机器学习(十)—聚类算法(KNN、Kmeans、密度聚类、层次聚类)
聚类算法
任务:将数据集中的样本划分成若干个通常不相交的子集,对特征空间的一种划分。
性能度量:类内相似度高,类间相似度低。两大类:1.有参考标签,外部指标;2.无参照,内部指标。
距离计算:非负性,同一性(与自身距离为0),对称性,直递性(三角不等式)。包括欧式距离(二范数),曼哈顿距离(一范数)等等。
1、KNN
k近邻(KNN)是一种基本分类与回归方法。
其思路如下:给一个训练数据集和一个新的实例,在训练数据集中找出与这个新实例最近的k 个训练实例,然后统计最近的k 个训练实例中所属类别计数最多的那个类,就是新实例的类。其流程如下所示:
- 计算训练样本和测试样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等);
- 对上面所有的距离值进行排序;
- 选前k 个最小距离的样本;
- 根据这k 个样本的标签进行投票,得到最后的分类类别;
KNN的特殊情况是k =1 的情况,称为最近邻算法。对输入的实例点(特征向量)x ,最近邻法将训练数据集中与x 最近邻点的类作为其类别。
(1)一般k 会取一个较小的值,然后用过交叉验证来确定;
(2)距离度量:一般是欧式距离(二范数),或者曼哈顿距离(一范数)
(3)回归问题:取K个最近样本的平均,或者使用加权平均。
算法的优点:(1)思想简单,理论成熟,既可以用来做分类也可以用来做回归;(2)可用于非线性分类;(3)训练时间复杂度为O(n);(4)准确度高,对数据没有假设,对outlier不敏感。
缺点:计算量大;样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少);需要大量的内存;
需要考虑问题:(1)KNN的计算成本很高;(2)所有特征应该标准化数量级,否则数量级大的特征在计算距离上会有偏移;(3)在进行KNN前预处理数据,例如去除异常值,噪音等。
KD树是一个二叉树,表示对K维空间的一个划分,可以进行快速检索(那KNN计算的时候不需要对全样本进行距离的计算了)。KD树更加适用于实例数量远大于空间维度的KNN搜索,如果实例的空间维度与实例个数差不多时,它的效率基于等于线性扫描。
2、K-Means
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛。
基本思想:对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
算法步骤:1.随机选择k个样本作为初始均值向量;2.计算样本到各均值向量的距离,把它划到距离最小的簇;3.计算新的均值向量;4.迭代,直至均值向量未更新或到达最大次数。
时间复杂度:O(tkmn),其中,t为迭代次数,k为簇的数目,m为记录数,n为维数;
空间复杂度:O((m+k)n),其中,k为簇的数目,m为记录数,n为维数。
优点:原理比较简单,实现也是很容易,收敛速度快;聚类效果较优;算法的可解释度比较强;主要需要调参的参数仅仅是簇数k。
缺点: 1、聚类中心的个数K 需要事先给定,这个 K 值的选定是非常难以估计的。很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适;一般通过交叉验证确定;
2、不同的初始聚类中心可能导致完全不同的聚类结果。算法速度依赖于初始化的好坏,初始质点距离不能太近;
3、如果各隐含类别的数据不平衡,比如各隐含类别的数据量严重失衡,或者各隐含类别的方差不同,则聚类效果不佳;
4、该方法不适于发现非凸面形状的簇或大小差别很大的簇,对于不是凸的数据集比较难收敛;
5、对噪音和异常点比较的敏感。
6、需样本存在均值(限定数据种类)。
7、采用迭代方法,得到的结果只是局部最优。
K-Means算法改进:
1、K-Means++算法就是对K-Means随机初始化质心的方法的优化。
K-Means++的对于初始化质心的优化策略也很简单,如下:
a) 从输入的数据点集合中随机选择一个点作为第一个聚类中心
b) 对于数据集中的每一个点,计算它与已选择的聚类中心中最近聚类中心的距离
c) 选择一个新的数据点作为新的聚类中心,选择的原则是:距离较大的点,被选取作为聚类中心的概率较大
d) 重复b和c直到选择出k个聚类质心
e) 利用这k个质心来作为初始化质心去运行标准的K-Means算法。
2、二分-K均值是为了解决k-均值的用户自定义输入簇值k所延伸出来的自己判断k数目,针对初始聚类中心选择问题,其基本思路是:
为了得到k个簇,将所有点的集合分裂成两个簇,从这些簇中选取一个继续分裂,如此下去,直到产生k个簇。
