先后顺序。
Import按钮和Export按钮用于导入和导出用户库。单击Export按钮会弹出Export User Libraries对话框,在该对话框中选择用户库列表中的用户库并且指定一个本地的文件路径,该对话框会将选择的用户库的配置信息导出到指定的文件中,文件类型为*.userlibraries;Import...按钮则恰好与Export...相反,该按钮打开Import User Libraries对话框,该对话框中选择一个本地的*.userlibraries文件,对话框会将该文件中的用户库导入到用户库列表中。
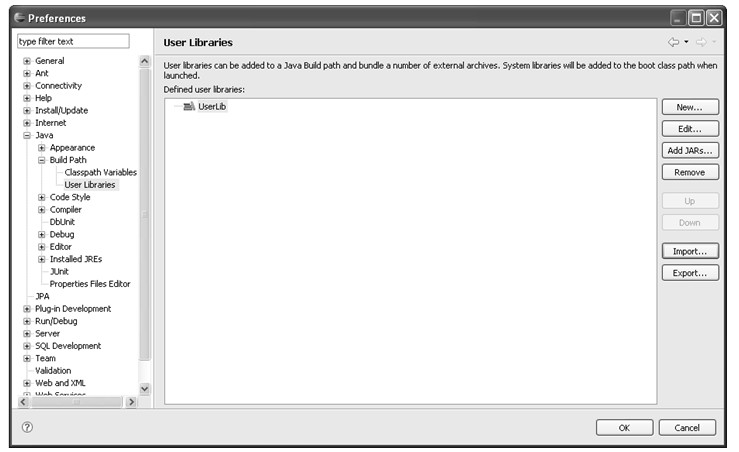
图4.20 完成用户库定义
在前面介绍Source菜单时,提到了Source菜单中的Clean up...菜单项根据Clean up preference的配置对代码进行清理。代码清理工作主要是对代码中的多余代码进行清除,或者重新组织代码的结构等,使得代码更加简洁、更加清晰。
Clean up配置项主页如图4.21所示。
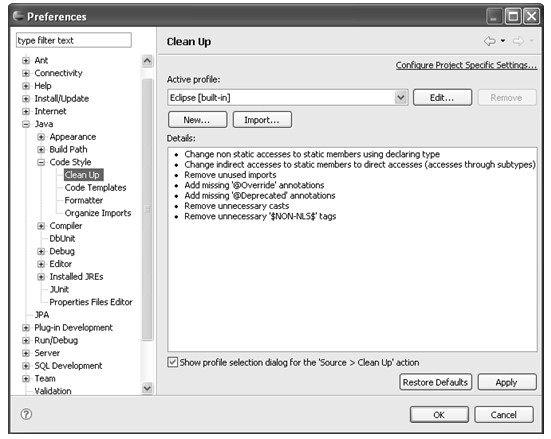
图4.21 Clean up配置项主页
其中Active profile的下拉菜单中列出了当前已有的所有Clean up配置记录,每条记录定义了一套清理代码的方式,在用户未进行任何操作前这里只有Eclipse提供的一条默认记录,即Eclipse[built-in]。用户可以通过New...按钮新建Clean up配置记录,也可以通过Import...按钮导入已定义好的Clean up配置记录。新建配置记录的各项设置都采用默认设置。
用户可以对任何一个配置记录进行配置,步骤是在Active profile的下拉列表中选择待编辑的配置记录,然后单击Edit...按钮,会弹出如图4.22所示的配置对话框。
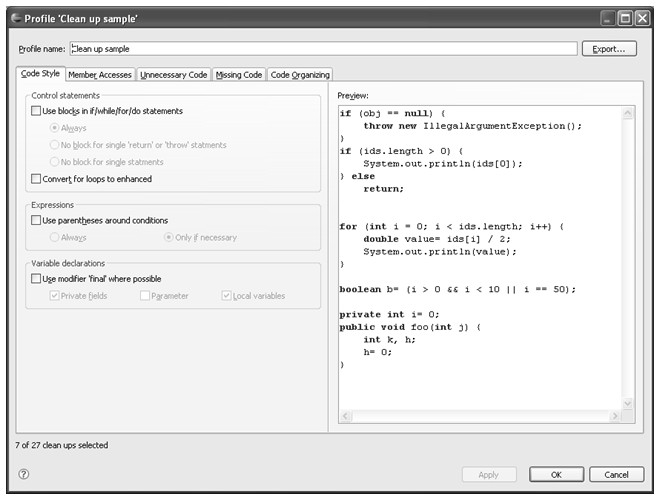
图4.22 定义Clean up属性文件
如图4.22所示,Clean up的配置项中有5个方面的配置:代码风格(Code Style)、成员访问(Member Accesses)、不必要的代码(Unnecessary Code)、缺失代码(Missing Code)和代码组织(Code Organizing)。每个方面配置页的左边都是可配置的项,右边都是当前配置的效果展示;当更改左边的配置项时,右边的效果展示会同时改变以展示当前配置项更改后的代码效果。
1.Code Style
该配置项提供给用户配置一些代码组织的风格,在意义相同的代码风格之间选择一个用户首选的风格。
Use blocks in if/while/for/do statements用于说明当if/while/for/do语句的代码体只有一条语句时,用户是否希望将该语句体加上大括号。Always表示不管什么情况都加上;No block for single ‘return’ or ‘throw’ statements表示当这一条语句是return语句或throw语句时不加大括号;No block for single statement表示不管这一条语句是什么语句都不加括号。
Convert for loops to enhanced用于说明是否将采用循环变量的循环形式转化为采用迭代的循环形式,示例如下:
循环变量形式迭代形式
for (int i = 0; i < dbArray.length; i++) {
double value= dbArray [i] / 2;
System.out.println(value);
}for (int element : dbArray) {
double value= element / 2;
System.out.println(value);
}
Use parentheses around conditions用于说明在什么情况下为条件语句加上括号。Always表示为所有的条件语句都加上括号;Only if necessary表示只在必要时加上括号。
Use modifier ‘final’ where possible用于说明如果可以的话在哪些情况下需要加上final修饰符。Private Fields表示为私有域加上;Parameter表示为参数加上;Local variables表示为内部变量加上。
2.Member Accesses
Use ‘this’ qualifier for field access说明在访问域变量时什么情况下需要在域变量前加上this限定符。Always表示所有情况下都加;Only if necessary表示只在必要时加,即只有当有本地有与域变量同名的变量时才加,因为这种情况下如果不加就会产生引用错误。
Use ‘this’ qualifier for method access与上一项类似,它说明在访问类方法时什么情况下需要在方法名前加上this限定符。
Use declaring class as qualifier说明在访问类的静态(static)域或方法时使用什么样的表达方式。Qualify field accesses表示在访问域时是否需要使用类名作为限定符;Qualify method accesses表示在访问方法时是否需要使用类名作为限定符;Change all accesses through subtypes表示是否需要将所有使用定义所在类的子类名作为限定符的表达都改变为使用定义所在类的类名作为限定符;Change all accesses through instances表示是否需要将所有使用实例作为限定符的表达都改变为使用类名作为限定符。
3.Unnecessary Code
Remove unused imports说明是否需要删除所有没有使用的import语句。
Remove unused private members说明需要删除那些没有使用的私有成员。Types表示删除所有没有使用的私有类型(Class、Interface等);Constructors表示删除所有没有使用的私有构造函数;Fields表示删除所有没有使用的私有域;Methods表示删除所有没有使用的私有方法。
Remove unused local variables说明是否需要删除所有没有使用的局部变量。
Remove unnecessary casts说明是否需要删除所有不必要的类型转换。
Remove unnecessary ‘$NON-NLS’ tags说明是否需要删除所有不必要的‘$NON-NLS’标记。
【注】
‘$NON-NLS’标记是一类作为提示的特殊标记,它们是以注释形式出现在Java代码中的标记。前面提到过Eclipse提供了Externalize String向导,支持自动将代码中的所有字符串外部化到一个配置文件中以支持字符串的可配置性。该标记就用于提示Java编译器和外部化向导具有该标记的行中的字符串不需要进行外部化。
4.Missing Code
Add Missing Annotations说明是否要增加缺失的注记(Annotation),这里只支持@Override和@Deprecated注记。注记在代码中只起到辅助作用,它们不会影响Java代码的编译和执行。
Add serial version ID说明是否需要增加缺失的序列化版本号(serial version ID)。Generated表示生成一个版本号并增加;Default(1L)表示增加默认的版本号(1L)。序列化版本号是实现了Serializable接口的类的一个域,它用于在序列化对象时使对象的更改情况可控。
5.Code Orginazing
Format source code说明在执行Clean up时是否对代码同时执行Format操作。
Remove trailing whitespace说明是否去掉行末的空白字符。All Lines表示去掉所有行末的空白字符包括空行中的空白字符;Ignore empty lines表示只去掉非空行的行末空白字符。
Organize imports说明在执行Clean up时是否对代码同时执行Organize imports操作。
Sort members说明在执行Clean up时是否对代码同时执行Sort members操作。Sort all members表示对所有成员都进行排序;Ignore fields and enum constants表示只对除域和枚举常量外的成员进行排序。
在为Java代码中的某种程序元素(如:类、域、方法等)添加注释时或者在生成某种新的程序元素(如:类、get方法、catch语句等)时Eclipse会自动生成一个注释模板或程序元素内容模板。而且,Eclipse还支持对这些模板进行定制,可以在Java→Code Style→Code Templates中进行设置,如图4.23所示:
如图4.23所示,右面窗口上面的列表列出了所有可以设置的模板项,当点击一个模板项时,该模板的内容会在下面的文本框中显示。如果用户想更改某模板的内容,可以选择某模板然后单击Edit按钮,这样会打开模板编辑器,用户可以直接在编辑器中输入模板的内容即可。
模板中形如${variable}的内容是一种对变量的引用,其中variable是Eclipse定义的一种变量,它随使用场景而改变,例如,${user}的值是当前系统的用户名,${date}的值是当前系统时间等。Edit...按钮打开的模板编辑器对话框左下角有图标 ,单击该图标可以打开动态帮助,在动态帮助中有对每个variable具体意义的解释。
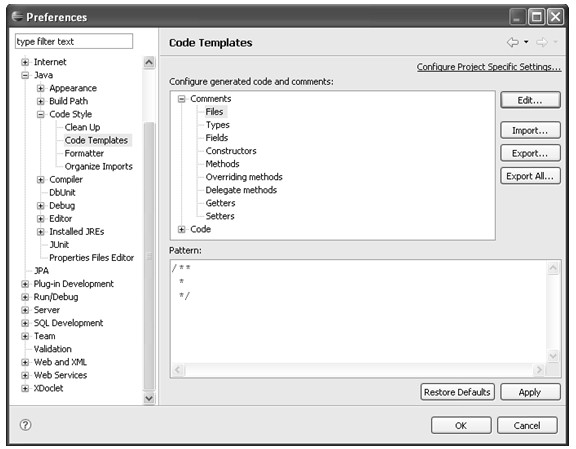
图4.23 代码模板配置项
在前面介绍菜单时提到Source→Format菜单可以根据Code Formatter preference的设置对选中的所有代码进行格式化,这个功能有助于保持编程风格的统一。Code Formatter preference在Preferences中的Java→Code Style→Formatter中设置,设置的主页面如图4.24所示。
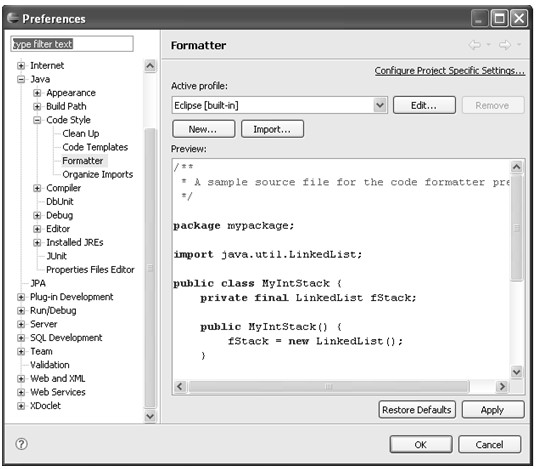
图4.24 代码格式化配置项
同Clean up的配置一样,该页面的Active profile文本框中显示的是当前系统中使用的Formatter的配置,下拉列表中列出了所有可用的配置。New...按钮可以新建配置、Import...按钮可以导入外部的配置文件(XML文件)、Edit...按钮对当前系统使用的配置进行编辑。
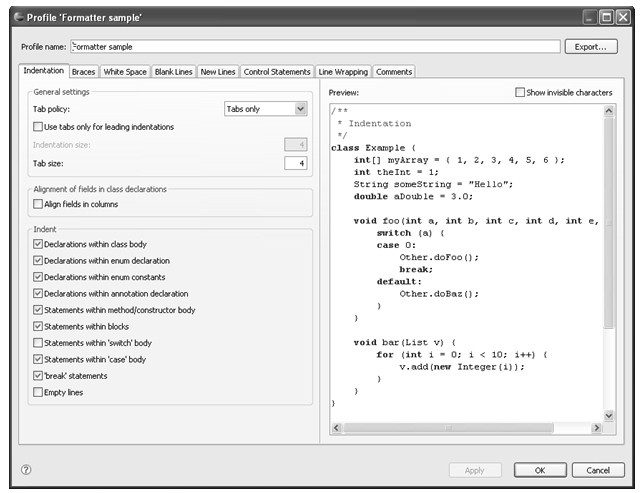
图4.25 定义格式化属性文件
图4.25为定义格式化属性文件,其中Formatter包含了八类配置项:Indentation、Braces、White Space、Blank Lines、New Lines、Control Statements、Line Wrapping、Comments。
1.Indentation
该类配置主要说明了一些对缩进的配置,包括:缩进的格式以及哪些地方需要缩进等。其中,Tab policy说明使用Tab键还是空格键进行缩进。Use tabs only for leading indentations说明是否只对leading indentation使用tab。Indentation size和Tab size说明缩进的字符数。
Align fields in columns说明类声明中的域名称是否需要使用tab对齐。
在Indent组合框中的所有复选框都用于说明在所描述的情况下是否需要缩进,例如:Declarations within class body表示在类内的声明行是否需要相对类的声明行向后缩进一级;Statements within method/constructor body表示在方法或构造函数体内的语句是否需要相对于方法的声明行向后缩进一级。
2.Braces
Braces类配置规定了在各种出现大括号的场合中大括号的位置。可选择的位置有四类:
Same line:表示大括号与声明或者语句的前面部分在同一行。一般都是指左大括号,因为大括号内如果有新的语句,那么新的语句都会另起一行。
Next line:表示大括号另起一行。
Next line indented:表示大括号另起一行,而且在上一行的基础上缩进一级。
Next line on wrap:表示如果语句出现截断时大括号另起一行,不出现截断时大括号不另起一行,如下所示:
Class This_is_a_very_long_class_name
extends SomeClass
{
...
}class ShortName extends SomeClass {
...
}
a)Next line on wrap示例b)Same line on no wrap示例
该类配置中的所有配置项都表示了一种出现大括号的场合,后面选择相应的值就表示在该种场合下大括号应该出现的情况。例如:Class or interface declaration表示在类或者接口声明中的大括号,Anonymous class declaration表示匿名类声明中的大括号,Array initializer表示数组初始化中使用的大括号。
3.White Space
该类配置规定了在什么情况下希望出现空格。例如:Declaration→Classes中选中before opening brace of a class表示在类声明中的左大括号前加上空格;Control statements→‘if else’中选中before opening parenthesis表示在if/else语句中用于括起布尔表达式的左圆括号前加空格。
4.Blank Lines
该类配置规定了在什么情况下希望出现空行。例如:After package declaration设为1表示在包声明行后增加一个空行;Before field declarations设为0表示类内的域定义前不添加空行;Number of empty lines to preserve设为1表示对代码中已存在的连续空行合并为一个空行。
5.New Lines
该类配置规定了在什么情况下希望出现换行,即另起一行。例如:in empty class body表示是否在空的类中添加换行符;Insert new line after opening brace of array initializer表示在数组初始化表达式中是否在左大括号后添加换行符;Put empty statement on new line表示是否在空语句后加上换行符;Insert new line after annotations表示是否在注记后加上换行符。
6.Control Statements
该类配置规定了控制语句(if/else/while/do/try/catch/return/throw等)的一些格式。例如:Insert new line before ‘else’ in an ‘if’ statement表示在if/else语句中是否在else语句前添加换行符;Keep ‘return’ or ‘throw’ clause on one line表示当if或else语句中只有一个return或throw语句时,是否保持该条语句与if或else语句在同一行。
7.Line Wrapping
默认情况下一条语句都用一行表示,但是为了代码结构的清晰和程序员阅读方便,有时需要将一条语句分成多行显示。该类配置规定了在什么情况下将一条语句分成多行。Maximum line width规定了代码中一行最长允许的字符数,当一行代码的字符数多于该值时就对代码分行。Default indentation for wrapped lines规定了当将一行代码分成多行时下一行默认的缩进级数(注意不是字符数)。Default indentation for array initializers规定了在数组初始化中,如果需要分多行时默认的缩进级数。
界面下部的树状列表分别列出了各种情况下希望的分行方式,每种方式都可以在预览栏中看到格式化的效果。
8.Comments
该类配置规定了关于注释的一些格式。Enable Javadoc comment formatting表示是否允许对Javadoc注释格式化,如果该配置项没有选中的话Javadoc comment settings中的各项配置将无法配置。Enable block comment formatting、Enable line comment formatting和Enable header comment formatting分别表示是否对块注释、行注释和头注释格式化。
Javadoc comment settings列出的配置项用于规定如何对Javadoc注释进行格式化,例如:Blank line before Javadoc tags表示在注释中的Javadoc标记前添加空行;Remove blank lines表示去掉注释中所有的空行。
Maximum line width for comments规定了注释中一行所允许的最多字符数,当某注释行超过该长度时就会自动变成多行。
Eclipse提供的代码格式化工具是一个非常强大的工具,它定义的格式项非常的详细,这对于某些对代码格式要求比较严格的团队来说是非常有用的。但是对于初学者来说,建议不要过多地修改格式化的配置项,因为Eclipse内建的格式化配置所提供的默认值都是借鉴了许多成功开发团队的代码格式规范,代表了Java开发领域中的主流风格,初学者应该去适应和习惯这种风格而不是改变这种风格。
在安装了WTP插件的Eclipse中,Preferences配置包含Web and XML配置项,这个配置项提供了对Web开发工具的配置,主要是对Web文件编辑器的一些配置。主要包含CSS文件、DTD文件、HTML文件、JavaScript文件、JSP文件、XML文件等。该配置的主页面如图4.26所示,选择每个子配置项对该项进行配置。
图4.26 Web and XML配置项
从图4.26中可以发现,对各种文件的配置主要分三类:Source、Syntax Coloring和Templates。Source用于配置在编辑文件时的格式化和内容辅助等功能;Syntax Coloring用于配置各种文件中的语法着色,比如关键字的颜色、字符串的颜色等;Templates用于配置一些固定的模板,这些模板可以在编辑文件时被选择用以自动生成特定格式的代码。下面以HTML文件为例对这些配置进行介绍。
1.Source
HTML Files→Source的配置页如图4.27所示:
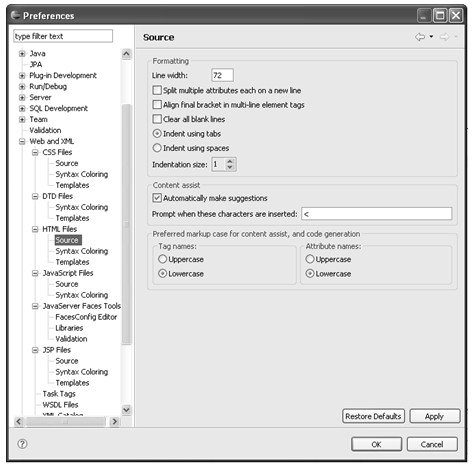
图4.27 Source配置页
Formatting组的配置项主要用于说明HTML文档的一些格式,例如:Line width表示单行最多字符数;Indent using tabs和Indent using spaces用于选择使用tab键进行缩进还是使用空格键进行缩进。
Content assist组的配置项主要用于内容帮助的设置,例如:Automatically make suggestions表示是否自动提供内容建议,当该项被选中时Prompt when these characters are inserted就会变为可编辑状态,其中列出的字符表示当输入这些字符时激发内容帮助。
Preferred markup case for content assist, and code generation组说明,在内容协助和自动生成的代码中希望标签名和属性名使用大写还是小写。
2.Syntax Coloring
HTML Files→Syntax Coloring的配置页如图4.28所示:
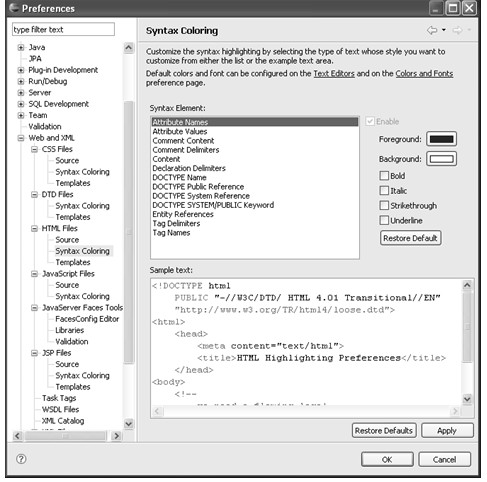
图4.28 Syntax Coloring配置项
在Syntax Element列表框中的每一项就表示一种类型的文字,具体含义如表4.2所示。
表4.2 语法元素含义对照表
选中某一种文字类型,就可以在右边设置该类文字的颜色和属性。其中Foreground表示前景色;Background表示背景色;Bold表示是否加粗;Italic表示是否变成斜体;Strikethrough表示是否加中画线;Underline表示是否加下画线。
1.Templates
HTML→Templates的配置页如图4.29所示。
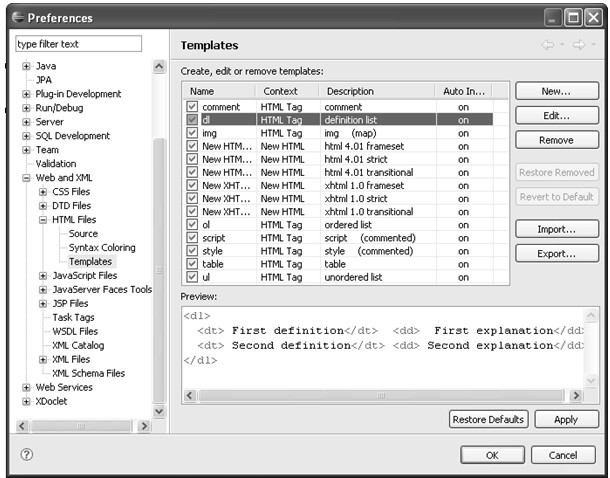
图4.29 Templates配置项
在图4.20的表格中列出了当前定义的所有HTML模板,用户可以通过New...按钮添加新的模板和通过Remove按钮删除已有模板,也可以通过Edit...按钮编辑已存在的模板。
每一个模板都有一个模板名称,在编写HTML文件时,激活内容帮助(Edit→Content Assist或者通过Ctrl+Space快捷键)并输入模板名称,然后选择对应的模板就可以在光标处加入模板的内容。如图4.30所示。
a)激活内容帮助
b)自动添加代码
图4.30 使用内容帮助自动添加代码
Eclipse和WTP插件都提供了许多的配置项,由于篇幅有限,本章只介绍几种比较常用的配置。实际上Eclipse的各项配置都提供了非常通用的默认值,所以初学者可以先不用过多的关注如何配置这些配置项;假如确实需要做相应配置请参阅Eclipse的帮助,在每个配置页都有动态帮助按钮 ,读者可以单击该按钮打开动态帮助进行学习。
在进行插件安装前,有时需要先查看当前已安装了哪些插件,因为有些插件的安装必须要有另外的插件作为前提。通过菜单Help→Software Updates→Manage Configuration可以打开Product Configuration对话框,如图4.31所示。
该对话框中列出了Eclipse当前已安装的所有插件。在左边树列表中单击Eclipse SDK,右边面板会显示针对整个Eclipse的产品配置情况,其中可以扫描Eclipse的在线更新情况、可以查看Eclipse的安装历史等;在树列表中单击任何一个插件(如图4.31中情景)可以查看插件的在线更新情况(Scan for Updates)、可以禁用/启用该插件(Disable,对于已禁用的插件这里会显示Enable)以及显示插件的版本、提供者和许可证等信息(Show Properties)。
图4.31 产品配置对话框
Eclipse插件的安装非常简单,但在安装时要注意插件的依赖关系。Eclipse插件是具有依赖关系的,Eclipse在启动时会按照插件的依赖关系逐个将插件装载,若找不到所依赖的插件,则所安装的插件就有可能运行不正常。
通常在下载插件的根目录中会有plugin.xml文件,该文件中的<requires>标记列出了插件所依赖的其他插件,<requires>的<import>子元素中的内容即表示所依赖插件的ID。一个插件的例子如下所示。
<plugin ... >
...
<requires>
<import plugin="org.eclipse.core.runtime" />
<import plugin="org.eclipse.core.resources" />
<import plugin="org.eclipse.ui" />
<import plugin="org.eclipse.debug.core" />
<import plugin="org.eclipse.swt" />
<import plugin="org.eclipse.jdt.core" />
<import plugin="org.eclipse.jdt.launching" />
<import plugin="org.eclipse.jdt.debug" />
<import plugin="org.eclipse.jdt.ui" />
<import plugin="org.eclipse.debug.ui" />
<import plugin="org.eclipse.jdt.debug.ui" />
<import plugin="org.eclipse.core.runtime.compatibility" optional="true" />
<import plugin="org.eclipse.ui.ide" optional="true" />
<import plugin="org.eclipse.ui.views" optional="true" />
</requires>
...
</plugin>
【注意】
严格来说通常所下载的插件应该是插件集,它里面包含了很多插件(包含其依赖的插件或本身就包含多个插件),所以在插件根目录外还会有外层目录,例如单独下载的WTP插件。包含plugin.xml文件的插件根目录是指某单个插件的根目录。
Eclipse有三种途径安装插件:在线更新、直接复制和链接文件。后两种都需要首先将插件文件下载到本地,第一种则是Eclipse自动从官方网站上下载并且安装。
1.在线更新
Eclipse提供了在线更新功能,Eclipse菜单Help→Software Update→Find and Install...会打开Install/Update对话框,如图4.32所示。
图4.32 Install/Update对话框
如图4.32所示,Search for updates of the currently installed features是搜索和更新当前已安装插件的最新版本;Search for new features to install是搜索和安装当前未安装的插件。如果选择第一项,单击Finish直接开始搜索(可能需要选择镜像站点);如果选择第二项,单击Next>按钮弹出Install对话框,在该对话框中选择想要更新的插件类型,选择后Eclipse更新管理器就只搜索被选择类型的插件。
在搜索结束后,如果有可更新的插件,这些插件就会被列出,用户只需要选择想要更新的插件并且按照指示操作,就可以将选定的插件安装到Eclipse中。
这种插件安装方式不需要提前寻找和下载插件,全界面操作完成安装,而且也不用考虑插件的依赖关系;但是这种方式必须首先获得插件更新的站点,而且只能通过这种更新下载方式,所以搜索和下载速度通常会比较慢而且能够安装的插件也非常有限。
2.直接复制
这种安装方式必须首先已经将插件文件下载到本地文件系统中,然后将已有的插件安装到Eclipse中。
Eclipse安装完成后,根目录内容如图4.33所示。
图4.33 Eclipse安装目录
该目录中的plugins目录用来放置所有的插件文件。Eclipse插件通常的根目录名为插件的包名加上插件的版本号,例如:org.eclipse.sdk_3.3.1.r331_v20070904。将下载插件的根目录直接复制到plugins目录下,重启Eclipse后即可完成该插件的安装。
这种插件安装方式简单易行,不容易出错;但是这种方式将所有插件都复制到plugins目录下,使得该目录过于庞杂,不利于插件的管理和动态加/卸载。
3.链接文件
这种方式是在直接复制的基础上将插件分类进行管理,然后通过链接文件的形式装载到Eclipse中。这种方式是比较好的插件安装方式,建议读者使用这种方式安装和管理Eclipse插件。
首先,在本地文件系统中(可以在Eclipse安装目录中也可以在Eclipse安装目录外)新建一个文件夹(例如在Eclipse根目录中新建MyPlugins目录)用于放置所有的Eclipse插件。
其次,为待安装插件(假设根目录为org.webtools.sdk_2.1_v20071210)取一个便于记忆和识别的名称(例如,WebTools),以该名称在MyPlugins目录中新建一个目录并且将插件根目录复制到该目录中。
然后,在Eclipse根目录中新建一个links目录,在该目录中新建一个*.link文件(例如,webtools.link),在该文件中加入一行path=MyPlugins/WebTools(假定MyPlugins目录在Eclipse根目录中),保存并关闭。
最后,重启Eclipse即可完成插件的安装。
这种安装插件的方式有利于分类管理插件,并且可以方便地卸/加载插件。当有新插件需要安装到Eclipse中时,可以在MyPlugins中建立该插件的目录,同时在links目录中新建和编辑新的link文件或在已存在的link文件中添加一个新行即可。当想卸载某个已安装的插件时,有很多方法:改变该插件对应link文件的后缀(改变为除link的其他值)、清除link文件中对应的行或将link文件移至其他目录等方式,只要使Eclipse无法在links目录中发现该插件即可。
本章对Eclipse的界面、常用配置以及Eclipse插件的安装进行了简单的介绍。
Eclipse中用于显示特定内容的窗口称为视图,视图的组织和布局方式称为透视图,Eclipse常用的透视图有Java、Debug等。
Eclipse的配置对话框通过Window→Preferences菜单打开,Eclipse及其所安装的所有插件都可以在该对话框中进行设置,最常用的配置项有:General→Keys用于配置快捷键;Java→Build Path→User Libraries用于配置用户自定义的库;Java→Code Style→Clean Up用于配置代码清理命令的操作原则;Java→Code Style→Code Templates用于配置自定义代码模板,可以在编辑代码时输入模板;Java→Code Style→Formatter用于定义和配置Java代码格式化的操作原则,在使用格式化命令时使用;Web and XML主要包括了对Web开发插件集的配置。
通过菜单Help→Software Updates→Manage Configuration可以浏览当前已安装的插件;安装Eclipse插件有三种方式:在线更新、直接复制和链接文件。
Eclipse为Java Web应用提供了专属集成开发环境,提供了Web工程管理、Web对象辅助开发等功能。本章将介绍在Eclipse中建立和配置Web工程的方法以及如何使用Eclipse开发各种Web对象。
本章在介绍使用Eclipse开发JSP和Servlet对象时会涉及一些JSP和Servlet的相关知识,对JSP和Servlet不了解的读者可以先大略了解,如有不懂可等学习了第8章和第9章后再结合学习这部分内容。
同其他大多数集成开发环境一样,Eclipse将应用程序的开发组织成工程进行管理,不同的工程用于开发不同的应用程序。在前面已经介绍过File→New→Project…菜单打开New Project菜单,该菜单中列出了各种不同类型的工程,其中Web目录下的Dynamic Web Project和Static Web Project是WTP专门提供为开发Web应用的工程。Dynamic Web Project是动态Web工程,Static Web Project是静态Web工程。
在开发Web工程时,Eclipse会在程序员确认后打开Java EE透视图,该透视图的Eclipse开发界面如图5.1所示。
静态Web工程用于开发非交户式的Web应用,在应用中只有静态内容,如HTML页面、图片等,没有Servlet、JSP等动态Web内容。
新建静态Web工程的步骤如下。
图5.1 Java EE透视图
1.在New Project对话框中选择Static Web Project,弹出对话框如图5.2所示。
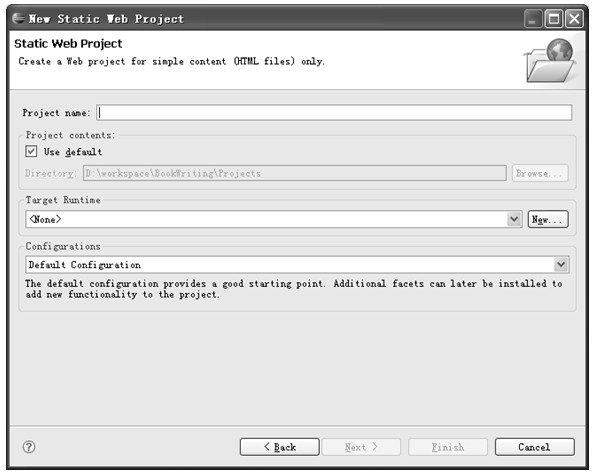
图5.2 新建静态Web工程
在该对话框的Project name栏中输入工程名称,例如:StaticWebProject。
2.单击Next>按钮,弹出菜单如图5.3所示。
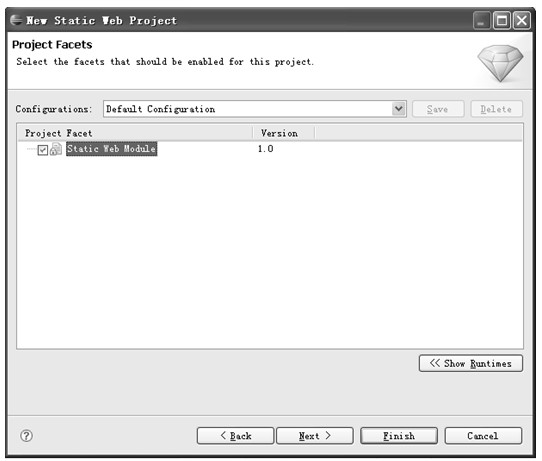
图5.3 选择工程模块
该对话框中列出了要在该工程中包含的模块,静态Web工程当前的版本只包含唯一的模块,即Static Web Module,版本号是1.0。
3.单击Next>按钮,弹出对话框如图5.4所示。
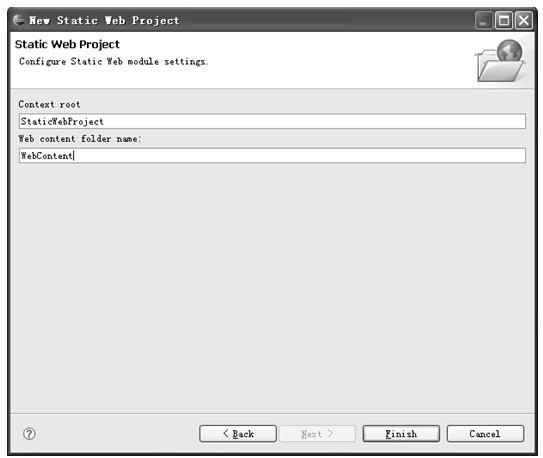
图5.4 配置Web模块设置
该对话框中列出了如下两项配置:
Context root:表示Web应用上下文的根目录,默认值通常与该静态工程的名称一样,此处为StaticWebProject;在使用Eclipse开发Web工程时该配置项没有实质意义,通常保持默认值即可;
Web content folder name:用于放置Web内容的目录,在此处指定一个目录名后Eclipse所做的只是在工程根目录中新建一个具有该名称的子目录;读者可以指定一个自己习惯的名称(此处可以保留其默认值,或者为了以后方便使用也可以使用更简单的名称,例如Web等)。
4.单击Finish完成新建静态Web工程向导,新建工程成功后,在左边的Project Explorer视图中就可以发现该工程;展开该工程可以发现该工程中的内容,如图5.5所示。
在文件系统中打开工程目录,工程根目录的内容如图5.6所示。
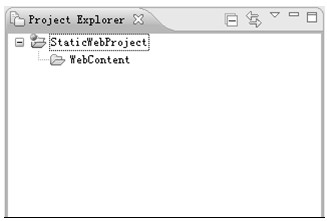
图5.5 静态Web工程内容

其中WebContent是新建工程时在Web content folder name中输入的名称所新建的文件夹,初始是空的;.settings和.project都是Eclipse自动生成的用于管理工程的辅助文件或文件夹,它们对Web应用没有意义。
动态Web工程的内容比静态Web工程的内容要丰富得多,它允许在工程中加入交互式的动态内容。新建的步骤与静态Web工程类似。
1.在New Project对话框中选择Dynamic Web Project,弹出对话框如图5.7所示。
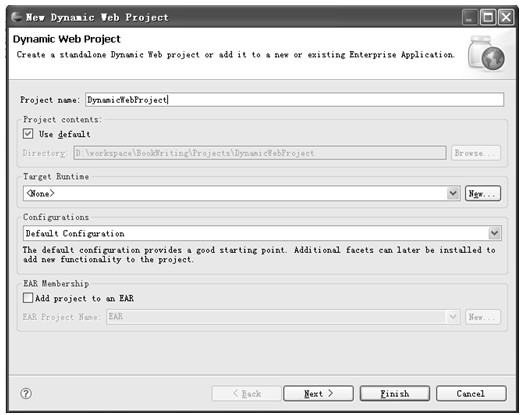
图5.7 新建动态Web工程
与静态Web工程类似,在该对话框的Project name栏中输入工程名称,例如:DynamicWebProject。
2.单击Next>按钮,弹出菜单如图5.8所示。
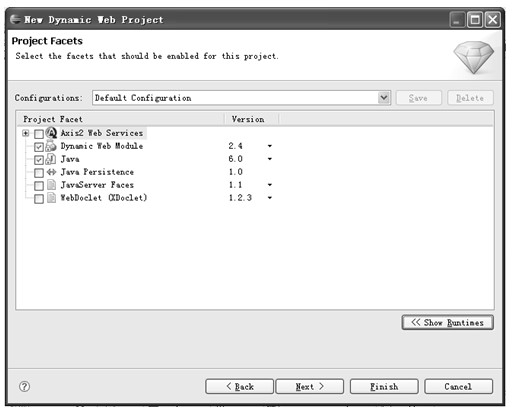
图5.8 选择动态Web工程模块
可以发现,动态Web工程所支持的模块比静态Web工程要多很多,不同的模块在Web工程中支持不同的Java技术。其中,Axis2 Web Services用于支持Web服务;Dynamic Web Module用于支持动态Web技术,后面的版本号表示支持的Servlet规范版本号;Java用于支持Java开发的内容,后面的版本号表示JDK的版本号;Java Persistence用于支持Java持久化,后面的版本号是使用的JPA版本号;JavaServer Faces用于支持JSF,后面的版本号是使用JSF的版本号;WebDoclet(Xdoclet)用于对WebDoclet的支持,后面的版本号是使用WebDoclet的版本号。对于只用于学习JSP和Servlet的工程来说,只需要选择默认的两样就足够了。
3.单击Next>按钮,弹出菜单如图5.9所示。
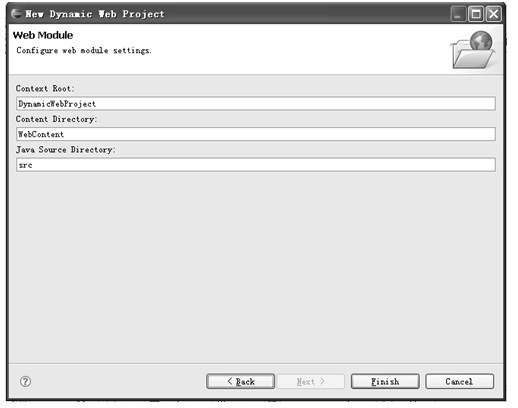
图5.9 配置Web模块设置
在图5.9所示的对话框中前两个输入项的意义与静态Web工程相同;由于在动态Web工程中需要编写Java代码,所以这里增加了Java Source Directory,用于说明放置Java源代码的目录,Eclipse会在工程的根目录下再建立一个src目录。
4.单击Finish完成新建静态Web工程向导,新建工程成功后,在左边的Project Explorer视图中就可以发现该工程;展开该工程可以发现该工程中的内容,如图5.10所示。
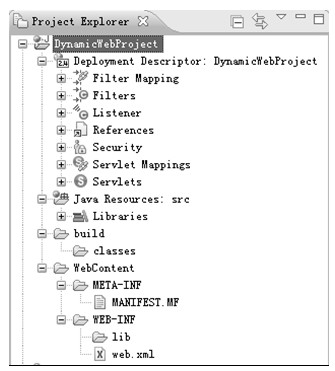
图5.10 动态Web工程内容
在文件系统中打开工程目录,工程根目录的目录结构如5.11图所示。
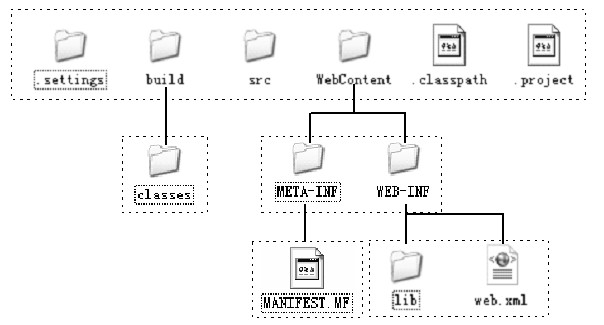
图5.11 动态Web工程根目录
其中.settings、.classpath和.project都是Eclipse自动生成的用于管理工程的辅助文件;src目录用于放置Java源代码;build目录用于放置工程编译后的输出文件,classes目录用于放置对src目录下的java文件编译后的class文件;WebContent用于放置Web内容,通常将 Web应用中所有的HTML文件、JSP文件、图片等网页元素文件按照适当的目录放置在该目录中;WEB-INF是Web应用的信息目录,其中lib目录用于放置工程所需要的库文件,web.xml是Web应用的描述文件,它在Web应用中起到了非常重要的作用,其具体内容结构将会在后面章节中介绍;META-INF用于放置工程的元数据信息,其中的MANIFEST.MF是用于描述工程的信息,初始只自动添加了版本属性。
由于静态Web应用涵盖的内容只是动态Web应用的一个子集,而且Java Web开发技术也主要是针对动态Web应用开发技术,所以后面的内容主要针对动态Web工程进行讲解。如果不加特别说明,那么所提到的Web工程也都是动态Web工程。
在Project Explorer中列出的Web工程上单击鼠标右键,在右键菜单中选择Properties会弹出该工程的属性对话框,如图5.12所示。
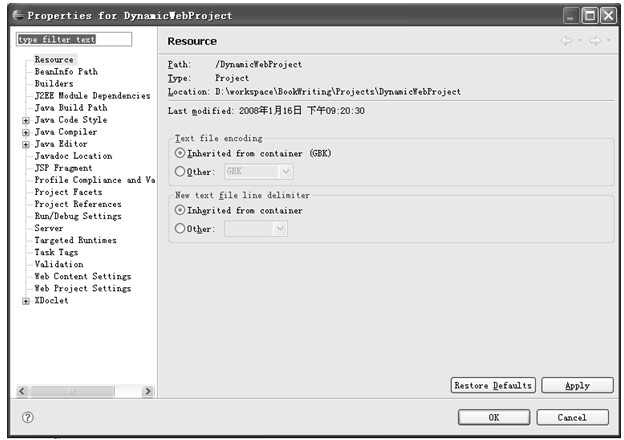
图5.12 动态Web工程配置
在该对话框中可以查看和配置与工程相关的很多属性。其中常见的属性如下。
1.Resource
该页列出了工程的相对路径、位置、更改时间、编码、行分隔符(在UNIX类系统和Windows系统中的分行符是不同的),同时也可以对编码和行分隔符进行配置。
2.Java Build Path
该页用于配置在该工程中编写Java代码时所引用的Java构建路径,配置对话框如图5.13所示。
Source页用于配置源代码目录(Source folders on build path)以及编译输出目录(Default output folder),Eclipse只对在源代码目录中的内容进行编译并且将编译的输出放置在编译输出目录中。
Projects页用于配置需要添加到该工程构建路径中的工程,只有添加到这里的其他工程才能够被该工程引用,待添加工程只能是当前工作空间中已打开的工程。
图5.13 配置动态Web工程的Java Build Path属性
Libraries页用于向工程中添加库文件,只有添加到这里的库文件才能够被该工程中的Java代码引用。Add JARs按钮用于选择并添加工作空间内的库文件;Add External JARs按钮用于选择并添加本地文件系统中的库文件;Add Variable…按钮用于添加一个环境变量;Add Library按钮用于添加Eclipse携带的库文件(例如,JRE、JUnit等);Add Class Folder按钮用于将文件系统中的一个目录作为库添加到工程构建路径中。
Order and Export页用于定义寻找资源时的搜索次序,候选搜索源包括工程源代码目录、引入到工程构建路径中的工程和库文件。当同一个资源在候选搜索源中出现超过一次时,排在前面的资源将会被引用。
3.Java Compiler
该配置页用于配置编译Java代码时使用的JDK的版本,配置对话框如图5.14所示。
图5.14 配置动态Web工程的Java Compiler属性
其中最主要的配置项就是希望使用哪个版本的JDK对工程中的Java代码进行编译,如图5.14.中所示的Compiler compliance level对应的下拉选择框中列出了当前可用的JDK版本,通常默认都是最高版本。
静态Web对象是指除Servlet、JSP等之外,在Web上的展现效果不会发生变化的对象文件,例如:各种图片、HTML页面、CSS文件、JavaScript代码文件等。对于这些类型的文件,可以使用浏览器在本地打开,在本地打开的展示效果与客户端浏览器通过Web服务器访问获得的展示效果完全相同;而且任何客户端在任何时间访问获得的效果也不会有很大的差异。这也正是称其为静态Web对象的原因。
WTP-Eclipse直接提供了对HTML、CSS、JavaScript等静态Web对象进行编辑的功能。在File→New→Others…菜单中,在Web文件夹中列出了这几种文件类型,选择相应的文件可以通过向导创建文件。
1.新建静态Web对象
静态Web对象都是以文件的形式存在,客户端浏览器通过Web服务器直接从Web应用的Web根目录中根据Web对象的路径获取这些文件。Eclipse动态Web工程的WebContent目录正是用于放置这些Web文件的根目录,在将Web工程部署到Web应用中后该目录中的所有Web文件将被放置在Web应用的根目录中,并且保持原有的目录结构。
所以在新建静态Web对象时,应该将所有的文件都新建在工程的WebContent目录中,并且按照最终在Web应用中的目录结构进行组织。假设,Web应用demo中有两个静态Web对象:index.html和bg.jpg,index.html通过http://localhost:8080/demo/index.html访问并且通过相对路径image/bg.jpg引用bg.jpg,那么在Web应用根目录中应该有index.html文件,和image目录,并且bg.jpg在image目录中;那么在开发demo应用时,应该将index.html文件和image目录都放在demo工程的WebContent目录中。
无论是开发HTML、CSS、JS文件或者引用图片,都应该将这些文件按照目标目录结构(即最终在Web应用中的目录结构)组织在WebContent目录中。
新建这些静态Web对象是非常简单的,Eclipse都提供了新建向导。以新建HTML文件为例,目标是在WebContent目录中新建一个display目录,然后在该目录中新建一个overview.html。步骤如下。
(1)在工程中的WebContent目录上单击鼠标右键,在右键菜单中选择New → Folder,新建一个目录,如图5.15所示。
图5.15 新建一个目录
在弹出的对话框中输入目录名:display,确定后完成目录的新建。
(2)在工程浏览器视图中WebContent目录下会出现一个新的目录display,在display上单击鼠标右键,在右键菜单中选择New → HTML,如图5.16所示。
图5.16 新建HTML文件
(3)选择HTML后将弹出如图5.17所示的对话框。
图5.17 新建HTML文件向导
在图5.17的对话框中可以选择存放HTML文件的目录以及HTML文件的名称,存放目录默认是单击右键所指向的目录。在文件名输入框中输入HTML文件的名称overview.html(后缀也可以是htm)。单击Next > 按钮会弹出一个窗口用于选择文件模板,待选择的模板都是当前Eclipse中预定义的HTML模板(模板的定义在Eclipse配置时已介绍过);单击Finish按钮将使用默认的HTML模板完成新建向导。
按照这种方式可以依靠Eclipse提供的新建向导完成几乎所有需要编辑的静态Web对象的新建,并且通过在父目录上单击右键调出新建向导可以很容易地将Web对象按预期的目录结构进行组织。
但是从图5.16和图5.17两个图中可以发现,New菜单项只提供了很少的Web对象,并没有提供JavaScript文件、CSS文件等。这是因为菜单中能够提供的选择是有限的,Eclipse不可能将提供的所有文件类型都列在菜单项中,但是Eclipse提供了Other...菜单项,通过该菜单项可以打开New对话框,通过New对话框可以选择所有可能的文件类型,如图5.18所示。
图5.18 New对话框
图5.18所示就是New对话框,它分类列出了所有Eclipse提供新建向导支持的对象类型,其中Web目录中主要提供了各种Web对象类型,包括下面将要介绍的动态Web对象JSP和Servlet。
2.编辑HTML
新创建的HTML文件内容并不是空的,而是一个简单HTML文件框架,具体的框架内容根据选择模板的不同而不同。图5.19为选择默认HTML模板生成的框架内容:
图5.19 新建HTML文件内容
在Eclipse中,默认会使用HTML编辑器打开HTML文件(*.html和*.htm),HTML编辑器对HTML文件的编辑提供了支持。
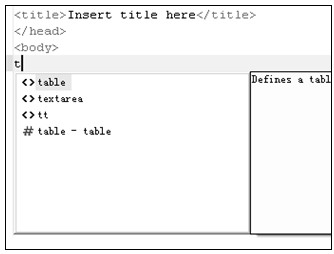
大多数编辑过HTML文件的程序员都会有一个感受:编辑HTML文件的最大难点就是HTML标准中定义了大量标签,并且大部分标签又定义了很多的属性,程序员很难准确记住每个元素的名称和使用格式,以及每个元素都有哪些属性。Eclipse的HTML编辑器提供的内容提示功能恰好解决了这个问题,HTML编辑器的内容提示功能类似于Java编辑器中的内容帮助功能。程序员在任何一个元素的开始标签和结束标签之间按下Alt+/(菜单Edit→Content Assist的快捷键),编辑器会弹出一个候选插入元素列表,列表中按字母顺序列出了所有可能出现在当前位置的元素以及在HTML设置中预定义的模板;同样,程序员在元素的开始标签中输入空格后再按下Alt+/可以调出候选插入属性列表。而且,这些列表还可以根据程序员的输入动态过滤列表中的候选元素。如图5.20、图5.21所示。
a)激活内容帮助
b)输入字符过滤
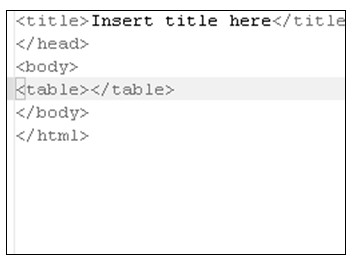
c)自动增加标签
图5.20 使用内容帮助插入元素
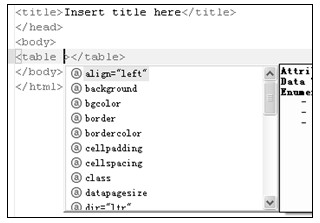
a)激活内容帮助
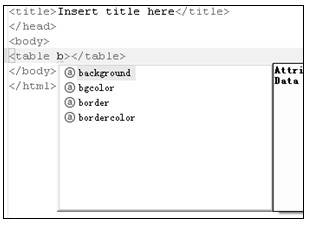
b)输入字符过滤
c)自动增加属性
图5.21 使用内容帮助插入属性
3.编辑JavaScript和CSS文件
同HTML类似,在新建向导中选择JavaScript项即启动新建JavaScript向导,在向导中选择存放目录和文件名后生成一个空的JS文件。JavaScript文件编辑器同样也提供了内容帮助功能,可以提供对象名补齐和显示候选方法列表等功能,如图5.22所示。
a)激活内容帮助输入对象

b)激活内容帮助输入方法
图5.22 使用内容帮助编辑JavaScript代码
使用同样的过程读者可以完成对CSS文件的创建,也可以使用CSS编辑器的Content Assist功能,如图5.23所示。
a)激活内容帮助
b)输入字符过滤
c)自动添加代码
图5.23 使用内容帮助编辑CSS代码
Eclipse除了可以开发静态Web对象外,还提供了对Servlet和JSP开发的支持。Servet本身就是一种特殊的Java类,Eclipse内建提供了对开发Java代码的支持;而对于JSP文件来说,Eclipse也提供了新建向导和JSP编辑器以提供对JSP的开发支持。
1.开发JSP文件
同静态Web对象一样,JSP也是以文件的形式通过相对路径进行访问的,所以在开发JSP文件时,通常也将其按照预订的目录存放在Web工程的WebContent目录中。
JSP的新建向导类似于HTML,在其父目录上单击鼠标右键,在右键菜单中选择New → JSP打开新建向导,在弹出的对话框中输入存放目录和文件名并且选择模板完成JSP文件的新建。
JSP是在HTML文件中加入动态的Java代码,所以JSP编辑器相当于将HTML编辑器与Java编辑器相结合。在编辑HTML代码时可以激活编辑HTML代码的内容帮助功能,在编辑Java代码时可以激活编辑Java代码的内容帮助功能。除此之外,对于一些JSP特有的内容,JSP编辑器也提供了支持,例如激活HTML内容帮助时支持对JSP内置标签的选择,激活Java内容帮助时支持对JSP内置对象的访问。
2.开发Servlet
Servlet是所有Web对象中最特殊的一种。Servlet与其他Web对象不同,不是以文件的形式存在,而是一种特殊的Java类。Servlet以Java类的形式被编辑,编译成的class文件被放在Web应用的类路径中,然后通过配置进Web应用的描述文件中被部署到Web应用中。在有请求访问Servlet时,Web服务器调用Servlet响应请求。所以这就决定了Servlet不能像其他Web对象一样直接放在WebContent目录下,而应该放在Web工程的src目录下,由Eclipse编译成class文件,在将Web工程部署到Web服务器中后放置在WEB-INF的classes目录下。
Java类应该有一定的包结构,所以在新建Servlet之前应该先在src目录下新建包,例如:cn.csai.web.servlet。然后再在包中新建Servlet,步骤如下。
(1)在工程的src中新建包。在工程中的Java Resources:src项上单击鼠标右键,在弹出菜单中选择New→Package,如图5.24所示。
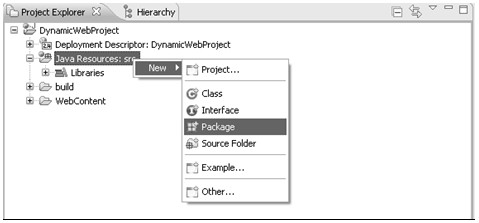
图5.24 在工程的src新建包
在弹出窗口中输入待建包的名称cn.csai.web.servlet后确定,就可完成对包的新建。
(2)在新建的包中新建Servlet。在新生成的包上单击鼠标右键,选择New→Other...,如图5.25所示。
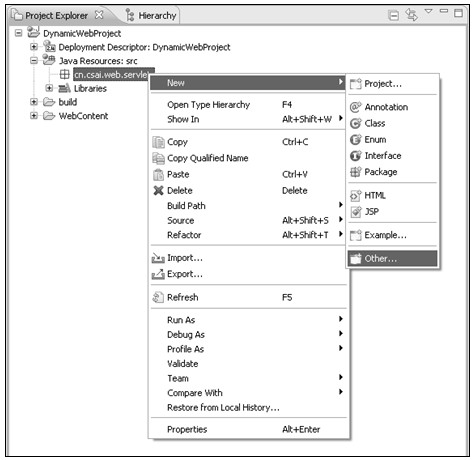
图5.25 打开Servlet新建向导
在弹出的New对话框中选择Web目录中的Servlet,激活Servlet新建向导。
(3)Servlet新建向导如图5.26所示。
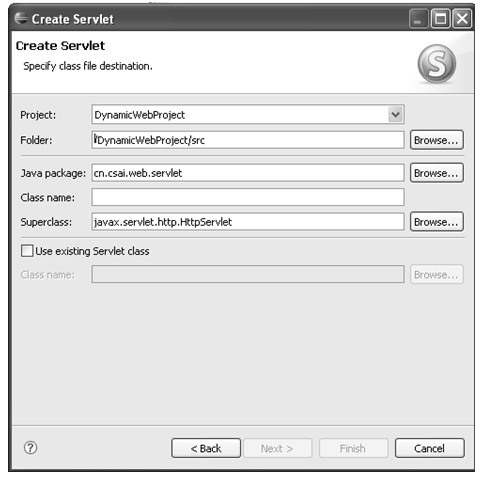
图5.26 新建Servlet向导
在图5.26中的Class name输入框中输入新建Servlet的类名,例如TestServlet,单击Next>按钮进入图5.27所示对话框。
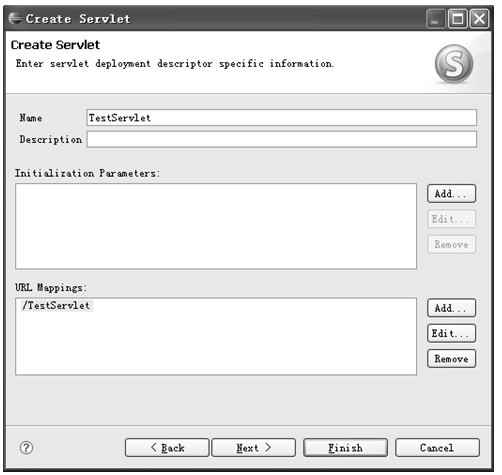
图5.27 指定web.xml中的Servlet配置
在图5.27所示对话框中可以设置该Servlet的初始化参数和URL映射模式,可以通过按钮添加/编辑/删除初始化参数和URL映射模式。确认输入后单击Next>按钮打开如图5.28所示对话框。
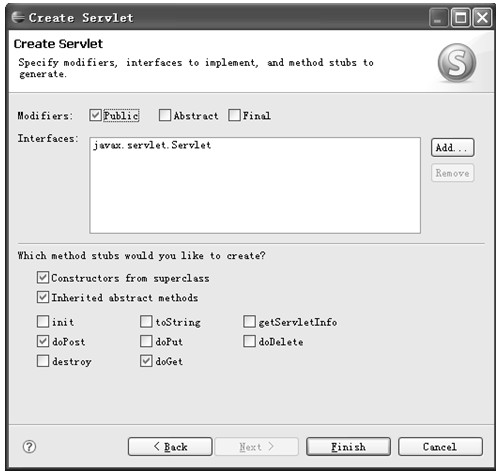
图5.28 指定自动生成的初始Servlet代码
在图5-28所示的对话框中可以选择一些设置,Eclipse会根据这些设置为创建的Servlet自动添加代码。Modifiers表示生成的Servlet类是否声明为Public/Abstract/Final的;Interfaces表示生成的Servlet类所实现的接口;Constructors from superclass被选中时,生成的Servlet类的构造方法会默认调用父类的构造方法;Inherited abstract methods被选中时,生成的Servlet类会自动添加对接口或父类中的抽象方法的空白实现;init、toString、getServletInfo、doPost、doPut、doDelete、destroy、doGet被选中时,生成的Servlet类会自动生成被选中方法的空白方法体,开发人员可以添加方法的具体实现以覆盖父类中对应的方法。
单击Finish完成Servlet的新建。在Servlet被新建成功后,Eclipse会用Java编辑器打开新建的Servlet,Servlet的初始内容会根据图5.28中选择的选项生成如下:
package cn.csai.web.servlet;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* Servlet implementation class for Servlet: TestServlet
*
*/
public class TestServlet extends javax.servlet.http.HttpServlet implements javax.servlet.Servlet {
static final long serialVersionUID = 1L;
/* (non-Java-doc)
* @see javax.servlet.http.HttpServlet#HttpServlet()
*/
public TestServlet() {
super();
}
/* (non-Java-doc)
* @see javax.servlet.http.HttpServlet#doGet(HttpServletRequest request, HttpServletResponse response)
*/
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws Servlet Exception, IOException {
// TODO Auto-generated method stub
}
/* (non-Java-doc)
* @see javax.servlet.http.HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response)
*/
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws Servlet Exception, IOException {
// TODO Auto-generated method stub
}
}
但是,在新建成功后Java编辑器会提示无法识别其中的一些类,这是因为Servlet库是J2EE中的内容,在J2SE中并不能被识别,所以在进行开发之前需要将Servlet库添加到动态Web工程的构建路径中:参考5.1.3节中关于Java Build Path的设置方法,使用Libraries标签中的Add External JARs...将库${TOMCAT_HOME}/lib/servlet-api.jar添加到工程的构建路径中。
同时,在Servlet新建好后Eclipse还自动将该Servlet配置到了该工程的web.xml文件中,配置的内容由图5.27中的设置情况决定。初始的web.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<web-app id="WebApp_ID" version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www. w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com /xml/ns/j2ee/web-app_2_4.xsd">
<display-name>
DynamicWebProject</display-name>
<welcome-file-list>
<welcome-file>index.html</welcome-file>
<welcome-file>index.htm</welcome-file>
<welcome-file>index.jsp</welcome-file>
<welcome-file>default.html</welcome-file>
<welcome-file>default.htm</welcome-file>
<welcome-file>default.jsp</welcome-file>
</welcome-file-list>
</web-app>
TestServlet新建完成后,web.xml文件的内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<web-app id="WebApp_ID" version="2.4"
xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com/xml/ns/j2ee/web-app_2_4.xsd">
<display-name>DynamicWebProject</display-name>
<servlet>
<description></description>
<display-name>TestServlet</display-name>
<servlet-name>TestServlet</servlet-name>
<servlet-class>cn.csai.web.servlet.TestServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>TestServlet</servlet-name>
<url-pattern>/TestServlet</url-pattern>
</servlet-mapping>
<welcome-file-list>
<welcome-file>index.html</welcome-file>
<welcome-file>index.htm</welcome-file>
<welcome-file>index.jsp</welcome-file>
<welcome-file>default.html</welcome-file>
<welcome-file>default.htm</welcome-file>
<welcome-file>default.jsp</welcome-file>
</welcome-file-list>
</web-app>
其中添加了对Servlet的配置,url-pattern对应于图5.27中的URL Mappings;由于没有配置初始化参数,所以这里也没有添加任何初始化参数。
Tomcat是目前最流行的Servlet和JSP容器,也是Sun公司官方推荐的Servlet和JSP容器,并且Tomcat的版本也会随着Servlet和JSP版本的更新不断地升级。Tomcat是学习Java Web开发和开发Java Web应用最理想的Web服务器。
本章将从如下几个方面对Tomcat进行介绍:
Tomcat和Servlet容器的概念;
Tomcat的下载和安装;
Tomcat服务器的结构和配置;
在Eclipse中安装Tomcat插件。
随着交互式Web应用的出现,Sun公司提出了基于Java技术的动态Web技术:JSP(JavaServer Page)技术和Servlet技术。作为Java领域中动态Web的两个基础技术,JSP和Servlet在Web开发中起着越来越重要的作用,几乎所有基于Java的高级Web技术都是建立在JSP技术和Servlet技术基础之上的。
Tomcat是Apache Jakarta项目中的一个重要的子项目,它是Sun公司官方推荐的Servlet和JSP容器,Servlet和JSP的最新规范都可以在Tomcat的新版本中得到实现;其次,Tomcat是完全免费的软件,任何人都可以从Tomcat的官方网站上自由地下载。因此,Tomcat越来越多的受到软件公司和开发人员的青睐;尤其对于学习Java Web开发的程序员来说非常合适,因为它可以免费获得而且功能完备、有完善的文档和发展成熟的社区、而且随着Servlet和JSP规范的不断发展会不断更新版本。Tomcat版本及其所实现的Servlet/JSP规范的版本之间的关系如表6.1所示。
表6.1 Tomcat版本与Servlet/JSP版本对应关系

表6.1中列出的Tomcat版本号都是二级版本号,通常下载的具体Tomcat版本会有更加细致的小版本号,但是通常二级版本号相同的Tomcat版本所实现的Servlet规范和JSP规范版本也是相同的。
在介绍Tomcat的资料和文档中都会提到,Tomcat是Servlet/JSP容器,或者说Tomcat是实现了JSP规范的Servlet容器。由此可见,Tomcat最主要的角色是作为一种Servlet容器出现的,本节首先介绍Servlet容器的概念。
Servlet容器也叫做Servlet引擎,顾名思义它是放置Servlet的容器,它在Servlet的生命周期内包容、装载、运行、和停止Servlet;它是Web服务器或应用程序服务器的一部分,它还必须具有在外部请求和Servlet之间传递消息的功能。外部请求在到达Servlet容器时,Servlet容器通过解析请求消息将请求消息分发给目的Servlet,运行Servlet获得响应,并将响应以特定格式返回给请求端。
Servlet容器的工作模式可以分为以下三类:
1.独立的Servlet容器
将Servlet容器与基于Java技术的Web服务器集成,Servlet容器与Web服务器在同一个JVM中运行,作为独立的Web服务器运行。这种运行模式称为独立的Servlet容器模式。
2.进程内的Servlet容器
假如将Servlet容器与基于非Java技术的Web服务器一起使用,则通过Web服务器插件便将Servlet容器集成到Web服务器中。Web服务器插件在某个Web服务器内部地址空间中打开一个JVM,使得Servlet容器可以在此JVM中加载并运行Servlet。如有客户端调用Servlet的请求到来,那么插件将此请求通过JNI接口传递给Servlet容器,然后由Servlet容器处理该请求。
3.进程外的Servlet容器
这种模式也是通过服务器插件的形式将Servlet容器与Web服务器联系起来。在这种模式下,Web服务器将Servlet容器运行于服务器外部的JVM。Web服务器插件与Servlet容器使用IPC机制进行通信。当访问Servlet的请求到达Web服务器时,Web服务器插件通过使用IPC消息传递给Servlet容器。所以这种方式与进程内的Servlet容器的区别就是Servlet容器与Web服务器的耦合程度不同和Web服务器插件与Servlet容器的通信方式不同。
Tomcat的运行模式默认是以独立的Servlet容器模式运行,同时Tomcat也可以附加到现有服务器(例如,Apache,IIS和Netscape服务器)。但对于学习、开发和调试Web应用来说,单纯使用Tomcat作为Web服务器就已经足够了。
Tomcat的官方主页是:http://tomcat.apache.org/,如图6.1所示。
图6.1 Tomcat官方主页
该页左边“Download”菜单下列出了几种经典的Tomcat版本,截至本书写作时Tomcat的最新版本是6.0.14。单击“Download”中的子菜单“Tomcat 6.x”,进入Tomcat的下载页面,如图6.2所示。
如图6.1所示,在打开页面的下部有6.0.14版的下载链接。下载的内容有两种发布形式:二进制数发布(Binary Distribution)和源代码发布(Source Code Distribution)。二进制数发布下载应用程序,源代码发布下载Tomcat的源代码。
图6.2 Tomcat 6.x下载页面
在二进制数发布中又提供了两种类型的内容:Core和Deployer。Core是Tomcat应用的核心内容,Deployer是供Web开发人员开发与Tomcat6本身相关的一些Web应用时发布Web应用的参考。Core中列出了三种下载的格式:zip格式、tar.gz格式和Windows Service Installer格式。Zip格式下载后得到的是一个zip文件,tar.gz格式下载后得到的是一个tar.gz文件,这两种格式下载的文件都无须安装,解压缩后即可使用,只是他们使用了不同的压缩方式,zip文件使用ZIP压缩方式,tar.gz文件通常是在GNU操作系统(一种类似于UNIX的操作系统)中用tar命令打包而成的,因此必须在与GNU相兼容的操作系统中解包;“Windows Service Installer”格式下载后得到的是一个exe文件,在Windows中运行该文件可以将Tomcat安装到Windows系统中,并且可以选择将Tomcat安装为系统服务,这样就可以通过Windows服务来控制启动和停止。在学习本书时建议读者使用zip格式的下载方式。
【提示】
Tomcat 6要求系统至少安装JDK5或更高版本。
将zip文件下载到本地后选择适当的ZIP解压软件将zip文件进行解压并保存到本地文件系统,例如保存为D:\Tomcat目录,那么该目录的目录内容如图6.3所示。
bin目录下是Windows系统下和UNIX类系统下的可执行文件(批处理文件和Shell脚本文件),如启动、停止Tomcat的执行文件。在Winodws操作系统中启动Tomcat的命令是startup.bat,停止Tomcat的命令是shutdown.bat。在UNIX下启动Tomcat的命令是startup.sh,停止Tomcat的命令是shutdown.sh。
conf目录下是一些有关Tomcat服务器的配置文件和属性文件,如server.xml、web.xml、logging.properties等。

图6.3 Tomcat安装目录
lib目录下是一些库文件(jar文件或class文件)和资源文件。在Tomcat 5.5版本中Tomcat还将库文件分成三个不同的目录:common目录用于存放供Tomcat服务器和Web应用共同使用的库文件; server目录用于存放供Tomcat服务器使用的库文件;shared目录用于存放供所有Web应用使用的库文件。在Tomcat 6.0中将这些目录去掉,只使用一个lib目录,此目录下的所有库文件都可以供Tomcat服务器和Web应用共用。
logs目录是Tomcat服务器的日志目录,Tomcat将各种与服务器相关的日志都放置在该目录下。
temp是供JVM使用的存放临时文件的目录。
webapps目录用于存放一些Tomcat中的Web应用,每个子文件夹表示一个Web应用,该目录中的Web应用会被Tomcat自动装载。默认该目录中已自带了一些Web应用,其中ROOT应用是默认的根Web应用。
work目录是供Web应用使用的临时工作目录。
解压完还需要确保系统中已正确配置了JAVA_HOME环境变量,如此便完成了Tomcat的安装。为了以后在使用Tomcat以及Tomcat在与其他工具联合工作时不至于产生问题,在安装完Tomcat后最好将TOMCAT_HOME环境变量添加到系统中,该环境变量的值应该是Tomcat的安装根目录,在上例中应该是D:\Tomcat。
安装好Tomcat后,双击bin目录下的startup.bat便可启动Tomcat,启动后的命令行界面如图6.4所示。
图6.4 启动Tomcat
Tomcat启动成功后,在浏览器中输入地址“http://localhost:8080”,将出现Tomcat默认的欢迎页面,如图6.5所示。
图6.5 Tomcat欢迎页面
如果该欢迎页面能正确出现,说明Tomcat已正确安装。
虽然Tomcat是开源的免费软件,但是Tomcat作为一种Servlet容器,其功能是十分强大的,而且Tomcat在结构设计上也是以一个大型商业软件为标准的。因此,理解Tomcat服务器的结构有助于读者很好地理解Tomcat的实现原理,有助于更好地理解Tomcat服务器的配置,而且如果读者有兴趣还可以在深入理解Tomcat结构和配置的基础上扩展Tomcat的功能。本节将从比较宏观的层面介绍Tomcat的结构,对于Tomcat的具体使用和配置方法将在后面介绍。
之所以说Tomcat的结构设计是以大型商业软件为标准的,是因为Tomcat在结构上充分考虑了多域名和多主机使用,以及服务器的可配置性和可扩展性。Tomcat服务器的结构层次如图6.6所示。
图6.6中,Tomcat Server代表整个Tomcat服务器,Tomcat服务器中可以配置多个Service,一个Service代表Tomcat提供的一种服务。一个Service中可以配置若干个Connector和一个Engine,Connector是负责与外界交流的模块,它负责在指定的服务器端口上监听来自客户端的请求,当请求到达时接受请求,将请求交给处理引擎,并将处理结果返回给客户端。每个Connector实例实际上是实现一种网络传输协议,它对通过这种协议传入的客户端请求进行分析,构造相应的Request和Response实例,将Request和Response实例传递给Engine,待Engine处理结束后将处理结果通过实现的传输协议返回给客户端。Engine是整个Service中的处理机,一个Service中只有一个Engine,它处理来自各个Connector的客户端请求。Engine中又可以配置一个或多个Host,Host就是常说的“虚拟主机”。通常,一个完整的Web服务器包含一个或多个“虚拟主机”。所谓虚拟主机,就是在一个物理的服务器上配置多个域名,这样在客户端看起来好像是有多个主机。每个虚拟主机中又可以部署一个或多个Web应用,如图6.6中的Context。Web应用中又可以配置多个Servlet。Tomcat通过分级的结构将其提供的多服务、多协议、多主机进行层层分解,最终都归结到一个一个的Servlet来执行具体的任务,这也是Tomcat被称为Servlet容器的原因。所以,开发人员在使用Tomcat服务器时,应该根据Tomcat的这种层次结构将自己的应用进行分析和分解,将应用中的每一块配置到合适的位置上。
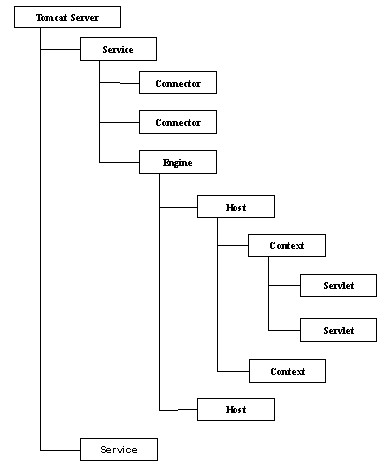
图6.6 Tomcat服务器结构层次图
将6.3节介绍的Tomcat服务器的结构与前面介绍的Eclipse的全插件结构进行比较,可以发现这两者有一些类似之处:Tomcat服务器的基础结构实质上是提供了一个可以容纳Service、Context、Servlet等组件的容器,开发人员通过设置配置文件将这些组件添加到Tomcat容器中,这种思想与Eclipse的全插件结构有异曲同工之妙。但是,没有安装任何插件的Eclipse是无法进行工作的;同样,没有添加任何组件的Tomcat也是无法进行工作的。所以,Eclipse在发布时也同时安装了Workspace、JDT、PDT等基础插件;同样,Tomcat在发布时也默认配置了一些组件以完成基本的功能,这在server.xml配置文件中可以体现出来。
server.xml配置文件的初始内容如下(已删除注释):
<Server port="8005" shutdown="SHUTDOWN">
<Listener className="org.apache.catalina.core.AprLifecycleListener" />
<Listener className="org.apache.catalina.core.JasperListener" />
<Listener className="org.apache.catalina.mbeans.ServerLifecycleListener" />
<Listener className="org.apache.catalina.mbeans.GlobalResourcesLifecycleListener" />
<GlobalNamingResources>
<Resource name="UserDatabase" auth="Container"
type="org.apache.catalina.UserDatabase"
description="User database that can be updated and saved"
factory="org.apache.catalina.users.MemoryUserDatabaseFactory"
pathname="conf/tomcat-users.xml" />
</GlobalNamingResources>
<Service name="Catalina">
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000"
redirectPort="8443"/>
<Connector port="8009"
protocol="AJP/1.3" redirectPort="8443" />
<Engine name="Catalina" defaultHost="localhost">
<Realm className="org.apache.catalina.realm.UserDatabaseRealm"
resourceName="UserDatabase"/>
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true"
xmlValidation="false" xmlNamespaceAware="false">
</Host>
</Engine>
</Service>
</Server>
从XML文件的内容可以发现,元素之间的层次结构与前面介绍的Tomcat服务器的结构大致一样。
1.Server
Server表示整个Tomcat服务器,它是整个文件的顶层元素,不能作为任何其他元素的子元素。Server元素可包含Listener元素、GlobalNamingResources元素和Services元素。Server元素的属性如表6.2所示。
表6.2 Server元素属性表

Listener元素用于提供对JMX MBeans的支持,其属性className是实现该元素的类。
GlobalNamingResources元素为Server定义全局的JNDI(Java Naming and Directory Interface,Java 命名和目录接口)资源。Resource元素配置Web应用可以使用的资源名字、数据类型以及资源需要的参数。
整个Tomcat服务器由一个Server元素表示,所以Server元素作为配置文件的根元素,并且在配置文件中不能再出现别的以Server为标签的元素。
2.Service
Service元素表示Server提供的一个服务,它由若干个Connector和一个Engine组成。Service元素的属性如表6.3所示。
表6.3 Service元素属性表

在Tomcat的初始配置中提供了一个名为Catalina的服务,该服务是随Tomcat一起发布的由Tomcat提供的默认服务。如果开发人员还希望Tomcat服务器提供别的服务,可以在Server元素下添加新的Service元素,并指定其实现类。
3.Connector
Connector元素代表与客户端实际交互的连接器,它负责接收客户的请求以及向客户返回响应结果。Connector根据protocol属性可分为两种类型:HTTP Connector和AJP Connector。HTTP Connector表示支持HTTP/1.1的连接器,它使得Tomcat可以通过HTTP协议通信,这也是使得Tomcat能够成为独立的Web服务器的关键部件。AJP Connector表示使用AJP协议通信的连接器,它用于Tomcat与Apache服务器通信,这样便于将Tomcat与Apache服务器集成,让Apache处理Web应用中的静态内容请求。HTTP Connector和AJP Connector都是Connector元素,根据Connector元素的protocol属性值进行区分,默认是HTTP Connector。Connector元素常见属性的含义如表6.4所示。
表6.4 Connector元素属性表
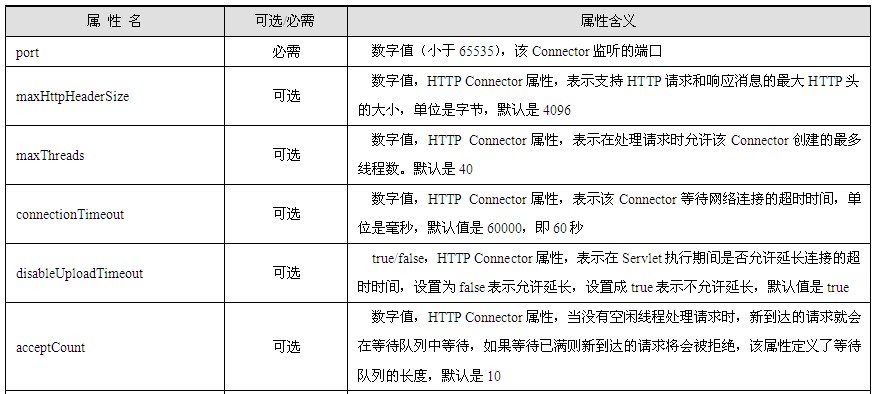
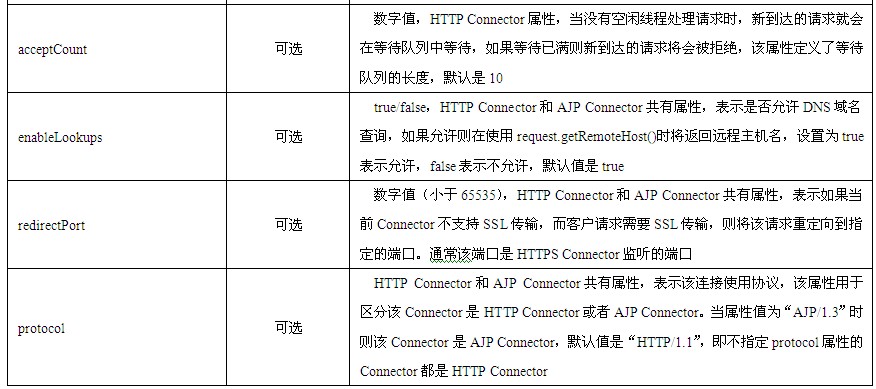
在Catalina服务中初始提供了两个Connector:一个HTTP Connector和一个AJP Connector。HTTP Connector监听8080端口,实现了标准的HTTP/1.1协议;AJP Connector监听8009端口,实现了AJP/1.3协议。在有些使用场合,这两个Connector是不够的,例如有些应用需要实现HTTPS的安全协议,那开发人员可以再增加一个Connector元素以添加支持HTTPS协议的Connector,server.xml文件的注释中提供的一个Connector如下:
<Connector port="8443" protocol="HTTP/1.1" SSLEnabled="true" maxThreads="150" scheme="https" secure="true" clientAuth="false" sslProtocol="TLS" />
4.Engine
Engine元素表示在一个Service中处理所有客户请求的引擎。Engine元素的属性如表6.5所示。
表6.5 Engine元素属性表

Engine在每个Service中只能配置一个,Catalina服务中默认配置了一个Catalina Engine。
Realm元素表示一个包含用户名、密码和角色定义的存储源,通过实现不同的Realm可以使Tomcat适应不同环境下不同的验证信息获取方式,以实现Tomcat的容器访问安全。其className属性表示实现该元素的Java类,该类必须实现org.apache.catalina.Realm接口,Tomcat提供了Realm类的几个标准实现,分别表示不同机制的Realm:org.apache.catalina.realm.JDBCRealm、org.apache.catalina.realm. DataSourceRealm、org.apache.catalina.realm.JNDIRealm和org.apache.catalina.realm.MemoryRealm。不同的Realm实现具有不同的属性。
5.Host
Host元素表示一个虚拟主机,由服务器的一个网络名称表示。Host元素的常见属性如表6.6所示。
表6.6 Host元素属性表
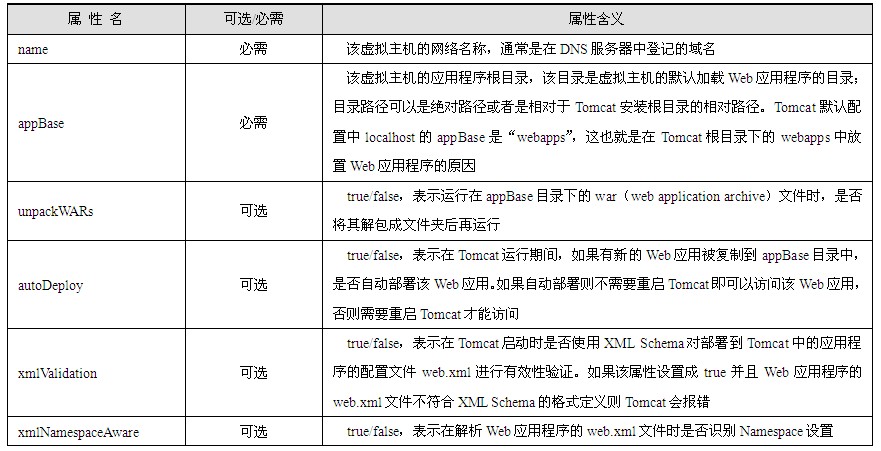
Catalina Engine中默认配置了一个Host:localhost,这个Host表示本地主机,在Web应用的开发和调试阶段使用这个Host部署Web应用已经足够了。
将server.xml文件的初始内容结合Tomcat的结构,可以得到Tomcat初始状态下所配置的组件,如图6.7所示。
图6.7 Tomcat初始配置的组件结构
初始状态下,Tomcat只提供一个服务,其中包括两个Connector和一个Host。对于学习Web开发的读者来说,可以将所有待开发的Web应用都部署到localhost中,然后用URL前缀http://localhost:8080(8080是HTTP Connector监听的端口号)访问Web应用进行调试。关于如何在Tomcat中部署、设置和访问Web应用将在第7章中介绍。
server.xml文件是用于配置Tomcat服务器的最主要的配置文件,Tomcat提供了很多可供配置的配置项以提供极大的灵活性,但是对于使用Tomcat进行学习和简单开发来说只需要涉及几个简单的配置项,其中最常用的可能是HTTP Connector的port属性。它表示Catalina服务通过HTTP协议提供服务的端口号,默认是8080,这就表示通过HTTP协议访问Catalina服务时必须使用服务器的8080端口,例如访问localhost中配置的Web应用时URL前缀是http://localhost:8080/;当然该端口号也可以更改为其他合法端口号,如果更改为HTTP协议的默认端口号80,那么在访问Catalina服务时URL前缀中就可以不用加上端口号,即http://localhost。
除了server.xml文件,Tomcat还有其他一些配置文件。Tomcat的配置文件都在${TOMCAT_HOME}/conf目录下,1.6版的Tomcat初始安装后,该目录中除了server.xml还有如下几个。
web.xml:在Tomcat中每个Web应用都拥有一个对Web应用进行配置的web.xml文件,由于所有Web应用的配置中有很多是相同的,所以Tomcat在这里提供了一个配置文件,用于配置所有Web应用共用的设置,使每个Web应用只需要关注自己应用特有的配置;在实际运行期间Tomcat会将共用配置文件和特有配置文件合并作用于Web应用。web.xml文件就是作为所有Web应用共用的配置文件,修改该文件中的配置会对所有Web应用起作用。web.xml文件的结构和内容将在后续章节中详细介绍。
tomcat-users.xml:该文件对登录Tomcat后台管理的用户做定义,包括角色和用户名/密码,用于登录Tomcat的管理界面。
Catalina文件夹:该文件夹包含用于配置Catalina服务的文件。
catalina.policy:Catalina服务的策略配置文件,其中主要说明一些安全访问的策略。
catalina.properties:Catalina服务的属性配置文件,其中主要说明该Service的一些属性。例如,common.loader、server.loader和shared.loader分别定义了三类库(服务器和Web应用共用、仅供服务器使用和仅供Web应用共用)的装载策略,即装载哪些文件添加到库中,默认server.loader和shared.loader没有配置任何值。通过修改这几个属性的值可以自定义分别将哪些文件夹中的哪些文件装载到这三类库中。对比6.2.2节中对安装目录下lib目录的介绍,正是因为这里将common.loader的值指向lib目录才使得lib目录中的库可以同时被Tomcat和Web应用使用。
context.xml:用于配置Web应用,该内容将被添加到每个Web应用的Context配置中。
logging.properties:Tomcat服务器日志功能属性文件,定义了每一种日志的级别、存放目录、日志文件名前缀、使用的日志处理器等属性。
该插件可以从Eclipse的官方网站上免费下载,官方网站的地址是:http://www.eclipsetotale.com/,主页打卡如图6.8所示。
图6.8 eclipsetotale主页
点击Download Tomcat Plugin按钮进入下载页面,在下载页面的下部有最新版本的下载链接,如图6.9所示。
图6.9 Tomcat插件下载页面
每个版本的Comment栏说明该版本的插件适用于哪些版本的Eclipse,这里选择适合Eclipse3.3的最新版3.2.1,点击File栏的链接下载文件。下载得到文件tomcatPluginV321.zip,对该文件解压缩,解压后获得文件夹com.sysdeo.eclipse.tomcat_3.2.1,该文件夹即为Tomcat插件根目录。
考虑到在开发Web应用时需要经常在Eclipse中操作Tomcat,所以Tomcat插件不应该被频繁地加载和卸载,而应该将Tomcat插件作为Eclipse一个较稳定的功能。因此,这里直接使用前面介绍的第二种插件安装方式,将插件根目录直接复制到Eclipse根目录下的plugins目录中以完成插件的安装。安装完成后重新打开Eclipse,即可在Eclipse工具栏上出现Tomcat的三个图标,如图6.10所示。
图6.10 安装了Tomcat插件后的Eclipse
图6.10中方框包围的三个图标,从左向右依次为:启动Tomcat、关闭Tomcat和重启Tomcat的按钮。通过这三个按钮就可以在Eclipse中直接操作Tomcat。
但是,将插件安装到Eclipse中,在对Tomcat插件进行正确配置之前这几个按钮是不能正常工作的。
该插件安装完成后,在Eclipse的Preferences配置对话框中就会出现对Tomcat插件的配置,如图6.11所示。
图6.11 配置Tomcat插件
在使用Tomcat前至少需要在该配置页指定Tomcat的版本系列和Tomcat home,即Tomcat的安装根目录。在前面介绍Tomcat的安装时安装的是Tomcat 6.0并且将Tomcat安装到D:\Tomcat目录中,所以此处在选择Tomcat version时应该选择Version 6.x,Tomcat home应该选择D:\Tomcat目录。完成这两项配置后,Tomcat插件就可以正常使用了。
本章主要介绍了Tomcat的下载、安装、结构、配置以及在Eclipse中安装Tomcat插件的方法。
Tomcat是Sun公司官方推荐的Servlet/JSP容器。其最新发布版本可以从官方主页直接免费下载,读者可下载zip文件并将其解压到系统本地目录中,再配置相关系统环境变量后就可以正常使用了。
Tomcat服务器是一种层次结构,最顶层是Server,逐级向下依次为Service→Engine→Host→Context→Servlet。Service代表Server提供的一种服务,一个Server中可以包含若干个Service;Engine是Service中的处理引擎,一个Service中只能包含一个Engine;Host表示一个虚拟主机,一个Engine可以包含若干个Host;Context表示Web应用;Servlet表示Web应用中部署的Servlet。Tomcat服务器的配置文件是${TOMCAT_HOME}/conf/server.xml文件,与Tomcat服务器的层次结构对应,该文件中元素的结构也按照从Server到Servlet的包含关系。
Web应用是指能够通过Web提供一系列功能的应用系统。如果脱离了Eclipse和Tomcat等开发工具和Web服务器,一个Web应用就是具有特定目录结构的文件和目录。不同Web服务器中的Web应用具有不同的目录结构。Tomcat中的Web应用也具有特定的文件结构,并且每个Web应用都包含一个配置文件。本章将介绍Tomcat中Web应用的结构、如何将Web应用部署到Tomcat中以及如何配置Web应用。
基于Java技术开发的典型Web应用中通常会存在如下几类Web对象:
静态文件对象:包括HTML页面、图片、普通文件等;
Servlet:依据Servlet规范实现的Java类,可以以编译后的class文件出现,也可以以包含class文件的jar文件出现;
JSP文件:符合JSP规范的动态页面。
实质上一个Web应用通常就是文件系统中的一个目录,称为Web应用根目录。Web应用根目录中的文件是该Web应用中的资源,包括:需要通过Web提供给客户端访问的资源以及Web应用本身的配置和描述文件等。不同的Web服务器对Web应用根目录中文件的结构和意义有不同的规定,只有结构符合规定的Web应用部署到Web服务器中后才能获得预期的效果。典型的Tomcat Web应用具有如下图7.1所示的目录结构。
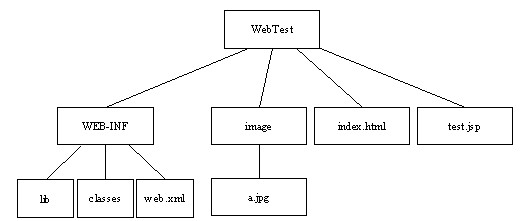
图7.1 Tomcat Web应用目录结构示例
该Web应用的根目录是WebTest,通常称该Web应用为WebTest应用。Web应用的所有资源和配置文件都应该放置在Web应用的根目录中,也只有Web应用根目录中的资源才能够通过该Web应用访问。
所有的静态Web对象和JSP文件可以按任意的目录层次放置在Web应用根目录下,在将Web应用部署到Tomcat中后这些文件都可以根据其目录结构通过URL直接访问;WEB-INF目录是一个特殊的子目录,它存在的目的不是为了能让客户端直接访问其中的文件,而是通过间接的方式支持Web应用的运行,比如提供Web应用需要访问的资源文件、放置Web应用的属性文件或者配置文件等。WEB-INF目录必须位于Web应用根目录下,通常该文件夹中包含lib子目录,classes子目录和web.xml文件。其中,lib目录用于放置该Web应用使用的库文件,classes目录用于放置该Web应用使用的class文件(按包结构组织),web.xml是Web应用描述符,用于设置Web应用特有的配置。WEB-INF目录中的文件是不能通过URL直接访问的。
Web应用在文件系统中存储时表现为一个目录,在文件系统中可以使用不同的路径用于区分目录。当将Web应用部署到Tomcat中时,Web应用就是一个抽象的概念,而且Tomcat中可以部署很多的Web应用,那Tomcat如何区分每个Web应用呢?答案是使用Web应用的上下文路径(Context Path)区分。
Web应用的上下文路径是一个字符串,在Tomcat中与Host名一起用于唯一确定Tomcat中的一个Web应用。在将Web应用部署到Tomcat中时必须为Web应用指定一个上下文路径,并且在同一个Host中每个Web应用的上下文路径必须唯一。例如,localhost中部署了2个Web应用,它们的上下文路径分别是:app1和app2。访问上下文路径为app1的Web应用时使用的URL前缀为:http://localhost:8080/app1;访问上下文路径为app2的Web应用时使用的URL前缀为:http://localhost: 8080/app2。
反过来,Tomcat也可以利用上下文路径根据客户端请求URL的前缀将客户端请求分发到适当的Web应用。例如,请求URL的前缀为http://localhost:8080/app1的客户端请求被分发到第一个Web应用;请求URL的前缀为http://localhost:8080/app2的客户端请求被分发到第二个Web应用。
【注意】
上下文路径与Web应用的根目录名称是两个概念,对于同一个Web应用而言,这两个值未必是一样的。在将Web应用部署到Tomcat中时可以为Web应用设置不同于Web应用根目录的上下文路径。
在前面介绍server.xml配置时讲过,文件中的Host元素有一个属性是appBase,localhost的该属性值是webapps。这个属性的值是一个本地目录路径,可以是绝对路径也可以是相对路径,相对路径的基准路径是${TOMCAT_HOME}①,这个路径所指向的目录即为该Host的应用程序根目录。以localhost为例,server.xml中localhost appBase的值是webapps,所以localhost的应用程序根目录是${TOMCAT_ HOME}\webapps。
Tomcat在启动时会自动将应用程序根路径中的每一个子目录作为一个Web应用装载到所对应的Host中。所以对于localhost来说,Tomcat会自动将${TOMCAT_HOME}\webapps中所有的子目录自动加载作为localhost的Web应用。
所以,将Web应用部署到Tomcat中最简单的方法就是将Web应用的根目录复制到应用程序根目录中。按照这种方式部署的Web应用,其上下文路径与Web应用根目录的目录名一致。
这种部署方式的优点是简单易行而且不容易出错,缺点是当部署到Tomcat中的Web应用越来越多时,会使Tomcat的安装目录变得很庞大,而且这种方式要求所有的Web应用都放置在同一个目录中,不利于自由灵活地组织Web应用。
① ${...}表示取出某环境变量的值。在安装Tomcat完成时已经将TOMCAT_HOME添加到环境变量中,所以这里${TOMCAT_HOME}就表示取TOMCAT_HOME环境变量的值,也就是安装Tomcat的根目录。
在第6章介绍Tomcat服务器结构时提到:Server表示Tomcat服务器、Service表示Tomcat提供的一个服务、Engine表示Service中的处理引擎、Host表示一个虚拟主机,Context表示Host中的一个Web应用。所以,读者很容易就可以想到可以利用Context元素将Web应用部署到Tomcat中。
Context元素表示一个运行于特定虚拟主机中的Web应用,每个Web应用可以是一个war(Web Application Archive)文件或者文件系统中的一个文件夹。理论上在一个Web服务器中可以定义任意多个Web应用,每个Web应用必须有一个唯一的上下文路径(Context Path)。如果某个Web应用的上下文路径是空串的话,该Web应用就成为其所在虚拟主机的默认Web应用,所有请求URL没有与虚拟主机中其他任何一个Web应用的上下文路径匹配的客户请求都会被分发到该Web应用。
Context元素常见的属性如表7.1所示。
表7.1 Context元素属性表
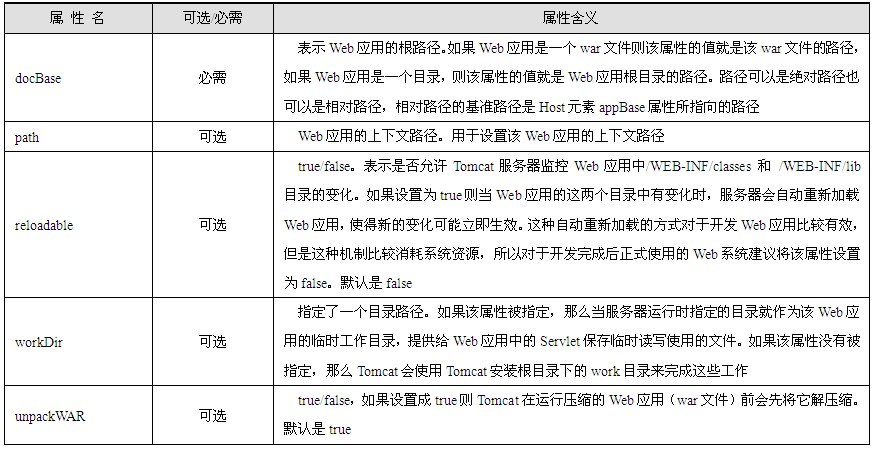
从Context元素的属性设置可以很清楚地发现,Web应用的根目录通过docBase指定,Web应用的上下文路径通过path属性指定,这两个属性是完全不同的。当然如果读者愿意,也可以将上下文路径设置成与Web应用的根目录一致,只要保证同一个Host中的Web应用上下文路径唯一就可以了。
如下是一个典型的Context元素的例子:
<Context docBase=”D:\\WebAppBase\application” path=”/app1”
workDir=”D:\\WebAppBase\application\work”/>
其中,D:\WebAppBase\application是Web应用的根目录,D:\WebAppBase\app1\work是Web应用的工作目录,/app1是该Web应用的上下文路径。
将Context元素配置到Tomcat服务器中的方法有如下几种:
1.在server.xml中添加Context元素。
因为server.xml是对整个Tomcat服务器的配置,Web应用隶属于虚拟主机,所以按照这种包含关系直接将Context元素添加到Host元素下。如下所示:
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true"
xmlValidation="false" xmlNamespaceAware="false">
<Context docBase="D:\\WebAppBase\application" path="/app1" workDir="D:\\WebAppBase\application\work"/>
</Host>
这种方式最简单直观,但是不利于维护,因为一个Tomcat服务器中可能会部署很多Web应用,每个Web应用必须配置一个Context元素,当server.xml文件中的Context元素很多以后会使得server.xml很大、很难阅读和维护。
2.添加到${TOMCAT_HOME}\conf\context.xml文件中
Tomcat提供了一个独立的文件conf/context.xml用于配置所有Web应用的Context元素。程序员可以将Context元素添加到该文件中,如下所示:
<Context>
<!-- Default set of monitored resources-->
<WatchedResource>WEB-INF/web.xml</WatchedResource>
<!--Uncomment this to disable session persistence across Tomcat restarts -->
<!--
<Nanager pathname="" />
-->
<!-- Uncomment this to enable Comet connection tacking (provides events
on sesslon expiracion as well as webapp lirecycle) -->
<!--
<Valve className="org.apache.catalina.valves.CometConnectionManagerValve" />
-->
</Context>
<Context docBase="D:\\WebAppBase\application" path="/app1" workDir="D:\\WebAppBase\application\work"/>
这种方式有利于将所有Web应用的Context配置从server.xml配置文件中独立出来,但是这种方式是将所有Web应用的配置放在一个配置文件中,当Web应用多了以后就不利于修改和维护。
3.为每个虚拟主机的所有Web应用使用一个独立的配置文件
${CATALINA_HOME}/conf/[enginename]/[hostname]/context.xml.default文件可以配置特定主机中所有Web应用的Context元素。其中,[enginename]是指主机所在的引擎的名称,即Engine元素name属性的值;[hostname]表示该主机的主机名,即Host元素name属性的值。例如,在localhost主机中添加三个Web应用后,${CATALINA_HOME}/conf/Catalina/localhost/context.xml.default文件内容如下:
<Context docBase="D:\\WebAppBase\application1" path="/app1" workDir="D:\\WebAppBase\application1\work"/>
<Context docBase="D:\\WebAppBase\application2" path="/app2" workDir="D:\\WebAppBase\application2\work"/>
<Context docBase="D:\\WebAppBase\application3" path="/app3" workDir="D:\\WebAppBase\application3\work"/>
4.为每个Web应用使用独立的配置文件
在${CATALINA_HOME}/conf/[enginename]/[hostname]目录中也可以通过使用xml文件来为每个Web应用定义Context,文件名为Web应用的上下文路径。例如在${CATALINA_HOME} /conf/Catalina/localhost/目录中新建文件app1.xml,并且添加如下内容也可以将application应用部署到localhost中:
<Context docBase="D:\\WebAppBase\application" path="/app1" workDir="D:\\WebAppBase\application\work"\>
将Web应用部署到Tomcat中后,从理论上说Web应用就已经可以通过Tomcat正常访问了。但是为了能够灵活地配置Web应用以及向Web应用中添加更加丰富的内容(例如Servlet),读者还应该了解Web应用部署描述符web.xml。
在第6章介绍Tomcat的配置时已经提到了,在Tomcat中每个Web应用都拥有一个对Web应用进行配置的web.xml文件,它位于Web应用根目录的WEB-INF目录下。由于Web应用的许多配置在各个Web应用之间是通用的,所以Tomcat使用${TOMCAT_HOME}\conf\web.xml文件(称通用部署描述符)来配置通用部分,各个Web应用将自己Web应用特有的配置内容放置在Web应用根目录下的WEB-INF\web.xml文件(称特有部署描述符)中。每个Web应用通过将通用部署描述符和特有部署描述符中的配置项合并起来进行配置,假如通用部署描述符和特有部署描述符中的某些配置项有冲突,则特有部署描述符中的配置项优先。
不管是通用部署描述符还是特有部署描述符,它们都是一个XML文件,都遵循Web应用部署描述符的结构。
web-app元素是Web应用部署描述符的根元素,它包含了若干个子元素,每个子元素对应于Web应用一个方面的配置,这些子元素的顺序是任意的。根据Web应用部署描述符2.5版本的XML Schema定义,web-app元素所有的属性和子元素如图7.2所示。
web-app元素包含三个主要属性:version、id和metadata-complete,其中最常用的是version,它表示Web描述文件兼容的最高版本。每个版本的Tomcat都有其兼容的Servlet标准版本号,例如Tomcat 6.x最高兼容Servlet 2.5,Tomcat 5.5最高兼容Servlet 2.4。每个Web应用也有其使用的版本号,该版本号与Servlet版本号一致,高版本的Web应用不能在只兼容低版本的Tomcat中使用,例如web-app元素version属性为2.5的Web应用不能应用于Tomcat 5.5中。
图7.2 Web部署描述符2.5版本Schema定义
web-app元素中可以定义许多元素,每一种元素对应一个Web应用的一项配置。其中最常用的有以下五种。
1.welcome-file-list:该元素定义了一个welcome文件列表,例如:
<welcome-file-list>
<welcome-file>index.html</welcome-file>
<welcome-file>index.htm</welcome-file>
<welcome-file>index.jsp</welcome-file>
</welcome-file-list>
welcome文件是目录的默认访问文件,即当请求URL指向的是一个目录而不是一个文件时,目录中的默认访问文件就会成为目标访问文件。在welcome文件列表中的文件是有序的,排在前面的文件将被优先返回,当前面的文件在目录中不存在时才会依次寻找排在后面的文件。例如,在welcome-file-list为上面所示配置时,假如在上下文路径为test的Web应用的根目录中有index.html和index.jsp两个文件,那么请求URL为http://localhost:8080/test的请求相当于请求URL为http://localhost:8080/test/index. html的请求。
2.servlet和servlet-mapping:这两个元素用于向Web应用中添加Servlet。servlet元素用于定义Servlet的名称、实现类等属性,servlet-mapping用于定义Servlet的路径映射方式。具体的实现和配置方式将在后面介绍Servlet技术时详细介绍。
3.filter和filter-mapping:这两个元素用于向Web应用中添加过滤器。filter用于定义过滤器的名称、实现类等属性,filter-mapping用于定义filter的路径映射方式。具体的实现和配置方式将在介绍Servlet过滤器技术时详细介绍。
4.mime-mapping:该元素用于定义在Web应用中,如何根据文件名后缀映射文件的mime类型。例如:
<mime-mapping>
<extension>htm</extension>
<mime-type>text/html</mime-type>
</mime-mapping>
表示将所有后缀名为htm的文件映射为text/html类型。
【注意】
MIME是Multipurpose Internet Mail Extensions(多用途Internet邮件扩展)的简称,最初作为电子邮件非文本格式附件传输方式被提出和使用,现在这种方式被广泛应用于使用HTTP协议传输的各种应用中。MIME类型由内容类型(大类型)和子类型(小类型)组成,被用于判断二进制数文件的内容和打开方式。
5.session-config:用于配置session的一些参数,例如session的超时时间:
<session-config>
<session-timeout>30</session-timeout>
</session-config>
Tomcat默认的通用Web应用部署描述符的初始内容如下:
<?xml version="1.0" encoding="ISO-8859-1"?>
<web-app xmlns="http://java.sun.com/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee http://java.sun.com/xml/ns/javaee/web-app_2_ 5.xsd"
version="2.5">
<servlet>
<servlet-name>default</servlet-name>
<servlet-class>org.apache.catalina.servlets.DefaultServlet</servlet-class>
<init-param>
<param-name>debug</param-name>
<param-value>0</param-value>
</init-param>
<init-param>
<param-name>listings</param-name>
<param-value>false</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet>
<servlet-name>jsp</servlet-name>
<servlet-class>org.apache.jasper.servlet.JspServlet</servlet-class>
<init-param>
<param-name>fork</param-name>
<param-value>false</param-value>
</init-param>
<init-param>
<param-name>xpoweredBy</param-name>
<param-value>false</param-value>
</init-param>
<load-on-startup>3</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>default</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>jsp</servlet-name>
<url-pattern>*.jsp</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>jsp</servlet-name>
<url-pattern>*.jspx</url-pattern>
</servlet-mapping>
<session-config>
<session-timeout>30</session-timeout>
</session-config>
<mime-mapping>
<extension>abs</extension>
<mime-type>audio/x-mpeg</mime-type>
</mime-mapping>
<mime-mapping>
<extension>ai</extension>
<mime-type>application/postscript</mime-type>
</mime-mapping>
<mime-mapping>
<extension>aif</extension>
<mime-type>audio/x-aiff</mime-type>
</mime-mapping>
...
<mime-mapping>
<extension>doc</extension>
<mime-type>application/vnd.ms-word</mime-type>
</mime-mapping>
<mime-mapping>
<extension>ppt</extension>
<mime-type>application/vnd.ms-powerpoint</mime-type>
</mime-mapping>
<welcome-file-list>
<welcome-file>index.html</welcome-file>
<welcome-file>index.htm</welcome-file>
<welcome-file>index.jsp</welcome-file>
</welcome-file-list>
</web-app>
可以发现,该默认的部署描述符中定义了两个Servlet(名称分别为default和jsp)、一个session-config、若干个mime-mapping和一个welcome-file-list。
1.default Servlet
这里配置的default Servlet是使用于所有Web应用的默认Servlet,即假如在Host中没有定义Servlet或者到达的请求无法根据匹配规则分发到任何一个Servlet时,请求就会被分发到default Servlet。部署描述符中的如下部分对default Servlet进行了设置:
<servlet>
<servlet-name>default</servlet-name>
<servlet-class>org.apache.catalina.servlets.DefaultServlet</servlet-class>
<init-param>
<param-name>debug</param-name>
<param-value>0</param-value>
</init-param>
<init-param>
<param-name>listings</param-name>
<param-value>false</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
...
<servlet-mapping>
<servlet-name>default</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
servlet-name定义了这个Servlet的名称,为default,用于标识这个Servlet;servlet-class是该Servlet使用的Java类,这里配置的是Tomcat提供的默认default Servlet的实现,正是这个Servlet实现了对静态Web对象的访问,使Tomcat能够支持静态Web对象访问;init-param定义了一些参数,这些参数在org.apache.catalina.servlets.DefaultServlet中使用;load-on-startup定义了一个整数值,当该值是0或正整数时,Tomcat在启动时必须加载和初始化该Servlet,而且保证该值越小的Servlet越早被加载并初始化;当该值是负数或该配置项不存在时Tomcat可以选择不在启动时加载和初始化Servlet。
url-pattern定义了一个请求URI模板,请求URI与该模板相匹配的请求将被分发到对应的Servlet。default Servlet的url-pattern是/,它可以与任意URI匹配,所以当没有其他Servlet的url-pattern更合适时,请求就会被分发到default Servlet。
2.jsp Servlet
jsp Servlet是Tomcat提供的用于处理所有JSP文件的Servlet,这也是Tomcat能正确处理JSP文件请求的原因。部署描述符中对于jsp Servlet的配置如下:
<servlet>
<servlet-name>jsp</servlet-name>
<servlet-class>org.apache.jasper.servlet.JspServlet</servlet-class>
<init-param>
<param-name>fork</param-name>
<param-value>false</param-value>
</init-param>
<init-param>
<param-name>xpoweredBy</param-name>
<param-value>false</param-value>
</init-param>
<load-on-startup>3</load-on-startup>
</servlet>
...
<servlet-mapping>
<servlet-name>jsp</servlet-name>
<url-pattern>*.jsp</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>jsp</servlet-name>
<url-pattern>*.jspx</url-pattern>
</servlet-mapping>
在Servlet配置的结构上,jsp Servlet与default Servlet一致,其含义也相同。这里需要强调的是url-pattern,有两个servlet-mapping中定义的两个url-pattern都对应jsp Servlet,这在web.xml中是允许的。这两个servlet-mapping产生的效果就是所有访问*.jsp和*.jspx的文件都被分发到jsp Servlet进行处理,也就是说,Tomcat中的JSP文件支持*.jsp和*.jspx两种格式。
3.session-config
session-config用于配置在Web应用中与session有关的设置,部署描述符中对于session-config的配置如下:
<session-config>
<session-timeout>30</session-timeout>
</session-config>
session-timeout用于设置session的超时时间,这里设置为30分钟。
4.mime-mapping
在部署描述符中预设了很多mime-mapping,用于将特定的文件后缀与一种MIME类型对应起来。开发人员可以通过在这里设置映射关系将Web应用中的某些文件映射为特定的MIME类型,以便客户端在接收到此类文件时可以使用适当的应用程序打开。部署描述符中对于mime-mapping的设置如下例所示:
<mime-mapping>
<extension>htm</extension>
<mime-type>text/html</mime-type>
</mime-mapping>
extension表示这种文件的后缀,mime-type表示将这种文件映射为MIME类型,该例将htm文件映射为text/html类型。
5.welcome-file-list
welcome-file-list定义了欢迎文件列表,即当请求URI指向一个目录时,那么就在目录中依次寻找欢迎文件列表中的文件,将找到的第一个返回。部署描述符中默认定义了三个欢迎文件:index.html、index.htm和index.jsp。
开发人员可以使用部署描述符对Web应用的许多方面进行配置,如果开发人员希望修改的配置对所有Web应用都有效,例如Session的超时时间,那么就可以直接在通用Web应用部署描述符中进行设置;如果开发人员只希望对某一个Web应用有效,例如某一个Servlet,那么就在该Web应用的特有部署描述符中进行设置。这样也简化了Web应用的配置。
Servlet是Java Web开发最重要的基础技术,绝大多数Java Web开发技术都是基于Servlet基础的,所以了解Servlet技术是深入理解其他Java Web开发技术的前提。同时Servlet也是Tomcat支持的最主要技术之一。
本章将简单介绍Servlet的基本概念、原理以及使用方法。重点介绍其中主要的一些接口和对象,包括使用广泛的ServletRequest和ServletResponse,以及Servlet中的高级概念——Servlet过滤器。最后通过大量实例应用为读者分别介绍Servlet开发、ServletConfig的使用、ServletContext的使用、HttpSession的使用、Cookie的使用以及如何在应用中使用Servlet Filter。
Servlet是Java Web开发技术中最主要和最基础的技术,希望初学者能够认真学习本章的内容,并且根据所学的内容多做一些实验。
Servlet是一种可以配置进Servlet容器(如Tomcat)中用于处理客户端请求的特殊Java对象。Servlet Specification(Servlet规范)规定了Servlet对象和Servlet容器的协作方式,以及Servlet体系中相关的API;其中最关键的是Servlet接口,它规定了一个Servlet应该具有的行为;开发人员开发出符合Servlet接口的Java对象,并将其部署到Servlet容器中就可以使Servlet容器具有该Servlet实现的功能。Servlet通过配置Servlet容器被部署到Servlet容器中,多种多样的Servlet为Servlet容器添加了丰富的Web处理功能;同时也丰富了与Servlet容器相结合的Web服务器的功能。Tomcat是具有普通Web服务器功能的最典型的Servlet容器,通过配置Tomcat的配置文件可以将Servlet部署到Tomcat中。本章就将Tomcat作为默认的Servlet容器进行讲解和实验。
一个Servlet就是一个Java对象,一般来讲它与其他Java对象没有本质的区别,唯一特殊的是,它的实现类必须实现Servlet体系中的javax.servlet.Servlet接口,该接口规定了程序员实现的Servlet必须满足的一种标准格式,只有满足该格式的Servlet才能被部署到 Servlet容器中。举一个形象的例子,国家规定两孔圆头插座的规格标准是227IEC42(RVB)2×0.5mm2 6A250V标准,所有厂商生产的两孔圆头插座必须符合该标准,所有生产两孔圆头插头的厂商也必须符合该标准,否则生产出来的插头和插座就无法匹配。
同样道理,Servlet容器与Servlet之间的关系也相当于插座和插头的关系,Servlet规范规定了所有的Servlet必须符合javax.servlet.Servlet接口规范,所有的Servlet容器必须使用该规范规定的格式调用Servlet,所以程序员编写的Servlet也必须符合该规范。这样,编写的Servlet被部署到Servlet容器中后Servlet容器才能够与Servlet协调工作。
插头标准可能规定了插头的大小、电流、电压等参数,Servlet接口标准则规定了Servlet类必须实现的方法。Servlet接口规定的一个最主要的方法就是Servlet的执行方法,service()方法,该方法是一个Servlet用于处理请求和响应的全部代码。任何一个实现了Servlet接口的Java类都必须实现该方法,所以Servlet容器不需要知道部署到其中的每个Servlet的具体实现,当有请求到达时,Servlet容器只需要调用该Servlet类的service()方法即可。
或者也可以反过来说,一个实现了javax.servlet.Servlet接口的Java类的对象就是一个Servlet。所以实现javax.servlet.Servlet接口与一个Java类是一个Servlet的充分必要条件。
程序员在开发Servlet时,首先开发一个实现了Servlet接口的Java类,暂称其为Servlet类;然后将该Servlet类部署到Tomcat中,此时Servlet还是以Java类的形式存在,并不具有任何实例;启动Tomcat,Tomcat实例化一个该Servlet的对象并且对其进行初始化;当有客户请求指向该Servlet时,Tomcat调用该Servlet对象的执行方法对请求和响应进行处理;处理完后销毁该Servlet对象。所以一个Servlet对象的生命周期包括三个阶段:初始化阶段、执行阶段和销毁阶段。如图8.1所示。
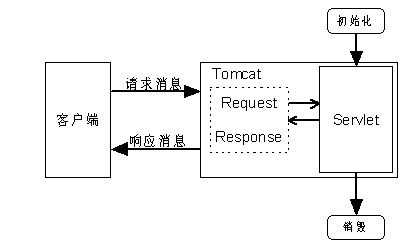
图8.1 Servlet工作过程示意图
如图8.1所示,Servlet在被初始化后才会进入Tomcat的地址空间中响应客户端的请求,在服务结束后在适当的时机Tomcat会销毁Servlet,将Servlet从地址空间中清除。
Tomcat初始化Servlet包括两个动作:将Servlet实例化并加载到Tomcat地址空间中;调用Servlet的初始化方法对Servlet进行初始化。
【注意】
实例化和初始化是两个不同的概念。实例化是指根据Java类生成一个该类的对象,在实例化时会调用Java对象的构造方法,任意一个非抽象的Java类都可以被实例化;初始化是一个特殊的概念,并不是所有Java类都有初始化的概念,Servlet的初始化是指在从一个Servlet类实例化一个Servlet对象后再调用该Servlet对象的初始化方法对其进行初始化。可见初始化的前提必须是先实例化。所以这里提到的Tomcat对Servlet的初始化默认就包括了从Servlet类实例化一个Servlet对象。
Tomcat初始化Servlet的时机可能有三个:
启动Tomcat时:在前面介绍web.xml文件配置时,介绍了在配置Servlet时有一个load-on-startup子标签,该标签的值是一个整数值。如果某个Servlet的该标签值是0或正整数,那么该Servlet就会在Tomcat启动时被初始化,而且值越小初始化得越早;如果某个Servlet没有配置该标签或者该标签的值为负数,那么该Servlet在Tomcat启动时就不会被初始化。所以,对于所有load-on-startup子标签值为正整数的Servlet都会在Tomcat启动时被初始化。
有请求访问Servlet时:如上所述,所有load-on-startup子标签值没有配置为正整数的Servlet都不会在Tomcat启动时被初始化;它们采用的是Lazy初始化机制,就是只有当Servlet需要被使用时才初始化,也就是有请求访问Servlet时才初始化。
在Servlet所在Web应用的/WEB-INF/classes或/WEB-INF/lib目录发生变化时:在前面介绍的使用Context元素将Web应用部署到Tomcat中的方法时,介绍了Context元素有一个属性reloadable,当将该属性设置为true时,Tomcat就会监控该Web应用的/WEB-INF/classes 和 /WEB-INF/lib目录的变化,如果这两个目录发生了变化,Tomcat就会重新载入该Web应用,这时该Web应用中的所有Servlet就会被重新初始化。
Servlet被销毁的时机由Tomcat指定,Tomcat并不会在Servlet响应完请求后就立即销毁Servlet,而是选择一个适当的时机销毁Servlet,销毁Servlet时Tomcat会调用Servlet的销毁方法。通常Tomcat销毁一个Servlet的时机可能有如下几种情况:
Servlet已处理完所有请求,并且长期处在闲置状态;
Servlet已处理完所有请求,并且当前Tomcat的空间资源相对紧张,需要销毁一些Servlet释放空间;
Servlet已处理完所有请求,并且当前Servlet需要被重启。
根据前面对Servlet生命周期的介绍,Servlet真正用于处理客户端请求的阶段是Servlet的执行阶段。Servlet采用Request/Response模式进行工作。如图8.1所示,在Servlet被初始化前直到处理完请求被销毁,其执行过程如下(假设Servlet在Tomcat启动时不被初始化)。
(1)在有指向Servlet的请求到达Tomcat时,Tomcat对Servlet进行实例化,并且调用Servlet的init()方法对Servlet对象进行初始化。
(2)Tomcat将客户端的请求构造成一个Request对象,同时构造一个输出指向客户端的Response对象,将Request对象和Response对象同时作为参数传递给Servlet的service()方法,并执行该方法。
(3)Servlet的service()方法解析Request对象,执行相应的操作,并且根据执行结果设置Response对象。
(4)Tomcat根据Servlet设置的Response对象,构造相应的响应消息返回给客户端。
(5)Servlet完成对请求的处理后,在适当的时候Tomcat会调用Servlet的destroy()方法将Servlet销毁。
Tomcat中可以配置若干个主机,一个主机可以配置若干个Web应用,一个Web应用中又可以配置若干个Servlet。那当有请求到达Tomcat时,Tomcat如何判断请求所要访问的Servlet呢?每个请求都有其所访问资源的URL,URL是全局资源定位符,用于说明请求所访问资源的位置,而且一个URL在同一时刻所指向的网络资源位置也是唯一的。Tomcat根据请求的URL确定请求所访问的Servlet。
根据Tomcat的层次结构:Server → Service → Host → Context → Servlet,请求在到达Tomcat后首先根据请求的主机名(域名)被分发到某个Host;再根据请求URI以及Host中各Context(Web应用)的上下文路径被分发到某个Web应用;最后将请求URI与Web应用中所有Servlet的URL Pattern进行匹配,匹配成功的Servlet将处理该请求。主机的主机名在Tomcat的server.xml文件中设置(Host标签表示一个主机)。Web应用上下文路径在Context标签中配置(webapps路径下的Web应用的上下文路径就是Web应用的根目录名),Context标签的path属性表示该应用的上下文路径,Context标签的配置信息可能存在于多个位置(参见7.2.2节)。Servlet在Web应用部署描述符web.xml文件中通过servlet标签和servlet-mapping标签配置,这里的Web应用部署描述符包括Tomcat的通用部署描述符和各个Web应用中的特有部署描述符。
Tomcat在启动时,Tomcat分别读取和解析server.xml文件、各个Context描述文件和各个web.xml文件,获取其中关于Host、Context和Servlet的配置信息,构建一个从Host到Servlet的树形结构,并将其保存在Tomcat的内存空间中。当有新请求到达Tomcat时,Tomcat解析请求的URL根据URL的格式将请求从该树顶端以级分发到Servlet。
一种配置情况的示例如图8.2所示。
如图8.2的示例所示,Tomcat中配置了两个Host:localhost和csai.cn;localhost中配置了两个Web应用:user-manage和book;user-manage和book中又分别定义了三个Servlet,每个Servlet的URL Pattern如图中所示。针对该例的配置情况,考虑具有如下几个URL请求的分发情况。
(1)http://localhost/user-manage/login/setup
首先根据域名localhost将请求分发到localhost主机,然后将请求URI“/user-manage/login/setup”与主机中所有Web应用的上下文路径进行匹配,该URI与上下文路径为user-manage的Web应用匹配成功,然后将相对路径“/login/setup”与user-manage中所有Servlet的URL Pattern进行匹配,与“/login/*”匹配成功,所以该请求将由URL Pattern为“/login/*”的Servlet处理。
(2)http://localhost/book/store/query.do?id=12432
主机和Web应用上下文路径的匹配情况类似于上例,但特殊的是该例中包含了查询参数。没关系,在匹配时可以不用管查询参数,直接忽略就可以了。所以很明确,该请求被分发到book中的“*.do”Servlet。
(3)http://localhost/book/buy
根据域名和Web应用可以将该请求分发到localhost的book应用,但是该应用的所有模板都无法与相对路径“/buy”相匹配。在这种情况下,请求会被分发给default Servlet处理。default Servlet是每个Web应用都有的一个比较特殊的Servlet,它的URL Pattern是“/”,这是由Tomcat默认提供的web.xml中配置的。
(4)http://localhost/webpage/setup.html
根据域名可以将该请求分发到localhost主机,但localhost中并不存在名为webpage的Web应用。对于这种情况,Tomcat将该请求分发到localhost主机的默认应用。在${TOMCAT_HOME}/webapps/目录中有一个特殊的目录ROOT,该目录表示了一个localhost的默认应用,当请求URI无法与任何Web应用的上下文路径相匹配时就会被分发到该应用。由于该应用默认并没有配置任何Servlet,所以该请求最终还是被分发到default Servlet。
default Servlet是Tomcat自带的一个用于处理静态文件请求的Servlet。由于default Servlet的URL Pattern是“/”,它可以匹配任何相对路径,所以如果某个请求的URL无法与任何其他Servlet的URL Pattern相匹配时,请求就会被分发到default Servlet。default Servlet将分发到它的请求都作为静态文件请求处理,例如上面第三个URL被分发到default Servlet中后,default Servlet就会认为该请求是想请求book应用根目录下面的buy文件,假如book应用根目录下不存在buy文件,Tomcat就会返回一个错误,指示请求的资源不存在;如上面第四个URL,default Servlet会认为该请求是想请求ROOT目录下webpage目录中的setup.html文件,如果ROOT目录下存在webpage目录,并且webpage目录中存在setup.html文件,那么该文件将被返回,否则Tomcat会返回一个错误,指示请求的资源不存在。
在上面的例子中,读者已经发现在URL Pattern中可以用*代表任意字符,很多读者肯定会很快将这个模式与正则表达式联系起来。但可惜的是URL Pattern并不支持使用正则表达式描述。实质上,在Servlet规范中已经对URL Pattern的写法、意义以及当有多个URL Pattern时匹配次序的选择都是有明确规定的。在Servlet规范中定义了URL Pattern支持的四种格式:
(1)以“/”开头和以“/*”结尾:这种模式用于匹配一个路径前缀,比如“/login/*”可以匹配“/login/aaa”、“/login/bb/a.html”和“/login/cc/dd/q?x=5”等。
(2)以前缀“*.”开始:这种模式用于匹配以一种后缀结束的路径,比如“*.do”可以匹配“/aaa.do”、“/bb/cc/d.do”和“/bb/cc/q.do?x=5”等。
(3)字符“/”:这种模式只用来表示default Servlet。
(4)一个以“/”开头的字符串,并且不符合以上的任何一种格式:除了上面三种格式以外,其他格式都被用于精确匹配。比如“/register”只被用于匹配路径“/register”,而无法匹配“/register/default”;即使形如“/register/*.do”也只能匹配路径“/register/*.do”,而无法匹配“/register/start.do”。
除了以上规定的四类URL Pattern,其他格式都会被认为是非法格式,如果Tomcat在启动时探测到非法格式,Tomcat会在启动窗口中打印错误。
如果在一个Web应用中,这几类URL Pattern都存在,那么Tomcat会按照一定的优先顺序逐个匹配,即使有一个相对路径同时与多个URL Pattern相匹配,Tomcat也会选择优先顺序在先的Servlet处理请求。顺序如下:
首先Tomcat会从精确匹配模式(以上第4)类模式)中寻找是否有相匹配的模式。比如分别有模式“/aa”、“/aa/bb”和“/aa/*”,对于相对路径为“/aa/bb”的请求就会与模式“/aa/bb”相匹配;
如果没有匹配成功则从属于以上第(1)类模式的各种URL Pattern中寻找相匹配的模式。比如分别有模式“/aa”、“/aa/bb”和“/aa/*”,对于相对路径为“/aa/bb/cc”的请求就会与模式“/aa/*”相匹配。而且,假如这种匹配是最长匹配原则,比如分别有模式“/aa/*”和“/aa/bb/*”,对于相对路径为“/aa/bb/cc”的请求会与模式“/aa/bb/*”相匹配;
如果没有匹配成功则从属于以上第(2)类模式的各种URL Pattern中寻找相匹配的模式。比如分别有模式“/aa”、“/aa/bb”、“/aa/*”和“*.do”,对于相对路径为“/bb/cc.do”的请求就会与模式“*.do”相匹配;
如果以上各类模式都没有匹配成功,那么就会与“/”匹配成功,并最终由default Servlet处理。
作者一直认为,学习编程最主要的是实践。在学习的过程中,不断构造适当代码并进行不断实验是最好的学习过程。学习Servlet也一样。在开始学习之前,读者先搭建好实验环境,在学习过程中可以将实例直接放进测试环境中测试。
本书中将Eclipse作为Servlet的开发环境,将Tomcat作为Servlet的运行环境。前面已经介绍了Eclipse和Tomcat的配置和使用,本节将介绍如何构建Servlet工程,并且将实现一个Servlet的Hello World工程、将该工程部署到Tomcat中、以及运行测试该Servlet。
1.新建工程
新建一个能够开发和测试Servlet的工程——ServletTest。在介绍Eclipse的使用时已经提到,用于开发Servlet应用的工程应该是动态Web工程。根据前面介绍的新建动态Web工程的步骤在Eclipse中新建一个动态Web工程ServletTest,建成的ServletTest工程在工程浏览视图中的内容如图8.3所示:
图8.3 新建ServletTest工程
新建的Web工程搭建了一个动态Web工程的基本架构,但是没有定义任何具有实质功能的内容。
2.编辑Servlet
工程建好后就可以直接新建待开发的Servlet。根据第5章中介绍的步骤新建一个TestServlet,所属的包为cn.csai.web.servlet。Eclipse为TestServlet自动生成的初始内容如下:
package cn.csai.web.servlet;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class TestServlet extends javax.servlet.http.HttpServlet implements javax.servlet.Servlet {
static final long serialVersionUID = 1L;
public TestServlet() {
super();
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
}
其中自动生成的方法中,除了默认构造方法外还有两个重要的方法doGet()和doPost(),这是大部分Servlet都会覆盖的方法。doGet()用于处理客户端的GET请求,doPost()用于处理客户端的POST。也就是说,当客户端使用GET方法的HTTP消息访问Servlet时,Servlet就将请求和响应传递给doGet()方法,由doGet()方法处理请求和响应;当客户端使用POST方法的HTTP消息访问Servlet时,Servlet就将请求和响应传递给doPost()方法,由doPost()方法处理请求和响应。
这两个方法的方法体中初始没有任何内容,程序员就将自己的代码添加到方法体中,所谓Servlet的不同主要也就是这两个方法的方法体有所不同。对于Hello World应用,读者可以在doGet()方法中添加输出“Hello World”的语句。将如下所示的HelloWorld代码体添加到doGet()方法中:
PrintWriter pw = response.getWriter();
pw.write("Hello World");
pw.flush();
pw.close();
这段代码从response对象获得一个Writer对象,然后利用Writer对象向客户端输出一个“Hello World”字符串,最后刷新和关闭Writer对象。所以这段代码的作用就是向客户端浏览器输出一个“Hello World”字符串。
Servlet需要被添加到Web应用中才能进行工作。使用Eclipse向导新建Servlet时,Eclipse已经自动将Servlet的配置信息写入到应用的web.xml文件中(参见第5章)。web.xml文件的内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<web-app id="WebApp_ID" version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee"
xmlns:xsi="http://www. w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/ j2ee http://java.sun.com /xml/ns/j2ee/web-app_2_4.xsd">
<display-name>
ServletTest</display-name>
<servlet>
<description>
</description>
<display-name>
TestServlet</display-name>
<servlet-name>TestServlet</servlet-name>
<servlet-class>
cn.csai.web.servlet.TestServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>TestServlet</servlet-name>
<url-pattern>/TestServlet</url-pattern>
</servlet-mapping>
<welcome-file-list>
<welcome-file>index.html</welcome-file>
<welcome-file>index.htm</welcome-file>
<welcome-file>index.jsp</welcome-file>
<welcome-file>default.html</welcome-file>
<welcome-file>default.htm</welcome-file>
<welcome-file>default.jsp</welcome-file>
</welcome-file-list>
</web-app>
3.部署Web应用
新建的工程必须被部署到Tomcat中才能够通过Tomcat测试,将Web工程部署到Tomcat中包括以下步骤:
(1)新建适用于Tomcat的Web应用:在${TOMCAT_HOME}/webapps目录下新建ServletTest目录;
(2)将Web工程的所有class文件和WEB-INF目录复制到Tomcat Web工程的适当目录中:打开ServletTest工程在文件系统中的目录(记为${ECLIPSE_PROJECTS}),将WebContent子目录中的WEB-INF目录整个复制到${TOMCAT_HOME}/webapps/ServletTest目录中;再将${ECLIPSE_ PROJECTS}/ServletTest/build中的classes目录复制到${TOMCAT_HOME}/webapps/ ServletTest/WEB- INF目录中;
(3)重新启动Tomcat。
4.运行Servlet
运行Servlet是相对比较容易的。在将Web工程部署到Tomcat中后,确保Tomcat已正常启动。然后打开浏览器,键入如下URL便会看到TestServlet的执行结果,如图8.4所示。
http://localhost:8080/ServletTest/TestServlet
图8.4 运行TestServlet
以上展示了新建、编辑、部署和运行Servlet工程和Servlet的步骤,读者在今后的学习中可以将该ServletTest工程作为测试环境,不断地修改TestServlet的doGet()方法和doPost(),以用于测试学到的新内容,而不需要重新建立新的工程和新的Servlet。步骤如下:
(1)在Eclipse中修改TestServlet的内容,保存并编译;
(2)删除${TOMCAT_HOME}/webapps/ServletTest/WEB-INF目录中的classes目录,将${TOMCAT_ HOME}/webapps/ServletTest/WEB-INF目录中的classes目录复制到${TOMCAT_HOME} /webapps/ ServletTest/WEB-INF目录中;
(3)重启Tomcat;
(4)输入URL测试。
Servlet接口代表一个Servlet。这在介绍Servlet的概念时已经做了阐述。service()方法是Servlet接口最核心的方法,但Servlet接口并不仅仅定义了这一个方法,Servlet接口的定义如下:
package javax.servlet;
import java.io.IOException;
public interface Servlet
{
public abstract void init(ServletConfig servletconfig)
throws ServletException;
public abstract ServletConfig getServletConfig();
public abstract void service(ServletRequest servletrequest, ServletResponse servletresponse) throws ServletException, IOException;
public abstract String getServletInfo();
public abstract void destroy();
}
其中:
init():该方法对应Servlet生命周期的初始化阶段,它在Tomcat初始Servlet时被调用。实质上,所谓Tomcat对Servlet初始化就是Tomcat调用Servlet的init()方法。该方法提供了一个ServletConfig作为参数,这是为了便于Servlet开发者能够在init()方法中获得关于Servlet的配置信息,该参数在Tomcat调用init()方法时由Tomcat提供,Tomcat可以通过调用getServletConfig()方法获得。同时,在初始化时还允许抛出ServletException,即开发人员在编写init()方法时可以将未处理的异常情况抛出为ServletException;
service():该方法对应于Servlet生命周期的执行阶段,在该Servlet的请求到达时被调用,任何到达该Servlet的请求都会执行这同一段代码,只是不同请求的输入参数不同;输入参数ServletRequest代表到达Servlet的请求,ServletResponse代表Servlet对请求的响应,Tomcat构造一个到客户端的ServletResponse对象并将其传给service()方法,方法在执行期间对该ServletResponse进行设置和操作,service()方法执行完后Servlet也就完成了对客户端的响应。该方法不仅可以抛出ServletException异常还可以抛出IOException,那是因为service()方法中经常会通过ServletResponse对象向客户端传输响应数据,在这个过程中可能会发生输入输出错误;
destroy():该方法对应于Servlet生命周期的销毁阶段,在Servlet执行结束后Tomcat可以适时地将其销毁,在Servlet被销毁时Tomcat会调用该方法。通常该方法中可以进行诸如释放资源等一些收尾工作;
getServletConfig():返回与该Servlet相关的ServletConfig对象;
getServletInfo():返回该Servlet的描述,通常该描述信息是Servlet实现者提供的用于描述Servlet的信息。
【注意】
由于Servlet基本上都被用于处理HTTP请求和响应,所以需要程序员就将Servlet等同于处理HTTP请求和响应的HttpServlet,但实际上Servlet接口所表示的是一种普遍概念的Servlet,它不仅表示处理HTTP请求和响应的HttpServlet,也可以用于表示处理其他通用请求和响应的Servlet。同样ServletRequest和ServletResponse不能将其狭义理解为HTTP请求和HTTP响应。
ServletConfig接口代表对一个Servlet的配置信息,对应于web.xml中对该Servlet的配置项,如下是web.xml中default Servlet的配置信息:
<servlet>
<servlet-name>default</servlet-name>
<servlet-class>org.apache.catalina.servlets.DefaultServlet</servlet-class>
<init-param>
<param-name>debug</param-name>
<param-value>0</param-value>
</init-param>
<init-param>
<param-name>listings</param-name>
<param-value>false</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>default</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
ServletConfig接口表示了一个Servlet的配置信息,在一个Servlet中可以通过ServletConfig接口的对象获得Servlet的这些配置信息。
ServletConfig接口的定义如下:
package javax.servlet;
import java.util.Enumeration;
public interface ServletConfig
{
public abstract String getServletName();
public abstract ServletContext getServletContext();
public abstract String getInitParameter(String s);
public abstract Enumeration getInitParameterNames();
}
其中:
getServletName():该方法获得该Servlet的名称,对应于web.xml中该Servlet的servlet-name标签的内容,例如default;
getServletContext():该方法返回该ServletConfig对象对应的ServletContext对象;
getInitParameter():该方法返回具有指定名称的初始参数的值。对应于Servlet的配置中,通过init-param标签定义的Servlet初始化参数,param-name是参数名,param-value是参数值。getInitParameter()方法可以通过参数名获得参数值,例如getInitParameter(“debug”)→ 0;
getInitParameterNames ():该方法返回一个Enumeration类型的对象,该对象中包含了该Servlet定义的所有初始化参数的参数名。
ServletContext接口代表了Servlet所运行的上下文信息,定义了一个Servlet环境对象。Tomcat在加载Web应用时,为每个Web应用创建唯一的ServletContext对象,Web应用中的Servlet通过该ServletContext对象与Servlet容器进行通信。定义如下:
package javax.servlet;
import java.io.InputStream;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.Enumeration;
import java.util.Set;
public interface ServletContext
{
public abstract ServletContext getContext(String s);
public abstract int getMajorVersion();
public abstract int getMinorVersion();
public abstract String getMimeType(String s);
public abstract Set getResourcePaths(String s);
public abstract URL getResource(String s) throws MalformedURLException;
public abstract InputStream getResourceAsStream(String s);
public abstract RequestDispatcher getRequestDispatcher(String s);
public abstract RequestDispatcher getNamedDispatcher(String s);
public abstract Servlet getServlet(String s) throws ServletException;
public abstract Enumeration getServlets();
public abstract Enumeration getServletNames();
public abstract void log(String s);
public abstract void log(Exception exception, String s);
public abstract void log(String s, Throwable throwable);
public abstract String getRealPath(String s);
public abstract String getServerInfo();
public abstract String getInitParameter(String s);
public abstract Enumeration getInitParameterNames();
public abstract Object getAttribute(String s);
public abstract Enumeration getAttributeNames();
public abstract void setAttribute(String s, Object obj);
public abstract void removeAttribute(String s);
public abstract String getServletContextName();
}
其中:
getContext(String s):该方法通过提供URI获得Server上其他ServletContext对象。参数是一个以“/”开始的字符串,表示相对于Server根路径的相对路径;
getMajorVersion():返回该Servlet容器支持的Servlet规范的主版本号;
getMinorVersion():返回该Servlet容器支持的Servlet规范的次版本号;
getMimeType(String s):根据提供的文件类型返回该文件类型对应的MIME类型;
getResourcePaths(String s):根据提供的子路径返回Web应用中的该子路径下的所有一级资源;例如Web应用中有如下文件:
/index.html
/images/bg.jpg
/WEB-INF/web.xml
/WEB-INF/lib/my.lib
那么:
getResourcePaths(“/”)将返回“/index.html”、“/images/”和“/WEB-INF/”;
getResourcePaths(“/WEB-INF”)将返回“/WEB-INF/web.xml”和“/WEB-INF/lib/”。
getResource(String s):根据给定的路径返回表示路径所指向资源的URL对象,提供的路径必须以“/”开头,表示以Web应用根路径计算的相对路径;
getResourceAsStream(String s):将给定路径所指向资源作为InputStream的对象返回。路径的格式和意义同getResource()方法;
getRequestDispatcher(String s):返回一个到给定路径所指向资源的RequestDispatcher对象。RequestDispatcher对象可以用于将请求转到资源或者将资源包含到响应中;
getNamedDispatcher(String s):返回一个到给定Servlet的RequestDispatcher对象,参数为Servlet名称;
getServlet(String s):已过时。返回名称为给定参数的Servlet对象;
getServlets():已过时。返回一个Enumeration,包含该ServletContext中所有的Servlet对象;
getServletNames():已过时。返回一个Enumeration,包含该ServletContext中所有Servlet的名称;
log(String s):记录日志,将参数字符串记录到日志文件中;
log(Exception exception,String s):记录日志,将给定Exception对象的stack trace和给定字符串所表示的解释字符串记录到日志文件中;
log(String s, Throwable throwable):将给定的解释字符串和给定Throwable对象的stack trace记录到日志文件中;
getRealPath(String s):返回给定路径所指向资源在文件系统中的绝对路径。路径的表现方式取决于Servlet容器所运行的操作系统;
getServerInfo():返回所运行的Servlet容器的名称版本号,输出格式为server-name/server-version;
getInitParameter(String s):返回给定具有给定名称的初始化参数的值,假如不存在给定名称的初始化参数则返回null;
getInitParameterNames():返回一个Enumeration对象,包含所有初始化参数的名称;
getAttribute(String s):Servlet容器可能为Servlet还提供了除该接口定义的属性以外的其他属性,该方法提供了一个扩展方法允许Servlet容器为Servlet提供其他可访问的属性。该方法根据属性名返回属性值,属性值可以是任何Object对象或其子对象;
getAttributeNames():返回一个Enumeration对象,包含Servlet容器提供的所有属性的名称;
setAttribute(String s, Object obj):在该ServletContext中设置属性名/值对,如果设置的属性名已经存在则用新值替换旧值,如果设置的属性值为null,则删除该属性;
removeAttribute(String s):在该ServletContext中删除具有给定名称的属性;
getServletContextName():在配置Web应用的web.xml时,可以通过display-name指定Web应用的名称,该方法返回配置的该名称。
RequestDispatcher接口表示一个请求转发器,它接收客户端的请求并把请求转发到任何Web资源,可以是:Servlet、JSP、HTML等。
定义如下:
package javax.servlet;
import java.io.IOException;
public interface RequestDispatcher {
void forward(ServletRequest arg0, ServletResponse arg1) throws ServletException, IOException;
void include(ServletRequest arg0, ServletResponse arg1) throws ServletException, IOException;
}
其中:
forward():将请求从一个Servlet转发到Server上的任何其他Web资源。该方法的出现允许一个Servlet对请求进行预处理,然后在响应消息发出前将请求转发给另一个Web资源,由另一个Web资源完成对请求的响应;
include():将资源的内容包含到响应消息中。
在Servlet接口、ServletConfig接口和ServletContext接口的方法中,虽然使用Servlet的getServletConfig()可以获得一个ServletConfig接口的对象,再通过ServletConfig接口的getServletContext()方法可以获得一个ServletContext接口的对象,但是这几个接口所表示的概念并不具有类似的层叠关系。
这几个接口分别属于不同的层面,ServletContext处于最高层,Servlet和ServletConfig属于同一层,在下层。每个Web应用有一个ServletContext对象,每个Servlet有一个ServletConfig对象,所以当一个Web应用中有多个Servlet时,从多个Servlet中获得的ServletContext对象是同一个,就是它们所在的Web应用的ServletContext对象。其关系如图8.5所示。
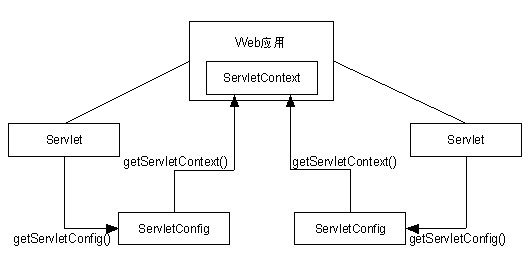
图8.5 Servlet、ServletConfig和ServletContext关系图
从各个概念所定义的方法也可以看出这种区别,ServletConfig中的方法可以用来获取单个Servlet相关的配置信息,而ServletContext中的方法可以用来获取Web应用或者Servlet容器相关的配置信息,这也是该接口被命名为ServletContext的原因,因为它代表了Servlet所运行环境的信息。RequestDispatcher接口与这几个概念之间没有明确的层次关系,它仅代表一个请求转发器。
除了这几个关键概念外,还有两个接口所表达的概念也非常重要,它们是ServletRequest和ServletResponse,这两个接口分别表示Servlet的请求和Servlet返回给客户端的响应。它们被广泛应用于Servlet的各个处理场合和概念中。这两个概念将在本章的后续小节中介绍。
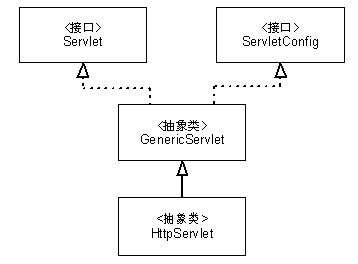
GenericServlet实现了Servlet接口和ServletConfig接口,它表示一种通用的Servlet可代表处理各种类型请求的Servlet;它只是抽象类,不能直接用于处理Servlet请求,所以只能通过实现继承自GenericServlet的子类来完成处理特定请求的功能。值得注意的是,GenericServlet类不仅实现了Servlet接口,而且还实现了ServletConfig接口,所以GenericServlet类还包含了对Servlet配置信息的操作。
GenericServlet对Servlet接口和ServletConfig接口的实现只是一种最简单的默认实现,实质上并不具备实际意义,GenericServlet存在的意义就是用来被其他类继承的。GenericServlet的定义如下:
package javax.servlet;
import java.io.IOException;
import java.io.Serializable;
import java.util.Enumeration;
public abstract class GenericServlet
implements Servlet, ServletConfig, Serializable
{
private transient ServletConfig config;
public GenericServlet()
{
}
public void init(ServletConfig config) throws ServletException
{
this.config = config;
init();
}
public void init() throws ServletException
{
}
public abstract void service(ServletRequest servletrequest, ServletResponse servletresponse) throws ServletException, IOException;
public void destroy()
{
}
public ServletConfig getServletConfig()
{
return config;
}
public String getServletInfo()
{
return "";
}
public String getServletName()
{
return config.getServletName();
}
public String getInitParameter(String name)
{
return getServletConfig().getInitParameter(name);
}
public Enumeration getInitParameterNames()
{
return getServletConfig().getInitParameterNames();
}
public ServletContext getServletContext()
{
return getServletConfig().getServletContext();
}
public void log(String msg)
{
getServletContext().log((new StringBuilder()).append(getServletName()).append(":").append(msg). toString());
}
public void log(String message, Throwable t)
{
getServletContext().log((new StringBuilder()).append(getServletName()).append(":").append(message).toString(), t);
}
}
从代码中可以发现,GenericServlet定义了一个ServletConfig对象的私有成员,并将从init(ServletConfig config)方法中传入的ServletConfig对象做了封装,然后增加了一个不带任何参数的init()方法供子类继承,这样可以简化子类的实现;对于init()、destroy()、getServletConfig()和getServletInfo()方法提供了实现,但是没有在方法体中提供任何实质性内容,这实际上只是搭建了一个Servlet的框架供子类使用,子类只需要覆盖其关心的方法即可;对于service()方法,GenericServlet将其定义为抽象方法,没有提供默认实现,因为service()方法是一个Servlet的核心处理代码,也是一个Servlet区别于其他Servlet的关键部分,所以GenericServlet将其定义为抽象方法,强制其具体子类提供该方法的具体实现。
对于ServletConfig接口的几个方法,GenericServlet也提供了最简单的实现。从代码体中可以发现,这种实现实际上只是对其封装的config的接口的一种调用,所以这种实现并没有实质作用,具体所执行的工作只能由交给传递进来的实现了ServletConfig接口的类来实现。
除此之外,GenericServlet类提供了两个log()方法,它们利用ServletContext对象的log()方法提供日志功能,它们虽然也没有实现任何实质内容,但是它们提供了一个进行日志工作的方便途径。
总而言之,GenericServlet类是一个抽象类,虽然只有一个抽象方法,但是它实现的其他方法都只仅仅提供了最基本的、无实质内容的实现,所以GenericServlet只能作为一种Servlet的父类进行继承,而且在子类中还应该将关心的相关方法进行覆盖,并提供相应实现。
HttpServlet类是GenericServlet类的子类,它比GenericServlet类所涵盖的范围要小得多,它仅表示处理HTTP请求/响应的Servlet。但是同GenericServlet一样,HttpServlet也是一个抽象类,它覆盖了GenericServlet的一些方法,而且对GenericServlet的service()方法提供了实现。HttpServlet的实现如下:
package javax.servlet.http;
import java.io.IOException;
import java.io.Serializable;
import java.lang.reflect.Method;
import java.text.MessageFormat;
import java.util.Enumeration;
import java.util.ResourceBundle;
import javax.servlet.*;
public abstract class HttpServlet extends GenericServlet
implements Serializable
{
public HttpServlet()
{
}
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
String protocol = req.getProtocol();
String msg = lStrings.getString("http.method_get_not_supported");
if(protocol.endsWith("1.1"))
resp.sendError(405, msg);
else
resp.sendError(400, msg);
}
protected long getLastModified(HttpServletRequest req)
{
return -1L;
}
protected void doHead(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
NoBodyResponse response = new NoBodyResponse(resp);
doGet(req, response);
response.setContentLength();
}
protected void doPost(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
String protocol = req.getProtocol();
String msg = lStrings.getString("http.method_post_not_supported");
if(protocol.endsWith("1.1"))
resp.sendError(405, msg);
else
resp.sendError(400, msg);
}
protected void doPut(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
String protocol = req.getProtocol();
String msg = lStrings.getString("http.method_put_not_supported");
if(protocol.endsWith("1.1"))
resp.sendError(405, msg);
else
resp.sendError(400, msg);
}
protected void doDelete(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
String protocol = req.getProtocol();
String msg = lStrings.getString("http.method_delete_not_supported");
if(protocol.endsWith("1.1"))
resp.sendError(405, msg);
else
resp.sendError(400, msg);
}
private static Method[] getAllDeclaredMethods(Class c)
{
if(c.equals(javax/servlet/http/HttpServlet))
return null;
Method parentMethods[] = getAllDeclaredMethods(c.getSuperclass());
Method thisMethods[] = c.getDeclaredMethods();
if(parentMethods != null && parentMethods.length > 0)
{
Method allMethods[] = new Method[parentMethods.length + thisMethods.length];
System.arraycopy(parentMethods, 0, allMethods, 0, parentMethods.length);
System.arraycopy(thisMethods, 0, allMethods, parentMethods.length, thisMethods.length);
thisMethods = allMethods;
}
return thisMethods;
}
protected void doOptions(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
Method methods[] = getAllDeclaredMethods(getClass());
boolean ALLOW_GET = false;
boolean ALLOW_HEAD = false;
boolean ALLOW_POST = false;
boolean ALLOW_PUT = false;
boolean ALLOW_DELETE = false;
boolean ALLOW_TRACE = true;
boolean ALLOW_OPTIONS = true;
for(int i = 0; i < methods.length; i++)
{
Method m = methods[i];
if(m.getName().equals("doGet"))
{
ALLOW_GET = true;
ALLOW_HEAD = true;
}
if(m.getName().equals("doPost"))
ALLOW_POST = true;
if(m.getName().equals("doPut"))
ALLOW_PUT = true;
if(m.getName().equals("doDelete"))
ALLOW_DELETE = true;
}
String allow = null;
if(ALLOW_GET && allow == null)
allow = "GET";
if(ALLOW_HEAD)
if(allow == null)
allow = "HEAD";
else
allow = (new StringBuilder()).append(allow).append(", HEAD").toString();
if(ALLOW_POST)
if(allow == null)
allow = "POST";
else
allow = (new StringBuilder()).append(allow).append(", POST").toString();
if(ALLOW_PUT)
if(allow == null)
allow = "PUT";
else
allow = (new StringBuilder()).append(allow).append(", PUT").toString();
if(ALLOW_DELETE)
if(allow == null)
allow = "DELETE";
else
allow = (new StringBuilder()).append(allow).append(", DELETE").toString();
if(ALLOW_TRACE)
if(allow == null)
allow = "TRACE";
else
allow = (new StringBuilder()).append(allow).append(", TRACE").toString();
if(ALLOW_OPTIONS)
if(allow == null)
allow = "OPTIONS";
else
allow = (new StringBuilder()).append(allow).append(", OPTIONS").toString();
resp.setHeader("Allow", allow);
}
protected void doTrace(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
String CRLF = "\r\n";
String responseString = (new StringBuilder()).append("TRACE ").append(req.getRequestURI()). append(" ").append(req.getProtocol()).toString();
for(Enumeration reqHeaderEnum = req.getHeaderNames(); reqHeaderEnum.hasMoreElements();)
{
String headerName = (String)reqHeaderEnum.nextElement();
responseString = (new StringBuilder()).append(responseString).append(CRLF).append(header Name).append(": ").append(req.getHeader(headerName)).toString();
}
responseString = (new StringBuilder()).append(responseString).append(CRLF).toString();
int responseLength = responseString.length();
resp.setContentType("message/http");
resp.setContentLength(responseLength);
ServletOutputStream out = resp.getOutputStream();
out.print(responseString);
out.close();
}
protected void service(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
String method = req.getMethod();
if(method.equals("GET"))
{
long lastModified = getLastModified(req);
if(lastModified == -1L)
{
doGet(req, resp);
} else
{
long ifModifiedSince = req.getDateHeader("If-Modified-Since");
if(ifModifiedSince < (lastModified / 1000L) * 1000L)
{
maybeSetLastModified(resp, lastModified);
doGet(req, resp);
} else
{
resp.setStatus(304);
}
}
} else if(method.equals("HEAD"))
{
long lastModified = getLastModified(req);
maybeSetLastModified(resp, lastModified);
doHead(req, resp);
} else if(method.equals("POST"))
doPost(req, resp);
else if(method.equals("PUT"))
doPut(req, resp);
else if(method.equals("DELETE"))
doDelete(req, resp);
else if(method.equals("OPTIONS"))
doOptions(req, resp);
else if(method.equals("TRACE"))
{
doTrace(req, resp);
} else
{
String errMsg = lStrings.getString("http.method_not_implemented");
Object errArgs[] = new Object[1];
errArgs[0] = method;
errMsg = MessageFormat.format(errMsg, errArgs);
resp.sendError(501, errMsg);
}
}
private void maybeSetLastModified(HttpServletResponse resp, long lastModified)
{
if(resp.containsHeader("Last-Modified"))
return;
if(lastModified >= 0L)
resp.setDateHeader("Last-Modified", lastModified);
}
public void service(ServletRequest req, ServletResponse res)
throws ServletException, IOException
{
HttpServletRequest request;
HttpServletResponse response;
try
{
request = (HttpServletRequest)req;
response = (HttpServletResponse)res;
}
catch(ClassCastException e)
{
throw new ServletException("non-HTTP request or response");
}
service(request, response);
}
private static final String METHOD_DELETE = "DELETE";
private static final String METHOD_HEAD = "HEAD";
private static final String METHOD_GET = "GET";
private static final String METHOD_OPTIONS = "OPTIONS";
private static final String METHOD_POST = "POST";
private static final String METHOD_PUT = "PUT";
private static final String METHOD_TRACE = "TRACE";
private static final String HEADER_IFMODSINCE = "If-Modified-Since";
private static final String HEADER_LASTMOD = "Last-Modified";
private static final String LSTRING_FILE = "javax.servlet.http.LocalStrings";
private static ResourceBundle lStrings =
ResourceBundle.getBundle("javax.servlet.http.LocalStrings");
}
其中所定义的方法及其含义如下。
public void service(ServletRequest req, ServletResponse res)throws ServletException, IOException:该方法是对GenericServlet的抽象方法service(ServletRequest req, ServletResponse res)的实现。由于所有到达HttpServlet的请求都是HTTP请求,而且对HTTP请求的响应也都是HTTP响应,所以在该方法中分别将参数req和res造型成HttpServletRequest和HttpServletResponse;并且用造型后的参数调用service(HttpServletRequest req, HttpServletResponse res)方法。
protected void service(HttpServletRequest req, HttpServletResponse resp)throws ServletException, IOException:与上一个service()方法不同的是上一个方法只是为了提供对抽象方法的实现,而这个方法实质上是提供对HTTP请求的处理,所有对上一个方法的调用都会被传递到该方法;该方法会对req参数进行分析,根据HTTP请求消息的方法是GET、HEAD、POST、PUT、DELETE、OPTIONS或TRACE分别调用方法doGet()、doHead()、doPost()、doPut()、doDelete()、doOptions()、doTrace()对请求进行处理。
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException:提供对GET方法HTTP请求的处理。
protected void doHead(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException:提供对HEAD方法HTTP请求的处理。
protected void doPost(HttpServletRequest req, HttpServletResponse resp)throws ServletException, IOException:提供对POST方法HTTP请求的处理。
protected void doPut(HttpServletRequest req, HttpServletResponse resp)throws ServletException, IOException:提供对PUT方法HTTP请求的处理。
protected void doDelete(HttpServletRequest req, HttpServletResponse resp)throws ServletException, IOException:提供对DELETE方法HTTP请求的处理。
protected void doOptions(HttpServletRequest req, HttpServletResponse resp)throws ServletException, IOException:提供对OPTIONS方法HTTP请求的处理。
protected void doTrace(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException:提供对TRACE方法HTTP请求的处理。
protected long getLastModified(HttpServletRequest req):返回对HTTP请求的最后修改时间。
虽然该类中没有定义任何抽象方法,但是由于该类也是抽象类,所以也只能被继承,而无法直接实例化。通常在实现HttpServlet的子类时,不需要覆盖HttpServlet对service(ServletRequest req, ServletResponse res)方法、service(HttpServletRequest req, HttpServletResponse res)方法、doOptions()方法和doTrace()方法,因为HttpServlet对这几个方法的实现对几乎所有处理HTTP消息的Servlet都是适用的,除非有些Servlet有特别的要求。而HttpServlet对doGet()方法、doHead()方法、doPost()方法、doPut()方法、doDelete()方法和getLastModified()方法的实现都是默认的最小实现,比如在doGet()、doHead()、doPost()、doPut()和doDelete()方法中只是发送错误信息说明该方法不被支持,而在getLastModified()方法中只是返回一个无效的时间,所以这几个方法都需要HttpServlet的子类来实现,如果实现的Servlet只希望提供给客户端通过GET方法获取资源,那么就只需要覆盖doGet()方法,如果还希望支持通过POST方法提交资源,那么就再覆盖doPost()方法,依此类推。对于没有实现的方法,如果接收到此类消息将返回一个错误消息,提示该方法没有被实现。
在Java Web开发中,绝大多数Servlet都继承自HttpServlet类,子类再根据各自业务需要分别实现do***()方法以覆盖父类的实现。
ServletRequest是Servlet体系中又一个重要的接口,它表示Servlet请求,不仅仅对请求消息作了封装,而且还代表一次请求过程,ServletRequest对象的生命周期就是从Servlet容器接收到请求到请求被处理结束。其定义如下:
package javax.servlet;
import java.io.*;
import java.util.*;
public interface ServletRequest
{
public abstract Object getAttribute(String s);
public abstract Enumeration getAttributeNames();
public abstract String getCharacterEncoding();
public abstract void setCharacterEncoding(String s)
throws UnsupportedEncodingException;
public abstract int getContentLength();
public abstract String getContentType();
public abstract ServletInputStream getInputStream()
throws IOException;
public abstract String getParameter(String s);
public abstract Enumeration getParameterNames();
public abstract String[] getParameterValues(String s);
public abstract Map getParameterMap();
public abstract String getProtocol();
public abstract String getScheme();
public abstract String getServerName();
public abstract int getServerPort();
public abstract BufferedReader getReader()
throws IOException;
public abstract String getRemoteAddr();
public abstract String getRemoteHost();
public abstract void setAttribute(String s, Object obj);
public abstract void removeAttribute(String s);
public abstract Locale getLocale();
public abstract Enumeration getLocales();
public abstract boolean isSecure();
public abstract RequestDispatcher getRequestDispatcher(String s);
public abstract String getRealPath(String s);
public abstract int getRemotePort();
public abstract String getLocalName();
public abstract String getLocalAddr();
public abstract int getLocalPort();
}
其中:
getAttribute(String s):获取具有给定名称属性的值。属性可能通过两种方式进行设置,一种是Servlet容器设置一些属性,使得Servlet容器可以与Servlet进行通信,另一种是在Servlet中自己调用setAttribute()方法设置;
getAttributeNames():返回一个Enumeration对象,包含所有属性的名称;
getCharacterEncoding():返回请求所使用的字符编码;
setCharacterEncoding(String s):设置字符编码,在将字符编码设置后,Servlet通过Reader读取Request的内容时就会以新的字符编码进行读取;
getContentLength():返回请求体的长度,以字节为单位。如果长度未知则返回 –1;
getContentType():返回请求内容的MIME类型;
getInputStream():返回一个ServletInputStream对象,通过该对象可以以二进制的形式读取Request的内容;
getParameter(String s):获取请求携带的参数中名称为s的参数值,如果没有该参数则返回null。在HTTP请求中,请求携带的查询字符串被作为参数,例如http://localhost:8080/query?num= 1&type=apple中的查询字符串有两个参数,参数名为num的值为1,参数名为type的值为apple。还有,从表单中提交的数据也作为参数,参数名为表单元素的名称,参数值为表单元素的值;
getParameterNames():返回一个Enumeration对象,包含所有参数的名称;
getParameterValues(String s):该方法与getParameter(String s)的作用一样,也是用于获取给定参数名的值。因为同一参数名可能具有多个参数值,所以getPatameter(String s)一般用来获得确信只有一个值的参数,getParameterValues(String s)一般用来获得可能有多个值的参数。多个值以字符串数组的形式返回;
getParameterMap():以Map的形式返回请求携带的所有参数的参数名和参数值。Map的键是String类型,表示参数名;Map的值是String数组类型,表示参数值;
getProtocol():返回请求所使用的协议及其版本,格式为:Protocol/MajorVersion.MinorVersion,例如,HTTP消息所使用的协议通常都是HTTP/1.0或HTTP/1.1;
getScheme():不同的模式(HTTP、HTTPS、FTP等)对于请求的格式有不同的形成规则。该方法返回请求所使用的模式名称;
getServerName():返回该请求的目的主机服务器的名称,通常为请求URL中的域名、主机名或IP地址;
getServerPort():返回请求的目的端口,通常在请求URL中域名后,用“:”与域名隔开。默认是80;
getReader():返回一个BufferedReader对象,通过该对象可以以字符形式读取请求的内容,如果在该方法被调用前已经使用setCharacterEncoding(String s)设置了编码,那么就使用设置的编码解析请求中的二进制形式内容,否则使用默认的编码解析;
getRemoteAddr():获得发出该请求的主机的IP地址,可能是客户机也可能是转发的代理服务器;
getRemoteHost():获得发出该请求的主机名称;
setAttribute(String s, Object obj):将名为s值为obj的属性设置到请求中;
removeAttribute(String s):删除请求中名为s的属性;
getLocale():返回客户端期望使用的本地化设置。根据HTTP请求消息头的Accept-Language头域的值进行判断;
getLocales():返回一个Enumeration对象,包含客户端可以接受的所有本地化设置,从期望的本地化设置开始按优先顺序排列;
isSecure():返回该请求是否使用了安全通道进行传输,比如HTTPS;
getRequestDispatcher(String s):s表示一个路径,该方法返回一个到s所指定资源的RequestDispatcher对象。与ServletContext的getRequestDispatcher(String s)不同的是,该方法的路径可以是相对路径;
getRemotePort():获得发出该请求的主机所使用的端口;
getLocalName():获得接收该请求的主机名;
getLocalAddr():获得接收该请求的主机IP地址;
getLocalPort():获得接收该请求的主机使用的端口。
从ServletRequest接口提供的方法可以看出,ServletRequest对象提供了一种对请求的封装,可以通过该接口中的方法获取请求相关的信息,例如请求的参数、发出和接收请求的主机的相关信息等;同时也提供了一些请求相关的操作,例如设置和获取作用域为本请求的属性,获取相对于请求的RequestDispatcher对象等。
虽然从设计上来说Servlet不仅仅局限于处理HTTP消息,但从Servlet诞生到现在不得不承认Servlet主要还是被用于处理HTTP消息。所以学习Servlet重点还是学习HTTP Servlet,同样学习ServletRequest重点还是学习HttpServletRequest。
HttpServletRequest表示HTTP请求,它是ServletRequest的子接口,所以ServletRequest中定义的方法也都是HttpServletRequest的方法。除此之外,HttpServletRequest还定义了一些HTTP请求特有的方法。定义如下:
package javax.servlet.http;
import java.security.Principal;
import java.util.Enumeration;
import javax.servlet.ServletRequest;
public interface HttpServletRequest
extends ServletRequest
{
public static final String BASIC_AUTH = "BASIC";
public static final String FORM_AUTH = "FORM";
public static final String CLIENT_CERT_AUTH = "CLIENT_CERT";
public static final String DIGEST_AUTH = "DIGEST";
public abstract String getAuthType();
public abstract Cookie[] getCookies();
public abstract long getDateHeader(String s);
public abstract String getHeader(String s);
public abstract Enumeration getHeaders(String s);
public abstract Enumeration getHeaderNames();
public abstract int getIntHeader(String s);
public abstract String getMethod();
public abstract String getPathInfo();
public abstract String getPathTranslated();
public abstract String getContextPath();
public abstract String getQueryString();
public abstract String getRemoteUser();
public abstract boolean isUserInRole(String s);
public abstract Principal getUserPrincipal();
public abstract String getRequestedSessionId();
public abstract String getRequestURI();
public abstract StringBuffer getRequestURL();
public abstract String getServletPath();
public abstract HttpSession getSession(boolean flag);
public abstract HttpSession getSession();
public abstract boolean isRequestedSessionIdValid();
public abstract boolean isRequestedSessionIdFromCookie();
public abstract boolean isRequestedSessionIdFromURL();
}
其中:
getAuthType():返回Servlet容器用于保护Servlet所使用的验证模式,返回的字符串可以是常量BASIC_AUTH、FORM_AUTH、CLIENT_CERT_AUTH和DIGEST_AUTH中之一;
getCookies():返回一个Cookie数组,包含请求所携带的所有Cookie对象;
getDateHeader(String s):获得HTTP请求消息头中日期类型的头域的值,参数为头域的名称,返回long表示的日期;
getHeader(String s):获得HTTP请求消息头中名为s的头域的值,返回String类型;
getHeaders(String s):因为在HTTP消息头中,允许多个头域具有相同的名称。该方法返回一个Enumeration对象,包含名为s的所有头域的值;
getHeaderNames():返回一个Enumeration对象,包含所有头域的名称;
getIntHeader(String s):获得Int类型头域的值;
getMethod():获得该HTTP请求所使用的HTTP方法,例如GET、POST等;
getPathInfo():返回URL中Servlet名和查询字符串之间的路径,以“/”开头;
getPathTranslated():获得URL中Servlet名和查询字符串之间的路径并且将其翻译成真实路径返回;
getContextPath():返回该请求URL所指向应用的上下文路径;
getQueryString():返回请求URL中的查询字符串;
getRemoteUser():如果发出该请求的终端用户进行了登录,则返回用户的登录信息,否则返回null;
isUserInRole(String s):如果终端用户进行了登录,则验证用户是否在指定的角色里,如果是则返回true,否则返回false;
getUserPrincipal():返回一个java.security.Principal 对象,该对象包含当前验证用户的名称;如果该用户没有经过验证则返回null;
getRequestedSessionId():返回指定给客户端的Session ID;
getRequestURI():返回请求消息中请求URI,就是在HTTP请求消息头中第一行出现的所请求资源的路径;
getRequestURL():请求的URL,包含协议、域名/IP、端口、服务器上的相对路径,但不包含查询字符串;
getServletPath():返回URL中用于进行Servlet映射的路径;
getSession(boolean flag):返回与当前Request相关联的HttpSession,如果没有与当前Request相关联的HttpSession且flag为true时就新建一个Session;
getSession():相当于getSession(true);
isRequestedSessionIdValid():检查请求的Session ID是否还有效;
isRequestedSessionIdFromCookie():检查请求的Session ID是否来自于Cookie;
isRequestedSessionIdFromURL():检查请求的Session ID是否来自于URL。
实验是学习编程的最好方法,本节将介绍一个实验用来学习ServletRequest和HttpServletRequest。本实验实现一个Servlet,该Servlet用于打印输出HTTP请求所对应的HttpServletRequest对象的相关方法的值。
直接在前面建成的ServletTest工程中进行实验。修改TestServlet,将TestServlet的内容修改如下:
示例8.1 HttpServletRequestPrinter
package cn.csai.web.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Enumeration;
import java.util.Map;
import javax.servlet.ServletException;
import javax.servlet.http.Cookie;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpSession;
/**
* Servlet implementation class for Servlet: TestServlet
*
*/
public class TestServlet extends javax.servlet.http.HttpServlet implements
javax.servlet.Servlet
{
static final long serialVersionUID = 1L;
private PrintWriter pw;
/*
* (non-Java-doc)
*
* @see javax.servlet.http.HttpServlet#HttpServlet()
*/
public TestServlet() {
super();
}
/*
* (non-Java-doc)
*
* @see javax.servlet.http.HttpServlet#doGet(HttpServletRequest request,
* HttpServletResponse response)
*/
protected void doGet(HttpServletRequest request,
HttpServletResponse response) throws ServletException, IOException
{
pw = response.getWriter();
writeln("--- Attributes --------------------");
Enumeration<String> attrNames = request.getAttributeNames();
for (String attr = ""; attrNames.hasMoreElements(); attr = attrNames
.nextElement())
{
writeln(attr + " = " + request.getAttribute(attr));
}
writeln("--- HTTP Message --------------------");
writeln("getScheme(): " + request.getScheme());
writeln("getProtocol(): " + request.getProtocol());
writeln("getMethod(): " + request.getMethod());
writeln("--- URL --------------------");
writeln("getRequestURI(): " + request.getRequestURI());
writeln("getRequestURL(): " + request.getRequestURL());
writeln("getPathInfo(): " + request.getPathInfo());
writeln("getPathTranslated(): " + request.getPathTranslated());
writeln("getQueryString(): " + request.getQueryString());
writeln("--- Parameters --------------------");
Map params = request.getParameterMap();
for(Object key : params.keySet()) {
String[] values = (String[]) params.get(key);
for(String v : values){
writeln(key + " = " + v);
}
}
writeln("--- Headers --------------------");
Enumeration<String> headerNames = request.getHeaderNames();
for (String header = headerNames.nextElement();
null != header && headerNames.hasMoreElements();
header = headerNames.nextElement())
{
writeln(header + " = " + request.getHeader(header));
}
writeln("--- Server Information --------------------");
writeln("getLocale(): " + request.getLocale());
writeln("getLocalAddr(): " + request.getLocalAddr());
writeln("getLocalName(): " + request.getLocalName());
writeln("getLocalPort(): " + request.getLocalPort());
writeln("getServerName(): " + request.getServerName());
writeln("getServerPort(): " + request.getServerPort());
writeln("getContextPath(): " + request.getContextPath());
writeln("getServletPath(): " + request.getServletPath());
writeln("--- Client Information --------------------");
writeln("getRemoteAddr(): " + request.getRemoteAddr());
writeln("getRemoteHost(): " + request.getRemoteHost());
writeln("getRemoteUser(): " + request.getRemoteUser());
writeln("--- Cookies --------------------");
Cookie[] cookies = request.getCookies();
if (null != cookies) {
for (Cookie cookie : cookies) {
writeln(cookie.getName() + "=" + cookie.getValue()+
";expires=" + cookie.getMaxAge() +
";domain="+ cookie.getDomain() +
";path=" + cookie.getPath());
}
}
writeln("--- Request Information --------------------");
writeln("getContentLength(): " + request.getContentLength());
writeln("getContentType(): " + request.getContentType());
writeln("getAuthType(): " + request.getAuthType());
writeln("getCharacterEncoding(): " + request.getCharacterEncoding());
writeln("getRequestedSessionId(): " + request.getRequestedSessionId());
pw.flush();
pw.close();
}
private void writeln(String str) {
pw.write(str + "<br>");
}
}
该Servlet将请求生成的HttpServletRequest对象的各个方法的值输出到客户端浏览器。按照以上内容编辑好TestServlet,并修改ServletTest工程的web.xml文件,将TestServlet的url-mapping修改为“/TestServlet/*”,即让所有相对路径以TestServlet开始的请求都分发到TestServlet。
重新部署Web应用并重新启动Tomcat,在浏览器中输入如下URL:
http://localhost:8080/ServletTest/TestServlet/a?b=1&c=tt
返回的页面内容如下:
--- Attributes --------------------
--- HTTP Message --------------------
getScheme(): http
getProtocol(): HTTP/1.1
getMethod(): GET
--- URL --------------------
getRequestURI(): /ServletTest/TestServlet/a
getRequestURL(): http://localhost:8080/ServletTest/TestServlet/a
getPathInfo(): /a
getPathTranslated(): D:\tomcat\MyWebapps\ServletTest\a
getQueryString(): b=1&c=tt
--- Parameters --------------------
c = tt
b = 1
--- Headers --------------------
accept = */*
accept-language = zh-cn,en-us;q=0.5
accept-encoding = gzip, deflate
user-agent = Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)
host = localhost:8080
--- Server Information --------------------
getLocale(): zh_CN
getLocalAddr(): 127.0.0.1
getLocalName(): localhost
getLocalPort(): 8080
getServerName(): localhost
getServerPort(): 8080
getContextPath(): /ServletTest
getServletPath(): /TestServlet
--- Client Information --------------------
getRemoteAddr(): 127.0.0.1
getRemoteHost(): 127.0.0.1
getRemoteUser(): null
--- Cookies --------------------
--- Request Information --------------------
getContentLength(): -1
getContentType(): null
getAuthType(): null
getCharacterEncoding(): null
getRequestedSessionId(): null
从返回的页面内容中可以发现各个方法所获得的值,对照输入的URL可以很清晰地明确每个方法所获取的内容。其中由于测试环境没有设置任何属性,所以Attributes项没有任何内容;同样原因Cookies项也没有内容。许多输出为null的就表示请求中没有设置该属性。
在学习其他部分内容时,读者也可以采用同样的实验方法,通过构造适当的Servlet内容,将Servlet实际部署到Tomcat中,通过运行Servlet观察输出结果;比较不同Servlet的不同输出结果可以很清楚的了解很多内容。
ServletResponse的定义如下:
package javax.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Locale;
public interface ServletResponse
{
public abstract String getCharacterEncoding();
public abstract String getContentType();
public abstract ServletOutputStream getOutputStream()
throws IOException;
public abstract PrintWriter getWriter()
throws IOException;
public abstract void setCharacterEncoding(String s);
public abstract void setContentLength(int i);
public abstract void setContentType(String s);
public abstract void setBufferSize(int i);
public abstract int getBufferSize();
public abstract void flushBuffer()
throws IOException;
public abstract void resetBuffer();
public abstract boolean isCommitted();
public abstract void reset();
public abstract void setLocale(Locale locale);
public abstract Locale getLocale();
}
其中:
getCharacterEncoding():返回在Response消息中使用的字符编码方式;
getContentType():返回Response消息内容所使用的MIME类型;
getOutputStream():获得ServletOutputStream类型的对象,通过该对象Servlet可以向客户端发送二进制形式的响应数据;
getWriter():获得PrintWriter类型的对象,通过该对象Servlet可以向客户端发送字符形式的响应数据;
setCharacterEncoding(String s):将响应消息所使用的字符编码方式设置为s;
setContentLength(int I):设置响应消息的内容长度,该数据将被设置为HTTP响应消息Content-Length头域的值;
setContentType(String s):设置响应消息内容的MIME类型为s,该设置也将体现到Content-Type头域中;
setBufferSize(int I):用于设置该响应消息所使用的缓冲区大小。在设置了缓冲区大小后,Servlet容器会为响应消息分配不小于所设置大小的缓冲区供响应消息缓冲数据;
getBufferSize():获得Servlet容器实际为响应消息分配的缓冲区大小;
flushBuffer():刷新缓冲区,强制将缓冲区中所有的响应数据发送给客户端;
resetBuffer():在响应消息发送给客户端之前,重置缓冲区,除HTTP响应消息头和响应代码外,清空缓冲区中HTTP响应消息的内容;
isCommitted():返回响应消息是否已经发送到客户端;
reset():清空缓冲区中的所有数据,包括HTTP响应消息头和响应代码;
setLocale(Locale locale):设置响应消息的本地化为locale对象;
getLocale():获得响应消息的本地化对象。
HttpServletResponse的定义如下:
package javax.servlet.http;
import java.io.IOException;
import javax.servlet.ServletResponse;
public interface HttpServletResponse
extends ServletResponse
{
public abstract void addCookie(Cookie cookie);
public abstract boolean containsHeader(String s);
public abstract String encodeURL(String s);
public abstract String encodeRedirectURL(String s);
public abstract void sendError(int i, String s)
throws IOException;
public abstract void sendError(int i)
throws IOException;
public abstract void sendRedirect(String s)
throws IOException;
public abstract void setDateHeader(String s, long l);
public abstract void addDateHeader(String s, long l);
public abstract void setHeader(String s, String s1);
public abstract void addHeader(String s, String s1);
public abstract void setIntHeader(String s, int i);
public abstract void addIntHeader(String s, int i);
public abstract void setStatus(int i);
public static final int SC_CONTINUE = 100;
public static final int SC_SWITCHING_PROTOCOLS = 101;
public static final int SC_OK = 200;
public static final int SC_CREATED = 201;
public static final int SC_ACCEPTED = 202;
public static final int SC_NON_AUTHORITATIVE_INFORMATION = 203;
public static final int SC_NO_CONTENT = 204;
public static final int SC_RESET_CONTENT = 205;
public static final int SC_PARTIAL_CONTENT = 206;
public static final int SC_MULTIPLE_CHOICES = 300;
public static final int SC_MOVED_PERMANENTLY = 301;
public static final int SC_MOVED_TEMPORARILY = 302;
public static final int SC_FOUND = 302;
public static final int SC_SEE_OTHER = 303;
public static final int SC_NOT_MODIFIED = 304;
public static final int SC_USE_PROXY = 305;
public static final int SC_TEMPORARY_REDIRECT = 307;
public static final int SC_BAD_REQUEST = 400;
public static final int SC_UNAUTHORIZED = 401;
public static final int SC_PAYMENT_REQUIRED = 402;
public static final int SC_FORBIDDEN = 403;
public static final int SC_NOT_FOUND = 404;
public static final int SC_METHOD_NOT_ALLOWED = 405;
public static final int SC_NOT_ACCEPTABLE = 406;
public static final int SC_PROXY_AUTHENTICATION_REQUIRED = 407;
public static final int SC_REQUEST_TIMEOUT = 408;
public static final int SC_CONFLICT = 409;
public static final int SC_GONE = 410;
public static final int SC_LENGTH_REQUIRED = 411;
public static final int SC_PRECONDITION_FAILED = 412;
public static final int SC_REQUEST_ENTITY_TOO_LARGE = 413;
public static final int SC_REQUEST_URI_TOO_LONG = 414;
public static final int SC_UNSUPPORTED_MEDIA_TYPE = 415;
public static final int SC_REQUESTED_RANGE_NOT_SATISFIABLE = 416;
public static final int SC_EXPECTATION_FAILED = 417;
public static final int SC_INTERNAL_SERVER_ERROR = 500;
public static final int SC_NOT_IMPLEMENTED = 501;
public static final int SC_BAD_GATEWAY = 502;
public static final int SC_SERVICE_UNAVAILABLE = 503;
public static final int SC_GATEWAY_TIMEOUT = 504;
public static final int SC_HTTP_VERSION_NOT_SUPPORTED = 505;
}
其中:
addCookie(Cookie cookie):将指定的Cookie添加到HTTP响应消息中;
containsHeader(String s):返回在HTTP响应消息中是否已经包含了指定的头域;
encodeURL(String s):参数为一个URL,该方法表示对指定的URL进行编码,将Session ID编码进URL中。如果不需要编码则返回原始URL;
encodeRedirectURL(String s):参数为一个用于重定向的URL,该方法对用于重定向的URL进行编码,将Session ID编码进URL中;
sendError(int i, String s):使用错误代码i和错误消息s向客户端发送错误消息;
sendError(int i):使用错误代码i向客户端发送错误消息;
sendRedirect(String s):该方法返回一个重定向响应到客户端,s是重定向的URL;
setDateHeader(String s, long l):设置HTTP响应消息日期类型的头域,s为头域名称,l为long表示的日期。如果s头域已经存在,则使用l替换原来的值;
addDateHeader(String s, long l):添加一个日期类型的头域到HTTP响应消息中,如果s头域已存在则新添加一个具有名称s的头域;
setHeader(String s, String s1):设置字符类型的头域,s为头域的名称,s1是头域的值。如果s头域已经存在,则使用s1替换原来的值;
addHeader(String s, String s1):添加一个字符类型的头域,s为头域名称,s1为头域的值,如果s头域已存在则新添加一个具有名称s的头域;
setIntHeader(String s, int I):设置int类型的头域;
addIntHeader(String s, int I):添加int类型的头域;
setStatus(int i):设置响应消息的响应码为i。
其中除了这些方法外,还定义了一系列静态常量,这些常量是一些常用的HTTP响应码,常量的名字简单表述了该响应码的含义。
Servlet过滤器,顾名思义是一种搭建在Servlet之上的过滤器,这种过滤器存在于Servlet容器和Servlet之间,对Servlet容器分发给Servlet的请求和Servlet返回给Servlet容器的响应进行过滤。但是这里所说的过滤的含义并不是“让一部分通过而不让另一部分通过”,而是“对经过的所有请求和响应消息进行修改”。Servlet过滤器对请求URL符合某种规则的请求和响应进行过滤,获取这些请求的ServletRequest对象和ServletResponse对象,对其进行修改和操作,以达到影响请求和响应的效果。
Servlet过滤器对所有Servlet是透明的,Servlet并不清楚Servlet过滤器的存在,Servlet还是一如既往地接收请求(已被Servlet过滤器处理过),对请求进行处理,然后将响应返回,返回后的响应还会通过Servlet过滤器,并被过滤器修改(如果需要的话)。
Servlet过滤器可以定义若干个,对于同一个请求可能有多个过滤器对其进行过滤,过滤器遵照一定的顺序排列在Servlet容器与Servlet之间,请求按照从Servlet容器到Servlet的顺序依次被过滤器修改,响应则按照反方向依次被过滤器修改。过滤器之间也同样不清楚对方的存在,它们也是对传递到的请求和响应进行处理,无论该请求来自于Servlet容器还是来自于其他过滤器。
Servlet过滤器工作如图8.5所示。
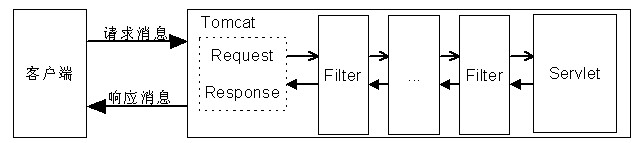
图8.5 Servlet过滤器工作示意图
如图8.5所示,处理流程如下:
(1)Tomcat接收到来自客户端的请求,将请求构造成为一个ServletRequest对象,同时构造一个空的ServletResponse对象;
(2)Tomcat将两个对象同时传递给第一个过滤器,第一个过滤器对ServletRequest对象和ServletResponse对象进行修改或者使用一个新的对象将其包装,然后将修改或包装好的ServletRequest对象和ServletResponse对象传递给第二个Filter,第二个做类似的处理,再传递给下一个,依次往后直到最终到达Servlet;
(3)Servlet调用传递进来的ServletRequest对象的相关方法对其进行解析,然后再调用传递进来的ServletResponse对象的相关方法向客户端发送响应消息;
由于每个Filter都可以对ServletRequest对象和ServletResponse对象进行修改或封装,所以Servlet调用的ServletResponse对象的方法实质上调用的是封装后的方法,或者调用ServletRequest对象的方法获得的信息实质上是修改后的信息。
【注意】
理论上并不是只有请求Servlet的请求和响应才会被过滤。所有请求URL符合过滤器匹配模式的请求和响应都会被过滤,即使请求所指向的是一个静态资源。但在Tomcat中,所有的请求最终都是由Servlet处理的(没有分发到用户Servlet的请求都会由default Servlet或jsp Servlet处理),所以过滤器过滤的请求最终都会达到某个Servlet。
Servlet中有三个与Servlet过滤器相关的接口:Filter、FilterChain和FilterConfig。
1.Filter接口
Filter接口表示一个Servlet过滤器。其定义如下:
package javax.servlet;
import java.io.IOException;
public interface Filter
{
public abstract void init(FilterConfig filterconfig) throws ServletException;
public abstract void doFilter(ServletRequest servletrequest, ServletResponse servletresponse, FilterChain filterchain) throws IOException, ServletException;
public abstract void destroy();
}
其中:
init(FilterConfig filterconfig):表示Filter初始化时执行的内容,在Tomcat初始化Filter时会调用Filter的方法;
doFilter(ServletRequest servletrequest, ServletResponse servletresponse, FilterChain filterchain):表示对请求和响应进行过滤的代码,在有请求通过该Filter时会执行该方法。其中servletrequest表示请求对象,servletresponse表示响应对象,filterchain表示过滤器链。该方法是一个Servlet过滤器的核心处理代码,Tomcat将构造的Request对象和Response对象传递给过滤器的该方法,过滤器可以对Request对象和Response对象做任何修改,然后将修改后的Request对象和Response对象通过filterchain对象传递给Filter链中的下一个过滤器;
destroy():表示Filter在销毁时执行的内容,在Tomcat销毁Filter时会调用Filter的该方法。
2.FilterChain接口
FilterChain接口表示一个过滤器链,它相当于一个链表,所有的过滤器按照顺序依次链接。链表的最后一个节点是目的Servlet。该接口只定义了一个方法,被过滤器用来将Request对象和Response对象向下传递,其定义如下:
package javax.servlet;
import java.io.IOException;
public interface FilterChain
{
public abstract void doFilter(ServletRequest servletrequest, ServletResponse servletresponse) throws IOException, ServletException;
}
其中:
doFilter(ServletRequest servletrequest, ServletResponse servletresponse):该方法用来将servletrequest对象和servletresponse对象传递给过滤器链中的下一个过滤器。
3.FilterConfig接口
FilterConfig接口表示对过滤器的配置,从中可以获取过滤器的相关配置信息。定义如下:
package javax.servlet;
import java.util.Enumeration;
public interface FilterConfig
{
public abstract String getFilterName();
public abstract ServletContext getServletContext();
public abstract String getInitParameter(String s);
public abstract Enumeration getInitParameterNames();
}
其中:
getFilterName():获得该过滤器的名称,对应于配置该过滤器时设置的filter-name属性;
getServletContext():获得调用该过滤器的应用的ServletContext对象;
getInitParameter(String s):获得名为s的初始化参数,这里的初始化参数是指在配置该过滤器时设置的初始化参数,是过滤器独有的,与Servlet定义的初始化参数无关;
getInitParameterNames():获得所有初始化参数的名称。
在前面介绍Filter的工作过程中提到,Filter影响Servlet对客户端的请求/响应有两种方式:一是通过修改传递进来的Request对象和Response对象;二是通过对Request和Response对象进行包装。对一种对象进行包装使得调用者在不做任何修改的情况下改变程序的行为,这种方式在设计模式中称为包装(Wrapper)模式。
ServletRequestWrapper和ServletResponseWrapper分别是ServletRequest和ServletResponse的包装器,HttpServletRequestWrapper和HttpServletResponseWrapper分别是HttpServletRequest和HttpServletResponse的包装器。它们的定义如下:
package javax.servlet;
import java.io.*;
import java.util.*;
public class ServletRequestWrapper
implements ServletRequest
{
public ServletRequestWrapper(ServletRequest request)
{
if(request == null)
{
throw new IllegalArgumentException("Request cannot be null");
} else
{
this.request = request;
return;
}
}
public ServletRequest getRequest()
{
return request;
}
public void setRequest(ServletRequest request)
{
if(request == null)
{
throw new IllegalArgumentException("Request cannot be null");
} else
{
this.request = request;
return;
}
}
public Object getAttribute(String name)
{
return request.getAttribute(name);
}
public Enumeration getAttributeNames()
{
return request.getAttributeNames();
}
public String getCharacterEncoding()
{
return request.getCharacterEncoding();
}
public void setCharacterEncoding(String enc)
throws UnsupportedEncodingException
{
request.setCharacterEncoding(enc);
}
public int getContentLength()
{
return request.getContentLength();
}
public String getContentType()
{
return request.getContentType();
}
public ServletInputStream getInputStream()
throws IOException
{
return request.getInputStream();
}
public String getParameter(String name)
{
return request.getParameter(name);
}
public Map getParameterMap()
{
return request.getParameterMap();
}
public Enumeration getParameterNames()
{
return request.getParameterNames();
}
public String[] getParameterValues(String name)
{
return request.getParameterValues(name);
}
public String getProtocol()
{
return request.getProtocol();
}
public String getScheme()
{
return request.getScheme();
}
public String getServerName()
{
return request.getServerName();
}
public int getServerPort()
{
return request.getServerPort();
}
public BufferedReader getReader()
throws IOException
{
return request.getReader();
}
public String getRemoteAddr()
{
return request.getRemoteAddr();
}
public String getRemoteHost()
{
return request.getRemoteHost();
}
public void setAttribute(String name, Object o)
{
request.setAttribute(name, o);
}
public void removeAttribute(String name)
{
request.removeAttribute(name);
}
public Locale getLocale()
{
return request.getLocale();
}
public Enumeration getLocales()
{
return request.getLocales();
}
public boolean isSecure()
{
return request.isSecure();
}
public RequestDispatcher getRequestDispatcher(String path)
{
return request.getRequestDispatcher(path);
}
public String getRealPath(String path)
{
return request.getRealPath(path);
}
public int getRemotePort()
{
return request.getRemotePort();
}
public String getLocalName()
{
return request.getLocalName();
}
public String getLocalAddr()
{
return request.getLocalAddr();
}
public int getLocalPort()
{
return request.getLocalPort();
}
private ServletRequest request;
}
package javax.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Locale;
public class ServletResponseWrapper
implements ServletResponse
{
private ServletResponse response;
public ServletResponseWrapper(ServletResponse response)
{
if(response == null)
{
throw new IllegalArgumentException("Response cannot be null");
} else
{
this.response = response;
return;
}
}
public ServletResponse getResponse()
{
return response;
}
public void setResponse(ServletResponse response)
{
if(response == null)
{
throw new IllegalArgumentException("Response cannot be null");
} else
{
this.response = response;
return;
}
}
public void setCharacterEncoding(String charset)
{
response.setCharacterEncoding(charset);
}
public String getCharacterEncoding()
{
return response.getCharacterEncoding();
}
public ServletOutputStream getOutputStream()
throws IOException
{
return response.getOutputStream();
}
public PrintWriter getWriter()
throws IOException
{
return response.getWriter();
}
public void setContentLength(int len)
{
response.setContentLength(len);
}
public void setContentType(String type)
{
response.setContentType(type);
}
public String getContentType()
{
return response.getContentType();
}
public void setBufferSize(int size)
{
response.setBufferSize(size);
}
public int getBufferSize()
{
return response.getBufferSize();
}
public void flushBuffer()
throws IOException
{
response.flushBuffer();
}
public boolean isCommitted()
{
return response.isCommitted();
}
public void reset()
{
response.reset();
}
public void resetBuffer()
{
response.resetBuffer();
}
public void setLocale(Locale loc)
{
response.setLocale(loc);
}
public Locale getLocale()
{
return response.getLocale();
}
}
package javax.servlet.http;
import java.security.Principal;
import java.util.Enumeration;
import javax.servlet.ServletRequestWrapper;
public class HttpServletRequestWrapper extends ServletRequestWrapper
implements HttpServletRequest
{
public HttpServletRequestWrapper(HttpServletRequest request)
{
super(request);
}
private HttpServletRequest _getHttpServletRequest()
{
return (HttpServletRequest)super.getRequest();
}
public String getAuthType()
{
return _getHttpServletRequest().getAuthType();
}
public Cookie[] getCookies()
{
return _getHttpServletRequest().getCookies();
}
public long getDateHeader(String name)
{
return _getHttpServletRequest().getDateHeader(name);
}
public String getHeader(String name)
{
return _getHttpServletRequest().getHeader(name);
}
public Enumeration getHeaders(String name)
{
return _getHttpServletRequest().getHeaders(name);
}
public Enumeration getHeaderNames()
{
return _getHttpServletRequest().getHeaderNames();
}
public int getIntHeader(String name)
{
return _getHttpServletRequest().getIntHeader(name);
}
public String getMethod()
{
return _getHttpServletRequest().getMethod();
}
public String getPathInfo()
{
return _getHttpServletRequest().getPathInfo();
}
public String getPathTranslated()
{
return _getHttpServletRequest().getPathTranslated();
}
public String getContextPath()
{
return _getHttpServletRequest().getContextPath();
}
public String getQueryString()
{
return _getHttpServletRequest().getQueryString();
}
public String getRemoteUser()
{
return _getHttpServletRequest().getRemoteUser();
}
public boolean isUserInRole(String role)
{
return _getHttpServletRequest().isUserInRole(role);
}
public Principal getUserPrincipal()
{
return _getHttpServletRequest().getUserPrincipal();
}
public String getRequestedSessionId()
{
return _getHttpServletRequest().getRequestedSessionId();
}
public String getRequestURI()
{
return _getHttpServletRequest().getRequestURI();
}
public StringBuffer getRequestURL()
{
return _getHttpServletRequest().getRequestURL();
}
public String getServletPath()
{
return _getHttpServletRequest().getServletPath();
}
public HttpSession getSession(boolean create)
{
return _getHttpServletRequest().getSession(create);
}
public HttpSession getSession()
{
return _getHttpServletRequest().getSession();
}
public boolean isRequestedSessionIdValid()
{
return _getHttpServletRequest().isRequestedSessionIdValid();
}
public boolean isRequestedSessionIdFromCookie()
{
return _getHttpServletRequest().isRequestedSessionIdFromCookie();
}
public boolean isRequestedSessionIdFromURL()
{
return _getHttpServletRequest().isRequestedSessionIdFromURL();
}
public boolean isRequestedSessionIdFromUrl()
{
return _getHttpServletRequest().isRequestedSessionIdFromUrl();
}
}
package javax.servlet.http;
import java.io.IOException;
import javax.servlet.ServletResponseWrapper;
public class HttpServletResponseWrapper extends ServletResponseWrapper
implements HttpServletResponse
{
public HttpServletResponseWrapper(HttpServletResponse response)
{
super(response);
}
private HttpServletResponse _getHttpServletResponse()
{
return (HttpServletResponse)super.getResponse();
}
public void addCookie(Cookie cookie)
{
_getHttpServletResponse().addCookie(cookie);
}
public boolean containsHeader(String name)
{
return _getHttpServletResponse().containsHeader(name);
}
public String encodeURL(String url)
{
return _getHttpServletResponse().encodeURL(url);
}
public String encodeRedirectURL(String url)
{
return _getHttpServletResponse().encodeRedirectURL(url);
}
public String encodeUrl(String url)
{
return _getHttpServletResponse().encodeUrl(url);
}
public String encodeRedirectUrl(String url)
{
return _getHttpServletResponse().encodeRedirectUrl(url);
}
public void sendError(int sc, String msg)
throws IOException
{
_getHttpServletResponse().sendError(sc, msg);
}
public void sendError(int sc)
throws IOException
{
_getHttpServletResponse().sendError(sc);
}
public void sendRedirect(String location)
throws IOException
{
_getHttpServletResponse().sendRedirect(location);
}
public void setDateHeader(String name, long date)
{
_getHttpServletResponse().setDateHeader(name, date);
}
public void addDateHeader(String name, long date)
{
_getHttpServletResponse().addDateHeader(name, date);
}
public void setHeader(String name, String value)
{
_getHttpServletResponse().setHeader(name, value);
}
public void addHeader(String name, String value)
{
_getHttpServletResponse().addHeader(name, value);
}
public void setIntHeader(String name, int value)
{
_getHttpServletResponse().setIntHeader(name, value);
}
public void addIntHeader(String name, int value)
{
_getHttpServletResponse().addIntHeader(name, value);
}
public void setStatus(int sc)
{
_getHttpServletResponse().setStatus(sc);
}
public void setStatus(int sc, String sm)
{
_getHttpServletResponse().setStatus(sc, sm);
}
}
从这几个包装器的定义中可以发现:
(1)包装器分别实现被包装接口:ServletRequestWrapper实现了ServletRequest接口、ServletResponse Wrapper实现了ServletResponse接口、HttpServletRequestWrapper实现了HttpServletRequest接口、HttpServletResponseWrapper实现了HttpServletResponse接口;
(2)包装器的继承关系与被包装者的继承关系一致:由于HttpServletRequest和HttpServletResponse分别继承了ServletRequest和ServletResponse,所以HttpServletRequestWrapper和HttpServletResponse Wrapper也分别继承了ServletRequestWrapper和ServletResponseWrapper;
(3)在包装器中都定义了一个被包装者的对象,并且都通过包装器的构造函数传递初始值。HttpServletRequestWrapper和HttpServletResponseWrapper没有定义被包装者的对象,这是因为它们使用了其父类中的对象。
(4)包装器可以通过调用被包装对象的方法来实现其所声明的方法,也可以自行添加任何代码以覆盖其所包装对象的该方法,从而体现与被包装对象不同的行为。
将包装器用到过滤器中,其工作原理是:过滤器接收传递进来的ServletRequest对象和ServletResponse对象,分别实现两个包装器将ServletRequest对象和ServletResponse对象包装起来,并且在包装器的相关方法中添加自己想要的行为,然后将包装器对象传递给Servlet,由于包装器对象都继承自被包装者,故Servlet还是把包装器对象当成原始的对象进行调用,但实质上调用的是包装器的对应方法,从而过滤器达到了干涉Servlet处理请求/响应的目的。
仔细研究以上列出的四个包装器的方法会发现,这些方法并没有添加任何自己的实现,而是单纯地调用被包装者的对应方法。这是因为Servlet提供这几个包装器只是一个包装器的默认实现,开发人员要开发自己的包装器的话,只需要继承对应的包装器并且覆盖自己感兴趣的方法即可,而不用自己去实现一个完整的包装器。
一个简单的例子就是利用过滤器添加日志功能。假设开发者希望在Servlet发生重定向时记录日志,那就需要实现一个HttpServletResponseWrapper对原始的HttpServletResponse进行包装,实现如下:
示例8.2
public class LogHttpResponseWrapper extends HttpServletResponseWrapper {
public LogHttpResponseWrapper(HttpServletResponse response) {
super(response);
}
@Override
public void sendRedirect(String location) throws IOException {
Log("Redirect to: " + location);
super.sendRedirect(location);
}
}
这个包装器很简单,只需要继承HttpServletResponseWrapper对象,并且覆盖其sendRedirect(String location)方法即可,在方法中先记录日志,然后调用父类的sendRedirect(String location)方法。当该包装器对象被传递到Servlet时,Servlet如果调用sendRedirect(String location)方法对响应进行重定向,那么该包装器对象的该方法就会被调用。调用结果就是首先记录日志,然后调用原始被包装者的该方法,所以这个记录日志的过程对Servlet是完全透明的。
Servlet过滤器必须符合Filter接口,所有实现了Filter接口的Java类都可以作为Servlet过滤器。以上面提到的记录日志的过滤器为例,其实现如下:
示例8.3
public class LogFilter implements Filter {
public void init(FilterConfig arg0) throws ServletException {
}
public void doFilter(ServletRequest arg0, ServletResponse arg1,
FilterChain arg2) throws IOException, ServletException
{
HttpServletResponse res = (HttpServletResponse) arg1;
LogHttpResponseWrapper wrapper = new LogHttpResponseWrapper(res);
arg2.doFilter(arg0, wrapper);
}
public void destroy() {
}
}
Filter接口定义了三个方法,在实现类中分别实现这三个方法。
在init()中实现初始化操作,如果没有初始化操作则方法体为空。
在doFilter()方法中实现过滤方法体,更改请求/响应对象或构造包装器对象;在处理结束后一定要调用FilterChain.doFilter()操作,这表示将参数中给定的请求和响应对象传递到过滤器链的下一个过滤器/Servlet中;所以,如果在过滤方法中对请求/响应对象做了包装,此处就应该使用包装对象向下传递;
在destroy()方法实现一些清理操作,如果没有清理操作则方法体为空。
同Servlet一样,过滤器编辑好后,如果没有部署到Tomcat中,Tomcat是不会知道过滤器存在的,过滤器也不会起到任何作用。将过滤器部署到Tomcat中的方法与Servlet一样:将其配置到web.xml文件中。
在web.xml文件中,web-app根元素的第一层子元素中可以定义filter元素,配置代码段如下例所示:
<filter>
<filter-name>logFilter</filter-name>
<filter-class>
cn.csai.web.servlet. LogFilter
</filter-class>
<init-param>
<param-name>logPrefix</param-name>
<param-value>csai-log:</param-value>
</init-param>
<init-param>
<param-name>max-line</param-name>
<param-value>256</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>logFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
filter元素定义Filter,filter-mapping定义需要过滤的请求的URL模式。其中,filter-name是该过滤器的名称,用于匹配filter元素和filter-mapping元素,同时用于当FilterConfig的getFilterName()方法被调用时返回该名称;filter-class表示该过滤器的实现类,该类必须实现了Filter接口;init-param定义了一系列初始化参数,可以通过FilterConfig的getInitParameter(String)方法和getInitParameterNames()方法获得;url-pattern定义了一个URL模式,只有与该URL模式匹配成功的请求才会经过该过滤器,这个url-pattern的格式和意义与Servlet配置中url-pattern的格式和意义相同。
将Filter部署到Tomcat中后,Filter就已经开始起作用了。当Tomcat处在运行状态时,向Tomcat提交符合Filter URL模式的请求就会激活Filter的doFilter()方法。
可能在其他很多介绍Servlet的材料中告诉读者,开发Servlet的大致步骤如下:
新建一个Java类,继承HttpServlet类;
根据需要实现父类中的doGet()或者doPost()方法。
这样,在读者心目中可能会形成一个定势,就是所有的Servlet都必须继承HttpServlet类。实质上,这个认识是不正确的。
正如本章前面所介绍的,一个Java类是Servlet的充分必要条件就是该类或者其父类实现了Servlet接口。了解了这一点,读者就可以有充分的灵活性随心所欲地开发Servlet了。
前面在介绍Hello World Servlet时,实现了一个TestServlet,与其他大多数Servlet一样,它继承自HttpServlet。那么,现在我们将要实现的HelloWorldPrinterServlet是一个不继承HttpServlet的Servlet,它的功能是无论接收到任何请求,都向客户端打印“Hello World”。这将是一个最基本最简单的Servlet。
首先,在ServletTest工程中新建一个Java类HelloWorldPrinterServlet,并且让这个类实现Servlet接口。实现Servlet接口的方法(但是所有方法体不包含任何实质内容)如下:
package cn.csai.web.servlet;
import java.io.IOException;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class HelloWorldPrinterServlet implements Servlet {
public void destroy() {
}
public ServletConfig getServletConfig() {
return null;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
}
}
理论上说,这就已经实现了一个完整的Servlet,如果将该Servlet部署到Web应用中,该Servlet就可以正常工作了,只是该Servlet不提供任何有意义的功能。参照TestServlet的部署,将HelloWorldPrinterServlet部署到应用的web.xml文件中:
<?xml version="1.0" encoding="UTF-8"?>
<web-app id="WebApp_ID" version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www. w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com /xml/ns/j2ee/web-app_2_4.xsd">
<display-name>ServletTest</display-name>
<servlet>
<description></description>
<display-name>HelloWorldPrinterServlet</display-name>
<servlet-name>HelloWorldPrinterServlet</servlet-name>
<servlet-class>cn.csai.web.servlet.HelloWorldPrinterServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>HelloWorldPrinterServlet</servlet-name>
<url-pattern>/HelloWorldPrinterServlet/*</url-pattern>
</servlet-mapping>
<welcome-file-list>
<welcome-file>index.html</welcome-file>
<welcome-file>index.htm</welcome-file>
<welcome-file>index.jsp</welcome-file>
<welcome-file>default.html</welcome-file>
<welcome-file>default.htm</welcome-file>
<welcome-file>default.jsp</welcome-file>
</welcome-file-list>
</web-app>
重新部署Web应用,然后访问URL:
http://localhost:8080/ServletTest/HelloWorldPrinterServlet
将获得一个空白页面,如图8.6所示。
由于当请求到达Servlet时,Servlet的service()方法会被调用,所以如果想要从Servlet获得响应,只要在service()方法体中添加适当的内容。例如,实现简单的利用HttpServletResponse参数向客户端打印一个HelloWorld字符串的过程如下:
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
HttpServletResponse resp = (HttpServletResponse) arg1;
PrintWriter writer = resp.getWriter();
writer.println("Hello World");
writer.flush();
writer.close();
}
图8.6 访问HttpWorldPrinterServlet获得的页面
service()方法的参数是一个ServletRequest对象和一个ServletResponse对象,这两个参数类型是由Servlet接口定义的,在这里由于我们要开发的Servlet是用于处理Http请求和响应的,所以这里的ServletRequest对象和ServletResponse对象肯定分别是HttpServletRequest对象和HttpServletResponse对象,所以在使用这两个参数时可以直接对其进行造型;获得了resp对象后,取出其中的PrintWriter对象,该对象用于向客户端打印字符串输出;然后通过writer对象的println()方法输出字符串;最后刷新和关闭输出对象。
不用改变前面对web.xml的配置,直接重新部署Web应用,使用上面的URL访问HelloWorldPrinterServlet,获得的页面如图8.7所示:
图8.7 访问修改后的HttpWorldPrinterServlet获得的页面
假如使用继承自HttpServlet的方法来实现具有相同功能的Servlet,其实现代码大致如下:
package cn.csai.web.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class HelloWorldPrinterServlet extends HttpServlet {
@Override
protected void doDelete(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
printHelloWorld(resp);
}
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
printHelloWorld(resp);
}
@Override
protected void doHead(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
printHelloWorld(resp);
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
printHelloWorld(resp);
}
@Override
protected void doPut(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
printHelloWorld(resp);
}
private void printHelloWorld(HttpServletResponse resp) throws IOException {
PrintWriter writer = resp.getWriter();
writer.println("Hello World");
writer.flush();
writer.close();
}
也就是说,无论HTTP请求是Delete、Get、Head、Post或Put,该Servlet的处理都是调用printHelloWord()通过响应向客户端输出“Hello World”。比较这个实现和前面实现,前面的实现还显得稍微简单,所以并不是实现所有Servlet时都要通过继承HttpServlet来实现的,有时候直接实现Servlet接口还会更简单而且更直接。
ServletConfig表示一个Servlet的配置信息,从ServletConfig中可以获得当前Servlet在web.xml中的一些配置信息。一个Servlet的ServletConfig信息会在Servlet被创建时由Servlet容器进行创建和初始化,通过Servlet的init(ServletConfig)方法传递给Servlet。
1.在Servlet中引入ServletConfig
如果通过实现Servlet接口来开发Servlet,那么程序员就需要在Servlet中管理ServletConfig对象。自己在代码中管理ServletConfig非常简单,模仿GenericServlet类的方法,在Servlet中定义一个ServletConfig对象,然后在init(ServletConfig)方法中将传入的ServletConfig赋给定义的对象,并且在getServletConfig()方法中返回定义的对象。代码如下:
package cn.csai.web.servlet;
import java.io.IOException;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class HelloWorldPrinterServlet1 implements Servlet {
private ServletConfig config;
public void destroy() {
}
public ServletConfig getServletConfig() {
return config;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
this.config = arg0;
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
}
}
这样,在service()方法中就可以直接通过config对象获得Servlet的配置信息。
如果使用继承HttpServlet的方法开发Servlet,那么在Servlet中引入ServletConfig就更简单了,因为HttpServlet的父类GenericServlet已经替我们完成了管理ServletConfig的工作,开发人员只需要在待开发的Servlet中直接使用getServletConfig()或super.getServletConfig()获得ServletConfig对象即可。
2.使用ServletConfig
在Servlet中引入ServletConfig的主要目的是通过ServletConfig对象获得Servlet的配置信息,然后根据配置信息决定Servlet的行为。开发人员可以编写相对通用的Servlet,让Servlet的行为可根据配置信息不同而不同,当使用Servlet时可根据具体的需求添加不同的配置信息。
例如,在HelloWorldPrinterServlet的基础上提高一点系统的需求:当有请求到达时,向客户端输出一个消息,该消息可通过应用的web.xml进行配置。
根据这个需求,可以考虑Servlet提供的一种初始化参数机制。Servlet在配置时,允许向Servlet中配置初始化参数,这些参数由参数名和参数值组成,这些参数可以在Servlet运行期间被Servlet获得。所以,可以在Servlet的初始化参数中定义待输出的消息内容,然后在Servlet运行期间通过ServletConfig对象读取该消息内容,然后输出到客户端。
将该Servlet命名为MessagePrinterServlet;为该Servlet定义一个名为message的初始化参数用于定义待输出的消息。那么,在web.xml中添加如下一段配置信息:
<servlet>
<description></description>
<display-name>MessagePrinterServlet</display-name>
<servlet-name>MessagePrinterServlet</servlet-name>
<servlet-class>cn.csai.web.servlet.MessagePrinterServlet</servlet-class>
<init-param>
<param-name>message</param-name>
<param-value>Hello China</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>MessagePrinterServlet</servlet-name>
<url-pattern>/MessagePrinterServlet/*</url-pattern>
</servlet-mapping>
在包cn.csai.web.servlet中新建一个MessagePrinterServlet,实现内容如下:
package cn.csai.web.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class MessagePrinterServlet implements Servlet {
private ServletConfig config;
public void destroy() {
}
public ServletConfig getServletConfig() {
return config;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
this.config = arg0;
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
PrintWriter writer = arg1.getWriter();
writer.println(config.getInitParameter("message"));
writer.flush();
writer.close();
}
}
该类自行管理了ServletConfig对象,并且在service方法中通过config读取参数名为message的初始化参数,并且将该参数值输出到客户端,根据上面的配置,将“Hello China”输出到客户端,如图8.8所示。
图8.8 通过MessagePrinterServlet输出Hello China
假如修改该Servlet的配置信息,则将message参数的值改为Hello America,如下所示:
<servlet>
<description></description>
<display-name>MessagePrinterServlet</display-name>
<servlet-name>MessagePrinterServlet</servlet-name>
<servlet-class>cn.csai.web.servlet.MessagePrinterServlet</servlet-class>
<init-param>
<param-name>message</param-name>
<param-value>Hello America</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>MessagePrinterServlet</servlet-name>
<url-pattern>/MessagePrinterServlet/*</url-pattern>
</servlet-mapping>
而不改变MessagePrinterServlet的实现。重新部署Web应用的配置,并且重启Tomcat后,再次访问该Servlet获得页面如图8.9所示:
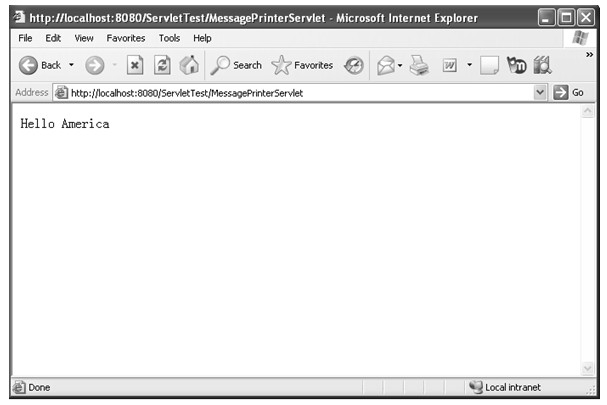
图8.9 通过MessagePrinterServlet输出Hello America
ServletConfig的主要功能是提供给Servlet用来获取Servlet在web.xml中配置的初始化参数信息。前面展示了如何通过参数名获取参数值,此外,ServletConfig还可以获取所有初始化参数的参数名和参数值。当程序员想获取所有的初始化参数或者在不知道特定参数的参数名时想通过遍历所有初始化参数的参数名获取参数参数值时,都可以通过ServletConfig的getInitParameterNames()方法获得所有初始化参数的一个Enumeration对象。
下面将展示一个InitParamPrinterServlet,该Servlet将打印所有初始化参数的参数值和参数名:
package cn.csai.web.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Enumeration;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class InitParamPrinterServlet implements Servlet {
private ServletConfig config;
public void destroy() {
}
public ServletConfig getServletConfig() {
return config;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
this.config = arg0;
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
PrintWriter writer = arg1.getWriter();
Enumeration<String> initParams = config.getInitParameterNames();
while(initParams.hasMoreElements()) {
String param = initParams.nextElement();
writer.println(param + " = " + config.getInitParameter(param));
writer.println("<br>");
}
writer.flush();
writer.close();
}
}
该Servlet的service()方法通过config的getInitParameterNames()方法获得一个Enumeration对象,该对象的每一个成员是一个初始化参数的参数名,然后根据参数名再获得参数值,并将参数名和参数值以“参数名 = 参数值”的格式输出到客户端页面上。
将该Servlet配置到web.xml中,并且添加一些初始化参数,如下所示:
<servlet>
<description>
</description><display-name>InitParamPrinterServlet</display-name>
<servlet-name>InitParamPrinterServlet</servlet-name>
<servlet-class>cn.csai.web.servlet.InitParamPrinterServlet</servlet-class>
<init-param>
<param-name>param1</param-name>
<param-value>value1</param-value>
</init-param>
<init-param>
<param-name>param2</param-name>
<param-value>5</param-value>
</init-param>
<init-param>
<param-name>param3</param-name>
<param-value>1/2</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>InitParamPrinterServlet</servlet-name>
<url-pattern>/InitParamPrinterServlet/*</url-pattern>
</servlet-mapping>
这里配置了三个初始化参数,读者也可以定义自己想定义的任何参数。重新部署Web应用并重启Tomcat后,获得的页面如图8.10所示:
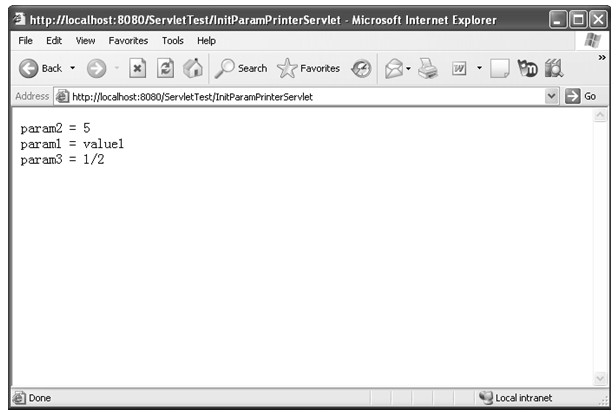
图8.10 InitParamPrinterServlet响应页面
另外,程序员还可以在Servlet的配置中为Servlet添加一个名字,然后通过ServletConfig的getServletName()方法获得,如下NamePrinterServlet将Servlet的名字作为页面标题输出到客户端。
package cn.csai.web.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class NamePrinterServlet implements Servlet {
private ServletConfig config;
public void destroy() {
}
public ServletConfig getServletConfig() {
return config;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
this.config = arg0;
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
PrintWriter writer = arg1.getWriter();
writer.println("<h1>" + config.getServletName() + "</h1>");
writer.flush();
writer.close();
}
}
配置片段如下:
<servlet>
<description></description>
<display-name>NamePrinterServlet</display-name>
<servlet-name>NamePrinterServlet</servlet-name>
<servlet-class>cn.csai.web.servlet.NamePrinterServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>NamePrinterServlet</servlet-name>
<url-pattern>/NamePrinterServlet/*</url-pattern>
</servlet-mapping>
重新部署Web应用,重启Tomcat,访问该Servlet获得的页面如图8.11所示:
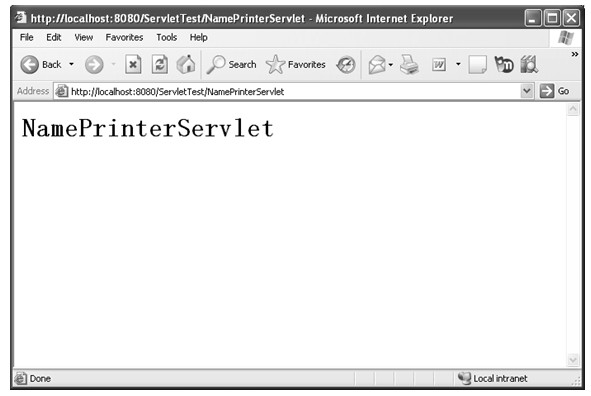
图8.11 NamePrinterServlet响应页面
顾名思义,ServletContext表示了一个Servlet运行的上下文环境,通过该对象可以获得Servlet乃至整个Tomcat所运行的大环境的信息。ServletContext接口的定义已在前面进行了介绍,下面我们分别用几个示例展示如何在Servlet中使用ServletContext。
1.使用ServletContext获得服务器的信息
ServletContext第一个功能就是可以通过它获取服务器的信息,这也是在Servlet中唯一一个可以获取服务器信息的途径。ServletContext的getServerInfo()方法通过一个字符串返回当前所运行的Web服务器的信息;getMajorVersion()和getMinorVersion()分别获取当前的Servlet容器所支持的Servlet的主版本号和次版本号。下面的GetServerInfoServlet展示了这几个方法的用法以及返回的值:
package cn.csai.web.servlet.context;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletContext;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class GetServerInfoServlet implements Servlet {
private ServletConfig config;
public void destroy() {
}
public ServletConfig getServletConfig() {
return config;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
config = arg0;
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
ServletContext context = getServletConfig().getServletContext();
PrintWriter writer = arg1.getWriter();
writer.print("Server Info: " + context.getServerInfo());
writer.print("<br>");
writer.print("Version: "
+ context.getMajorVersion() + "." + context.getMinorVersion());
writer.flush();
writer.close();
}
}
显示页面如图8.12所示:
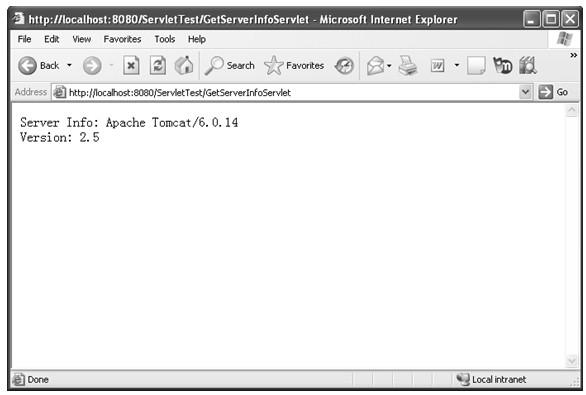
图8.12 GetServerInfoServlet页面效果
2.使用ServletContext获得Web应用的信息
这里所说的Web应用就是指Servlet所在的Web应用。在Servlet中,通过ServletContext对象可以获得当前Web应用的一些信息。通过ServletContext的getServletContextName()方法可以获得当前ServletContext的上下文路径名;通过ServletContext的getMimeType(file)可以获得指定文件名的文件所属的MIME类型。下面的GetApplicationInfoServlet展示了这些方法的用法:
package cn.csai.web.servlet.context;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletContext;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class GetApplicationInfoServlet implements Servlet {
private ServletConfig config;
public void destroy() {
}
public ServletConfig getServletConfig() {
return config;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
config = arg0;
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
ServletContext context = getServletConfig().getServletContext();
PrintWriter writer = arg1.getWriter();
writer.print("Servlet Context Name: " + context.getServletContextName());
writer.print("<br>");
writer.print("doc MIME: " + context.getMimeType("file.doc"));
writer.flush();
writer.close();
}
}
显示的页面如图8.13所示:
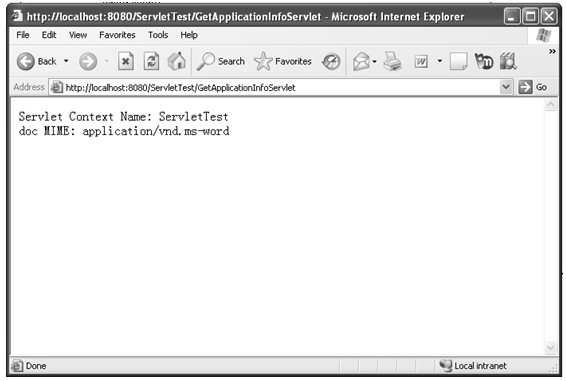
图8.13 GetApplicationInfoServlet页面效果
第一行显示的是当前的Web应用的上下文路径,即ServletTest;第二行显示的是doc文件的MIME类型。
3.使用ServletContext获得资源的信息
ServletContext还有一个很重要的功能就是获取Web应用中所有资源的信息。通过ServletContext对象提供的方法,Servlet可以获得当前Web应用中各个资源的包含关系、每个资源的本地地址和URL,以及获得每个资源的输入流对象等。
ServletContext的 getResourcePaths(path)可以获得指定URI下所有资源的URI;getRealPath(uri)可以获得指定URI所代表的资源在本地文件系统中的路径; getResource(uri)可以获得指定URI所代表的资源的全局URL;getResourceAsStream(uri)可以获得指定URI所代表资源的输入流,如果资源是一个目录则输入流为空。
下面的GetResourceInfoServlet获得当前Web应用根目录下所有一级资源的资源名、本地路径、URL和读取资源的InputStream对象:
package cn.csai.web.servlet.context;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Set;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletContext;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class GetResourceInfoServlet implements Servlet {
private ServletConfig config;
public void destroy() {
}
public ServletConfig getServletConfig() {
return config;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
config = arg0;
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
ServletContext context = getServletConfig().getServletContext();
PrintWriter writer = arg1.getWriter();
Set<String> resources = context.getResourcePaths("/");
writer.print("All resources in root directory:");
writer.print("<br>");
for (String res : resources) {
writer.print("<br>");
writer.print(res);
writer.print("<br>");
writer.print("------------");
writer.print("<br>");
writer.print("Path on local machine: " + context.getRealPath(res));
writer.print("<br>");
writer.print("URL: " + context.getResource(res));
writer.print("<br>");
writer.print("Input stream object: " + context.getResourceAsStream(res));
writer.print("<br>");
}
writer.flush();
writer.close();
}
}
显示的页面如图8.14所示。
从图8.14中的运行结果可以发现,在ServletTest应用中,根目录下只有三个一级资源:WEB_INF目录、build.xml文件和index.html文件。WEB_INF所对应的本地路径为:D:\tomcat\webapps\Servlet Test\WEB-INF;访问该目录的URL是:jndi:/localhost/ServletTest/WEB-INF/;由于该资源是一个目录,无法读取,所以读取该资源的InputStream对象是空。其他两个资源类似。
4.使用ServletContext进行请求前转
利用ServletContext除了可以获得资源的信息外,还可以将请求直接前转到指定的资源文件或者Servlet。ServletContext的getRequestDispatcher(uri)返回一个到指定URI所指向资源的RequestDispatcher对象,getNamedDispatcher(servlet)返回一个到指定Servlet的RequestDispatcher对象。通过返回的RequestDispatcher对象,Servlet可以将请求前转到指定的资源或者将资源的响应嵌入到当前响应中。
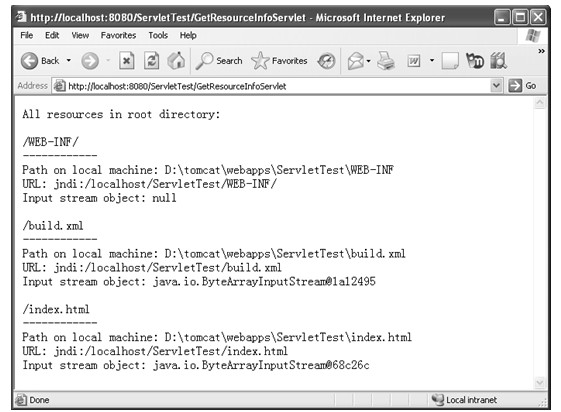
图8.14 GetResourceInfoServlet页面效果
使用RequestDispatcher对象进行前转和通过ServletResponse的sendRedirect()方法进行重定向,这两个操作是不一样的。重定向是针对当前的请求向客户端返回一个响应,响应消息中告诉客户端需要重新请求另外一个URL,然后客户端再向指定的URL重新发出请求从而获得响应;而前转是Servlet/JSP在获得请求后直接在Web服务器内部向另外一个资源发出请求并且将请求结果返回给客户端。虽然前转和重定向都是将另外一个资源的响应返回给客户端,但是前转操作只有一次请求/响应过程而重定向会有两次请求/响应过程。
下面的FileDispatcherServlet将客户端请求前转到应用中的一个文件:
package cn.csai.web.servlet.context;
import java.io.IOException;
import javax.servlet.RequestDispatcher;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletContext;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class FileDispatcherServlet implements Servlet {
private ServletConfig config;
public void destroy() {
}
public ServletConfig getServletConfig() {
return config;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
config = arg0;
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
ServletContext context = getServletConfig().getServletContext();
RequestDispatcher disp = context.getRequestDispatcher("/Blue hills.jpg");
disp.forward(arg0, arg1);
}
}
将Windows图片收藏夹中自带的Blue hills.jpg复制到ServletTest工程的WebContent中,然后重新发布Web应用到Tomcat中。发布完后,图片就会在ServletTest应用的根目录中。打开Tomcat,访问FileDispatcherServlet,会得到如图8.15所示的页面。
图8.15 FileDispatcherServlet页面效果
可以发现获得的响应页面中包含一个图片,这个图片就是Blue hill.jpg。
下面的ServletDispatcherServlet将客户端请求前转到另一个Servlet:
package cn.csai.web.servlet.context;
import java.io.IOException;
import javax.servlet.RequestDispatcher;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletContext;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class ServletDispatcherServlet implements Servlet {
private ServletConfig config;
public void destroy() {
}
public ServletConfig getServletConfig() {
return config;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
config = arg0;
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
ServletContext context = getServletConfig().getServletContext();
RequestDispatcher disp =
context.getNamedDispatcher("GetResourceInfoServlet");
disp.forward(arg0, arg1);
}
}
从代码中可以发现,该Servlet将请求前转到前面开发的GetResourceInfoServlet。访问该Servlet获得的页面如图8.16所示。
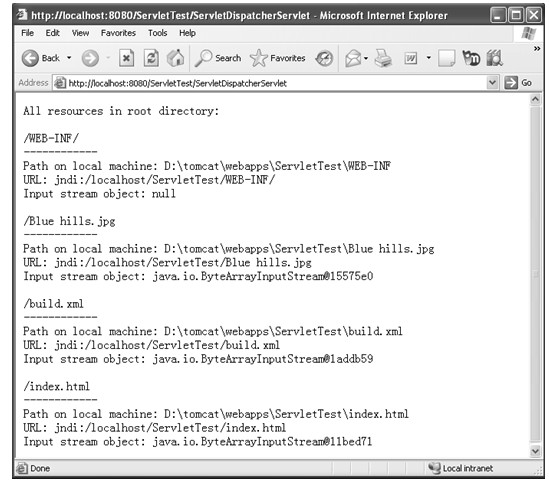
图8.16 ServletDispatcherServlet页面效果
可以发现,获得页面同访问GetResourceInfoServlet获得的页面效果一模一样。
5.使用ServletContext记录日志
Tomcat自带有日志功能,在Tomcat的logs目录中保存了Tomcat的所有日志文件。默认的日志文件分为5类,分别以如下名字开头:admin、catalina、host-manager、localhost和manager,后面是当天的日期。这些日志会记录Tomcat服务器的启动、停止、出现的错误信息、打印的提示信息,等等。
通过ServletContext对象,开发人员就同样可以利用Tomcat的这个日志功能为自己开发的代码记录日志。ServletContext的几个log()通过不同的参数向localhost类日志中写入日志信息。
下面的LogServlet展示了如何使用ServletContext对象进行日志记录:
package cn.csai.web.servlet.context;
import java.io.IOException;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletContext;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class LogServlet implements Servlet {
private ServletConfig config;
public void destroy() {
}
public ServletConfig getServletConfig() {
return config;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
config = arg0;
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
ServletContext context = getServletConfig().getServletContext();
context.log("cn.csai.web.servlet.context.LogServlet is running!");
try {
String s = null;
s.length();
} catch(NullPointerException e) {
context.log(e, "s is null");
}
}
}
在该Servlet中,首先通过调用log(String)方法记录了一条运行信息,然后在捕捉到Exception时通过log(Exception, String)方法记录了一条异常信息。为了查看该Servlet记录日志的效果,可以在准备访问Servlet之前,先将Tomcat原有的日志文件全部删除。然后启动Tomcat再访问该Servlet,访问完后查看logs目录中会有几个日志文件,其中有一个文件名是localhost+日期,打开该文件,内容如下:
Jun 23, 2008 3:25:13 PM org.apache.catalina.core.ApplicationContext log
INFO: cn.csai.web.servlet.context.LogServlet is running!
Jun 23, 2008 3:25:13 PM org.apache.catalina.core.ApplicationContext log
SEVERE: s is null
java.lang.NullPointerException
at cn.csai.web.servlet.context.LogServlet.service(LogServlet.java:39)
at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:290)
at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:206)
at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:233)
at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:175)
at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:128)
at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:102)
at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:109)
at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:263)
at org.apache.coyote.http11.Http11Processor.process(Http11Processor.java:844)
at org.apache.coyote.http11.Http11Protocol$Http11ConnectionHandler.process(Http11Protocol.java:584)
at org.apache.tomcat.util.net.JIoEndpoint$Worker.run(JIoEndpoint.java:447)
at java.lang.Thread.run(Thread.java:595)
这就是记录LogServlet调用log()方法记录的日志内容。其中前两行是第一次调用生成的日志,第一行是日期,第二行是日志级别(INFO)和日志消息内容;后面的是第二次调用生成的日志,同样是以一行日期开始,后面有日志级别(SEVERE)、日志消息内容以及所报的异常的栈信息。这两个日志的级别是不一样的,调用log(String)记录的日志是INFO级别的,调用log(Exception, String)记录的日志是SEVERE级别的。
在HTTP Servlet体系中,HttpServletResponse代表一个向客户端发出的响应,它与HTTP响应消息不能完全等同,但是由于HTTP协议的特点,对HttpServletResponse对象的相关操作基本上可以与修改HTTP响应消息的相关内容对应起来。所以,在编写Servlet时,对响应所做的任何操作基本上都应该从HttpServletResponse对象着手,该对象对HTTP响应消息的内容和行为提供了非常好的封装。
响应的主要目的就是向客户端返回响应消息,最常见的响应消息就是文本消息(HTML页面内容),还有可能是二进制形式内容、错误信息或者重定向操作等。
1.返回文本消息
使用文本消息响应客户端是最常用的一种响应方式,前面的几个Servlet也都是使用这种方式。
通过HttpServletResponse的getWriter()方法可以获得一个向客户端输出字符信息的输出流,它是一个PrintWriter对象。通过这个对象,Servlet可以向客户端输出文本响应消息,响应消息的文本内容通常都是按HTML结构进行组织的。如下例的HtmlResponseServlet向客户端返回一个HTML页面的响应消息。
package cn.csai.web.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class HtmlResponseServlet implements Servlet {
public void destroy() {
}
public ServletConfig getServletConfig() {
return null;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
PrintWriter writer = arg1.getWriter();
writer.write(getHtml());
writer.flush();
writer.close();
}
private String getHtml() {
StringBuilder html = new StringBuilder();
html.append("<html>");
html.append("<head><title>HtmlResponseServlet</title></head>");
html.append("<body>");
html.append("<h1 align=\"center\">HtmlResponseServlet</h1>");
html.append("<hr size=\"3\"/>");
html.append("<div align=\"center\">Content</div>");
html.append("</body>");
html.append("</html>");
return html.toString();
}
}
该Servlet的getHtml()是一个字符串,字符串的内容是一个HTML文档,service()方法通过PrintWriter将字符串输出到客户端。显示的页面如图8.17所示:
图8.17 HtmlResponseServlet响应页面
查看该页面的源文件,如下所示:
<html>
<head><title>HtmlResponseServlet</title></head>
<body>
<h1 align="center">HtmlResponseServlet</h1>
<hr size="3"/>
<div align="center">Content</div>
</body>
</html>
可以发现,该源文件的内容就是getHtml()方法返回的字符串的内容。
2.返回二进制数内容
Servlet不仅可以向客户端返回HTML格式的文本消息,还可以返回二进制数的内容,例如图片、Word文档等。
在Java中,字符输出流是用Writer,而字节输出流就是OutputStream。针对二进制数的字节内容,HttpServletResponse也提供了一个getOutputStream()方法,该方法返回一个ServletOutputStream对象,通过这个对象Servlet可以向客户端返回一个二进制数的响应消息。
为了演示这个功能,首先在工程中新建一个包cn.csai.web.servlet.resource,挑选一个图片放在该包中,假设图片名取为test.jpg。然后编写一个名为PictureResponseServlet,如下所示:
package cn.csai.web.servlet;
import java.io.IOException;
import java.io.InputStream;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class PictureResponseServlet implements Servlet {
private static final String picPath = "/cn/csai/web/servlet/resource/test.jpg";
public void destroy() {
}
public ServletConfig getServletConfig() {
return null;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
InputStream is = this.getClass().getResourceAsStream(picPath);
ServletOutputStream os = arg1.getOutputStream();
int avail = 0;
while((avail=is.available()) > 0) {
byte[] buff = new byte[avail];
is.read(buff);
os.write(buff);
}
os.flush();
is.close();
os.close();
}
}
访问该Servlet返回的页面如图8.18所示:
图8.18 PictureResponseServlet响应页面
3.返回错误信息
当Servlet在处理用户请求时,可能会遇到一些问题导致请求无法被正常处理,这些问题可能是用户请求的格式不正确,也可能是服务器端发生了一些异常。这种情况下,Servlet需要向客户端返回错误报告响应消息,这种错误报告响应消息具有不同于正常响应的响应码(不同类别响应码的含义在1.3.2节中已做介绍)。
HttpServletResponse提供了sendError()方法向客户端返回错误报告响应消息,该方法允许Servlet指定错误消息的错误码以及一个可选的错误文本信息。如下的SendErrorResponseServlet向客户端返回一个错误报告响应消息,错误码表示用户的请求消息不正确,并且反馈一个错误信息文本。
package cn.csai.web.servlet;
import java.io.IOException;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.HttpServletResponse;
public class SendErrorResponseServlet implements Servlet {
public void destroy() {
}
public ServletConfig getServletConfig() {
return null;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
HttpServletResponse resp = (HttpServletResponse) arg1;
resp.sendError(HttpServletResponse.SC_BAD_REQUEST, "Bad Request!");
}
}
响应页面如图8.19所示,sendError()方法中提供的提示信息“Bad Request!”会显示在错误提示页面中:
4.返回重定向操作
重定向操作就是向客户端返回一个响应,响应要求客户端浏览器的访问请求重新指向另一个URL。例如,将请求一个Servlet的请求重新定向到另一个Servlet或另一个图片,甚至是另一个网站的某个页面。
图8.19 SendErrorResponseServlet响应页面
HttpServletResponse提供了sendRedirect()方法,该方法接受一个字符串参数,该参数表示要重定向的URL。下面的SendRedirectResponseServlet将用户请求重定向到csai网的主页:
package cn.csai.web.servlet;
import java.io.IOException;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.HttpServletResponse;
public class SendRedirectResponseServlet implements Servlet {
private static final String redirectURL = "http://www.csai.cn";
public void destroy() {
}
public ServletConfig getServletConfig() {
return null;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
HttpServletResponse resp = (HttpServletResponse) arg1;
resp.sendRedirect(redirectURL);
}
}
访问该Servlet后,请求会被重定向到“http://www.csai.cn”,如果客户端可以打开csai的主页,那么响应的页面将会是csai的主页,地址栏也会显示csai主页的地址,如图8.20所示:
图8.20 SendRedirectResponseServlet响应页面
5.设置响应消息的内容类型
在介绍HTTP消息的头域时,提到过一个Content-Type头域,该头域说明了消息内容的MIME类型,这是HTTP消息的发送方告知HTTP消息接收方有关消息体格式的唯一方法;HTTP消息接收方会根据Content-Type中携带的MIME类型决定在接收到消息体后对接收到的内容所采取的处理方式,可以是在浏览器中打开、调用某个本地应用程序打开、直接保存为本地文件,等等。
Servlet可以显式地为响应消息设置一种MIME类型,如果Servlet没有显式地设置,那么客户端就无法获知消息体的MIME类型,这种情况下大部分浏览器会根据获得的消息体的实际内容判断消息体的MIME类型,并且使用合适的方式对消息体进行处理。
前面在介绍Tomcat的web.xml文件配置时,发现在${TOMCAT_HOME}\conf目录下的web.xml文件中列出了许多有关文件后缀与MIME类型的映射关系(mime-mapping元素,见7.3.2节),这些映射关系是用于配置DefaultServlet行为的,当程序员自己开发的Servlet向客户端返回文件时这些设置并不会起作用。当客户端请求的是某个文件(而不是Servlet)时,DefaultServlet会根据所请求文件的后缀获得所对应的MIME类型,并将这个类型设置到响应中。假如请求访问的是程序员自己开发的Servlet时,这些映射并不会起作用。例如PictureResponseServlet最终向客户端返回了一个图片,但是Tomcat并不会自动向响应消息设置image/jpeg的MIME类型,因为读取二进制数内容以及返回二进制数内容的工作都是由程序员的Servlet负责的,Tomcat并不知道二进制数消息体的具体类型,而且也没有机会设置MIME类型。图片返回给客户端后,之所以IE能够将图片正确显示,那是因为IE通过分析返回的二进制数内容判断出来了文件的类型(大部分类型文件的前几个字节都具有一定的特征)。而且在有些浏览器中(例如IE),自己判断获得的MIME类型有可能还会覆盖掉Servlet显式设置的类型,这取决于浏览器的实现。
例如,下面的XMLDisplayServlet向客户端输出一段文本:
package cn.csai.web.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class XMLDisplayServlet implements Servlet {
public void destroy() {
}
public ServletConfig getServletConfig() {
return null;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
PrintWriter writer = arg1.getWriter();
writer.write(getContent());
writer.flush();
writer.close();
}
private String getContent() {
StringBuilder html = new StringBuilder();
html.append("<persons>");
html.append("<person id=\"1\">");
html.append("<name>kevin</name>");
html.append("<age>26</age>");
html.append("</person>");
html.append("<person id=\"2\">");
html.append("<name>tom</name>");
html.append("<age>22</age>");
html.append("</person>");
html.append("</persons>");
return html.toString();
}
}
文本内容是:
<persons>
<person id="1">
<name>kevin</name>
<age>26</age>
</person>
<person id="2">
<name>tom</name>
<age>22</age>
</person>
</persons>
如果不设置响应的MIME类型,显示的页面如图8.21所示:
由于IE将返回响应的内容自动识别为“text/html”MIME类型,也就是说,IE将返回的内容按HTML进行显示,所以所有的标签以及回车都被忽略了。
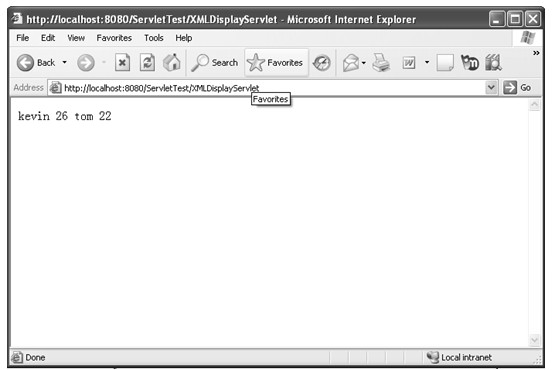
图8.21 XMLDisplayServlet响应页面
但是假如在service()中将响应的MIME类型显式地设置为“application/xml”,那么IE就会按XML显示。所以将XMLDisplayServlet修改为如下的XMLDisplayServlet2:
package cn.csai.web.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class XMLDisplayServlet2 implements Servlet {
public void destroy() {
}
public ServletConfig getServletConfig() {
return null;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
PrintWriter writer = arg1.getWriter();
arg1.setContentType("application/xml");
writer.write(getContent());
writer.flush();
writer.close();
}
private String getContent() {
StringBuilder html = new StringBuilder();
html.append("<persons>");
html.append("<person id=\"1\">");
html.append("<name>kevin</name>");
html.append("<age>26</age>");
html.append("</person>");
html.append("<person id=\"2\">");
html.append("<name>tom</name>");
html.append("<age>22</age>");
html.append("</person>");
html.append("</persons>");
return html.toString();
}
}
其响应页面如图8.22所示:
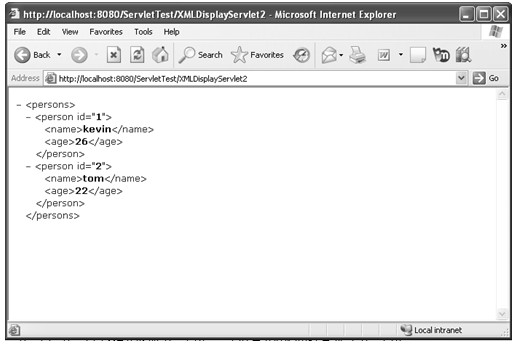
图8.22 XMLDisplayServlet2响应页面
由于在XMLDisplayServlet2中设置了MIME类型为XML,所以IE就会以XML的格式正确显式内容。
6.设置响应消息的字符编码
如果返回的响应消息是文本类型,那么浏览器就会涉及使用哪一种字符编码对消息中的文本进行解析的问题,这种情形一般会有三种解决方式:
浏览器使用本地操作系统默认的编码方式:这种方式最简单而且对响应提供者也没有限制,但在互联网上可能会出现使用任意一种编码的响应文本,所以这种方式就限制了浏览器显式其他编码的能力。
浏览器根据内容猜测编码方式:虽然在很多浏览器中已经提供了这种功能,但是并不能依赖于这种功能,因为毕竟是由浏览器猜测的,可能会出现猜测不准确的情况。
响应提供者在响应消息中指定编码方式:这是一种最直接也是使用最普遍的方式,这种方式可以根据相应提供者的意图对响应文本进行解析,但是就对响应提供者提出了要求。
实际上,在现实的使用中,是将这三种方式共同使用的:如果响应中指定了编码方式,就按指定的编码方式解析响应,否则浏览器会猜测一种编码方式,如果提供的信息不足以猜测出编码方式,那么浏览器就会使用系统默认的编码方式解析。
可见,如果开发人员在编写Web系统时如果直接指定了编码方式,将大大简化了浏览器的工作量,而且也能保证需要显示的内容能够被正确解析。
前面提到了HTTP响应消息用Content-Type头域指定响应内容的MIME类型,但同时Content-Type头域还会指定一个charset,例如:
Content-Type: text/html; charset=iso-8859-1
这个HTTP消息头域指定了消息内容的MIME格式是text/html,内容编码为ISO—8859—1。
ServletResponse的setCharacterEncoding(String encoding)方法是用来设置响应的字符编码的,在Servlet中直接调用ServletResponse的改方法设置所使用的编码方式,如下面的SetEncodingServlet所示:
package cn.csai.web.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
public class SetEncodingServlet implements Servlet {
public void destroy() {
}
public ServletConfig getServletConfig() {
return null;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
PrintWriter writer = arg1.getWriter();
arg1.setCharacterEncoding("UTF-8");
writer.write(getMessage());
writer.flush();
writer.close();
}
private String getMessage() {
StringBuffer sb = new StringBuffer();
sb.append("<html><head>");
sb.append("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=UTF-8\"/>" );
sb.append("</head><body><h1>中文</h1></body></html>");
return sb.toString();
}
}
其响应页面如图8.23所示:
7.向响应消息中添加头域
HTTP的响应消息由响应头和响应消息体组成,响应头通过头域来设定响应消息的一系列属性。前面讲到的设置响应消息的内容类型就是通过在响应消息的头域中添加Content-Type头域实现的,以及返回重定向消息时重定向的URL也是通过设置Location头域实现的。
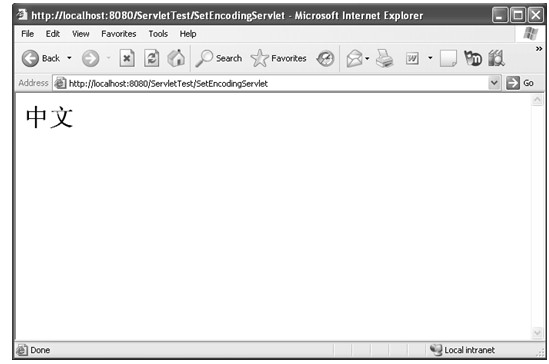
图8.23 SetEncodingServlet响应页面
对于一些特殊的并且常用的头域HttpServletResponse提供了专门的方法用于设置,同时HttpServletResponse还提供了通用的方法用于设置任意的头域,这些方法包括:

通过这些方法,开发人员可以向响应消息中添加任何头域,可以是HTTP协议中预定义的头域,也可以是产品自定义或者用户自己定义的头域。例如下面的SetHeaderServlet向响应消息中添加Last-Modified头域,以指定返回内容的最后修改时间:
package cn.csai.web.servlet;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Date;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.HttpServletResponse;
public class SetHeaderServlet implements Servlet {
private Date now;
public void destroy() {
}
public ServletConfig getServletConfig() {
return null;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
HttpServletResponse resp = (HttpServletResponse) arg1;
now = new Date();
resp.setDateHeader("Last-Modified", now.getTime());
PrintWriter writer = resp.getWriter();
writer.write(getContent());
writer.flush();
writer.close();
}
private String getContent() {
StringBuilder html = new StringBuilder();
html.append("Last-Modified:" + now.toString());
return html.toString();
}
}
Session在HTTP协议中是一个非常重要的概念,本书已经在1.5.2节中介绍了Session的概念。在Servlet中,用HttpSession接口及其实现类用于表示Web开发中Session的概念,并且使用该接口提供的方法可以实现对会话的管理,以及存取会话级的属性。HttpSession接口的定义如下:
package javax.servlet.http;
import java.util.Enumeration;
import javax.servlet.ServletContext;
public interface HttpSession
{
public abstract long getCreationTime();
public abstract String getId();
public abstract long getLastAccessedTime();
public abstract ServletContext getServletContext();
public abstract void setMaxInactiveInterval(int i);
public abstract int getMaxInactiveInterval();
public abstract Object getAttribute(String s);
public abstract Enumeration getAttributeNames();
public abstract void setAttribute(String s, Object obj);
public abstract void removeAttribute(String s);
public abstract void invalidate();
public abstract boolean isNew();
}
其中:
getCreationTime():返回该session对象创建的时间。
getId():返回该session对象对应的Session ID。
getLastAccessedTime():返回该session对应的客户端最后一次访问服务器的时间。
getServletContext():返回该session对象对应应用的ServletContext对象。
setMaxInactiveInterval(int i):设置最大的不活动时间(session对象失效的最大间隔),以秒为单位。假如某个客户端持续不访问服务器的时间超过了设置的时间间隔,那么服务器就会让该客户端对应的session失效。
getMaxInactiveInterval():获得当前设置的最大不活动时间。
getAttribute(String s):获得该session中具有指定属性名的属性。
getAttributeNames():返回Enumeration对象,包含该session中所有属性的名称。
setAttribute(String s, Object obj):将属性名为s,属性值为obj的属性设置到session对象中。
removeAttribute(String s):删除具有属性名s的属性。
invalidate():将该session失效,并将任何绑定到该session的对象与之解除绑定。
isNew():判断该session是否是新创建的。如果某session已经被创建但并未与任何客户端关联,则认为该session为新创建的。
在进行Web开发时,HttpSession最常被使用在保存会话级信息,即向Session中设置和获取属性对象,Session比Servlet更高一个级别,可以协调各个Servlet之间的行为。例如,可以在一个Servlet里面设置属性而在另外一个Servlet里面获取属性。
下面的SetSessionServlet和GetSessionServlet分别向Session中设置一个属性和取出该属性,属性名为Date:
SetSessionServlet
package cn.csai.web.servlet.session;
import java.io.IOException;
import java.util.Date;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
public class SetSessionServlet implements Servlet {
public void destroy() {
}
public ServletConfig getServletConfig() {
return null;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
HttpServletRequest req = (HttpServletRequest) arg0;
HttpSession session = req.getSession();
session.setAttribute("Date", new Date());
}
}
GetSessionServlet
package cn.csai.web.servlet.session;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.Date;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
public class GetSessionServlet implements Servlet {
public void destroy() {
}
public ServletConfig getServletConfig() {
return null;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
HttpServletRequest req = (HttpServletRequest) arg0;
HttpSession session = req.getSession();
Date date = (Date) session.getAttribute("Date");
PrintWriter writer = arg1.getWriter();
if(null == date) writer.print("null");
else writer.print(date.toString());
writer.flush();
writer.close();
}
}
将两个Servlet部署到Tomcat中然后对实现进行验证。
首先,打开一个浏览器窗口并且访问GetSessionServlet,获得的响应页面如图8.24所示:
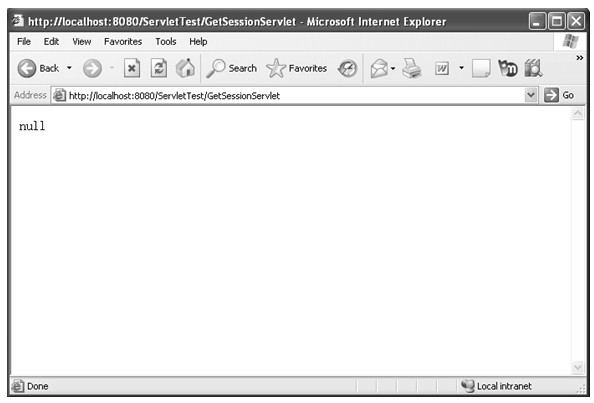
图8.24 GetSessionServlet响应页面
由于,并没有向Session中设置Date属性,所以直接访问GetSessionServlet时Date属性为空。
然后,重新启动一个窗口,首先访问SetSessionServlet,该Servlet只在Session中设置一个Date属性,并不返回任何响应内容,所以访问该Servlet获得的页面是一个空白页面,如图8.25所示:
图8.25 SetSessionServlet响应页面
最后,直接在打开SetSessionServlet的窗口中访问GetSessionServlet。由于在当前会话中已经通过SetSessionServlet设置了Date属性,所以此时GetSessionServlet将显示以设置的属性的值。如图8.26所示:
图8.26 GetSessionServlet响应页面
此时,重新打开一个窗口,然后再访问GetSessionServlet时,获得页面与图8.19相同。这是因为,虽然已经通过SetSessionServlet设置了Date属性,但是那是在上一个Session中设置的,新打开一个浏览器窗口后,已经不是同一个Session了,在新的Session中由于并没有通过访问SetSessionServlet设置Date属性,所以访问GetSessionServlet时获得的Date属性是一个空值。
这个例子比较简单,但是也在一定程度上反映了Session的概念以及Session在Servlet中的使用方式。
Cookie是服务器端要求浏览器在本地存储的一段简短的文本,并且浏览器会在适当的时候在再次访问服务器时携带这段文本。这种机制使服务器得以在客户机本地保存客户机的状态信息。
在Servlet中,Java提供了Cookie类用于实现这个概念,与HttpSession一样,Cookie位于javax.servlet.http包中。Cookie类的结构如下:
package javax.servlet.http;
import java.text.MessageFormat;
import java.util.ResourceBundle;
public class Cookie implements Cloneable {
public Cookie(String name, String value);
public void setComment(String purpose);
public String getComment();
public void setDomain(String pattern);
public String getDomain();
public void setMaxAge(int expiry);
public int getMaxAge();
public void setPath(String uri);
public String getPath();
public void setSecure(boolean flag);
public boolean getSecure();
public String getName();
public void setValue(String newValue);
public String getValue();
public int getVersion();
public void setVersion(int v);
public Object clone();
}
其中:
Cookie(String name, String value):构造函数,参数是该Cookie的名和值;
SetCommen(String purpose):一段注释用于说明该Cookie的目的;
getComment():返回该Cookie的注释;
setDomain(String pattern):设置该Cookie的域,参数是一个模式;
getDomain():返回该Cookie的域;
setMaxAge(int expiry):设置该Cookie最大的有效时长,单位是秒;
getMaxAge():获得该Cookie的最大有效时长;
setPath(String uri):设置该Cookie路径的URL;
getPath():获得该Cookie的路径;
setSecure(boolean flag):设置该Cookie的安全性,为浏览器提供指示,是否该Cookie只能在安全协议下使用;
getSecure():获得该Cookie的安全性设置;
getName():获得该Cookie的名称;
setValue(String newValue):为该Cookie设置新值;
getValue():获得该Cookie的值;
getVersion():获得该Cookie所使用的版本;
setVersion(int v):设置该Cookie所使用的版本;
clone():克隆一个Cookie对象。
在第1章介绍Cookie基本知识时已经提到,一个Cookie的基本内容包括:名称、值、域、过期时间和路径。从Cookie类的结构也可以发现,Java的Cookie类也基本上是对这些属性的设置和获取。
下面的SetCookieServlet演示了如何通过响应向客户端设置Cookie:
package cn.csai.web.servlet.cookie;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.Cookie;
import javax.servlet.http.HttpServletResponse;
public class SetCookieServlet implements Servlet {
public void destroy() {
}
public ServletConfig getServletConfig() {
return null;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
HttpServletResponse resp = (HttpServletResponse) arg1;
String cookieName = "TestCookieName";
String cookieValue = "TestCookieValue";
String cookieDomain = "csai.cn";
String path = "/";
int maxAge = 60 * 60;
Cookie c = new Cookie(cookieName, cookieValue);
c.setDomain(cookieDomain);
c.setPath(path);
c.setMaxAge(maxAge);
resp.addCookie(c);
PrintWriter writer = resp.getWriter();
writer.write("Set " + cookieName + "=" + cookieValue);
writer.flush();
writer.close();
}
}
该Servlet向响应中设置了一个Cookie,该Cookie设置TestCookieName=TestCookieValue,域为“csai.cn”,path为“/”,过期时间为1个小时。该Cookie设置相当于在HTTP响应消息头中添加:
Set-Cookie: TestCookieName=TestCookieValue; Domain=csai.cn; Expires=Tue, 17-Jun-2008 09:37:43 GMT; Path=/
其中Expires的值是根据响应发生的时间和设置的1个小时过期时间计算而获得的,所以每次执行获得的值会不一样。设置好后,如果用户在Tue, 17-Jun-2008 09:37:43 GMT之前访问csai.cn域名下的任何资源都会在请求消息头携带TestCookieName=TestCookieValue的Cookie项,如下所示:
Tue, 17-Jun-2008 09:37:43 GMT
如下的PrintCookieServlet从用户的请求中获取携带的Cookie,并且打印出每一个Cookie的名和值:
package cn.csai.web.servlet.cookie;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.Servlet;
import javax.servlet.ServletConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.Cookie;
import javax.servlet.http.HttpServletRequest;
public class PrintCookieServlet implements Servlet {
public void destroy() {
}
public ServletConfig getServletConfig() {
return null;
}
public String getServletInfo() {
return null;
}
public void init(ServletConfig arg0) throws ServletException {
}
public void service(ServletRequest arg0, ServletResponse arg1)
throws ServletException, IOException
{
PrintWriter writer = arg1.getWriter();
HttpServletRequest req = (HttpServletRequest) arg0;
Cookie[] cookies = req.getCookies();
writer.write("All Cookies: <br>");
if (null != cookies) {
for (Cookie c : cookies) {
writer.write(c.getName() + "=" + c.getValue() + "<br>");
}
}
writer.flush();
writer.close();
}
}
Servlet Filter常被用于对过滤特定的请求和响应,通常一个Filter会具有一种特定的功能。多个Filter常以链的形式连接起来对请求和响应进行作用,但Filter之间是相互独立的,每个Filter并不需要知道其他Filter的存在。Filter在Java Web编程中是非常重要的,其中一个最普遍的使用就是用来实现登录验证。
登录验证的功能是比较容易理解的。假设需要开发一个非常简单的SecretInfo系统,系统需求如下。
SecretInfo系统只有两个页面,/login.htm和/content/view.jsp,/login.htm提供登录入口要求用户提交用户名和密码。如果用户提供的用户名和密码正确将会进入到/content/view.jsp页面,该页面会显示一段秘密的文本;如果用户提供的用户名密码错误,将不能看到一段秘密的文本。这个系统的需求可以说非常的简单,很快就可以拿出一个解决方案:login.htm提供一个登录界面,并且将登录信息提交给LoginServlet。LoginServlet用于判断登录信息是否正确,如果登录信息正确则将用于请求重定向到/content/view.jsp,否则将用户请求重定向回login.htm。/content/view.jsp只负责显示一段秘密的文本。具体实现如下:
login.htm
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4 /loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<title>Insert title here</title>
</head>
<body>
<form action="LoginServlet">
用户名: <input type="text" name="username"><br>
密码: <input type="password" name="password"><br>
<input type="submit" value="提交">
</form>
</body>
</html>
view.jsp
<%@ page language="java" contentType="text/html; charset=ISO-8859-1"
pageEncoding="ISO-8859-1"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4 /loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<title>Insert title here</title>
</head>
<body>
A Secret Message.
</body>
</html>
LoginServlet
package cn.csai.web.secretinfo;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class LoginServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
String username = req.getParameter("username");
String password = req.getParameter("password");
if (null != username && null != password && username.equals("admin")
&& password.equals("admin"))
resp.sendRedirect("content/view.jsp");
else
resp.sendRedirect("login.htm");
}
}
为了简单起见,以上提供的实现都只是最简单的实现。view.jsp提供的一段秘密文本是“A Secret Message.”,LoginServlet也只是简单的判断用户名和密码是否都等于“admin”。配置好web.xml,并将该应用部署到Tomcat中后,实验该系统的功能。打开login.htm如图8.27所示:
图8.27 login.htm页面
在用户名和密码输入框中输入任意的非“admin”的字符,页面将仍然返回到login.htm。如果用户名和密码都输入admin,将打开view.jsp页面,如图8.28所示。
图8.28 view.jsp页面
截止到目前的测试情况看,系统的工作与需求是一致的,但对于别有用心的用户,该系统存在的一个漏洞将是致命的:不用登录也可以看到这段秘密的文本。现在重新打开一个浏览器,直接把浏览器地址栏中URL后面部分的“login.htm”改为“content/view.jsp”,view.jsp就会被打开,而且这一段秘密的文本也会被发现。这也就是说用户可以不需要用户名和密码而直接登录系统。这在任何通过用户名和密码来管理权限的系统来说都是一个致命的缺陷。而且,在很多Web系统中,使用用户名和密码进行权限管理是非常常用的。下面就介绍一种方法,在前面开发的系统的基础上修复这个缺陷。
这个方法就是使用Servlet Filter来验证登录:当用户登录成功后,在用户Session中添加一个属性用于指示用户已经成功登录;为受限资源(需要登录才能查看的资源,例如view.jsp)部署一个Servlet Filter,当用户访问这些受限资源时查看用户的Session是否已经登录成功,如果已登录成功则允许通过Servlet Filter,否则将用户响应重定向到一个错误页面。
在这个方法中,要注意以下几点。
1.login.htm和view.jsp都不需要改变任何内容。
2.由于在用户登录成功后需要在Session中添加属性,所以需要在LoginServlet中做相应修改。如下所示。
package cn.csai.web.secretinfo;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class LoginServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
String username = req.getParameter("username");
String password = req.getParameter("password");
if (null != username && null != password && username.equals("admin")
&& password.equals("admin"))
{
req.getSession().setAttribute("Loged", Boolean.TRUE);
resp.sendRedirect("content/view.jsp");
}
else
resp.sendRedirect("login.htm");
}
}
当用户登录成功时,首先在Session中添加一个属性Loged=true。这个属性名和属性值可以随意设置,只要在检查登录情况时获取相同的属性就可以了。
3.实现一个错误信息提示页面error.htm,提示用户“未登录或者登录已过期”。这只需要一个非常简单的HTML页面即可,如下所示。
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/ loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<title>Insert title here</title>
</head>
<body>
未登录或者登录已过期。回到<a href="login.htm">登录</a>页面。
</body>
</html>
在页面中提示错误信息,并且提供一个链接到登录页面。
4.实现一个LoginFilter,使其对访问view.jsp的请求进行过滤,在Filter中检查当前Session是否已登录,如果没有登录则将用户响应重定向到error.htm。这是其中最重要的环节,但是LoginFilter的实现可以非常简单,如下所示。
package cn.csai.web.secretinfo;
import java.io.IOException;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class LoginFilter implements Filter {
public void destroy() {
}
public void doFilter(ServletRequest arg0, ServletResponse arg1,
FilterChain arg2) throws IOException, ServletException
{
HttpServletRequest req = (HttpServletRequest) arg0;
Object loged = req.getSession().getAttribute("Loged");
if(null == loged) {
HttpServletResponse resp = (HttpServletResponse) arg1;
resp.sendRedirect(req.getContextPath() + "/error.htm");
}
else {
arg2.doFilter(arg0, arg1);
}
}
public void init(FilterConfig arg0) throws ServletException {
}
}
将LoginFilter部署到web.xml中,如下所示。
<?xml version="1.0" encoding="UTF-8"?>
<web-app id="WebApp_ID" version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www. w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com /xml/ns/j2ee/web-app_2_4.xsd">
<display-name>
SecretInfo</display-name>
<servlet>
<description>
</description>
<display-name>LoginServlet</display-name>
<servlet-name>LoginServlet</servlet-name>
<servlet-class>cn.csai.web.secretinfo.LoginServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>LoginServlet</servlet-name>
<url-pattern>/LoginServlet/*</url-pattern>
</servlet-mapping>
<filter>
<filter-name>LoginFilter</filter-name>
<filter-class>cn.csai.web.secretinfo.LoginFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>LoginFilter</filter-name>
<url-pattern>/content/view.jsp</url-pattern>
</filter-mapping>
<welcome-file-list>
<welcome-file>login.htm</welcome-file>
</welcome-file-list>
</web-app>
将url-mapping设置为/content/view.jsp,即只对view.jsp一个页面进行登录信息检查,这是因为在本系统中只有一个页面中包含了受限信息。但在实际的系统中会有许多页面包含受限信息,那么只需要修改这个url-pattern的值,使其符合所有包含受限信息的页面的URL。比如最简单的,将所有包含受限信息的页面放在一个目录中(例如content目录),那么就可以将url-pattern修改为/content/*。如果包含受限信息的页面比较多,程序员又不想将所有这些页面放在一个目录中,那么可以使用多个filter-mapping,如下所示。
<filter>
<filter-name>LoginFilter</filter-name>
<filter-class>cn.csai.web.secretinfo.LoginFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>LoginFilter</filter-name>
<url-pattern>/content/*</url-pattern>
</filter-mapping>
<filter-mapping>
<filter-name>LoginFilter</filter-name>
<url-pattern>*.jsp </url-pattern>
</filter-mapping>
本例中对content目录下的所有页面以及所有jsp文件使用Filter进行登录验证。
开发完成后将系统部署到Tomcat中,验证系统的功能。
打开login.htm,输入正确的登录信息,提交后可以正常显示view.jsp及其内容。重新打开一个浏览器,直接在其中输入view.jsp的URL,如图8.29所示。
图8.29 直接输入view.jsp的URL
然后回车,浏览器显示如图8.30所示。
图8.30 error.htm页面
所打开的页面并不是view.jsp而是error.htm,由此可见,当用户想在不登录的情况下直接访问受限页面时,用户响应会被重定向到error.htm。
通过使用Servlet Filter来实现对受限页面进行登录信息验证非常方便,只需要对登录验证的Servlet稍加修改,以及适当地对Filter的url-mapping进行配置就可以在保持受限页面代码不用改变的情况下灵活控制对受限页面的访问。
Servlet Filter的工作方式就是通过影响请求和响应进而改变Servlet的处理过程,最终影响到用户提交请求所产生的执行效果,以及对用户产生有别于Servlet原始响应结果的响应。
在没有Filter存在的情况下,Servlet所获得的ServletRequest是根据用户提交的原始请求构造而成的,这个ServletRequest对象反映了用户所提交请求的实际情况,比如请求的URL、参数、Cookie、消息体的输入流,等等。Servlet通过ServletRequest的相关get方法获得这些参数,比如getRequestURI()、getAttribute(name)、getCookies()、getInputStream()。
如果希望Servlet在通过相关方法获得的值不同于原始用户请求的话,就可以通过添加一个Filter对请求进行修改。通过添加Filter,可以在不修改Servlet实现的情况下使Servlet对用户的请求采取不同的处理策略。
使用Filter修改请求的方式通常只有一种,就是使用ServletRequestWrapper重新构造一个ServletRequest对象,并且修改这个对象相应方法的行为,然后将这个对象当作用户提交的ServletRequest对象传递给Servlet。在Servlet调用ServletRequest的相应方法时,实质上调用的是ServletRequestWrapper的方法,由于ServletRequestWrapper的方法是根据开发人员的意图修改过的实现,当Servlet调用时获得结果会与调用原ServletRequest的相应方法不一样,从而模拟了修改ServletRequest的功能。
使用这种方法修改请求的关键就是如何实现一个合适的ServletRequestWrapper。FilterTest演示了如何通过构造ServletRequestWrapper改变请求。最初,FilterTest实现了一个简单的用户登录功能,在登录页面中输入用户名和密码,然后提交给LoginServlet,LoginServlet判断用户名和密码是否正确,这个功能与SecretInfo系统的登录功能一样,可以使用SecretInfo系统的login.htm和LoginServlet。在login.htm中用户名输入框的名称是username,密码输入框的名称是password,所以在LoginServlet中分别使用req.getParameter(“username”)和req.getParameter(“password”)获得用户输入的用户名和密码。假如现在需要在不修改Servlet的情况下,那就支持用如下的login2.htm进行登录:
login2.htm
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4 /loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312">
<title>Insert title here</title>
</head>
<body>
<form action="LoginServlet">
用户名: <input type="text" name="usnm"><br>
密码: <input type="password" name="pswd"><br>
<input type="submit" value="提交">
</form>
</body>
</html>
login2.htm与login.htm唯一的区别就是为用户名和密码输入框取了两个不同的名称。假如直接使用login2.htm进行登录,就算输入的用户名和密码都是正确的(LoginServlet判断是否都等于admin)也无法登录。查看LoginServlet的实现(不考虑登录验证功能):
package cn.csai.web.filter;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class LoginServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
String username = req.getParameter("username");
String password = req.getParameter("password");
if (null != username && null != password && username.equals("admin")
&& password.equals("admin"))
{
resp.sendRedirect("content/view.jsp");
}
else
resp.sendRedirect("login.htm");
}
}
LoginServlet会从请求中取username和password参数的值,由于在请求中取不到这两个参数,所以username和password都为null,那么LoginServlet就会当作登录不成功对待。归根究底,就是因为不同的参数名。这只需要修改LoginServlet的实现,将username改为usnm,将password改为pswd就可以了。
那假如不能修改Servlet、而希望通过Filter来解决这个问题,该怎么办呢?最直接的就是修改请求,当Servlet使用req.getParameter(“username”)时返回req.getParameter(“usnm”),当使用req.getParameter(“password”)时返回req.getParameter(“pswd”)。
首先,实现一个HttpServletRequestWrapper的子类:
AttributeRequestWrapper
package cn.csai.web.filter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletRequestWrapper;
public class AttributeRequestWrapper extends HttpServletRequestWrapper {
public AttributeRequestWrapper(HttpServletRequest request) {
super(request);
}
@Override
public String getParameter(String name) {
if(name.equals("username")) {
return super.getParameter("usnm");
}
else if(name.equals("password")) {
return super.getParameter("pswd");
}
return super.getParameter(name);
}
}
AttributeRequestWrapper继承自HttpServletRequestWrapper并且覆盖Wrapper的getParameter(name)方法。如果请求的参数名为username则返回usnm参数的值,如果请求的参数名为password则返回pswd参数的值,否则就直接返回原参数值。
然后,实现一个Filter,在过滤时使用原ServletRequest构造一个AttributeRequestWrapper的对象并传递给Servlet:
AttributeFilter
package cn.csai.web.filter;
import java.io.IOException;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.HttpServletRequest;
public class AttributeFilter implements Filter {
public void destroy() {
}
public void doFilter(ServletRequest arg0, ServletResponse arg1,
FilterChain arg2) throws IOException, ServletException
{
arg2.doFilter(new AttributeRequestWrapper((HttpServletRequest) arg0), arg1);
}
public void init(FilterConfig arg0) throws ServletException {
}
}
将该Filter配置到web.xml中并且部署应用后就可以正常工作了。
打开login2.htm,并且输入admin/admin,如图8.31所示:
图8.31 login2.htm页面
登录后就可以打开view.jsp,如图8.32所示:
图8.32 登录成功后的view.jsp页面
在这种情况下,login.htm又无法正常登录。其实,只要对AttributeRequestWrapper稍作修改就能够使两个命名方式的login.htm和login2.htm都能够正确登录。将AttributeRequestWrapper修改如下:
package cn.csai.web.filter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletRequestWrapper;
public class AttributeRequestWrapper extends HttpServletRequestWrapper {
public AttributeRequestWrapper(HttpServletRequest request) {
super(request);
}
@Override
public String getParameter(String name) {
if(name.equals("username")) {
String username = super.getParameter("username");
String usnm = super.getParameter("usnm");
if(null == username) return usnm;
}
else if(name.equals("password")) {
String password = super.getParameter("password");
String pswd = super.getParameter("pswd");
if(null == password) return pswd;
}
return super.getParameter(name);
}
}
在这个实现中,分别获取username参数和usnm参数的值。如果第一个值为空则返回第二个值,密码的获取也一样,如此一来两种命名方式都可以支持。同理,开发人员可以通过Filter实现对各种命名方式的支持,而不需要修改Servlet;当不需要支持这些命名方式时只需要取消Filter的部署即可。
使用Servlet Filter对改变响应的使用范围远远多于用于改变请求,因为用Servlet Filter改变响应更直接地影响到用户体验。使用Servlet Filter改变响应的方式主要有两种,直接调用响应的相关方法和使用响应包装器。
1.直接调用响应的相关方法
ServletResponse提供了许多设置属性和执行操作的方法,通过这些方法可以设置响应的MIME类型、直接向客户端发送响应消息(包括重定向消息、错误消息、一般响应消息等)、设置响应消息的头域,等等。比如:setContentType(mime)、sendRedirect(url)、sendError(status)、setHeader(name, value)等。在Filter中,Filter可以直接对获得的ServletResponse对象调用这些方法进而改变用户获得的响应,甚至Filter可以直接拦截请求并且自主地为客户端发送响应,而不将请求传递给Serlvet。
在SecretInfo中,LoginFilter就是在判断到用户未登录时就直接截断请求的传递,而是直接通过调用响应的sendRedirect(url)方法向客户端发送了一个重定向消息。
这种方法简单直接,但很难与Servlet配合工作。
2.使用响应包装器
这种方式与前面提到的修改请求的方式一模一样,Servlet中也提供了SerlvetResponseWrapper对象,开发人员可以通过实现一个ServletResponseWrapper的子类并将其传递给Servlet以改变原ServletResponse的行为。
下面将使用一个示例来对这种方式进行说明。在这个例子将实现一个NewLineFilter。在前面的一些示例中读者可能已经发现,使用ServletResponse的PrintWriter直接输出回车符时,只是在响应的HTML页面中多一个回车符,但是当显示到页面中后这个回车符并不会被显示为一个换行符,因为在HTML中换行符是通过标签<br>表示的。这个NewLineFilter将替换响应消息中的回车符为<br>,使Servlet在输出回车符时就能够体现为页面中的一个新行。
首先,在没有NewLineFilter的时候查看一下效果。下面是一个非常简单的Servlet,它只向响应中输出两行文本:
TextPrinterServlet
package cn.csai.web.filter;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class TextPrinterServlet extends HttpServlet {
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
PrintWriter writer = resp.getWriter();
writer.println("line1");
writer.println("line2");
writer.flush();
writer.close();
}
}
该Servlet使用PrintWriter的println()方法向响应中输出两行文字。部署该Servlet并用浏览器访问该Servlet获得的结果,如图8.33所示:
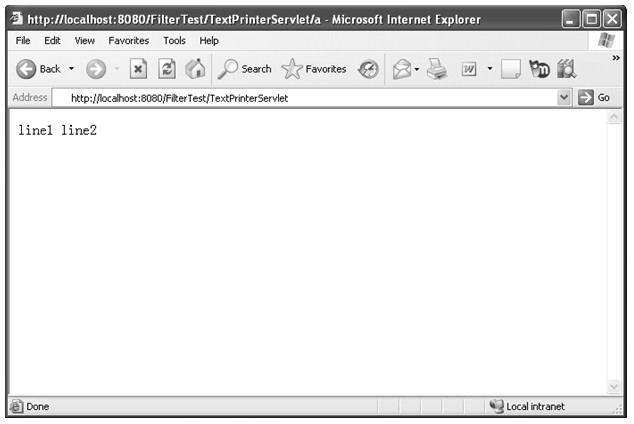
图8.33 没有NewLineFilter的页面
查看该页的HTML源代码如下:
line1
line2
可以发现在HTML源代码中确实是被分为两行,但是显示到页面中后就只有一行了,这是因为HTML是通过标签进行格式化的。所以,在Servlet中向响应打印回车符时只能体现在源代码中,而无法体现在页面上。
为了解决这个问题,我们就开发一个NewLineFilter,让它在过滤响应消息中将其中的回车符替换为HTML的换行标签<br>。也就是说当Servlet调用println(s)时,Filter使用print(s + “<br>”)进行替换。因为Servlet首先是通过ServletResponse的getWriter()方法,然后再使用PrintWriter的println()方法,所以必须要新建一个新的PrintWriter的子类,覆盖其默认的println()方法和print()方法,然后创建一个ServletResponseWrapper的子类,让它的getWriter()方法返回新建的PrintWriter类。在Filter中将ServletResponseWrapper的子类传递给Servlet。这几个类的实现如下:
ChangeNewLinePrintWriter
package cn.csai.web.filter;
import java.io.PrintWriter;
import java.io.Writer;
public class ChangeNewLinePrintWriter extends PrintWriter {
public ChangeNewLinePrintWriter(Writer arg0) {
super(arg0);
}
@Override
public void print(String s) {
super.print(s.replace("\n", "<br>"));
}
@Override
public void println(String x) {
super.println(x + "<br>");
}
}
NewLineResponseWrapper
package cn.csai.web.filter;
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.http.HttpServletResponse;
import javax.servlet.http.HttpServletResponseWrapper;
public class NewLineResponseWrapper extends HttpServletResponseWrapper {
public NewLineResponseWrapper(HttpServletResponse resp)
{
super(resp);
}
@Override
public PrintWriter getWriter() throws IOException {
return new ChangeNewLinePrintWriter(super.getWriter());
}
}
NewLineFilter
package cn.csai.web.filter;
import java.io.IOException;
import javax.servlet.Filter;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;
import javax.servlet.http.HttpServletResponse;
public class NewLineFilter implements Filter {
public void destroy() {
}
public void doFilter(ServletRequest arg0, ServletResponse arg1,
FilterChain arg2) throws IOException, ServletException
{
arg2.doFilter(arg0, new NewLineResponseWrapper(
(HttpServletResponse) arg1));
}
public void init(FilterConfig arg0) throws ServletException {
}
}
将NewLineFilter配置到web.xml中:
<filter>
<filter-name>NewLineFilter</filter-name>
<filter-class>cn.csai.web.filter.NewLineFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>NewLineFilter</filter-name>
<url-pattern>/TextPrinterServlet</url-pattern>
</filter-mapping>
因为这里作为测试,所以其配置只对TextPrinterServlet进行过滤。
将这个Filter配置到应用中后,访问TextPrinterServlet的过程如下:
当有请求TextPrinterServlet的请求到达时,NewLineFilter拦截到请求,在进行过滤时,用原ServletResponse对象构造一个NewLineResponseWrapper对象传递给Servlet;
当Servlet的doGet()方法开始执行时,传递进来的ServletResponse对象实质上是NewLineResponse Wrapper对象;Servlet调用ServletResponse对象的getWriter()方法实质上是调用NewLineResponse Wrapper的getWriter()方法,所以获得的PrintWriter对象实质上是在NewLineResponseWrapper中构造的ChangeNewLinePrintWriter;
Servlet调用获得PrintWriter对象的println(s)方法,实质上是调用了ChangeNewLinePrintWriter的println(s)方法,所以当Servlet调用println(“line1”)时实质上相当于调用println(“line1” + "<br>"),同样println(“line2”)相当于调用println(“line2” + “<br>”);
所以,最终到响应中的是“line1<br>\nline2<br>\n”。
将Filter配置到应用中,重新访问TextPrinterServlet,获得的页面如图8.34所示:
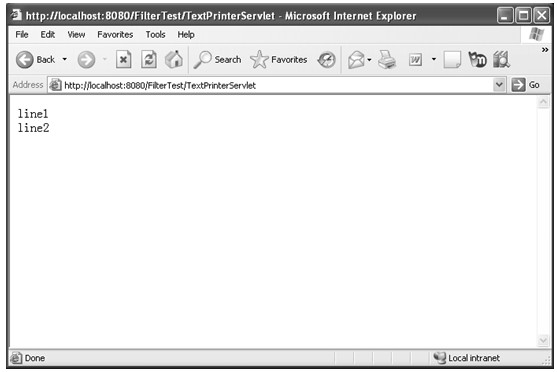
图8.34 增加了NewLineFilter后的页面
查看HTML源文件如下:
line1<br>
line2<br>
Servlet是一种可以配置进Servlet容器中用于处理客户端请求的特殊Java对象。在接收到客户端请求后,Tomcat将请求封装为一个ServletRequest对象,同时构造一个指向客户端的空白ServletResponse对象,然后将两个对象同时传递给Servlet,Servlet分析并处理ServletRequest对象并将响应结果通过ServletResponse对象传递给客户端。
Servlet中最重要的几个概念分别是:Servlet接口代表一个Servlet;ServletConfig接口代表对一个Servlet的配置信息;ServletContext接口代表Servlet所运行的上下文信息;RequestDispatcher接口表示一个请求转发器。
GenericServlet和HttpServlet是两个对Servlet的默认实现,GenericServlet表示一个通用Servlet,HttpServlet对象表示一个专门处理HTTP请求的Servlet。ServletRequest和ServletResponse分别表示通用Servlet请求和响应,HttpServletRequest和HttpServletResponse分别表示HTTP请求和响应。
Servlet过滤器,是一种搭建在Servlet容器和Servlet之间的过滤器,它对Servlet容器分发给Servlet的请求和Servlet返回给Servlet容器的响应进行处理,并且这种处理对于目的Servlet和客户端都是透明的。
JSP是Java ServerPage的简称,是Java Web开发中又一个重要的基础技术。作为一种Web对象,JSP以JSP文件的形式与HTML文件一样存在于Web应用目录中。JSP文件的格式类似于HTML文件,它通过特殊标签在HTML文件中添加Java代码以实现动态处理功能。在服务器运行期间,JSP文件可以根据Java代码的执行情况动态地生成HTML文件的内容。
本章将首先揭开JSP文件的表象,对JSP的本质及其内部实现机制进行介绍,然后介绍JSP的基本语法以及JSP中隐含对象的使用。最后将介绍JSP中最强大的功能,那就是自定义标签的开发,包括JSP中标签的体系结构,以及通过实例介绍如何进行各个级别自定义标签的开发。
在Web应用中,JSP以单个文件存在,它的内容可以包含静态内容(HTML代码)也可包含动态内容(Java代码);客户端在访问JSP文件时,直接按照JSP文件的路径请求。test.jsp的一个简单的JSP文件实例如下所示:
示例9.1 test.jsp
<%@ page language="java" contentType="text/html; charset=GB2312" pageEncoding="GB2312"%>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<title>Test</title>
</head>
<body>
<%
out.print("Hello World");
%>
</body>
</html>
从表面上看JSP文件与HTML文件的格式很类似,只是在HTML文件中添加了由<%和%>括起来的内容。这些被括起来的内容就是JSP中的动态内容。
将该JSP部署到Web应用test中后,访问得到的页面效果如图9.1所示。
图9.1 test.jsp运行效果
在打开的页面上单击鼠标右键→查看源文件,得到该JSP文件在客户端浏览器中被打开时的HTML代码,内容如下:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<title>Test</title>
</head>
<body>
Hello World
</body>
</html>
比较JSP文件内容和打开后的源文件内容可以发现,打开后的源文件是一个标准的HTML文件,其中已经没有任何由<%和%>括起来的内容,而是被<%和%>之间的代码的执行结果所取代。
从这个现象不难推测,JSP文件在被请求时的执行过程如图9.2所示:
如图9.2所示,客户端请求服务器上的JSP文件,服务器首先执行JSP文件中的Java代码并且根据代码逻辑将输出结果写入代码所在位置;所有Java代码执行结束后JSP文件的内容便成为纯静态内容,变成一个HTML文件,然后服务器再将该HTML文件的内容返回给客户端。可见,JSP文件中虽然将静态的HTML内容和动态的Java代码混合,但是实质上它们是被分成两层的,静态的HTML内容是底层,动态的Java代码是上层。
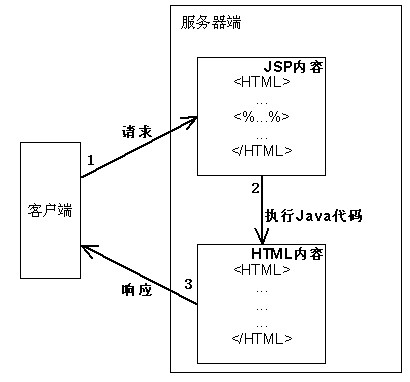
图9.2 推断的JSP执行过程示意图
作为一个普通的Web开发人员,单纯从JSP文件执行的表象来看,这种方式已经完全可以将JSP的工作过程解释清楚。但如果要深入JSP文件在服务器端被处理的实质过程,这种解释并不完全正确。JSP文件的本质实际上是一个Servlet,JSP最终会在服务器中被转化为一个Servlet,然后由Servlet响应客户端的请求。所以,JSP的实际执行过程如图9.3所示。
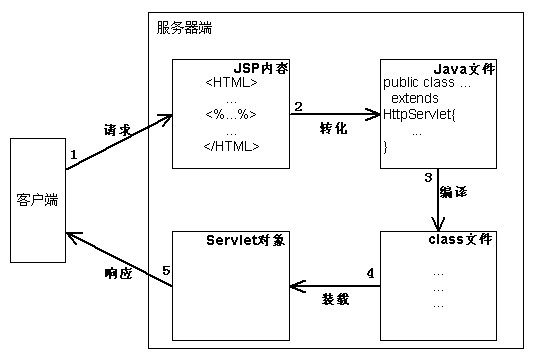
图9.3 实际的JSP执行过程示意图
如图9.3可以发现,在有请求到达JSP文件时,服务器会将JSP文件首先转化成为一个Java文件,这个Java文件定义了一个Servlet;然后将该Java文件编译成一个class文件,服务器装载class文件为Servlet对象;Servlet对象根据请求对客户端进行响应。
在这个过程中,编译和装载都比较好理解,这与普通的Servlet一样;而转化是这其中的关键步骤,也是比较难于理解的一步。其实,在前面介绍Tomcat的web.xml文件配置时已经介绍过在初始状态下,通用web.xml中配置了两个Servlet,一个是DefaultServlet,另一个是JspServlet;JspServlet就负责将JSP文件转化为Java文件、调用JDK编译Java文件、并且装载Servlet。JspServlet同DefaultServlet一样,它也是Tomcat自带的一个Servlet,它专门负责响应客户端对JSP文件的访问。
在有客户端请求访问JSP文件时,JspServlet会在Tomcat的工作目录中生成对应的Java文件,并且编译成class文件。Tomcat的工作目录是${TOMCAT_HOME}/work,JSP文件转换而成的Java文件以及将Java文件编译生成的class文件都在该目录下的${Service}/${Host}/${Context}/org/apache/jsp目录中,其中${Service}表示使用的Tomcat Service的名称,${Host}表示使用的虚拟主机的名称,${Context}表示Web应用的上下文路径。以上面Hello World实例中的test.jsp文件为例,它使用的是Catalina的localhost,Web应用的上下文路径为test,所以test.jsp对应的Java文件和class文件都在${TOMCAT_HOME}/work/Catalina/localhost/test/org/apache/jsp目录中。test.jsp转换的Java文件如下:
package org.apache.jsp;
import javax.servlet.*;
import javax.servlet.http.*;
import javax.servlet.jsp.*;
public final class test_jsp extends org.apache.jasper.runtime.HttpJspBase
implements org.apache.jasper.runtime.JspSourceDependent {
private static final JspFactory _jspxFactory = JspFactory.getDefaultFactory();
private static java.util.List _jspx_dependants;
private javax.el.ExpressionFactory _el_expressionfactory;
private org.apache.AnnotationProcessor _jsp_annotationprocessor;
public Object getDependants() {
return _jspx_dependants;
}
public void _jspInit() {
_el_expressionfactory =
_jspxFactory.getJspApplicationContext(getServletConfig().getServletContext())
.getExpressionFactory();
_jsp_annotationprocessor =
(org.apache.AnnotationProcessor) getServletConfig().getServletContext()
.getAttribute(org.apache.AnnotationProcessor.class.getName());
}
public void _jspDestroy() {
}
public void _jspService(HttpServletRequest request, HttpServletResponse response)
throws java.io.IOException, ServletException {
PageContext pageContext = null;
HttpSession session = null;
ServletContext application = null;
ServletConfig config = null;
JspWriter out = null;
Object page = this;
JspWriter _jspx_out = null;
PageContext _jspx_page_context = null;
try {
response.setContentType("text/html; charset=GB2312");
pageContext = _jspxFactory.getPageContext(this, request, response, null, true, 8192, true);
null, true, 8192, true);
_jspx_page_context = pageContext;
application = pageContext.getServletContext();
config = pageContext.getServletConfig();
session = pageContext.getSession();
out = pageContext.getOut();
_jspx_out = out;
out.write("\n");
out.write("\n");
out.write("<html>\n");
out.write("<head>\n");
out.write("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=ISO-8859-1\">\n");
out.write("<title>Test</title>\n");
out.write("</head>\n");
out.write("<body>\n");
out.print("Hello World");
out.write("\n");
out.write("</body>\n");
out.write("</html>");
} catch (Throwable t) {
if (!(t instanceof SkipPageException)){
out = _jspx_out;
if (out != null && out.getBufferSize() != 0)
try { out.clearBuffer(); } catch (java.io.IOException e) {}
if (_jspx_page_context != null) _jspx_page_context.handlePageException(t);
}
} finally {
_jspxFactory.releasePageContext(_jspx_page_context);
}
}
}
可以发现,JSP文件最终被转化成为一个HttpJspBase的子类,HttpJspBase是一个抽象类,它的继承关系如图9.4所示。
图9.4 HttpJspBase类的继承层次图
由此可见,HttpJspBase实质上也是一个Servlet,自动生成的Java类test_jsp也会作为一个Servlet被部署到Tomcat中。在test_jsp中,最核心的一段代码是:
response.setContentType("text/html; charset=GB2312");
pageContext = _jspxFactory.getPageContext(this, request, response, null, true, 8192, true);
null, true, 8192, true);
_jspx_page_context = pageContext;
application = pageContext.getServletContext();
config = pageContext.getServletConfig();
session = pageContext.getSession();
out = pageContext.getOut();
_jspx_out = out;
out.write("\n");
out.write("\n");
out.write("<html>\n");
out.write("<head>\n");
out.write("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=ISO-8859-1\">\n");
out.write("<title>Test</title>\n");
out.write("</head>\n");
out.write("<body>\n");
out.write("\n");
out.write("</body>\n");
out.write("</html>");
其中,response.setContentType("text/html; charset=GB2312")一行对应test.jsp文件中page设置<%@ page language="java" contentType="text/html; charset=GB2312" pageEncoding="GB2312"%>中的contentType="text/html; charset=GB2312";下面几行是用于获取out对象;JSP文件中的Java代码直接搬移到Java文件中,将HTML内容通过out.write()方法写入到响应对象中。
JSP文件不管复杂还是简单,JspServlet都会根据同样的规则将其转换成Servlet来响应客户端的请求。所以JSP文件表象是一个包含了Java代码片段的HTML文件,但实质上它是一个Servlet。
JSP文件中所有JSP使用的动态内容都由<%和%>符号包围着,在这两个符号之间开发人员可以编写任何符合Java规范和语法的代码。例如:
<%
for(int i=0; i<10; i++){
out.print("Hello World");
}
%>
这段代码最终会在页面上显示10个Hello World。
Java代码块可以被分开到两个<%...%>块中,例如下面这段代码也可以在页面上显示10个Hello World:
<%
for(int i=0; i<10; i++){
%>
Hello World
<%
}
%>
因为两段代码在JSP被转化为Servlet后分别对应如下两段Java代码:
for(int i=0; i<10; i++){
out.print("Hello World");
}
for(int i=0; i<10; i++){
out.write("Hello World");
}
这两段代码的执行结果完全一样。
在代码块中可以定义变量但不可以定义方法。下例是允许的:
<%
int sum = 0;
sum += 2;
out.println(sum);
%>
而下例这样是不允许的:
<%
private int add(int x, int y){
return x+y;
}
out.println(add(1+2));
%>
JSP声明是指一块专门用来进行变量和方法定义的程序段,其格式如下:
<%!
int var;
private int add(int x, int y){
return x+y
}
%>
声明代码块由<%!和%>包围,其中只能用来声明,而不能添加任何代码块。所以如下的代码块是错误的:
<%!
int var = 0;
var++;
%>
JSP中所有关于方法的声明必须在声明代码块中定义,而变量可以在声明块中定义也可以在程序代码块中定义,那这两种的区别在哪里?下面构造一个JSP文件,将其转化生成的Servlet文件打开就可以发现其区别。JSP文件如下:
示例9.2 test.jsp
<%@ page language="java" contentType="text/html; charset=GB2312" pageEncoding="GB2312"%>
<html>
<head>
<title>Test</title>
</head>
<body>
<%!
int declareVar;
%>
<%
int programVar;
%>
</body>
</html>
在JSP文件中有一个声明块和一个程序块,声明块中定义了一个变量declareVar,在程序块中定义了一个变量programVar。将该JSP文件部署到Web应用中,通过Tomcat访问该JSP文件,在Tomcat的工作目录中就可以获得转化后的Java文件,查看其内容如下:
package org.apache.jsp;
import javax.servlet.*;
import javax.servlet.http.*;
import javax.servlet.jsp.*;
public final class test_jsp extends org.apache.jasper.runtime.HttpJspBase
implements org.apache.jasper.runtime.JspSourceDependent {
int declareVar;
private static final JspFactory _jspxFactory = JspFactory.getDefaultFactory();
private static java.util.List _jspx_dependants;
private javax.el.ExpressionFactory _el_expressionfactory;
private org.apache.AnnotationProcessor _jsp_annotationprocessor;
public Object getDependants() {
return _jspx_dependants;
}
public void _jspInit() {
_el_expressionfactory =
_jspxFactory.getJspApplicationContext(getServletConfig().getServletContext())
.getExpressionFactory();
_jsp_annotationprocessor =
(org.apache.AnnotationProcessor) getServletConfig().getServletContext()
.getAttribute(org.apache.AnnotationProcessor.class.getName());
}
public void _jspDestroy() {
}
public void _jspService(HttpServletRequest request, HttpServletResponse response)
throws java.io.IOException, ServletException {
PageContext pageContext = null;
HttpSession session = null;
ServletContext application = null;
ServletConfig config = null;
JspWriter out = null;
Object page = this;
JspWriter _jspx_out = null;
PageContext _jspx_page_context = null;
try {
response.setContentType("text/html; charset=GB2312");
pageContext = _jspxFactory.getPageContext(this, request, response, null, true, 8192, true);
null, true, 8192, true);
_jspx_page_context = pageContext;
application = pageContext.getServletContext();
config = pageContext.getServletConfig();
session = pageContext.getSession();
out = pageContext.getOut();
_jspx_out = out;
out.write("\n");
out.write("<html>\n");
out.write("\t<head>\n");
out.write("\t\t<title>Test</title>\n");
out.write("\t</head>\n");
out.write("\t<body>\n");
out.write("\t");
out.write('\r');
out.write('\n');
int programVar;
out.write("\n");
out.write("</body>\n");
out.write("</html>");
} catch (Throwable t) {
if (!(t instanceof SkipPageException)){
out = _jspx_out;
if (out != null && out.getBufferSize() != 0)
try { out.clearBuffer(); } catch (java.io.IOException e) {}
if (_jspx_page_context != null) _jspx_page_context.handlePageException(t);
}
} finally {
_jspxFactory.releasePageContext(_jspx_page_context);
}
}
}
如代码中粗体部分所示,这两个变量的区别是,declareVar被作为类中的一个域变量,而programVar被作为一个Service方法中的局部变量。域变量在JSP生成的Servlet被装载时生成直到Servlet被卸载时才会被销毁,而局部变量在每次service()方法执行时就会创建和销毁一次;所以在声明块中定义的变量在多次请求时能保持其上次请求的值,而在程序块中定义的变量在多次请求时每次都是初始值。下例可以帮助理解这种情况,编辑JSP文件内容如下:
示例9.3 test.jsp
<%@ page language="java" contentType="text/html; charset=GB2312" pageEncoding="GB2312"%>
<html>
<head>
<title>Test</title>
</head>
<body>
<%!
int declareVar = 0;
%>
<%
int programVar = 0;
%>
<%
declareVar++;
programVar++;
out.println("declareVar:" + declareVar);
out.println("programVar:" + programVar);
%>
</body>
</html>
部署该JSP文件到Web应用中,然后请求访问该JSP文件,第一次访问得到的结果如图9.5所示。
图9.5 第一次访问结果
第二次访问得到的结果如图9.6所示:
图9.6 第二次访问结果
在第一次访问时,两个变量都是从0开始,自增了一次,所以都是1;第二次访问时,declareVar的值是2,而programVar的值仍然是1,这是因为declareVar是域变量而programVar是service()方法的局部变量,每次访问JSP文件时,Servlet对象并不会销毁,只是再一次执行Servlet的service()方法,所以在每次请求时programVar都会被重新声明和赋值,而declareVar则不会被重新声明和赋值,除非Servlet被销毁(Tomcat重启或者由于闲置时间过长将Servlet清理出内存)。
JSP文件中的注释是由<%--和--%>包围的代码块,其中无论是Java代码还是HTML代码都会被注释掉,例如:
<%-- 这是一段注释 --%>
<%
...
%>
将“这是一段注释”作为注释。
<%--
<%
for(int i=0; i<10; i++)
{
%>
Hello World
<% } %>
--%>
会将<%--和--%>当中的所有内容作为注释。
除此之外,在程序代码块内部还可以使用标准的Java注释方式,例如:
<%
String s = “Hello World”;
//out.print(s);
%>
和
<%
String s = “Hello World”;
/*out.print(s);*/
%>
都是正确的注释使用方式。
而在HTML代码块中,HTML的注释符号<!-- -->也同样是可以使用的,例如:
<%
for(int i=0; i<10; i++)
{
%>
Hello <!--World-->
<% } %>
其实,只需要将带有各种注释的JSP文件转换为Servlet,就可以发现各种注释起作用的本质了,以如下一个JSP文件为例:
示例9.4
<%@ page language="java" contentType="text/html; charset=GB2312"
pageEncoding="GB2312"%>
<html>
<head>
<title>Test</title>
</head>
<body>
<%--
<%
for(int i=0; i<10; i++) {
%>
Hello World
<%
out.print("Hello World1");
}
%>
--%>
<%
for(int i=0; i<10; i++) {
%>
Hello <!--World2-->
<%
//out.print("Hello World3");
}
%>
</body>
</html>
生成的Servlet中相关的代码片段如下:
out.write("\r\n");
out.write("<html>\r\n");
out.write("<head>\r\n");
out.write("<title>Test</title>\r\n");
out.write("</head>\r\n");
out.write("<body>\r\n");
out.write("\r\n");
for(int i=0; i<10; i++) {
out.write("\r\n");
out.write("Hello <!--World2-->\r\n");
//out.print("Hello World3");
}
out.write("\r\n");
out.write("</body>\r\n");
out.write("</html>");
访问得到的页面如图9.7所示。
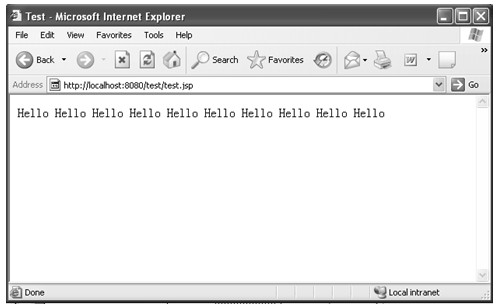
图9.7 test.jsp执行结果
页面的源文件如下:
<html>
<head>
<title>Test</title>
</head>
<body>
Hello <!--World-->
Hello <!--World-->
Hello <!--World-->
Hello <!--World-->
Hello <!--World-->
Hello <!--World-->
Hello <!--World-->
Hello <!--World-->
Hello <!--World-->
Hello <!--World-->
</body>
</html>
对比这几种文件的内容可以发现,由<%-- --%>注释的所有内容在转化为Servlet后就被完全删除了,其中无论包含的是Java代码还是HTML代码;而由//或/* */包围的Java代码会被转换到Servlet中,但是被注释掉的,所以在将Java文件编译成class文件后带注释的代码会被忽略;由<!-- -->包围的HTML代码会带着注释由out.write()语句输出,所以HTML文件中会有带着注释符号的内容,只是HTML文件在最终显示时会忽略掉这段内容。
所以,不同类型的注释是在从JSP文件最终到页面展现的不同阶段中起作用的,使用不同类型的注释会影响到各个阶段的数据处理量。
这里所谓的JSP指令代码块,是指由<%@和%>包围的JSP内容。在当前的JSP版本中,JSP指令有三种:page、taglib和include。
1.page指令
page指令用于设置JSP页面的一些属性,通常写在页面的顶端,page指令的格式如下:
<%@ page attr1="value1" attr2="value2" ... %>
一个page指令可以定义多个页面的属性,一个JSP页面也可以出现多个page指令。可以将多个属性写在一个page指令中,也可以将它们分开写在多个page指令中,这两者的效果是相同的。
page指令中能定义的属性及其含义如下。
language:表示脚本使用的语言,暂时只能用Java。
extends:表明JSP转化的Java类需要继承的父类,包含包名和类名。这个属性要小心使用,因为有些JSP容器在转化JSP时已经对其指定了父类。例如,Tomcat在将JSP转化为Java类时已经为其添加了HttpJspBase父类,所以在Tomcat中的JSP页面中使用extends属性会使得指定的父类覆盖了HttpJspBase父类,这将导致执行JSP时出错,所以使用Tomcat时不要为JSP页面定义extends属性。
import:需要引入的包或者类,作用与Java文件中的import语句一样。属性值也与Java文件中的import语句的内容一致,多个值用逗号隔开。例如:
<%@ page import="java.util.*, java.io.InputStream" %>
session:设定客户端是否需要HTTP Session,取值true/false。如果设定为false,那么在JSP页面中就不能使用session对象也不能将任何变量的scope设置成session,否则会产生错误。默认是true。
buffer:设定JSP向客户端输出响应时所使用的缓冲区大小,不使用可以设置成none。默认是8kB。
autoFlush:设置如果buffer满的话是否自动将响应输出到客户端,true表示自动输出,false表示不自动输出。如果将该值设置为false,那么在当buffer满时就会有异常发生。如果buffer设置为none,那么就不能把autoFlush设置为false。默认是true。
isThreadSafe:说明该JSP文件是否是线程安全的,如果是线程安全的那么Web服务器就会允许多线程访问该文件,否则一次就只能允许一个请求访问JSP文件。默认是true。
info:一段用于描述JSP文件的文本,当JSP被转换为Servlet后,这段文本便成为Servlet的描述信息,可以通过Servlet.getServletInfo()方法获得。
errorPage:设置出错跳转页面。当该JSP文件出错后,请求会被跳转到该页面。
isErrorPage:设置本页是否是错误处理页面,如果设置为true,则本页可以访问exception对象。
contentType:设置该JSP页面内容类型,包括MIME类型和字符编码。通常格式是:contentType="mimeType; charset=encoding"。默认值是:text/html;charset=ISO-8859-1。
pageEncoding:设置JSP页面中的文本所使用的字符编码方式。即JspServlet将使用该编码方式读取和解析JSP文件的内容。
假设在JSP页面中定义了如下的page指令:
<%@ page language="java" buffer="10kb" import="java.util.*" %>
<%@ page contentType="text/html; charset=GB2312" pageEncoding="GB2312" %>
<%@ page autoFlush="true" errorPage="error.jsp" info="test jsp page"%>
<%@ page isThreadSafe="true" isErrorPage="false" session="true" %>
该JSP页面转换的Java文件如下:
package org.apache.jsp;
import javax.servlet.*;
import javax.servlet.http.*;
import javax.servlet.jsp.*;
import java.util.*;
public final class test_jsp extends org.apache.jasper.runtime.HttpJspBase
implements org.apache.jasper.runtime.JspSourceDependent {
public String getServletInfo() {
return "test jsp page";
}
private static final JspFactory _jspxFactory = JspFactory.getDefaultFactory();
private static java.util.List _jspx_dependants;
private javax.el.ExpressionFactory _el_expressionfactory;
private org.apache.AnnotationProcessor _jsp_annotationprocessor;
public Object getDependants() {
return _jspx_dependants;
}
public void _jspInit() {
_el_expressionfactory=
_jspxFactory.getJspApplicationContext(getServletConfig()
.getServletContext()).getExpressionFactory();
_jsp_annotationprocessor =
(org.apache.AnnotationProcessor) getServletConfig().getServletContext()
.getAttribute(org.apache.AnnotationProcessor.class.getName());
}
public void _jspDestroy() {
}
public void _jspService(HttpServletRequest request, HttpServletResponse response)
throws java.io.IOException, ServletException {
PageContext pageContext = null;
HttpSession session = null;
ServletContext application = null;
ServletConfig config = null;
JspWriter out = null;
Object page = this;
JspWriter _jspx_out = null;
PageContext _jspx_page_context = null;
try {
response.setContentType("text/html; charset=GB2312");
pageContext = _jspxFactory.getPageContext(this, request, response, "error.jsp", true, 10240, true);
_jspx_page_context = pageContext;
application = pageContext.getServletContext();
config = pageContext.getServletConfig();
session = pageContext.getSession();
out = pageContext.getOut();
_jspx_out = out;
out.write("\r\n");
out.write("\r\n");
out.write("\r\n");
out.write("\r\n");
out.write("\r\n");
out.write("<html>\r\n");
out.write("\t<head>\r\n");
out.write("\t\t<title>Test</title>\r\n");
out.write("\t</head>\r\n");
out.write("\t<body>\r\n");
out.write("\t\r\n");
out.write("\t</body>\r\n");
out.write("</html>");
} catch (Throwable t) {
if (!(t instanceof SkipPageException)){
out = _jspx_out;
if (out != null && out.getBufferSize() != 0)
try { out.clearBuffer(); } catch (java.io.IOException e) {}
if (_jspx_page_context != null) _jspx_page_context.handlePageException(t);
}
} finally {
_jspxFactory.releasePageContext(_jspx_page_context);
}
}
}
page中的import属性会导致Java文件中添加import语句;info属性会导致Java文件中的getServletInfo()方法返回其属性值;contentType属性会由response.setContentType()方法设置。
buffer、errorPage、autoflush和session会体现在_jspxFactory.getPageContext()方法中,_jspxFactory是JspFactory的对象,getPageContext()的方法声明如下:
public abstract PageContext getPageContext(Servlet servlet, ServletRequest request,
ServletResponse response, String errorPageURL,
boolean needsSession, int buffer, boolean autoflush)
其中的参数与page指令中的属性的对应关系是:errorPageURL →errorPage、needsSession →session、buffer →buffer、autoflush →autoFlush。
剩下的language、pageEncoding、isThreadSafe和isErrorPage属性都是对Web服务器的提示信息,不会体现到Java文件中。
2.taglib指令
在JSP中除了由<%和%>包围的动态内容外,还可以使用传统的HTML标签自定义的标签,只是这些自定义标签必须通过taglib指令引入进来。taglib指令用于定义JSP页面中用户自定义标签的标签库和标签前缀。
比如:
<%@ taglib uri="ctag.tld" prefix="c" %>
将标记库ctag.tld引入到JSP页面中,这样在JSP页面中就可以使用ctag.tld定义的标签了;prefix是指在使用标签时在标签名前加的前缀,所有拥有该前缀的标签都表示对ctag.tld中标签的引用,例如<c:tag1> ... </c:tag1>。uri唯一指定了一个标签库,其值可以是一个URL,也可以是一个标签库的唯一名称。
在JSP文件中,除了JSP预定义标签库以外的任何标签库都必须经过taglib定义后才能够使用;一个JSP文件中允许有多个taglib指令引入多个标签库,每个标签库所定义的prefix必须唯一,而且prefix不能是:jsp, jspx, java, javax, servlet, sun, 和sunw中的任何一个,因为这些是Sun公司保留的前缀。
3.include指令
include指令是一种编辑层的包含指令,它可以在一个JSP文件中插入一个文本文件或者JSP文件的内容。把它称作编辑层的包含指令,是指这种包含方式相当于将被包含者的内容直接输入到JSP文件中的相应位置。假设有如下的JSP文件:
示例9.5 including.jsp
<%@ page language="java" pageEncoding="GB2312" %>
<HTML>
<BODY>
<%@ include file=”included.html” %>
</BODY>
</HTML>
included.html
<H1> Hello World </H1>
那么在访问including.jsp时,Web服务器首先将included.html插入到including.jsp中,然后再将插入后的内容转换为Servlet,所以将including.jsp转换而成的including_jsp.java文件的内容是:
...
out.write("<HTML>\r\n");
out.write("\t<BODY>\r\n");
out.write("\t\t<H1> Hello World </H1>\r\n");
out.write("\t</BODY>\r\n");
out.write("</HTML>");
...
include指令的属性只有一个file,它就表示所包含文件的路径。
JSP预定义标签是一些自动引入的标签库中的标签,它们不需要通过taglib指令引入,而可以直接在JSP页面中通过jsp前缀使用。主要有:<jsp:forward>、<jsp:include>、<jsp:useBean>、<jsp:getProperty>、<jsp:setProperty>和<jsp:plugin>。
1.<jsp:forword>
该标签将一个客户请求前转到一个HTML文件、JSP文件或一个Servlet,前转的资源必须与当前JSP文件处于同一个Web应用中。其格式定义如下:
<jsp:forward page="relativeURL" />
或
<jsp:forward page="relativeURL" >
<jsp:param name="parameterName" value="parameterValue" />
......
</jsp:forward>
其中,page属性的值就是前转页面的URL地址,但是该URL地址不能包含协议名和端口值,而是指向当前Web应用中的文件;该URL地址有两个格式,一种是以“/”开头,它表示从Web应用根目录开始的路径,另一种不以“/”开头,它表示相对于当前JSP文件路径的相对路径。
假如目标文件是动态Web对象(JSP或Servlet等),那么可以为前转URL添加参数,参数将被目标Web对象获得。
示例:
<jsp:forward page="/page/login.jsp" />
<jsp:forward page="login">
<jsp:param name="username" value="kevin" />
</jsp:forward>
2.<jsp:include>
将一个静态页面或者动态页面包含到本JSP文件中。该标签与include指令不同的是:include指令无论被包含者是静态还是动态,只是单纯地将文件内容放在include指令处;而<jsp:include>标签则是向被包含页面发出一个请求,将请求返回的响应结果放在标签处,所以当被包含页面是静态页面时其效果同include指令,而当被包含页面是动态页面时,它会将页面执行结束返回的内容包含在标签处。
除此之外,当包含的页面是动态页面时,<jsp:include>标签还可以通过<jsp:param>标签向被包含页面提供参数。
其格式如下:
<jsp:include page="relativeURL" flush="true" />
或
<jsp:include page="relativeURL " flush="true" >
<jsp:param name="parameterName" value="parameterValue" />
......
</jsp:include>
此处关于relativeURL的定义与<jsp:forward>一样;flush="true"在这里是一个必须给出而且也不能修改其值的属性,在使用时直接加上即可。
3.<jsp:useBean>、<jsp:getProperty>和<jsp:setProperty>
JavaBean组件是用Java开发的一个用于完成特定工作的Java类。同使用的Java库很类似,JavaBean组件在开发完毕后可以通过对JavaBean组件实例化进而使用JavaBean组件中的功能。JavaBean组件存在的目的也是为了使Java代码的广泛复用。JavaBean组件在开发时需要遵照一定的要求:
针对一个名为xxx的域属性,通常要为其定义两个函数:getXxx()用于获取该属性的值,setXxx(...)用于设置该属性的值;
对外界公布的其他方法没有命名要求,但需要定义为public。
例如下面的类可以看作一个JavaBean组件:
public class Person{
private String name;
private int age;
public Date getBirthday(){
......
}
public String getFamilyName(){
......
}
public String getName(){
return name;
}
public int getAge(){
return age;
}
public void setName(String n){
name = n;
}
public void setAge(int a){
age = a;
}
private void analyzeName(){
......
}
}
该类中定义了两个属性name和age,并且分别为两个属性定义了getName()/getAge()/set Name()/setAge()方法;对外提供了两个方法getBirthday()和getFamilyName();同时,还有一个默认的无参构造函数。外界程序如果需要使用这个组件的功能时,只需要通过无参构造函数实例化一个Person的实例,然后通过setName()和setAge()方法将属性值传入,就可以通过调用Person定义的public方法使用该组件提供的功能了。
<jsp:useBean>标签就是JSP提供的一种在JSP文件中声明JavaBean组件的方法,JSP文件通过该标签声明JavaBean对象及其ID,通过<jsp:setProperty>标签设置JavaBean对象的属性值,然后就可以通过JavaBean的ID调用该JavaBean的方法了。
<jsp:useBean>标签的格式如下:
<jsp:useBean
id="beanInstanceName"
scope="page | request | session | application"
{
class="package.class" |
type="package.class" |
class="package.class" type="package.class" |
beanName="package.class" type="package.class"
}
>
......
</jsp:useBean>
id定义了引用该JavaBean对象的代号;scope定义了该JavaBean对象的作用域大小:page是页面域(默认),request是请求域,session是HTTP Session域,application是整个Web应用域。
<jsp:getProperty>用于获得JavaBean组件的属性值并将其打印到页面,其格式:
<jsp:getProperty name="beanInstanceName" property="propertyName" />
示例:
<jsp:useBean id="me" scope="session" class="Person" />
<jsp:setProperty name="me" property="name" value="kevin"/>
<jsp:setProperty name="me" property="age" value="25"/>
<% out.print(me.getBirthday()); %>
4.<jsp:plugin>
该标签用于在浏览器中运行或显示一个Applet或JavaBean,在执行过程中如果浏览器无法运行则可以到指定的链接下载插件。该标签的定义如下:
<jsp:plugin
type="bean | applet"
code="classFileName"
codebase="classFileDirectoryName"
[ name="instanceName" ]
[ archive="URIToArchive, ..." ]
[ align="bottom | top | middle | left | right" ]
[ height="displayPixels" ]
[ width="displayPixels" ]
[ hspace="leftRightPixels" ]
[ vspace="topBottomPixels" ]
[ jreversion="JREVersionNumber | 1.1" ]
[ nspluginurl="URLToPlugin" ]
[ iepluginurl="URLToPlugin" ] >
[ <jsp:params>
[ <jsp:param name="parameterName" value="parameterValue" /> ]
</jsp:params> ]
[ <jsp:fallback> text message for user </jsp:fallback> ]
</jsp:plugin>
其中:
type:表示plugin的类型,是JavaBean还是Applet。
code:表示plugin所需要执行的Java类。
codebase:包含待执行Java类的文件目录。
name:该Bean/Applet的名称,使用此名称便于与JSP文件交流。
archive:包文件在codebase中的位置,可以定义多个包文件,之间用逗号隔开。这些包文件会使用类装载器进行加载。
align:希望待打开对象在页面中的位置。
height:待打开对象在页面中显示时的初始高度。
width:待打开对象在页面中显示时的初始宽度。
hspace:待打开对象在页面中显示时的左右边距。
vspace:待打开对象在页面中显示时的上下边距。
jreversion:Applet或者Bean运行时使用的JRE的版本,默认是1.1。
nspluginurl:客户端下载Netscape Navigator JRE插件的URL。
iepluginurl:客户端下载Internet Explorer JRE插件的URL。
<jsp:params>标签用来定义需要向Applet或Bean传递的参数。<jsp:fallback>用来定义如果插件无法运行时向客户端显示的文本消息。
示例:
<jsp:plugin type=applet code="Show.class" codebase="/applets">
<jsp:params>
<jsp:param name="id" value="2134" />
</jsp:params>
<jsp:fallback>
<p>无法装载Applet</p>
</jsp:fallback>
</jsp:plugin>
request对象是HttpServletRequest类的实例,相当于Servlet的service()方法中传递进来的HttpServletRequest参数。通过该对象JSP可以获得或设置请求相关属性,例如:通过getParameter()方法可以获得请求中的参数;通过getHeader()可以获得HTTP请求消息的头域等。
response对象是HttpServletResponse类的实例,相当于Servlet的service()方法中传递来的HttpServletResponse参数,通过该对象JSP可以获得或设置响应相关的属性,以及向响应中添加内容,例如:通过setHeader()方法向响应消息中设置HTTP头域,通过sendRedirect()方法向客户端发出重定向消息等。
config对象是ServletConfig类的实例,相当于使用Servlet.getServletConfig()方法获得的对象。通过该对象JSP可以获得或设置当前JSP页面所表示Servlet的属性。具体的方法可参见Servlet中关于ServletConfig类的介绍。
application对象是ServletContext类的实例,相当于Servlet中使用Servlet.getServlet Config().getServletContext()获得的对象。通过该对象JSP可以获得或设置与当前Web应用相关的属性。具体的方法可参见Servlet中关于ServletContext类的介绍。
out对象是JspWriter对象的实例。它表示向响应消息中输出字符内容的输出流。JspWriter是一个抽象类,其定义如下:
package javax.servlet.jsp;
import java.io.IOException;
import java.io.Writer;
public abstract class JspWriter extends Writer
{
protected JspWriter(int bufferSize, boolean autoFlush)
{
this.bufferSize = bufferSize;
this.autoFlush = autoFlush;
}
public abstract void newLine()
throws IOException;
public abstract void print(boolean flag)
throws IOException;
public abstract void print(char c)
throws IOException;
public abstract void print(int i)
throws IOException;
public abstract void print(long l)
throws IOException;
public abstract void print(float f)
throws IOException;
public abstract void print(double d)
throws IOException;
public abstract void print(char ac[])
throws IOException;
public abstract void print(String s)
throws IOException;
public abstract void print(Object obj)
throws IOException;
public abstract void println()
throws IOException;
public abstract void println(boolean flag)
throws IOException;
public abstract void println(char c)
throws IOException;
public abstract void println(int i)
throws IOException;
public abstract void println(long l)
throws IOException;
public abstract void println(float f)
throws IOException;
public abstract void println(double d)
throws IOException;
public abstract void println(char ac[])
throws IOException;
public abstract void println(String s)
throws IOException;
public abstract void println(Object obj)
throws IOException;
public abstract void clear()
throws IOException;
public abstract void clearBuffer()
throws IOException;
public abstract void flush()
throws IOException;
public abstract void close()
throws IOException;
public int getBufferSize()
{
return bufferSize;
}
public abstract int getRemaining();
public boolean isAutoFlush()
{
return autoFlush;
}
public static final int NO_BUFFER = 0;
public static final int DEFAULT_BUFFER = -1;
public static final int UNBOUNDED_BUFFER = -2;
protected int bufferSize;
protected boolean autoFlush;
}
其中:
print():向输出流中写入数据,该方法接受多种类型的参数。
println():该方法与print()方法类似,只是在写入数据后再写入一个回车符。这里需要注意的是,这个回车符是指在HTML文件中写入回车符,由于HTML文件中的回车符只是用于显示格式而不会最终体现到页面上,所以如果程序员希望在最终的页面上添加回车符,应该使用:print(“<BR>”)或println(“<BR>”)。
clear():清除输出缓冲区中的所有数据。如果清除时缓冲区中的数据已经被发出到客户端了,则该方法会抛出一个IOException异常,因为已经将不应该发送给客户端的数据发出。
clearBuffer():清除输出缓冲区中当前的数据,与clear()方法不同的是,即使数据已经被发出了该方法也不会抛出异常。
flush():刷新输出缓冲区中的数据,将输出缓冲区中的数据立即发送给客户端。如果允许自动刷新,当缓冲区满时该方法会被自动调用。
close():关闭当前输出流,在关闭之前刷新缓冲区。
getBufferSize():返回该对象使用的缓冲区大小。
getRemaining():返回缓冲区中尚未使用的字节数。
isAutoFlush():返回该对象是否自动刷新。
在上面列出的隐含对象对照表中将page对象的类型列为Object。在一个特定的系统中,使用Object对象的目的主要有两种:一是该对象不明确表示某种类型的对象,也不需要明确表示为某种类型的对象;二是该对象在具体的环境中可能会表示不同种类型的对象。此处的page对象属于第二类,它在不同的JSP文件中表示的类型不一样,但是属于同一类型的子类型。
page对象代表JSP文件本身,具体来说就是代表JSP所转换成Servlet的对象,由于不同的JSP文件转换成为Servlet的类型不一样(类名根据JSP文件的名称而定,例如test.jsp的类名为test_jsp),所以该page对象在不同的JSP文件中所具有的类型也不一样。
在test.jsp中打印page对象的类型如下例所示:
示例9.6 test.jsp
<%@ page language="java" pageEncoding="GB2312" %>
<%@ page contentType="text/html; charset=GB2312" %>
<html>
<head>
<title>Test</title>
</head>
<body>
<%= page.toString() %>
</body>
</html>
访问该页面,得到运行结果如图9.8所示。
图9.8 在页面中打印page对象
因为test.jsp被转换成Servlet后,Servlet的类名为test_jsp,而且在包org.apache.jsp中,所以此处输出了page对象所代表的类,以及代表page对象的一个数字。
查看以前任何一个从JSP文件转换而成的java文件,或者打开test.jsp转换成的java文件,可以发现其中都有关于page的定义,如下:
Object page = this;
即将page对象定义为当前对象。
在JSP文件中,开发人员可以将page对象造型为Servlet对象,然后就可以将page对象当成当前Servlet的对象进行使用,进而可以使用Servlet接口中定义的所有方法,获得Servlet相关的信息。例如:
示例9.7
<%@ page language="java" pageEncoding="GB2312" %>
<html>
<head>
<title>Test</title>
</head>
<body>
<% Servlet s = (Servlet)page; %>
<%= s.getServletConfig().getServletContext().getServletContextName() %>
</body>
</html>
获得页面内容如图9.9所示。
图9.9 在页面中打印ServletContextName
将page对象造型成Servlet后,就可以在JSP页面中调用Servlet的方法,包括通过Servlet获得ServletConfig(相当于config隐含对象)和ServletContext对象(相当于application隐含对象)。
这里的session对象与HTTP协议中定义的Session一一对应,它表示客户端与Web服务器的一次会话过程;通过session对象,JSP页面可以获取这次会话相关的Session信息。在同一段时间内,与服务器交互的一个客户端只有一个session对象,session对象由服务器创建并管理;当客户端第一次访问服务器时对应的session对象就被创建,并且将该session对象与该客户端一一对应;往后同一客户端在访问服务器时,同一session对象将会与之关联。
通过session对象,开发人员可以获得服务器与某一客户端本次会话的相关信息,并且可以设置和获取session作用域内的属性。session是HttpSession的对象,HttpSession的定义和使用已在第8章做了介绍。
Java通过try/catch语句和Exception类体系提供了比较完善的异常处理机制。JSP文件最终被转换为Java文件,所以在JSP文件中当然也可以使用Java固有的异常处理机制。除此之外,JSP还提供了一种更宏观的异常处理机制,那就是errorPage。
在前面介绍page指令时,讲到page指令中有两个与errorPage相关的属性:errorPage和isErrorPage。其中errorPage指定了一个错误处理页面,假如当前页面中出现了JSP错误那么请求就会转向这个错误处理页面;isErrorPage指定当前页面是否是错误处理页面,假如当前页面是错误处理页面,那么当前页面就可以访问exception对象,并且通过分析exception对象对各种异常进行处理。这种异常处理机制将对异常的处理集中到一个页面,更加提高了代码的抽象度,更便于系统的维护。这种异常处理的逻辑如图9.10所示:
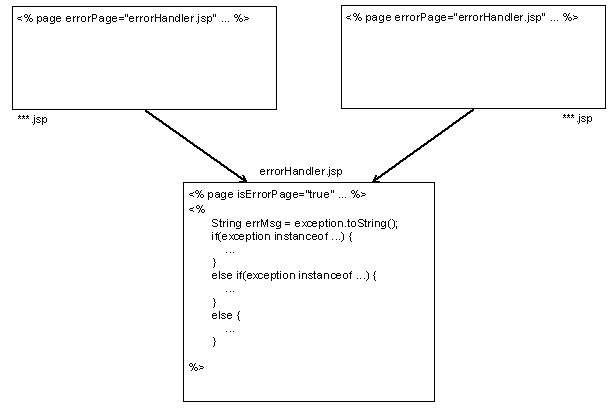
图9.10 JSP异常处理示意图
exception是标准的Exception类的对象,其方法和使用可参见Exception类的相关资料或Java文档。
假如某个JSP页面配置了errorPage属性,例如errorPage="errorHandler.jsp",那么转换成的Java文件中会有:
pageContext = _jspxFactory.getPageContext(this, request, response, "errorHandler.jsp", true, 8192, true);
其中的errorHandler.jsp是以参数的形式传递给了pageContext对象,然后将pageContext对象赋值给_jspx_page_context对象:
_jspx_page_context = pageContext;
最后在做异常处理时使用:
_jspx_page_context.handlePageException(t);
在该方法中,请求会被重定向到errorHandler.jsp,并且会将异常对象传递给该页面。
PageContext对象是PageContext类的实例。该对象是JSP页面各个对象和方法的门面对象,它提供了:
(1)获得JSP页面中各隐含对象的公有方法;
(2)方便地进行各种与当前页面相关的操作。
PageContext是个抽象类,其定义如下:
package javax.servlet.jsp;
import java.io.IOException;
import javax.servlet.*;
import javax.servlet.http.HttpSession;
import javax.servlet.jsp.tagext.BodyContent;
public abstract class PageContext extends JspContext
{
public PageContext()
{
}
public abstract void initialize(Servlet servlet, ServletRequest servletrequest, ServletResponse servletresponse, String s, boolean flag, int i, boolean flag1)
throws IOException, IllegalStateException, IllegalArgumentException;
public abstract void release();
public abstract HttpSession getSession();
public abstract Object getPage();
public abstract ServletRequest getRequest();
public abstract ServletResponse getResponse();
public abstract Exception getException();
public abstract ServletConfig getServletConfig();
public abstract ServletContext getServletContext();
public abstract void forward(String s)
throws ServletException, IOException;
public abstract void include(String s)
throws ServletException, IOException;
public abstract void include(String s, boolean flag)
throws ServletException, IOException;
public abstract void handlePageException(Exception exception)
throws ServletException, IOException;
public abstract void handlePageException(Throwable throwable)
throws ServletException, IOException;
public BodyContent pushBody()
{
return null;
}
public ErrorData getErrorData()
{
return new ErrorData((Throwable)getRequest().getAttribute("javax.servlet.error.exception"), ((Integer) getRequest().getAttribute("javax.servlet.error.status_code")).intValue(), (String)getRequest().getAttribute("javax.servlet.error.request_uri"), (String)getRequest().getAttribute("javax.servlet.error.servlet_name"));
}
public static final int PAGE_SCOPE = 1;
public static final int REQUEST_SCOPE = 2;
public static final int SESSION_SCOPE = 3;
public static final int APPLICATION_SCOPE = 4;
public static final String PAGE = "javax.servlet.jsp.jspPage";
public static final String PAGECONTEXT = "javax.servlet.jsp.jspPageContext";
public static final String REQUEST = "javax.servlet.jsp.jspRequest";
public static final String RESPONSE = "javax.servlet.jsp.jspResponse";
public static final String CONFIG = "javax.servlet.jsp.jspConfig";
public static final String SESSION = "javax.servlet.jsp.jspSession";
public static final String OUT = "javax.servlet.jsp.jspOut";
public static final String APPLICATION = "javax.servlet.jsp.jspApplication";
public static final String EXCEPTION = "javax.servlet.jsp.jspException";
}
其中:
initialize(Servlet servlet, ServletRequest servletrequest, ServletResponse servletresponse, String s, boolean flag, int i, boolean flag1):对该PageContext对象进行初始化。因为PageContext的构造函数是无参数构造函数,所以PageContext的对象并没有被初始化,该方法将PageContext需要的参数传递给PageContext,并对PageContext对象进行初始化。该方法相当于JSP转化成的Servlet中的:
pageContext = _jspxFactory.getPageContext(this, request, response, "errorHandler.jsp", true, 8192, true);
并且其中参数的个数、顺序和含义均相同。
release():释放该PageContext对象。该方法对PageContext对象的内部状态进行重置,使该PageContext对象可以在initialize()后被重新使用。
getSession():获得session隐含对象。
getPage():获得page隐含对象。
getRequest():获得request隐含对象。
getResponse():获得response隐含对象。
getException():获得exception隐含对象。
getServletConfig():获得config隐含对象。
getServletContext():获得application隐含对象。
forward(String s):将请求前转到s指定的Web对象,其效果等同于<jsp:forward>标签。
include(String s):将s指定的Web对象包含到处理中,相当于该JSP页面向指定的Web对象发出请求,并且处理返回的响应。效果等同于<jsp:include>标签。
include(String s, boolean flag):除了起到上面方法的效果外,还提供了一个额外效果,即当flag为true时,该方法同时刷新输出缓冲区。
handlePageException(Exception exception):处理页面级的异常,即将参数提供的异常与请求一起转发给错误处理页面。
handlePageException(Throwable throwable):同上方法。
pushBody():返回一个新的BodyContent对象,保存当前out对象的内容。并且更新out属性的值。
getErrorData():返回一个ErrorData对象,在错误处理页面中该对象用于表示错误内容。在非错误处理页面中返回的对象是无意义的。
在JSP的这些隐含对象中,有四个对象都定义了类似的getAttribute()和setAttribute()方法。这四个对象都可以通过属性的名称设置和获取属性,但不同的是这四个对象设置的属性具有不同的作用域。这四个对象分别是:pageContext、request、session、application;分别代表四个作用域:页面、请求、会话、应用。
如果简单理解和记忆这几种作用域是非常低效的,而且很容易出错。其实,从本质上看,属性是针对对象进行设置的,调用某对象的setAttribute()方法是将某属性保存在该对象中,只有再次调用该对象的getAttribute()方法才能够获取此属性,调用其他对象的getAttribute()当然无法获取同一属性。所以,从本质上说,属性的作用域就是对象的作用域。在某个范围内如果使用的某个类的对象都是一个对象,那么该对象的作用域就是该范围,同时该范围也是对该对象设置的属性的作用域。图9.11示意了pageContext、request、session、application四种对象的作用域。
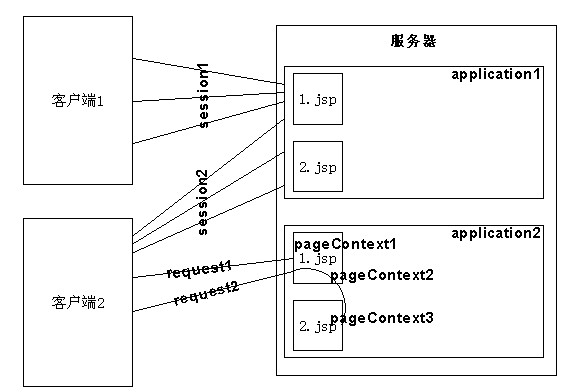
图9.11 四种对象作用域对比示意图
图9.11示意了四种对象的作用域。
application对象表示应用,在同一个应用中只有一个application对象,所以任何客户端的任何请求只要访问的是同一个application,那么访问的application对象就是一个,所以对application设置的属性也一样。在图9.11中,服务器中有两个应用:application1和application2。任何客户端访问application1中任何文件使用的application对象都是application1。
session对象表示会话,在同一个客户端访问同一个应用时(在Session超时时间内),只有一个session对象;而对于同一个应用来说,不同的客户端访问就会产生不同的session对象。如图9.11中,客户端1访问application1的session对象是session1,而客户端2访问application1的session对象是session2。
request对象表示一次客户端请求,无论请求从哪里来以及访问哪里,一次请求就会产生一个request对象。如图9.11中,客户端2向1.jsp发出两次请求,那么每次请求就会产生一个request对象,即使1.jsp将request2传递给了2.jsp,还是不会产生新request对象的。
pageContext对象表示一个页面对一次请求的处理。如图9.11中,客户端2通过request1访问1.jsp,1.jsp对request1进行处理就产生了pageContext1;客户端2通过request2访问1.jsp,1.jsp对request2进行处理就产生了pageContext2,进而1.jsp将request2传递给了2.jsp,2.jsp对request2进行处理就产生了pageContext3。
所以,通过9.11示意图可以发现,各个对象根据其代表意义的不同,其作用域也不同,所以对其进行设置的属性的作用域也不同。总的来说这四个对象的作用域从大到小依次为:application > session > request > pageContext。
从前面对JSP的介绍可以发现,JSP是基于标签的语法,所谓标签就是用尖括号“<”和“>”括起的一个标识符;通常标签都是成对出现的,有起始标签和结束标签,例如<tag> ... </tag>,但如果标签中没有包含其他任何内容,也可以将起始标签和结束标签合并为一个标签,例如<tag />;起始标签中还可以添加属性。
最基本的,JSP继承了HTML的标签集,并且在其基础上扩充了自己的标签集,例如9.2.6节中介绍的JSP预定义标签。除此之外,JSP还提供一种程序员自己开发标签并且在JSP页面中使用标签的途径。JSP预定义标签是以jsp为前缀、具有特定功能的系统预定义标签,这些可以直接在JSP页面中使用。除此之外,程序员可以自行开发具有特定功能的标签,将这些标签引入到应用中,然后就可以在JSP页面中使用。
通过开发和使用自定义标签,开发人员可以将功能开发和页面开发的工作分开,功能开发人员关注开发功能组件,页面开发人员关注页面设计并且将开发的标签组件直接在页面中使用。
自定义标签是JSP提供的一种自我扩展的方式,它允许开发人员自己定义标签以及标签的功能,然后在JSP页面中像预定义标签一样使用。
一个自定义标签在代码中就用一个javax.servlet.jsp.tagext.Tag表示,Tag中定义了标签的行为,当包含标签的JSP页面被转化为Servlet时,Servlet会在标签引用处调用Tag的相应方法进而实现标签的功能。
开发和使用一套自定义标签的步骤如下:
开发自定义标签类(或称自定义标签处理类);
定义一个标签定义文件(tld文件),在其中定义待使用的标签,并且将相应的标签处理类指定给标签;每个标签具有一个唯一的名称;
将标签定义文件在web.xml中使用taglib进行声明;
在需要使用标签的JSP页面中使用<%@ taglib uri="..." prefix="..." %>进行声明,然后再用指定的prefix和名称使用标签。
由此可以知道,在定义一个标签之前首先需要确定的是:标签的名称以及标签所需要进行的工作。
在JSP标签体系中根据标签的表现形式和功能定义了多种不同的标签层次和类别,每一个层次和类别都定义了一些标签所要进行的操作。JSP的标签都必须实现JspTag接口,这个接口是一个概念级别的接口,并没有定义任何实质的操作,因此基本上所有标签都实现自JspTag接口的子接口,Tag接口,这个接口定义了一些方法,它们表示标签在使用时与标签相关联的一些操作。同时JSP还实现了TagSupport类和BodyTagSupport,用于为Tag提供一些默认的实现,方便开发人员在此基础上进行开发。与标签相关的接口和类的层次结构如图9.12所示:
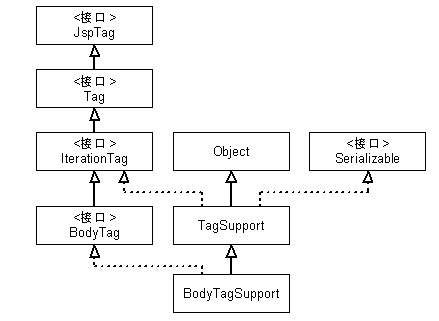
图9.12 与标签相关的接口和类的层次结构
从图9.12中可以发现,JSP标签的顶级接口是JspTag,Tag接口继承自JspTag,IterationTag接口继承自Tag,BodyTag继承自IterationTag;TagSupport和BodyTagSupport是两个实现类,TagSupport分别实现了IterationTag和Serializable,说明TagSupport的对象是一个JSP标签并且这个对象可以序列化;BodyTagSupport实现了BodyTag接口并且继承自TagSupport,说明BodyTagSupport肯定是一个TagSupport,而且它提供的功能比TagSupport要多,可以说BodyTagSupport是一个特殊的TagSupport。
【注意】
JSP自定义标签相关的接口和类都被封装在jsp-api.jar,它与servlet-api.jar一样,位于Tomcat根目录下的lib目录中。
1.JspTag
javax.servlet.jsp.tagext.JspTag接口表示一个概念上的JSP标签,它的定义如下:
package javax.servlet.jsp.tagext;
public interface JspTag {
}
该接口并没有定义任何方法,该接口的存在只是为了定义一个概念,它是所有其他JSP标签接口和类的根接口,它主要用于组织类结构和类型检查等目的。
2.Tag
javax.servlet.jsp.tagext.Tag接口表示一个具有明确起始位置和结束位置的JSP标签,该接口定义了一些方法,这些方法会在处理标签引用时被调用。它的定义如下:
package javax.servlet.jsp.tagext;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.PageContext;
public interface Tag extends JspTag {
public abstract void setPageContext(PageContext pagecontext);
public abstract void setParent(Tag tag);
public abstract Tag getParent();
public abstract int doStartTag() throws JspException;
public abstract int doEndTag() throws JspException;
public abstract void release();
public static final int SKIP_BODY = 0;
public static final int EVAL_BODY_INCLUDE = 1;
public static final int SKIP_PAGE = 5;
public static final int EVAL_PAGE = 6;
}
其中:
setPageContext(PageContext pagecontext):将JSP页面的PageContent对象设置到对象中,该方法通常由JSP容器调用。在Tag对象被初始化成功后,在调用其他任何处理方法之前被调用。
setParent(Tag tag):设置该Tag的父标签,也是有JSP容器调用。
getParent():返回该Tag的父标签。
doStartTag():在处理JSP页面时,在标签起始处调用的代码;该方法会返回标志EVAL_BODY_INCLUDE或SKIP_BODY,用于决定是继续处理标签(EVAL_BODY_INCLUDE)还是跳过该标签(SKIP_BODY)。
doEndTag():在处理JSP页面时,在标签结束处调用的代码;该代码会返回标志EVAL_PAGE或SKIP_PAGE,用于决定是继续处理页面剩下的内容(EVAL_PAGE)还是跳过页面剩下部分的处理(SKIP_PAGE)。
release():用于释放状态,在标签处理完成后会被JSP容器调用。
SKIP_BODY:标志位,表示跳过标签体的处理。
EVAL_BODY_INCLUDE:标志位,表示继续标签体的处理。
SKIP_PAGE:标志位,表示跳过页面剩余部分的处理。
EVAL_PAGE:标志位,表示继续页面剩余部分的处理。
从该接口定义的方法可以发现,该接口定义了一个标签处理器的框架,实现者需要在doStartTag()和doEndTag()中添加自己的代码,用于实现标签的功能。通过实现该接口子类可以实现一个对标签进行处理的最基本的能力。
3.IterationTag
javax.servlet.jsp.tagext.IterationTag继承自Tag,并且在Tag的基础上又增加了一个方法的定义。IterationTag是一个Tag并且增加了对Tag的处理,不仅提供了在标签开始和结束时方法,而且还提供了一个在处理方法体后执行的方法。定义如下:
package javax.servlet.jsp.tagext;
import javax.servlet.jsp.JspException;
public interface IterationTag extends Tag {
public abstract int doAfterBody() throws JspException;
public static final int EVAL_BODY_AGAIN = 2;
}
其中:
doAfterBody():在标签体运行完后执行的代码,该方法返回标志EVAL_BODY_AGAIN或SKIP_BODY,用于决定是再次运行标签体还是不再运行标签体而直接转向doEndTag()。
EVAL_BODY_AGAIN:标志位,表示再次运行标签体。
该接口提供了一种实现迭代标签的途径,在迭代标签中,标签体内的内容或代码可以以迭代的形式多次出现或执行。通过实现该接口子类可以实现一个具有迭代功能的标签。
4.BodyTag
javax.servlet.jsp.tagext.BodyTag继承自IterationTag接口,它在IterationTag的基础上又多定义了两个方法,提供了对标签体中内容进行操纵的支持。定义如下:
package javax.servlet.jsp.tagext;
import javax.servlet.jsp.JspException;
public interface BodyTag extends IterationTag
{
public abstract void setBodyContent(BodyContent bodycontent);
public abstract void doInitBody() throws JspException;
public static final int EVAL_BODY_TAG = 2;
public static final int EVAL_BODY_BUFFERED = 2;
}
其中:
setBodyContent(BodyContent bodycontent):设置一个BodyContent对象,该对象表示标签体中的内容;该方法由JSP容器进行调用,使得实现BodyTag的类可以操纵标签的内容;该方法先于doInitBody()被调用。
doInitBody():在处理标签时,该方法会在运行标签体之前被调用,用以为运行标签体做准备。
EVAL_BODY_BUFFERED:标志位,是BodyTag对Tag中定义的SKIP_BODY和EVAL_BODY_INCLUDE的扩展。当BodyTag的doStartTag()执行时,可以返回该标志位用于申请一个新的缓冲区,提供执行标签体时放置BodyContent。
EVAL_BODY_TAG:与EVAL_BODY_BUFFERED具有相同的值,这是以前使用的名字,现在已过期。
该接口的父接口更近了一步,它定义的标签可以对标签体中的内容进行操纵。通过实现这个接口子类可以实现一个可以对标签体中内容进行操纵的标签。
5.TagSupport
javax.servlet.jsp.tagext.TagSupport是一个具体的类,它实现了IterationTag,也就是说它是一个可迭代的标签。但TagSupport只是一个默认的实现,其实现并没有实质性的逻辑。TagSupport是为了方便程序员的开发而存在的,程序员在开发一个IterationTag时就可以直接从TagSupport继承而不需要从实现接口开始。该类的声明如下:
package javax.servlet.jsp.tagext;
import java.io.Serializable;
import java.util.Enumeration;
import java.util.Hashtable;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.PageContext;
public class TagSupport implements IterationTag, Serializable {
private Tag parent;
private Hashtable values;
protected String id;
protected PageContext pageContext;
public static final Tag findAncestorWithClass(Tag from, Class class);
public TagSupport();
public int doStartTag() throws JspException;
public int doEndTag() throws JspException;
public int doAfterBody() throws JspException;
public void release();
public void setParent(Tag t);
public Tag getParent();
public void setId(String id);
public String getId();
public void setPageContext(PageContext pageContext);
public void setValue(String k, Object o);
public Object getValue(String k);
public void removeValue(String k);
public Enumeration getValues();
}
其中:
parent:用于保存该标签的父标签。
values:一个属性表,其中通过键值对可以保存该Tag的属性,键是一个字符串,值是一个对象。
id:该标签id属性的值,或者是null。
pageContext:所在页面的PageContext对象。
findAncestorWithClass(Tag from, Class class):静态方法,该方法通过Tag接口的getParent()方法,从标签from开始一直寻找上级标签,直到寻找到第一个具有class类型的标签返回。
TagSupport():无参数构造方法,该方法体没有提供任何操作。
doStartTag():实现Tag接口的方法;TagSupport中的该方法直接返回SKIP_BODY,即默认实现将忽略标签。
doEndTag():实现Tag接口的方法;TagSupport中的该方法直接返回EVAL_PAGE,即继续对页面剩下的部分进行执行。所以,结合doStartTag()的实现,默认实现中TagSupport对标签不做任何处理,其效果相当于标签不存在。
doAfterBody():实现IterationTag接口的方法;TagSupport中的该方法直接返回SKIP_BODY,即任何时候都不重复执行标签体;其目的同前两个方法一样,就是效果等同于标签不存在。
release():实现Tag接口的方法;TagSupport中的该方法对自己的所有状态进行释放,恢复到初始状态,这包括:将parent设置为空,将id设置为空,清空values中的所有属性。
setParent(Tag t):实现Tag接口的方法;为TagSupport设置父标签,该方法只是将t设置给域变量parent。
getParent():实现Tag接口的方法;获得TagSupport的父标签,该方法只是返回域变量parent。
setId(String id):设置TagSupport的id,将参数id设置给域变量id。
getId():获得TagSupport的id,返回域变量id的值。
setPageContext(PageContext pageContext):实现Tag接口的方法;为TagSupport设置PageContext,该方法将参数pageContext设置给域变量pageContext。
setValue(String k, Object o):将键为k值为o的属性添加到values中。
getValue(String k):获得键为k的值。
removeValue(String k):删除键为k的属性。
getValues():获得一个Enumeration对象,其中包含所有属性的键;如果没有属性则返回空。
可见,TagSupport具备了一个IterationTag的概念,但并没有提供任何实质性的实现,如果单纯地将一个TagSupport实现的标签添加到JSP页面中,那么这个标签并不会有任何效果,其结果相当于没有添加任何标签。TagSupport的存在是为了方便开发人员,当开发人员需要开发一个IterationTag时,只需要继承TagSupport类并且重写其中的一些标签处理方法(doStartTag()、doEndTag()和doAfterBody());另外TagSupport还提供了一些方便的属性和操作,比如静态方法findAncestorWithClass(),开发人员可以在开发标签时直接调用该方法;TagSupport还为其子类提供了对id、属性和PageContext对象的管理。通过继承TagSupport开发新的标签可以使程序员只关注标签的业务逻辑。
6.BodyTagSupport
与TagSupport类似,javax.servlet.jsp.tagext.BodyTagSupport也是一个具体的类,它继承了TagSupport类,并且还另外实现了BodyTag接口,这使得BodyTagSupport具备了TagSupport的属性和处理能力,而且又增加了BodyTag的特性。该类的声明如下:
package javax.servlet.jsp.tagext;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.JspWriter;
public class BodyTagSupport extends TagSupport implements BodyTag {
protected BodyContent bodyContent;
public BodyTagSupport();
public int doStartTag() throws JspException;
public int doEndTag() throws JspException;
public void setBodyContent(BodyContent b);
public void doInitBody() throws JspException;
public int doAfterBody() throws JspException;
public void release();
public BodyContent getBodyContent();
public JspWriter getPreviousOut();
}
其中:
bodyContent:BodyContent的对象,通过setBodyContent()方法设置进来,可以在其他方法中使用,但不能在构造方法中使用,因为在构造方法中setBodyContent()方法还不可能被调用,所以bodyContent对象还是空。
BodyTagSupport():构造方法,同TagSupport一样,该类的构造方法体也为空。
doStartTag():覆盖TagSupport中的同名方法,不是返回SKIP_BODY,而是返回EVAL_BODY_BUFFERED,因为BodyTagSupport是一个BodyTag,所以返回该标志用于申请一个缓冲区。
doEndTag():覆盖TagSupport中的同名方法,但是这里还是返回了EVAL_PAGE,其用意与TagSupport也是一样的。
setBodyContent(BodyContent b):实现BodyTag的方法;将参数b设置给域变量bodyContent。
doInitBody():实现BodyTag的方法;方法体中并没有提供任何操作,对于该方法而言没有任何操作就是一种恰当的默认实现。
doAfterBody():覆盖TagSupport中的同名方法,但是这里还是返回了SKIP_BODY,默认实现。
release():覆盖TagSupport中的同名方法,在该方法中除了调用父类中的同名方法用于释放父类中的域,还要将bodyContent置为空。
getBodyContent():获得该标签的BodyContent对象,该方法中返回域变量bodyContent。
getPreviousOut():获得BodyContent所封装的JspWriter对象,通过该对象可以向BodyContent中写入内容。
BodyTagSupport是在TagSupport的基础上又添加了对BodyTag接口的默认实现。BodyTagSupport与TagSupport的区别主要是在处理标签时是否需要与标签体进行交互,如果不需要交互就用TagSupport,如果需要交互就要用BodyTagSupport。或者可以反过来说,如果开发人员想开发一个需要标签体交互的标签就用BodyTagSupport,否则就用TagSupport。这里所谓的交互就是处理标签时是否要读取标签体的内容或改变标签体的内容。由于BodyTagSupport是TagSupport的子类,所以所有用TagSupport实现的标签也可以用BodyTagSupport来实现,只是将BodyTagSupport实现BodyTag接口的方法保持为默认实现即可。但是,还是建议读者对于不需要交互的标签使用TagSupport实现,因为这样会避免多余的操作。
7.BodyContent
在实现了BodyTag的类中,包括BodyTagSupport。BodyContent是一个非常重要的结构,在需要和标签内容进行交互的标签中,BodyContent就是BodyTag子类与所处理标签内容进行交互的媒介;BodyTag子类通过BodyContent类的方法对标签的内容进行获取、写入、清空等操作。
BodyContent实质上是一个对JspWriter的封装,它对向JSP页面内容进行写入的Writer封装起来并且向外提供一个JspWriter的接口。在BodyContent的实现中,它保持了一个缓冲,在外部调用其写入方法时写入的内容会被放入BodyContent的缓冲中;同时BodyContent还提供了读取方法,读取方法会返回一个读取缓冲区内容的Reader;清空内容的方法会将缓冲中的内容清空。
一个标签的内容就是一个BodyContent对象,嵌套标签会产生BodyContent对象之间的相互包含;BodyContent的初始内容是标签中本来已有的内容,在对标签进行处理时可以读取、写入和清空这些内容,标签中的最终的内容就是标签处理完后BodyContent的内容。
这里需要注意的是,BodyContent的内容是JSP原始内容的执行结果而非原始内容。例如:
<tag>
<% out.print(“Hello”) %>
</tag>
在处理tag标签时,BodyContent的内容是“Hello”而不是“<% out.print(“Hello”) %>”。
BodyContent类的声明如下:
package javax.servlet.jsp.tagext;
import java.io.*;
import javax.servlet.jsp.JspWriter;
public abstract class BodyContent extends JspWriter {
private JspWriter enclosingWriter;
protected BodyContent(JspWriter e);
public void flush() throws IOException;
public void clearBody();
public abstract Reader getReader();
public abstract String getString();
public abstract void writeOut(Writer writer) throws IOException;
public JspWriter getEnclosingWriter();
}
其中:
enclosingWriter:JspWriter的对象,是BodyContent对象封装的JspWriter;
BodyContent(JspWriter e):构造函数,将e传递给封装的enclosingWriter;
flush():实现了JspWriter的flush()方法,在BodyContent中该方法被声明为无效方法,因为对BodyContent调用该方法没有意义,所以在使用BodyContent时不要调用flush()方法;
clearBody():清空BodyContent的内容;
getReader():获得读取BodyContent内容的Reader;
getString():将BodyContent的内容作为字符串返回;
writeOut(Writer writer):将BodyContent的内容写入到指定的writer;
getEnclosingWriter():返回被BodyContent封装的JspWriter,即返回enclosingWriter对象。
BodyContent类是一个抽象类,其中的getReader()、getString()、writeOut()都没有提供具体的实现,它们的实现由软件提供商实现,但方法的作用和意义是不会改变的。作为开发Web应用的开发人员,应该针对BodyContent提供的接口进行编程。
8.标签处理流程
在前面介绍了三种标签接口:Tag、IterationTag和BodyTag,它们分别定义了一些方法,这些方法分别在标签处理过程中的不同时间点被调用,而且某些方法是否被调用以及调用的次数还可能取决于前面方法返回的结果。这些方法包括:Tag接口的doStartTag()方法和doEndTag()方法、IterationTag的doAfterBody()、BodyTag的setBodyContent()和doInitBody();返回值包括:EVAL_BODY、SKIP_BODY、EVAL_BODY_AGAIN、EVAL_BODY_BUFFERED。
下面我们分别针对不同类型标签的处理过程,详细介绍各个方法被调用的状态转换图。
IterationTag继承Tag,BodyTag又继承IterationTag,所以某个类对这几个接口的实现可能存在如下几种情况:
Tag:实现类只实现了Tag标签。对于这种情况而言所实现的标签是一个不可迭代而且不需要与内容进行交互的标签。所以,它的处理方法只有doStartTag()和doEndTag()。执行的流程图如图9.13所示。
如图9.13所示,Tag子类的在被创建以后,首先会通过setPageContext()、setParent()、setId()等方法将Tag的初始信息传递给Tag;然后在处理到标签开始处时调用doStartTag()方法,根据方法的返回值确定是否要继续执行标签体内的内容;在标签结束处调用doEndTag()方法,根据方法的返回值确定是否继续处理页面的剩余部分。
IterationTag:实现类实现了IterationTag,那实现类也自动实现了Tag接口。这说明所实现的标签是一个可迭代但无需与标签体进行交互的标签。该类中的处理方法会增加一个doAfterTag()方法。处理的流程图如图9.14所示:
如图9.14所示,IterationTag的执行流程图是在Tag执行流程图的基础上添加了对doAfterTag()方法的调用和判断,添加了对标签体中内容的多次执行逻辑。
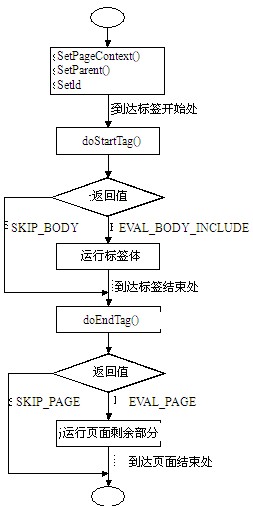
图9.13 Tag子类执行流程图
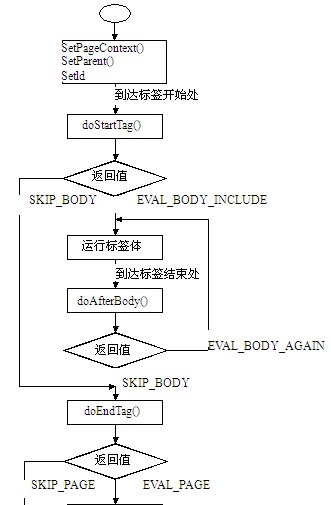
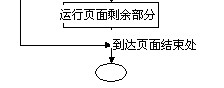
图9.14 IterationTag子类执行流程图
BodyTag:实现类实现了BodyTag,也就自动实现了Tag和IterationTag。这说明实现的标签是一个可迭代而且需要与标签内容进行交互的标签。这种标签又在IterationTag的基础上增加了setBodyContent()方法和doInitBody()方法,而且在实现类的其他方法中还可以引用BodyContent对象对标签的内容进行操纵。处理的流程图如图9.15所示:
从图9.15可以发现,与IterationTag对Tag的扩展类似,BodyTag也在doStartTag()与doEngTag()之间对Tag进行了扩展。BodyContent是通过setBodyContent()方法被设置到类中的,所以在BodyContent对象只有在setBodyContent()方法调用后才能被使用,从流程图中可以很容易地发现,在doStartTag()被执行时BodyContent还没有被赋值,因此是不能使用的;而在doInitBody()、doAfterBody()和doEndTag()中就可以使用。
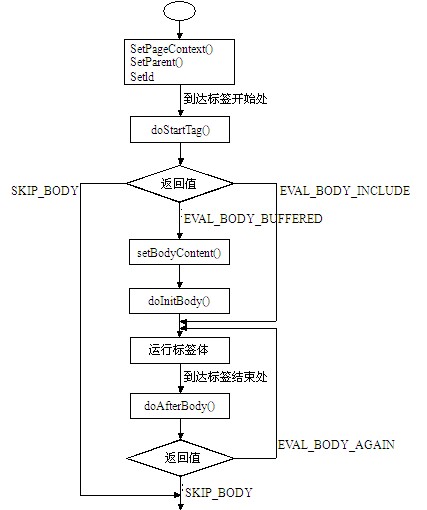
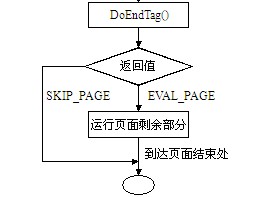
图9.15 BodyTag子类执行流程图
从前面对JSP标签体系的介绍可以发现,在JSP中标签根据其功能分为三个级别:Tag、IterationTag和BodyTag。从本小节开始的以下三个小节将分别举例介绍这三个级别标签的开发。本小节首先介绍Tag级别的标签。
Tag标签是只实现了Tag接口而没有实现IterationTag和BodyTag接口的标签。Tag标签只定义了标签的起始和结束,并分别在标签的起始和结束处调用接口的方法对标签进行处理。下面针对一种特定的标签使用场景开发一个Tag标签。
1.标签使用场景
假设在开发的系统中要添加一种日志功能:要求为每个JSP页面添加访问日志,在JSP页面被访问时在Tomcat的日志文件中记录一条日志,包括日志内容访问时间以及在访问该JSP页面的客户端主机名。
关于日志功能,我们在第8.7.3节中已经介绍了如何用ServletContext对象记录日志。完成这个功能可以通过在JSP页面中添加一个代码块,在代码块中获取ServletContext对象进行日志记录;日志功能本身会记录当前时间,客户端主机名可以通过ServletRequest的getRemoteHost()方法获得。开发的test.jsp如下:
test.jsp
<%@ page language="java" contentType="text/html; charset=ISO-8859-1"
pageEncoding="ISO-8859-1"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<%
String host = request.getRemoteHost();
config.getServletContext().log("test.jsp: " + host);
%>
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<title>Insert title here</title>
</head>
<body>
...
</body>
</html>
在该test.jsp中添加一块Java代码块,获得host后,将JSP文件名和host一同写入日志,日志内容如下:
Jun 23, 2008 4:05:10 PM org.apache.catalina.core.ApplicationContext log
INFO: test.jsp: 127.0.0.1
如果在所有JSP页面中都添加这么一段代码来实现日志功能,那将会很烦琐而且还很容易出错。所以,希望开发一个通用标签,在JSP页面中只需要将这个标签添加到页面中就可以完成同样的日志功能,使用格式如下:
<mytag:loghost jspfile="test.jsp"/>
2.开发标签
前面已经将标签的功能描述得非常清楚,可以发现该标签不需要迭代处理也不需要与标签内容进行交互,所以只需要实现Tag接口即可。具体的实现如下:
package cn.csai.web.jsp;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.PageContext;
import javax.servlet.jsp.tagext.Tag;
public class LogTag implements Tag {
private PageContext context;
private String fileName;
public int doEndTag() throws JspException {
String host = context.getRequest().getRemoteHost();
context.getServletContext().log(fileName + ": " + host);
return EVAL_PAGE;
}
public int doStartTag() throws JspException {
return EVAL_BODY_INCLUDE;
}
public Tag getParent() {
return null;
}
public void release() {
}
public void setPageContext(PageContext arg0) {
context = arg0;
}
public void setParent(Tag arg0) {
}
public void setJspfile(String jspFile) {
this.fileName = jspFile;
}
}
实现Tag接口必须实现它的所有方法,但这里只需要为doStartTag()和doEndTag()方法添加适当的内容即可。另外,由于该标签还有一个jspfile的属性,所以还必须为其提供一个setter方法。
doStartTag():该方法是在遇到标签起始位置时被调用的。在该标签的实现中我们将实现日志功能的代码放到标签结束位置,所以该方法不需要提供任何实现代码,直接返回即可。由于该标签不支持标签中包含的任何内容,所以此处返回SKIP_BODY和EVAL_BODY_INCLUDE都不影响标签功能的实现。
doEndTag():该实现没有在doStartTag()中添加功能代码,而是选择在doEndTag()中实现标签的功能,所以该方法中就必须实现日志功能。具体的实现代码与在JSP中添加Java代码块实现的代码类似。最后,返回EVAL_PAGE让JSP继续对页面其他内容进行解析,保证添加该标签后不影响页面其他内容的正常处理。
setJspfile():由于该标签中包含了一个jspfile的属性用于指定记录日志的JSP文件的文件名,以便于在日志中包含JSP文件名。JSP的实现规定,标签的实现必须为标签的每个属性定义一个setter方法,而且setter方法的方法名也应该符合命名规范:set + 属性名(首字母变大写)。例如jspfile属性的setter方法就是setJspfile()。这个方法名是大小写敏感的,所以在实现时要注意方法名中字母的大小写。即使将setJspfile()写成setJspFile()也会导致错误。但是,在实现类中所定义的对应属性的名称没有任何限制,例如本实现中的fileName也是可以的。
在该实现中将标签功能的实现放在了doEndTag()中。其实对于该标签来说,由于它的标签体中不会包含任何内容,所以将标签功能的实现放在doStartTag()或doEndTag()中都是可行的。将标签功能放在doStartTag()方法中实现,并且让doStartTag()方法返回SKIP_BODY的实现如下:
package cn.csai.web.jsp;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.PageContext;
import javax.servlet.jsp.tagext.Tag;
public class LogTag implements Tag {
private PageContext context;
private String fileName;
public int doEndTag() throws JspException {
return EVAL_PAGE;
}
public int doStartTag() throws JspException {
String host = context.getRequest().getRemoteHost();
context.getServletContext().log(fileName + ": " + host);
return SKIP_BODY;
}
public Tag getParent() {
return null;
}
public void release() {
}
public void setPageContext(PageContext arg0) {
context = arg0;
}
public void setParent(Tag arg0) {
}
public void setJspfile(String jspFile) {
this.fileName = jspFile;
}
}
这个实现所获得的效果与上一个实现相同。
这两个实现都是直接从实现Tag接口开始的,这会使得这其中的许多方法都显得很多余,比如:getParent()、release()、setParent(Tag)方法。为了避免这个问题,也可以通过继承TagSupport类来实现标签,虽然这个标签实现了IterationTag接口,但正如前面提到的,TagSupport对IterationTag中定义方法的默认实现并不会对标签产生任何附加的影响。所以如果通过继承TagSupport类来实现一个不可迭代的标签,只需要不对TagSupport的doAfterBody()方法提供覆盖实现即可。这样,开发人员只需要实现自己关心的方法,而不用在实现类中列举多余的方法实现。通过继承TagSupport实现LogTag的代码如下:
package cn.csai.web.jsp;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.tagext.TagSupport;
public class LogTag extends TagSupport {
private String fileName;
public int doEndTag() throws JspException {
String host = pageContext.getRequest().getRemoteHost();
pageContext.getServletContext().log(fileName + ": " + host);
return EVAL_PAGE;
}
public int doStartTag() throws JspException {
return EVAL_BODY_INCLUDE;
}
public void setJspfile(String jspFile) {
this.fileName = jspFile;
}
}
3.配置和使用标签
完成了标签类的开发并不能直接在JSP页面中使用标签,因为Tomcat服务器并不知道标签类的存在,也并不知道标签的格式,所以必须要对标签进行定义并且将定义标签的标签库的声明添加到web.xml中。
在开发完标签类后,首先要将标签添加到一个标签库中,也可以自己创建一个新的标签库。
标签库通常是一个tld文件,其内容是一个XML文档,例如下面是一个自定义的标签文件的内容:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE taglib PUBLIC "-//Sun Microsystems, Inc.//DTD JSP Tag Library 1.1//EN" "http://java.sun.com /j2ee/dtds/web-jsptaglibrary_1_1.dtd">
<taglib>
<tlibversion>1.2</tlibversion>
<jspversion>1.1</jspversion>
<shortname>MyTag</shortname>
<uri>/mytag</uri>
<tag>
<name>log</name>
<tagclass>cn.csai.web.jsp.LogTag</tagclass>
<bodycontent>empty</bodycontent>
<attribute>
<name>jspfile</name>
<required>true</required>
</attribute>
</tag>
</taglib>
标签定义的XML文档的根元素是taglib,tlibversion是标签库格式的版本,jspversion是JSP标准的版本,shortname是为标签库定义的一个名称,uri是引用该标签库的URI。一个标签库可以定义多个标签,每个标签使用一个tag元素,tag元素的name子元素是标签的名称;tagclass子元素是实现该标签的类的全路径;bodycontent是指定该标签内容的形式,可以是tagdependent、JSP和empty,empty就表示该标签不应该包含有内容;attribute为该标签定义了该标签可能会包含的属性,name是属性的名称,required说明该属性是否是必须的。这个示例就是LogTag的标签定义。在定义文件中定义的属性要与标签实现类中定义的属性setter方法相一致,这里定义了多少的属性就需要在实现类中定义相同数量的setter方法,而且setter方法的名字要符合命名规范。
将该标签定义文件命名为MyTag.tld,将其放在Web应用的WEB_INF目录中。并且还需要在web.xml中添加对标签定义文件的引用:
<web-app ...>
<jsp-config>
<taglib>
<taglib-uri>/mytag</taglib-uri>
<taglib-location>/WEB-INF/MyTag.tld</taglib-location>
</taglib>
</jsp-config>
...
</web-app>
接下来就可以在JSP页面中使用自定义标签了,格式如下:
<%@ page language="java" contentType="text/html; charset=ISO-8859-1"
pageEncoding="ISO-8859-1"%>
<%@ taglib uri="/mytag" prefix="mytag"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<mytag:log jspfile="test.jsp" />
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<title>Insert title here</title>
</head>
<body>
...
</body>
</html>
在JSP页面中使用标签,首先要在JSP页面中通过taglib添加标签应用声明,taglib中的uri就对应web.xml中taglib-uri所指定的uri,prefix是开发人员自己定义的一个前缀,这里可以随意定义。
在使用标签时,标签名是taglib中声明的prefix加上标签在标签库中定义的名称,这里就是mytag:log。
对于Tomcat来说,它是一次性就将一个标签库引入进JSP页面中,而使用标签时一次只会使用一个标签,所以当有多个标签时,可以将多个标签定义到同一个标签库定义文件中,这样就可以通过一次引用而使用标签库中的所有标签。
将Web应用部署到Tomcat中后,访问test.jsp文件,然后查看Tomcat的日志文件就可以发现:在localhost当前日志的最后多了一条日志记录:
Jun 23, 2008 5:03:39 PM org.apache.catalina.core.ApplicationContext log
INFO: test.jsp: 127.0.0.1
4.标签处理的本质
在前面已经讲过,所有的JSP页面最终都会被转换为一个Servlet进行工作,所以只要查看JSP所转化的Servlet就可以明白自定义标签处理的本质。以上面使用LogTag的test.jsp为例,它转化的Servlet如下:
package org.apache.jsp;
import javax.servlet.*;
import javax.servlet.http.*;
import javax.servlet.jsp.*;
public final class test_jsp extends org.apache.jasper.runtime.HttpJspBase
implements org.apache.jasper.runtime.JspSourceDependent {
private static final JspFactory _jspxFactory = JspFactory.getDefaultFactory();
private static java.util.List _jspx_dependants;
static {
_jspx_dependants = new java.util.ArrayList(1);
_jspx_dependants.add("/WEB-INF/MyTag.tld");
}
private org.apache.jasper.runtime.TagHandlerPool _005fjspx_005ftagPool_005fmytag_005flog_ 005fjspfile_005fnobody;
private javax.el.ExpressionFactory _el_expressionfactory;
private org.apache.AnnotationProcessor _jsp_annotationprocessor;
public Object getDependants() {
return _jspx_dependants;
}
public void _jspInit() {
_005fjspx_005ftagPool_005fmytag_005flog_005fjspfile_005fnobody = org.apache.jasper. runtime.TagHandlerPool.getTagHandlerPool(getServletConfig());
_el_expressionfactory = _jspxFactory.getJspApplicationContext(getServletConfig().getServletContext()). getExpressionFactory();
_jsp_annotationprocessor = (org.apache.AnnotationProcessor) getServletConfig().getServletContext(). getAttribute(org.apache.AnnotationProcessor.class.getName());
}
public void _jspDestroy() {
_005fjspx_005ftagPool_005fmytag_005flog_005fjspfile_005fnobody.release();
}
public void _jspService(HttpServletRequest request, HttpServletResponse response)
throws java.io.IOException, ServletException {
PageContext pageContext = null;
HttpSession session = null;
ServletContext application = null;
ServletConfig config = null;
JspWriter out = null;
Object page = this;
JspWriter _jspx_out = null;
PageContext _jspx_page_context = null;
try {
response.setContentType("text/html; charset=ISO-8859-1");
pageContext = _jspxFactory.getPageContext(this, request, response,
null, true, 8192, true);
_jspx_page_context = pageContext;
application = pageContext.getServletContext();
config = pageContext.getServletConfig();
session = pageContext.getSession();
out = pageContext.getOut();
_jspx_out = out;
out.write("\r\n");
out.write("\n");
out.write("<!DOCTYPE html PUBLIC \"-//W3C//DTD HTML 4.01 Transitional//EN\" \"http://www.w3.org/ TR/html4/loose.dtd\">\n");
out.write("<html>\n");
out.write("<head>\r\n");
if (_jspx_meth_mytag_005flog_005f0(_jspx_page_context))
return;
out.write("\n");
out.write("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=ISO-8859-1\">\n");
out.write("<title>Insert title here</title>\n");
out.write("</head>\n");
out.write("<body>\n");
out.write("\n");
out.write("</body>\n");
out.write("</html>");
} catch (Throwable t) {
if (!(t instanceof SkipPageException)){
out = _jspx_out;
if (out != null && out.getBufferSize() != 0)
try { out.clearBuffer(); } catch (java.io.IOException e) {}
if (_jspx_page_context != null) _jspx_page_context.handlePageException(t);
}
} finally {
_jspxFactory.releasePageContext(_jspx_page_context);
}
}
private boolean _jspx_meth_mytag_005flog_005f0(PageContext _jspx_page_context)
throws Throwable {
PageContext pageContext = _jspx_page_context;
JspWriter out = _jspx_page_context.getOut();
cn.csai.web.jsp.LogTag _jspx_th_mytag_005flog_005f0 = (cn.csai.web.jsp.LogTag) _005fjspx_ 005ftagPool_005fmytag_005flog_005fjspfile_005fnobody.get(cn.csai.web.jsp.LogTag.class);
_jspx_th_mytag_005flog_005f0.setPageContext(_jspx_page_context);
_jspx_th_mytag_005flog_005f0.setParent(null);
_jspx_th_mytag_005flog_005f0.setJspfile("test.jsp");
int _jspx_eval_mytag_005flog_005f0 = _jspx_th_mytag_005flog_005f0.doStartTag();
if (_jspx_th_mytag_005flog_005f0.doEndTag() == javax.servlet.jsp.tagext.Tag.SKIP_PAGE) {
_005fjspx_005ftagPool_005fmytag_005flog_005fjspfile_005fnobody.reuse(_jspx_th_mytag_005flog_005f0);
return true;
}
_005fjspx_005ftagPool_005fmytag_005flog_005fjspfile_005fnobody.reuse(_jspx_th_mytag_005flog_005f0);
return false;
}
}
查看代码中的黑体部分。首先,Servlet中添加了一个TagHandlerPool类的对象,该对象专门用于处理自定义标签的转换。该对象在_jspInit()中被初始化,在_jspDestory()中被释放。
而对标签处理的核心代码都在_jspService()中,体现在如下这句:
if (_jspx_meth_mytag_005flog_005f0(_jspx_page_context))
return;
该句调用方法_jspx_meth_mytag_005flog_005f0(PageContext),并且判断返回值,如果返回值为true则返回_jspService()方法,终止对页面剩余部分的处理,否则继续执行代码剩下的部分。这就自然会与doEndTag()方法的两个返回值(SKIP_PAGE和EVAL_PAGE)联系起来。
_jspx_meth_mytag_005flog_005f0(PageContext)方法的定义就在类声明中,下面我们详细考察一下这个方法。这个方法接受一个PageContext对象作为参数,返回值是一个boolean变量。在方法中,首先以LogTag类为参数获得一个LogTag类的对象:
cn.csai.web.jsp.LogTag _jspx_th_mytag_005flog_005f0 =
(cn.csai.web.jsp.LogTag) _005fjspx_005ftagPool_005fmytag_005flog_005fjspfile_005fnobody
.get(cn.csai.web.jsp.LogTag.class);
然后分别调用LogTag对象的setPageContext()方法和setParent()方法,将PageContext对象和当前标签的父标签赋给LogTag对象。实质上这两个方法是Tag接口的方法。接下来调用LogTag的属性setter方法setJspfile(),将属性参数设置进LogTag。这些都是执行标签处理代码前的准备工作。
准备工作做完了以后就调用LogTag对象的doStartTag()方法和doEndTag()方法,并且判断doEndTag()方法的返回值;如果返回值为SKIP_PAGE则返回true,否则返回false。这恰恰应证了前面的猜测。
所以,对于含有自定义标签的JSP页面来说,它的处理就是在JSP页面转化而成的Servlet中添加了对标签处理类相关方法调用,并且将调用的返回值用于影响_jspService()方法的处理流程。
Tag标签是标签内容不可迭代执行的标签或者不包含标签内容的标签,多数用于实现功能比较单一的标签。而从IterationTag实现的标签会比Tag标签稍微复杂一些,它的标签内容可以迭代执行。下面我们用一个IterationTag的实例介绍IterationTag的开发。
1.标签使用场景
考虑如下的使用场景:在页面中经常需要让一段内容重复出现多次,例如重复打印一段文本。直接使用JSP代码块也可以实现这个功能,例如下面的test2.jsp在页面上连续输出三行Hello World:
test2.jsp
<%@ page language="java" contentType="text/html; charset=ISO-8859-1"
pageEncoding="ISO-8859-1"%>
<%@ taglib uri="/mytag" prefix="mytag"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<%for(int i=0;i<3;i++) { %>
Hello world!<br>
<%} %>
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<title>Insert title here</title>
</head>
<body>
</body>
</html>
页面显示如图9.16所示。
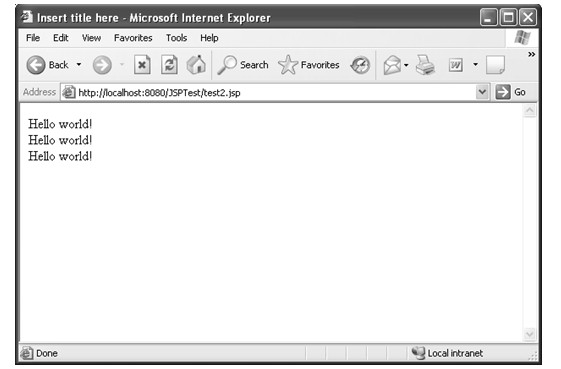
图9.16 test2.jsp页面效果
这种实现显然是可以达到目的的,但是由于需要在JSP页面中添加Java代码,就会使页面显得比较凌乱;假如需要重复的内容再复杂一些,就更容易出现错误。下面我们就介绍如何使用一个自定义标签来实现这个功能,使用方式如下:
<mytag:repeat times="3">
Hello world!<br>
</mytag:repeat>
其中,times表示要重复的次数,标签之间的内容就是要重复的内容。
2.开发标签
显而易见,该标签是需要进行迭代的标签,所以不能使用Tag接口,而使用IterationTag。TagSupport实现了IterationTag,所以这里就可以直接继承TagSupport来实现。实现的标签如下:
package cn.csai.web.jsp;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.tagext.TagSupport;
public class RepeatTag extends TagSupport {
private int counter = 0;
private int repeatTimes;
@Override
public int doAfterBody() throws JspException {
counter++;
if (skip())
return SKIP_BODY;
return EVAL_BODY_AGAIN;
}
@Override
public int doEndTag() throws JspException {
return EVAL_PAGE;
}
@Override
public int doStartTag() throws JspException {
if (skip())
return SKIP_BODY;
return EVAL_BODY_INCLUDE;
}
public void setTimes(String rep) {
try {
repeatTimes = Integer.parseInt(rep);
} catch (NumberFormatException e) {
repeatTimes = 0;
}
}
private boolean skip() {
if (counter >= repeatTimes) {
return true;
}
return false;
}
}
给该标签类取名为RepeatTag。该标签有一个参数times,用于说明内容需要重复的次数,所以在标签类中首先必须声明一个setter方法,setTimes()用于将times属性的值传递给域变量repeatTimes。在类中定义另一个域变量counter用于记录重复执行内容的次数,当counter大于等于repeatTimes时就退出重复执行内容的循环,所以实现了一个skip()方法用于判断是否该退出循环。
在doStartTag()方法中,首先判断是否该退出循环,这是因为如果指定的times小于等于0那就是不执行内容。所以如果在doStartTag()调用skip()时输出为true则返回SKIP_BODY,表示不执行内容;否则返回EVAL_BODY_INCLUDE便表示执行内容。
在doAfterBody()方法中,首先将counter自增1,因为执行到doAfterBody()方法时标签体已经执行了一遍了,然后再判断是否应该退出,如果不应该退出则返回EVAL_BODY_AGAIN再继续执行标签体,直到执行的次数达到为止,此时返回SKIP_BODY退出循环。
在doEndTag()方法中,不需要做其他操作,只要返回EVAL_PAGE保证页面剩余部分被正确解析。
3.配置和使用标签
无论是什么标签,配置都是类似的,都需要放在标签定义文件中。在第9.4.4节中已经定义了MyTag.tld,而且在其中定义了LogTag;现在开发的新的标签只需要在MyTag.tld中再添加RepeatTag的定义就可以了,如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE taglib PUBLIC "-//Sun Microsystems, Inc.//DTD JSP Tag Library 1.1//EN" "http://java.sun.com/j2ee /dtds/web-jsptaglibrary_1_1.dtd">
<taglib>
<tlibversion>1.2</tlibversion>
<jspversion>1.1</jspversion>
<shortname>MyTag</shortname>
<uri>/mytag</uri>
<tag>
<name>log</name>
<tagclass>cn.csai.web.jsp.LogTag</tagclass>
<bodycontent>empty</bodycontent>
<attribute>
<name>jspfile</name>
<required>true</required>
</attribute>
</tag>
<tag>
<name>repeat</name>
<tagclass>cn.csai.web.jsp.RepeatTag</tagclass>
<bodycontent>JSP</bodycontent>
<attribute>
<name>times</name>
<required>true</required>
</attribute>
</tag>
</taglib>
只需要在taglib元素下再添加一个tag元素就可以了,tag元素中的声明含义不变,只是由于该标签是包含标签体内容的,所以bodycontent不能设为empty,而应该设为JSP。
在test2.jsp中使用RepeatTag的格式如下:
test2.jsp
<%@ page language="java" contentType="text/html; charset=ISO-8859-1"
pageEncoding="ISO-8859-1"%>
<%@ taglib uri="/mytag" prefix="mytag"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4 /loose.dtd">
<html>
<head>
<mytag:repeat times="3">
Hello world!<br>
</mytag:repeat>
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<title>Insert title here</title>
</head>
<body>
</body>
</html>
如其中黑体部分所示,其含义就是将“Hello world!<br>”输出3次,页面如图9.17所示:
图9.17 使用RepeatTag标签的test2.jsp页面效果
4.标签处理的本质
为了探究IterationTag标签处理的本质,我们对test2.jsp所转化的Servlet进行了研究,Servlet如下所示。
package org.apache.jsp;
import javax.servlet.*;
import javax.servlet.http.*;
import javax.servlet.jsp.*;
public final class test2_jsp extends org.apache.jasper.runtime.HttpJspBase
implements org.apache.jasper.runtime.JspSourceDependent {
private static final JspFactory _jspxFactory = JspFactory.getDefaultFactory();
private static java.util.List _jspx_dependants;
static {
_jspx_dependants = new java.util.ArrayList(1);
_jspx_dependants.add("/WEB-INF/MyTag.tld");
}
private org.apache.jasper.runtime.TagHandlerPool _005fjspx_005ftagPool_005fmytag_005frepeat_005ftimes;
private javax.el.ExpressionFactory _el_expressionfactory;
private org.apache.AnnotationProcessor _jsp_annotationprocessor;
public Object getDependants() {
return _jspx_dependants;
}
public void _jspInit() {
_005fjspx_005ftagPool_005fmytag_005frepeat_005ftimes = org.apache.jasper.runtime.TagHandlerPool. getTagHandlerPool(getServletConfig());
_el_expressionfactory = _jspxFactory.getJspApplicationContext(getServletConfig().getServletContext()). getExpressionFactory();
_jsp_annotationprocessor = (org.apache.AnnotationProcessor) getServletConfig().getServletContext(). getAttribute(org.apache.AnnotationProcessor.class.getName());
}
public void _jspDestroy() {
_005fjspx_005ftagPool_005fmytag_005frepeat_005ftimes.release();
}
public void _jspService(HttpServletRequest request, HttpServletResponse response)
throws java.io.IOException, ServletException {
PageContext pageContext = null;
HttpSession session = null;
ServletContext application = null;
ServletConfig config = null;
JspWriter out = null;
Object page = this;
JspWriter _jspx_out = null;
PageContext _jspx_page_context = null;
try {
response.setContentType("text/html; charset=ISO-8859-1");
pageContext = _jspxFactory.getPageContext(this, request, response,
null, true, 8192, true);
_jspx_page_context = pageContext;
application = pageContext.getServletContext();
config = pageContext.getServletConfig();
session = pageContext.getSession();
out = pageContext.getOut();
_jspx_out = out;
out.write("\r\n");
out.write("\n");
out.write("<!DOCTYPE html PUBLIC \"-//W3C//DTD HTML 4.01 Transitional//EN\" \"http://www.w3.org /TR/html4/loose.dtd\">\n");
out.write("<html>\n");
out.write("<head>\r\n");
if (_jspx_meth_mytag_005frepeat_005f0(_jspx_page_context))
return;
out.write("\n");
out.write("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=ISO-8859-1\">\n");
out.write("<title>Insert title here</title>\n");
out.write("</head>\n");
out.write("<body>\n");
out.write("\n");
out.write("</body>\n");
out.write("</html>");
} catch (Throwable t) {
if (!(t instanceof SkipPageException)){
out = _jspx_out;
if (out != null && out.getBufferSize() != 0)
try { out.clearBuffer(); } catch (java.io.IOException e) {}
if (_jspx_page_context != null) _jspx_page_context.handlePageException(t);
}
} finally {
_jspxFactory.releasePageContext(_jspx_page_context);
}
}
private boolean _jspx_meth_mytag_005frepeat_005f0(PageContext _jspx_page_context)
throws Throwable {
PageContext pageContext = _jspx_page_context;
JspWriter out = _jspx_page_context.getOut();
cn.csai.web.jsp.RepeatTag _jspx_th_mytag_005frepeat_005f0 = (cn.csai.web.jsp.RepeatTag) _005fjspx_ 005ftagPool_005fmytag_005frepeat_005ftimes.get(cn.csai.web.jsp.RepeatTag.class);
_jspx_th_mytag_005frepeat_005f0.setPageContext(_jspx_page_context);
_jspx_th_mytag_005frepeat_005f0.setParent(null);
_jspx_th_mytag_005frepeat_005f0.setTimes("3");
int _jspx_eval_mytag_005frepeat_005f0 = _jspx_th_mytag_005frepeat_005f0.doStartTag();
if (_jspx_eval_mytag_005frepeat_005f0 != javax.servlet.jsp.tagext.Tag.SKIP_BODY) {
do {
out.write("\r\n");
out.write("Hello world!<br>\r\n");
int evalDoAfterBody = _jspx_th_mytag_005frepeat_005f0.doAfterBody();
if (evalDoAfterBody != javax.servlet.jsp.tagext.BodyTag.EVAL_BODY_AGAIN)
break;
} while (true);
}
if (_jspx_th_mytag_005frepeat_005f0.doEndTag() == javax.servlet.jsp.tagext.Tag.SKIP_PAGE) {
_005fjspx_005ftagPool_005fmytag_005frepeat_005ftimes.reuse(_jspx_th_mytag_005frepeat_005f0);
return true;
}
_005fjspx_005ftagPool_005fmytag_005frepeat_005ftimes.reuse(_jspx_th_mytag_005frepeat_005f0);
return false;
}
}
从代码中可以发现,总体的结构与test.jsp的Servlet类似。只是标签处理函数有了一些变化,添加了一些处理代码。观察方法中的黑体部分,首先还是调用doStartTag()方法,如果doStartTag()返回值不等于SKIP_BODY则继续执行标签体。但这里处理标签体却是使用了一个do-while循环;首先输出标签体中的内容然后调用doAfterBody()方法,如果返回值不是EVAL_BODY_AGAIN则跳出循环,否则继续循环输出标签体。
BodyTag是在IterationTag的基础上又添加了与标签体中内容的交互。
1.标签使用场景
考虑下面的一种使用场景:希望在页面中显示一段文字,而且这段文字可以根据客户端浏览器的语言设置而动态变化,比如如果客户端浏览器使用的是英文语言设置则返回“Hello,××!”,如果客户端浏览器使用的是中文语言设置则返回“你好,××!”。
浏览器所使用的语言可以在浏览器的选项中进行设置,在IE的菜单Tools(工具)→Internet Options(Internet选项)...选项打开的窗口中的General(常规)页的下部有一个 Languages(语言)...按钮,如图9.18所示。
图9.18 Internet Options窗口
点击Languages...按钮打开Language Preference窗口,如图9.19所示。
图9.19 Language Preference窗口
可以通过Add...添加新的语言,通过Move Up和Move Down移动语言的上下顺序,在最上面的语言是最优选的语言。
另外在服务器端,在Servlet中,可以通过ServletRequest的getLocale()方法获得客户端所使用的语言,如图9.19中显示的两个语言设置分别是中文和英文,所对应的Locale就是Locale.Chinese和Locale.US,两个Locale的缩写代码分别是zh_CN和en_US。程序员可以通过为浏览器设置不同的Locale,然后测试开发的功能是否正确。
假设我们要开发一个JSP页面,页面根据客户端设置的不同Locale分别显示“你好,王先生!”和“Hello, Mr. Wang!”。
根据不同的Locale显示不同语言的字符串,这在Java中已经提供了支持。首先,为每个Locale创建一个资源properties文件,文件名包含Locale的缩写代码,例如MessageBundle_zh_CN.properties和MessageBundle_en_US.properties;这两个文件的文件名都是MessageBundle,但它们分别定义了针对中文和英文的两套资源文件。然后,在每个资源文件中为每一个需要进行多语言支持的字符串定义一个键值对,每个资源文件中的键名一样,但值分别用资源文件对应的语言进行表达,例如:
表9.2 不同资源文件中键值对的描述

同时,还可以定义一个默认的properties,即当客户端设置的既不是中文也不是英文时,就用默认的语言值,通常默认的与英文的一样,只是文件名不包含任何Locale的缩写,而直接是MessageBundle.properties。
定义完资源文件,然后实现一个类用于从资源文件中获取值,如下面的Message类:
package cn.csai.web.jsp;
import java.util.Locale;
import java.util.MissingResourceException;
import java.util.ResourceBundle;
public class Messages {
private static final String BUNDLE_NAME = "cn.csai.web.jsp.resource.MessageBundle";
private Messages() {
}
public static String getString(String key, Locale locale) {
try {
ResourceBundle bundle = ResourceBundle.getBundle(BUNDLE_NAME, locale);
return bundle.getString(key);
} catch (MissingResourceException e) {
return "";
}
}
}
该类定义了一个静态方法getString(),该方法接受一个String和一个Locale对象作为参数,表示取Locale属性文件中键为key的值。例如getString(“hello”, Locale.Chinese)就是“你好”,而getString(“mrWang”, Locale.US)就是Mr. Wang。
通过这一套体系就可以完成根据不同Locale获取不同语言的文字的功能。下面就关注于如何在JSP页面中添加这个功能。
假如不使用自定义标签,那么只能在页面中添加Java代码以实现这个功能:
test3.jsp
<%@ page language="java" contentType="text/html; charset=ISO-8859-1"
pageEncoding="ISO-8859-1"%>
<%@ page import="cn.csai.web.jsp.Messages, java.util.Locale" %>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<%
Locale locale = request.getLocale();
String s = Messages.getString("hello", locale) + ", " + Messages.getString("mrWang", locale) + "!";
%>
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<title>Insert title here</title>
</head>
<body>
<%= s %>
</body>
</html>
下面我们将介绍如何使用自定义标签的方式实现这个功能,以使这个功能能够被通用。
2.开发标签
根据该功能要求,需要开发一个可以根据客户端浏览器Locale设置输出多种语言的标签。设计标签的格式如下:
<mytag:locale>hello</mytag:locale>
标签的内容包含的是所需要输出消息的键。
由于该标签需要输出标签内容,所以首先可以肯定该标签必须是一个BodyTag标签,为了简单起见,继承BodyTagSupport来实现LocaleTag。标签的实现如下:
package cn.csai.web.jsp;
import java.io.IOException;
import java.util.Locale;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.tagext.BodyTagSupport;
public class LocaleTag extends BodyTagSupport {
@Override
public int doStartTag() throws JspException {
return EVAL_BODY_BUFFERED;
}
@Override
public int doEndTag() throws JspException {
String key = bodyContent.getString().trim();
Locale locale = pageContext.getRequest().getLocale();
String message = Messages.getString(key, locale);
try {
bodyContent.getEnclosingWriter().print(message);
} catch (IOException e) {
}
return SKIP_BODY;
}
}
标签不含任何属性,所以也不需要实现任何setter方法;在doStartTag()中,由于后期需要对标签内容进行处理,所以返回EVAL_BODY_BUFFERED;主要的代码集中在doEndTag()中,当标签处理结束后首先获得标签体中的内容,然后结合获取的Locale;接着通过Messages方法获取适当的消息值,然后通过bodyContent的输出对象输出到标签内容中。
3.配置和使用标签
与RepeatTag一样,LocaleTag可以定义在MyTag.tld中,如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE taglib PUBLIC "-//Sun Microsystems, Inc.//DTD JSP Tag Library 1.1//EN" "http://java.sun.com /j2ee/dtds/web-jsptaglibrary_1_1.dtd">
<taglib>
<tlibversion>1.2</tlibversion>
<jspversion>1.1</jspversion>
<shortname>MyTag</shortname>
<uri>/mytag</uri>
...
<tag>
<name>locale</name>
<tagclass>cn.csai.web.jsp.LocaleTag</tagclass>
<bodycontent>JSP</bodycontent>
</tag>
</taglib>
该标签实现后,具有根据所给出的key值从MessageBundle中获取与客户端Locale设置对应的消息的能力。在本应用中,需要向客户端输出“你好,王先生!”或“Hello, Mr. Wang!”,需要进行多语言支持的有四个元素,分别是:“你好”和“Hello”、“,”和“,”、“王先生”和“Mr. Wang”、“!”和“!”。所以,首先需要将这四个键值添加到MessageBundle属性文件中,如表9.3所示:
表9.3 资源文件内容配置

然后在test3.jsp中的使用如下:
<%@ page language="java" contentType="text/html; charset=ISO-8859-1"
pageEncoding="ISO-8859-1"%>
<%@ taglib uri="/mytag" prefix="mytag"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<mytag:locale>hello</mytag:locale>
<mytag:locale>dh</mytag:locale>
<mytag:locale>mrWang</mytag:locale>
<mytag:locale>th</mytag:locale>
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<title>Insert title here</title>
</head>
<body>
</body>
</html>
当把浏览器设为中文时,显示的页面如图9.20所示。
图9.20 中文Locale访问获得的test3.jsp页面
在显示中文时,可能会由于浏览器的编码识别问题产生乱码。如果出现乱码,只需要在菜单View(视图) → Encoding(编码)中选择合适的编码方式(GB2312或UTF-8)即可。
如果将浏览器设为英文,显示的页面如图9.21所示。
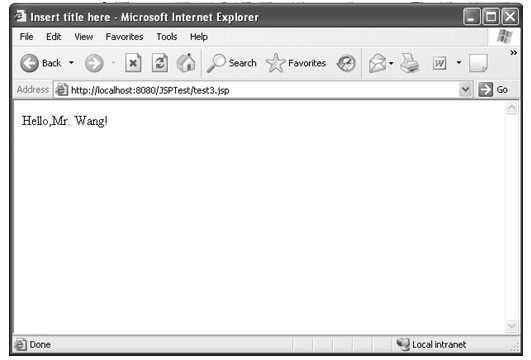
图9.21 英文Locale访问获得的test3.jsp页面
该例中为了使应用尽量通用化,所以将一个消息分解成了四段进行获取。实际上最简单的可以只用一个键值对(键名为message),在英文的properties文件中值设为“Hello,Mr.Wang!”,而在中文中设为“你好,王先生!”。这样在test3.jsp文件中只需要用一次mytag:locale标签就可以实现消息的多语言显示了。
4.标签处理的本质
test3.jsp转化的Servlet如下:
package org.apache.jsp;
import javax.servlet.*;
import javax.servlet.http.*;
import javax.servlet.jsp.*;
public final class test3_jsp extends org.apache.jasper.runtime.HttpJspBase
implements org.apache.jasper.runtime.JspSourceDependent {
private static final JspFactory _jspxFactory = JspFactory.getDefaultFactory();
private static java.util.List _jspx_dependants;
static {
_jspx_dependants = new java.util.ArrayList(1);
_jspx_dependants.add("/WEB-INF/MyTag.tld");
}
private org.apache.jasper.runtime.TagHandlerPool _005fjspx_005ftagPool_005fmytag_005flocale;
private javax.el.ExpressionFactory _el_expressionfactory;
private org.apache.AnnotationProcessor _jsp_annotationprocessor;
public Object getDependants() {
return _jspx_dependants;
}
public void _jspInit() {
_005fjspx_005ftagPool_005fmytag_005flocale = org.apache.jasper.runtime.TagHandlerPool.getTagHandler Pool(getServletConfig());
_el_expressionfactory = _jspxFactory.getJspApplicationContext(getServletConfig().getServletContext()). getExpressionFactory();
_jsp_annotationprocessor = (org.apache.AnnotationProcessor) getServletConfig().getServletContext(). getAttribute(org.apache.AnnotationProcessor.class.getName());
}
public void _jspDestroy() {
_005fjspx_005ftagPool_005fmytag_005flocale.release();
}
public void _jspService(HttpServletRequest request, HttpServletResponse response)
throws java.io.IOException, ServletException {
PageContext pageContext = null;
HttpSession session = null;
ServletContext application = null;
ServletConfig config = null;
JspWriter out = null;
Object page = this;
JspWriter _jspx_out = null;
PageContext _jspx_page_context = null;
try {
response.setContentType("text/html; charset=ISO-8859-1");
pageContext = _jspxFactory.getPageContext(this, request, response,
null, true, 8192, true);
_jspx_page_context = pageContext;
application = pageContext.getServletContext();
config = pageContext.getServletConfig();
session = pageContext.getSession();
out = pageContext.getOut();
_jspx_out = out;
out.write("\r\n");
out.write("\n");
out.write("<!DOCTYPE html PUBLIC \"-//W3C//DTD HTML 4.01 Transitional//EN\" \"http://www.w3. org/TR/html4/loose.dtd\">\n");
out.write("<html>\n");
out.write("<head>\r\n");
out.write("\r\n");
if (_jspx_meth_mytag_005flocale_005f0(_jspx_page_context))
return;
out.write('\r');
out.write('\n');
if (_jspx_meth_mytag_005flocale_005f1(_jspx_page_context))
return;
out.write('\r');
out.write('\n');
if (_jspx_meth_mytag_005flocale_005f2(_jspx_page_context))
return;
out.write('\r');
out.write('\n');
if (_jspx_meth_mytag_005flocale_005f3(_jspx_page_context))
return;
out.write("\r\n");
out.write("\r\n");
out.write("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=ISO-8859-1\">\n");
out.write("<title>Insert title here</title>\n");
out.write("</head>\n");
out.write("<body>\n");
out.write("\n");
out.write("</body>\n");
out.write("</html>");
} catch (Throwable t) {
if (!(t instanceof SkipPageException)){
out = _jspx_out;
if (out != null && out.getBufferSize() != 0)
try { out.clearBuffer(); } catch (java.io.IOException e) {}
if (_jspx_page_context != null) _jspx_page_context.handlePageException(t);
}
} finally {
_jspxFactory.releasePageContext(_jspx_page_context);
}
}
private boolean _jspx_meth_mytag_005flocale_005f0(PageContext _jspx_page_context)
throws Throwable {
PageContext pageContext = _jspx_page_context;
JspWriter out = _jspx_page_context.getOut();
cn.csai.web.jsp.LocaleTag _jspx_th_mytag_005flocale_005f0 = (cn.csai.web.jsp.LocaleTag) _005fjspx_ 005ftagPool_005fmytag_005flocale.get(cn.csai.web.jsp.LocaleTag.class);
_jspx_th_mytag_005flocale_005f0.setPageContext(_jspx_page_context);
_jspx_th_mytag_005flocale_005f0.setParent(null);
int _jspx_eval_mytag_005flocale_005f0 = _jspx_th_mytag_005flocale_005f0.doStartTag();
if (_jspx_eval_mytag_005flocale_005f0 != javax.servlet.jsp.tagext.Tag.SKIP_BODY) {
if (_jspx_eval_mytag_005flocale_005f0 != javax.servlet.jsp.tagext.Tag.EVAL_BODY_ INCLUDE) {
out = _jspx_page_context.pushBody();
_jspx_th_mytag_005flocale_005f0.setBodyContent((javax.servlet.jsp.tagext.BodyContent) out);
_jspx_th_mytag_005flocale_005f0.doInitBody();
}
do {
out.write("hello");
int evalDoAfterBody = _jspx_th_mytag_005flocale_005f0.doAfterBody();
if (evalDoAfterBody != javax.servlet.jsp.tagext.BodyTag.EVAL_BODY_AGAIN)
break;
} while (true);
if (_jspx_eval_mytag_005flocale_005f0 != javax.servlet.jsp.tagext.Tag.EVAL_BODY_INCLUDE) {
out = _jspx_page_context.popBody();
}
}
if (_jspx_th_mytag_005flocale_005f0.doEndTag() == javax.servlet.jsp.tagext.Tag.SKIP_PAGE) {
_005fjspx_005ftagPool_005fmytag_005flocale.reuse(_jspx_th_mytag_005flocale_005f0);
return true;
}
_005fjspx_005ftagPool_005fmytag_005flocale.reuse(_jspx_th_mytag_005flocale_005f0);
return false;
}
private boolean _jspx_meth_mytag_005flocale_005f1(PageContext _jspx_page_context)
throws Throwable {
PageContext pageContext = _jspx_page_context;
JspWriter out = _jspx_page_context.getOut();
cn.csai.web.jsp.LocaleTag _jspx_th_mytag_005flocale_005f1 = (cn.csai.web.jsp.LocaleTag) _005fjspx_ 005ftagPool_005fmytag_005flocale.get(cn.csai.web.jsp.LocaleTag.class);
_jspx_th_mytag_005flocale_005f1.setPageContext(_jspx_page_context);
_jspx_th_mytag_005flocale_005f1.setParent(null);
int _jspx_eval_mytag_005flocale_005f1 = _jspx_th_mytag_005flocale_005f1.doStartTag();
if (_jspx_eval_mytag_005flocale_005f1 != javax.servlet.jsp.tagext.Tag.SKIP_BODY) {
if (_jspx_eval_mytag_005flocale_005f1 != javax.servlet.jsp.tagext.Tag.EVAL_BODY_INCLUDE) {
out = _jspx_page_context.pushBody();
_jspx_th_mytag_005flocale_005f1.setBodyContent((javax.servlet.jsp.tagext.BodyContent) out);
_jspx_th_mytag_005flocale_005f1.doInitBody();
}
do {
out.write('d');
out.write('h');
int evalDoAfterBody = _jspx_th_mytag_005flocale_005f1.doAfterBody();
if (evalDoAfterBody != javax.servlet.jsp.tagext.BodyTag.EVAL_BODY_AGAIN)
break;
} while (true);
if (_jspx_eval_mytag_005flocale_005f1 != javax.servlet.jsp.tagext.Tag.EVAL_BODY_INCLUDE) {
out = _jspx_page_context.popBody();
}
}
if (_jspx_th_mytag_005flocale_005f1.doEndTag() == javax.servlet.jsp.tagext.Tag.SKIP_PAGE) {
_005fjspx_005ftagPool_005fmytag_005flocale.reuse(_jspx_th_mytag_005flocale_005f1);
return true;
}
_005fjspx_005ftagPool_005fmytag_005flocale.reuse(_jspx_th_mytag_005flocale_005f1);
return false;
}
private boolean _jspx_meth_mytag_005flocale_005f2(PageContext _jspx_page_context)
throws Throwable {
PageContext pageContext = _jspx_page_context;
JspWriter out = _jspx_page_context.getOut();
cn.csai.web.jsp.LocaleTag _jspx_th_mytag_005flocale_005f2 = (cn.csai.web.jsp.LocaleTag) _005fjspx_ 005ftagPool_005fmytag_005flocale.get(cn.csai.web.jsp.LocaleTag.class);
_jspx_th_mytag_005flocale_005f2.setPageContext(_jspx_page_context);
_jspx_th_mytag_005flocale_005f2.setParent(null);
int _jspx_eval_mytag_005flocale_005f2 = _jspx_th_mytag_005flocale_005f2.doStartTag();
if (_jspx_eval_mytag_005flocale_005f2 != javax.servlet.jsp.tagext.Tag.SKIP_BODY) {
if (_jspx_eval_mytag_005flocale_005f2 != javax.servlet.jsp.tagext.Tag.EVAL_BODY_INCLUDE) {
out = _jspx_page_context.pushBody();
_jspx_th_mytag_005flocale_005f2.setBodyContent((javax.servlet.jsp.tagext.BodyContent) out);
_jspx_th_mytag_005flocale_005f2.doInitBody();
}
do {
out.write("mrWang");
int evalDoAfterBody = _jspx_th_mytag_005flocale_005f2.doAfterBody();
if (evalDoAfterBody != javax.servlet.jsp.tagext.BodyTag.EVAL_BODY_AGAIN)
break;
} while (true);
if (_jspx_eval_mytag_005flocale_005f2 != javax.servlet.jsp.tagext.Tag.EVAL_BODY_INCLUDE) {
out = _jspx_page_context.popBody();
}
}
if (_jspx_th_mytag_005flocale_005f2.doEndTag() == javax.servlet.jsp.tagext.Tag.SKIP_PAGE) {
_005fjspx_005ftagPool_005fmytag_005flocale.reuse(_jspx_th_mytag_005flocale_005f2);
return true;
}
_005fjspx_005ftagPool_005fmytag_005flocale.reuse(_jspx_th_mytag_005flocale_005f2);
return false;
}
private boolean _jspx_meth_mytag_005flocale_005f3(PageContext _jspx_page_context)
throws Throwable {
PageContext pageContext = _jspx_page_context;
JspWriter out = _jspx_page_context.getOut();
cn.csai.web.jsp.LocaleTag _jspx_th_mytag_005flocale_005f3 = (cn.csai.web.jsp.LocaleTag) _005fjspx_ 005ftagPool_005fmytag_005flocale.get(cn.csai.web.jsp.LocaleTag.class);
_jspx_th_mytag_005flocale_005f3.setPageContext(_jspx_page_context);
_jspx_th_mytag_005flocale_005f3.setParent(null);
int _jspx_eval_mytag_005flocale_005f3 = _jspx_th_mytag_005flocale_005f3.doStartTag();
if (_jspx_eval_mytag_005flocale_005f3 != javax.servlet.jsp.tagext.Tag.SKIP_BODY) {
if (_jspx_eval_mytag_005flocale_005f3 != javax.servlet.jsp.tagext.Tag.EVAL_BODY_INCLUDE) {
out = _jspx_page_context.pushBody();
_jspx_th_mytag_005flocale_005f3.setBodyContent((javax.servlet.jsp.tagext.BodyContent) out);
_jspx_th_mytag_005flocale_005f3.doInitBody();
}
do {
out.write('t');
out.write('h');
int evalDoAfterBody = _jspx_th_mytag_005flocale_005f3.doAfterBody();
if (evalDoAfterBody != javax.servlet.jsp.tagext.BodyTag.EVAL_BODY_AGAIN)
break;
} while (true);
if (_jspx_eval_mytag_005flocale_005f3 != javax.servlet.jsp.tagext.Tag.EVAL_BODY_INCLUDE) {
out = _jspx_page_context.popBody();
}
}
if (_jspx_th_mytag_005flocale_005f3.doEndTag() == javax.servlet.jsp.tagext.Tag.SKIP_PAGE) {
_005fjspx_005ftagPool_005fmytag_005flocale.reuse(_jspx_th_mytag_005flocale_005f3);
return true;
}
_005fjspx_005ftagPool_005fmytag_005flocale.reuse(_jspx_th_mytag_005flocale_005f3);
return false;
}
}
从代码中可以发现,由于test3.jsp使用了四个mytag:locale标签,所以在类中定义了四个标签处理方法,同时在_jspService()方法中也调用了这四个处理方法。每个处理方法中的实现内容大致相同,只是在调用out.write()方法向标签体中写入的内容不一样。
仔细分析第一个处理方法中的黑体部分可以发现:调用doStartTag()时,如果返回SKIP_BODY则不会对标签体做任何处理而是直接跳转到执行doEndTag();如果返回的不是EVAL_BODY_INCLUDE(而是EVAL_BODY_BUFFERED)才会调用BodyTag的setBodyContent()方法和doInitBody()方法,否则就直接跳转到do-while循环处理标签体和doAfterBody()方法,这正好应证了前面画的流程图。最后调用doEndTag()处理标签结束,由于LocaleTag是在doEndTag()方法中读取标签内容和写入标签新内容的,所以标签内容是在执行到这个时候才被更新的。
结合JSP文件内容、标签实现类、JSP所转换的Servlet以及前面介绍的标签处理流程图,可以非常清晰地了解JSP中对自定义标签的处理机制和流程。
本章介绍了Java Web开发中又一项重要的基础技术,JSP技术。从JSP文件的内容格式和执行JSP文件时的表现来看,很多人会认为JSP文件的执行过程是首先执行JSP文件中的Java代码,将执行完后获得的HTML文件返回给客户端;但实际上JSP的执行过程并非如此,而是JSP文件在被请求时将会被完全转化为Servlet,并通过Servlet响应客户段的请求。
为了能够使JSP文件被正确解析,程序员编辑的JSP文件必须符合JSP的语法规范。JSP定义了许多语法结构,包括:程序代码、声明代码、输出代码、注释代码、指令代码、预定义代码等。而且,为了方便代码访问HTTP请求、Web应用及Web服务器的参数和设置,JSP提供了若干隐含对象;在JSP文件中,这些对象可以直接被用来获取各种参数和设置。
自定义标签是JSP对自身系统的一种扩展。JSP的自定义标签体系包含三个级别,Tag是有明确起始位置和结束位置的标签,IterationTag是在Tag的基础上标签内容可以迭代执行的标签,BodyTag是在IterationTag的基础上可以与标签内容进行交互的标签。
Java通过try/catch语句和Exception类体系提供了比较完善的异常处理机制。JSP文件最终被转换为Java文件,所以在JSP文件中当然也可以使用Java固有的异常处理机制。除此之外,JSP还提供了一种更宏观的异常处理机制,那就是errorPage。
在前面介绍page指令时,讲到page指令中有两个与errorPage相关的属性:errorPage和isErrorPage。其中errorPage指定了一个错误处理页面,假如当前页面中出现了JSP错误那么请求就会转向这个错误处理页面;isErrorPage指定当前页面是否是错误处理页面,假如当前页面是错误处理页面,那么当前页面就可以访问exception对象,并且通过分析exception对象对各种异常进行处理。这种异常处理机制将对异常的处理集中到一个页面,更加提高了代码的抽象度,更便于系统的维护。这种异常处理的逻辑如图9.10所示:
图9.10 JSP异常处理示意图
exception是标准的Exception类的对象,其方法和使用可参见Exception类的相关资料或Java文档。
假如某个JSP页面配置了errorPage属性,例如errorPage="errorHandler.jsp",那么转换成的Java文件中会有:
pageContext = _jspxFactory.getPageContext(this, request, response, "errorHandler.jsp", true, 8192, true);
其中的errorHandler.jsp是以参数的形式传递给了pageContext对象,然后将pageContext对象赋值给_jspx_page_context对象:
_jspx_page_context = pageContext;
最后在做异常处理时使用:
_jspx_page_context.handlePageException(t);
在该方法中,请求会被重定向到errorHandler.jsp,并且会将异常对象传递给该页面。
PageContext对象是PageContext类的实例。该对象是JSP页面各个对象和方法的门面对象,它提供了:
(1)获得JSP页面中各隐含对象的公有方法;
(2)方便地进行各种与当前页面相关的操作。
PageContext是个抽象类,其定义如下:
package javax.servlet.jsp;
import java.io.IOException;
import javax.servlet.*;
import javax.servlet.http.HttpSession;
import javax.servlet.jsp.tagext.BodyContent;
public abstract class PageContext extends JspContext
{
public PageContext()
{
}
public abstract void initialize(Servlet servlet, ServletRequest servletrequest, ServletResponse servletresponse, String s, boolean flag, int i, boolean flag1)
throws IOException, IllegalStateException, IllegalArgumentException;
public abstract void release();
public abstract HttpSession getSession();
public abstract Object getPage();
public abstract ServletRequest getRequest();
public abstract ServletResponse getResponse();
public abstract Exception getException();
public abstract ServletConfig getServletConfig();
public abstract ServletContext getServletContext();
public abstract void forward(String s)
throws ServletException, IOException;
public abstract void include(String s)
throws ServletException, IOException;
public abstract void include(String s, boolean flag)
throws ServletException, IOException;
public abstract void handlePageException(Exception exception)
throws ServletException, IOException;
public abstract void handlePageException(Throwable throwable)
throws ServletException, IOException;
public BodyContent pushBody()
{
return null;
}
public ErrorData getErrorData()
{
return new ErrorData((Throwable)getRequest().getAttribute("javax.servlet.error.exception"), ((Integer) getRequest().getAttribute("javax.servlet.error.status_code")).intValue(), (String)getRequest().getAttribute("javax.servlet.error.request_uri"), (String)getRequest().getAttribute("javax.servlet.error.servlet_name"));
}
public static final int PAGE_SCOPE = 1;
public static final int REQUEST_SCOPE = 2;
public static final int SESSION_SCOPE = 3;
public static final int APPLICATION_SCOPE = 4;
public static final String PAGE = "javax.servlet.jsp.jspPage";
public static final String PAGECONTEXT = "javax.servlet.jsp.jspPageContext";
public static final String REQUEST = "javax.servlet.jsp.jspRequest";
public static final String RESPONSE = "javax.servlet.jsp.jspResponse";
public static final String CONFIG = "javax.servlet.jsp.jspConfig";
public static final String SESSION = "javax.servlet.jsp.jspSession";
public static final String OUT = "javax.servlet.jsp.jspOut";
public static final String APPLICATION = "javax.servlet.jsp.jspApplication";
public static final String EXCEPTION = "javax.servlet.jsp.jspException";
}
其中:
initialize(Servlet servlet, ServletRequest servletrequest, ServletResponse servletresponse, String s, boolean flag, int i, boolean flag1):对该PageContext对象进行初始化。因为PageContext的构造函数是无参数构造函数,所以PageContext的对象并没有被初始化,该方法将PageContext需要的参数传递给PageContext,并对PageContext对象进行初始化。该方法相当于JSP转化成的Servlet中的:
pageContext = _jspxFactory.getPageContext(this, request, response, "errorHandler.jsp", true, 8192, true);
并且其中参数的个数、顺序和含义均相同。
release():释放该PageContext对象。该方法对PageContext对象的内部状态进行重置,使该PageContext对象可以在initialize()后被重新使用。
getSession():获得session隐含对象。
getPage():获得page隐含对象。
getRequest():获得request隐含对象。
getResponse():获得response隐含对象。
getException():获得exception隐含对象。
getServletConfig():获得config隐含对象。
getServletContext():获得application隐含对象。
forward(String s):将请求前转到s指定的Web对象,其效果等同于<jsp:forward>标签。
include(String s):将s指定的Web对象包含到处理中,相当于该JSP页面向指定的Web对象发出请求,并且处理返回的响应。效果等同于<jsp:include>标签。
include(String s, boolean flag):除了起到上面方法的效果外,还提供了一个额外效果,即当flag为true时,该方法同时刷新输出缓冲区。
handlePageException(Exception exception):处理页面级的异常,即将参数提供的异常与请求一起转发给错误处理页面。
handlePageException(Throwable throwable):同上方法。
pushBody():返回一个新的BodyContent对象,保存当前out对象的内容。并且更新out属性的值。
getErrorData():返回一个ErrorData对象,在错误处理页面中该对象用于表示错误内容。在非错误处理页面中返回的对象是无意义的。
在JSP的这些隐含对象中,有四个对象都定义了类似的getAttribute()和setAttribute()方法。这四个对象都可以通过属性的名称设置和获取属性,但不同的是这四个对象设置的属性具有不同的作用域。这四个对象分别是:pageContext、request、session、application;分别代表四个作用域:页面、请求、会话、应用。
如果简单理解和记忆这几种作用域是非常低效的,而且很容易出错。其实,从本质上看,属性是针对对象进行设置的,调用某对象的setAttribute()方法是将某属性保存在该对象中,只有再次调用该对象的getAttribute()方法才能够获取此属性,调用其他对象的getAttribute()当然无法获取同一属性。所以,从本质上说,属性的作用域就是对象的作用域。在某个范围内如果使用的某个类的对象都是一个对象,那么该对象的作用域就是该范围,同时该范围也是对该对象设置的属性的作用域。图9.11示意了pageContext、request、session、application四种对象的作用域。
图9.11 四种对象作用域对比示意图
图9.11示意了四种对象的作用域。
application对象表示应用,在同一个应用中只有一个application对象,所以任何客户端的任何请求只要访问的是同一个application,那么访问的application对象就是一个,所以对application设置的属性也一样。在图9.11中,服务器中有两个应用:application1和application2。任何客户端访问application1中任何文件使用的application对象都是application1。
session对象表示会话,在同一个客户端访问同一个应用时(在Session超时时间内),只有一个session对象;而对于同一个应用来说,不同的客户端访问就会产生不同的session对象。如图9.11中,客户端1访问application1的session对象是session1,而客户端2访问application1的session对象是session2。
request对象表示一次客户端请求,无论请求从哪里来以及访问哪里,一次请求就会产生一个request对象。如图9.11中,客户端2向1.jsp发出两次请求,那么每次请求就会产生一个request对象,即使1.jsp将request2传递给了2.jsp,还是不会产生新request对象的。
pageContext对象表示一个页面对一次请求的处理。如图9.11中,客户端2通过request1访问1.jsp,1.jsp对request1进行处理就产生了pageContext1;客户端2通过request2访问1.jsp,1.jsp对request2进行处理就产生了pageContext2,进而1.jsp将request2传递给了2.jsp,2.jsp对request2进行处理就产生了pageContext3。
所以,通过9.11示意图可以发现,各个对象根据其代表意义的不同,其作用域也不同,所以对其进行设置的属性的作用域也不同。总的来说这四个对象的作用域从大到小依次为:application > session > request > pageContext。
从前面对JSP的介绍可以发现,JSP是基于标签的语法,所谓标签就是用尖括号“<”和“>”括起的一个标识符;通常标签都是成对出现的,有起始标签和结束标签,例如<tag> ... </tag>,但如果标签中没有包含其他任何内容,也可以将起始标签和结束标签合并为一个标签,例如<tag />;起始标签中还可以添加属性。
最基本的,JSP继承了HTML的标签集,并且在其基础上扩充了自己的标签集,例如9.2.6节中介绍的JSP预定义标签。除此之外,JSP还提供一种程序员自己开发标签并且在JSP页面中使用标签的途径。JSP预定义标签是以jsp为前缀、具有特定功能的系统预定义标签,这些可以直接在JSP页面中使用。除此之外,程序员可以自行开发具有特定功能的标签,将这些标签引入到应用中,然后就可以在JSP页面中使用。
通过开发和使用自定义标签,开发人员可以将功能开发和页面开发的工作分开,功能开发人员关注开发功能组件,页面开发人员关注页面设计并且将开发的标签组件直接在页面中使用。
自定义标签是JSP提供的一种自我扩展的方式,它允许开发人员自己定义标签以及标签的功能,然后在JSP页面中像预定义标签一样使用。
一个自定义标签在代码中就用一个javax.servlet.jsp.tagext.Tag表示,Tag中定义了标签的行为,当包含标签的JSP页面被转化为Servlet时,Servlet会在标签引用处调用Tag的相应方法进而实现标签的功能。
开发和使用一套自定义标签的步骤如下:
开发自定义标签类(或称自定义标签处理类);
定义一个标签定义文件(tld文件),在其中定义待使用的标签,并且将相应的标签处理类指定给标签;每个标签具有一个唯一的名称;
将标签定义文件在web.xml中使用taglib进行声明;
在需要使用标签的JSP页面中使用<%@ taglib uri="..." prefix="..." %>进行声明,然后再用指定的prefix和名称使用标签。
由此可以知道,在定义一个标签之前首先需要确定的是:标签的名称以及标签所需要进行的工作。
在JSP标签体系中根据标签的表现形式和功能定义了多种不同的标签层次和类别,每一个层次和类别都定义了一些标签所要进行的操作。JSP的标签都必须实现JspTag接口,这个接口是一个概念级别的接口,并没有定义任何实质的操作,因此基本上所有标签都实现自JspTag接口的子接口,Tag接口,这个接口定义了一些方法,它们表示标签在使用时与标签相关联的一些操作。同时JSP还实现了TagSupport类和BodyTagSupport,用于为Tag提供一些默认的实现,方便开发人员在此基础上进行开发。与标签相关的接口和类的层次结构如图9.12所示:
图9.12 与标签相关的接口和类的层次结构
从图9.12中可以发现,JSP标签的顶级接口是JspTag,Tag接口继承自JspTag,IterationTag接口继承自Tag,BodyTag继承自IterationTag;TagSupport和BodyTagSupport是两个实现类,TagSupport分别实现了IterationTag和Serializable,说明TagSupport的对象是一个JSP标签并且这个对象可以序列化;BodyTagSupport实现了BodyTag接口并且继承自TagSupport,说明BodyTagSupport肯定是一个TagSupport,而且它提供的功能比TagSupport要多,可以说BodyTagSupport是一个特殊的TagSupport。
【注意】
JSP自定义标签相关的接口和类都被封装在jsp-api.jar,它与servlet-api.jar一样,位于Tomcat根目录下的lib目录中。
1.JspTag
javax.servlet.jsp.tagext.JspTag接口表示一个概念上的JSP标签,它的定义如下:
package javax.servlet.jsp.tagext;
public interface JspTag {
}
该接口并没有定义任何方法,该接口的存在只是为了定义一个概念,它是所有其他JSP标签接口和类的根接口,它主要用于组织类结构和类型检查等目的。
2.Tag
javax.servlet.jsp.tagext.Tag接口表示一个具有明确起始位置和结束位置的JSP标签,该接口定义了一些方法,这些方法会在处理标签引用时被调用。它的定义如下:
package javax.servlet.jsp.tagext;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.PageContext;
public interface Tag extends JspTag {
public abstract void setPageContext(PageContext pagecontext);
public abstract void setParent(Tag tag);
public abstract Tag getParent();
public abstract int doStartTag() throws JspException;
public abstract int doEndTag() throws JspException;
public abstract void release();
public static final int SKIP_BODY = 0;
public static final int EVAL_BODY_INCLUDE = 1;
public static final int SKIP_PAGE = 5;
public static final int EVAL_PAGE = 6;
}
其中:
setPageContext(PageContext pagecontext):将JSP页面的PageContent对象设置到对象中,该方法通常由JSP容器调用。在Tag对象被初始化成功后,在调用其他任何处理方法之前被调用。
setParent(Tag tag):设置该Tag的父标签,也是有JSP容器调用。
getParent():返回该Tag的父标签。
doStartTag():在处理JSP页面时,在标签起始处调用的代码;该方法会返回标志EVAL_BODY_INCLUDE或SKIP_BODY,用于决定是继续处理标签(EVAL_BODY_INCLUDE)还是跳过该标签(SKIP_BODY)。
doEndTag():在处理JSP页面时,在标签结束处调用的代码;该代码会返回标志EVAL_PAGE或SKIP_PAGE,用于决定是继续处理页面剩下的内容(EVAL_PAGE)还是跳过页面剩下部分的处理(SKIP_PAGE)。
release():用于释放状态,在标签处理完成后会被JSP容器调用。
SKIP_BODY:标志位,表示跳过标签体的处理。
EVAL_BODY_INCLUDE:标志位,表示继续标签体的处理。
SKIP_PAGE:标志位,表示跳过页面剩余部分的处理。
EVAL_PAGE:标志位,表示继续页面剩余部分的处理。
从该接口定义的方法可以发现,该接口定义了一个标签处理器的框架,实现者需要在doStartTag()和doEndTag()中添加自己的代码,用于实现标签的功能。通过实现该接口子类可以实现一个对标签进行处理的最基本的能力。
3.IterationTag
javax.servlet.jsp.tagext.IterationTag继承自Tag,并且在Tag的基础上又增加了一个方法的定义。IterationTag是一个Tag并且增加了对Tag的处理,不仅提供了在标签开始和结束时方法,而且还提供了一个在处理方法体后执行的方法。定义如下:
package javax.servlet.jsp.tagext;
import javax.servlet.jsp.JspException;
public interface IterationTag extends Tag {
public abstract int doAfterBody() throws JspException;
public static final int EVAL_BODY_AGAIN = 2;
}
其中:
doAfterBody():在标签体运行完后执行的代码,该方法返回标志EVAL_BODY_AGAIN或SKIP_BODY,用于决定是再次运行标签体还是不再运行标签体而直接转向doEndTag()。
EVAL_BODY_AGAIN:标志位,表示再次运行标签体。
该接口提供了一种实现迭代标签的途径,在迭代标签中,标签体内的内容或代码可以以迭代的形式多次出现或执行。通过实现该接口子类可以实现一个具有迭代功能的标签。
4.BodyTag
javax.servlet.jsp.tagext.BodyTag继承自IterationTag接口,它在IterationTag的基础上又多定义了两个方法,提供了对标签体中内容进行操纵的支持。定义如下:
package javax.servlet.jsp.tagext;
import javax.servlet.jsp.JspException;
public interface BodyTag extends IterationTag
{
public abstract void setBodyContent(BodyContent bodycontent);
public abstract void doInitBody() throws JspException;
public static final int EVAL_BODY_TAG = 2;
public static final int EVAL_BODY_BUFFERED = 2;
}
其中:
setBodyContent(BodyContent bodycontent):设置一个BodyContent对象,该对象表示标签体中的内容;该方法由JSP容器进行调用,使得实现BodyTag的类可以操纵标签的内容;该方法先于doInitBody()被调用。
doInitBody():在处理标签时,该方法会在运行标签体之前被调用,用以为运行标签体做准备。
EVAL_BODY_BUFFERED:标志位,是BodyTag对Tag中定义的SKIP_BODY和EVAL_BODY_INCLUDE的扩展。当BodyTag的doStartTag()执行时,可以返回该标志位用于申请一个新的缓冲区,提供执行标签体时放置BodyContent。
EVAL_BODY_TAG:与EVAL_BODY_BUFFERED具有相同的值,这是以前使用的名字,现在已过期。
该接口的父接口更近了一步,它定义的标签可以对标签体中的内容进行操纵。通过实现这个接口子类可以实现一个可以对标签体中内容进行操纵的标签。
5.TagSupport
javax.servlet.jsp.tagext.TagSupport是一个具体的类,它实现了IterationTag,也就是说它是一个可迭代的标签。但TagSupport只是一个默认的实现,其实现并没有实质性的逻辑。TagSupport是为了方便程序员的开发而存在的,程序员在开发一个IterationTag时就可以直接从TagSupport继承而不需要从实现接口开始。该类的声明如下:
package javax.servlet.jsp.tagext;
import java.io.Serializable;
import java.util.Enumeration;
import java.util.Hashtable;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.PageContext;
public class TagSupport implements IterationTag, Serializable {
private Tag parent;
private Hashtable values;
protected String id;
protected PageContext pageContext;
public static final Tag findAncestorWithClass(Tag from, Class class);
public TagSupport();
public int doStartTag() throws JspException;
public int doEndTag() throws JspException;
public int doAfterBody() throws JspException;
public void release();
public void setParent(Tag t);
public Tag getParent();
public void setId(String id);
public String getId();
public void setPageContext(PageContext pageContext);
public void setValue(String k, Object o);
public Object getValue(String k);
public void removeValue(String k);
public Enumeration getValues();
}
其中:
parent:用于保存该标签的父标签。
values:一个属性表,其中通过键值对可以保存该Tag的属性,键是一个字符串,值是一个对象。
id:该标签id属性的值,或者是null。
pageContext:所在页面的PageContext对象。
findAncestorWithClass(Tag from, Class class):静态方法,该方法通过Tag接口的getParent()方法,从标签from开始一直寻找上级标签,直到寻找到第一个具有class类型的标签返回。
TagSupport():无参数构造方法,该方法体没有提供任何操作。
doStartTag():实现Tag接口的方法;TagSupport中的该方法直接返回SKIP_BODY,即默认实现将忽略标签。
doEndTag():实现Tag接口的方法;TagSupport中的该方法直接返回EVAL_PAGE,即继续对页面剩下的部分进行执行。所以,结合doStartTag()的实现,默认实现中TagSupport对标签不做任何处理,其效果相当于标签不存在。
doAfterBody():实现IterationTag接口的方法;TagSupport中的该方法直接返回SKIP_BODY,即任何时候都不重复执行标签体;其目的同前两个方法一样,就是效果等同于标签不存在。
release():实现Tag接口的方法;TagSupport中的该方法对自己的所有状态进行释放,恢复到初始状态,这包括:将parent设置为空,将id设置为空,清空values中的所有属性。
setParent(Tag t):实现Tag接口的方法;为TagSupport设置父标签,该方法只是将t设置给域变量parent。
getParent():实现Tag接口的方法;获得TagSupport的父标签,该方法只是返回域变量parent。
setId(String id):设置TagSupport的id,将参数id设置给域变量id。
getId():获得TagSupport的id,返回域变量id的值。
setPageContext(PageContext pageContext):实现Tag接口的方法;为TagSupport设置PageContext,该方法将参数pageContext设置给域变量pageContext。
setValue(String k, Object o):将键为k值为o的属性添加到values中。
getValue(String k):获得键为k的值。
removeValue(String k):删除键为k的属性。
getValues():获得一个Enumeration对象,其中包含所有属性的键;如果没有属性则返回空。
可见,TagSupport具备了一个IterationTag的概念,但并没有提供任何实质性的实现,如果单纯地将一个TagSupport实现的标签添加到JSP页面中,那么这个标签并不会有任何效果,其结果相当于没有添加任何标签。TagSupport的存在是为了方便开发人员,当开发人员需要开发一个IterationTag时,只需要继承TagSupport类并且重写其中的一些标签处理方法(doStartTag()、doEndTag()和doAfterBody());另外TagSupport还提供了一些方便的属性和操作,比如静态方法findAncestorWithClass(),开发人员可以在开发标签时直接调用该方法;TagSupport还为其子类提供了对id、属性和PageContext对象的管理。通过继承TagSupport开发新的标签可以使程序员只关注标签的业务逻辑。
6.BodyTagSupport
与TagSupport类似,javax.servlet.jsp.tagext.BodyTagSupport也是一个具体的类,它继承了TagSupport类,并且还另外实现了BodyTag接口,这使得BodyTagSupport具备了TagSupport的属性和处理能力,而且又增加了BodyTag的特性。该类的声明如下:
package javax.servlet.jsp.tagext;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.JspWriter;
public class BodyTagSupport extends TagSupport implements BodyTag {
protected BodyContent bodyContent;
public BodyTagSupport();
public int doStartTag() throws JspException;
public int doEndTag() throws JspException;
public void setBodyContent(BodyContent b);
public void doInitBody() throws JspException;
public int doAfterBody() throws JspException;
public void release();
public BodyContent getBodyContent();
public JspWriter getPreviousOut();
}
其中:
bodyContent:BodyContent的对象,通过setBodyContent()方法设置进来,可以在其他方法中使用,但不能在构造方法中使用,因为在构造方法中setBodyContent()方法还不可能被调用,所以bodyContent对象还是空。
BodyTagSupport():构造方法,同TagSupport一样,该类的构造方法体也为空。
doStartTag():覆盖TagSupport中的同名方法,不是返回SKIP_BODY,而是返回EVAL_BODY_BUFFERED,因为BodyTagSupport是一个BodyTag,所以返回该标志用于申请一个缓冲区。
doEndTag():覆盖TagSupport中的同名方法,但是这里还是返回了EVAL_PAGE,其用意与TagSupport也是一样的。
setBodyContent(BodyContent b):实现BodyTag的方法;将参数b设置给域变量bodyContent。
doInitBody():实现BodyTag的方法;方法体中并没有提供任何操作,对于该方法而言没有任何操作就是一种恰当的默认实现。
doAfterBody():覆盖TagSupport中的同名方法,但是这里还是返回了SKIP_BODY,默认实现。
release():覆盖TagSupport中的同名方法,在该方法中除了调用父类中的同名方法用于释放父类中的域,还要将bodyContent置为空。
getBodyContent():获得该标签的BodyContent对象,该方法中返回域变量bodyContent。
getPreviousOut():获得BodyContent所封装的JspWriter对象,通过该对象可以向BodyContent中写入内容。
BodyTagSupport是在TagSupport的基础上又添加了对BodyTag接口的默认实现。BodyTagSupport与TagSupport的区别主要是在处理标签时是否需要与标签体进行交互,如果不需要交互就用TagSupport,如果需要交互就要用BodyTagSupport。或者可以反过来说,如果开发人员想开发一个需要标签体交互的标签就用BodyTagSupport,否则就用TagSupport。这里所谓的交互就是处理标签时是否要读取标签体的内容或改变标签体的内容。由于BodyTagSupport是TagSupport的子类,所以所有用TagSupport实现的标签也可以用BodyTagSupport来实现,只是将BodyTagSupport实现BodyTag接口的方法保持为默认实现即可。但是,还是建议读者对于不需要交互的标签使用TagSupport实现,因为这样会避免多余的操作。
7.BodyContent
在实现了BodyTag的类中,包括BodyTagSupport。BodyContent是一个非常重要的结构,在需要和标签内容进行交互的标签中,BodyContent就是BodyTag子类与所处理标签内容进行交互的媒介;BodyTag子类通过BodyContent类的方法对标签的内容进行获取、写入、清空等操作。
BodyContent实质上是一个对JspWriter的封装,它对向JSP页面内容进行写入的Writer封装起来并且向外提供一个JspWriter的接口。在BodyContent的实现中,它保持了一个缓冲,在外部调用其写入方法时写入的内容会被放入BodyContent的缓冲中;同时BodyContent还提供了读取方法,读取方法会返回一个读取缓冲区内容的Reader;清空内容的方法会将缓冲中的内容清空。
一个标签的内容就是一个BodyContent对象,嵌套标签会产生BodyContent对象之间的相互包含;BodyContent的初始内容是标签中本来已有的内容,在对标签进行处理时可以读取、写入和清空这些内容,标签中的最终的内容就是标签处理完后BodyContent的内容。
这里需要注意的是,BodyContent的内容是JSP原始内容的执行结果而非原始内容。例如:
<tag>
<% out.print(“Hello”) %>
</tag>
在处理tag标签时,BodyContent的内容是“Hello”而不是“<% out.print(“Hello”) %>”。
BodyContent类的声明如下:
package javax.servlet.jsp.tagext;
import java.io.*;
import javax.servlet.jsp.JspWriter;
public abstract class BodyContent extends JspWriter {
private JspWriter enclosingWriter;
protected BodyContent(JspWriter e);
public void flush() throws IOException;
public void clearBody();
public abstract Reader getReader();
public abstract String getString();
public abstract void writeOut(Writer writer) throws IOException;
public JspWriter getEnclosingWriter();
}
其中:
enclosingWriter:JspWriter的对象,是BodyContent对象封装的JspWriter;
BodyContent(JspWriter e):构造函数,将e传递给封装的enclosingWriter;
flush():实现了JspWriter的flush()方法,在BodyContent中该方法被声明为无效方法,因为对BodyContent调用该方法没有意义,所以在使用BodyContent时不要调用flush()方法;
clearBody():清空BodyContent的内容;
getReader():获得读取BodyContent内容的Reader;
getString():将BodyContent的内容作为字符串返回;
writeOut(Writer writer):将BodyContent的内容写入到指定的writer;
getEnclosingWriter():返回被BodyContent封装的JspWriter,即返回enclosingWriter对象。
BodyContent类是一个抽象类,其中的getReader()、getString()、writeOut()都没有提供具体的实现,它们的实现由软件提供商实现,但方法的作用和意义是不会改变的。作为开发Web应用的开发人员,应该针对BodyContent提供的接口进行编程。
8.标签处理流程
在前面介绍了三种标签接口:Tag、IterationTag和BodyTag,它们分别定义了一些方法,这些方法分别在标签处理过程中的不同时间点被调用,而且某些方法是否被调用以及调用的次数还可能取决于前面方法返回的结果。这些方法包括:Tag接口的doStartTag()方法和doEndTag()方法、IterationTag的doAfterBody()、BodyTag的setBodyContent()和doInitBody();返回值包括:EVAL_BODY、SKIP_BODY、EVAL_BODY_AGAIN、EVAL_BODY_BUFFERED。
下面我们分别针对不同类型标签的处理过程,详细介绍各个方法被调用的状态转换图。
IterationTag继承Tag,BodyTag又继承IterationTag,所以某个类对这几个接口的实现可能存在如下几种情况:
Tag:实现类只实现了Tag标签。对于这种情况而言所实现的标签是一个不可迭代而且不需要与内容进行交互的标签。所以,它的处理方法只有doStartTag()和doEndTag()。执行的流程图如图9.13所示。
如图9.13所示,Tag子类的在被创建以后,首先会通过setPageContext()、setParent()、setId()等方法将Tag的初始信息传递给Tag;然后在处理到标签开始处时调用doStartTag()方法,根据方法的返回值确定是否要继续执行标签体内的内容;在标签结束处调用doEndTag()方法,根据方法的返回值确定是否继续处理页面的剩余部分。
IterationTag:实现类实现了IterationTag,那实现类也自动实现了Tag接口。这说明所实现的标签是一个可迭代但无需与标签体进行交互的标签。该类中的处理方法会增加一个doAfterTag()方法。处理的流程图如图9.14所示:
如图9.14所示,IterationTag的执行流程图是在Tag执行流程图的基础上添加了对doAfterTag()方法的调用和判断,添加了对标签体中内容的多次执行逻辑。
图9.13 Tag子类执行流程图
图9.14 IterationTag子类执行流程图
BodyTag:实现类实现了BodyTag,也就自动实现了Tag和IterationTag。这说明实现的标签是一个可迭代而且需要与标签内容进行交互的标签。这种标签又在IterationTag的基础上增加了setBodyContent()方法和doInitBody()方法,而且在实现类的其他方法中还可以引用BodyContent对象对标签的内容进行操纵。处理的流程图如图9.15所示:
从图9.15可以发现,与IterationTag对Tag的扩展类似,BodyTag也在doStartTag()与doEngTag()之间对Tag进行了扩展。BodyContent是通过setBodyContent()方法被设置到类中的,所以在BodyContent对象只有在setBodyContent()方法调用后才能被使用,从流程图中可以很容易地发现,在doStartTag()被执行时BodyContent还没有被赋值,因此是不能使用的;而在doInitBody()、doAfterBody()和doEndTag()中就可以使用。
图9.15 BodyTag子类执行流程图
从前面对JSP标签体系的介绍可以发现,在JSP中标签根据其功能分为三个级别:Tag、IterationTag和BodyTag。从本小节开始的以下三个小节将分别举例介绍这三个级别标签的开发。本小节首先介绍Tag级别的标签。
Tag标签是只实现了Tag接口而没有实现IterationTag和BodyTag接口的标签。Tag标签只定义了标签的起始和结束,并分别在标签的起始和结束处调用接口的方法对标签进行处理。下面针对一种特定的标签使用场景开发一个Tag标签。
1.标签使用场景
假设在开发的系统中要添加一种日志功能:要求为每个JSP页面添加访问日志,在JSP页面被访问时在Tomcat的日志文件中记录一条日志,包括日志内容访问时间以及在访问该JSP页面的客户端主机名。
关于日志功能,我们在第8.7.3节中已经介绍了如何用ServletContext对象记录日志。完成这个功能可以通过在JSP页面中添加一个代码块,在代码块中获取ServletContext对象进行日志记录;日志功能本身会记录当前时间,客户端主机名可以通过ServletRequest的getRemoteHost()方法获得。开发的test.jsp如下:
test.jsp
<%@ page language="java" contentType="text/html; charset=ISO-8859-1"
pageEncoding="ISO-8859-1"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<%
String host = request.getRemoteHost();
config.getServletContext().log("test.jsp: " + host);
%>
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<title>Insert title here</title>
</head>
<body>
...
</body>
</html>
在该test.jsp中添加一块Java代码块,获得host后,将JSP文件名和host一同写入日志,日志内容如下:
Jun 23, 2008 4:05:10 PM org.apache.catalina.core.ApplicationContext log
INFO: test.jsp: 127.0.0.1
如果在所有JSP页面中都添加这么一段代码来实现日志功能,那将会很烦琐而且还很容易出错。所以,希望开发一个通用标签,在JSP页面中只需要将这个标签添加到页面中就可以完成同样的日志功能,使用格式如下:
<mytag:loghost jspfile="test.jsp"/>
2.开发标签
前面已经将标签的功能描述得非常清楚,可以发现该标签不需要迭代处理也不需要与标签内容进行交互,所以只需要实现Tag接口即可。具体的实现如下:
package cn.csai.web.jsp;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.PageContext;
import javax.servlet.jsp.tagext.Tag;
public class LogTag implements Tag {
private PageContext context;
private String fileName;
public int doEndTag() throws JspException {
String host = context.getRequest().getRemoteHost();
context.getServletContext().log(fileName + ": " + host);
return EVAL_PAGE;
}
public int doStartTag() throws JspException {
return EVAL_BODY_INCLUDE;
}
public Tag getParent() {
return null;
}
public void release() {
}
public void setPageContext(PageContext arg0) {
context = arg0;
}
public void setParent(Tag arg0) {
}
public void setJspfile(String jspFile) {
this.fileName = jspFile;
}
}
实现Tag接口必须实现它的所有方法,但这里只需要为doStartTag()和doEndTag()方法添加适当的内容即可。另外,由于该标签还有一个jspfile的属性,所以还必须为其提供一个setter方法。
doStartTag():该方法是在遇到标签起始位置时被调用的。在该标签的实现中我们将实现日志功能的代码放到标签结束位置,所以该方法不需要提供任何实现代码,直接返回即可。由于该标签不支持标签中包含的任何内容,所以此处返回SKIP_BODY和EVAL_BODY_INCLUDE都不影响标签功能的实现。
doEndTag():该实现没有在doStartTag()中添加功能代码,而是选择在doEndTag()中实现标签的功能,所以该方法中就必须实现日志功能。具体的实现代码与在JSP中添加Java代码块实现的代码类似。最后,返回EVAL_PAGE让JSP继续对页面其他内容进行解析,保证添加该标签后不影响页面其他内容的正常处理。
setJspfile():由于该标签中包含了一个jspfile的属性用于指定记录日志的JSP文件的文件名,以便于在日志中包含JSP文件名。JSP的实现规定,标签的实现必须为标签的每个属性定义一个setter方法,而且setter方法的方法名也应该符合命名规范:set + 属性名(首字母变大写)。例如jspfile属性的setter方法就是setJspfile()。这个方法名是大小写敏感的,所以在实现时要注意方法名中字母的大小写。即使将setJspfile()写成setJspFile()也会导致错误。但是,在实现类中所定义的对应属性的名称没有任何限制,例如本实现中的fileName也是可以的。
在该实现中将标签功能的实现放在了doEndTag()中。其实对于该标签来说,由于它的标签体中不会包含任何内容,所以将标签功能的实现放在doStartTag()或doEndTag()中都是可行的。将标签功能放在doStartTag()方法中实现,并且让doStartTag()方法返回SKIP_BODY的实现如下:
package cn.csai.web.jsp;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.PageContext;
import javax.servlet.jsp.tagext.Tag;
public class LogTag implements Tag {
private PageContext context;
private String fileName;
public int doEndTag() throws JspException {
return EVAL_PAGE;
}
public int doStartTag() throws JspException {
String host = context.getRequest().getRemoteHost();
context.getServletContext().log(fileName + ": " + host);
return SKIP_BODY;
}
public Tag getParent() {
return null;
}
public void release() {
}
public void setPageContext(PageContext arg0) {
context = arg0;
}
public void setParent(Tag arg0) {
}
public void setJspfile(String jspFile) {
this.fileName = jspFile;
}
}
这个实现所获得的效果与上一个实现相同。
这两个实现都是直接从实现Tag接口开始的,这会使得这其中的许多方法都显得很多余,比如:getParent()、release()、setParent(Tag)方法。为了避免这个问题,也可以通过继承TagSupport类来实现标签,虽然这个标签实现了IterationTag接口,但正如前面提到的,TagSupport对IterationTag中定义方法的默认实现并不会对标签产生任何附加的影响。所以如果通过继承TagSupport类来实现一个不可迭代的标签,只需要不对TagSupport的doAfterBody()方法提供覆盖实现即可。这样,开发人员只需要实现自己关心的方法,而不用在实现类中列举多余的方法实现。通过继承TagSupport实现LogTag的代码如下:
package cn.csai.web.jsp;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.tagext.TagSupport;
public class LogTag extends TagSupport {
private String fileName;
public int doEndTag() throws JspException {
String host = pageContext.getRequest().getRemoteHost();
pageContext.getServletContext().log(fileName + ": " + host);
return EVAL_PAGE;
}
public int doStartTag() throws JspException {
return EVAL_BODY_INCLUDE;
}
public void setJspfile(String jspFile) {
this.fileName = jspFile;
}
}
3.配置和使用标签
完成了标签类的开发并不能直接在JSP页面中使用标签,因为Tomcat服务器并不知道标签类的存在,也并不知道标签的格式,所以必须要对标签进行定义并且将定义标签的标签库的声明添加到web.xml中。
在开发完标签类后,首先要将标签添加到一个标签库中,也可以自己创建一个新的标签库。
标签库通常是一个tld文件,其内容是一个XML文档,例如下面是一个自定义的标签文件的内容:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE taglib PUBLIC "-//Sun Microsystems, Inc.//DTD JSP Tag Library 1.1//EN" "http://java.sun.com /j2ee/dtds/web-jsptaglibrary_1_1.dtd">
<taglib>
<tlibversion>1.2</tlibversion>
<jspversion>1.1</jspversion>
<shortname>MyTag</shortname>
<uri>/mytag</uri>
<tag>
<name>log</name>
<tagclass>cn.csai.web.jsp.LogTag</tagclass>
<bodycontent>empty</bodycontent>
<attribute>
<name>jspfile</name>
<required>true</required>
</attribute>
</tag>
</taglib>
标签定义的XML文档的根元素是taglib,tlibversion是标签库格式的版本,jspversion是JSP标准的版本,shortname是为标签库定义的一个名称,uri是引用该标签库的URI。一个标签库可以定义多个标签,每个标签使用一个tag元素,tag元素的name子元素是标签的名称;tagclass子元素是实现该标签的类的全路径;bodycontent是指定该标签内容的形式,可以是tagdependent、JSP和empty,empty就表示该标签不应该包含有内容;attribute为该标签定义了该标签可能会包含的属性,name是属性的名称,required说明该属性是否是必须的。这个示例就是LogTag的标签定义。在定义文件中定义的属性要与标签实现类中定义的属性setter方法相一致,这里定义了多少的属性就需要在实现类中定义相同数量的setter方法,而且setter方法的名字要符合命名规范。
将该标签定义文件命名为MyTag.tld,将其放在Web应用的WEB_INF目录中。并且还需要在web.xml中添加对标签定义文件的引用:
<web-app ...>
<jsp-config>
<taglib>
<taglib-uri>/mytag</taglib-uri>
<taglib-location>/WEB-INF/MyTag.tld</taglib-location>
</taglib>
</jsp-config>
...
</web-app>
接下来就可以在JSP页面中使用自定义标签了,格式如下:
<%@ page language="java" contentType="text/html; charset=ISO-8859-1"
pageEncoding="ISO-8859-1"%>
<%@ taglib uri="/mytag" prefix="mytag"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<mytag:log jspfile="test.jsp" />
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<title>Insert title here</title>
</head>
<body>
...
</body>
</html>
在JSP页面中使用标签,首先要在JSP页面中通过taglib添加标签应用声明,taglib中的uri就对应web.xml中taglib-uri所指定的uri,prefix是开发人员自己定义的一个前缀,这里可以随意定义。
在使用标签时,标签名是taglib中声明的prefix加上标签在标签库中定义的名称,这里就是mytag:log。
对于Tomcat来说,它是一次性就将一个标签库引入进JSP页面中,而使用标签时一次只会使用一个标签,所以当有多个标签时,可以将多个标签定义到同一个标签库定义文件中,这样就可以通过一次引用而使用标签库中的所有标签。
将Web应用部署到Tomcat中后,访问test.jsp文件,然后查看Tomcat的日志文件就可以发现:在localhost当前日志的最后多了一条日志记录:
Jun 23, 2008 5:03:39 PM org.apache.catalina.core.ApplicationContext log
INFO: test.jsp: 127.0.0.1
4.标签处理的本质
在前面已经讲过,所有的JSP页面最终都会被转换为一个Servlet进行工作,所以只要查看JSP所转化的Servlet就可以明白自定义标签处理的本质。以上面使用LogTag的test.jsp为例,它转化的Servlet如下:
package org.apache.jsp;
import javax.servlet.*;
import javax.servlet.http.*;
import javax.servlet.jsp.*;
public final class test_jsp extends org.apache.jasper.runtime.HttpJspBase
implements org.apache.jasper.runtime.JspSourceDependent {
private static final JspFactory _jspxFactory = JspFactory.getDefaultFactory();
private static java.util.List _jspx_dependants;
static {
_jspx_dependants = new java.util.ArrayList(1);
_jspx_dependants.add("/WEB-INF/MyTag.tld");
}
private org.apache.jasper.runtime.TagHandlerPool _005fjspx_005ftagPool_005fmytag_005flog_ 005fjspfile_005fnobody;
private javax.el.ExpressionFactory _el_expressionfactory;
private org.apache.AnnotationProcessor _jsp_annotationprocessor;
public Object getDependants() {
return _jspx_dependants;
}
public void _jspInit() {
_005fjspx_005ftagPool_005fmytag_005flog_005fjspfile_005fnobody = org.apache.jasper. runtime.TagHandlerPool.getTagHandlerPool(getServletConfig());
_el_expressionfactory = _jspxFactory.getJspApplicationContext(getServletConfig().getServletContext()). getExpressionFactory();
_jsp_annotationprocessor = (org.apache.AnnotationProcessor) getServletConfig().getServletContext(). getAttribute(org.apache.AnnotationProcessor.class.getName());
}
public void _jspDestroy() {
_005fjspx_005ftagPool_005fmytag_005flog_005fjspfile_005fnobody.release();
}
public void _jspService(HttpServletRequest request, HttpServletResponse response)
throws java.io.IOException, ServletException {
PageContext pageContext = null;
HttpSession session = null;
ServletContext application = null;
ServletConfig config = null;
JspWriter out = null;
Object page = this;
JspWriter _jspx_out = null;
PageContext _jspx_page_context = null;
try {
response.setContentType("text/html; charset=ISO-8859-1");
pageContext = _jspxFactory.getPageContext(this, request, response,
null, true, 8192, true);
_jspx_page_context = pageContext;
application = pageContext.getServletContext();
config = pageContext.getServletConfig();
session = pageContext.getSession();
out = pageContext.getOut();
_jspx_out = out;
out.write("\r\n");
out.write("\n");
out.write("<!DOCTYPE html PUBLIC \"-//W3C//DTD HTML 4.01 Transitional//EN\" \"http://www.w3.org/ TR/html4/loose.dtd\">\n");
out.write("<html>\n");
out.write("<head>\r\n");
if (_jspx_meth_mytag_005flog_005f0(_jspx_page_context))
return;
out.write("\n");
out.write("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=ISO-8859-1\">\n");
out.write("<title>Insert title here</title>\n");
out.write("</head>\n");
out.write("<body>\n");
out.write("\n");
out.write("</body>\n");
out.write("</html>");
} catch (Throwable t) {
if (!(t instanceof SkipPageException)){
out = _jspx_out;
if (out != null && out.getBufferSize() != 0)
try { out.clearBuffer(); } catch (java.io.IOException e) {}
if (_jspx_page_context != null) _jspx_page_context.handlePageException(t);
}
} finally {
_jspxFactory.releasePageContext(_jspx_page_context);
}
}
private boolean _jspx_meth_mytag_005flog_005f0(PageContext _jspx_page_context)
throws Throwable {
PageContext pageContext = _jspx_page_context;
JspWriter out = _jspx_page_context.getOut();
cn.csai.web.jsp.LogTag _jspx_th_mytag_005flog_005f0 = (cn.csai.web.jsp.LogTag) _005fjspx_ 005ftagPool_005fmytag_005flog_005fjspfile_005fnobody.get(cn.csai.web.jsp.LogTag.class);
_jspx_th_mytag_005flog_005f0.setPageContext(_jspx_page_context);
_jspx_th_mytag_005flog_005f0.setParent(null);
_jspx_th_mytag_005flog_005f0.setJspfile("test.jsp");
int _jspx_eval_mytag_005flog_005f0 = _jspx_th_mytag_005flog_005f0.doStartTag();
if (_jspx_th_mytag_005flog_005f0.doEndTag() == javax.servlet.jsp.tagext.Tag.SKIP_PAGE) {
_005fjspx_005ftagPool_005fmytag_005flog_005fjspfile_005fnobody.reuse(_jspx_th_mytag_005flog_005f0);
return true;
}
_005fjspx_005ftagPool_005fmytag_005flog_005fjspfile_005fnobody.reuse(_jspx_th_mytag_005flog_005f0);
return false;
}
}
查看代码中的黑体部分。首先,Servlet中添加了一个TagHandlerPool类的对象,该对象专门用于处理自定义标签的转换。该对象在_jspInit()中被初始化,在_jspDestory()中被释放。
而对标签处理的核心代码都在_jspService()中,体现在如下这句:
if (_jspx_meth_mytag_005flog_005f0(_jspx_page_context))
return;
该句调用方法_jspx_meth_mytag_005flog_005f0(PageContext),并且判断返回值,如果返回值为true则返回_jspService()方法,终止对页面剩余部分的处理,否则继续执行代码剩下的部分。这就自然会与doEndTag()方法的两个返回值(SKIP_PAGE和EVAL_PAGE)联系起来。
_jspx_meth_mytag_005flog_005f0(PageContext)方法的定义就在类声明中,下面我们详细考察一下这个方法。这个方法接受一个PageContext对象作为参数,返回值是一个boolean变量。在方法中,首先以LogTag类为参数获得一个LogTag类的对象:
cn.csai.web.jsp.LogTag _jspx_th_mytag_005flog_005f0 =
(cn.csai.web.jsp.LogTag) _005fjspx_005ftagPool_005fmytag_005flog_005fjspfile_005fnobody
.get(cn.csai.web.jsp.LogTag.class);
然后分别调用LogTag对象的setPageContext()方法和setParent()方法,将PageContext对象和当前标签的父标签赋给LogTag对象。实质上这两个方法是Tag接口的方法。接下来调用LogTag的属性setter方法setJspfile(),将属性参数设置进LogTag。这些都是执行标签处理代码前的准备工作。
准备工作做完了以后就调用LogTag对象的doStartTag()方法和doEndTag()方法,并且判断doEndTag()方法的返回值;如果返回值为SKIP_PAGE则返回true,否则返回false。这恰恰应证了前面的猜测。
所以,对于含有自定义标签的JSP页面来说,它的处理就是在JSP页面转化而成的Servlet中添加了对标签处理类相关方法调用,并且将调用的返回值用于影响_jspService()方法的处理流程。
Tag标签是标签内容不可迭代执行的标签或者不包含标签内容的标签,多数用于实现功能比较单一的标签。而从IterationTag实现的标签会比Tag标签稍微复杂一些,它的标签内容可以迭代执行。下面我们用一个IterationTag的实例介绍IterationTag的开发。
1.标签使用场景
考虑如下的使用场景:在页面中经常需要让一段内容重复出现多次,例如重复打印一段文本。直接使用JSP代码块也可以实现这个功能,例如下面的test2.jsp在页面上连续输出三行Hello World:
test2.jsp
<%@ page language="java" contentType="text/html; charset=ISO-8859-1"
pageEncoding="ISO-8859-1"%>
<%@ taglib uri="/mytag" prefix="mytag"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<%for(int i=0;i<3;i++) { %>
Hello world!<br>
<%} %>
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<title>Insert title here</title>
</head>
<body>
</body>
</html>
页面显示如图9.16所示。
图9.16 test2.jsp页面效果
这种实现显然是可以达到目的的,但是由于需要在JSP页面中添加Java代码,就会使页面显得比较凌乱;假如需要重复的内容再复杂一些,就更容易出现错误。下面我们就介绍如何使用一个自定义标签来实现这个功能,使用方式如下:
<mytag:repeat times="3">
Hello world!<br>
</mytag:repeat>
其中,times表示要重复的次数,标签之间的内容就是要重复的内容。
2.开发标签
显而易见,该标签是需要进行迭代的标签,所以不能使用Tag接口,而使用IterationTag。TagSupport实现了IterationTag,所以这里就可以直接继承TagSupport来实现。实现的标签如下:
package cn.csai.web.jsp;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.tagext.TagSupport;
public class RepeatTag extends TagSupport {
private int counter = 0;
private int repeatTimes;
@Override
public int doAfterBody() throws JspException {
counter++;
if (skip())
return SKIP_BODY;
return EVAL_BODY_AGAIN;
}
@Override
public int doEndTag() throws JspException {
return EVAL_PAGE;
}
@Override
public int doStartTag() throws JspException {
if (skip())
return SKIP_BODY;
return EVAL_BODY_INCLUDE;
}
public void setTimes(String rep) {
try {
repeatTimes = Integer.parseInt(rep);
} catch (NumberFormatException e) {
repeatTimes = 0;
}
}
private boolean skip() {
if (counter >= repeatTimes) {
return true;
}
return false;
}
}
给该标签类取名为RepeatTag。该标签有一个参数times,用于说明内容需要重复的次数,所以在标签类中首先必须声明一个setter方法,setTimes()用于将times属性的值传递给域变量repeatTimes。在类中定义另一个域变量counter用于记录重复执行内容的次数,当counter大于等于repeatTimes时就退出重复执行内容的循环,所以实现了一个skip()方法用于判断是否该退出循环。
在doStartTag()方法中,首先判断是否该退出循环,这是因为如果指定的times小于等于0那就是不执行内容。所以如果在doStartTag()调用skip()时输出为true则返回SKIP_BODY,表示不执行内容;否则返回EVAL_BODY_INCLUDE便表示执行内容。
在doAfterBody()方法中,首先将counter自增1,因为执行到doAfterBody()方法时标签体已经执行了一遍了,然后再判断是否应该退出,如果不应该退出则返回EVAL_BODY_AGAIN再继续执行标签体,直到执行的次数达到为止,此时返回SKIP_BODY退出循环。
在doEndTag()方法中,不需要做其他操作,只要返回EVAL_PAGE保证页面剩余部分被正确解析。
3.配置和使用标签
无论是什么标签,配置都是类似的,都需要放在标签定义文件中。在第9.4.4节中已经定义了MyTag.tld,而且在其中定义了LogTag;现在开发的新的标签只需要在MyTag.tld中再添加RepeatTag的定义就可以了,如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE taglib PUBLIC "-//Sun Microsystems, Inc.//DTD JSP Tag Library 1.1//EN" "http://java.sun.com/j2ee /dtds/web-jsptaglibrary_1_1.dtd">
<taglib>
<tlibversion>1.2</tlibversion>
<jspversion>1.1</jspversion>
<shortname>MyTag</shortname>
<uri>/mytag</uri>
<tag>
<name>log</name>
<tagclass>cn.csai.web.jsp.LogTag</tagclass>
<bodycontent>empty</bodycontent>
<attribute>
<name>jspfile</name>
<required>true</required>
</attribute>
</tag>
<tag>
<name>repeat</name>
<tagclass>cn.csai.web.jsp.RepeatTag</tagclass>
<bodycontent>JSP</bodycontent>
<attribute>
<name>times</name>
<required>true</required>
</attribute>
</tag>
</taglib>
只需要在taglib元素下再添加一个tag元素就可以了,tag元素中的声明含义不变,只是由于该标签是包含标签体内容的,所以bodycontent不能设为empty,而应该设为JSP。
在test2.jsp中使用RepeatTag的格式如下:
test2.jsp
<%@ page language="java" contentType="text/html; charset=ISO-8859-1"
pageEncoding="ISO-8859-1"%>
<%@ taglib uri="/mytag" prefix="mytag"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4 /loose.dtd">
<html>
<head>
<mytag:repeat times="3">
Hello world!<br>
</mytag:repeat>
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<title>Insert title here</title>
</head>
<body>
</body>
</html>
如其中黑体部分所示,其含义就是将“Hello world!<br>”输出3次,页面如图9.17所示:
图9.17 使用RepeatTag标签的test2.jsp页面效果
4.标签处理的本质
为了探究IterationTag标签处理的本质,我们对test2.jsp所转化的Servlet进行了研究,Servlet如下所示。
package org.apache.jsp;
import javax.servlet.*;
import javax.servlet.http.*;
import javax.servlet.jsp.*;
public final class test2_jsp extends org.apache.jasper.runtime.HttpJspBase
implements org.apache.jasper.runtime.JspSourceDependent {
private static final JspFactory _jspxFactory = JspFactory.getDefaultFactory();
private static java.util.List _jspx_dependants;
static {
_jspx_dependants = new java.util.ArrayList(1);
_jspx_dependants.add("/WEB-INF/MyTag.tld");
}
private org.apache.jasper.runtime.TagHandlerPool _005fjspx_005ftagPool_005fmytag_005frepeat_005ftimes;
private javax.el.ExpressionFactory _el_expressionfactory;
private org.apache.AnnotationProcessor _jsp_annotationprocessor;
public Object getDependants() {
return _jspx_dependants;
}
public void _jspInit() {
_005fjspx_005ftagPool_005fmytag_005frepeat_005ftimes = org.apache.jasper.runtime.TagHandlerPool. getTagHandlerPool(getServletConfig());
_el_expressionfactory = _jspxFactory.getJspApplicationContext(getServletConfig().getServletContext()). getExpressionFactory();
_jsp_annotationprocessor = (org.apache.AnnotationProcessor) getServletConfig().getServletContext(). getAttribute(org.apache.AnnotationProcessor.class.getName());
}
public void _jspDestroy() {
_005fjspx_005ftagPool_005fmytag_005frepeat_005ftimes.release();
}
public void _jspService(HttpServletRequest request, HttpServletResponse response)
throws java.io.IOException, ServletException {
PageContext pageContext = null;
HttpSession session = null;
ServletContext application = null;
ServletConfig config = null;
JspWriter out = null;
Object page = this;
JspWriter _jspx_out = null;
PageContext _jspx_page_context = null;
try {
response.setContentType("text/html; charset=ISO-8859-1");
pageContext = _jspxFactory.getPageContext(this, request, response,
null, true, 8192, true);
_jspx_page_context = pageContext;
application = pageContext.getServletContext();
config = pageContext.getServletConfig();
session = pageContext.getSession();
out = pageContext.getOut();
_jspx_out = out;
out.write("\r\n");
out.write("\n");
out.write("<!DOCTYPE html PUBLIC \"-//W3C//DTD HTML 4.01 Transitional//EN\" \"http://www.w3.org /TR/html4/loose.dtd\">\n");
out.write("<html>\n");
out.write("<head>\r\n");
if (_jspx_meth_mytag_005frepeat_005f0(_jspx_page_context))
return;
out.write("\n");
out.write("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=ISO-8859-1\">\n");
out.write("<title>Insert title here</title>\n");
out.write("</head>\n");
out.write("<body>\n");
out.write("\n");
out.write("</body>\n");
out.write("</html>");
} catch (Throwable t) {
if (!(t instanceof SkipPageException)){
out = _jspx_out;
if (out != null && out.getBufferSize() != 0)
try { out.clearBuffer(); } catch (java.io.IOException e) {}
if (_jspx_page_context != null) _jspx_page_context.handlePageException(t);
}
} finally {
_jspxFactory.releasePageContext(_jspx_page_context);
}
}
private boolean _jspx_meth_mytag_005frepeat_005f0(PageContext _jspx_page_context)
throws Throwable {
PageContext pageContext = _jspx_page_context;
JspWriter out = _jspx_page_context.getOut();
cn.csai.web.jsp.RepeatTag _jspx_th_mytag_005frepeat_005f0 = (cn.csai.web.jsp.RepeatTag) _005fjspx_ 005ftagPool_005fmytag_005frepeat_005ftimes.get(cn.csai.web.jsp.RepeatTag.class);
_jspx_th_mytag_005frepeat_005f0.setPageContext(_jspx_page_context);
_jspx_th_mytag_005frepeat_005f0.setParent(null);
_jspx_th_mytag_005frepeat_005f0.setTimes("3");
int _jspx_eval_mytag_005frepeat_005f0 = _jspx_th_mytag_005frepeat_005f0.doStartTag();
if (_jspx_eval_mytag_005frepeat_005f0 != javax.servlet.jsp.tagext.Tag.SKIP_BODY) {
do {
out.write("\r\n");
out.write("Hello world!<br>\r\n");
int evalDoAfterBody = _jspx_th_mytag_005frepeat_005f0.doAfterBody();
if (evalDoAfterBody != javax.servlet.jsp.tagext.BodyTag.EVAL_BODY_AGAIN)
break;
} while (true);
}
if (_jspx_th_mytag_005frepeat_005f0.doEndTag() == javax.servlet.jsp.tagext.Tag.SKIP_PAGE) {
_005fjspx_005ftagPool_005fmytag_005frepeat_005ftimes.reuse(_jspx_th_mytag_005frepeat_005f0);
return true;
}
_005fjspx_005ftagPool_005fmytag_005frepeat_005ftimes.reuse(_jspx_th_mytag_005frepeat_005f0);
return false;
}
}
从代码中可以发现,总体的结构与test.jsp的Servlet类似。只是标签处理函数有了一些变化,添加了一些处理代码。观察方法中的黑体部分,首先还是调用doStartTag()方法,如果doStartTag()返回值不等于SKIP_BODY则继续执行标签体。但这里处理标签体却是使用了一个do-while循环;首先输出标签体中的内容然后调用doAfterBody()方法,如果返回值不是EVAL_BODY_AGAIN则跳出循环,否则继续循环输出标签体。
BodyTag是在IterationTag的基础上又添加了与标签体中内容的交互。
1.标签使用场景
考虑下面的一种使用场景:希望在页面中显示一段文字,而且这段文字可以根据客户端浏览器的语言设置而动态变化,比如如果客户端浏览器使用的是英文语言设置则返回“Hello,××!”,如果客户端浏览器使用的是中文语言设置则返回“你好,××!”。
浏览器所使用的语言可以在浏览器的选项中进行设置,在IE的菜单Tools(工具)→Internet Options(Internet选项)...选项打开的窗口中的General(常规)页的下部有一个 Languages(语言)...按钮,如图9.18所示。
图9.18 Internet Options窗口
点击Languages...按钮打开Language Preference窗口,如图9.19所示。
图9.19 Language Preference窗口
可以通过Add...添加新的语言,通过Move Up和Move Down移动语言的上下顺序,在最上面的语言是最优选的语言。
另外在服务器端,在Servlet中,可以通过ServletRequest的getLocale()方法获得客户端所使用的语言,如图9.19中显示的两个语言设置分别是中文和英文,所对应的Locale就是Locale.Chinese和Locale.US,两个Locale的缩写代码分别是zh_CN和en_US。程序员可以通过为浏览器设置不同的Locale,然后测试开发的功能是否正确。
假设我们要开发一个JSP页面,页面根据客户端设置的不同Locale分别显示“你好,王先生!”和“Hello, Mr. Wang!”。
根据不同的Locale显示不同语言的字符串,这在Java中已经提供了支持。首先,为每个Locale创建一个资源properties文件,文件名包含Locale的缩写代码,例如MessageBundle_zh_CN.properties和MessageBundle_en_US.properties;这两个文件的文件名都是MessageBundle,但它们分别定义了针对中文和英文的两套资源文件。然后,在每个资源文件中为每一个需要进行多语言支持的字符串定义一个键值对,每个资源文件中的键名一样,但值分别用资源文件对应的语言进行表达,例如:
表9.2 不同资源文件中键值对的描述
同时,还可以定义一个默认的properties,即当客户端设置的既不是中文也不是英文时,就用默认的语言值,通常默认的与英文的一样,只是文件名不包含任何Locale的缩写,而直接是MessageBundle.properties。
定义完资源文件,然后实现一个类用于从资源文件中获取值,如下面的Message类:
package cn.csai.web.jsp;
import java.util.Locale;
import java.util.MissingResourceException;
import java.util.ResourceBundle;
public class Messages {
private static final String BUNDLE_NAME = "cn.csai.web.jsp.resource.MessageBundle";
private Messages() {
}
public static String getString(String key, Locale locale) {
try {
ResourceBundle bundle = ResourceBundle.getBundle(BUNDLE_NAME, locale);
return bundle.getString(key);
} catch (MissingResourceException e) {
return "";
}
}
}
该类定义了一个静态方法getString(),该方法接受一个String和一个Locale对象作为参数,表示取Locale属性文件中键为key的值。例如getString(“hello”, Locale.Chinese)就是“你好”,而getString(“mrWang”, Locale.US)就是Mr. Wang。
通过这一套体系就可以完成根据不同Locale获取不同语言的文字的功能。下面就关注于如何在JSP页面中添加这个功能。
假如不使用自定义标签,那么只能在页面中添加Java代码以实现这个功能:
test3.jsp
<%@ page language="java" contentType="text/html; charset=ISO-8859-1"
pageEncoding="ISO-8859-1"%>
<%@ page import="cn.csai.web.jsp.Messages, java.util.Locale" %>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<%
Locale locale = request.getLocale();
String s = Messages.getString("hello", locale) + ", " + Messages.getString("mrWang", locale) + "!";
%>
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<title>Insert title here</title>
</head>
<body>
<%= s %>
</body>
</html>
下面我们将介绍如何使用自定义标签的方式实现这个功能,以使这个功能能够被通用。
2.开发标签
根据该功能要求,需要开发一个可以根据客户端浏览器Locale设置输出多种语言的标签。设计标签的格式如下:
<mytag:locale>hello</mytag:locale>
标签的内容包含的是所需要输出消息的键。
由于该标签需要输出标签内容,所以首先可以肯定该标签必须是一个BodyTag标签,为了简单起见,继承BodyTagSupport来实现LocaleTag。标签的实现如下:
package cn.csai.web.jsp;
import java.io.IOException;
import java.util.Locale;
import javax.servlet.jsp.JspException;
import javax.servlet.jsp.tagext.BodyTagSupport;
public class LocaleTag extends BodyTagSupport {
@Override
public int doStartTag() throws JspException {
return EVAL_BODY_BUFFERED;
}
@Override
public int doEndTag() throws JspException {
String key = bodyContent.getString().trim();
Locale locale = pageContext.getRequest().getLocale();
String message = Messages.getString(key, locale);
try {
bodyContent.getEnclosingWriter().print(message);
} catch (IOException e) {
}
return SKIP_BODY;
}
}
标签不含任何属性,所以也不需要实现任何setter方法;在doStartTag()中,由于后期需要对标签内容进行处理,所以返回EVAL_BODY_BUFFERED;主要的代码集中在doEndTag()中,当标签处理结束后首先获得标签体中的内容,然后结合获取的Locale;接着通过Messages方法获取适当的消息值,然后通过bodyContent的输出对象输出到标签内容中。
3.配置和使用标签
与RepeatTag一样,LocaleTag可以定义在MyTag.tld中,如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE taglib PUBLIC "-//Sun Microsystems, Inc.//DTD JSP Tag Library 1.1//EN" "http://java.sun.com /j2ee/dtds/web-jsptaglibrary_1_1.dtd">
<taglib>
<tlibversion>1.2</tlibversion>
<jspversion>1.1</jspversion>
<shortname>MyTag</shortname>
<uri>/mytag</uri>
...
<tag>
<name>locale</name>
<tagclass>cn.csai.web.jsp.LocaleTag</tagclass>
<bodycontent>JSP</bodycontent>
</tag>
</taglib>
该标签实现后,具有根据所给出的key值从MessageBundle中获取与客户端Locale设置对应的消息的能力。在本应用中,需要向客户端输出“你好,王先生!”或“Hello, Mr. Wang!”,需要进行多语言支持的有四个元素,分别是:“你好”和“Hello”、“,”和“,”、“王先生”和“Mr. Wang”、“!”和“!”。所以,首先需要将这四个键值添加到MessageBundle属性文件中,如表9.3所示:
表9.3 资源文件内容配置
然后在test3.jsp中的使用如下:
<%@ page language="java" contentType="text/html; charset=ISO-8859-1"
pageEncoding="ISO-8859-1"%>
<%@ taglib uri="/mytag" prefix="mytag"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<mytag:locale>hello</mytag:locale>
<mytag:locale>dh</mytag:locale>
<mytag:locale>mrWang</mytag:locale>
<mytag:locale>th</mytag:locale>
<meta http-equiv="Content-Type" content="text/html; charset=ISO-8859-1">
<title>Insert title here</title>
</head>
<body>
</body>
</html>
当把浏览器设为中文时,显示的页面如图9.20所示。
图9.20 中文Locale访问获得的test3.jsp页面
在显示中文时,可能会由于浏览器的编码识别问题产生乱码。如果出现乱码,只需要在菜单View(视图) → Encoding(编码)中选择合适的编码方式(GB2312或UTF-8)即可。
如果将浏览器设为英文,显示的页面如图9.21所示。
图9.21 英文Locale访问获得的test3.jsp页面
该例中为了使应用尽量通用化,所以将一个消息分解成了四段进行获取。实际上最简单的可以只用一个键值对(键名为message),在英文的properties文件中值设为“Hello,Mr.Wang!”,而在中文中设为“你好,王先生!”。这样在test3.jsp文件中只需要用一次mytag:locale标签就可以实现消息的多语言显示了。
4.标签处理的本质
test3.jsp转化的Servlet如下:
package org.apache.jsp;
import javax.servlet.*;
import javax.servlet.http.*;
import javax.servlet.jsp.*;
public final class test3_jsp extends org.apache.jasper.runtime.HttpJspBase
implements org.apache.jasper.runtime.JspSourceDependent {
private static final JspFactory _jspxFactory = JspFactory.getDefaultFactory();
private static java.util.List _jspx_dependants;
static {
_jspx_dependants = new java.util.ArrayList(1);
_jspx_dependants.add("/WEB-INF/MyTag.tld");
}
private org.apache.jasper.runtime.TagHandlerPool _005fjspx_005ftagPool_005fmytag_005flocale;
private javax.el.ExpressionFactory _el_expressionfactory;
private org.apache.AnnotationProcessor _jsp_annotationprocessor;
public Object getDependants() {
return _jspx_dependants;
}
public void _jspInit() {
_005fjspx_005ftagPool_005fmytag_005flocale = org.apache.jasper.runtime.TagHandlerPool.getTagHandler Pool(getServletConfig());
_el_expressionfactory = _jspxFactory.getJspApplicationContext(getServletConfig().getServletContext()). getExpressionFactory();
_jsp_annotationprocessor = (org.apache.AnnotationProcessor) getServletConfig().getServletContext(). getAttribute(org.apache.AnnotationProcessor.class.getName());
}
public void _jspDestroy() {
_005fjspx_005ftagPool_005fmytag_005flocale.release();
}
public void _jspService(HttpServletRequest request, HttpServletResponse response)
throws java.io.IOException, ServletException {
PageContext pageContext = null;
HttpSession session = null;
ServletContext application = null;
ServletConfig config = null;
JspWriter out = null;
Object page = this;
JspWriter _jspx_out = null;
PageContext _jspx_page_context = null;
try {
response.setContentType("text/html; charset=ISO-8859-1");
pageContext = _jspxFactory.getPageContext(this, request, response,
null, true, 8192, true);
_jspx_page_context = pageContext;
application = pageContext.getServletContext();
config = pageContext.getServletConfig();
session = pageContext.getSession();
out = pageContext.getOut();
_jspx_out = out;
out.write("\r\n");
out.write("\n");
out.write("<!DOCTYPE html PUBLIC \"-//W3C//DTD HTML 4.01 Transitional//EN\" \"http://www.w3. org/TR/html4/loose.dtd\">\n");
out.write("<html>\n");
out.write("<head>\r\n");
out.write("\r\n");
if (_jspx_meth_mytag_005flocale_005f0(_jspx_page_context))
return;
out.write('\r');
out.write('\n');
if (_jspx_meth_mytag_005flocale_005f1(_jspx_page_context))
return;
out.write('\r');
out.write('\n');
if (_jspx_meth_mytag_005flocale_005f2(_jspx_page_context))
return;
out.write('\r');
out.write('\n');
if (_jspx_meth_mytag_005flocale_005f3(_jspx_page_context))
return;
out.write("\r\n");
out.write("\r\n");
out.write("<meta http-equiv=\"Content-Type\" content=\"text/html; charset=ISO-8859-1\">\n");
out.write("<title>Insert title here</title>\n");
out.write("</head>\n");
out.write("<body>\n");
out.write("\n");
out.write("</body>\n");
out.write("</html>");
} catch (Throwable t) {
if (!(t instanceof SkipPageException)){
out = _jspx_out;
if (out != null && out.getBufferSize() != 0)
try { out.clearBuffer(); } catch (java.io.IOException e) {}
if (_jspx_page_context != null) _jspx_page_context.handlePageException(t);
}
} finally {
_jspxFactory.releasePageContext(_jspx_page_context);
}
}
private boolean _jspx_meth_mytag_005flocale_005f0(PageContext _jspx_page_context)
throws Throwable {
PageContext pageContext = _jspx_page_context;
JspWriter out = _jspx_page_context.getOut();
cn.csai.web.jsp.LocaleTag _jspx_th_mytag_005flocale_005f0 = (cn.csai.web.jsp.LocaleTag) _005fjspx_ 005ftagPool_005fmytag_005flocale.get(cn.csai.web.jsp.LocaleTag.class);
_jspx_th_mytag_005flocale_005f0.setPageContext(_jspx_page_context);
_jspx_th_mytag_005flocale_005f0.setParent(null);
int _jspx_eval_mytag_005flocale_005f0 = _jspx_th_mytag_005flocale_005f0.doStartTag();
if (_jspx_eval_mytag_005flocale_005f0 != javax.servlet.jsp.tagext.Tag.SKIP_BODY) {
if (_jspx_eval_mytag_005flocale_005f0 != javax.servlet.jsp.tagext.Tag.EVAL_BODY_ INCLUDE) {
out = _jspx_page_context.pushBody();
_jspx_th_mytag_005flocale_005f0.setBodyContent((javax.servlet.jsp.tagext.BodyContent) out);
_jspx_th_mytag_005flocale_005f0.doInitBody();
}
do {
out.write("hello");
int evalDoAfterBody = _jspx_th_mytag_005flocale_005f0.doAfterBody();
if (evalDoAfterBody != javax.servlet.jsp.tagext.BodyTag.EVAL_BODY_AGAIN)
break;
} while (true);
if (_jspx_eval_mytag_005flocale_005f0 != javax.servlet.jsp.tagext.Tag.EVAL_BODY_INCLUDE) {
out = _jspx_page_context.popBody();
}
}
if (_jspx_th_mytag_005flocale_005f0.doEndTag() == javax.servlet.jsp.tagext.Tag.SKIP_PAGE) {
_005fjspx_005ftagPool_005fmytag_005flocale.reuse(_jspx_th_mytag_005flocale_005f0);
return true;
}
_005fjspx_005ftagPool_005fmytag_005flocale.reuse(_jspx_th_mytag_005flocale_005f0);
return false;
}
private boolean _jspx_meth_mytag_005flocale_005f1(PageContext _jspx_page_context)
throws Throwable {
PageContext pageContext = _jspx_page_context;
JspWriter out = _jspx_page_context.getOut();
cn.csai.web.jsp.LocaleTag _jspx_th_mytag_005flocale_005f1 = (cn.csai.web.jsp.LocaleTag) _005fjspx_ 005ftagPool_005fmytag_005flocale.get(cn.csai.web.jsp.LocaleTag.class);
_jspx_th_mytag_005flocale_005f1.setPageContext(_jspx_page_context);
_jspx_th_mytag_005flocale_005f1.setParent(null);
int _jspx_eval_mytag_005flocale_005f1 = _jspx_th_mytag_005flocale_005f1.doStartTag();
if (_jspx_eval_mytag_005flocale_005f1 != javax.servlet.jsp.tagext.Tag.SKIP_BODY) {
if (_jspx_eval_mytag_005flocale_005f1 != javax.servlet.jsp.tagext.Tag.EVAL_BODY_INCLUDE) {
out = _jspx_page_context.pushBody();
_jspx_th_mytag_005flocale_005f1.setBodyContent((javax.servlet.jsp.tagext.BodyContent) out);
_jspx_th_mytag_005flocale_005f1.doInitBody();
}
do {
out.write('d');
out.write('h');
int evalDoAfterBody = _jspx_th_mytag_005flocale_005f1.doAfterBody();
if (evalDoAfterBody != javax.servlet.jsp.tagext.BodyTag.EVAL_BODY_AGAIN)
break;
} while (true);
if (_jspx_eval_mytag_005flocale_005f1 != javax.servlet.jsp.tagext.Tag.EVAL_BODY_INCLUDE) {
out = _jspx_page_context.popBody();
}
}
if (_jspx_th_mytag_005flocale_005f1.doEndTag() == javax.servlet.jsp.tagext.Tag.SKIP_PAGE) {
_005fjspx_005ftagPool_005fmytag_005flocale.reuse(_jspx_th_mytag_005flocale_005f1);
return true;
}
_005fjspx_005ftagPool_005fmytag_005flocale.reuse(_jspx_th_mytag_005flocale_005f1);
return false;
}
private boolean _jspx_meth_mytag_005flocale_005f2(PageContext _jspx_page_context)
throws Throwable {
PageContext pageContext = _jspx_page_context;
JspWriter out = _jspx_page_context.getOut();
cn.csai.web.jsp.LocaleTag _jspx_th_mytag_005flocale_005f2 = (cn.csai.web.jsp.LocaleTag) _005fjspx_ 005ftagPool_005fmytag_005flocale.get(cn.csai.web.jsp.LocaleTag.class);
_jspx_th_mytag_005flocale_005f2.setPageContext(_jspx_page_context);
_jspx_th_mytag_005flocale_005f2.setParent(null);
int _jspx_eval_mytag_005flocale_005f2 = _jspx_th_mytag_005flocale_005f2.doStartTag();
if (_jspx_eval_mytag_005flocale_005f2 != javax.servlet.jsp.tagext.Tag.SKIP_BODY) {
if (_jspx_eval_mytag_005flocale_005f2 != javax.servlet.jsp.tagext.Tag.EVAL_BODY_INCLUDE) {
out = _jspx_page_context.pushBody();
_jspx_th_mytag_005flocale_005f2.setBodyContent((javax.servlet.jsp.tagext.BodyContent) out);
_jspx_th_mytag_005flocale_005f2.doInitBody();
}
do {
out.write("mrWang");
int evalDoAfterBody = _jspx_th_mytag_005flocale_005f2.doAfterBody();
if (evalDoAfterBody != javax.servlet.jsp.tagext.BodyTag.EVAL_BODY_AGAIN)
break;
} while (true);
if (_jspx_eval_mytag_005flocale_005f2 != javax.servlet.jsp.tagext.Tag.EVAL_BODY_INCLUDE) {
out = _jspx_page_context.popBody();
}
}
if (_jspx_th_mytag_005flocale_005f2.doEndTag() == javax.servlet.jsp.tagext.Tag.SKIP_PAGE) {
_005fjspx_005ftagPool_005fmytag_005flocale.reuse(_jspx_th_mytag_005flocale_005f2);
return true;
}
_005fjspx_005ftagPool_005fmytag_005flocale.reuse(_jspx_th_mytag_005flocale_005f2);
return false;
}
private boolean _jspx_meth_mytag_005flocale_005f3(PageContext _jspx_page_context)
throws Throwable {
PageContext pageContext = _jspx_page_context;
JspWriter out = _jspx_page_context.getOut();
cn.csai.web.jsp.LocaleTag _jspx_th_mytag_005flocale_005f3 = (cn.csai.web.jsp.LocaleTag) _005fjspx_ 005ftagPool_005fmytag_005flocale.get(cn.csai.web.jsp.LocaleTag.class);
_jspx_th_mytag_005flocale_005f3.setPageContext(_jspx_page_context);
_jspx_th_mytag_005flocale_005f3.setParent(null);
int _jspx_eval_mytag_005flocale_005f3 = _jspx_th_mytag_005flocale_005f3.doStartTag();
if (_jspx_eval_mytag_005flocale_005f3 != javax.servlet.jsp.tagext.Tag.SKIP_BODY) {
if (_jspx_eval_mytag_005flocale_005f3 != javax.servlet.jsp.tagext.Tag.EVAL_BODY_INCLUDE) {
out = _jspx_page_context.pushBody();
_jspx_th_mytag_005flocale_005f3.setBodyContent((javax.servlet.jsp.tagext.BodyContent) out);
_jspx_th_mytag_005flocale_005f3.doInitBody();
}
do {
out.write('t');
out.write('h');
int evalDoAfterBody = _jspx_th_mytag_005flocale_005f3.doAfterBody();
if (evalDoAfterBody != javax.servlet.jsp.tagext.BodyTag.EVAL_BODY_AGAIN)
break;
} while (true);
if (_jspx_eval_mytag_005flocale_005f3 != javax.servlet.jsp.tagext.Tag.EVAL_BODY_INCLUDE) {
out = _jspx_page_context.popBody();
}
}
if (_jspx_th_mytag_005flocale_005f3.doEndTag() == javax.servlet.jsp.tagext.Tag.SKIP_PAGE) {
_005fjspx_005ftagPool_005fmytag_005flocale.reuse(_jspx_th_mytag_005flocale_005f3);
return true;
}
_005fjspx_005ftagPool_005fmytag_005flocale.reuse(_jspx_th_mytag_005flocale_005f3);
return false;
}
}
从代码中可以发现,由于test3.jsp使用了四个mytag:locale标签,所以在类中定义了四个标签处理方法,同时在_jspService()方法中也调用了这四个处理方法。每个处理方法中的实现内容大致相同,只是在调用out.write()方法向标签体中写入的内容不一样。
仔细分析第一个处理方法中的黑体部分可以发现:调用doStartTag()时,如果返回SKIP_BODY则不会对标签体做任何处理而是直接跳转到执行doEndTag();如果返回的不是EVAL_BODY_INCLUDE(而是EVAL_BODY_BUFFERED)才会调用BodyTag的setBodyContent()方法和doInitBody()方法,否则就直接跳转到do-while循环处理标签体和doAfterBody()方法,这正好应证了前面画的流程图。最后调用doEndTag()处理标签结束,由于LocaleTag是在doEndTag()方法中读取标签内容和写入标签新内容的,所以标签内容是在执行到这个时候才被更新的。
结合JSP文件内容、标签实现类、JSP所转换的Servlet以及前面介绍的标签处理流程图,可以非常清晰地了解JSP中对自定义标签的处理机制和流程。
本章介绍了Java Web开发中又一项重要的基础技术,JSP技术。从JSP文件的内容格式和执行JSP文件时的表现来看,很多人会认为JSP文件的执行过程是首先执行JSP文件中的Java代码,将执行完后获得的HTML文件返回给客户端;但实际上JSP的执行过程并非如此,而是JSP文件在被请求时将会被完全转化为Servlet,并通过Servlet响应客户段的请求。
为了能够使JSP文件被正确解析,程序员编辑的JSP文件必须符合JSP的语法规范。JSP定义了许多语法结构,包括:程序代码、声明代码、输出代码、注释代码、指令代码、预定义代码等。而且,为了方便代码访问HTTP请求、Web应用及Web服务器的参数和设置,JSP提供了若干隐含对象;在JSP文件中,这些对象可以直接被用来获取各种参数和设置。
自定义标签是JSP对自身系统的一种扩展。JSP的自定义标签体系包含三个级别,Tag是有明确起始位置和结束位置的标签,IterationTag是在Tag的基础上标签内容可以迭代执行的标签,BodyTag是在IterationTag的基础上可以与标签内容进行交互的标签。
本章简要介绍了Ant的基础知识,并引导没有接触过Ant的读者进入Ant的世界。在经过本章学习后读者会对Ant有一个基本的认识,并且也会为进一步学习Ant准备好了环境。对于已经对Ant有所认识并且使用过Ant的读者可以略过本章的学习。本章主要:
(1)讲述了Ant是什么以及Ant的特点,使读者对于Ant的作用以及Ant与其他类似工具的区别有简单的了解;
(2)介绍了Ant的下载、安装和配置的方法,指导读者为进一步学习Ant搭建好环境;
(3)使用一个简单的应用向读者展示如何编辑和运行Ant应用,使读者对Ant的工作方式有一个最基本的感性认识。
对于大多数Java程序员来说,在使用文本编辑器编写第一个Hello World程序时,都有如下的经历:编辑好程序后,在命令行中手动键入javac命令对程序进行编译,然后在命令行中手动键入java命令运行程序,可能还需要在不同的目录之间不断切换或经常修改环境变量CLASSPATH的设置……在学会了使用一些辅助开发工具以后,每个程序员肯定都不愿意再回去尝试这些经历。下面先来回顾一下这些经历。
目标任务:
编写一段Java程序,要求在控制台中输出Hello World,同时将class文件打包为jar文件。
操作步骤:
对于这个系统需求,典型的操作步骤如下(操作系统以Windows XP为例):
(1)新建一个目录结构用于组织项目中的文件,例如根目录位于D:\helloworld,子目录src用于存放源代码,bin用于存放class文件,output用于存放jar文件,可以直接在文件浏览器中操作,也可以通过如下批处理命令完成:
mkdir d:\helloworld
cd d:\helloworld
mkdir src bin output
(2)打开文本编辑器,编写输出Hello World的Java代码,如下:
示例10.1 HelloWorld
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello World");
}
}
将该段代码保存在src目录下的HelloWorld.java文件中;
(3)打开Windows 命令行界面,输入如下命令:
cd d:\helloworld
javac –d bin src\HelloWorld.java
该命令表示进入HelloWorld工程的根目录,然后编译源文件并将类文件放在工程根目录的bin子目录下;
(4)在Windows 命令行界面输入如下命令:
jar cvf output\HelloWorld.jar bin\*
该命令表示将bin目录下输出的所有文件打包为output目录下的HelloWorld.jar文件;
(5)运行HelloWorld.class,命令如下:
cd bin
java HelloWorld
结果输出:Hello World
读者可以发现,加上代码编辑工作,完成这个HelloWorld应用总共用了五步。对于刚开始学习Java的程序员来说,这个时候可能还不会觉得这个过程有什么不便,毕竟只用了五步就完成了第一个工程的构建。但是,假如编写的每一个Java应用都需要这五步来完成构建的话,程序员可能就无法忍受了;这时候使用一款IDE是个不错的选择,IDE工具可以帮助程序员管理文件结构、编辑代码以及运行和打包代码。但是,假如程序员是工作在一个用Java开发大型系统的Team中,Team开发的系统会由很多成员协同开发,每个成员独立开发并通过版本控制工具进行代码管理,然后定时对系统进行自动构建,这时候IDE可能就无能为力了;不过如果这个Team工作在Windows平台下,则Windows批处理可以帮助他们解决这个问题,他们可以编写一个Windows批处理文件并且定期运行以完成代码的自动构建。但是,假如这个Team又需要将系统构建的工作放到Linux平台下去完成,那他们不得不再用Shell编写一套系统构建脚本呢!维护两套脚本必然是一种资源的浪费,不过这可能是能够想出的唯一办法了!
但是,假如有了Ant,这个Team遇到的这个问题就可以迎刃而解了,因为这正是Ant出现的原因,也是Ant致力于解决的问题。
Ant是Apache又一个影响深远的开源项目,它是一种类似于make的构建工具。读者可能已经听过或者用过一些其他的构建工具,比如:make,gnumake,nmake,jam等,就功能来说Ant非常类似于它的这些同胞。但是Ant又在很多方面优于这些工具:
1.简单易学
一个Ant应用的所有内容就是一个脚本文件,Ant脚本文件是标准的XML文件,易于编写、阅读和交换,而且脚本文件的结构也很清晰,非常容易理解和记忆。另外,Ant常用任务的定义非常类似于Windows中的CMD命令和UNIX中的Shell命令,而且Ant也提供了与Java各种命令相同功能和相同名称的任务,所以对于使用过这些命令的读者来说Ant的这些任务将会非常容易理解和学习。例如,创建文件夹的脚本是:
<mkdir dir=”temp”/>
编译Java程序的脚本是:
<javac srcdir=”src”/>
2.基于Java实现,具有跨平台性
Ant的作者就是因为无法容忍其他构建工具在跨平台开发中的限制才决定开发Ant的。Ant用Java实现,天生具有Java跨平台的优势。
3.具有优秀的可扩展性
Ant体系定义了方便的接口用于扩充自己,用户只需要用Java语言编写出符合Ant提供的接口的任务和Listener,就可以直接应用于Ant脚本中。
Ant具备了这些优秀的特性,同时又随着Java的迅速发展和广泛应用,所以越来越受到程序员的青睐,Ant也正在迅速地发展壮大。
- 上一节
- 本书简介
- 下一节
Ant是Apache基金的开源软件,读者可以在Apache的官方网站上下载到Ant的各个发布版本,截至本书成稿,Ant的最新版本是Ant 1.7.0。
Ant的官方主页是http://ant.apache.org,如图10.1所示。
图10.1 Ant官方主页
在这里读者可以获得Ant的官方文档和Ant的官方下载链接,如图10.1中上面的方框为Ant官方文档链接,下面的方框为Ant官方下载链接。读者可以看到,Ant提供了两种发布形式,一种是二进制数发布(Binary Distributions),一种是源代码发布(Source Distributions)。以二进制数发布的Ant中提供了用来运行Ant应用的命令,但是没有Ant的源代码;而以源代码发布的Ant里面提供了Ant的源代码,在源代码里面也提供了运行Ant应用的脚本命令,但由于这些命令在运行时需要调用Ant的库,所以只有将源代码正确编译后这些命令才能够正常运行。所以,如果读者只是打算学习如何应用Ant,那么只需要下载Ant的二进制数发布即可;而对于需要深入学习Ant实现机制的读者,那就需要下载Ant的源代码发布进行研究。
图10.2 Ant二进制数发布下载
图10.3 Ant源代码发布下载
图10.2和图10.3分别为Ant两种发布的下载链接。两种发布都提供了三种压缩方式来打包文件,读者可以选择适合自己系统的压缩方式进行下载。
读者下载了Ant的发布版本以后,选择合适的解压方式对文件进行解压。解压后的文件内容如图10.4和图10.5所示,其中图10.4为二进制数发布的内容,图10.5为源代码发布的内容:
图10.4 Ant二进制数发布文件内容
图10.5 Ant源代码发布文件内容
两种发布版本中有些内容是一样的,其中:
(1)docs目录的内容是一样的,它是Ant的文档,基本上涵盖了Ant在线文档的内容;
(2)一些包含版本信息的文件内容也是一样的,比如:INSTALL、KEYS、LICENSE,等等;
(3)fetch.xml和get-m2.xml也是一样的,这两个文件都是Ant构建脚本,可以用来下载Ant可选任务所使用的jar文件,并且将这些文件装载到Ant可以访问到的位置,文件中的描述信息说明了具体的用法;
(4)都有lib目录,但lib目录下的内容是不一样的,源代码发布的lib目录中的内容只有二进制数发布的lib目录中内容的一部分。
二进制数发布中的各目录内容如图10.6、图10.7和图10.8所示:

图10.6 二进制数发布bin目录内容
图10.7 二进制数发布etc目录内容

图10.8 二进制数发布lib目录部分内容
bin目录中提供了在不同操作系统环境和不同运行环境下运行Ant的命令,ant和antRun是Shell命令,*.bat是MS-Dos批处理命令,*.pl是Perl脚本,*.py是Python脚本,*.cmd是Windows NT命令脚本;其中最重要的是ant.*,它被用来运行ant应用;build.xml是一个简单的用于测试的Ant脚本。
etc目录下主要是xsl文件,这些文件被用来将Ant中的一些XML文件解析成容易阅读的形式。在学习和使用Ant时,读者无须了解这些文件的细节。
lib目录下放置的全部是Ant的库文件,其中包括ant*.jar、ant*.pom、ant*.pom.md5、ant*.pom.sha1,以及libraries.properties、xercesImpl.jar、xml-apis.jar和README。其中,ant*.jar是Ant源代码编译打包成的库文件,每一个jar文件对应Ant的一个子工程,其对应的*.pom文件是描述该子工程的一个XML文件,对应的*.pom.md5是文件的md5校验码,对应的*.pom.sha1是文件的sha1(Secure Hash Algorithm 1)校验码。libraries.properties是库文件的属性文件,主要记录了各个库的版本号;xercesImpl.jar和xml-apis.jar是Ant调用的第三方库,主要用于对XML文件处理。
源代码发布中的目录内容如图10.9和图10.10所示:

图10.9 源代码发布src目录内容

图10.10 源代码发布lib目录内容
src目录中主要是Ant的所有源代码以及源代码编译和运行时需要的一些资源文件,其中main目录中是Ant的Java代码;另外,二进制数发布的bin目录中包含的那些Ant命令文件在这里作为脚本文件放置在script目录中;etc目录中的内容也与二进制数发布中的etc目录相似。
由于源代码发布中已经包含了源代码,所以lib目录中就没有Ant源代码编译打包的那些ant*.jar文件,只有第三方库文件。
另外,在源代码发布的根目录中还有几个文件在二进制数发布中是没有的:bootstrap.bat、bootstrap.sh、build.bat、build.sh、build.xml。这几个文件用于构建发布的Ant源代码,并将其打包为jar文件,读者可以在命令行中进入该目录并输入bootstrap命令或build命令就可以完成对源代码的构建,并可以在当前目录的build目录中找到Ant的各个jar文件。
读者现在已经获得了Ant的发布版本,并且也了解了发布版本中各个文件的作用,那接下来就可以进行安装和配置了。下面所进行的工作都是基于二进制数发布版本的,源代码发布版本读者可以自行研究和学习。
版权方授权希赛网发布,侵权必究在安装和配置Ant之前,首先要求系统中已正确地安装和配置了JDK。对于JDK的安装和配置请参考相关手册,本书这里不再详细说明,以下假定系统中已安装并配置了JDK。
Ant的安装和配置比较简单,只需将以上介绍的二进制数发布解压到本地文件系统,并对系统相关环境变量做适当设置即可。Windows中打开环境变量设置窗口的方法如下:鼠标右键单击“我的电脑”→选择“属性”,在弹出的窗口选择“高级”属性;如图10.11 a)所示,点击图中方框所示的“环境变量”按钮,弹出环境变量设置窗口,如图10.11 b)所示:
a)高级系统属性设置窗口
b)环境变量设置窗口
图10.11 设置环境变量
在环境变量设置窗口中共需要设置两个环境变量:ANT_HOME和Path。如图1.12所示:
a)新建ANT_HOME环境变量
b)编辑Path环境变量
图10.12 设置环境变量
假如系统中以前没有配置过Ant,那么ANT_HOME环境变量是不存在的,所以需要新建一个ANT_HOME环境变量,如图10.12 a)所示。步骤为:点击图10.11 b)中的“新建”按钮,在弹出的“新建系统变量”对话框的变量名输入框中输入ANT_HOME,在变量值输入框中输入Ant在系统中的安装路径,即D:\ant。
而Path环境变量是操作系统定义的,肯定是已经存在的,所以需要找到该环境变量并编辑其变量值,如图10.12 b)所示。步骤为:点击图10.11 b)中的“编辑”按钮,在弹出的“编辑系统变量”对话框的变量值输入框的最前面加上Ant安装目录中bin目录的路径,即D:\ant\bin,这是绝对路径表示,也可以使用相对路径表示,即%ANT_HOME%\bin,并且用分号与后面内容隔开。
配置ANT_HOME环境变量的原因是:在执行Ant命令时,Ant批处理脚本需要从环境变量中读取该变量值,从中获得Ant的安装路径,进而调用安装路径中的Ant库来运行应用。而且,假如系统中安装了多个版本的Ant,那么将哪个版本Ant的安装路径设置到该环境变量中,那么在命令行中使用Ant命令时就使用该版本的Ant运行应用。将Ant的bin目录添加到Path环境变量中的目的是为了方便使用Ant命令,假如不做该设置那么每次在命令行环境下运行Ant应用时必须将当前路径切换到Ant的bin目录下才能使用Ant命令,而做了该设置后可以在任意目录下使用Ant命令。
Ant的安装和配置比较简单,到此Ant的安装和配置就已经完成了。为了验证安装和配置是否正确,可以运行一个Ant命令进行测试:打开系统的命令行窗口,输入ant – version。该命令用于查看当前配置到系统中的Ant的版本号,如果输出的结果是Apache Ant version 1.7.0,如图10.13所示,说明Ant已经正确安装和配置到系统中。
图10.13 验证Ant的安装和配置
版权方授权希赛网发布,侵权必究- 上一节
- 本书简介
- 下一节
在安装和配置Ant之前,首先要求系统中已正确地安装和配置了JDK。对于JDK的安装和配置请参考相关手册,本书这里不再详细说明,以下假定系统中已安装并配置了JDK。
Ant的安装和配置比较简单,只需将以上介绍的二进制数发布解压到本地文件系统,并对系统相关环境变量做适当设置即可。Windows中打开环境变量设置窗口的方法如下:鼠标右键单击“我的电脑”→选择“属性”,在弹出的窗口选择“高级”属性;如图10.11 a)所示,点击图中方框所示的“环境变量”按钮,弹出环境变量设置窗口,如图10.11 b)所示:
a)高级系统属性设置窗口
b)环境变量设置窗口
图10.11 设置环境变量
在环境变量设置窗口中共需要设置两个环境变量:ANT_HOME和Path。如图1.12所示:
a)新建ANT_HOME环境变量
b)编辑Path环境变量
图10.12 设置环境变量
假如系统中以前没有配置过Ant,那么ANT_HOME环境变量是不存在的,所以需要新建一个ANT_HOME环境变量,如图10.12 a)所示。步骤为:点击图10.11 b)中的“新建”按钮,在弹出的“新建系统变量”对话框的变量名输入框中输入ANT_HOME,在变量值输入框中输入Ant在系统中的安装路径,即D:\ant。
而Path环境变量是操作系统定义的,肯定是已经存在的,所以需要找到该环境变量并编辑其变量值,如图10.12 b)所示。步骤为:点击图10.11 b)中的“编辑”按钮,在弹出的“编辑系统变量”对话框的变量值输入框的最前面加上Ant安装目录中bin目录的路径,即D:\ant\bin,这是绝对路径表示,也可以使用相对路径表示,即%ANT_HOME%\bin,并且用分号与后面内容隔开。
配置ANT_HOME环境变量的原因是:在执行Ant命令时,Ant批处理脚本需要从环境变量中读取该变量值,从中获得Ant的安装路径,进而调用安装路径中的Ant库来运行应用。而且,假如系统中安装了多个版本的Ant,那么将哪个版本Ant的安装路径设置到该环境变量中,那么在命令行中使用Ant命令时就使用该版本的Ant运行应用。将Ant的bin目录添加到Path环境变量中的目的是为了方便使用Ant命令,假如不做该设置那么每次在命令行环境下运行Ant应用时必须将当前路径切换到Ant的bin目录下才能使用Ant命令,而做了该设置后可以在任意目录下使用Ant命令。
Ant的安装和配置比较简单,到此Ant的安装和配置就已经完成了。为了验证安装和配置是否正确,可以运行一个Ant命令进行测试:打开系统的命令行窗口,输入ant – version。该命令用于查看当前配置到系统中的Ant的版本号,如果输出的结果是Apache Ant version 1.7.0,如图10.13所示,说明Ant已经正确安装和配置到系统中。
图10.13 验证Ant的安装和配置
版权方授权希赛网发布,侵权必究本章为Ant初学者提供了入门指导,主要引导读者对Ant进行下载、安装和配置,并最后用一个简单的实例向读者展示了一个完整的Ant应用的开发过程。
Ant是Apache基于Java开发的一个开源的系统构建工具,它可以帮助程序员自动地完成诸如编译、打包等系统构建工作。读者可以在Ant的官方主页上下载到Ant的发布版本,发布版本有二进制数发布和源代码发布两种;Ant的安装配置比较简单,只需要将二进制数发布文件解压缩到本地,并且适当配置ANT_HOME和Path环境变量即可。
Ant应用的工作由构建脚本描述,构建脚本通常为build.xml,它是一个标准的XML文件,该文件的根元素为project,代表一个Ant工程,project元素中包含若干target元素,每个代表一个构建目标,target之间通过depends属性描述相互的依赖关系,默认执行的target由project元素的default属性指定。
第10章中已经提到了Ant构建脚本是Ant应用的核心,一个Ant应用的全部工作都通过一个Ant构建脚本来描述。Ant构建脚本是一个标准的XML文件,通常文件名为build.xml,文件内容符合Ant构建脚本的结构要求。本章将介绍Ant构建脚本的编写,着重从比较高的层次描述Ant构建脚本的结构;进而描述在编写完Ant构建脚本后如何运行Ant应用。本章假定读者已经对XML有所了解,如果读者对XML还比较陌生,请提前简单了解一下XML的基础知识。
Ant脚本是一个标准的XML文件,Ant脚本默认的文件名为build.xml,不过读者也可以使用其他名称来命名它。使用XML描述脚本是Ant区别于其他脚本语言的一个显著特点。XML的易用性使得Ant脚本非常易于编写和理解,而同时XML良好的扩展性又使得Ant脚本非常灵活。XML的语法结构和格式是固定的,所以学习编写Ant脚本的重点就是熟悉脚本文件的结构以及熟悉各种任务的使用方式。本节主要介绍脚本文件的总体结构,具体的各种任务的使用方式会在后面章节中详细介绍。
版权方授权希赛网发布,侵权必究Ant脚本的根元素是project,该元素中可以包含description元素、target元素、property元素和任何Task;target元素中也可以包含若干Task。Ant脚本的总体结构如图11.1所示。
其中:
(1)project元素是Ant构建文件的根元素,它表示一个Ant工程,也就是该Ant脚本所定义的工程。在一个Ant构建脚本中只能有一个project元素,并且该元素必须为根元素。project元素可以定义的属性如表11.1所示:
图11.1 Ant脚本结构图
表11.1 project元素属性表

【提示】
对Ant脚本中元素的讲解都会涉及对元素的属性进行描述,故本书后面将沿用如上表所示的格形式进行说明。
(2)description元素是对工程的描述,该元素可以包含一段文字;该元素只是为了方便程序员理解该工程的作用,在运行Ant脚本时不会产生任何影响,相当于注释。一个project元素中可以包含若干个description元素。
(3)target元素表示工程中的一个执行目标,它是对一系列task的归整;一个target中可以定义若干个task;通常一个project会定义一个默认执行的target,然后target通过depends属性定义各target之间的依赖关系。
(4)tasks是一系列Ant Task。每个Task都是一个可执行的任务,它可以完成一个特定的功能。在project元素下面出现的Task称为全局Task,在Target中出现的Task称为局部Task。Ant定义了许多不同类型的Task,用于执行不同类型的操作,同一种Task可以作为全局Task也可以作为局部Task。
(5)properties是定义的一系列property元素,每个property元素用于定义一个属性(或称变量),在定义时可以为属性赋值,并且使用${var}来获取属性的值。
一个Ant脚本定义了一个project元素,在project中可以定义description元素,它用于描述工程的信息,对Ant脚本的执行不造成任何影响。除此之外主要还是定义了若干全局Task和若干包含Task的Target。不管是全局Task还是包含于Target中的局部Task,都是Ant定义的可以完成一定功能的任务。project元素的default属性允许指定一个Target名称作为默认执行的Target,即当执行构建脚本时默认执行该Target。
版权方授权希赛网发布,侵权必究Task是构成Ant脚本的原子,除了全局Task外其他Task都是通过Target组织起来的。Target是一个比Task更高级的功能集合,其中可以定义任意Task。Target的depends属性规定了Target之间的依赖关系。结合project元素的default属性和Target属性的depends属性,一个工程中的Task就被组织成一个执行链,执行链的最后一个节点是project元素default属性所指定的Target。
project元素的default属性只允许定义一个target,而target的depends属性允许定义多个target,同一个Target也可以被多个Target依赖。所以,Ant构建脚本的执行链是一个由Target构成的有向无环图,图中只有一个没有出边的节点,这个节点就是default Target,图中所有没有入边的节点就是不依赖于任何Target的Target。而对于全局Task来说,它们永远是先于任何一个Target执行,而且全局Task之间的执行先后顺序取决于它们在脚本中的先后顺序,排在前面的先执行。
示例11.1给出了一个Ant脚本:
示例11.1
<?xml version="1.0" encoding="UTF-8"?>
<project default="root">
<target name="root" depends="t1,t2">
<echo>run root</echo>
</target>
<target name="t1" depends="t3">
<echo>run t1</echo>
</target>
<target name="t2" depends="t3,t4">
<echo>run t2</echo>
</target>
<target name="t3" depends="t4">
<echo>run t3</echo>
</target>
<target name="t4">
<echo>run t4</echo>
</target>
<echo>run global1</echo>
<echo>run global2</echo>
</project>
执行结果如下:
[echo] run global1
[echo] run global2
t4:
[echo] run t4
t3:
[echo] run t3
t1:
[echo] run t1
t2:
[echo] run t2
root:
[echo] run root
该构建脚本中各Target之间的依赖关系如图11.2所示:
图11.2 示例11.1的各Target依赖关系图
图11.2中上面虚框里表示全局Task,下面虚框是定义的各个Target,其中root是default Target,其他各Target的箭头指示了它们之间的依赖关系。在执行该构建脚本时,首先default Target被执行,然后根据依赖关系,从上向下执行,最后执行default Target。
Target的depends属性只定义了一种Target之间的依赖关系,并不是所有在脚本中定义的Target都会被执行,即使它定义了depends属性也不一定全被执行。在构建脚本被运行时,有且只有存在于default Target的依赖链中的Target才会被执行。除非在运行脚本时明确指定了执行某个Target。
当一个Target依赖于两个之间没有依赖关系的Target时,这两个被依赖的Target的执行顺序依赖于它们在属性值中的先后顺序,Tomcat尽量让写在前面的先于写在后面的执行。例如:
<target depends="target1,target2"> ... </target>
Ant会尽量保证让target1先于target2执行,除非target1依赖于target2。
除此之外,target元素还提供了if和unless属性,属性值是一个变量。例如:
<target if="var"> ... </target>
表示当变量var被设置时该Target才会被执行,否则该Target将不被执行,即使该Target被其他Target所依赖。而:
<target unless="var"> ... </target>
则刚好相反,它表示当变量var被设置时该Target就不执行,否则执行该Target。
值得注意的是,if和unless仅能够控制设置该属性的Target,而该Target依赖的和依赖于该Target的Target不会受到影响。
target元素的属性如表11.2所示:
表11.2 target元素属性表
 版权方授权希赛网发布,侵权必究
版权方授权希赛网发布,侵权必究一个Task是一段可执行的代码,也是由一个元素表示,元素的名称就是该Task的名称;不同的Task中可以定义不同的属性列表。Task的通用结构如下:
<name attribute1="value1" attribute2="value2" ... />
或
<name attribute1="value1" attribute2="value2" ... >
...
</name>
其中,name是Task的名称,不同名称的Task用于完成不同的工作,而且其定义的属性也不同。Task的属性根据attribute="value"的格式进行定义,attribute是属性名,value是属性值。
Ant定义了许多内建的Task,每个Task都有明确的功能和定义。同时,开发人员也可以使用Java语言自行开发Task,自行开发的Task也可以同内建Task一样使用。
版权方授权希赛网发布,侵权必究Property表示属性,它可以定义一个变量。在project元素中或Target中都可以定义property元素,在project元素中定义的属性其作用域是整个构建脚本,而在Target中定义的属性则只在当前Target中有效。例如:
示例11.2
<?xml version="1.0" encoding="UTF-8"?>
<project default="root">
<target name="root">
<property name="data" value="dataValue" />
<echo>${data}</echo>
</target>
<echo>${data}</echo>
</project>
执行结果:
[echo] ${data}
root:
[echo] dataValue
在root Target中定义的data变量,只在root Target中有效,所以在root Target中echo输出改变量时可以获得变量值,而在root Target以外输出时,就无法获得该属性。
上例也说明了如何在脚本中引用一个属性:无论是在元素的文本内容中还是在元素属性值中,使用${var}都表示用var属性的值替换该位置。例如:
示例11.3
<?xml version="1.0" encoding="UTF-8"?>
<property name="Given-name" value="Kevin" />
<property name="Family-name" value="Lee" />
<property name="Full-name" value="${Given-name} ${Family-name}" />
<echo>${Given-name}</echo>
<echo>${Family-name}</echo>
<echo>${Full-name}</echo>
执行结果为:
[echo] Kevin
[echo] Lee
[echo] Kevin Lee
正因为$被用来获得对属性的引用,所以$在这里被用作转义字符,当需要在构建脚本中使用$字符本身时,需要用$$来表示。例如:
示例11.4
<?xml version="1.0" encoding="UTF-8"?>
<property name="Given-name" value="Kevin" />
<echo>${Given-name}</echo>
<echo>$${Given-name}</echo>
执行结果为:
[echo] Kevin
[echo] ${Given-name}
为了方便获得系统信息,Ant定义了一些内建属性,通过这些属性构建脚本可以获得与运行环境相关的信息,构建脚本中可以直接使用这些属性就像这些属性已经被定义和赋值了一样。这些内建属性如表11.3所示。
表11.3 Ant的内建属性
 版权方授权希赛网发布,侵权必究
版权方授权希赛网发布,侵权必究在Ant的发布内容中提供了执行Ant脚本的ant.bat、ant.cmd和ant Shell脚本。它们分别用于在不同操作系统中运行Ant脚本。在将Ant安装好后,读者可以直接使用Ant命令运行Ant脚本。
Ant构建脚本的默认名称是build.xml,所以假如在命令行中只键入Ant命令的话,Ant会自动在当前目录中寻找build.xml,如果当前目录中有build.xml文件那么该文件就会被执行,否则就会报告没有找到build.xml文件的错误。如图11.3所示。
如果需要执行的Ant脚本不是build.xml,那么就需要将该脚本的名称添加到Ant命令后,如下所示:
ant –f another.xml
该命令会执行当前目录下的another.xml。
图11.3 在不包含build.xml文件的目录中执行Ant命令
如果只需要执行Ant脚本中的某一个特定的Target,而不是根据project元素的default属性和各Target元素的depends属性构成的执行链执行的话,可以在Ant命令后直接加上待执行Target的名称,可以在一条命令中添加多个Target,如下:
ant t1 t2 t3
该命令会执行当前目录下build.xml脚本中的t1,t2和t3 Target,以及所有全局Task。
ant –f another.xml t1 t2 t3
该命令会执行当前目录下another.xml脚本中的t1,t2和t3 Target,以及所有的全局Task。
ant命令的一般格式如下:
ant [options] [target [target2 [target3] ...]]
其中,[target [target2 [target3] …]]表示待执行的Target,可以是任意多个,之间用空格隔开;options是可选配置项,可分别取如下值:
(1)–help | -h:
打印关于Ant命令用法的帮助信息,如图11.4所示。
图11.4 使用-help配置项查看帮助信息
(2)-projecthelp | -p
打印工程的基本信息,包括工程中的全局Task、有哪些Target、default Target有哪些等,如图11.5所示。
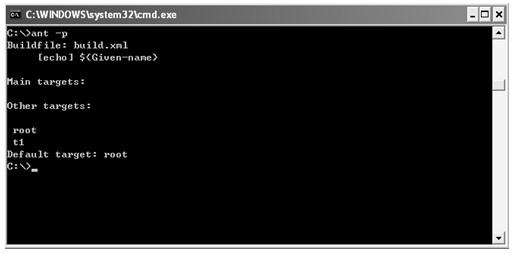
图11.5 添加-p配置项的执行效果
(3)-version
打印Ant版本信息并退出,如图11.6所示。
图11.6 使用-version配置项查看版本信息
(4)-diagnostics
打印可以帮助诊断和报告错误的系统信息,包括Ant的版本、Ant系统内建属性的值、Ant库、Java系统的属性、计算机的属性等。如图11.7所示。
图11.7 使用-diagnostics配置项查看诊断信息
(5)-quiet | -q
让构建脚本安静的执行,即打印尽可能少的信息到输出终端,只打印Task的输出信息和重要的出错信息,如图11.8所示。

图11.8 添加-q配置项的执行效果
(6)-verbose | -v
尽量详细的执行脚本,即打印尽可能详细的信息到输出终端,如图11.9所示。
图11.9 添加-v配置项的执行效果
(7)-debug | -d
执行脚本时打印调试信息,调试信息比使用-v打印的详细信息提供了更丰富的信息,如图11.10所示。
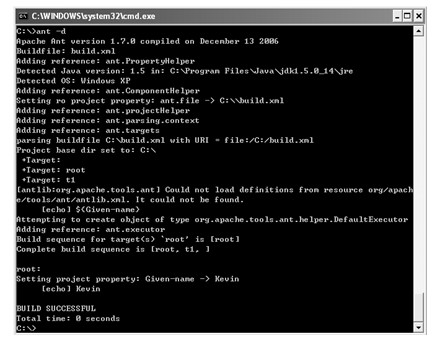
图11.10 添加-d配置项的执行效果
(8)-emacs, -e
对打印的信息不做任何修饰,如图11.11所示。
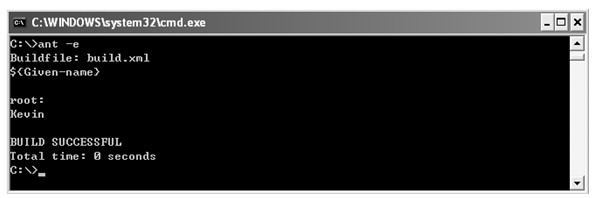
图11.11 添加-e配置项的执行效果
(9)-lib <path>
指定一个搜索库文件的路径,包括jar文件和class文件。
(10)-logfile | -l <file>
使用指定的文件记录日志。
(11)-logger <classname>
指定进行日志记录的类。
(12)-listener <classname>
指定一个类,将该类的实例添加为工程的一个监听器。
(13)-noinput
不允许输入交互性质的输入。
(14)-buildfile|-file|-f <file>
不运行默认的build.xml构建文件,而运行指定的构建文件。
(15)-D<property>=<value>
将指定值作为指定属性的值,类似于在运行构建脚本时输入参数。
(16)-keep-going, -k
在执行过程中,如果在运行某个Target时出错,那么继续执行剩余的所有不依赖于出错Target的Target。
(17)-propertyfile <name>
指定一个属性文件,从文件中装载所有属性的值,但假如还使用-D指定了相同的属性,则-D指定的属性值具有更高的优先级。
(18)-inputhandler <class>
指定一个类,使用该类处理输入请求。
(19)-find | -s <file>
从当前目录逐级向上级目录搜索指定的构建文件直到文件系统的根目录。如果没有指定<file>则搜索build.xml,搜索到构建文件后执行构建文件。
(20)-nice number
设置Ant主线程的优先级,0为最低,10为最高,默认是5。
(21)-nouserlib
运行脚本的时候不使用用户目录库中的jar文件。
(22)-noclasspath
运行脚本的时候不使用类路径。
(23)-autoproxy
在Java 1.5以上的运行环境中,该设置在运行Ant脚本时自动使用操作系统配置的代理服务器。
(24)-main <class>
指定一个提供主函数的类,该主函数将覆盖Ant的常规主函数,提供新的运行入口点。
版权方授权希赛网发布,侵权必究Eclipse默认提供了对Ant的支持,在Eclipse中不需要安装任何插件就可以直接编辑和运行Ant。Eclipse中包含了一个Ant脚本编辑器,Ant脚本编辑器提供了对Ant脚本的语法高亮、自动补全、根据模板生成代码等功能。另外,Eclipse还提供了一个Ant视图,该视图提供了对工作空间中Ant脚本的查看、内容查找、执行等功能。本章将主要介绍在Eclipse中如何配置Ant、编辑和运行Ant脚本。
在Eclipse发布的版本中包含了用于执行Ant脚本的jar包,不同版本的Eclipse所附带的Ant版本也不同,Eclipse 3.3.1附带的Ant版本是1.7。在正确安装了Eclipse后,不需要任何配置就可以直接在Eclipse中编辑和运行Ant脚本。为了给开发人员提供定制,Eclipse也为Ant开发插件提供了简单的配置。
打开Eclipse菜单Window→Preferences,在左边的列表中就可以发现对Ant的配置项,如图12.1所示。
图12.1 Eclipse中Ant配置页
如图12.1中所示是Ant的通用配置,其中Names定义了Ant脚本的默认名称,默认是build.xml;Separate JRE timeout(ms)定义了独立的JRE运行的超时时间,默认是20秒;Documentation URL定义了Ant文档的位置,默认是链接到Ant官方主页上的Ant文档。下面几个复选框的含义上面都有详细的说明。此外,还可以设置Ant的各种消息(error、warning、information、verbose和debug)在控制台中打印出来时所使用的颜色。
Editor提供了对Ant脚本编辑器的配置,在其中可以定义各种语法元素在编辑器中显示的颜色,如图12.2所示。
图12.2 Editor配置页
配置Ant编辑器的内容帮助功能,如图12.3所示。
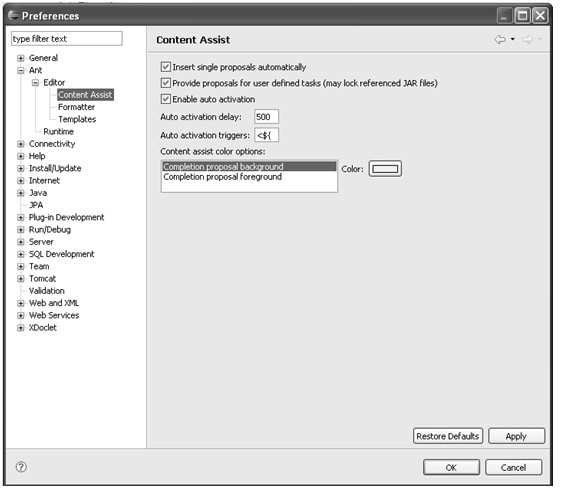
图12.3 Content Assist配置页
为Ant脚本定义格式,这样在Ant编辑器中使用Format命令时就能够根据定义的格式将Ant脚本进行格式化,如图12.4所示。
图12.4 Formatter配置页
定义和修改一些模板,这样在编辑器中使用内容帮助时就可以通过选择模板在脚本中添加一段代码,如图12.5所示。
图12.5 Templates配置页
这些设置项与前面介绍的对HTML编辑器、JSP编辑器的设置都非常相似,具体的配置方法读者可以参照前面的介绍以及Eclipse中配置界面中的文字进行实际操作。
Runtime提供了对Ant运行时环境的配置,在其中可以配置所使用的Ant根路径,默认是Eclipse自带的Ant;还可以向其中配置全局属性或全局属性文件等,如图12.6所示。
图12.6 Runtime配置页
版权方授权希赛网发布,侵权必究Eclipse对Ant的支持主要就表现在对编辑和运行Ant脚本提供了支持。Eclipse为Ant脚本提供了一种编辑器,在编辑器中编辑Ant脚本时Eclipse会提供内容帮助功能。除此之外,在Eclipse中还可以直接运行Ant脚本,而不需要到命令行窗口中通过Ant命令运行。

Ant脚本表现为一个XML文件。在工程中添加Ant脚本时,首先需要在工程的某个目录(一般为工程根目录)中新建一个XML文件,在工程的目录上点击鼠标右键在弹出菜单中选择New→Other...,如图12.7所示。
在弹出窗口中选择XML文件夹中的XML,在弹出对话框中输入Ant脚本的文件名,如图12.8所示。
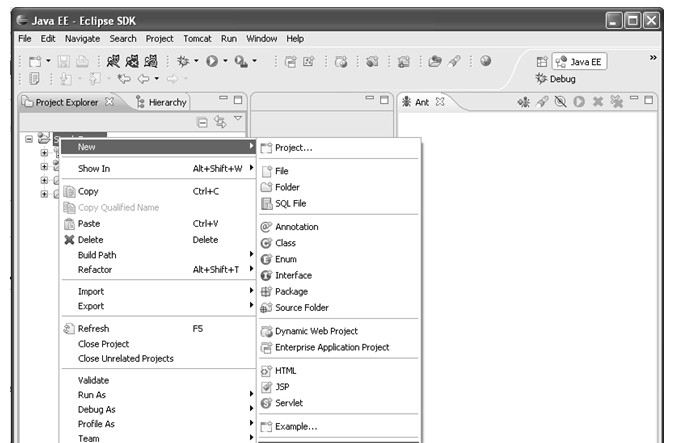

图12.7 新建XML文件向导

图12.8 输入XML文件名称
点击Finish按钮就完成了脚本文件的新建向导。由于Ant脚本只是一个XML文件,所以Eclipse并没有为Ant脚本提供单独的新建向导,而是采用了XML文件的向导。在新建向导完成后,Eclipse也只是使用一个XML编辑器打开新建的文件,而不是Ant脚本编辑器(默认只有文件名为build.xml的XML文件才会自动用Ant脚本编辑器打开)。可以根据所打开文件的标签页的图标区分当前打开的是XML编辑器还是Ant脚本编辑器,使用XML编辑器打开文件时标签的图标和使用Ant脚本编辑器打开文件时标签的图标,如图12.9所示。
a)XML编辑器的图标
图12.9 XML编辑器和Ant脚本编辑器
可以在工程浏览器视图中的文件上使用右键菜单选择打开方式,如图12.10所示。
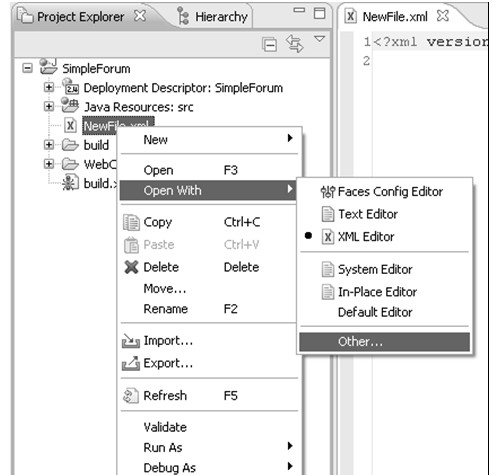
图12.10 改变文件打开方式
选择Other...打开选择编辑器对话框,从中选择Ant编辑器,确定后就会使用Ant脚本编辑器打开该XML文件,如图12.11所示。
图12.11 选择文件的打开方式
Ant编辑器也是文本编辑器的一种,程序员可以完全手动地将Ant脚本的所有内容直接键入到文本编辑器中。Ant编辑器在普通文本编辑器的基础上增加了以下针对于编辑Ant脚本的功能。
1.自动语法校验,实时将语法错误标红。
a)错误语法实时标红
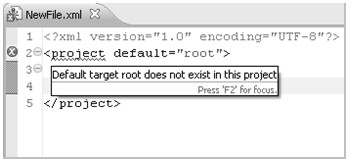
b)鼠标悬停显示错误原因
图12.12 自动语法校验
如图12.12所示,在project元素中定义的default Target并没有在脚本中定义,编辑器就会自动在project元素下方标红;如果将鼠标悬浮在该红线处,Ant编辑器还会给出该错误的原因。
2.在脚本的任意位置激活内容帮助,都会获得适当的内容帮助选项。例如:在元素内激活内容帮助可以获得一个候选列表,其中包括能够作为当前元素子元素的元素和在Ant设置中预定义的所有模板;在元素的属性定义处激活内容帮助可以获得该元素的属性列表;在输入属性时激活内容帮助可以获得当前位置可用的所有属性,如图12.13和图12.15所示。
图12.13 元素内激活内容帮助
图12.14 属性定义处激活内容帮助
图12.15 在输入属性时激活内容帮助
3.根据预定义的格式,格式化Ant脚本的内容。图12.16为编辑的格式不良好的Ant脚本内容:
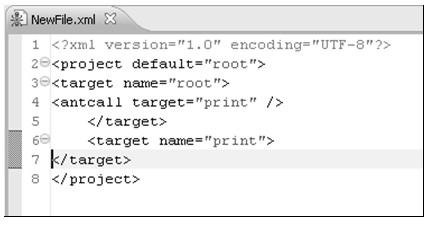
图12.16 格式混乱的脚本
将光标置于脚本中,然后调用格式化命令(Ctrl+Shift+F,或菜单Edit→Format)后,Ant编辑器会根据在Ant设置中定义的脚本格式对当前脚本内容进行格式化,使用默认的格式化设置进行格式化后的脚本内容如图12.17所示。
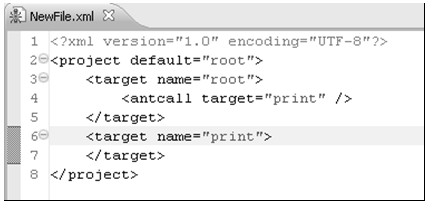
图12.17 格式化后的脚本
在Eclipse中运行Ant脚本非常简单,只需要在待运行的Ant脚本上点击鼠标右键,选择Run As → 2 Ant Build,Ant脚本就会自动执行,如图12.18所示。
图12.18 使用右键运行Ant脚本
Ant编辑器还提供了调试Ant脚本执行的功能,调试的方式与调试Java程序一样。首先在Ant脚本中添加断点,然后在右键菜单中选择Debug As → 2 Ant Build。调试时使用的透视图也是Debug透视图,在调试过程中可以在Variables视图中查看所有系统属性和用户定义属性的值,如图12.19所示:
其中Runtime Properties包含的就是在Ant脚本中定义的属性,例如userDefined属性就是脚本中定义的属性。
调试时使用的Step into、Step over、Step return等操作都与调试Java程序时的含义相同。
图12.19 调试Ant脚本时的Variables视图
GZip和BZip2是两个独立的任务,但是这两个任务的功能和属性类似。GZip使用GZip算法对文件进行打包;BZip2使用BZip2算法对文件进行打包。值得注意的是,假如打包生成的输出文件已存在并且待打包的文件不比输出文件新,那么该任务将不会进行打包动作。
这两个任务所拥有的属性是一样的,如表13.1所示。
表13.1 GZip/BZip2元素属性表

示例:
<gzip src="test.tar" destfile="test.tar.gz"/>
使用GZip算法将test.tar打包为test.tar.gz。
<bzip2 src="test.tar" destfile="test.tar.bz2"/>
使用BZip2算法将test.tar打包为test.tar.bz2。
<gzip destfile="archive.tar.gz">
<url url="http://example.org/archive.tar"/>
</gzip>
使用GZip算法将URL为http://example.org/archive.tar的文件打包为archive.tar.gz。
恰好与GZip和BZip2相反,这两个任务用于将使用GZip和BZip2算法打包的文件进行解包,属性如表13.2所示。
表13.2 GUnzip/BUnzip2元素属性表

如果dest指定的是一个文件,那么输出文件就是指定的文件;如果dest指定的是一个目录,那么目标文件将使用源文件的名称,如果源文件名有.gz或.bz2后缀,则去掉后缀;如果没有指定dest属性,那么输出文件将被输出到与源文件同一个目录下。
同GZip和BZip2一样,假如指定的输出文件已存在并且源文件不比输出文件新,那么GUnzip和BUnzip2将不进行解包动作。
示例:
<gunzip src="test.tar.gz"/>
使用GZip算法解压test.tar.gz文件,输出文件与test.tar.gz在同一个目录下,文件名为test.tar。
<bunzip2 src="test.tar.bz2"/>
使用BZip2算法解压test.tar.bz2文件,输出文件与test.tar.bz2在同一个目录下,文件名为test.tar。
<gunzip src="test.tar.gz" dest="test2.tar"/>
使用GZip算法解压test.tar.gz文件,输出文件与test.tar.gz在同一个目录下,文件名为test2.tar。
<gunzip src="test.tar.gz" dest="subdir"/>
使用GZip算法解压test.tar.gz文件,输出文件在subdir目录下,文件名为test.tar。
<gunzip dest=".">
<url url="http://example.org/archive.tar.gz"/>
</gunzip>
使用GZip算法解压URL http://example.org/archive.tar.gz指向的文件,输出文件在当前目录下,文件名为archive.tar。
该任务用于创建一个Zip文件包。
属性如表13.3所示。
表13.3 Zip元素属性表


文件的访问权限不会被保存到Zip文件中。baseDir用于指定待打包的文件目录,默认情况下,zip任务根据默认的过滤规则将baseDir中符合条件的文件和文件夹打包到Zip文件中;同时,includes、includesfile、excludes和excludesfile属性允许开发人员提供文件模板,如果提供了includes或includesfile属性,那么就只将符合所提供文件模板的文件包含进来,如果提供了excludes或excludesfile属性,那么就将除符合所提供文件模板的文件以外的文件包含进来。
嵌套元素:
fileset
用于指定待打包的文件集合,fileset可以用于指定一个文件集合。
示例:
<zip destfile="${dist}/manual.zip" basedir="htdocs/manual"/>
将htdocs/manual目录下的所有文件打包到${dist}目录下的manual.zip文件。
<zip destfile="${dist}/manual.zip" basedir="htdocs/manual" update="true"/>
将htdocs/manual目录下的所有文件打包到${dist}目录下的manual.zip文件,如果manual.zip文件不存在则创建它,否则用新文件替换。
<zip destfile="${dist}/manual.zip" basedir="htdocs/manual" excludes="mydocs/**, **/todo.html" />
将htdocs/manual目录下的所有文件打包到${dist}目录下的manual.zip文件,除了mydocs目录下的文件和文件名为todo.html的文件。
<zip destfile="${dist}/manual.zip" basedir="htdocs/manual" ncludes="api/**/*.html" excludes="** /todo. html" />
打包htdocs/manual目录中的文件,仅包含api目录(包括子目录)中的html文件,并且除过文件名为todo.html的文件
<zip destfile="${dist}/manual.zip">
<fileset dir="htdocs/manual"/>
<fileset dir="." includes="ChangeLog.txt"/>
</zip>
将目录htdocs/manual中的所有文件和当前目录下的ChangeLog.txt文件打包到${dist}/manual.zip文件。打包后,ChangeLog.txt文件将会在Zip文件的顶级目录中。
该任务用于将文件集合打包为jar文件。
属性如表13.4所示。
表13.4 Jar元素属性表



可以发现,jar任务同zip任务的属性很类似,因为jar文件和zip文件比较类似。
嵌套元素:
metainf:
指定一个文件集合。所有在这里指定的文件都将被放置在jar文件的META-INF目录中,如果指定的文件中包含名为MANIFEST.MF文件,那么该文件将被忽略,同时会提示警告。
manifest:
该元素允许将manifest文件中的内容内嵌到脚本中,而不用另外指定一个manifest文件。如果这里使用了内嵌的脚本又指定了manifest文件,那么两个内容会被合并。
indexjars
见jar任务的index属性。
用于将文件打包为一个tar文件。
属性如表13.5所示。
表13.5 Tar元素属性表
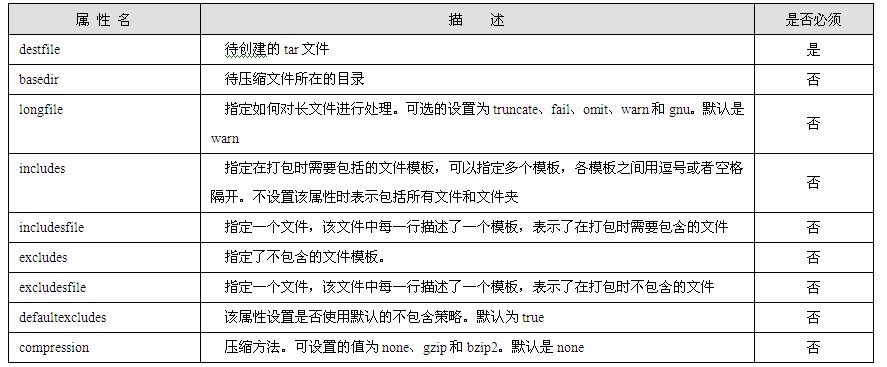
嵌套元素:
tarfileset:
该元素是fileset元素的扩展,它额外添加了属性,如表13.6所示。
表13.6 arfileset元素属性表

示例:
<tar destfile="/Users/antoine/dev/asf/ant-core/docs.tar">
<tarfileset dir="${dir.src}/docs" fullpath="/usr/doc/ant/README" preserveLeadingSlashes="true">
<include name="readme.txt"/>
</tarfileset>
<tarfileset dir="${dir.src}/docs" prefix="/usr/doc/ant" preserveLeadingSlashes="true">
<include name="*.html"/>
</tarfileset>
</tar>
将${dir.src}/docs目录下的文件打包到/Users/antoine/dev/asf/ant-core/docs.tar文件中,其中readme.txt文件打包为tar文件中的/usr/doc/ant/README文件,所有html文件打包到/usr/doc/ant目录下。
该任务用于将一个Web应用打包为一个war文件。WAR是Web Application Archive的缩写,它表示Web应用包。war任务的特别之处就是它对WEB-INF/lib、WEB-INF/classes和WEB-INF目录进行了特殊处理。
属性如表13.7所示。
表13.7 War元素属性表
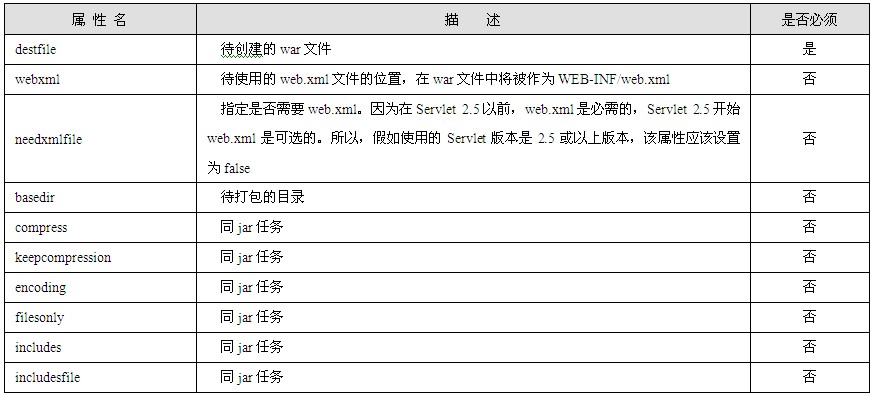
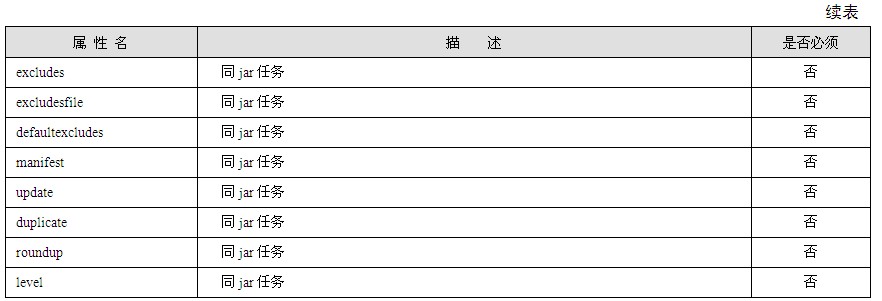
嵌套元素:
lib
lib元素用于指定一个文件集合。所有在这里指定的文件都将被放置在war文件的WEB-INF/lib目录中。
classes
与lib元素类似,该元素用于指定一个文件集合。所有在这里指定的文件都将被放置在war文件的WEB-INF/classes目录中。
webinf
同样,该元素用于指定一个文件集合。所有在这里指定的文件都将被放置在war文件的WEB-INF目录中。如果指定的文件中包含名为web.xml文件,那么该文件将被忽略,同时会提示警告。
metainf
指定一个文件集合。所有在这里指定的文件都将被放置在war文件的META-INF目录中,如果指定的文件中包含名为MANIFEST.MF文件,那么该文件将被忽略,同时会提示警告。
示例:
假设某Web工程的根目录中有如下文件:
thirdparty/libs/jdbc1.jar
thirdparty/libs/jdbc2.jar
build/main/com/myco/myapp/Servlet.class
src/metadata/myapp.xml
src/html/myapp/index.html
src/jsp/myapp/front.jsp
src/graphics/images/gifs/small/logo.gif
src/graphics/images/gifs/large/logo.gif
使用war任务对其打包,代码如下:
<war destfile="myapp.war" webxml="src/metadata/myapp.xml">
<fileset dir="src/html/myapp"/>
<fileset dir="src/jsp/myapp"/>
<lib dir="thirdparty/libs">
<exclude name="jdbc1.jar"/>
</lib>
<classes dir="build/main"/>
<zipfileset dir="src/graphics/images/gifs" prefix="images"/>
</war>
那么最终的myapp.war文件中的目录结构如下:
WEB-INF/web.xml
WEB-INF/lib/jdbc2.jar
WEB-INF/classes/com/myco/myapp/Servlet.class
META-INF/MANIFEST.MF
index.html
front.jsp
images/small/logo.gif
images/large/logo.gif
其中web.xml的内容就是原来的myapp.xml
该任务用于将文件打包为ear文件,ear是Enterprise Application aRchive的缩写。
属性如表13.8所示。
表13.8 Ear元素属性表
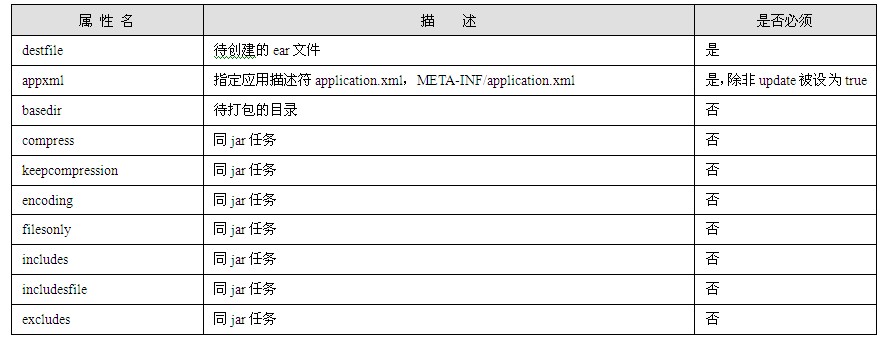
嵌套元素:
metainf
同war的metainf子元素。
示例:
<ear destfile="build/myapp.ear" appxml="src/metadata/application.xml">
<fileset dir="build" includes="*.jar,*.war"/>
</ear>
将build目录下的所有jar文件和war文件打包到build目录下的myapp.ear文件,使用src/metadata/application.xml文件作为应用描述符。

这几个任务分别对jar文件、tar文件、war文件和zip文件进行解包,由于其功能和属性比较相似,所以将它们放在一起进行介绍。
属性如表13.10所示。
表13.10 Unjar/Untar/Unwar/Unzip元素属性表
同打包的任务一样,这几个任务也允许使用fileset或patternset元素选择待解包的文件,如果没有指定那么归档文件中的所有文件将被解包。fileset可以独立指定一个文件集合,而patternset只能指定一个模板集合,还需要作用于一个目录才能够指定一个文件结合,所有使用fileset子元素时不需要指定src属性,而使用patternset子元素时需要指定src属性。
示例:
<unzip src="${tomcat_src}/tools-src.zip" dest="${tools.home}"/>
将${tomcat_src}目录下的tools-src.zip文件解包到目录${tools.home}目录中。
<untar src="tools.tar" dest="${tools.home}"/>
将tools.tar文件解包到目录${tools.home}中。
<unzip src="${tomcat_src}/tools-src.zip" dest="${tools.home}">
<patternset>
<include name="**/*.java"/>
<exclude name="**/Test*.java"/>
</patternset>
</unzip>
将${tomcat_src}目录中的tools-src.zip文件中所有文件名不以Test开头的java文件解压到${tools.home}目录中。
<unzip dest="${tools.home}">
<patternset>
<include name="**/*.java"/>
<exclude name="**/Test*.java"/>
</patternset>
<fileset dir=".">
<include name="**/*.zip"/>
<exclude name="**/tmp*.zip"/>
</fileset>
</unzip>
将当前目录中所有文件名不以tmp开头的zip文件中所有文件名不以Test开头的java文件解压到${tools.home}目录中。
该任务用于对一个Java源代码树进行编译。其功能类似于JDK提供的javac命令。该任务会递归地搜索源目录中的Java源代码文件,将其中所有没有对应class文件的java文件或class文件已过期(class文件比java文件老)的java文件编译成class文件,并保持java文件的目录结构。
实质上该任务就是通过调用本地JDK的javac命令来完成编译工作,所以该任务所配置的属性与javac命令的命令行参数有非常密切的关联关系。
属性如表13.11所示。
表13.11 Javac元素属性表


该任务支持fileset、include、exclude和patternset元素作为子元素,用于选择待编译的java文件。srcdir、classpath、sourcepath、bootclasspath和extdirs属性都分别可以用src、classpath、sourcepath、bootclasspath和extdirs子元素代替。
另外javac任务还有一个特殊的compilerarg子元素,用于指定编译时的命令行参数。
示例:
<javac srcdir="${src}" destdir="${build}" classpath="xyz.jar" debug="on" />
编译${src}目录下的所有java文件,并将编译的结果输出到${build}目录中,编译时将xyz.jar添加到类路径中,并且打开调试信息。
<javac srcdir="${src}" destdir="${build}" source="1.2" target="1.2" />
编译${src}目录中的所有java文件,并将编译的结果输出到${build}目录中。源代码是1.2的,同时编译输出的类文件也需要兼容1.2。
<javac srcdir="${src}" destdir="${build}" fork="java$javac.exe" source="1.5" />
编译${src}目录中的所有java文件,并将编译的结果输出到${build}目录中。在编译时使用名为java$javac.exe的java编译器。编译的源代码是1.5的。
<javac srcdir="${src}" destdir="${build}" includes="mypackage/p1/**,mypackage/p2/**" excludes= "mypackage/p1/testpackage/**" classpath="xyz.jar" debug="on" />
编译${src}目录中在mypackage/p1子目录中而不在mypackage/p1/testpackage子目录中和在mypackage/p2子目录中的java文件,并将编译的结果输出到${build}目录中。编译时将xyz.jar添加到类路径中,并且打开调试信息。
<javac srcdir="${src}:${src2}" destdir="${build}" includes="mypackage/p1/**,mypackage/p2/**" excludes="mypackage/p1/testpackage/**" classpath="xyz.jar" debug="on" />
该例在上例基础上又添加了一个源文件目录,该任务会编译${src}和${src2}两个目录中的文件。也可以通过src子元素指定多个源代码目录,例如:
<javac destdir="${build}" classpath="xyz.jar" debug="on">
<src path="${src}"/>
<src path="${src2}"/>
<include name="mypackage/p1/**"/>
<include name="mypackage/p2/**"/>
<exclude name="mypackage/p1/testpackage/**"/>
</javac>
该任务用于管理Java类文件之间的依赖关系。depend任务通过比较类文件和源代码文件的修改时间,将已过期的类文件和依赖于过期类文件的类文件删除。
在分析类依赖关系时,depend任务并不去分析源代码,而是通过分析编译器编码到类文件中的类引用来进行分析,这样会比分析源代码效率高。一旦分析出了类之间的依赖关系,该任务会倒转这种关系,从中得到一个影响链,当影响链中排在前面的类过期了以后,排在后面的类将全部失效。
属性如表13.12所示。
表13.12 Depend元素属性表

同javac任务一样,depend任务也支持将fileset、include、exclude和patternset作为子元素。
示例:
<depend srcdir="src/main" destdir="build/classes" cache="depcache" closure="yes"/>
检查src/main中源代码编译得到的build/classes目录中的类文件。删除过期的类文件和所有依赖于过期类文件的类文件。使用depcache目录作为缓冲目录。
<depend srcdir="src/main" destdir="build/classes" cache="depcache" closure="yes">
<include name="**/*.java"/>
<excludesfile name="src/main/build_excludes"/>
</depend>
完成的功能类似于上例。明确说明了包含所有java文件,并且不包含src/mian/build_excludes文件中给出的模板相匹配的文件。
该任务在Java虚拟机中运行一个Java类。可以是Ant所运行的Java虚拟机也可以是指定的另一个虚拟机。该任务同javac任务一样,都是使用JDK提供的命令,该任务使用java命令。
属性如表13.13所示。
表13.13 Java元素属性表

嵌套元素如下。
arg和jvmarg
arg元素用于向Java类提供运行时参数;jvmarg元素用于向启动的Java虚拟机提供参数。
sysproperty
sysproperty元素用于向类提供需要的系统属性。这些属性在该类执行期间可用。
syspropertyset
指定一个系统属性集合。
classpath
指定运行时的Java类路径。
bootclasspath
指定bootstrap类文件的路径。该元素只有在fork属性设为false时才可用。
env
该元素用于向使用fork启动的Java虚拟机传递环境变量。只有在fork设为true时才有效。
permissions
通过该元素可以停止和启动安全访问控制。如果没有指定该元素,则Java会使用一套默认的访问控制策略。
assertions
可以通过该元素控制是否允许断言。
redirector
用于指定输入、输出和错误信息的重定向。
示例:
<java classname="test.Main">
<arg value="-h"/>
<classpath>
<pathelement location="dist/test.jar"/>
<pathelement path="classes:build"/>
</classpath>
</java>
运行test.Main,将dist/test.jar文件、classes目录和build目录假如到类路径。
<java jar="dist/test.jar" fork="true" failonerror="true" maxmemory="128m" >
<arg value="-h"/>
<classpath>
<pathelement location="dist/test.jar"/>
</classpath>
</java>
重新启动一个Java虚拟机运行dist/test.jar文件,为Java虚拟机分配的最大内存为128MB。运行时将dist/test.jar加入到类路径。任何非0的返回值将终止该任务。
<java dir="${exec.dir}" jar="${exec.dir}/dist/test.jar" fork="true" failonerror="true" maxmemory="128m" >
<arg value="-h"/>
<classpath>
<pathelement location="dist/test.jar"/>
</classpath>
</java>
重新启动一个Java虚拟机在目录${exec.dir}中运行${exec.dir}/dist/test.jar文件,为Java虚拟机分配的最大内存为128MB。运行时将dist/test.jar加入到类路径。任何非0的返回值将终止该任务。
<java classname="test.Main" fork="yes" >
<sysproperty key="DEBUG" value="true"/>
<arg value="-h"/>
<jvmarg value="-Xrunhprof:cpu=samples,file=log.txt,depth=3"/>
</java>
重新启动一个Java虚拟机运行test.Main,运行时设置DEBUG系统属性为true,设置Java虚拟机参数-Xrunhprof:cpu=samples,file=log.txt,depth=3。 相当于在命令行中执行命令:java -Xrunhprof:cpu=samples,file=log.txt,depth=3 -DDEBUG=true test.Main
该任务用于执行另一个脚本文件。通常该任务被用于执行子工程的脚本文件。假如所调用的脚本文件是当前脚本文件,那么这个任务必须位于某Target内。
该任务的antfile属性用于指定待调用的脚本文件,假如没有指定antfile,那么就调用名为build.xml的默认脚本文件。还可以通过target属性指定待执行的脚本文件中的Target,如果没有指定Target则default Target就会被执行。
在默认情况下,当前脚本中所有的属性都会被传递到新的脚本文件。假如新的脚本文件中本来定义的属性中有与传递的属性同名的属性,则传递进来的属性值会覆盖原来的属性值。但是,可以通过将指定inheritAll属性设置为false来改变这种默认行为,改变后只有user属性会被传递到新的脚本文件中。
属性如表13.14所示。
表13.14 Ant元素属性表

嵌套元素如下。
property
该元素用于向新调用的脚本中传递属性。相当于在使用ant命令运行脚本文件时使用命令行参数传递给脚本的属性。
reference
用于选择需要被复制到被调用工程中的引用,而且还可以选择改变其引用ID。
propertyset
该元素用于传递一个属性集合。
target
可以通过target元素指定多个待执行的Target,作用同使用target属性一样。
示例:
<ant antfile="subproject/subbuild.xml" target="compile"/>
调用subproject/subbuild.xml脚本执行其中的compile Target。
<ant dir="subproject"/>
调用subproject中的build.xml脚本执行其中的default Target。
<ant antfile="subproject/property_based_subbuild.xml">
<property name="param1" value="version 1.x"/>
<property file="config/subproject/default.properties"/>
</ant>
调用subproject/property_based_subbuild.xml脚本执行其中的default Target,将属性param1=version1.x和config/subproject/default.properties文件中定义的所有传递到脚本中。
<ant inheritAll="false" antfile="subproject/subbuild.xml">
<property name="output.type" value="html"/>
</ant>
调用subproject/subbuild.xml脚本执行其中的default Target,将属性output.type=html传递到脚本中,当前工程中的其他属性不传递。
调用同一个脚本文件中的其他Target,并且在执行时可以提供一些属性作为参数。该任务不能在Target外作为全局任务使用,只能用于某Target内部。
属性如表13.15所示。
表13.15 AntCall元素属性表

嵌套元素如下。
param
指定属性作为调用Target的参数。
reference
同Ant任务。
propertyset
同Ant任务。
示例:
<target name="default">
<antcall target="doSomethingElse">
<param name="param1" value="value"/>
</antcall>
</target>
<target name="doSomethingElse">
<echo message="param1=${param1}"/>
</target>
default Target调用doSomethingElse Target将传递的param1参数的值输出。
该任务指定一个系统命令。在不同的操作系统上具有的系统命令是不一样的。
属性如表13.16所示。
表13.16 Exec元素属性表
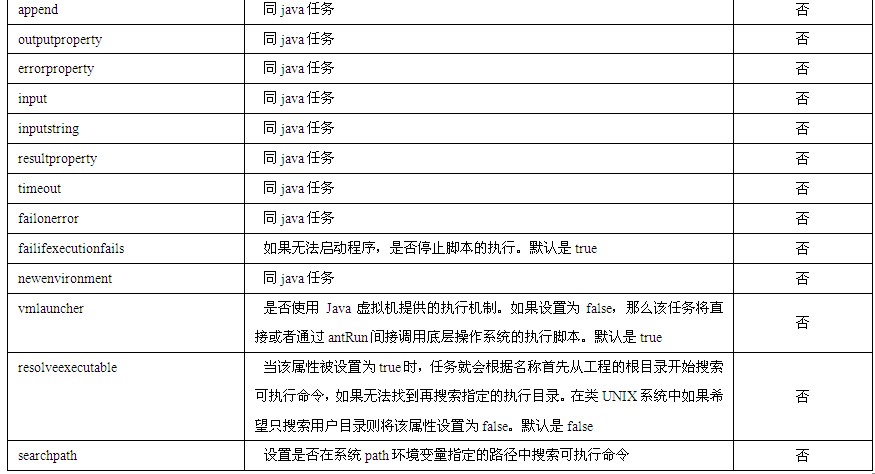
嵌套元素如下。
arg
指定所执行命令的命令行参数。
env
向执行的命令传递指定的环境变量。
redirector
同Java任务。
示例:
<exec executable="emacs">
<env key="DISPLAY" value=":1.0"/>
</exec>
执行emacs命令,并且设置环境变量DISPLAY=”:1.0”。
<property name="browser" location="C:/Program Files/Internet Explorer/iexplore.exe"/>
<property name="file" location="ant/docs/manual/index.html"/>
<exec executable="${browser}" spawn="true">
<arg value="${file}"/>
</exec>
执行browser属性定义的iexplore.exe可执行命令,打开file执行的文件。
<exec executable="cat">
<redirector outputproperty="redirector.out" errorproperty="redirector.err"
inputstring="blah before blah">
<inputfilterchain>
<replacestring from="before" to="after"/>
</inputfilterchain>
<outputmapper type="merge" to="redirector.out"/>
<errormapper type="merge" to="redirector.err"/>
</redirector>
</exec>
将字符串“blah before blah”传递给cat命令并执行cat命令,在传递字符串时使用inputfilterchain元素对输入字符串进行过滤,将before替换成to。将执行的结果分别输出到名为redirector.out的属性和名为redirector.out的文件;将错误信息输出到名为 redirector.err的属性和名为redirector.err的文件。
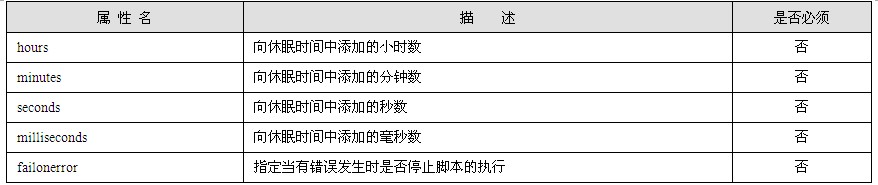
一个FileSet表示一个文件集合。可以是通过指定一个根目录从目录树中选择也可以通过PatternSet和Selector元素指定模板进行选择。
实质上FileSet的includes、includesfile、excludes和excludesfile属性也可以指定文件选择的模板,而且还可以通过嵌套的include、includesfile、exclude和excludesfile元素指定模板。
属性如表13.18所示。
表13.18 FileSet元素属性表
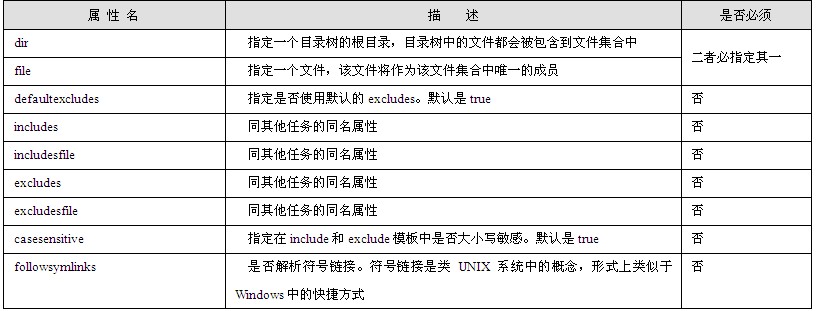
示例:
<fileset dir="${server.src}" casesensitive="yes">
<include name="**/*.java"/>
<exclude name="**/Test*"/>
</fileset>
指定一个文件集合,它包含${server.src}目录下所有文件名不以Test开头的java文件。文件名大小写敏感。
<fileset dir="${server.src}" casesensitive="yes">
<patternset id="non.test.sources">
<include name="**/*.java"/>
<exclude name="**/*Test*"/>
</patternset>
</fileset>
指定了一个和上例包含同样文件的文件集合,而且还定义了一个patternset,可以在其他fileset中通过id引用。
该任务改变一个文件或者指定目录下所有文件的拥有者。当前版本中该任务只能在类UNIX系统中起效。类似于UNIX系统中的chown命令。
属性如13.19所示。
表13.19 Chown元素属性表

示例:
<chown file="${dist}/start.sh" owner="coderjoe"/>
将文件${dist}/start.sh文件的拥有者改为coderjoe。
<chown owner="coderjoe">
<fileset dir="${dist}/bin" includes="**/*.sh"/>
</chown>
将${dist}/bin目录下所有的sh文件的拥有者都改为coderjoe。
该任务将一个或多个资源合并到一个文件或到控制台中。如果目标文件不存在则创建该文件。
属性如表13.20所示。
表13.20 Concat元素属性表

嵌套元素如下。
资源集合
任意一种资源集合类型。可以用于指定待合并的资源。
filterchain
添加对资源文件进行过滤的filter。
header, footer
用于添加在合并流开始处和结尾处的文本。待添加的文本可以是通过直接内嵌到脚本中也可以在指定的文件中。
示例:
<concat destfile="README">Hello, World!</concat>
将字符串“Hello, World!”写入到文件README中。
<concat>
<fileset dir="messages" includes="*important*"/>
</concat>
将messages目录中文件名包含important的文件内容合并起来,将内容输出到控制台。
该任务将一个文件或资源集合复制为一个新的文件或者到一个目录中。默认情况下,只有当源文件比目标文件更新或这目标文件尚不存在的情况下才进行复制。但是,可以通过设置overwrite属性改变这种默认行为,强制覆盖目标文件。
属性如表13.21所示。
表13.21 Copy元素属性表
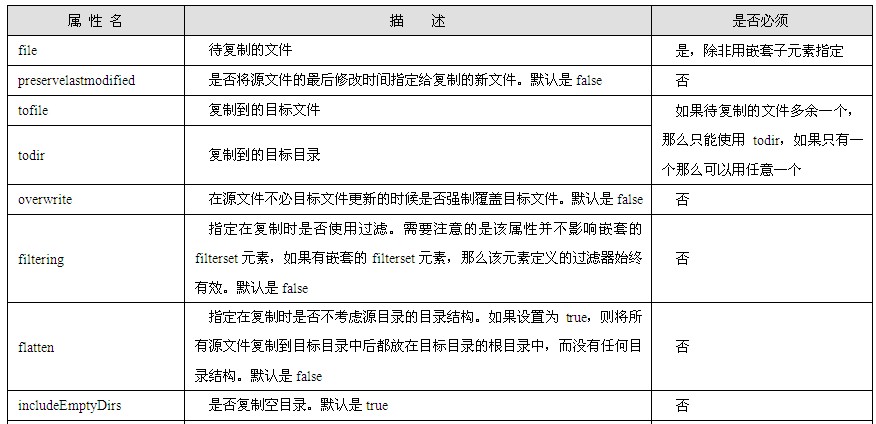

嵌套元素如下。
资源集合
任意一种资源集合类型。可以用于指定待复制的资源。
mapper
使用该元素可以定义文件名的变形方式。
filterset
过滤器集被用于对所复制的文件内容中的文本进行替换。
filterchain
同filterset功能类似。
示例:
<copy file="myfile.txt" tofile="mycopy.txt"/>
将将文件myfile.txt复制为文件mycopy.txt。
<copy file="myfile.txt" todir="../some/other/dir"/>
将文件myfile.txt复制到../some/other/dir目录中。
<copy todir="../dest/dir">
<fileset dir="src_dir">
<exclude name="**/*.java"/>
</fileset>
</copy>
将src_dir目录中的所有非java文件复制到../dest/dir目录中。
<copy todir="../backup/dir">
<fileset dir="src_dir"/>
<globmapper from="*" to="*.bak"/>
</copy>
将src_dir目录中的所有文件复制到../backup/dir目录下,并且在文件末尾添加.bak后缀。
<copy todir="../backup/dir">
<fileset dir="src_dir"/>
<filterset>
<filter token="TITLE" value="Foo Bar"/>
</filterset>
</copy>
将src_dir目录中的所有文件复制到../backup/dir目录中,并且将所有文件中的TITLE替换为Foo Bar。
<copy todir="dest" flatten="true">
<resources>
<file file="src_dir/file1.txt"/>
<url url="http://ant.apache.org/index.html"/>
</resources>
</copy>
将文件src_dir/file1.txt和url为http://ant.apache.org/index.html的文件复制到dest目录中,并且不形成任何目录结构,都放在根目录中。
该任务用于删除文件或者目录。可以是一个单独的文件,或者由fileset指定的一个文件集合,或者指定的一个目录。当删除一个目录时会同时删除其下包含的所有文件和子目录。
属性如表13.22所示。
表13.22 Delete元素属性表

示例:
<delete file="lib/ant.jar"/>
删除文件lib/ant.jar。
<delete dir="lib"/>
删除目录lib。
<delete>
<fileset dir="." includes="**/*.bak"/>
</delete>
删除当前目录(包括子目录)中的所有bak文件。
<delete includeEmptyDirs="true">
<fileset dir="build"/>
</delete>
删除build目录及其包含的所有文件和目录,包括空目录。
<delete includeemptydirs="true">
<fileset dir="build" includes="**/*"/>
</delete>
删除build目录包含的所有文件和目录,包括空目录,但不删除build目录本身。
该任务用于将一个文件移动到另一个新的文件位置或者一个目录中; 或者将一个文件集合移动到一个目录中。
属性如表13.23所示。
表13.23 Move元素属性表
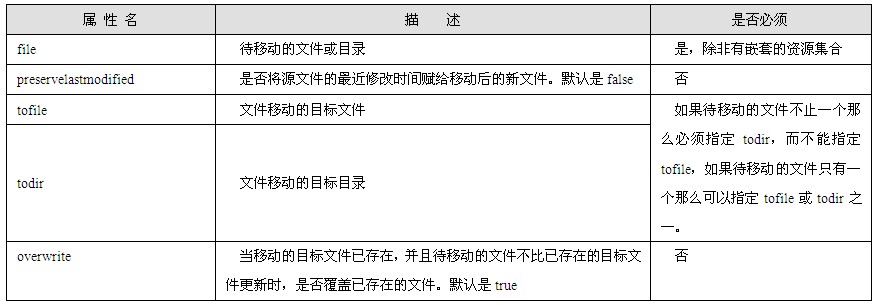
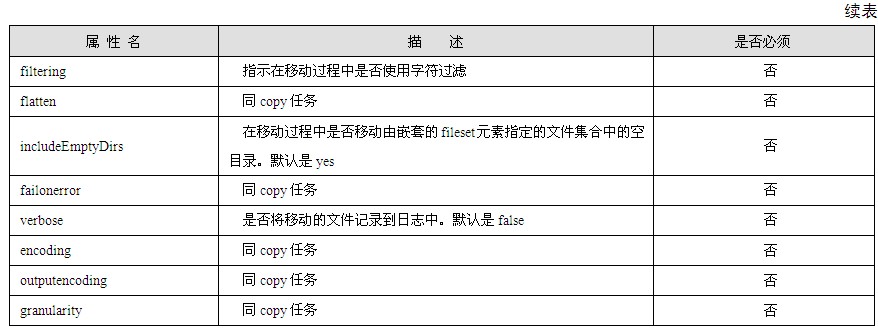
嵌套元素如下。
mapper
同copy元素。
filterchain
同copy元素。
示例:
<move file="file.orig" tofile="file.moved"/>
将file.orig文件移动为file.moved文件,即将file.orig重命名为file.moved。
<move file="file.orig" todir="dir/to/move/to"/>
将file.orig移动到目录dir/to/move/to中。
<move todir="new/dir/to/move/to">
<fileset dir="src/dir"/>
</move>
将目录src/dir下的所有文件移动到目录new/dir/to/move/to中。
<move todir="some/new/dir">
<fileset dir="my/src/dir">
<include name="**/*.jar"/>
<exclude name="**/ant.jar"/>
</fileset>
</move>
将目录my/src/dir(包括子目录)下除了ant.jar文件外的其他jar文件移动到some/new/dir目录下。
<move todir="my/src/dir" includeemptydirs="false">
<fileset dir="my/src/dir">
<exclude name="**/*.bak"/>
</fileset>
<mapper type="glob" from="*" to="*.bak"/>
</move>
将目录my/src/dir(包括子目录)下所有非bak文件后都加上.bak后缀。

获得一个URL所指向的文件。当前支持的URL模式包括http:、 ftp:和jar:。https:模式在Java 1.4之前的JDK上必须添加相应的支持。
属性如表13.25所示。
表13.25 Get元素属性表

示例:
<get src="http://ant.apache.org/" dest="help/index.html"/>
获得http://ant.apache.org指向的页面内容,将其保存为文件help/index.html。
<get src="http://www.apache.org/dist/ant/KEYS" dest="KEYS" verbose="true" usetimestamp="true"/>
获得http://www.apache.org/dist/ant/KEYS指向的页面内容,将其保存为文件KEYS。在获取页面的过程中打印详细的进度信息。假如KEYS文件已存在并且页面的时间戳不比本地文件更新,则不用下载。
<get src="https://insecure-bank.org/statement/user=1214" dest="statement.html" username="1214" password="secret"/>
获得https://insecure-bank.org/statement/user=1214指向的页面,将其保存为statement.html文件,安全连接使用用户名为1214密码为secret进行验证。
该任务用于将文件中指定字符串的所有出现替换为另一个字符串。
属性如表13.26所示。
表13.26 Replace元素属性表

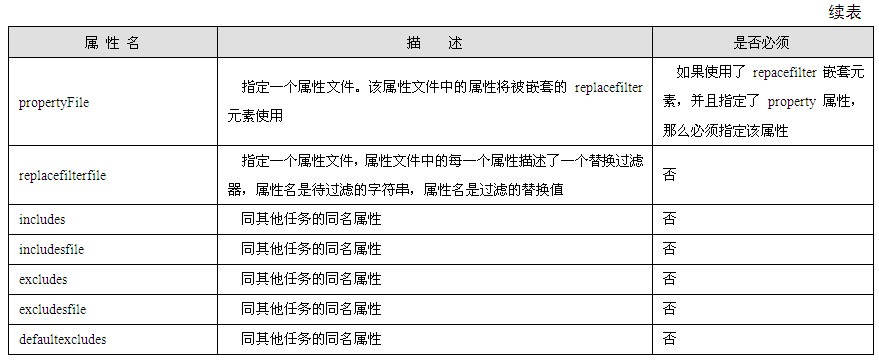
示例:
<replace dir="${src}" value=" ">
<include name="**/*.html"/>
<replacetoken>
<![CDATA[<br>]]>
</replacetoken>
</replace>
将${src}目录(包括子目录)中所有的html文件中出现的<br>替换成 。
<replace file="configure.sh" value="defaultvalue">
<replacefilter token="@token1@"/>
<replacefilter token="@token2@" value="value2"/>
<replacefilter token="@token3@" property="property.key"/>
</replace>
将configure.sh文件中所有出现的@token1@替换为defaultvalue,所有@token2@替换为value2,所有@token3@替换为属性property.key的值。
该任务用于为一个或多个属性赋值。属性值可以来自于文件或资源文件。
属性名是大小写敏感的,属性名可以包含除保留字符外的任何字符,不仅限于Java标识符所能使用的字符。属性是互斥的,相同名字的属性被第二次赋值时,第一次的值将会被覆盖。
有下列六种方式可以设置属性:
(1)通过设置属性名和属性值;
(2)通过设置属性名和一个引用ID;
(3)通过设置file属性,从一个属性文件中读取其中包含的所有属性;
(4)通过设置url属性,从url指定的文件中装载属性;
(5)通过设置resource属性,指定一个属性文件的名字,在当前的类路径中搜索该属性文件;
(6)通过设置environment属性指定一个前缀,通过在环境变量前加上该前缀就可以获得该属性,并且可以向该属性赋值而不会影响环境变量本身的值。
尽管同时指定几个属性是允许的,但是一次应该只使用一种方式设置属性。
属性如表13.27所示。
表13.27 Property元素属性表
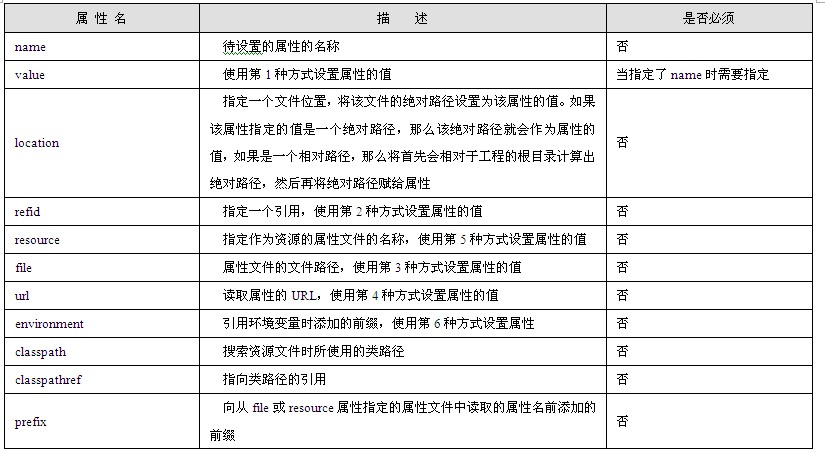
嵌套元素如下。
classpath
同元素的classpath属性的作用一样,用于指定一个搜索资源的类路径。
示例:
<property name="foo.dist" value="dist"/>
设置属性foo.dist的值为dist。
<property file="foo.properties"/>
从foo.properties文件中读取其中定义的所有属性。
<property url="http://www.mysite.com/bla/props/foo.properties"/>
从http://www.mysite.com/bla/props/foo.properties指定的属性文件中读取其定义的所有属性。
<property resource="foo.properties"/>
从类路径中寻找foo.properties文件,并且从中读取其中定义的所有属性。
在运行时实时地测试某资源是否存在,如果存在该任务就设置一个指定的属性。该资源可以是文件、目录、类或Java虚拟机系统中的资源文件。
如果指定的资源存在则将指定的属性设为true,否则不设置该属性。当然也可以将属性设置为其他任何给定值。
属性如表13.28所示。
表13.28 Available元素属性表
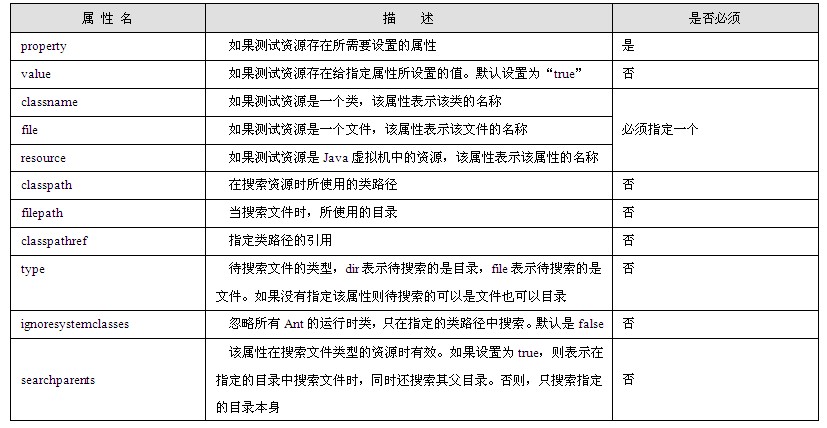
嵌套元素如下。
classpath
同元素的classpath属性的作用一样,用于指定一个搜索资源的类路径。
filepath
同元素的filepath属性的作用一样,用于指定一个搜索文件的目录。
示例:
<available classname="org.whatever.Myclass" property="Myclass.present"/>
测试在类路径中是否存在类org.whatever.Myclass,如果存在则将Myclass.present属性的值赋为true。
<property name="jaxp.jar" value="./lib/jaxp11/jaxp.jar"/>
<available file="${jaxp.jar}" property="jaxp.jar.present"/>
如果文件./lib/jaxp11/jaxp.jar存在,则将jaxp.jar.present属性的值赋为true。
<available file="c:\\usr\local\lib" type="dir" property="local.lib.present"/>
如果目录c:\\usr\local\lib存在则将local.lib.present的值赋为true。
<available property="have.extras" resource="extratasks.properties">
<classpath>
<pathelement location="c:\\usr\local\ant\extra.jar" />
</classpath>
</available>
在类路径c:\\usr\local\ant\extra.jar中如果能够找到extratasks.properties资源文件,则将属性have.extras属性赋为true。
该任务用于判断一个条件,如果该条件是true则设置一个属性的值,默认将属性的值设为true。Condition任务通常通过使用and、or、not等逻辑运算元素将多个条件合并进行判断。
属性如表13.29所示。
表13.29 Condition元素属性表

所有用来生成一个条件的元素都可以作为该任务的子元素。例如:equal用于判断两个属性是否相等;available用于判断某个资源是否可用;os用于判断使用的操作系统;http用于判断指定的url是否可以连接等。
示例:
<condition property="javamail.complete">
<and>
<available classname="javax.activation.DataHandler"/>
<available classname="javax.mail.Transport"/>
</and>
</condition>
如果在类路径中javax.activation.DataHandler类和javax.mail.Transport类都可用,则将属性javamail.complete赋为true。
<condition property="isMacOsButNotMacOsX">
<and>
<os family="mac"/>
<not>
<os family="unix"/>
</not>
</and>
</condition>
如果当前操作系统是mac家族的而且不是unix家族则将属性isMacOsButNotMacOsX赋为true。
LoadFile任务读取指定的文件,将文件内容赋给指定属性。LoadResource从类路径中寻找指定的资源文件,并将文件内容赋给指定的属性。
属性如表13.30所示。
表13.30 LoadFile/LoadResource元素属性表
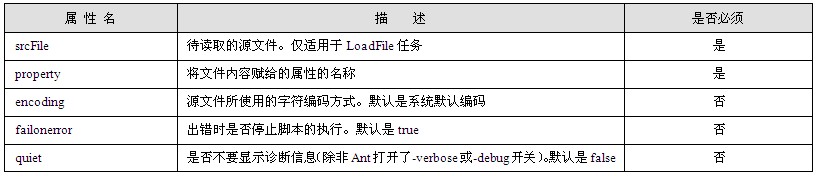
嵌套元素如下。
filterchain
定义过滤器链,用于过滤所读取的文件内容。
示例:
<loadfile property="message" srcFile="message.txt"/>
读取文件message.txt中的内容,将其赋给message属性。
<loadresource property="message">
<file file="message.txt"/>
</loadresource>
与上例功能相同,只是该用内嵌元素的形式。
<loadfile property="encoded-file" srcFile="loadfile.xml" encoding="ISO-8859-1"/>
使用ISO-8859-1编码方式读取文件loadfile.xml的内容,将内容赋给属性encoded-file。
将属性文件中定义的属性装载进当前工程中。该任务与<property file|resource=”...”/>的功能一致。该任务默认是将文件中所有的属性都装载进来,但可以通过设置filterchain子元素定义过滤规则。
属性如表13.31所示。
表13.31 LoadProperties元素属性表
嵌套元素如下。
filterchain
定义过滤器链,用于过滤所读取的属性类型。
classpath
同classpath属性的意义一样,用于指定搜索资源文件时的类路径。
示例:
<loadproperties srcFile="file.properties"/>
读取file.properties属性文件中的所有属性。
<loadproperties>
<file file="file.properties"/>
</loadproperties>
与上例功能相同,只是该用内嵌元素的形式。
<loadproperties srcFile="file.properties">
<filterchain>
<linecontains>
<contains value="import."/>
</linecontains>
</filterchain>
</loadproperties>
读取file.properties属性文件中包含import.字符串的行,并装载这些行中包含的属性。
<loadproperties>
<gzipresource>
<url url="http://example.org/url.properties.gz"/>
</gzipresource>
</loadproperties>
从http://example.org/url.properties.gz指向的用gzip压缩的属性文件中读取和加载所有属性。
该任务用于显示当前工程中的属性的值,默认打印所有属性,包括系统属性。也可以通过定义属性或子元素打印一部分属性的值。
属性如表13.32所示。
表13.32 Echoproperties元素属性表

嵌套元素如下。
propertyset
定义了一个属性集,只有在属性集中的属性才会被输出。
示例:
<echoproperties/>
输出当前工程中所有的属性到工作台。
<echoproperties destfile="my.properties"/>
输出当前工程中所有的属性到文件my.properties中。
<echoproperties prefix="java."/>
输出当前工程中所有文件名以java.打头的属性到工作台。
<echoproperties regex=".*ant.*"/>
输出当前工程中所有文件名与正则表达式“.*ant.*”匹配的属性到工作台。
该任务用于输出指定的消息。默认是输出到标准控制台,同时也可以通过指定file属性将消息输出到文件中。另外,可以通过level属性指定在哪一种消息级别下需要输出该消息。
属性如表13.33所示。
表13.33 Echo元素属性表
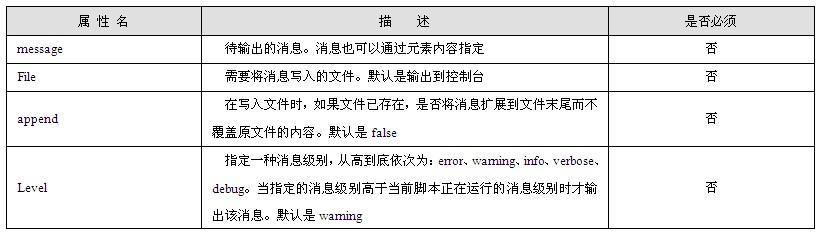
示例:
<echo message="Hello, world"/>
将Hello, world输出到控制台。
<echo>Hello, world</echo>
同上例相同功能。
<echo level="error">
Imminent failure in the antimatter containment facility.
Please withdraw to safe location at least 50km away.
</echo>
当脚本以error消息模式启动时输出其中消息内容。
在启动Ant脚本时,不同的启动开关设置了不同的消息级别,echo的level属性也用于指定输出消息的级别,下表列出了不同的启动开关设置和不同level消息之间的输出情况,如表13.34所示:
表13.34 level级别与启动开关作用表
该任务退出当前构建脚本的执行。只是抛出一个BuildException,可以通过设置属性打印附加信息。
属性如表13.35所示。
表13.35 Fail元素属性表

示例:
<fail/>
退出脚本的执行,不提供任何附加信息。
<fail message="Something wrong here."/>
退出脚本的执行,并且提示“Something wrong here.”作为出错信息。
<fail>Something wrong here.</fail>
与上例功能相同。
<fail unless="thisdoesnotexist"/>
当thisdoesnotexist属性存在时退出脚本的执行。
<fail>
<condition>
<not>
<isset property="thisdoesnotexist"/>
</not>
</condition>
</fail>
与上例功能相同。isset元素用于判断指定的属性是否已设置。
在脚本执行过程中弹出对话框允许用户输入交互性的信息为某属性赋值,而且可以通过设置 validargs,将可选的选择值提供给用户进行选择。
属性如表13.36所示。
表13.36 Input元素属性表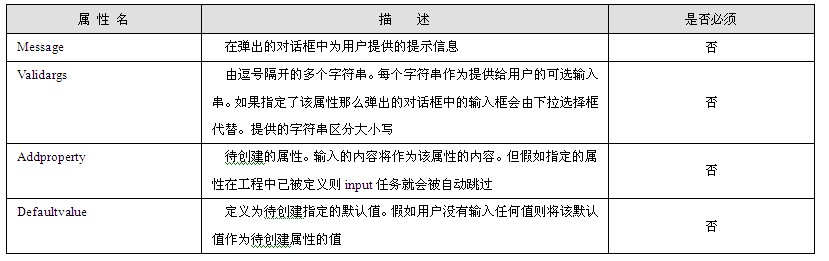
示例:
<input/>
弹出输入框,输入框上不提供任何提示消息,如下图所示:
<input>Press Return key to continue...</input>
弹出输入框,输入框上提示例中提示指定的消息。
<input message="All data is going to be deleted from DB continue (y/n)?" validargs="y,n"
addproperty="do.delete"/>
弹出对话框如下图所示:
可选的输入值为y和n,用户选择了某个值在点击OK后,该任务会创建属性do.delete,并把用户选择的值赋给该属性。
根据脚本执行结束的成功与否播放不同的声音文件。可以指定一个声音文件或者一个目录,如果指定的是一个目录时,该任务会从中随机选择一个声音文件播放。需要注意的是,如果指定的是一个目录,该任务在选择声音文件时会选择目录中任意一个文件,假如目录中存在非声音文件也有可能会被选择上,所以在指定目录时应该保证目录中的文件都是可以被正确播放的。
嵌套元素如下。
success
指定在脚本成功执行结束时播放的声音文件。
fail
指定在脚本失败执行结束时播放的声音文件。
如下是success和fail元素都可以设置的属性,如表13.37所示:
表13.37 success和fail元素属性表

示例:
<sound>
<success source="sounds/bell.wav"/>
<fail source="sounds/ohno.wav" loops="2"/>
</sound>
在脚本执行结束时,如果是成功执行结束则播放sounds/bell.wav文件1次,如果是失败执行结束则播放sounds/ohno.wav文件3次。

在Ant预定义的任务中,最常用的几类是:
(1)归档任务:该类任务用于对文件集合进行打包或者将包文件解包,支持的格式有GZip、BZip2、Zip、Jar、Tar、War、Tar和Cab。
(2)编译任务:该类任务包含了与编译Java文件相关的任务,其中Javac用于编译Java文件,Depend用于管理Java文件之间的依赖关系。
(3)执行任务:该类任务包含了与执行一段程序或应用相关的任务,包括执行Java类、Ant脚本、Ant Target和系统命令等。
(4)文件任务:该类任务包含了关于文件的相关操作,包括文件的复制、删除、移动、改变属性等任务。
(5)属性任务:该类任务包含了有关属性的操作,例如定义属性、根据条件定义属性、装载属性等。
(6)其他任务:除以上几类以外的常见任务,例如输入输出、引用其他脚本等。
传统的Ant脚本开发方式将Ant脚本看作是一个执行过程;为每一个应用开发一个脚本,将应用的所有代码放在一个脚本中,各个脚本之间几乎相互独立;每个脚本都从头开始开发。这种开发方式存在着以下弊端:
(1)当Ant脚本规模扩大后将难于开发,并且容易出现错误;
(2)开发的脚本只能一次使用,不利于代码的复用;
(3)开发的脚本难于理解,不易维护。
从本章开始将介绍Ant结构化程序设计,这种方式利用结构化程序设计的思想进行Ant脚本的开发。这种开发方式有利于Ant代码的复用、有利于快速开发大型稳定的Ant应用。
结构化程序设计元素是结构化程序设计的基础,本章首先介绍Ant结构化程序设计元素,包括:常量和变量、分支结构、函数、循环结构、输入/输出。
常量和变量是程序设计语言的基本元素,在一段程序中用于记录一个数据、一段文字或者一个实体内容。通常,常量和变量都具有特定的类型,但在有些语言中所有的变量都是一种类型。常量和变量都由一个标识符表示,常量的值在程序运行期间不会改变,而变量的值在程序运行期间可能会被改变。在有些语言中变量需要先定义后使用,有些语言中变量不需要定义就可以直接使用。
如果将Ant看作是一种开发Ant脚本的语言,那么Ant中也包含了常量和变量的概念。
Ant脚本中的工程名和所有Target的名称都是Ant脚本中的常量。
工程名由project元素的name属性定义,它表示当前工程的名称,用于指代当前工程;它在脚本文件中已固定写入,在整个Ant脚本执行期间,该名称不能被改变。
Target名称由各个target元素的name属性定义,它们用于指代一个Target;它们的值在脚本文件中已固定写入,在整个Ant脚本执行期间,该名称不能被改变。
<project name="test" basedir="." default="root">
<target name="root" depends="t1">
...
</target>
<target name="t1">
...
</target>
<target name="t2">
...
</target>
</project>
如上例,其中test是整个工程的名称,root、t1和t2分别代表三个Target。project元素的default属性引用了root,此处的root就代表root Target。同样,root Target的depends属性引用了t1,此处的t1就代表t1 Target。这其中的test、root、t1和t2所代表的对象在整个脚本执行过程中是不会改变的。
Ant中表示常量名的标识符比常见编程语言的标识符可选的字符要多得多,除了字母、数字和下画线外,Ant常量标识符还可以取除几个符号外的其他几乎所有符号。常量标识符中不能出现的字符有:&<,和”。其他的字符基本上都可以在常量标识符中出现。如下例:
示例14.1
<?xml version="1.0" encoding="UTF-8"?>
<project name=”~`!@#$%^*()_-+={}|[]\:;’>?./” basedir=”.” default=”~`!@#$%^*()_-+={}|[]\:;’>?./”>
<target name=”~`!@#$%^*()_-+={}|[]\:;’>?./”>
<echo>OK!</echo>
</target>
</project>
输出:
~`!@#$%^*()_-+={}|[]\:;'>?./:
[echo] OK!
BUILD SUCCESSFUL
Ant脚本中定义的这些常量的作用域是全局的,在整个Ant脚本中不允许有同名的Target,但是project的名称和Target的名称可以相同。
Ant脚本中的变量就是经常提到的属性(property)的概念。Ant中的变量可以不用定义直接使用,未定义的变量处于“未定义”(undefined)状态,在向未定义变量赋值时Ant会先对变量进行定义然后再对其赋值;在从未定义变量取值时,根据取值操作的不同会产生不同的行为,这取决于取值操作对未定义变量所采取行为的认定。例如,在使用echo打印一个未定义变量的引用时,会直接打印变量名;在将未定义变量作为条件判断的条件时,会将其作为false对待。
如下例:
示例14.2
<?xml version="1.0" encoding="UTF-8"?>
<project name="test" basedir=".">
<property name="defined" value="defined value" />
<echo>${defined}</echo>
<echo>${undefine}</echo>
</project>
输出:
[echo] defined value
[echo] ${undefine}
BUILD SUCCESSFUL
示例14.3
<?xml version="1.0" encoding="UTF-8"?>
<project name="test" basedir="." default="root">
<target name="root" depends="echo defined, echo undefined"/>
<property name="defined" value="defined value" />
<target name="echo defined" if="defined">
<echo>${defined}</echo>
</target>
<target name="echo undefined" if="undefined">
<echo>${undefine}</echo>
</target>
</project>
输出:
echo defined:
[echo] defined value
echo undefined:
root:
BUILD SUCCESSFUL
对于变量名的取值,原则上与常量是一样的,但由于Ant脚本中在引用变量的值时使用的是${}符号将变量名包括起来,所以除了常量标识符中提到的几个字符,还有 { 和 } 也建议不要出现在变量名中,否则在引用变量值时可能会将变量认为是未定义。
Ant中变量的作用域也同其他语言类似,变量只在定义语句所在块内部有效,并且只在定义语句后有效。Ant脚本中的每个Target相当于一个块,在块内部的任务顺序执行,定义的变量作用域只在块内部,而且只能在定义语句后才有值,如下例:
示例14.4
<?xml version="1.0" encoding="UTF-8"?>
<project name="test" basedir="." default="root">
<target name="root">
<echo>${inner}</echo>
<property name="inner" value="property in root" />
<echo>${inner}</echo>
</target>
<echo>${inner}</echo>
</project>
输出:
[echo] ${inner}
root:
[echo] ${inner}
[echo] property in root
BUILD SUCCESSFUL
注意,在root Target外的echo语句虽然顺序排在root Target下面,但是由于它是全局Task,所以其执行顺序仍然在root Target之前。而在root内容在定义inner的property语句之前inner是未定义变量,在property语句之后inner才有所赋的值。
由于Ant脚本是基于XML语言的,所以Ant脚本中的所有变量的值都是基于字符串的,即使某个变量的值是数字,那也只是数字字符,而无法进行任何形式的数字运算。如下例:
示例14.5
<?xml version="1.0" encoding="UTF-8"?>
<project name="test" basedir=".">
<property name="pi" value="3.14" />
<property name="r" value="1 + 0.5" />
<echo>2 * ${pi} * ${r}</echo>
</project>
输出:
[echo] 2 * 3.14 * 1 + 0.5
BUILD SUCCESSFUL
尤其要特别注意的是将变量作为条件表达式的判断条件,在条件表达式中只有未定义变量被当作false,而具有任何字面值的变量都被当作true,如下例:
示例14.6
<?xml version="1.0" encoding="UTF-8"?>
<project name="test" basedir="." default="root">
<property name="falseVar" value="false" />
<target name="root" if="falseVar">
<echo>falseVar is true!</echo>
</target>
</project>
输出:
root:
[echo] falseVar is true!
BUILD SUCCESSFUL
由此可见,虽然falseVar的值为false,但在将其作为判断条件时,由于它是已定义变量所以被认为是true。
Ant提供了对最基本的选择条件分支的支持,target元素的if属性和unless属性提供了一种根据变量的true和false选择不同执行分支的机制。其基本结构如下:
<target name="ifTarget" if="var">
...
</target>
<target name="unlessTarget" unless="var">
...
</target>
通过适当的组织Target的依赖关系,就可以利用target元素的if属性或者unless构建分支结构。如下例根据不同的操作系统执行不同的代码块:
示例14.7
<?xml version="1.0" encoding="UTF-8"?>
<project name="test" basedir="." default="root">
<condition property="isWindows">
<os family="windows"/>
</condition>
<target name="root" depends="if,unless"/>
<target name="if" if="isWindows">
<echo>is windows</echo>
</target>
<target name="unless" unless="isWindows">
<echo>is not windows</echo>
</target>
</project>
在上例中,通过condition元素和嵌套的os元素判断当前操作系统是否是Windows家族的,如果是则创建isWindows变量并将其赋值。默认执行的root Target依赖于if Target和unless Target,if Target当isWindows为true时执行,unless Target当isWindows为false时执行,相当于如下的伪代码:
boolean isWindows = os(windows);
if(isWindows) {
echo(“is windows”);
} else {
echo(“is not windows”);
}
由于Ant并不是针对科学计算的,而是针对任务执行的,所以在Ant中并没有定义诸如>(大于)、<(小于)、= =(等于)、!=(不等于)等用于判断数量的符号;相反,Ant提供了很多在任务执行过程中需要用到的可以判断条件的元素。
在前面介绍属性任务时介绍了available和condition任务。available是一个特殊的条件判断任务,它专门用于判断指定的资源是否存在,如果存在就为某个变量赋值;condition则是Ant中的通用条件判断任务,它可以根据其内嵌的任意复杂的条件判断元素为指定的变量赋值,如果其内嵌的元素所表示的条件表达式为true则将指定变量的值赋为true,否则不为指定变量赋值。
所有用于判断条件的元素都可以内嵌于condition任务中,常用的有如下几种。
1.not
该元素可内嵌其他条件元素,当内嵌的条件元素为true时,该元素所表示的条件就为false;如果内嵌的条件元素为false时,该元素所表示的条件就为true。该条件元素没有任何属性可以定义。该元素只能内嵌一个条件元素。
2.and
该元素可内嵌其他条件元素,理论上内嵌的条件元素的个数不限。当内嵌的所有条件元素都为true时该元素所表示的条件才为true;只要有一个或一个以上的内嵌条件元素为false时该元素所表示的条件就为false。该元素也没有任何属性可以定义。
3.or
该元素可内嵌其他条件元素,理论上内嵌的条件元素的个数不限。它与and表示的意义恰好相反,当内嵌的所有条件元素都为false时该元素所表示的条件才为false;只要有一个或一个以上的内嵌条件元素为true时该元素所表示的条件就为true。该元素也没有任何属性可以定义。
4.xor
该元素可内嵌其他条件元素,理论上内嵌的条件元素的个数不限。在所有其内嵌的条件元素里面,如果为true的条件元素的个数为奇数则该条件元素所表示的条件为true,否则如果为true的条件元素的个数为偶数则该条件所表示的条件为false。该元素也没有任何属性可以定义。
5.available
该条件元素与available任务类似,所能取的属性除了property属性和value属性外其他属性都可以取,所表示的含义也一样。available任务当指定的资源可用时向property属性所指定的变量赋于value属性所指定的值;而此处作为条件元素时,当指定的资源可用时所表示的条件为true,否则为false。
6.uptodate
该条件元素与uptodate任务类似,所能取的属性除了property属性和value属性外其他属性都可以取,所表示的含义也一样。uptodate用于测试某个资源目标文件与某个源文件相比是否是已过时,如果已过时则该条件元素所表示的条件为false。
7.os
该条件元素用于判断Ant脚本所执行的操作系统是否是某个操作系统或某个操作系统家族。可设置的属性如表14.1所示。
表14.1 os元素属性表

其中最常用的是family属性,因为不同的操作系统家族在功能使用、路径表示以及提供的可执行命令上都会有特别大的差别。所以在Ant脚本如果需要执行的某段任务只能在特定的操作系统上执行,那么有必要使用os条件元素判断操作系统的家族,并根据操作系统的家族执行相应的代码。
不同的family属性与其对应的操作系统如表14.2所示。
表14.2 family属性与操作系统对照表
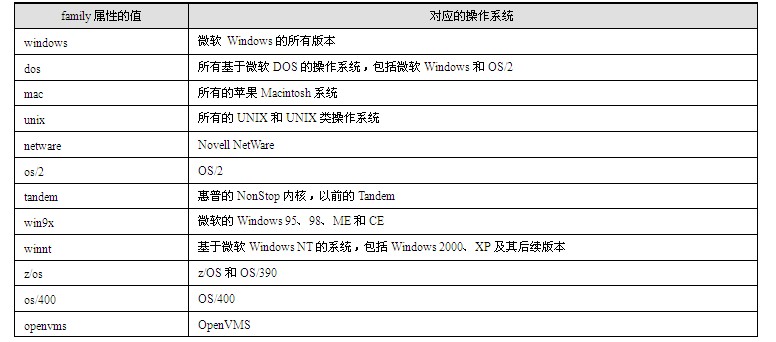
8.equals
测试给定的两个字符串是否相同,属性如表14.3所示。
表14.3 equals元素属性表

9.isset
测试指定的变量在工程中是否已被设置,属性如表14.4元素属性表。
表14.4 isset元素属性表

10.http
向指定的url发出请求并且测试返回的是否是有效的响应。默认情况下返回的响应码大于或等于400被认为是无效的,也可以通过设置errorsBeginAt属性设置将响应码大于或等于该属性值的响应认定为无效的。
属性如表14.5所示。
表14.5 http元素属性表

11.socket
用于测试指定的服务器的端口上是否有TCP/IP监听器,属性如表14.6所示。
表14.6 socket元素属性表

12.filesmatch
用于一个字节一个字节地测试两个文件内容是否相同。特别地,假如两个文件都不存在则为true,如果一个文件存在一个文件不存在则为false。
属性如表14.7所示。
表14.7 filesmatch元素属性表

13.contains
用于测试一个字符串是否包含另一个字符串,属性如表14.8所示。
表14.8 contains元素属性表

如果string指定的字符串包含substring指定字符串则为true,否则为false。
14.istrue
测试一个表达式的值是否是true、yes、on中的一个,如果是则为true,否则为false,属性如表14.9所示。
表14.9 istrue元素属性表

例如:
<istrue value="${someproperty}"/>
<istrue value="false"/>
15.isfalse
测试一个表达式的值是否不是true、yes、on中的一个,恰好与istrue相反,属性如表14.10所示。
表14.10 isfalse元素属性表

16.isfileselected
用于测试一个文件是否符合内嵌的选择器,属性如表14.11所示。
表14.11 isfileselected元素属性表

例如:
<isfileselected file="a.xml">
<date datetime="06/28/2000 2:02 pm" when="equal"/>
</isfileselected>
17.matches
用于测试指定的字符串是否匹配指定的正则表达式,属性如表14.12所示。
表14.12 matches元素属性表
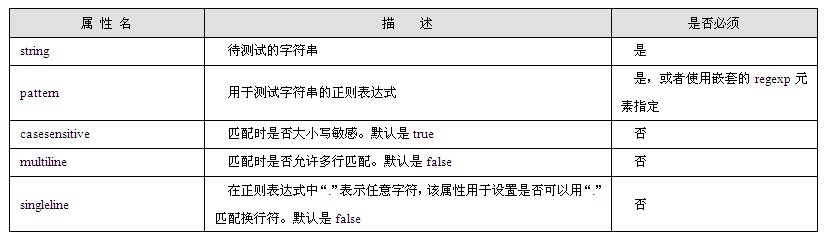
18.antversion
表14.13 antversion元素属性表

例如:
<condition property="ant-is-exact-7">
<antversion exactly="1.7.0"/>
</condition>
在前面介绍变量时已经介绍过,Ant中布尔变量的true和false并不是根据其字面值而定的,而是根据其是否已被赋值,凡是已被赋值的变量在进行条件判断是一律认为是true。
如前面所讲,Ant中提供了许多用于判断某些条件是否满足的条件判断元素,这些元素可以被嵌套于像condition任务等需要内嵌条件判断元素的任务中。以condition为例,condition元素中定义了property属性,它指定了一个变量,如果内嵌的条件判断元素为true则将指定的变量赋为true,否则不为指定的变量赋值。
示例14.8
<?xml version="1.0" encoding="UTF-8"?>
<project>
<condition property="test1">
<contains string="1111" substring="11" />
</condition>
<echo>${test1}</echo>
<condition property="test2">
<contains string="1111" substring="12" />
</condition>
<echo>${test2}</echo>
</project>
输出:
[echo] true
[echo] ${test2}
BUILD SUCCESSFUL
在上例中,由于“11”是“1111”的子串,所以<contains string="1111" substring="11" />为true,即test1被赋为“true”;而“12”不是“1111”的子串,所以<contains string="1111" substring="12" />为false,即test2不被赋值,即test2保持未定义。所以,在用echo打印时test1输出true,而test2直接被输出。
需要注意的是,在condition任务中,如果嵌套的条件表达式为true则为指定的变量赋“true”,如果嵌套的条件表达式为false则不为指定的变量赋任何值,即保持指定变量的原值(如果指定变量尚未赋值则保持未赋值状态,如果指定变量已被赋值则保持原来的值)。所以,在向condition中指定变量时尽量保证指定的变量未被定义和赋值,否则在使用condition判断结果进行决策时极易产生错误,如示例14.9所示:
示例14.9
<?xml version="1.0" encoding="UTF-8"?>
<project default="root">
<property name="cond" value="someValue" />
<condition property="cond">
<contains string="1111" substring="12" />
</condition>
<target name="root" if="cond">
<echo>cond is true!It is ${cond}.</echo>
</target>
</project>
输出:
root:
[echo] cond is true!It is someValue.
BUILD SUCCESSFUL
cond首先被定义并且被赋值(无论任何值,即使是“false”),说明cond已经不是未定义变量;当使用condition任务测试时,由于测试的条件表达式为false,所以cond不会被进行任何赋值操作,其值仍保持其原来被赋的值;当把cond作为条件判断时,由于cond已经不是未定义变量,所以被认为其值是true。
尤其是在为condition指定变量时,不要指定系统中默认提供的变量,因为这种变量虽然没有在代码中出现,但是其作为条件判断时是恒true的;而且由于这种错误引入的异常是很难发现的。如示例14.10所示:
示例14.10
<?xml version="1.0" encoding="UTF-8"?>
<project default="root">
<condition property="basedir">
<contains string="1111" substring="12" />
</condition>
<target name="root" if="basedir">
<echo>cond is true!It is ${basedir}.</echo>
</target>
</project>
输出:
root:
[echo] cond is true!It is D:\Workspace\Java Web开发\Projects\ServletTest.
BUILD SUCCESSFUL
basedir是系统默认定义的属性变量,在工程中表示当前工程的根路径,所以其恒真。
在Ant中变量的赋值是顺序优先,即先定义和赋值的语句会将后面的赋值语句操作隐藏。某个赋值语句在为一个变量赋值时,如果它发现该变量已被赋值,那么该语句就不会重新赋值,所以Ant中对同一个变量的定义和赋值操作是前优先的,如示例14.11所示:
示例14.11
<?xml version="1.0" encoding="UTF-8"?>
<project default=”root”>
<property name=”outter” value=”outter first value” />
<property name=”outter” value=”outter last value” />
<echo>outter value is: ${outter}.</echo>
<target name=”root”>
<property name=”inner” value=”inner first value” />
<property name=”inner” value=”inner last value” />
<echo>inner value is: ${inner}.</echo>
</target>
</project>
[echo] outter value is: outter first value.
root:
[echo] inner value is: inner first value.
BUILD SUCCESSFUL
condition任务在对指定的变量进行赋值时,也遵循该原则,如示例14.12所示:
示例14.12
<?xml version="1.0" encoding="UTF-8"?>
<project default="root">
<property name="outter1" value="outter1 string value" />
<condition property="outter1">
<contains string="1111" substring="11" />
</condition>
<echo>outter1 value is: ${outter1}.</echo>
<condition property="outter2">
<contains string="1111" substring="11" />
</condition>
<property name="outter2" value="outter2 first value" />
<echo>outter2 value is: ${outter2}.</echo>
<target name="root">
<property name="inner1" value="inner1 string value" />
<condition property="inner1">
<contains string="1111" substring="11" />
</condition>
<echo>inner1 value is: ${inner1}.</echo>
<condition property="inner2">
<contains string="1111" substring="11" />
</condition>
<property name="inner2" value="inner2 string value" />
<echo>inner2 value is: ${inner2}.</echo>
</target>
</project>
[echo] outter1 value is: outter1 string value.
[echo] outter2 value is: true.
root:
[echo] inner1 value is: inner1 string value.
[echo] inner2 value is: true.
BUILD SUCCESSFUL
不管是全局任务还是局部任务,如果向变量赋值的property任务先于condition任务,那么变量就会以property任务所赋值为准,即使condition任务的条件判断为true;如果condition任务先于property任务,假如condition任务的条件判断为true,那么指定变量的值就是true,无论property任务为变量赋的是什么值。
综上所述,在为条件判断任务指定变量时一定要保证该变量在当前工程中没有被定义;除非有其他特殊的用途,但在使用时必须要仔细考虑各种情况。
在介绍执行任务时已经介绍了Ant和AntCall任务。Ant可以调用一个已存在的脚本文件,相当于适用ant命令脚本执行一次;AntCall用于调用一个已存在的Target,并且可以通过参数设置向Target传入需要的变量。如下是两个典型的例子:
示例14.13
caller.xml
<?xml version="1.0" encoding="UTF-8"?>
<project name="ant call test" default="root">
<target name="root">
<ant antfile="callee.xml" />
</target>
</project>
callee.xml
<?xml version="1.0" encoding="UTF-8"?>
<project name="printer">
<echo>Hello world!</echo>
</project>
在运行caller.xml时输出:
root:
[echo] Hello world!
BUILD SUCCESSFUL
在使用ant任务调用另一个脚本文件执行时,调用者和被调用者的执行顺序是串行的,调用者只有等到被调用者执行结束后才能继续执行。如示例14.14:
示例14.14
caller.xml
<?xml version="1.0" encoding="UTF-8"?>
<project name="ant call test" default="root">
<target name="root">
<echo>caller start to call.</echo>
<ant antfile="callee.xml" />
<echo>caller end.</echo>
</target>
</project>
callee.xml
<?xml version="1.0" encoding="UTF-8"?>
<project name="printer">
<echo>Start getting...</echo>
<get src="http://www.csai.cn" dest="csai.html"/>
<echo>Getting end.</echo>
</project>
在运行caller.xml时输出:
root:
[echo] caller start to call.
[echo] Start getting...
[get] Getting: http://www.csai.cn
[get] To: D:\Workspace\Java Web开发\Projects\ServletTest\ant\csai.html
[echo] Getting end.
[echo] caller end.
BUILD SUCCESSFUL
callee.xml在运行时获取http://www.csai.cn指向的资源并保存到本地,这个网络操作需要的时间相对较长,但从最终打印的输出可以发现,caller.xml是等待callee.xml中的get任务执行结束后才继续往下执行的。
ant任务还可以指定调用另一个脚本文件中的某一个Target,如示例14.15所示:
示例14.15
caller.xml
<?xml version="1.0" encoding="UTF-8"?>
<project default="root">
<target name="root">
<ant antfile="callee.xml" target="print" />
</target>
</project>
callee.xml
<?xml version="1.0" encoding="UTF-8"?>
<project name="printer">
<target name="print">
<echo>callee.xml -> print Target!</echo>
</target>
</project>
在运行caller.xml时输出:
root:
print:
[echo] callee.xml -> print Target!
BUILD SUCCESSFUL
与ant不同,antcall用于调用本脚本文件中的Target,并且可以向被调用的Target中传递参数。antcall是Ant提供的用于函数调用的核心方法,如示例14.16是antcall的使用实例:
示例14.16
<?xml version="1.0" encoding="UTF-8"?>
<project default="root">
<target name="deleteTempFilesUnderDir">
<delete dir="${dirForDelete}" includes="**/*.tmp" />
</target>
<target name="root">
<antcall target="deleteTempFilesUnderDir">
<param name="dirForDelete" value="src" />
</antcall>
<antcall target="deleteTempFilesUnderDir">
<param name="dirForDelete" value="bin" />
</antcall>
</target>
</project>
例中deleteTempFilesUnderDir Target用于删除指定目录下的所有tmp文件;在root Target中可以使用antcall任务调用deleteTempFilesUnderDir Target以删除不同目录下的tmp文件而不需要重写删除的代码。
无论是ant或antcall任务,都只能被定义在某个Target内部,而不能作为全局任务出现。ant不能调用其所在的工程,antcall也不能调用其所在的Target。如示例14.17所示是错误的:
示例14.17
wrongAntDemo.xml
<?xml version="1.0" encoding="UTF-8"?>
<project default="root">
<target name="root">
<ant antfile="wrongAntDemo.xml" />
</target>
</project>
wrongAntCallDemo.xml
<?xml version="1.0" encoding="UTF-8"?>
<project default="root">
<target name="root">
<antcall target="root" />
</target>
ant任务和antcall任务的不同之处在于ant任务用于调用另外一个脚本文件中的代码,而antcall用于调用同一个脚本文件中的代码。这两种调用方式都允许调用者向被调用者传递参数。
antcall任务是通过嵌套的param元素向被调用的Target传递参数,param元素的name属性和value属性分别定义传递参数的变量名和变量值,被调用的Target在执行时就可以通过该变量名获得传递进来的变量值。
ant任务则是通过嵌套的property元素向被调用者传递参数,property元素的name属性和value属性分别定义传递参数的变量名和变量值。如示例14.18所示:
示例14.18
caller.xml
<?xml version="1.0" encoding="UTF-8"?>
<project default="root">
<target name="root">
<ant antfile="callee.xml">
<property name="property" value="value" />
</ant>
</target>
</project>
callee.xml
<?xml version="1.0" encoding="UTF-8"?>
<project name="printer">
<echo>value of property: ${property}</echo>
</project>
在运行caller.xml时输出:
root:
[echo] value of property: value
BUILD SUCCESSFUL
除此之外,ant和antcall任务都可以定义一个inheritAll属性,该属性表示是否将当前可用的属性全部传递给被调用者使用。这个属性默认是true。也就是说,实质上在使用ant和antcall进行函数调用时,如果调用语句没将inheritAll属性设置为false,那么在调用语句处所有可用的属性都会被传递给被调用者,在被调用者中可以直接使用这些变量。所以,程序员也可以通过这种方式进行参数传递。两个脚本之间利用inheritAll属性传递参数的示例如下:
示例14.19
caller.xml
<?xml version="1.0" encoding="UTF-8"?>
<project default="root">
<property name="callerProperty" value="callerValue" />
<target name="root">
<ant antfile="callee.xml" />
</target>
</project>
callee.xml
<?xml version="1.0" encoding="UTF-8"?>
<project name="printer">
<echo>value of callerProperty: ${callerProperty}</echo>
</project>
在运行caller.xml时输出:
root:
[echo] value of callerProperty: callerValue
BUILD SUCCESSFUL
一个脚本中利用inheritAll属性传递参数的示例14.20如下:
示例14.20
<?xml version="1.0" encoding="UTF-8"?>
<project name="printer" default="root">
<target name="print">
<echo>${content}</echo>
</target>
<target name="root">
<property name="content" value="value"></property>
<antcall target="print" inheritall="true"></antcall>
<antcall target="print" inheritall="false"></antcall>
</target>
</project>
输出:
root:
print:
[echo] value
print:
[echo] ${content}
BUILD SUCCESSFUL
由此可见,当inheritAll属性为true确实可以通过全局变量的形式传递参数。但是,使用这种方式时应该特别注意,因为使用这种方式传递参数时,每进行一次函数调用就需要向工程中添加一些变量,当函数调用发生很多次以后就会在工程中产生许多变量,这会为程序设计带来很多的麻烦。所以,除非确实必要,建议不要使用这种方式传递参数,而是明确用嵌套的param元素或property元素进行参数传递。
无论使用ant还是antcall进行函数调用,调用的级别都可以针对Target;虽然ant在不指定target属性的情况下是执行整个脚本,但实质上也是执行脚本的default Target。所以,在函数调用的时候实质上调用的就是Target,那么编写函数实质上也就是编写执行特定功能的Target。
Target的编写格式,前面已经介绍了,这里需要特别强调的是,如果编写的函数需要指定参数,那么在编写函数时可以直接假定需要的参数已经存在。下面的例子是一个删除指定文件夹中所有tmp文件的函数:
<target name="deleteTempFilesUnderDir">
<delete dir="${dirForDelete}" includes="**/*.tmp" />
</target>
其中,函数的参数就是dirForDelete,在函数编写时直接假定该属性已存在;在调用该函数时,调用者需要将参数值赋给dirForDelete。
Ant提供了各种各样的集合类型,而且还提供了许多模式和过滤器用于向集合中选择适合的对象。同时,Ant的许多任务也可以接受集合类型的嵌套元素,这些任务会对集合中的所有对象逐个进行操作。常用的集合类型有:
1.FileList
FileList也表示一个文件集合,但是与FileSet不同的是FileList只能包含某目录中的文件,而不能包含其子目录中的文件。而且FileSet中选中的文件都是已存在的文件,因为FileSet是从已存在的所有文件中用模式进行匹配;而FileList可以直接指定文件名,所以FileList指定的文件可能是不存在的。
属性如表14.14所示。
表14.14 filelist元素属性表

示例:
<filelist id="docfiles" dir="src" files="foo.xml,bar.xml"/>
指定一个FileList docfiles,包含src目录中的foo.xml和bar.xml文件。
<filelist id="docfiles" dir="src">
<file name="foo.xml"/>
<file name="bar.xml"/>
</filelist>
与上例含义相同。
2.DirSet
该集合表示一个目录集合。这个集合可以通过指定根路径和匹配模式进行选择,也可以通过嵌套的元素指定匹配模式或选择器。
属性如表14.15所示。
表14.15 dirset元素属性表
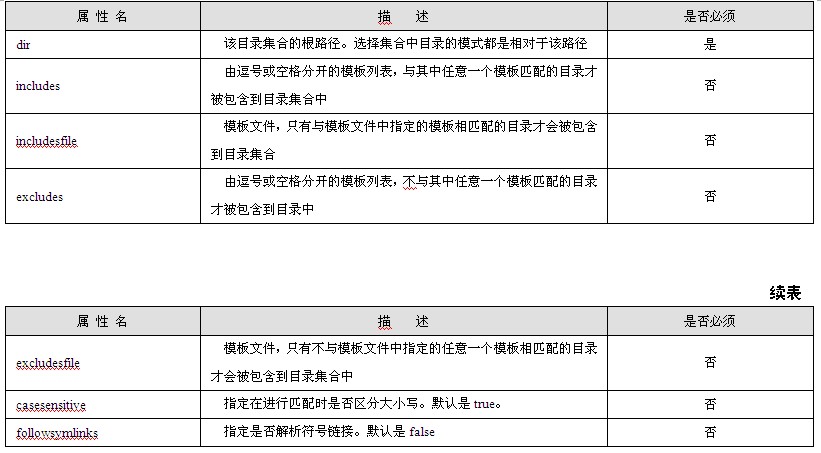
示例:
<dirset dir="build">
<include name="apps/**/classes"/>
<exclude name="apps/**/*Test*"/>
</dirset>
包含build/apps目录(包括子目录)中所有名为classes的目录,而不包含目录名中有Test出现的目录。
<dirset dir="build">
<patternset id="non.test.classes">
<include name="apps/**/classes"/>
<exclude name="apps/**/*Test*"/>
</patternset>
</dirset>
与上例含义相同。
3.FileSet
与DirSet类似,FileSet也表示一个根目录下所包含的对象集合,只不过此处的对象是文件。FileSet同样是指定一个根目录以及一些模板或选择器,从指定的根目录下的目录树中选择符合条件的文件。
属性如表14.16所示。
表14.16 fileset元素属性表
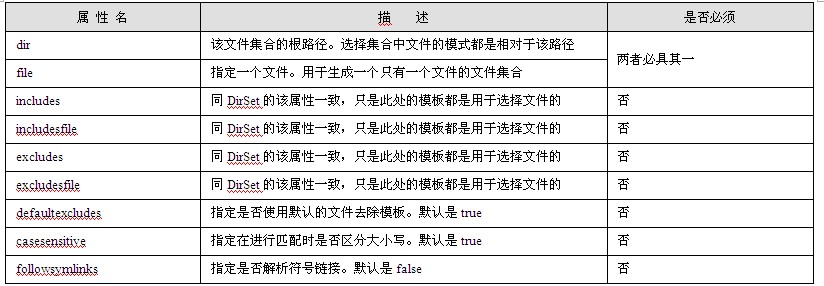
示例:
<fileset dir="src" casesensitive="yes">
<include name="**/*.java"/>
<exclude name="**/*Test*"/>
</fileset>
包含src目录(包括子目录)中所有名称中不包含Test的java文件。比较是区分大小写。
<fileset dir="src" casesensitive="yes">
<patternset id="non.test.sources">
<include name="**/*.java"/>
<exclude name="**/*Test*"/>
</patternset>
</fileset>
与上例含义相同。
FileSet是一种非常强大的文件集合类型,它除了支持使用模式选择文件外,还可以使用选择器选择文件。选择器是一类元素的统称,它们可作为fileset元素的子元素,用于定义一些准则向文件集合中选择文件。选择器也可以用selector元素包围起来,在其他地方通过refid引用。
Ant中已定义了很多种选择器,不同的选择器考虑的方面不同,适用的属性也不同,常用的选择器如下。
<contains>:选择包含特定文本内容的文件。
<date>:选择最近修改时间在特定时间之前或者之后的文件。
<depend>:选择最近修改时间比指定的另一个文件更晚的文件。
<depth>:选择在一个目录树中目录深度小于或大于某个数值的文件。
<different>:选择与指定的某个文件不同的文件。
<filename>:选择文件名符合特定模式的文件。同include和exclude中定义的模式相同。
<present>:选择在另外一个位置存在或者不存在的文件。
<containsregexp>:选择符合特定正则表达式的文件。
<size>:选择文件大小大于或小于特定数量字节的文件。
<type>:选择目录或者文件。
<modified>:根据指定的算法(比如:校验和)为文件计算一个值,并将计算的值与指定的cache(比如:属性文件)中的值进行比较,只选择值已发生改变的文件。
示例:
<fileset dir="path" includes="**/*.html">
<contains text="script" casesensitive="no"/>
</fileset>
获得一个文件集合,集合中只包括path目录下所有文件中有script字符串出现的html文件。
<fileset dir="path" includes="**/*.jar">
<date datetime="01/01/2008 12:00 AM" when="before"/>
</fileset>
获得一个文件集合,集合中只包括path目录下所有生成日期在2008年1月1日12时之前的文件。
<fileset dir="path" includes="**/*">
<filename name="**/*.css"/>
</fileset>
获得一个文件集合,集合中只包含path目录中所有的css文件。
由于Ant有很多任务是针对文件进行操作的,所以Ant的集合类型也大部分都是文件的集合。大部分的文件任务都支持集合类型,这些任务会对集合中的对象依次进行操作。如以下例中所示:
<copy todir="../new/dir">
<fileset dir="src_dir"/>
</copy>
将fileset表示的文件集合中的所有文件复制到目的目录中。
<delete>
<fileset dir="." includes="**/*.bak"/>
</delete>
删除fileset表示的文件集合中的所有文件。
<move todir="some/new/dir">
<filelist dir="my/src/dir">
<file name="file1.txt"/>
<file name="file2.txt"/>
</filelist>
</move>
将filelist指定的两个文件移动到目的目录中。
自建循环是指通过巧妙地使用分支语句和函数调用对循环语句进行模拟的一种代码模式。由于Ant没有直接提供对循环的支持,所以在需要进行循环操作的地方只能通过结合分支语句和函数调用产生循环的效果。
虽然Ant没有提供对循环的支持,但实质上在许多Ant脚本中循环的效果会大大扩展Ant脚本的实用性和用户体验。考虑如下两个用例:
(1)当在某目录中新建一个目录时,需要用户输入目录名,假如目录已存在则提示用户目录已存在,需要重新指定目录名;用户重新输入目录名,检查新的目录名,如果目录还存在则再次提示用户重新输入;如此直到用户输入的目录名不存在为止;
(2)Ant脚本需要访问某个目录中指定的文件,该文件由其他进程写入;当Ant脚本检查文件不存在时就等待一段时间后再进行检查,直到该文件存在。
在这两个实例中,需要循环语句才能完成指定的效果;否则,可能需要增加其他大量的工作才能达到类似的效果。这两个实例的伪代码如下:
(1)
String dirName = getInput();
File dir = new File(dirName);
while(dir.exist()) {
dirName = getInput();
dir = new File(dirName);
}
dir.mkdirs();
(2)
while(!getDesignateFile().exist()) {
Thread.sleep(3000);
}
实现Ant循环语句的思想非常直接,考虑Ant提供的分支语句和函数调用。分支语句可以用于判断循环的条件是否被满足;通过将两个函数相互调用可以实现无限循环;在循环的某个函数中判断条件,如果条件满足则继续调用另一个函数,否则停止调用。以下是一个循环语句的模板:
<target name="structured.while">
获得条件
<condition property="structured.while.condition">
判断条件
</condition>
<antcall target="structured.decide" />
</target>
<target name="structured.decide" if="structured.while.condition">
<antcall target="structured.whileBlock" inheritall="false"></antcall>
<antcall target="structured.while" inheritall="false"></antcall>
</target>
<target name="structured.whileBlock">
循环代码体
</target>
这段代码实现的功能相当于下面这段伪代码:
获得条件
while(判断条件) {
循环代码体
}
这种循环语句的执行流程分析如下。
循环语句的入口Target是structured.while,在该Target中首先获得与待判断条件有关的外部数据,例如用例(1)中获取用户的输入,用例(2)中获得待检测的文件;当获得了外部数据后需要对该外部数据进行判断,判断条件是否满足,例如用例(1)中判断用户输入的目录名指向的目录是否存在,用例(2)中判断待判断的文件是否存在,把判断结果指定给structured.while.condition变量;然后调用structured.decide Target,注意此处的inheritall属性没有设为false,默认是true,所以structured.while.condition将自动传递到structured.decide Target。
structured.decide Target用于调用执行循环代码体,然后继续调用structured.while Target以使得循环得以继续。该Target的执行是有条件的,只有当structured.while.condition变量为true时才执行。假如在判断条件时条件为假,那么structured.while.condition变量就为false,该Target就不会被执行,所以循环就会就此结束;相反,如果判断条件为真,那么structured.while.condition变量就为true,该Target会被执行,所以该Target内部就会调用执行循环代码体,同时继续循环。值得注意的是,该Target中的两个调用都将inheritall属性设为false,这是因为调用structured.while Target时,如果不将该属性设为false,那么structured.while.condition变量就会被再传递回structured.while Target中,此时structured.while.condition就会变成已定义变量,无论判断条件是否成立,structured.while.condition会永远为true,那么循环就会成为无限循环。另外,在调用structured.whileBlock Target时,因为循环体内可能会增加任意代码,为了消除当前Target中定义的变量与循环体内使用的变量发生冲突的可能,不将任何变量传入循环体内。
structured.whileBlock Target的功能非常简单,它只是一个框架,用于放置循环代码体。
根据这种循环结构实现上述的用例(1)和用例(2),实现的脚本片段如下:
(1)
<project default="structured.while">
<target name="structured.while">
<input message="输入目录名:" addproperty="input" defaultvalue="dir"/>
<condition property="structured.while.condition">
<available file="${input}" />
</condition>
<antcall target="structured.decide" />
<mkdir dir="${input}"/>
</target>
<target name="structured.decide" if="structured.while.condition">
<antcall target="structured.whileBlock" inheritall="false">
</antcall>
<antcall target="structured.while" inheritall="false">
</antcall>
</target>
<target name="structured.whileBlock">
</target>
</project>
(2)
<project default="structured.while">
<target name="structured.while">
<property name="fileName" value="temp" />
<condition property="structured.while.condition">
<not>
<available file="${fileName}" />
</not>
</condition>
<antcall target="structured.decide" />
</target>
<target name="structured.decide" if="structured.while.condition">
<antcall target="structured.whileBlock" inheritall="false">
</antcall>
<antcall target="structured.while" inheritall="false">
</antcall>
</target>
<target name="structured.whileBlock">
<echo>文件不存在,等待3秒钟...</echo>
<sleep seconds="3" />
</target>
</project>
脚本中Target的名称在整个脚本执行期间是不会变化的,属于常量范畴;变量就是经常提到的属性(property)的概念。Ant脚本中的变量可以不用预先定义就可以直接使用,对于未定义变量的引用产生的结果,会根据引用方式的不同而不同。在为变量赋值时最好选择未定义的变量,因为对已定义变量进行赋值并不会覆盖原来的值。
target元素定义了if和unless属性,这两个属性用来决定当前target执行的条件,target只有当if属性满足或unless属性不满足时才执行。根据这种机制可以定义通用的分支结构。
Ant提供了ant和antcall两种任务分别用于调用其他脚本(或脚本中的Target)和本脚本中的Target。利用这种机制可以使用Target定义函数,并且使用ant和antcall调用函数,并且还可以通过内嵌元素向函数中传递参数。
Ant并没有提供内建的可用于产生循环结构的机制,但通过巧妙的使用函数调用可以构造出通用的循环结构。
Ant提供了很多用于输入输出的任务,通过使用这些任务可以完成输入/输出的功能。
在理解了Ant结构化程序元素后,本章将向读者介绍一种Ant应用开发的步骤,以便读者更好地理解和使用Ant结构化程序设计的思想。
结合传统Ant脚本的开发方法和Ant结构化程序设计的思想,作者将Ant结构化程序设计的步骤总结为以下几个步骤:
1.了解需求:无论使用什么方法进行开发,详细地了解需求是必不可少的,所以Ant结构化程序设计的第一步就是对待开发的工作进行详细地了解和分析,仔细考虑各方面的因素,从中归纳出Ant脚本执行的大致流程;
2.将归纳的流程具体化,使用构建流程图描述脚本的执行过程。逐步对流程图中的每一个执行块进行细化,直至流程图中的每一块能够使用一个简单的Target就可以完成;
3.对流程图中每一个执行块的功能进行提炼,从中抽象出可以被通用的函数;
4.实现各个函数,并根据程序流程图和已实现的函数编写Ant脚本。
构建流程图总共定义了四种符号,如图15.1所示。

图15.1 构建流程图符号
1.执行块
执行块用一个方框表示,方框中写入该执行块需要完成的工作。它用于表示一个执行过程。执行块可以有流向流入也可以有流向流出。
执行块可大可小,大的执行块在不断细化的过程中可以被分解为一个独立的流程图;小的执行块可以用一个单独的函数甚至是一个任务实现。
如图15.2所示为两个执行块。


图15.2 执行块的范围
2.起点/终点
起点/终点用一个椭圆表示,椭圆中写入“起点”或者“终点”,用于表示执行流程的开始或者结束。起点只有流向流出,终点只有流向流入。
任何一个Ant脚本都是一个执行过程,执行过程就有开始和结束的地方。对于一个已编写好的Ant脚本来说,执行结束的地方比较直观,它就是default Target执行结束的地方,那执行开始的地方并不是那么明显,原因在前面讲过,因为根据default Target倒退分析得到的Target依赖链是一个多头开始的无环有向图。但实际上,Ant脚本中的所有代码都是有执行的先后顺序的,除了Target的依赖关系确定了执行顺序外,同级的Target或任务之间通过其书写的先后顺序也确定了一种先后执行的关系。最初执行的一定全局任务,全局任务中写在前面的先执行;同时被一个Target依赖的两个Target的执行顺序也依赖于这两个Target的名称出现在depends属性中的先后顺序。例如,考察下面的执行脚本:
<project default="root">
<task1 .../>
<task2 .../>
<target name="t2">
<task5 .../>
</target>
<target name="root" depends="t1,t2">
<task6 .../>
</target>
<target name="t1">
<task4 .../>
</target>
<task3 .../>
</project>
其任务的执行顺序依次为:task1 →task2 →task3 →task4 →task5 →task6。
但是,在考虑构建流程图时,只需要从前面对执行步骤的分析考虑执行的顺序。执行步骤是有明确顺序的,执行步骤中有执行的起始位置和结束位置,暂时不用考虑Ant脚本的结构和执行顺序。
3.判断
判断用一个菱形表示,菱形中写入待判断的条件,用于根据判断条件的不同结果决定程序的流向。这里的判断只能是二值判断,所以判断有一个流向流入,有两个流向流出。在流出的两个流向上分别标明判断的结果是“是”还是“否”,如图15.3所示。
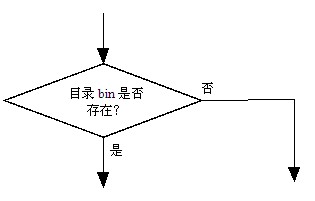
图15.3 判断图示
4.流向
流向用一个带箭头的线段表示,为了流程图的整洁也可以用带箭头的折线表示,用于表示程序的流向,流向从一个节点流向另一个节点或另一个流向,不允许将两个流向合并为一个流向。如图15.4分别示出了正确的流向表示和错误的流向表示。
a)正确的流向标示
b)错误的流向标示
图15.4 流向图示
在初期,由于对待开发任务的步骤处于相对比较模糊的阶段,所以极端地可以将整个脚本的任务作为一个执行块,也就是整个构建流程图只包含一个执行块;在对任务不断细化后,将该执行块进行细分,用一个相对比较宏观的构建流程图替换最初的执行块;然后再不断对其中的执行块进行细化,直到最终的执行块的功能都大致能与Ant的任务相关联为止。
这种不断细化的过程也可以帮助程序员进行任务需求的分析以及执行步骤的整理。
考虑下面的需求。
DemoProject是一个Java工程,工程根目录中包含一个src目录,其中是所有的源代码,所有源代码编译而成的class文件与源文件在相同目录中。现在需要通过执行Ant脚本完成如下工作:清理src目录中所有的class文件,对src目录中的java文件进行编译,编译输出的class文件放在工程根目录下的bin目录中;编译时需要使用key库文件,在与根目录同级的3rdParty目录中有编译时需要使用的key库文件,要求在编译前将key库文件复制到工程根目录下的lib目录中;该库文件有两个版本,文件名分别为key_v2.jar和key_v3.jar,要求如果高版本的key_v3.jar存在就使用key_v3.jar,否则使用key_v2.jar。
该工作的需求非常明确,但在刚开始可能还不清楚如何组织构建流程图,可首先将整个工作作为一个执行块,如图15.5所示。
然后,根据需求对执行块“执行任务”进行细化,第一步可将其细化,如图15.6所示。
图15.5 只包含一个执行块的构建流程图
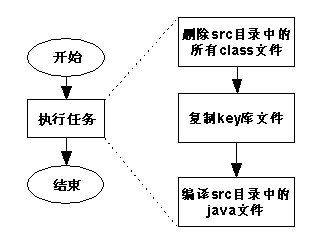
图15.6 对构建流程图逐渐细化
再分别对分离出来的三个执行块进行分析和细化:
删除src目录中的所有class文件:可以直接通过delete任务完成,所以无须再细化;
复制key库文件:在复制库文件之前得保证lib目录已经存在,所以首先得新建文件夹;在复制库文件时,由于涉及判断key_v3.jar是否存在,所以需要使用一个判断;假如key_v3.jar存在则复制该文件,否则复制key_v2.jar,所以每个需要一个执行块;
编译src目录中的java文件:编译java文件只需要一个任务,但是在编译之前首先要确定输出目录bin目录已经存在,所以可以将该块分解成两个执行块。
新的执行块如图15.7所示。
所以该工程最终的构建流程图如图15.8所示。
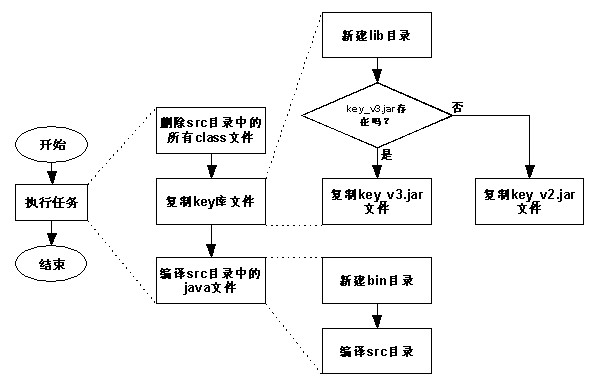
图15.7 对构建流程图进一步细化
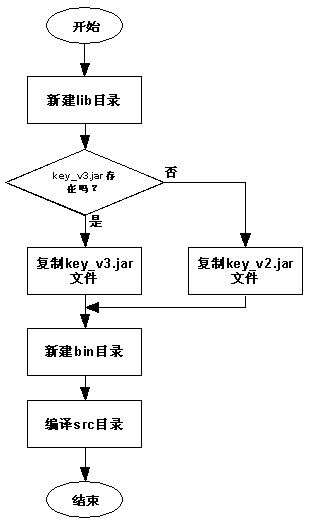
图15.8 最终的构建流程图
函数的抽象程度决定了函数的适用面和复杂度。通常来讲,抽象程度越高的函数适用面越宽,但是编写和调用时的复杂度就越高;抽象程度越低的函数适用面越窄,编写和调用时的复杂度就越低。通过观察其他语言(例如,C/C++、Java等)的函数可以发现,在公共函数库中定义的函数通常都具有很高的抽象程度,所以其适用面很宽,但是这些函数通常都比较复杂,而且调用时可能需要提供很多的参数;而由程序员在各个工程中定义的函数通常抽象程度就会低很多,所以其适用面就在当前工程中,但其 实现和调用起来相对较简单。
Ant并没有提供内建的函数库,如果广义的来讲,可以将Ant提供的所有任务都看做是Ant提供的函数库,但是这些任务提供的功能都特别的抽象和有限,所有具体而丰富的功能都需要程序员通过组合这些任务自己进行开发,这样就大大约束了Ant脚本执行复杂功能的能力,使得开发复杂Ant脚本变得非常困难。在Ant开发过程中引入函数,可以将一些相对通用的功能,经过抽象作为函数开发,其他需要使用类似功能的地方可以通过调用这些函数来实现;而且如果将抽象程度较高、适用面较广的函数组织为函数库,为其他Ant工程使用,那将会简化Ant脚本开发的复杂度,提高开发效率。这就将Ant中的函数开发归结为两种类型:单一工程中使用的函数开发和函数库的开发。
单一工程中开发的函数只用在本工程中,只要开发的功能和抽象程度能够满足调用处的要求即可,开发出来的函数也可以直接与调用处放在同一个脚本文件中。例如:在一个工程中有两个地方需要删除文件,一个地方是从根目录中删除temp.txt文件,一个地方是从根目录中删除data.dat文件。那么可以在脚本中编写一个“用于在工程根目录中删除文件的函数”,然后在两个需要删除文件的地方调用,代码如下:
...
<target name="deleteFileInRootDir">
<delete file="${fileName}" />
</target>
...
<antcall target="deleteFileInRootDir" inheritall="false">
<param name="fileName" value="temp.txt"/>
</antcall>
...
<antcall target="deleteFileInRootDir" inheritall="false">
<param name="fileName" value="data.dat"/>
</antcall>
...
函数库的开发相对会比较复杂一些,函数库中的函数需要被有机地组织起来,而且这些函数的声明代码与调用函数的代码肯定处于不同的脚本文件中。除此之外,开发的函数必须具有较强的通用性和抽象程度,以便于能够广泛地应用于其他工程中。对于函数库组织方式,读者可以探索一种适合自己的方式,目的是在今后开发和运行其他构建脚本时可以方便地访问到库中的函数。这里介绍一种简单方便的函数库组织方式:首先为所有函数库建立一个根目录,例如D:\AntLib;在该目录中根据函数的不同功能分别建立不同的子目录,在子目录中再根据函数的功能分别建立不同的脚本文件,将各个函数写在对应的脚本文件中,为目录、文件和函数取意义比较明显的名字;添加一个系统环境变量ANT_LIB,值为函数库的根目录,即D:\AntLib;在编写脚本时,如果需要调用函数库中的某个函数,只需要使用ant任务,根据环境变量ANT_LIB的值和函数所在脚本文件的相对路径计算出antfile属性的值,将函数的名字作为target属性的值就可以对函数进行调用。
函数的编写方式在第14章中已做了详细介绍。本小节继续介绍如何为15.2节中给出的DemoProject工程构建的例子编写函数。
观察构建流程图中的各个执行块,其中“新建lib目录”和“新建bin目录”可提炼为“在工程根目录中新建目录”函数,“复制key_v3.jar”和“复制key_v2.jar”可提炼为“复制文件”函数,“编译src目录”可提炼为“编译目录”函数。
(1)“在工程根目录中新建目录”函数
该函数向工程根目录中新建目录,将该函数实现为工程中的函数。如下:
<target name="MkDirInRootDir">
<mkdir dir="${dirName}"/>
</target>
(2)“复制文件”函数
该函数用于从3rdParty目录中复制文件到lib目录中,将该函数实现为工程中的函数,如下:
<target name="MoveFileFrom3rdPartyToLib">
<move file="../3rdParty/${fileName}" todir="lib" />
</target>
(3)“编译目录”函数
该函数用于编译指定目录下的所有java文件到指定的输出目录,该功能具有相对的普遍性,可以将其实现为函数库中的函数。根据该函数的功能,将其分类为Compile→javac,函数名为JavacDirToDest;根据所分的类,在Ant函数库根目录中新建Compile目录,在Compile目录中新建javac.xml文件,在该文件中实现函数体,如下:
<target name="JavacDirToDest">
<javac srcdir="${srcDir}" destdir="${destDir}" />
</target>
在完成了构建流程图和函数的编写后,就可以进行最终构建脚本的开发了。
第一步,编写脚本框架,添加project元素并为project元素添加name属性和default属性,同时添加一个空的default Target,如下:
<project name="DemoProject" default="root">
<target name="root"></target>
</project>
第二步,将编写的所有没有放到函数库中的函数添加到当前工程中,如DemoProject例中的MkDirInRootDir函数和MoveFileFrom3rdPartyToLib函数,脚本如下:
<project name="DemoProject" basedir="." default="root">
<target name="MkDirInRootDir">
<mkdir dir="${dirName}" />
</target>
<target name="MoveFileFrom3rdPartyToLib">
<move file="../3rdParty/${fileName}" todir="lib" />
</target>
<target name="root"></target>
</project>
第三步,如果需要在脚本中使用函数库中的函数,则将引用函数库的路径声明添加到工程中,如下:
<project name="DemoProject" basedir="." default="root">
<property environment="env" />
<property name="ant_lib" value="${env.ANT_LIB}" />
<target name="MkDirInRootDir">
<mkdir dir="${dirName}" />
</target>
<target name="MoveFileFrom3rdPartyToLib">
<move file="../3rdParty/${fileName}" todir="lib" />
</target>
<target name="root"></target>
</project>
第四步,编写每个执行块及判断。在不影响功能的前提下,可以适当调整执行块的顺序、可以将相邻执行块合并为一个Target、也可以将某些任务作为全局任务。通常,将会影响到整个脚本内容的任务作为全局任务,例如整个脚本都需要使用的全局变量的定义;将程序执行的前提条件、不依赖于其他任务以及在脚本执行中肯定要执行的任务放在“初始化”Target中,例如必备目录的创建。编写完执行块和判断后,脚本内容如下:
<project name="DemoProject" basedir="." default="root">
<property environment="env" />
<property name="ant_lib" value="${env.ANT_LIB}" />
<target name="MkDirInRootDir">
<mkdir dir="${dirName}" />
</target>
<target name="MoveFileFrom3rdPartyToLib">
<move file="../3rdParty/${fileName}" todir="lib" />
</target>
<target name="Init">
<antcall target="MkDirInRootDir" inheritall="false">
<param name="dirName" value="lib" />
</antcall>
<antcall target="MkDirInRootDir" inheritall="false">
<param name="dirName" value="bin" />
</antcall>
</target>
<target name="CopyKeyLib" depends="if,unless" />
<available file="../3rdParth/key_v3.jar" property="v3Available" />
<target name="if" if="v3Available">
<antcall target="MoveFileFrom3rdPartyToLib" inheritall="false">
<param name="fileName" value="key_v3.jar" />
</antcall>
</target>
<target name="unless" unless="v3Available">
<antcall target="MoveFileFrom3rdPartyToLib" inheritall="false">
<param name="fileName" value="key_v2.jar" />
</antcall>
</target>
<target name="Compile" >
<ant antfile="${ant_lib}/Compile/javac.xml" target="JavacDirToDest" inheritall="false">
<property name="srcDir" value="src" />
<property name="destDir" value="bin" />
</ant>
</target>
<target name="root"></target>
</project>
根据构建流程图中的各个步骤,其中又实现了三个Target:Init用于进行初始化,在工程根目录中创建lib和bin目录;CopyKeyLib用于复制key库,复制前判断key_v3.jar是否存在,根据情况复制适当的文件;Compile用于编译src目录。但到此为止脚本还没法正确执行,因为脚本的default Target还是root,它并没有做任何实质性的工作。
第五步,将已编写好的各个Target,考虑其内部依赖关系,根据其之间的依赖关系定义每个Target的depends属性。在该脚本中:
复制key库前必须lib目录已经存在,所以CopyKeyLib依赖于Init;
编译src目录前必须bin目录已经存在,所以Compile依赖于Init;
在编译src目录前必须key库已经复制到lib目录中,所以Compile依赖于CopyKeyLib;
root是default Target,root执行完后脚本就退出了,所以root必须在所有工作都完成了以后才能执行,所以root依赖于Init、CopyKeyLib和Compile。
根据以上对依赖关系的分析,可以得到:CopyKeyLib依赖于Init;Compile依赖于Init和CopyKeyLib;root依赖于Init、CopyKeyLib和Compile。为第四步得到的脚本中的相关Target添加depands属性,得到如下脚本内容:
<project name="DemoProject" basedir="." default="root">
<property environment="env" />
<property name="ant_lib" value="${env.ANT_LIB}" />
<target name="MkDirInRootDir">
<mkdir dir="${dirName}" />
</target>
<target name="MoveFileFrom3rdPartyToLib">
<move file="../3rdParty/${fileName}" todir="lib" />
</target>
<target name="Init">
<antcall target="MkDirInRootDir" inheritall="false">
<param name="dirName" value="lib" />
</antcall>
<antcall target="MkDirInRootDir" inheritall="false">
<param name="dirName" value="bin" />
</antcall>
</target>
<target name="CopyKeyLib" depends="Init,if,unless" />
<available file="../3rdParth/key_v3.jar" property="v3Available" />
<target name="if" if="v3Available">
<antcall target="MoveFileFrom3rdPartyToLib" inheritall="false">
<param name="fileName" value="key_v3.jar" />
</antcall>
</target>
<target name="unless" unless="v3Available">
<antcall target="MoveFileFrom3rdPartyToLib" inheritall="false">
<param name="fileName" value="key_v2.jar" />
</antcall>
</target>
<target name="Compile" depends="Init,CopyKeyLib">
<ant antfile="${ant_lib}/Compile/javac.xml" target="JavacDirToDest" inheritall="false">
<property name="srcDir" value="src" />
<property name="destDir" value="bin" />
</ant>
</target>
<target name="root" depends="Init,CopyKeyLib,Compile"></target>
</project>
虽然在脚本中有多个Target都依赖于同一个Target,例如CopyKeyLib、Compile和root都依赖于Init,但读者不用担心该Target会被执行多次,因为在Ant脚本中,依赖关系只是确保在依赖的Target执行前被依赖的Target已经执行过,所以在执行Compile时,如果发现在Init已经执行过就不会再次执行。所以,现在的脚本在功能上已经圆满完成需求的要求。但在脚本中由于有许多多重依赖存在,可能会为阅读脚本和分析脚本的执行流程带来一些复杂性,所以读者还可以根据第六步中介绍的方法对依赖关系进行简化。
第六步,前面已经介绍过,Target之间的依赖关系可以用一个有向无环图来表示,在图中每个Target用一个节点表示,Target之间的依赖关系用节点之间的有向边来表示,例如DemoProject工程中的几个Target的依赖关系如图15.9所示。
图15.9 最初的Target依赖关系图
该图描述了各Target之间的依赖关系,通过该图可以很方便地将工程中各Target的依赖关系进行简化,简化的方法就是删除所有多余的直接依赖,所谓多余的直接依赖就是存在于两个可以通过间接依赖相连的节点之间的依赖关系。例如,图15.9中Init通过CopyKeyLib可以到达root,所以从Init到达root的直接有向边就是一个多余的直接依赖,应该被删除;除此之外,还有CopyKeyLib到root的有向边和从Init到Compile的有向边也是多余的直接依赖。经过删除多余的直接依赖,可以得到如图15.10的依赖关系图。
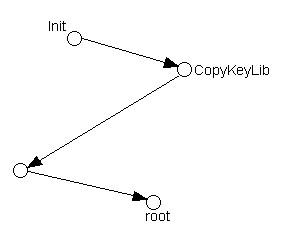
图15.10 化简后的Target依赖关系图
删除了多余的直接依赖后,得到的新的脚本如下:
<project name="DemoProject" basedir="." default="root">
<property environment="env" />
<property name="ant_lib" value="${env.ANT_LIB}" />
<target name="MkDirInRootDir">
<mkdir dir="${dirName}" />
</target>
<target name="MoveFileFrom3rdPartyToLib">
<move file="../3rdParty/${fileName}" todir="lib" />
</target>
<target name="Init">
<antcall target="MkDirInRootDir" inheritall="false">
<param name="dirName" value="lib" />
</antcall>
<antcall target="MkDirInRootDir" inheritall="false">
<param name="dirName" value="bin" />
</antcall>
</target>
<target name="CopyKeyLib" depends="Init,if,unless" />
<available file="../3rdParth/key_v3.jar" property="v3Available" />
<target name="if" if="v3Available">
<antcall target="MoveFileFrom3rdPartyToLib" inheritall="false">
<param name="fileName" value="key_v3.jar" />
</antcall>
</target>
<target name="unless" unless="v3Available">
<antcall target="MoveFileFrom3rdPartyToLib" inheritall="false">
<param name="fileName" value="key_v2.jar" />
</antcall>
</target>
<target name="Compile" depends="CopyKeyLib">
<ant antfile="${ant_lib}/Compile/javac.xml" target="JavacDirToDest" inheritall="false">
<property name="srcDir" value="src" />
<property name="destDir" value="bin" />
</ant>
</target>
<target name="root" depends="Compile"></target>
</project>
本章介绍了一种Ant结构化程序设计的基本方法,该方法包括以下步骤:
(1)分析需求,在充分理解需求的情况下逐步细化构建流程图:构建流程图是一种类似于普通程序流程图的图式体系,它可以帮助程序员充分理解和清晰描述待编写的Ant脚本的执行流程;
(2)构建流程图中抽象出函数并编写函数:函数是代码复用的基础和也是代码复用的基本元素,编写抽象度高的函数有利于将已有的代码复制到其他地方。所开发的函数根据其抽象程度的不同可分为函数库中的函数和工程中的函数;
(3)根据构建流程图和编写的函数组合成脚本。
Ant作为一种应用发布工具,在使用Eclipse开发Web应用时也是非常有用的。在进行Web应用开发之前可以首先将发布Web应用的脚本编写好,在开发期间可以不断地运行发布脚本将Web应用发布到Tomcat中,这样便于在开发Web应用期间不断地对当前开发的内容进行调试。
本章将首先对Eclipse中Web工程和Tomcat中Web应用的结构进行分析,然后利用Ant结构化程序设计的方法开发发布Web应用的脚本。
发布Web应用实质上就是将使用特定IDE(例如Eclipse)开发的Web工程发布到特定的Web服务器(例如Tomcat)上,使工程可以在Web服务器上正确的运行。本节就以将Eclipse构建Web工程发布到Tomcat上为例介绍如何使用Ant发布Web应用。
在编写Ant脚本之前首先需要明确待发布的Web工程的结构,以及需要将工程发布成什么结构才能使工程能够在Tomcat上正确运行。
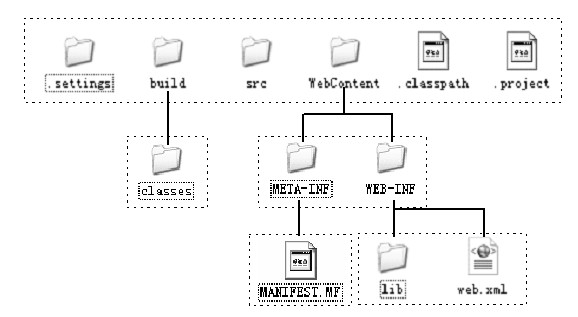
比较Eclipse中Web工程的结构和Tomcat中Web应用的结构,可以发现这两种结构具有相似之处,比如WEB-INF目录、lib目录、classes目录和web.xml文件等。在发布Web应用时,需要做的就是将Eclipse Web工程中的内容根据Tomcat对Web应用结构的要求组织到Tomcat的webapps目录中。所以,可以将发布的所有动作总结为如下几点:
(1)在Tomcat的webapps目录中新建一个空目录作为Web应用的根目录,该目录名即为该Web应用的上下文路径。通常可以将Eclipse中Web工程的名称作为该目录的名称;
(2)将WEB-INF目录及其中的子目录和文件复制到(1)中新建的目录中;
(3)将build目录下的classes目录中的所有文件和目录复制到Web应用的WEB-INF目录中;
(4)将Web工程中WebContent目录中除了WEB-INF和META-INF的所有目录和文件全部复制到Web应用根目录中。
分析构建流程图中的每个执行块,可以发现除了第一个“新建Web应用根目录”执行块是创建一个目录外,其他三个执行块都是从Eclipse的Web工程中向Tomcat的Web应用中复制文件或文件夹。
复制文件本身可以用一个任务完成,所以这里没必要为复制文件编写一个独立的函数。
由于在整个脚本中都要使用Web工程的根目录和Web应用的根目录,所以可以将这两个变量作为全局变量定义。但通常Web工程的根目录就作为该Ant脚本工程的根目录,所以Web工程的根目录可以不用定义。
全局变量的定义如下(假设将Web应用的上下文路径定义为WebTest):
<property environment="env" />
<property name="WebAppRoot" value="${env.TOMCAT_HOME}/webapps/WebTest" />
根据构建流程图中对各个执行块的描述,分别编写每个执行块,如下:
<target name="Init">
<mkdir dir="${WebAppRoot}" />
</target>
<target name="CopyWebInf">
<copy flatten="false" todir="${WebAppRoot}" overwrite="true">
<fileset dir="WebContent">
<include name="WEB-INF/lib/*" />
<include name="WEB-INF/web.xml" />
</fileset>
</copy>
</target>
<target name="CopyClasses">
<copy todir="${WebAppRoot}/WEB-INF" overwrite="true">
<fileset dir="build">
<include name="classes/**/*" />
</fileset>
</copy>
</target>
<target name="CopyOthers">
<copy todir="${WebAppRoot}" overwrite="true" includeemptydirs="false">
<fileset dir="WebContent">
<exclude name="WEB-INF/**/*" />
<exclude name="META-INF/**/*" />
</fileset>
</copy>
</target>
为了让这四个脚本顺序执行,可以通过设置每个Target的depends属性,让它依赖于前一个Target。但这里也可以将三个复制的执行块合成为一个Target,得到最终的执行脚本如下:
示例16.1 build.xml
<project name="DemoProject" basedir="." default="root">
<property environment="env" />
<property name="WebAppRoot" value="${env.TOMCAT_HOME}/webapps/WebTest" />
<target name="Init">
<mkdir dir="${WebAppRoot}" />
</target>
<target name="Copy" depends="Init">
<copy flatten="false" todir="${WebAppRoot}" overwrite="true">
<fileset dir="WebContent">
<include name="WEB-INF/lib/*" />
<include name="WEB-INF/web.xml" />
</fileset>
</copy>
<copy todir="${WebAppRoot}/WEB-INF" overwrite="true">
<fileset dir="build">
<include name="classes/**/*" />
</fileset>
</copy>
<copy todir="${WebAppRoot}" overwrite="true" includeemptydirs="false">
<fileset dir="WebContent">
<exclude name="WEB-INF/**/*" />
<exclude name="META-INF/**/*" />
</fileset>
</copy>
</target>
<target name="root" depends="Copy">
</target>
</project>
Struts2是目前最流行的MVC实现框架之一,也是最流行的Java Web开发框架之一。Struts2提供了一个MVC的框架,并且提供灵活的接口和配置文件,这使得程序员使用Struts2开发Web应用时,不需要自己搭建符合MVC模式的框架,而只需要关注应用相关的实现即可。
Struts2的得名是为了相对于早期出现的Struts框架(在Struts2出现后人们将这个框架称为Struts1),但实际上Struts2大部分是从另一个流行的框架WebWork发展而来。学习Struts2并不一定需要具备Struts或WebWork的知识。
Struts2是Apache基金会以WebWork框架为核心,吸收了Struts1的优秀成分而开发出来的MVC框架。Struts2的目标是让原来使用Struts1和WebWork的开发人员都能够平滑的过渡到Struts2上来。
Struts2不是像Eclipse或Tomcat一样的开发工具,也不是像Servlet或JSP一样的开发技术标准,而是一个根据MVC设计模式利用Servlet和JSP技术开发的一套Web系统框架。开发人员在使用Struts2开发Web系统时,不需要自己设计和实现基于MVC的框架,而只需要遵照Struts2的架构将业务逻辑填充到框架中就可以了。
Struts2是一个Web开发框架,如果想在系统中使用Struts2框架就必须下载Struts2的库,并且将库添加到系统的类路径中。
Struts2可以从其官方网站上下载:http://struts.apache.org/2.x/index.html。如图17.1所示。
图17.1 Struts2官方主页
点击Download Now进入下载页面,如图17.2所示。
图17.2 Struts2下载页面
该页面列出了Struts2最新版本的下载链接,这里提供了多种不同的下载内容,其中包括全发布(Full Distribution)、示例应用(Example Application)、空白应用框架(Blank Application only)、关键依赖包(Essential Dependencies Only)、文档(Documentation)、源代码(Source)、可切换的Java1.4库(Alternative Java 4 JARs),等等。读者可以选择全发布(Full Distribution),该下载包中包含了所有内容,其中就包括示例应用、依赖库、文档、源代码等。
将下载的文件struts-2.0.11.1-all.zip解压缩,获得的目录内容如图17.3所示。

图17.3 Struts2包目录内容
apps中包含了一些示例系统,每个系统是一个war文件,其中struts2-blank-2.0.11.1.war是一个空白示例系统,它并没有实现任何实际应用内容,而只是一个搭建了Struts2框架的空白系统,开发人员可以直接以该系统为基础在上面开发自己的系统。backport中提供了开源的工程Retrotranslator,该工程用于将使用JDK1.5编译的Java类转换成为可以在JVM1.4上运行的类。docs中是Struts2的文档。lib中是Struts2的各种库以及其所依赖的库。src是Struts2的源代码。
Struts2使用Servlet Filter而不是Servlet来实现MVC模式中的控制器,如图17.4所示为Struts2实现的MVC架构图。
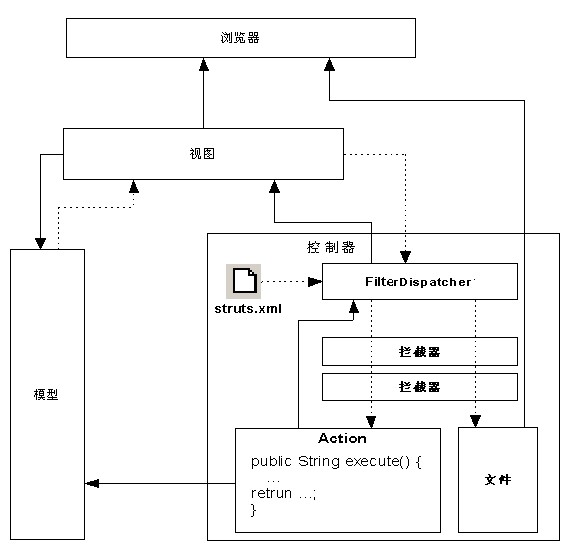
图17.4 Struts2实现的MVC架构
Struts2与其他MVC框架差别就在于控制器部分的实现方式,Struts2使用Servlet Filter技术实现控制器。
其中,FilterDispatcher是控制器的核心,它是一个实现了javax.servlet.Filter接口的Servlet 过滤器。Struts2正是使用这个过滤器来拦截来自客户端的消息并根据配置文件struts.xml对请求进行分发,以起到控制器的作用。是否使用这个控制器也正是一个应用是否是Struts2应用的根本标志。该过滤器可以根据配置文件中的配置对请求进行转发、重定向、直接返回响应消息等操作。
struts.xml是Struts2的核心配置文件,FilterDispathcher根据该文件中配置对请求进行操作。在该文件中定义了一系列的action,每个action定义了对一类请求的一种操作,即定义了根据请求URL的不同特征所需要调用的处理代码(用户实现的控制器具体代码,具体表现为一个Action类的处理方法),以及根据处理代码的执行结果所需要采取的操作。
拦截器是Struts2提供的一种AOP(Aspect-Oriented Programming,面向方面的程序设计)机制,它可以使开发者定义一段在Action执行前或执行后进行执行的代码,包括在一个Action执行前阻止其执行。通常可以用拦截器来完成一个方面的功能,比如记录日志、登录验证等。拦截器也在struts.xml中配置。
Action是一个标准的JavaBean,它实现了域成员的getter/setter方法和execute()方法;当execute()方法被调用时,它根据域成员的值执行方法体并且根据执行结果返回适当的返回值。该返回值将被返回到FilterDispatcher中,并且该返回值应该与struts.xml中对应的action定义中所设置的返回值相符合。
文件表示本地文件系统中的文件。当客户端请求的并不是某个Action,而是某个文件时,FilterDispatcher将查找文件并返回。
Struts2框架处理请求的流程大致如下:
(1)浏览器通过视图向Web服务器发出一个请求;
(2)请求到达服务器后会自动被核心控制器FilterDispatcher拦截;
(3)FilterDispatcher获取配置文件struts.xml中配置的所有Action以及每个Action的拦截器;FilterDispatcher根据请求的URL调用适当的拦截器和Action;
(4)执行所调用Action的execute()方法,并获得返回值;
(5)FilterDispatcher根据获得的返回值与struts.xml中的配置进行对比,对请求施加适当的操作,包括返回适当的视图、返回错误代码等。
web.xml是Web应用的唯一入口点,任何框架或者工具都必须配置到Web应用的web.xml文件中才能够被应用到Web应用中。Struts2框架也不例外,Struts2通过在核心控制器中使用FilterDispatcher对用户请求进行分发,所以对于Struts2应用来说必须将FilterDispatcher部署到web.xml中。
FilterDispatcher并不是一个Servlet,而是一个Servlet Filter,所以在web.xml中配置FilterDispatcher时,将其配置为一个Filter,如下:
<filter>
<filter-name>struts</filter-name>
<filter-class>org.apache.struts2.dispatcher.FilterDispatcher</filter-class>
</filter>
<filter-mapping>
<filter-name>struts</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
其中,org.apache.struts2.dispatcher.FilterDispatcher是FilterDispatcher的全包路径,将映射规则设为“/*”表示该Filter适用于所有的请求。这是在Web应用中使用Struts2框架最基本的设置。
如果还希望在Web应用的视图中使用Struts2的标签库,则还需要将标签库的配置添加到web.xml中。
该配置文件是Struts2的核心配置文件,从图17.4所示的Struts2的框架可以看到,该文件位于控制器中,用于指示FilterDispatcher如何对请求进行分发。所有Struts2应用的基本框架都是相同的,因为它们使用的都是Struts2的基本框架,而使用Struts2框架搭建的如此丰富的Web应用,它们的主要区别就是struts.xml的配置内容不同。
struts.xml文件用于定义Web应用的Action,每个Action对应于一个Java类,该类中定义了一段执行代码,当Action被调用时这段代码就会被执行。struts.xml中定义了Action的适用条件、所执行的Java类、根据Java类的不同执行结果所采取的动作、以及在执行Action时需要调用的拦截器或拦截器链。其中Action的适用条件指的是当请求满足何种条件时才调用该Action,配置文件中用一个模式表示,当请求的URL满足定义的模式时就调用Action。
struts.xml提供了方便的结构对Action和拦截器的定义进行组织:使用include标签将其他定义文件引入到当前文件中;使用package对Action和拦截器的定义进行封装,而且package还可以继承。
下面是定义struts.xml文件格式的DTD文件:
<!ELEMENT struts (package|include|bean|constant)*>
<!ELEMENT package (result-types?, interceptors?, default-interceptor-ref?,
default-action-ref?, global-results?, global-exception-mappings?, action*)>
<!ATTLIST package
name CDATA #REQUIRED
extends CDATA #IMPLIED
namespace CDATA #IMPLIED
abstract CDATA #IMPLIED
externalReferenceResolver NMTOKEN #IMPLIED>
<!ELEMENT result-types (result-type+)>
<!ELEMENT result-type (param*)>
<!ATTLIST result-type
name CDATA #REQUIRED
class CDATA #REQUIRED
default (true|false) "false">
<!ELEMENT interceptors (interceptor|interceptor-stack)+>
<!ELEMENT interceptor (param*)>
<!ATTLIST interceptor
name CDATA #REQUIRED
class CDATA #REQUIRED>
<!ELEMENT interceptor-stack (interceptor-ref+)>
<!ATTLIST interceptor-stack
name CDATA #REQUIRED>
<!ELEMENT interceptor-ref (param*)>
<!ATTLIST interceptor-ref
name CDATA #REQUIRED>
<!ELEMENT default-interceptor-ref (param*)>
<!ATTLIST default-interceptor-ref
name CDATA #REQUIRED>
<!ELEMENT default-action-ref (param*)>
<!ATTLIST default-action-ref
name CDATA #REQUIRED>
<!ELEMENT global-results (result+)>
<!ELEMENT global-exception-mappings (exception-mapping+)>
<!ELEMENT action (param|result|interceptor-ref|exception-mapping)*>
<!ATTLIST action
name CDATA #REQUIRED
class CDATA #IMPLIED
method CDATA #IMPLIED
converter CDATA #IMPLIED>
<!ELEMENT param (#PCDATA)>
<!ATTLIST param
name CDATA #REQUIRED>
<!ELEMENT result (#PCDATA|param)*>
<!ATTLIST result
name CDATA #IMPLIED
type CDATA #IMPLIED>
<!ELEMENT exception-mapping (#PCDATA|param)*>
<!ATTLIST exception-mapping
name CDATA #IMPLIED
exception CDATA #REQUIRED
result CDATA #REQUIRED>
<!ELEMENT include (#PCDATA)>
<!ATTLIST include
file CDATA #REQUIRED>
<!ELEMENT bean (#PCDATA)>
<!ATTLIST bean
type CDATA #IMPLIED
name CDATA #IMPLIED
class CDATA #REQUIRED
scope CDATA #IMPLIED
static CDATA #IMPLIED
optional CDATA #IMPLIED>
<!ELEMENT constant (#PCDATA)>
<!ATTLIST constant
name CDATA #REQUIRED
value CDATA #REQUIRED>
为了便于读者直观地了解定义的结构,图17.5用树形结构示出了该DTD文件所定义的struts.xml文件的结构。
图17.5中,长方形的方框表示XML文件的一个元素的名称,括号中是该元素可以定义的所有属性名;一个树节点的子节点表示当前节点可以定义的子元素;元素名后面标识的* ?和+表示当前节点在该位置上所能出现的情况,*表示0次或多次,?表示0次或1次,+表示1次或多次。
在图17.5的下部定义了四个单独的节点,它们是这四个节点的定义情况,这四个节点会在整体结构的多处位置被引用。
整个配置文件的根节点是struts节点。
package定义了一个模块,一个模块是对一组配置的封装,包括action的配置,拦截器的配置等。package由其name属性的值唯一区分,所以package的name必须是唯一的。package的extends属性定义了一种继承关系,子package继承了父package中的所有配置,父package的配置对于子package也有效;struts-default是struts-default.xml中定义的一个package。namespace定义了package的命名空间,该命名空间是一个相对URL,该相对URL就是访问package中定义的action的相对URL。假如在namespace为“/test”的package中定义了一个name为login的Action,那么访问该Action的URL应该是:
http://localhost:8080/app/test/login.action
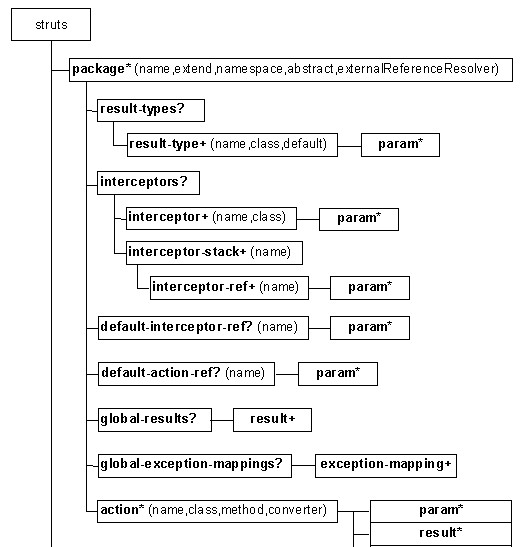
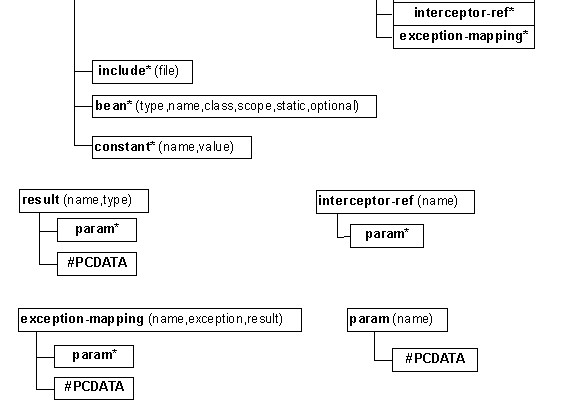
图17.5 sturts.xml文件内容结构图
package的abstract属性用于表示当前的package是否是抽象的,抽象的package中不能定义action。externalReferenceResolver属性允许为当前package指定一个外部引用的解析器,通常这个属性很少使用。
package中允许对result-types、interceptors和actions进行定义,result-type、interceptor/interceptor-stack和action都必须先定义然后再进行引用;这里定义的result-type、interceptor和action在当前package以及继承了当前package的package中有效。另外,package中还定义了一些适用于package及子package中所有Action的默认信息或全局信息,default-interceptor-ref定义了一个默认的拦截器引用,假如某个Action中没有定义任何拦截器引用那么就会引用默认的拦截器,但如果定义了其他拦截器引用则默认的拦截器将不会起作用;default-action-ref定义了一个默认的Action引用,当package中已定义的所有Action中没有任何一个与请求相匹配,则会调用默认的Action执行;global-results中定义了一些result,这些result可以被应用到所有该package及子package中定义的所有Action的执行结果;global-exception-mappings定义了一些exception-mapping,这些exception-mapping适用于package及子package中定义的所有Action。
一个result-types元素中可以定义一个或多个result-type,每个result-type定义了一种result类型,在action的配置信息和global-results的配置信息中定义的所有result的type属性必须引用已定义的result-type。result-type的name和class分别指定了该result-type的名称和所调用的类,default属性通过true/false指示当前result-type是否是默认的result-type。name属性用于标识该result-type,在result的type属性中就通过result-type的name属性指定type;class属性指定的Java类用于处理该类result,result指定的功能就是通过指定的Java类对result进行处理而实现的。
interceptors中可以定义若干的拦截器和拦截器链,这些拦截器和拦截器链可以在各个Action的配置内容中通过interceptor-ref进行引用,拦截器和拦截器链也是必须先定义后才能引用。interceptor用于定义一个拦截器,name属性和class属性分别指定了该拦截器的名称和实现该拦截器的Java类。interceptor-stack用于定义一个拦截器链,name属性是拦截器链的名称,拦截器链中通过interceptor-ref引用已定义的拦截器,其中的拦截器就是该拦截器链中包含的拦截器。
actions用于定义package中的Action,这是最核心和最重要的配置项。name和class属性定义了Action的名称和实现该Action的Java类;method属性指定了所要执行的Java类中的方法名,默认是execute;converter允许为Action定义一个转换器。Action的param用于定义参数,该参数将被传递到执行操作的Action类中;result是为该Action定义结果处理方式,每个result定义一种处理方式,result的name属性定义了一个字符串,当Action类执行的返回结果与result的name一致时就按这种result处理执行结果,result的type指向一个已定义的result-type;interceptor-ref为当前Action定义拦截器,如果该Action需要被执行时就会首先执行定义的这些拦截器;exception-mapping为该Action定义了特有的异常处理方式。
include是将另外一个文件引入到当前文件的方法,这是struts2组件化的方式,可以将每个功能模块的配置信息独立到一个xml配置文件中,然后再用include标签引用。file属性指向待引入的文件。
bean用于定义Struts2使用的JavaBean组件,name和class属性分别定义了bean的名称和实现类;type表示该bean的类型,也就是该bean的实现类所实现的接口;scope表示该bean的作用范围;static指定该bean是否是静态bean;optional指示该bean是否是可选的。
constant用于定义一个常量,该常量是Struts2框架中的一个属性,name是属性名,value是属性值,这些属性用于为Struts2框架提供一些设置以使其具备不同的行为。具体的各种属性将在17.2.3节做详细介绍。
如下是一个简单的struts.xml配置文件的示例:
<struts>
<include file="struts-default.xml"></include>
<package name="cn.csai.web.struts2" extends="struts-default" namespace="/test">
<interceptors>
<interceptor name="timer" class=" cn.csai.web.struts2.timer"></interceptor>
<interceptor name="logger" class=" cn.csai.web.struts2.logger"></interceptor>
<interceptor-stack name="mystack">
<interceptor-ref name="timer"></interceptor-ref>
<interceptor-ref name="logger"></interceptor-ref>
</interceptor-stack>
</interceptors>
<default-interceptor-ref name="mystack"></default-interceptor-ref>
<global-results>
<result name="error">/error.jsp</result>
</global-results>
<action name="login" class=" cn.csai.web.struts2.Action.LoginAction">
<interceptor-ref name="timer"></interceptor-ref>
<result name="success" type="dispatcher">/welcome.jsp</result>
<param name="email">username@website.com</param>
</action>
</package>
</struts>
该文件引入了struts-default.xml文件,并且定义了一个继承自struts-default package的package。其中定义了两个拦截器和一个拦截器链,拦截器链包含这两个拦截器。并且将拦截器链作为默认的拦截器引用;定义了一个全局result,即无论package中的哪个Action返回error,则返回error.jsp。
其中定义了一个login Action,由cn.csai.web.struts2.Action.LoginAction实现。当访问http://localhost: 8080/AppName/test/login.action时(其中AppName为Web应用的上下文路径),框架会自动调用LoginAction的execute()方法,在调用之前会先经过timer拦截器处理,并且通过setEmail()方法和/或其他setter方法将username@website.com及其他请求参数设置到LoginAction的私有域成员中;然后执行execute()方法;执行完后,如果返回的是“success”,则会返回welcome.jsp给客户端,如果返回的是“error”,则会返回error.jsp给客户端。
struts-default.xml是Struts2自带的配置文件,它提供了许多常用的基本配置,包括许多bean、struts-default package和各种拦截器。程序员在对自己应用的struts.xml文件进行配置时可以包含该文件并且继承其中定义的struts-default package,这样大大简化了工作量。基本上,所有的Struts2应用的struts.xml配置文件都是在该文件的基础之上进行配置的。
在解压Struts2压缩包所获得的目录中有一个lib目录,该目录中包含了Struts2所需要的jar包;打开其中的struts2-core-2.0.11.1.jar,其中就包含struts-default.xml文件,内容如下:
<struts>
<bean class="com.opensymphony.xwork2.ObjectFactory" name="xwork" />
<bean type="com.opensymphony.xwork2.ObjectFactory" name="struts"
class="org.apache.struts2.impl. StrutsObjectFactory" />
<bean type="com.opensymphony.xwork2.ActionProxyFactory" name="xwork"
class="com.opensymphony. xwork2.DefaultActionProxyFactory"/>
<bean type="com.opensymphony.xwork2.ActionProxyFactory" name="struts"
class="org.apache.struts2. impl.StrutsActionProxyFactory"/>
<bean type="com.opensymphony.xwork2.util.ObjectTypeDeterminer" name="tiger"
class="com. opensymphony.xwork2.util.GenericsObjectTypeDeterminer"/>
<bean type="com.opensymphony.xwork2.util.ObjectTypeDeterminer" name="notiger"
class="com. opensymphony.xwork2.util.DefaultObjectTypeDeterminer"/>
<bean type="com.opensymphony.xwork2.util.ObjectTypeDeterminer" name="struts"
class="com. opensymphony.xwork2.util.DefaultObjectTypeDeterminer"/>
<bean type="org.apache.struts2.dispatcher.mapper.ActionMapper" name="struts"
class="org.apache. struts2.dispatcher.mapper.DefaultActionMapper" />
<bean type="org.apache.struts2.dispatcher.mapper.ActionMapper" name="composite"
class="org.apache. struts2.dispatcher.mapper.CompositeActionMapper" />
<bean type="org.apache.struts2.dispatcher.mapper.ActionMapper" name="restful"
class="org.apache. struts2.dispatcher.mapper.RestfulActionMapper" />
<bean type="org.apache.struts2.dispatcher.mapper.ActionMapper" name="restful2"
class="org.apache. struts2.dispatcher.mapper.Restful2ActionMapper" />
<bean type="org.apache.struts2.dispatcher.multipart.MultiPartRequest" name="struts"
class="org.apache. struts2.dispatcher.multipart.JakartaMultiPartRequest" scope="default" optional="true"/>
<bean type="org.apache.struts2.dispatcher.multipart.MultiPartRequest" name="jakarta"
class="org. apache.struts2.dispatcher.multipart.JakartaMultiPartRequest" scope="default" optional="true" />
<bean type="org.apache.struts2.views.TagLibrary" name="s"
class="org.apache.struts2.views. DefaultTagLibrary" />
<bean class="org.apache.struts2.views.freemarker.FreemarkerManager" name="struts" optional="true"/>
<bean class="org.apache.struts2.views.velocity.VelocityManager" name="struts" optional="true" />
<bean class="org.apache.struts2.components.template.TemplateEngineManager" />
<bean type="org.apache.struts2.components.template.TemplateEngine" name="ftl"
class="org.apache. struts2.components.template.FreemarkerTemplateEngine" />
<bean type="org.apache.struts2.components.template.TemplateEngine" name="vm"
class="org.apache. struts2.components.template.VelocityTemplateEngine" />
<bean type="org.apache.struts2.components.template.TemplateEngine" name="jsp"
class="org.apache. struts2.components.template.JspTemplateEngine" />
<bean type="com.opensymphony.xwork2.util.XWorkConverter" name="xwork1"
class="com.open symphony.xwork2.util.XWorkConverter" />
<bean type="com.opensymphony.xwork2.util.XWorkConverter" name="struts"
class="com.opensymphony. xwork2.util.AnnotationXWorkConverter" />
<bean type="com.opensymphony.xwork2.TextProvider" name="xwork1"
class="com.opensymphony. xwork2.TextProviderSupport" />
<bean type="com.opensymphony.xwork2.TextProvider" name="struts"
class="com.opensymphony. xwork2.TextProviderSupport" />
<bean class="com.opensymphony.xwork2.ObjectFactory" static="true" />
<bean class="com.opensymphony.xwork2.util.XWorkConverter" static="true" />
<bean class="com.opensymphony.xwork2.util.OgnlValueStack" static="true" />
<bean class="org.apache.struts2.dispatcher.Dispatcher" static="true" />
<bean class="org.apache.struts2.components.Include" static="true" />
<bean class="org.apache.struts2.dispatcher.FilterDispatcher" static="true" />
<bean class="org.apache.struts2.views.util.ContextUtil" static="true" />
<bean class="org.apache.struts2.views.util.UrlHelper" static="true" />
<package name="struts-default" abstract="true">
<result-types>
<result-type name="chain" class="com.opensymphony.xwork2.ActionChainResult"/>
<result-type name="dispatcher"
class="org.apache.struts2.dispatcher.ServletDispatcherResult" default="true"/>
<result-type name="freemarker" class="org.apache.struts2.views.freemarker.FreemarkerResult"/>
<result-type name="httpheader"
class="org.apache.struts2.dispatcher.HttpHeaderResult"/>
<result-type name="redirect"
class="org.apache.struts2.dispatcher.ServletRedirect Result"/>
<result-type name="redirectAction"
class="org.apache.struts2.dispatcher.ServletAction RedirectResult"/>
<result-type name="stream"
class="org.apache.struts2.dispatcher.StreamResult"/>
<result-type name="velocity"
class="org.apache.struts2.dispatcher.VelocityResult"/>
<result-type name="xslt" class="org.apache.struts2.views.xslt.XSLTResult"/>
<result-type name="plainText" class="org.apache.struts2.dispatcher.PlainTextResult" />
<result-type name="redirect-action" class="org.apache.struts2.dispatcher.ServletAction RedirectResult"/>
<result-type name="plaintext"
class="org.apache.struts2.dispatcher.PlainTextResult" />
</result-types>
<interceptors>
<interceptor name="alias"
class="com.opensymphony.xwork2.interceptor.AliasInterceptor"/>
<interceptor name="autowiring"
class="com.opensymphony.xwork2.spring.interceptor. ActionAutowiringInterceptor"/>
<interceptor name="chain"
class="com.opensymphony.xwork2.interceptor.ChainingInterceptor"/>
<interceptor name="conversionError"
class="org.apache.struts2.interceptor.StrutsConversion ErrorInterceptor"/>
<interceptor name="cookie" class="org.apache.struts2.interceptor.CookieInterceptor"/>
<interceptor name="createSession"
class="org.apache.struts2.interceptor.CreateSessionInterceptor" />
<interceptor name="debugging"
class="org.apache.struts2.interceptor.debugging.Debugging Interceptor" />
<interceptor name="externalRef"
class="com.opensymphony.xwork2.interceptor.External ReferencesInterceptor"/>
<interceptor name="execAndWait"
class="org.apache.struts2.interceptor.ExecuteAndWait Interceptor"/>
<interceptor name="exception"
class="com.opensymphony.xwork2.interceptor.ExceptionMapping Interceptor"/>
<interceptor name="fileUpload"
class="org.apache.struts2.interceptor.FileUploadInterceptor"/>
<interceptor name="i18n"
class="com.opensymphony.xwork2.interceptor.I18nInterceptor"/>
<interceptor name="logger"
class="com.opensymphony.xwork2.interceptor.LoggingInterceptor"/>
<interceptor name="modelDriven"
class="com.opensymphony.xwork2.interceptor.ModelDriven Interceptor"/>
<interceptor name="scopedModelDriven"
class="com.opensymphony.xwork2.interceptor.Scoped ModelDrivenInterceptor"/>
<interceptor name="params"
class="com.opensymphony.xwork2.interceptor.Parameters Interceptor"/>
<interceptor name="prepare"
class="com.opensymphony.xwork2.interceptor.PrepareInterceptor"/>
<interceptor name="staticParams"
class="com.opensymphony.xwork2.interceptor.Static ParametersInterceptor"/>
<interceptor name="scope"
class="org.apache.struts2.interceptor.ScopeInterceptor"/>
<interceptor name="servletConfig"
class="org.apache.struts2.interceptor.ServletConfig Interceptor"/>
<interceptor name="sessionAutowiring"
class="org.apache.struts2.spring.interceptor. SessionContextAutowiringInterceptor"/>
<interceptor name="timer"
class="com.opensymphony.xwork2.interceptor.TimerInterceptor"/>
<interceptor name="token" class="org.apache.struts2.interceptor.TokenInterceptor"/>
<interceptor name="tokenSession"
class="org.apache.struts2.interceptor.TokenSession StoreInterceptor"/>
<interceptor name="validation"
class="org.apache.struts2.interceptor.validation.Annotation ValidationInterceptor"/>
<interceptor name="workflow"
class="com.opensymphony.xwork2.interceptor.Default Workflow Interceptor"/>
<interceptor name="store"
class="org.apache.struts2.interceptor.MessageStoreInterceptor" />
<interceptor name="checkbox"
class="org.apache.struts2.interceptor.CheckboxInterceptor" />
<interceptor name="profiling"
class="org.apache.struts2.interceptor.ProfilingActivation Interceptor" />
<interceptor name="roles"
class="org.apache.struts2.interceptor.RolesInterceptor" />
<interceptor-stack name="basicStack">
<interceptor-ref name="exception"/>
<interceptor-ref name="servletConfig"/>
<interceptor-ref name="prepare"/>
<interceptor-ref name="checkbox"/>
<interceptor-ref name="params"/>
<interceptor-ref name="conversionError"/>
</interceptor-stack>
<interceptor-stack name="validationWorkflowStack">
<interceptor-ref name="basicStack"/>
<interceptor-ref name="validation"/>
<interceptor-ref name="workflow"/>
</interceptor-stack>
<interceptor-stack name="fileUploadStack">
<interceptor-ref name="fileUpload"/>
<interceptor-ref name="basicStack"/>
</interceptor-stack>
<interceptor-stack name="modelDrivenStack">
<interceptor-ref name="modelDriven"/>
<interceptor-ref name="basicStack"/>
</interceptor-stack>
<interceptor-stack name="chainStack">
<interceptor-ref name="chain"/>
<interceptor-ref name="basicStack"/>
</interceptor-stack>
<interceptor-stack name="i18nStack">
<interceptor-ref name="i18n"/>
<interceptor-ref name="basicStack"/>
</interceptor-stack>
<interceptor-stack name="paramsPrepareParamsStack">
<interceptor-ref name="exception"/>
<interceptor-ref name="alias"/>
<interceptor-ref name="params"/>
<interceptor-ref name="servletConfig"/>
<interceptor-ref name="prepare"/>
<interceptor-ref name="i18n"/>
<interceptor-ref name="chain"/>
<interceptor-ref name="modelDriven"/>
<interceptor-ref name="fileUpload"/>
<interceptor-ref name="checkbox"/>
<interceptor-ref name="staticParams"/>
<interceptor-ref name="params"/>
<interceptor-ref name="conversionError"/>
<interceptor-ref name="validation">
<param name="excludeMethods">input,back,cancel</param>
</interceptor-ref>
<interceptor-ref name="workflow">
<param name="excludeMethods">input,back,cancel</param>
</interceptor-ref>
</interceptor-stack>
<interceptor-stack name="defaultStack">
<interceptor-ref name="exception"/>
<interceptor-ref name="alias"/>
<interceptor-ref name="servletConfig"/>
<interceptor-ref name="prepare"/>
<interceptor-ref name="i18n"/>
<interceptor-ref name="chain"/>
<interceptor-ref name="debugging"/>
<interceptor-ref name="profiling"/>
<interceptor-ref name="scopedModelDriven"/>
<interceptor-ref name="modelDriven"/>
<interceptor-ref name="fileUpload"/>
<interceptor-ref name="checkbox"/>
<interceptor-ref name="staticParams"/>
<interceptor-ref name="params">
<param name="excludeParams">dojo\..*</param>
</interceptor-ref>
<interceptor-ref name="conversionError"/>
<interceptor-ref name="validation">
<param name="excludeMethods">input,back,cancel,browse</param>
</interceptor-ref>
<interceptor-ref name="workflow">
<param name="excludeMethods">input,back,cancel,browse</param>
</interceptor-ref>
</interceptor-stack>
<interceptor-stack name="completeStack">
<interceptor-ref name="defaultStack"/>
</interceptor-stack>
<interceptor-stack name="executeAndWaitStack">
<interceptor-ref name="execAndWait">
<param name="excludeMethods">input,back,cancel</param>
</interceptor-ref>
<interceptor-ref name="defaultStack"/>
<interceptor-ref name="execAndWait">
<param name="excludeMethods">input,back,cancel</param>
</interceptor-ref>
</interceptor-stack>
<interceptor name="external-ref" class="com.opensymphony.xwork2.interceptor.External ReferencesInterceptor"/>
<interceptor name="model-driven" class="com.opensymphony.xwork2.interceptor.Model DrivenInterceptor"/>
<interceptor name="static-params" class="com.opensymphony.xwork2.interceptor.Static ParametersInterceptor"/>
<interceptor name="scoped-model-driven" class="com.opensymphony.xwork2.interceptor.Scoped ModelDrivenInterceptor"/>
<interceptor name="servlet-config" class="org.apache.struts2.interceptor.ServletConfig Interceptor"/>
<interceptor name="token-session" class="org.apache.struts2.interceptor.TokenSessionStore Interceptor"/>
</interceptors>
<default-interceptor-ref name="defaultStack"/>
</package>
</struts>
从文件内容中可以发现,该配置文件主要了若干的bean和拦截器/拦截器链,还定义了默认的struts-default package。程序员在对自己的应用进行配置时,可以参照该文件的内容引用其中已定义的内容,可大大简化用户系统的配置和实现。由于篇幅有限,具体的含义这里不作介绍。
Struts2应用中另一个比较重要的配置文件就是struts.properties,这个文件是一个标准的Java Properties文件。与struts.xml不同的是这个文件主要用于设置Struts2框架的属性,Struts2框架在Web应用运行期间根据该配置文件中所设置属性的不同值而采取不同的行为。
Struts2框架定义了若干个有效的属性,只有属性文件中定义的属性属于有效的属性时才会被Struts2框架识别和接受。其中常见的属性如表17.1所示。
表17.1 Struts2框架的属性列表
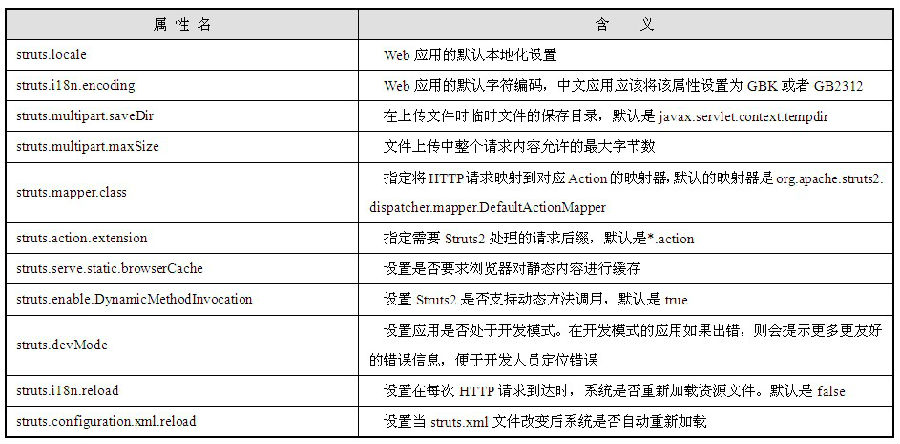
struts.properties文件必须位于Web应用的类加载路径中,通常将其放在Web应用的WEB-INF/classes目录中。
其实这些属性也可以在struts.xml文件中配置,所起到的作用是一样的。在struts.xml文件中通过constant元素配置,如下:
<?xml version="1.0" encoding="UTF-8" ?>
<struts>
<constant name="struts.devMode" value="true" />
...
</struts>
Struts2应用从本质上说就是一种Web应用,只不过它是使用了Struts2框架的Web应用。本节将在前面介绍的开发普通Web应用的基础上进一步介绍如何用Eclipse、Tomcat和Ant开发Struts2应用。
因为Struts2应用仍旧是一个Web应用,Eclipse并没有对Struts2应用提供特殊的设置,所以在使用Eclipse开发Struts2应用时首先还是在Eclipse中新建一个动态Web工程。有关在Eclipse中新建工程的方法在第5章已经做了详细介绍,这里就不再详述。假设建成的动态Web工程为Struts2Test,新建的工程没有任何实质内容,如图17.6所示。
图17.6 新建的Struts2Test工程
然后向Web应用中添加Struts2框架。
1.添加支持库
Struts2应用必需有Struts2库的支持才能够运行,同样Struts2工程也必须要有Struts2库才能够编译。Struts2的所有库文件都在发布目录中的lib目录中,如图17.7所示。
图17.7 Struts2发布的所有库文件
虽然Struts2的发布中包含了如此多的jar文件,但是并不是所有jar文件都是每个Struts2应用必须的。其中必须的jar文件只有5个:commons-logging-1.0.4.jar、freemarker-2.3.8.jar、ognl-2.6.11.jar、struts2-core-2.0.11.1.jar和xwork-2.0.4.jar。只有在动态Web工程中添加这些库文件后才能在Web工程中使用Struts2框架。
有两种方法可以将这些库添加到Web工程中。
新建用户库并添加到工程中
这种方法是首先在Eclipse中定义一个用户库,并将Struts2的库文件添加到该用户库中;在开发Struts2应用时只需要将该用户库添加到工程中即可。
读者可以按照4.2.2节介绍的方法在Eclipse中定义一个Struts2的用户库,在以后使用时只需要在Web工程中添加该用户库即可。方法如下:
(1)在菜单Windows→Preference...打开的对话框中选择Java→Build Path→User Libraries选项,在右边窗口中新建一个用户库Struts2。
(2)点击Add JARs...按钮,在打开的文件选择器中选择Struts2解压目录下lib目录中的5个必需的jar文件。确定后就已将这几个jar添加到Struts2用户库中,完成后的用户库定义窗口如图17.8所示:
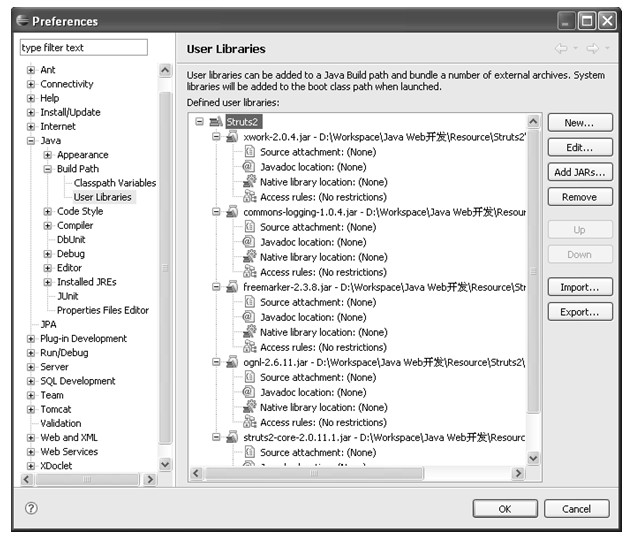
图17.8 Struts2用户库定义成功
(3)定义完用户库后,需要将用户库添加到Web工程中。以Struts2Test工程为例,在工程浏览器视图中右键单击工程名,在右键菜单中选择Properties菜单项,弹出工程属性对话框。
(4)在工程属性对话框中选择Java Build Path配置项,在右边窗口中选择Libraries配置页。
(5)点击配置页中的Add Libraries...按钮,弹出Add Library对话框,如图17.9所示。
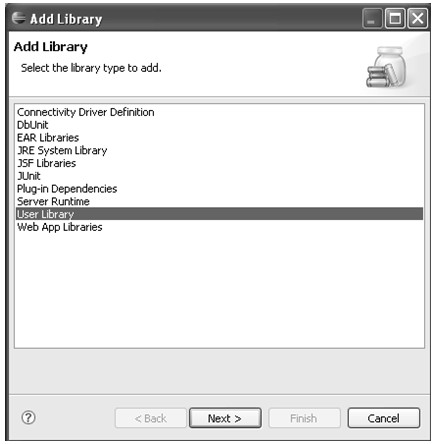
图17.9 Add Library对话框
(6)在对话框中的列表中选择User Library然后点击Next>按钮,对话框就会显示Eclipse中已定义的用户库,包括刚刚定义的Struts2用户库,如图17.10所示。
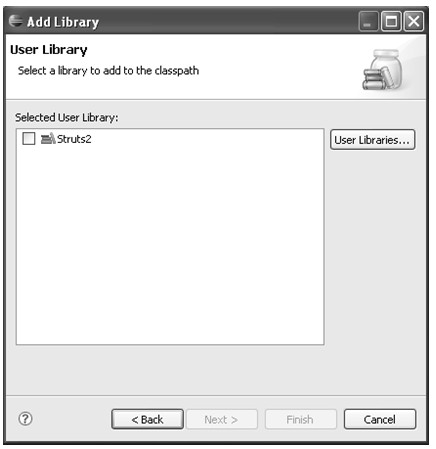
图17.10 选择用户库
(7)选中Struts2用户库前面的复选框,然后点击Finish按钮完成用户库的添加。
复制Struts2库到工程中并作为工程的库文件添加到工程中
首先将Struts2的库文件复制到Web工程的WEB-INF/lib目录中,然后在工程属性的Java Build Path页的Libraries标签页中点击Add JARs...按钮,弹出窗口如图17.11所示。
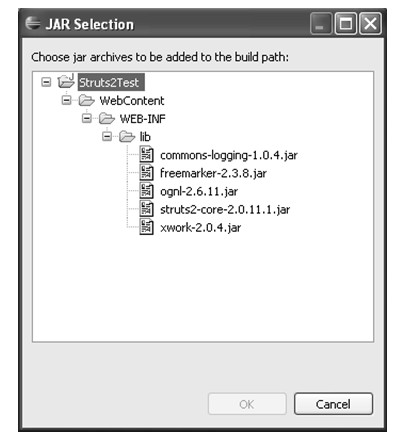
图17.11 选择工程中的JAR文件
使用Ctrl或者Shift快捷键将5个jar文件同时选中,然后点击OK就可以将这5个库文件添加到工程中。
2.修改web.xml文件
初始的web.xml中并没有配置任何的Servlet或Servlet Filter。使用Struts2框架的Web应用的web.xml文件中必需配置FilterDispatcher过滤器,这样Tomcat在加载Web应用时才能加载FilterDispatcher过滤器,Struts2框架也才能起作用。
向web.xml中添加Filter的配置,在web.xml文件中的web-app根元素下直接添加:
<filter>
<filter-name>struts</filter-name>
<filter-class>org.apache.struts2.dispatcher.FilterDispatcher</filter-class>
</filter>
<filter-mapping>
<filter-name>struts</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
3.添加struts.xml文件
struts.xml文件是Struts2应用必需的配置文件,通常放在Web应用的WEB-INF/classes目录中;在Eclipse的工程中就应该将该文件放在src的根目录中,因为Eclipse在编译工程时会自动将src目录中的所有非java文件直接复制到工程的classes目录中,而在发布Web应用时会将classes目录中的内容全部发布到WEB-INF/classes目录中。
在src目录中新建一个xml文件,文件名为struts.xml,并向其中添加如下内容:
<?xml version="1.0" encoding="UTF-8"?>
<struts>
<include file="struts-default.xml"></include>
<package name="cn.csai.web.struts2" extends="struts-default" namespace="/struts2test">
</package>
</struts>
这是一个基本的struts.xml文件的基本框架,在开发实际应用时根据需求向package中添加action配置。其中package的name和namespace属性都是个示例,在具体的应用中需要根据实际情况加以修改。
4.添加struts.properties文件
与struts.xml配置文件类似,在src目录中新建一个空白的文本文件,文件名为struts.properties。该文件的内容需要根据具体应用的需求具体添加,读者可以根据前面对各种属性的说明添加相应的属性。初学者也可以不用添加任何属性,而都使用默认的设置。
5.开发Action
Action是Struts2的基本处理单元,也是开发人员处理具体业务逻辑的地方。Action的不同也是一个Struts2应用区别于另一个Struts2应用的主要部分,但是Action的开发也有其共同的部分。Action是Java类,所以必须将其放置在适当的包中,首先在工程的src目录中新建包cn.csai.web.struts2。
在包中新建一个Java类,并且继承com.opensymphony.xwork2.ActionSupport类。在类中重写父类中的execute()方法,该方法的原型如下:
public String execute() throws Exception {
...
}
该方法在Action被调用时执行,执行完后返回一个字符串。该方法是无参方法,所有参数都只能通过setter方法传进来,所以Action的每一个域变量都必须实现setter和getter方法。Struts2的核心控制器在调用Action前首先通过setter方法将参数设置到Action对象中,然后在调用execute()方法执行操作。
以用户登录为例,在用户登录系统时,登录的Action需要判断登录的用户名和密码是否正确,正确则返回字符串“yes”,错误则返回字符串“no”。首先新建LogonAction,并且继承com.opensymphony.xwork2.ActionSupport;在类中定义私有字符串域userName和password,并且为这两个域添加相应的setter和getter方法;重写父类中的execute()方法,在execute()中判断当前的userName和password是否合法和匹配,根据判断结果返回适当的字符串。该LogonAction类的内容大致如下:
package cn.csai.web.struts2;
import com.opensymphony.xwork2.ActionSupport;
public class LogonAction extends ActionSupport {
private String userName;
private String password;
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
@Override
public String execute() throws Exception {
if(isMatch(userName, password))
return "yes";
return "no";
}
}
6.在struts.xml中添加Action配置
开发的Action必须被配置到struts.xml中才会被Struts2框架识别和调用。在前面已经新建的struts.xml文件中的package元素中添加action子元素,一个action子元素表示一个Action。
按照struts.xml配置文件的格式将开发的Action配置到struts.xml中,并且可以根据需要添加相应的拦截器。
前面已经提到过,Struts2应用只是使用了Struts2框架的Web应用,在将Struts2应用部署到Tomcat中后,Tomcat并不知道Struts2框架的存在,它还是按照一个普通的Web应用进行处理。
从另一个角度讲,Struts2框架也正是按照Tomcat对普通Web应用的处理方式而开发的,Struts2框架并不需要Tomcat提供任何特殊的支持。
Struts2应用与普通Web应用的不同点在于:
特殊的web.xml配置:Struts2要求在web.xml中配置FilterDispatcher作为默认的Filter,这在前面已经有所介绍;
在应用中添加Struts2的库:Struts2有5个必需库,任何使用了Struts2框架的应用都必须讲这几个库添加到类路径中,可以是Tomcat的lib目录中,也可以是Web应用的WEB-INF/lib目录中;
在类路径中添加struts.xml配置文件:Struts2框架的运行必须有struts.xml文件,所以Struts2应用必须将格式正确的struts.xml文件添加到应用的类路径中,通常在Web应用的WEB-INF/classes目录中。
所以Struts2应用在普通Web应用的基础上添加了一些内容,如图17.12所示。
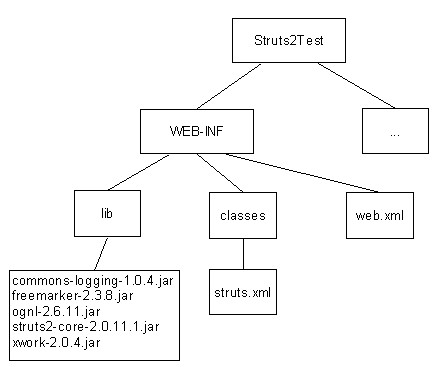
图17.12 Struts2应用内容
在16章中介绍了使用Ant发布Web应用的方法,最终使用的发布脚本如下:
<project name="DemoProject" basedir="." default="root">
<property environment="env" />
<property name="WebAppRoot" value="${env.TOMCAT_HOME}/webapps/WebTest" />
<target name="Init">
<mkdir dir="${WebAppRoot}" />
</target>
<target name="Copy" depends="Init">
<copy flatten="false" todir="${WebAppRoot}" overwrite="true">
<fileset dir="WebContent">
<include name="WEB-INF/lib/*" />
<include name="WEB-INF/web.xml" />
</fileset>
</copy>
<copy todir="${WebAppRoot}/WEB-INF" overwrite="true">
<fileset dir="build">
<include name="classes/**/*" />
</fileset>
</copy>
<copy todir="${WebAppRoot}" overwrite="true" includeemptydirs="false">
<fileset dir="WebContent">
<exclude name="WEB-INF/**/*" />
<exclude name="META-INF/**/*" />
</fileset>
</copy>
</target>
<target name="root" depends="Copy">
</target>
</project>
对比Struts2应用与普通的Web应用可以发现只是在lib目录中多了几个jar文件以及在classes目录中多了一个struts.xml。而观察上面的发布脚本,该脚本在发布时已经包含了这些文件,所以发布Struts2应用时并不需要添加额外的脚本,也不需要修改脚本。
但是,有一种情况需要注意,由于Struts2应用在Tomcat中运行时,必须保证Struts2的库文件存在于应用的类路径中。前面介绍了两种在Eclipse的工程中添加Struts2库的方法,如果读者使用的是将Struts2库复制到工程lib目录下的方式,那么发布脚本就会自动将库文件发布到Tomcat的Web应用中;如果读者使用的是添加用户库的方式,那么建议读者最好直接将Struts2的库文件复制到Tomcat的lib目录中,以便于所有Struts2应用在运行时能够发现这些库文件。
Struts2是当前最流行的一种基于MVC模式的Web开发框架,也是Java Web开发最流行的技术之一。Struts2框架使用FilterDispatcher作为默认过滤器,FilterDispatcher根据struts.xml配置文件中的配置调用适当的Action,并根据Action的执行结果决定响应的方式和内容。Struts2框架还运行在执行Action之前调用拦截器对请求进行处理,甚至阻止请求的传递。
Struts2中的Action是一个普通的Java对象,它只需要实现execute()方法,并为每一个域变量定义相应的setter和getter方法。Action在被调用时其参数通过setter方法被设置到对象中,然后执行execute()方法,执行结束后返回一个字符串。
Struts2应用本质上也只是一个普通的Web应用,只是Struts2应用需要添加Struts2的支持库和配置文件,在将Struts2应用发布到Tomcat中时,Tomcat并不会对Struts2应用提供任何额外的支持。
基于本书介绍的工具和技术,本章将介绍简单论坛系统的开发。该系统实现了论坛系统的基本功能,包括用户注册、用户登录、浏览文章、发表文章。
本章将从分析系统需求开始,分别介绍界面设计、系统开发。在系统开发中介绍了系统每个模块及页面的代码和功能。最后对开发的系统进行简单的测试。
简单论坛系统,或称其为SimpleForum系统,是一个简单的论坛系统。为了让读者只关注Web开发部分,本系统在其他方面做了尽可能多的简化:不考虑多余的界面美工,使用最原始的表格和form展示页面内容;不使用任何数据库系统,只将论坛数据保存在内存的一个对象中;只完成了基本的用户注册、用户登录、浏览文章和发表文章的工作。
系统的详细需求如下:
1.系统主页为用户登录界面,提供给用户输入用户名和密码进行登录;如果用户输入的用户名在系统中不存在或用户名和密码不匹配则在页面中提示输入的用户名或密码错误;如果用户输入的用户名和密码正确,则进入文章列表页;登录界面上还提供给用户到达用户注册界面的链接;
2.用户注册界面提供给用户输入个人数据,包括用户名和密码,点击“注册”按钮完成注册;注册完成后弹出页面提示用户注册成功,并且提供链接返回登录界面;如果用户提供的用户名在系统中已存在,则返回到注册页面并提示给定的用户名已存在;
3.文章列表页上以表格的形式显示了系统中当前所有用户发表的所有文章的列表,表格的每一行显示一个文章记录,每个记录显示文章的序号、标题、作者和发表时间;点击文章标题的链接后,打开新的文章浏览窗口;
4.在文章浏览窗口中显示文章的所有信息,包括文章的内容;
5.在文章列表页的底部提供一个链接用于发表文章,点击该链接进入发表文章页面;
6.发表文章页中提供一个单行文本框、一个多行文本框和一个按钮,单行文本框用于输入文章标题、多行文本框用于输入文章内容、按钮用于发表文章;分别填写好文章的标题、内容后,点击“发表”按钮返回到文章列表页,其中可以看到发表的文章;
7.系统支持多人同时登录并且进行各种操作。
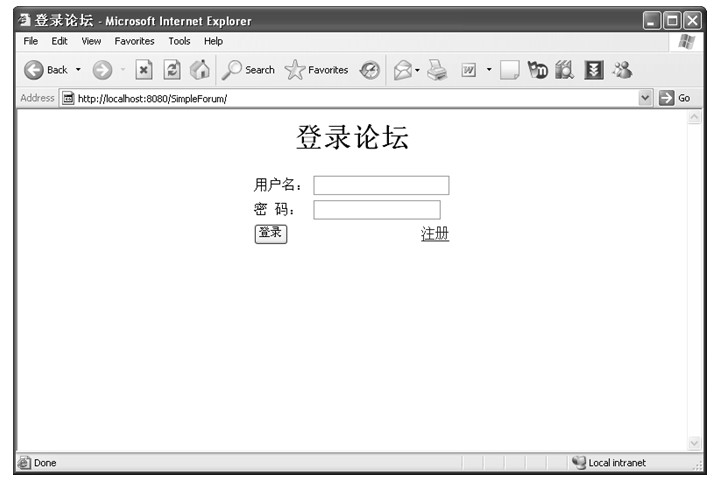
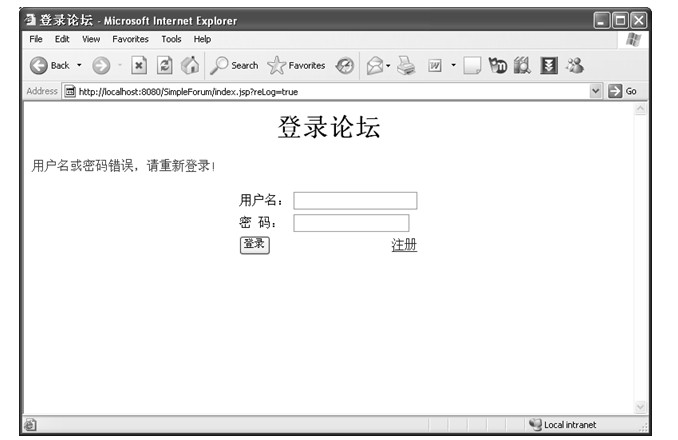
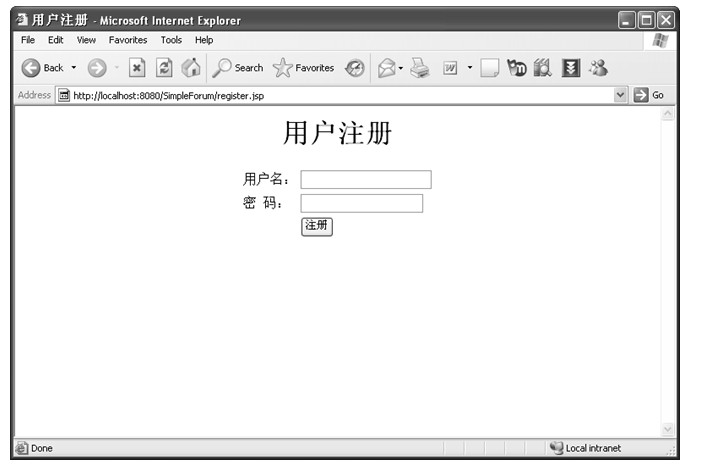
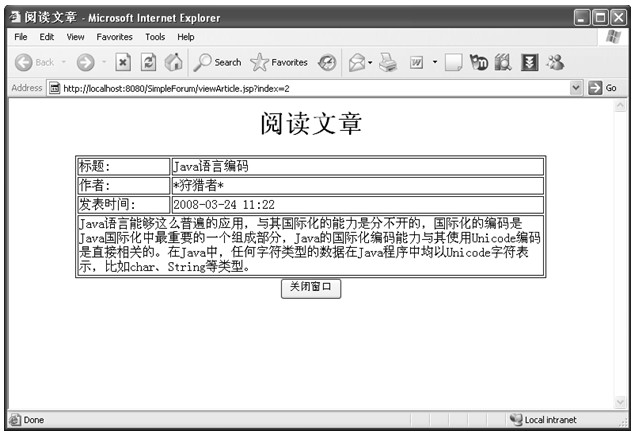
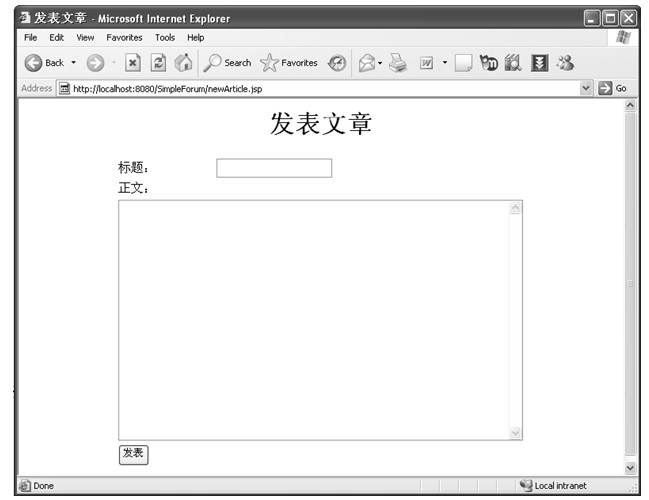
该系统是典型的动态Web应用系统,所以首先需要在Eclipse中新建动态Web系统,命名为SimpleForum。新建向导中的设置都使用默认设置,建成后在Eclipse中获得一个空的Web工程,如图18.10所示。
图18.10 在Eclipse中新建SimpleForum工程
在进行系统开发之前,可以先在工程根目录中新建build.xml文件,作为工程的发布脚本,内容参照16章中介绍的Web应用发布脚本,如下:
<project name="DemoProject" basedir="." default="root">
<property environment="env" />
<property name="WebAppRoot" value="${env.TOMCAT_HOME}/webapps/SimpleForum" />
<target name="Init">
<mkdir dir="${WebAppRoot}" />
</target>
<target name="Copy" depends="Init">
<copy flatten="false" todir="${WebAppRoot}" overwrite="true">
<fileset dir="WebContent">
<include name="WEB-INF/lib/*" />
<include name="WEB-INF/web.xml" />
</fileset>
</copy>
<copy todir="${WebAppRoot}/WEB-INF" overwrite="true">
<fileset dir="build">
<include name="classes/**/*" />
</fileset>
</copy>
<copy todir="${WebAppRoot}" overwrite="true" includeemptydirs="false">
<fileset dir="WebContent">
<exclude name="WEB-INF/**/*" />
<exclude name="META-INF/**/*" />
</fileset>
</copy>
</target>
<target name="root" depends="Copy">
</target>
</project>
将发布Web应用的脚本添加到工程中后,就可以随时将Web工程当前的内容发布到Tomcat中,随时测试已实现的功能。
MVC(模型 - 视图 - 控制器)模型是在Web开发中使用非常多的设计模式,使用该模式开发Web系统可以使系统各个层面的实现相互独立、易于实现和维护。使用MVC模型开发Web系统前首先应该分析出在系统中模型有什么、视图有什么、控制器有什么以及这些之间的关系。
根据前面对SimpleForum系统界面的设计和对系统功能的描述,按照MVC模型,可以分析出SimpleForum系统的MVC交互如图18.11所示:
如图18.11所示,模型由Java对象实现,它是对系统的建模,主要用于存取系统中的持久化数据;视图由JSP页面实现,用于接收用户的交互输入以及对系统数据进行展现;控制器由Servlet实现,主要用于控制在特定情况下调用适当的视图来显示数据。其中,模型和控制器属于Java对象,实现时代码放在SimpleForum工程的src中;视图是JSP页面,实现时JSP文件放在SimpleForum工程的WebContent目录中。
图18.11中的箭头描述了程序的逻辑流程或数据流向,箭头上的文字描述了执行该流程的条件或数据的内容。以用户注册为例,在登录页面中用户点击“注册”链接跳转到注册页面;在注册页面中,用户点击“注册”按钮将注册的信息提交到注册Servlet;注册Servlet从模型中查找注册的用户名是否存在,如果指定的用户名已存在则跳转回注册页面,如果不存在则向模型中添加该用户信息,并且跳转到注册成功页面;用户点击注册成功页面中的“返回登录页面”链接返回到登录页面。
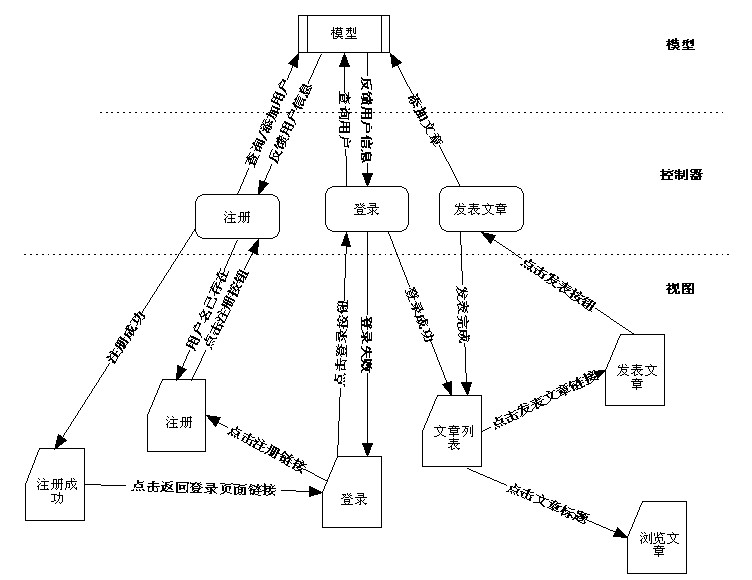
图18.11 SimpleForum系统MVC交互图
下面几节将分别针对模型、视图和控制器的开发进行详细介绍。
模型主要负责对系统数据进行建模、存储和读取,通常大部分系统中先对数据进行建模,将系统中需要使用的数据用对象表示,然后将对象映射为关系型数据库中的记录,将数据存储在关系型数据库中。本章为了简化系统,省略数据库的实现,将数据直接存储在内存对象中;虽然这种数据对象不能将数据持久化,但该对象也在很大程度上反映了数据存取对象的框架和作用。
本系统涉及两种数据:用户数据和文章数据。用户注册和登录涉及对用户数据的添加和访问;用户发表文章、查看文章列表和浏览文章内容涉及对文章数据的添加和访问。这两种数据可以很直观地用两种对象表示:用户对象和文章对象。用户对象只需要两个属性:用户名和密码。文章对象需要定义四个属性:文章标题、文章内容、作者和发表时间。
首先,在SimpleForum工程中新建用户对象和文章对象,命名为User和Article。在SimpleForum工程的src中首先新建一个包cn.csai.simple_forum.model,在该包中分别新建User类和Article类,类的内容如下:
package cn.csai.simple_forum.model;
public class User {
private String name;
private String password;
public User(String name, String password) {
this.name = name;
this.password = password;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}
package cn.csai.simple_forum.model;
import java.text.SimpleDateFormat;
import java.util.Date;
public class Article {
private String title;
private String auther;
private String content;
private Date submitTime;
public Article(String title, String auther, String content, Date submitTime)
{
this.title = title;
this.auther = auther;
this.content = content;
this.submitTime = submitTime;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getAuther() {
return auther;
}
public void setAuther(String auther) {
this.auther = auther;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getSubmitTime() {
return new SimpleDateFormat("yyyy-MM-dd hh:mm").format(submitTime);
}
public void setSubmitTime(Date submitTime) {
this.submitTime = submitTime;
}
}
这两个对象都只是简单地用于保存数据,只是定义了每个属性,以及对每个属性的set方法和get方法。
在将数据对象化后,需要再添加一个类用于对对象进行存储和获取,为了简化实现,我们将对象放在一个内存对象中,用静态对象的形式保存。如下是实现的ForumDataPool:
package cn.csai.simple_forum.model;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class ForumDataPool {
private static Map<String, User> userMap = new HashMap<String, User>();
private static List<Article> articles = new ArrayList<Article>();
public static int getUserNum() {
return userMap.size();
}
public static int getArticleNum() {
return articles.size();
}
public static boolean userExists(User u) {
if(null != userMap.get(u.getName()))
return true;
else
return false;
}
public static boolean infoExists(User u) {
User user = userMap.get(u.getName());
if (null == user)
return false;
if (user.getPassword().equals(u.getPassword()))
return true;
else
return false;
}
public static void addUser(User u) {
userMap.put(u.getName(), u);
}
public static void addArticle(Article a) {
articles.add(a);
}
public static List<Article> getArticles() {
return articles;
}
}
该类将所有成员都定义为静态成员,使用两个静态的集合成员来存储所有的User对象和Article对象。userMap是一个HashMap,键是用户名,值是一个User对象,它可能通过用户名查找用户对象。articles是一个ArrayList,每个成员是一个Article对象。该类定义的所有方法也是静态方法,分别定义了获取两种集合对象信息和向两种集合对象添加成员的方法,其中:
getUserNum()返回当前注册的用户数量;
getArticleNum()返回当前论坛中的文章数量;
userExist()判断指定的用户是否存在;
addUser()注册新的用户,向当前用户列表中添加一个新用户;
addArticle()发表新文章,向当前文章列表中添加一篇新文章;
getArticles()返回当前系统中拥有的所有文章的列表。
通过该类中的方法,程序员可以在工程的其他代码中直接存储和获取对象。模型只提供对数据对象的操作,并不关心数据对象如何被使用和如何被展现。
视图是系统中直接与用户交互的部分,通常由JSP页面负责。视图只关心如何展示获得的数据,而并不关心数据是从哪来的。视图的设计是与界面的设计紧密联系的,可以说视图就是界面。所以说,有多少界面一般就需要设计多少视图。
视图通常是JSP页面,在Eclipse的Web工程中,所有的JSP页面都放在工程的WebContent目录下(可以组织适当的子目录结构),根据前面对界面的描述,可以得到如下的JSP实现。
1.用户登录页面(系统主页面)
该页面的代码如下:
index.jsp
<%@ page language="java" contentType="text/html; charset=GBK" pageEncoding="GBK"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=GBK">
<title>登录论坛</title>
</head>
<body>
<%
String reLog = request.getParameter("reLog");
%>
<h1 align="center">登录论坛</h1>
<%
if(reLog != null) {
%>
<font color="red"> 用户名或密码错误,请重新登录!</font>
<%
}
%>
<form action="login">
<table align="center" border="0">
<tr>
<td>用户名:</td>
<td><input type="text" name="name"></td>
</tr>
<tr>
<td>密 码:</td>
<td><input type="password" name="pswd"></td>
</tr>
<tr>
<td><input type="submit" value="登录"></td>
<td align="right"><a href="register.jsp">注册</a></td>
</tr>
</table>
</form>
</body>
</html>
其中,核心的就是一个form,form中用table进行布局,包含了用户名输入框、密码输入框和“登录”按钮以及注册链接,“登录”按钮会将form的数据提交到URL login。
除此之外,由于当用户登录失败后需要在页面中显示登录失败的提示,所以还需要使用一个标志区别这种情况。在form前包含了一些JSP代码,这些代码试图从request中获得reLog的值,如果reLog的值不为空则在页面中添加<font color="red"> 用户名或密码错误,请重新登录!</font>以提示用户。所以,假如用户直接打开登录页面时链接中不定义reLog参数,提示信息就不会被显示;如果用户由于登录失败重新返回到该页面,可以将链接地址中加上reLog参数,提示信息就会被显示。
2.用户注册页面
该页面的代码如下:
register.jsp
<%@ page language="java" contentType="text/html; charset=GBK" pageEncoding="GBK"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=GBK">
<title>用户注册</title>
</head>
<body>
<%
String userExist = request.getParameter("userExist");
%>
<h1 align="center">用户注册</h1>
<%
if(userExist != null) {
%>
<font color="red"> 用户名已存在,请重新选择用户名!</font>
<%
}
%>
<form action="register">
<table align="center" border="0">
<tr>
<td>用户名:</td>
<td><input type="text" name="name"></td>
</tr>
<tr>
<td>密 码:</td>
<td><input type="password" name="pswd"></td>
</tr>
<tr>
<td> </td>
<td><input type="submit" value="注册"></td>
</tr>
</table>
</form>
</body>
</html>
该页面的内容与登录页面的内容极其相似,只是点击“注册”时将内容提交到URL register。与登录页面一样,注册页面也需要向用户提示用户名已存在的信息,这里使用了相同的机制。
3.注册成功页面
该页面的代码如下:
registerSuccessful.jsp
<%@ page language="java" contentType="text/html; charset=GBK" pageEncoding="GBK"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=GBK">
<title>注册成功</title>
</head>
<body>
<h1 align="center">注册成功!</h1>
<div align="right">
<a href="index.jsp">返回登录页面</a>
</div>
</body>
</html>
注册成功页面的内容非常简单,只是提示注册成功并提供一个链接到登录页面。
4.文章列表页面
该页面的代码如下:
mainPage.jsp
<%@ page language="java" contentType="text/html; charset=GBK" pageEncoding="GBK"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<%@page import="cn.csai.simple_forum.model.*;"%>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=GBK">
<title>文章列表</title>
</head>
<body>
<h1 align="center">文章列表</h1>
<table align="center" width="80%" border="1">
<tr>
<th>编号</th><th>标题</th><th>作者</th><th>发表日期</th>
</tr>
<%
for(int i=0; i<ForumDataPool.getArticleNum(); i++) {
Article a = ForumDataPool.getArticles().get(i);
%>
<tr>
<td align="center"><%= i+1 %></td>
<td align="center"><a href="viewArticle.jsp?index=<%= i %>" target="blank"><%= a.getTitle() %></a></td>
<td align="center"><%= a.getAuther() %></td>
<td align="center"><%= a.getSubmitTime() %></td>
</tr>
<%
}
%>
<tr> <td colspan="4"> </td></tr>
<tr> <td colspan="4"><a href="newArticle.jsp">发表文章</a></td></tr>
</table>
</body>
</html>
该页面需要读取模型中的所有文章对象,并将其逐个显示在表格中。由于该页面需要引用ForumDataPool对象和Article对象,所以必须在页面的page属性中输入(import)这两个类或者这两个类所在的包。在页面正文中就是一个显示文章列表的表格,表格的行数根据文章的总个数来确定,循环获取每一个文章,每获取一个文章就在表格中添加一行,并添加对应文章的信息。每行的标题列提供一个到查看文章页面的链接,链接中包含了文章的编号。表格的末尾提供到发表文章页面的链接。
5.浏览文章页面
该页面的代码如下:
viewArticle.jsp
<%@ page language="java" contentType="text/html; charset=GBK" pageEncoding="GBK" import="cn.csai. simple_forum.model.*"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=GBK">
<title>阅读文章</title>
</head>
<body>
<h1 align="center">阅读文章</h1>
<%
String index = request.getParameter("index");
Article a = ForumDataPool.getArticles().get(Integer.parseInt(index));
%>
<table align="center" border="1" width="80%" bordercolor="blue">
<tr>
<td width="20%">标题:</td>
<td><%= a.getTitle() %></td>
</tr>
<tr>
<td width="20%">作者:</td>
<td><%= a.getAuther() %></td>
</tr>
<tr>
<td width="20%">发表时间:</td>
<td><%= a.getSubmitTime() %></td>
</tr>
<tr>
<td colspan="2"><%= a.getContent() %></td>
</tr>
</table>
<div align="center">
<a onclick="JavaScrip:window.close()">
<input type="button" value="关闭窗口">
</a>
</div>
</body>
</html>
该页面从请求中获得待查看的文章的编号,然后从ForumDataPool中获得指定的文章并在表格中分别显示文章的各项。
6.发表文章页面
该页面的代码如下:
newArticle.jsp
<%@ page language="java" contentType="text/html; charset=GBK" pageEncoding="GBK"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=GBK">
<title>发表文章</title>
</head>
<body>
<h1 align="center">发表文章</h1>
<form action="newArticle">
<table align="center" border="0">
<tr>
<td>标题:</td>
<td><input type="text" name="title"></td>
</tr>
<tr>
<td colspan="2">正文:</td>
</tr>
<tr>
<td colspan="2">
<textarea name="article" rows="20" cols="70"></textarea>
</td>
</tr>
<tr>
<td><input type="submit" value="发表"></td>
<td> </td>
</tr>
</table>
</form>
</body>
</html>
该页面提供一个发表文章的界面,用户可以在这里输入待发表文章的标题和内容,然后发表。发表后将文章内容提交到URL newArticle。
根据MVC交互图,本系统需要三个Servlet,分别完成注册、登录和发表文章。
1.注册
注册Servlet负责接收注册请求,根据请求中携带的用户名和密码参数进行注册操作。如果指定的用户名已存在则将用户响应重定向到register.jsp页面并且指定userExist参数以告知该页面提示用户指定的用户名已存在;如果指定的用户名不存在则将用户名和密码添加到模型中,并且将用户响应重定向到registerSuccessful.jsp。
在SimpleForum工程的src中新建一个专门放置Servlet的包:cn.csai.simple_forum.servlet,在该包中通过向导新建RegisterServlet。编辑代码内容如下:
package cn.csai.simple_forum.servlet;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import cn.csai.simple_forum.model.ForumDataPool;
import cn.csai.simple_forum.model.User;
public class RegisterServlet extends javax.servlet.http.HttpServlet implements javax.servlet.Servlet {
static final long serialVersionUID = 1L;
public RegisterServlet() {
super();
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String name = request.getParameter("name");
String password = request.getParameter("pswd");
User user = new User(name, password);
if(ForumDataPool.infoExists(user)) {
response.sendRedirect("register.jsp?userExist=true");
} else {
ForumDataPool.addUser(user);
response.sendRedirect("registerSuccessful.jsp");
}
}
}
2.登录
登录Servlet负责接收登录请求,根据登录请求中携带的用户名和密码信息进行操作。如果用户登录的用户名在模型中不存在或指定的用户名和密码不匹配,则将用户响应重定向到登录页面,并且指定reLog参数以告知用户提供的用户名或密码有误;如果登录的用户名和密码正确则将当前用户名保存在当前Session中,并且将用户响应重定向到文章列表页面以表示登录成功。
在cn.csai.simple_forum.servlet包中新建LoginServlet。编辑代码内容如下:
package cn.csai.simple_forum.servlet;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import cn.csai.simple_forum.model.ForumDataPool;
import cn.csai.simple_forum.model.User;
public class LoginServlet extends javax.servlet.http.HttpServlet implements javax.servlet.Servlet {
static final long serialVersionUID = 1L;
public LoginServlet() {
super();
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String name = request.getParameter("name");
String password = request.getParameter("pswd");
if(ForumDataPool.userExists(new User(name, password))){
request.getSession().setAttribute("name", name);
response.sendRedirect("mainPage.jsp");
}
else {
response.sendRedirect("index.jsp?reLog=true");
}
}
}
3.发表文章
发表文章Servlet用于接收发表文章的请求,请求中携带待发表文章的文章标题和内容。该Servlet从请求中获取标题和内容,从当前Session中获得用户名信息,获取当前的系统时间作为文章发表的时间。然后利用这些信息新建一个Article对象并将其添加到模型中。
在cn.csai.simple_forum.servlet包中新建NewArticleServlet。编辑代码内容如下:
package cn.csai.simple_forum.servlet;
import java.awt.event.FocusAdapter;
import java.io.IOException;
import java.util.Date;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import cn.csai.simple_forum.model.Article;
import cn.csai.simple_forum.model.ForumDataPool;
public class NewArticleServlet extends javax.servlet.http.HttpServlet implements javax.servlet.Servlet {
static final long serialVersionUID = 1L;
public NewArticleServlet() {
super();
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String title = request.getParameter("title");
String article = request.getParameter("article");
ForumDataPool.addArticle(new Article(title, (String)request.getSession().getAttribute("name"), article, new Date()));
response.sendRedirect("mainPage.jsp");
}
}
在编写完以上所有代码后,运行工程根目录中的build.xml脚本将工程发布到Tomcat中,启动Tomcat就可以对该Web应用进行简单测试。由于系统采用的内存对象存储数据,所以在Tomcat刚启动时,系统中没有任何用户也没有任何文章。
打开浏览器键入:http://localhost:8080/SimpleForum进入系统主页,随便输入一个用户名和密码,检查是否会提示错误信息。例如输入如图18.12所示信息:
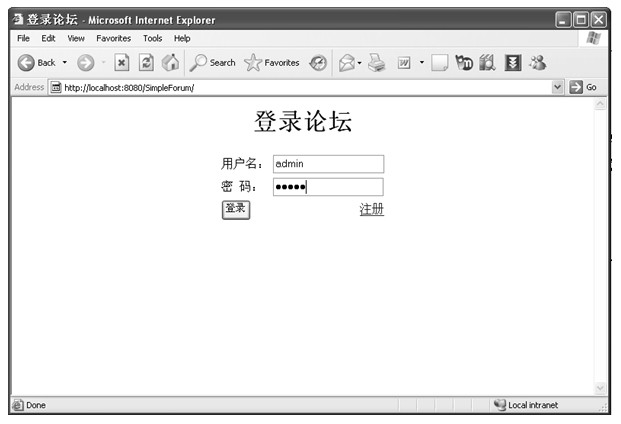
图18.12 登录系统
点击登录,发现系统界面如图18.13所示:
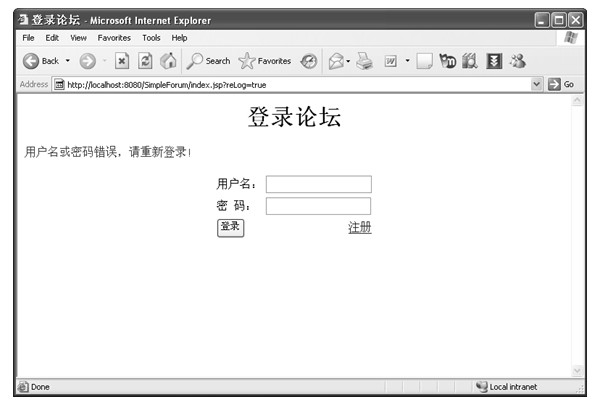
图18.13 登录失败提示
点击注册,进入注册页面,输入一个用户名和密码,如图18.14所示。
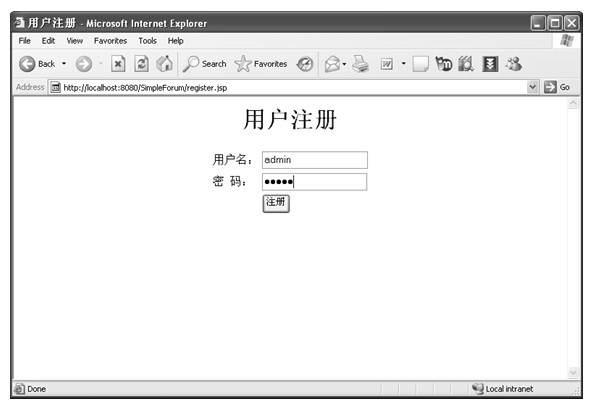
图18.14 新用户注册
然后点击“注册”按钮,进行注册,出现如图18.15所示页面:
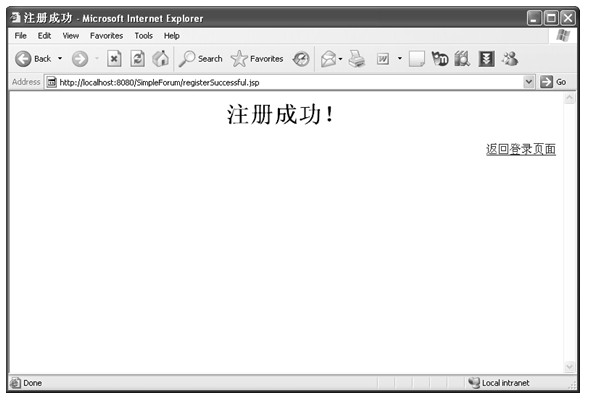
图18.15 新用户注册成功
点击“返回登录页面”链接跳转到登录页面,再进入注册页面,注册相同的用户名,出现如图18.16所示页面。
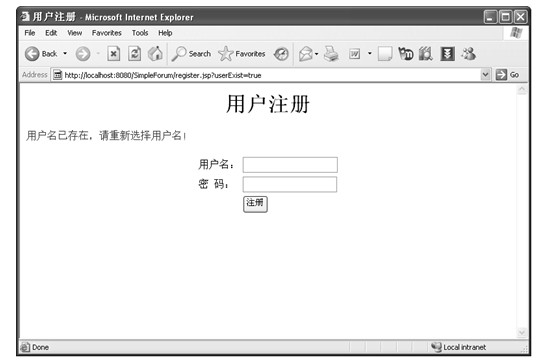
图18.16 新用户注册失败
返回到登录页面,输入注册的用户名和密码,进入到如图18.17所示文章列表页面:
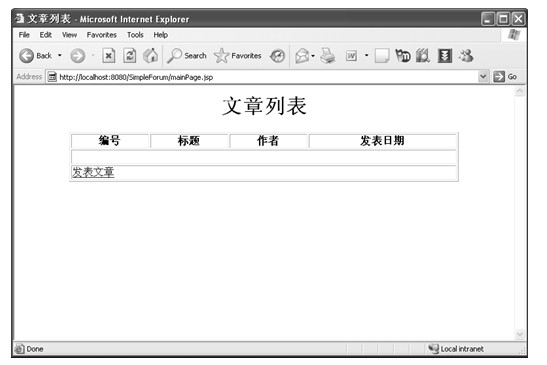
图18.17 空白文件列表
点击“发表文章”链接,进入发表文章页面,在其中随意填写一些内容,如图18.18所示。
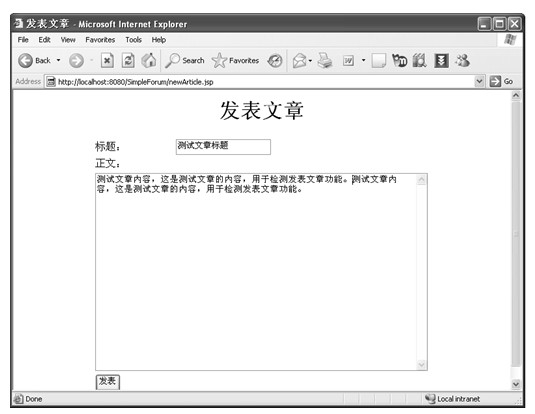
图18.18 发表文章
然后点击“发表”按钮,进入如图18.19所示文章列表页面:
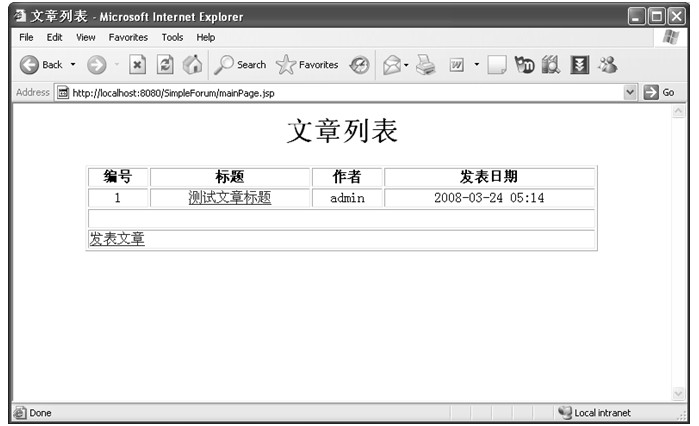
图18.19 在文章列表中显示新发表的文章
这时,文章列表中已包含刚刚发表的文章,包括作者和发表的日期。点击文章的标题,在新窗口中打开阅读文章页面,如图18.20所示。
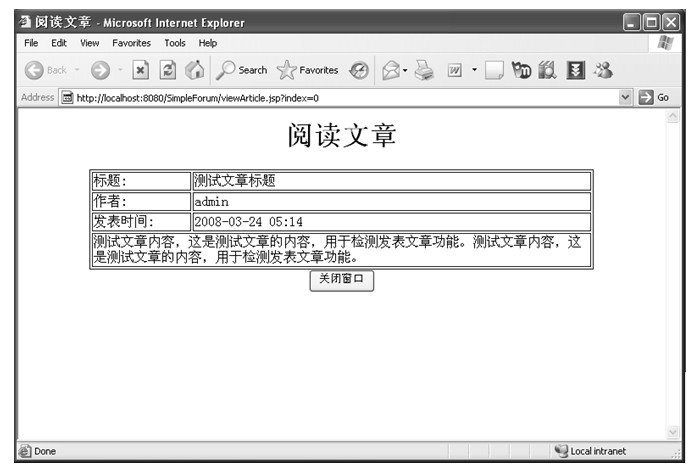
图18.20 阅读文章
点击“关闭窗口”按钮关闭阅读文章页面。
第18章介绍了简单论坛系统的开发,其方法是使用JSP和Servlet技术根据MVC模式的思想进行开发。Struts2是一种成熟而且有效的MVC架构,使用Struts2开发基于MVC的应用可以不用关注MVC的实现方式,而只关注业务逻辑。本章将介绍如果使用Struts2开发简单论坛系统。
本章将要开发的简单论坛系统的功能与第18章的完全相同,所以本章将不再对系统需求和界面设计进行重复说明。
Struts2框架已经搭建了一个灵活的MVC框架,所以在设计基于Struts2框架的Web系统时不需要考虑如何实现MVC,而是需要了解Struts2框架的工作方式,并且按照Struts2框架的要求将业务逻辑添加到框架的适当位置。但是,这并不表示使用Struts2框架就可以完全不用理解MVC模式,因为理解MVC模式的工作原理并且有效地将MVC模式与Struts2架构结合特别有助于理解Struts2的工作方式和充分的发挥Struts2框架的灵活性。本章将以MVC模式基本原理为背景结合Struts2框架的工作方式,介绍如何对待开发系统进行设计。
第18章介绍了简单论坛系统的开发,其方法是使用JSP和Servlet技术根据MVC模式的思想进行开发。Struts2是一种成熟而且有效的MVC架构,使用Struts2开发基于MVC的应用可以不用关注MVC的实现方式,而只关注业务逻辑。本章将介绍如果使用Struts2开发简单论坛系统。
本章将要开发的简单论坛系统的功能与第18章的完全相同,所以本章将不再对系统需求和界面设计进行重复说明。
Struts2框架已经搭建了一个灵活的MVC框架,所以在设计基于Struts2框架的Web系统时不需要考虑如何实现MVC,而是需要了解Struts2框架的工作方式,并且按照Struts2框架的要求将业务逻辑添加到框架的适当位置。但是,这并不表示使用Struts2框架就可以完全不用理解MVC模式,因为理解MVC模式的工作原理并且有效地将MVC模式与Struts2架构结合特别有助于理解Struts2的工作方式和充分的发挥Struts2框架的灵活性。本章将以MVC模式基本原理为背景结合Struts2框架的工作方式,介绍如何对待开发系统进行设计。
Struts2框架是基于MVC模式的,但是Struts2框架最主要的改进和实现是控制器部分,视图和模型完全可以沿用第18章介绍的内容,只需要做少许改动。控制器部分的改动将会很大,在第18章中介绍的系统的控制器由Servlet实现,本章由于有了Struts2框架,则控制器部分只需要适当的设计Action。
由于系统展现给用户的界面不需要做任何改变,所以视图大体上是不需要做任何变化的,视图还是6个页面:用户登录、用户注册、注册成功、文章列表、文章浏览和发表文章。模型的实现独立于控制器,所以模型不需要做任何改变。唯一变化比较大的还是控制器的实现,从18章对系统的分析中可以发现,客户端对系统的请求总共有三种情况:注册、登录、发表文章。可以用三个Action实现这三种情况。
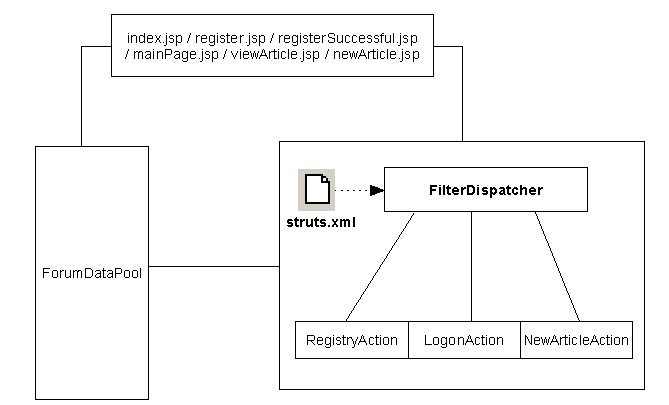
图19.1 基于Struts2框架的系统架构
图19.1是系统的架构图,数据还是存放在内存对象ForumDataPool中,视图需要操作时向控制器提交请求,FilterDispatcher拦截请求并根据所请求的Action的名称,将参数传递给Action并且调用对应Action的execute()方法,然后根据返回结果决定返回哪一个视图作为响应。
根据19.1.1节对框架的设计,本系统包含3个Action:
1.RegistryAction:该Action对用户进行注册。该Action需要获得待注册的用户名和密码;注册过程就是首先从模型中查找用户名是否存在,如果存在则警告用户名已存在,如果不存在则将用户名和密码新建一个用户添加到模型中。所以,执行结束有两种结果,用户名已存在则返回userExist,将视图返回到register.jsp并且提醒用户名已存在;执行成功则返回success,返回视图registerSuccessful.jsp。
2.LogonAction:该Action处理用户登录。该Action需要获得登录使用的用户名和密码;登录过程就是首先从模型中查找指定的用户名和密码是否存在于模型中,如果用户名和密码存在并且匹配则允许用户登录,否则返回登录页面并且提示用户名或密码错误。所以,执行结束有两种结果,用户名和密码匹配则返回success,返回视图mainPage.jsp;用户名和密码不匹配则返回error,将视图返回到index.jsp并且提醒用户名或密码不正确。
3.NewArticleAction:该Action处理用户发表文章。该Action需要获得用户发表文章的标题、内容以及发表文章用户的用户名;发表过程就是将待发表文章的标题、内容和作者构建一个文章对象并将其添加到模型中。所以,执行结束只有一种结果,返回视图mainPage.jsp。
根据以上分析,可以画出如图19.2所示的Action控制转发图:
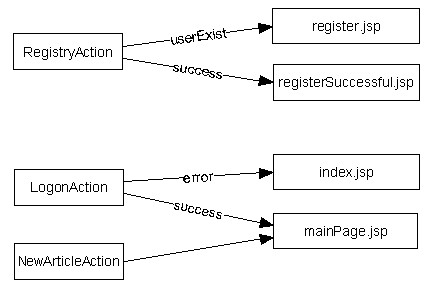
图19.2 Action控制转发图
图19.2中标出了每个Action与相关视图之间的关系,以及转发条件。
另外,除了Action的类名外,还需要为Action设置链接名,这将会出现在访问Action的URL链接中以及配置文件中。为了便于记忆,将类名的Action后缀去掉,并且首字母小写,生成的字符串作为Action的名称,即:registry、logon和newArticle。
搭建Struts2应用有两种方式,一种是新建一个动态Web工程并且在其中添加Struts2的支持库和配置文件,一种是将Struts2发布中的struts2-blank-2.0.11.1.war解包然后在其基础上开发。为了让读者能够清晰的认识Struts2应用的框架,本节采用第一种方式从新建的工程开始搭建Struts2应用。
第一步,在Eclipse中新建一个动态Web工程,命名为SimpleForum2。这一步与前面介绍的新建普通的Web工程一样,没有特殊的地方。
第二步,将Struts2的5个核心库文件(commons-logging-1.0.4.jar、freemarker-2.3.8.jar、ognl-2.6.11.jar、struts2-core-2.0.11.1.jar和xwork-2.0.4.jar)复制到工程目录下WebContent/WEB-INF/lib目录中,并且从工程属性中设置工程的Java Build Path,将这5个库文件添加到工程的构建路径中。
第三步,修改工程的web.xml文件,将其内容修改为:
<?xml version="1.0" encoding="UTF-8"?>
<web-app id="WebApp_ID" version="2.4" xmlns="http://java.sun.com/xml/ns/j2ee" xmlns:xsi="http://www. w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/j2ee http://java.sun.com /xml/ns/j2ee/web-app_2_4.xsd">
<display-name>SimpleForum2</display-name>
<welcome-file-list>
<welcome-file>index.html</welcome-file>
<welcome-file>index.htm</welcome-file>
<welcome-file>index.jsp</welcome-file>
<welcome-file>default.html</welcome-file>
<welcome-file>default.htm</welcome-file>
<welcome-file>default.jsp</welcome-file>
</welcome-file-list>
<filter>
<filter-name>struts</filter-name>
<filter-class>org.apache.struts2.dispatcher.FilterDispatcher</filter-class>
</filter>
<filter-mapping>
<filter-name>struts</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
</web-app>
第四步,在工程的src目录中新建包cn.csai.simple_forum2和配置文件struts.xml。为struts.xml中添加初始的内容,如下:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE struts PUBLIC
"-//Apache Software Foundation//DTD Struts Configuration 2.0//EN"
"http://struts.apache.org/dtds/struts-2.0.dtd">
<struts>
<include file="struts-default.xml"></include>
<package name="cn.csai.simple_forum2" namespace="" extends="struts-default">
</package>
</struts>
第五步,为了在开发过程中可以方便地将工程内容发布到Tomcat中进行调试,在工程根目录中新建build.xml文件,添加内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project name="DemoProject" basedir="." default="root">
<property environment="env" />
<property name="WebAppRoot" value="${env.TOMCAT_HOME}/webapps/SimpleForum2" />
<target name="Init">
<mkdir dir="${WebAppRoot}" />
</target>
<target name="Copy" depends="Init">
<copy flatten="false" todir="${WebAppRoot}" overwrite="true">
<fileset dir="WebContent">
<include name="WEB-INF/lib/*" />
<include name="WEB-INF/web.xml" />
</fileset>
</copy>
<copy todir="${WebAppRoot}/WEB-INF" overwrite="true">
<fileset dir="build">
<include name="classes/**/*" />
</fileset>
</copy>
<copy todir="${WebAppRoot}" overwrite="true" includeemptydirs="false">
<fileset dir="WebContent">
<exclude name="WEB-INF/**/*" />
<exclude name="META-INF/**/*" />
</fileset>
</copy>
</target>
<target name="root" depends="Copy">
</target>
</project>
通过这几步就已经基本完成了一个Struts2应用的基本框架,下面再根据设计添加具体的内容。
虽然使用了Struts2框架,但是由于模型是相对独立的部分,在从传统的JSP+Servlet移至到Struts2框架上时基本不需要对模型做任何改动。所以这部分只需要沿用第18章中编写的模型即可。
在cn.csai.simple_forum2中新建一个子包model,将第18章开发的User、Article和ForumDataPool直接添加到model包中。注意修改各个类中关于包的声明,确保新的类不存在编译错误,将包声明从package cn.csai.simple_forum.model;改为package cn.csai.simple_forum2.model;。
由于系统界面不需要变动,所以视图基本上不会有太大的改变,只需要将以前访问Servlet的链接修改成访问对应Action的链接。
1.用户登录页面(系统主页面)
该页面中将访问login Servlet的链接替换为访问logon Action;另外,由于Struts2直接根据request携带的参数名将参数值传递给Action,所以向Action提交的链接中携带的参数的参数名必须与相应的Action类中的setter方法相对应。例如,该页面中有访问logon.action的链接,并且各个输入框中输入的内容将通过链接参数的形式传递到Struts2框架并且通过LogonAction的setter方法设置到LogonAction中,例如密码输入框的name是pswd,那么LogonAction中必须提供setPswd()方法以便于Struts2可以设置密码到LogonAction中。所以,在开发Struts2的视图时,视图中的参数名应该写的尽量规范和完整并且与Action中的setter方法保持一致:
index.jsp
<%@ page language="java" contentType="text/html; charset=GBK" pageEncoding="GBK"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=GBK">
<title>登录论坛</title>
</head>
<body>
<%
String reLog = request.getParameter("reLog");
%>
<h1 align="center">登录论坛</h1>
<%
if(reLog != null) {
%>
<font color="red"> 用户名或密码错误,请重新登录!</font>
<%
}
%>
<form action="logon.action">
<table align="center" border="0">
<tr>
<td>用户名:</td>
<td><input type="text" name="userName"></td>
</tr>
<tr>
<td>密 码:</td>
<td><input type="password" name=" password "></td>
</tr>
<tr>
<td><input type="submit" value="登录"></td>
<td align="right"><a href="register.jsp">注册</a></td>
</tr>
</table>
</form>
</body>
</html>
2.用户注册页面
将该页面中访问register Servlet的链接替换为访问registry Action;同样,将名称写得尽量规范:
register.jsp
<%@ page language="java" contentType="text/html; charset=GBK" pageEncoding="GBK"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=GBK">
<title>用户注册</title>
</head>
<body>
<%
String userExist = request.getParameter("userExist");
%>
<h1 align="center">用户注册</h1>
<%
if(userExist != null) {
%>
<font color="red"> 用户名已存在,请重新选择用户名!</font>
<%
}
%>
<form action="registry.action">
<table align="center" border="0">
<tr>
<td>用户名:</td>
<td><input type="text" name="userName"></td>
</tr>
<tr>
<td>密 码:</td>
<td><input type="password" name="password"></td>
</tr>
<tr>
<td> </td>
<td><input type="submit" value="注册"></td>
</tr>
</table>
</form>
</body>
</html>
3.注册成功页面
由于该页面中没有任何访问控制器的链接,所以该页面内容不变。
4.文章列表页面
由于该页面中没有任何访问控制器的链接,所以该页面内容不变,只需注意页面中对模型对象引用时的包路径需修改正确。
5.浏览文章页面
由于该页面中没有任何访问控制器的链接,所以该页面内容不变,只需注意页面中对模型对象引用时的包路径需修改正确。
6.发表文章页面
将该页面中访问newArticle Servlet的链接替换为访问newArticle Action;同样,将名称写得尽量规范:
newArticle.jsp
<%@ page language="java" contentType="text/html; charset=GBK" pageEncoding="GBK"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose. dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=GBK">
<title>发表文章</title>
</head>
<body>
<h1 align="center">发表文章</h1>
<form action="newArticle.action">
<table align="center" border="0">
<tr>
<td>标题:</td>
<td><input type="text" name="title"></td>
</tr>
<tr>
<td colspan="2">正文:</td>
</tr>
<tr>
<td colspan="2">
<textarea name="article" rows="20" cols="70"></textarea>
</td>
</tr>
<tr>
<td><input type="submit" value="发表"></td>
<td> </td>
</tr>
</table>
</form>
</body>
</html>
这是整个应用的核心逻辑,其实现方式大大区别于使用Servlet作为控制器的方式,这也是Struts2应用区别于传统应用的关键所在。Action都是Java类,在编写之前先为其定义一个包:在包cn.csai.simple_forum2中新建包actions。
1.RegistryAction
根据前面的分析,该Action根据给定的用户名和密码完成注册功能,需要的参数是userName和password,返回结果可能是“userExist”或“success”。
首先在actions包中新建一个普通的Java类RegistryAction,继承自类com.opensymphony. xwork2.ActionSupport。
然后编辑代码内容如下:
package cn.csai.simple_forum2.actions;
import cn.csai.simple_forum2.model.ForumDataPool;
import cn.csai.simple_forum2.model.User;
public class RegistryAction {
private static final String USER_EXIST = "userExist";
private static final String SUCCESS = "success";
private String userName;
private String password;
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String execute() throws Exception {
if (null == userName || null == password)
throw new IllegalStateException();
User user = new User(userName, password);
if (ForumDataPool.infoExists(user)) {
return USER_EXIST;
} else {
ForumDataPool.addUser(user);
return SUCCESS;
}
}
}
该类定义了两个静态的字符串变量,定义了两个字符串,每个字符串代表了一种处理结果,userExist是当待注册的用户名已存在的时候被返回,success是当注册成功时被返回;定义了两个私有域变量userName和password,并且分别为它们定义了getter和setter方法,用于Struts2框架获取和设置这两个变量;最主要的业务逻辑是有execute()完成的,它由userName和password构造出一个User对象,并且判断该User对象所表示的用户信息在系统中是否已存在,如果存在则返回userExist,否则将该用户信息添加到系统中,然后返回success。
2.登录
该Action负责用户登录操作,与RegistryAction类似,该Action需要的参数也是userName和password,返回结果可能是“error”或“success”。
编辑代码内容如下:
package cn.csai.simple_forum2.actions;
import javax.servlet.http.HttpServletRequest;
import org.apache.struts2.ServletActionContext;
import cn.csai.simple_forum2.model.ForumDataPool;
import cn.csai.simple_forum2.model.User;
public class LogonAction {
private static final String ERROR = "error";
private static final String SUCCESS = "success";
private String userName;
private String password;
public String getUserName() {
return userName;
}
public void setUserName(String userName) {
this.userName = userName;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public String execute() throws Exception {
if (null == userName || null == password)
throw new IllegalStateException();
User user = new User(userName, password);
if (ForumDataPool.InfoExists(user)) {
HttpServletRequest request = (HttpServletRequest) ServletActionContext.getContext().get (ServletActionContext.HTTP_REQUEST);
request.getSession().setAttribute("userName", userName);
return SUCCESS;
} else {
return ERROR;
}
}
}
在execute()中判断提供的用户名和密码在系统中是否存在,如果存在则允许登录,并且将登录用户的用户名记录在Session中,然后返回success;否则返回error。
3.发表文章
该Action负责处理用户发表文章的请求,该Action需要的参数是待发表文章的标题和内容。返回的结果只有一个,就是完成了发表文章,用always表示。
编辑代码内容如下:
package cn.csai.simple_forum2.actions;
import java.util.Date;
import javax.servlet.http.HttpServletRequest;
import org.apache.struts2.ServletActionContext;
import cn.csai.simple_forum2.model.Article;
import cn.csai.simple_forum2.model.ForumDataPool;
public class NewArticleAction {
private String title;
private String article;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getArticle() {
return article;
}
public void setArticle(String article) {
this.article = article;
}
public String execute() throws Exception {
String author = (String) ((HttpServletRequest) ServletActionContext.getContext().get(ServletAction Context.HTTP_REQUEST)).getSession().getAttribute("userName");
ForumDataPool.addArticle(new Article(title, author, article, new Date()));
return "always";
}
}
在execute()中,从Session中获取当前登录用户的用户名以及当前时间,然后与标题和内容一起构建一个Article对象,并将该Article添加到系统中。
编写好了模型、视图和控制器,下面需要根据这些内容对应用进行配置,将开发的Action配置到struts.xml文件中。
在介绍搭建工程时,已经为struts.xml文件建立了一个基本框架,现在只需要将开发的各个Action添加到其中就可以了。
内容如下:
<action name="registry" class="cn.csai.simple_forum2.actions.RegistryAction">
<result name="userExist">/register.jsp?userExist=true</result>
<result name="success">/registerSuccessful.jsp</result>
</action>
<action name="logon" class="cn.csai.simple_forum2.actions.LogonAction">
<result name="error">/index.jsp?reLog=true</result>
<result name="success">/mainPage.jsp</result>
</action>
<action name="newArticle" class="cn.csai.simple_forum2.actions.NewArticleAction">
<result name="always">/mainPage.jsp</result>
</action>
这里规定了各个Action不同的处理结果所应该返回的不同视图。注册时如果指定的用户名已存在那么将返回到注册页面并且给出相应提示,所以这里userExist result指向register.jsp?userExist=true;注册成功则转向registerSuccessful.jsp。登录时如果指定的用户名和密码不正确则返回到登录页面并且给出相应提示,所以这里error result指向index.jsp?reLog=true;如果登录成功则返回mainPage.jsp。发表文章比较特殊,因为它只有一个结果,所以只定义了一个result,该result指向mainPage.jsp。
本章介绍了如何使用Struts2技术开发简单论坛系统,由于系统需求和界面在第18章已详细说明,所以本章一开始直接介绍系统的框架设计,然后从框架出发分别对Action以及Action与视图的交互方式进行设计。最后按照设计对系统进行开发,包括:搭建工程、开发模型、开发视图、开发控制器和配置应用。由于模型和视图基本可以延用第18章开发的内容,而控制器必须重新开发,所以本章重点介绍了控制器中各个Action的开发以及Action的配置。
java web 开发三剑客 -------电子书的更多相关文章
- Java Web开发中MVC设计模式简介
一.有关Java Web与MVC设计模式 学习过基本Java Web开发的人都已经了解了如何编写基本的Servlet,如何编写jsp及如何更新浏览器中显示的内容.但是我们之前自己编写的应用一般存在无条 ...
- 【转】 java web开发之安全事项
从事java web开发也有几年了,可是开发中的安全问题却越来越不以为然.直到不久遇到一黑软,瞬间sql注入,少时攻破网站数据库.还好,我还没有用root级的用户连接数据库.不过也没有什么用了,因为我 ...
- 【原创】三分钟教你学会MVC框架——基于java web开发(2)
没想到我的上一篇博客有这么多人看,还有几位看完之后给我留言加油,不胜感激,备受鼓励,啥都别说了,继续系列文章之第二篇.(如果没看过我第一篇博客的朋友,可以到我的主页上先浏览完再看这篇文章,以免上下文对 ...
- [Java Web整合开发王者归来·刘京华] 1、 Java Web开发
目录: 1.Web技术简介 2.动态网站与静态网站 3.Java Web开发模式 4.JavaScript简介 1.Web技术简介 PS: 最近还有更凶残的技术,即整个操作系统都是基于Web的,如 ...
- 个人的java web开发书单
首发至个人博客http://www.zidafone.com/blog/36 以下是对一些读过的书和一些买后随便翻了翻的书的个人感觉.都是java web开发的程序员可能接触的书,其他的如设计/手机开 ...
- java web开发必备知识
从各种招聘网站的要求上筛选出了一些java开发的一些基本的要求,对照自身看看有哪些缺陷. java基础 既然是java web开发,java SE肯定要学好了. 多线程,IO,集合等,对队列,缓存,消 ...
- Java Web开发之详解JSP
JSP作为Java Web开发中比较重要的技术,一般当作视图(View)的技术所使用,即用来展现页面.Servlet由于其本身不适合作为表现层技术,所以一般被当作控制器(Controller)所使用, ...
- Java Web开发介绍
转自:http://www.cnblogs.com/pythontesting/p/4963021.html Java Web开发介绍 简介 Java很好地支持web开发,在桌面上Eclipse RC ...
- 《Java web 开发实战经典》读书笔记
去年年末,也就是大四上学期快要结束的时候,当时保研的事情确定了下来,终于有了一些空闲的时间可以学点实用的技术. 之前做数据库课程设计的时候,也接触过java web的知识,当时做了一个卖二手书籍的网站 ...
随机推荐
- 蓝牙App漏洞系列分析之二CVE-2017-0639
蓝牙App漏洞系列分析之二CVE-2017-0639 0x01 漏洞简介 Android本月的安全公告,修复了我们发现的另一个蓝牙App信息泄露漏洞,该漏洞允许攻击者获取 bluetooth用户所拥有 ...
- 内置函数 lambda sorted filter map 递归
一 lambda 匿名函数 为了解决一些简单的需求而设计的一句话函数 # 计算 n 的 n次方 def func(n): return n**n print(func(10)) f = lambda ...
- python基础编程: 编码补充、文件操作、集合、函数参数、函数递归、二分查找、匿名函数与高阶函数
目录: 编码的补充 文件操作 集合 函数的参数 函数的递归 匿名函数与高阶函数 二分查找示例 一.编码的补充: 在python程序中,首行一般为:#-*- coding:utf-8 -*-,就是告诉p ...
- sql 实现取表中相同id时间最大的一行 利用distinct on
数据表是这样的 select * from water_level_records m where ( select count(*) from water_level_records n where ...
- linux内核 进程调度
概念: 进程调度决定那个进程投入运行,运行多长时间. 进程调度没有太复杂的原理,最大限度的利用处理器时间的原则是:只要有可执行的程序,那么总会有进程在执行,如果可运行的进程比处理器数目要多,那么注定要 ...
- 【idea】idea 2018.2 for mac永久破解激活方法(亲测2099)
1. 下载安装idea: 2. 下载激活Jar包 链接:https://pan.baidu.com/s/1NaxYrDNi2eW66epjmk10dg 密码:aec5 3. 在访达中新建/Librar ...
- 重新学习ESP32(零)之环境搭建——转载——windows平台
原文来自:https://www.makingfun.xyz/2018/09/18/esp32-hello-world/ 前言 前几天看到乐鑫的公众号推送了一篇文章,说是ESP8266最新的SDK风格 ...
- hive日期函数-杂谈(一)
来到广发返现由于历史遗留问题很多时间格式十分杂乱 我将总结一下时间日期的事情 1.hive原生时间函数的功能 2.一些基本业务时间范围的指标的sql案例 3.自定义udf函数让后来人更方便
- VUE: 移动端长按弹出确认删除地址(后面测试发现IOS有BUG,后面有更新随笔,更新后的亲测有效)
收货地址的删除方式可能有很多种,我目前见过的暂时只有两种(1.在编辑页删除 2.长按某一条收货地址弹出是否删除地址) 在开发的项目上要求第二种删除方法,于是记录一下我写的代码 ~ 1.首先,在移动端 ...
- 灰度图像--频域滤波 傅里叶变换之连续信号傅里叶变换(FT)
学习DIP第20天 转载请标明本文出处:http://blog.csdn.net/tonyshengtan,欢迎大家转载,发现博客被某些论坛转载后,图像无法正常显示,无法正常表达本人观点,对此表示很不 ...