具体描述:比如要分成5个组,第一次分裂产生2个组,然后从这2个组中选一个目标函数产生的误差比较大的,分裂这个组产生2个,这样加上开始那1个就有3个组了,然后再从这3个组里选一个分裂,产生4个组,重复此过程,产生5个组。这算是一中基本求精的思想。
二分k均值不太受初始化的困扰,因为它执行了多次二分试验并选取具有最小误差的试验结果,还因为每步只有两个质心。
3、大样本优化Mini Batch K-Means
也就是用样本集中的一部分的样本来做传统的K-Means,这样可以避免样本量太大时的计算难题,算法收敛速度大大加快。当然此时的代价就是我们的聚类的精确度也会有一些降低。一般来说这个降低的幅度在可以接受的范围之内。
在Mini Batch K-Means中,我们会选择一个合适的批样本大小batch size,我们仅仅用batch size个样本来做K-Means聚类。那么这batch size个样本怎么来的?一般是通过无放回的随机采样得到的。为了增加算法的准确性,我们一般会多跑几次Mini Batch K-Means算法,用得到不同的随机采样集来得到聚类簇,选择其中最优的聚类簇。
3、 层次聚类
步骤:1.先将数据集中的每个样本看作一个初始聚类簇;2.找到距离最近的两个聚类簇进行合并。
优点:无需目标函数,没有局部极小问题或是选择初始点的问题。缺点:计算代价大。
4、密度聚类
DBSCAN既可以适用于凸样本集,也可以适用于非凸样本集。找到几个由密度可达关系导出的最大的密度相连样本集合。即为我们最终聚类的一个类别,或者说一个簇。
基本思想:它任意选择一个没有类别的核心对象作为种子,然后找到所有这个核心对象能够密度可达的样本集合,即为一个聚类簇。接着继续选择另一个没有类别的核心对象去寻找密度可达的样本集合,这样就得到另一个聚类簇。一直运行到所有核心对象都有类别为止。
步骤:1、找到任意一个核心点,对该核心点进行扩充;2、扩充方法是寻找从该核心点出发的所有密度相连的数据点;3、遍历该核心的邻域内所有核心点,寻找与这些数据点密度相连的点。
优点:不需要确定要划分的聚类个数,聚类结果没有偏倚;抗噪声,在聚类的同时发现异常点,对数据集中的异常点不敏感;处理任意形状和大小的簇,相对的,K-Means之类的聚类算法一般只适用于凸数据集。
缺点:数据量大时内存消耗大,相比K-Means参数多一些;样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用DBSCAN聚类一般不适合;
那么我们什么时候需要用DBSCAN来聚类呢?一般来说,如果数据集是稠密的,并且数据集不是凸的,那么用DBSCAN会比K-Means聚类效果好很多。如果数据集不是稠密的,则不推荐用DBSCAN来聚类。
面试问题:
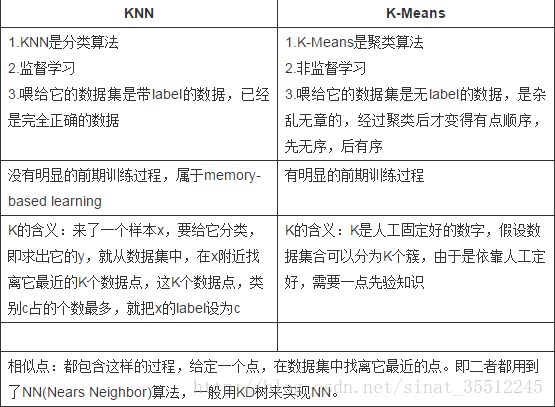
1、K-Means与KNN区别
2、Kmeans的k值如何确定?
(1)枚举,由于kmeans一般作为数据预处理,所以k一般不会设置很大,可以通过枚举,令k从2到一个固定的值,计算当前k的所有样本的平均轮廓系数,最后选择轮廓系数最接近于1对应的k作为最终的集群数目;(2)数据先验知识,或者对数据进行简单的分析或可视化得到。
3、初始点选择方法?
初始的聚类中心之间相互距离尽可能远。(1)kmeans++,随机选择一个,对每一个样本计算到他的距离,距离越大的被选中聚类中心的概率也就越大,重复。(2)选用层次聚类进行出初始聚类,然后从k个类别中分别随机选取k个点。
4、kmeans不能处理哪种数据?
(1)非凸(non-convex)数据。可以用kernal k均值聚类解决。
(2)非数值型数据。Kmeans只能处理数值型数据。可以用k-modes。初始化k个聚类中心,计算样本之间相似性是根据两个样本之间所有属性,如属性不同则距离加1,相同则不加,所以距离越大,样本的不相关性越大。更新聚类中心,使用一个类中每个属性出现频率最大的那个属性值作为本类的聚类中心。
(3)噪声和离群值的数据。可以用kmedoids(根据中值而不是均值)。
(4)不规则形状(有些部分密度很大,有些很小),可以用密度聚类DBSCAN解决。
5、kmeans如何处理大数据,几十亿?
并行计算。MapReduce,假设有H个Mapper,把数据集分为H个子集,分布到H个Mapper上,初始化聚类中心,并同时广播到H个Mapper上。
参考资料:http://www.cnblogs.com/pinard/p/6164214.html
http://www.cnblogs.com/pinard/p/6208966.html
https://blog.csdn.net/sinat_35512245/article/details/55051306
机器学习(十)—聚类算法(KNN、Kmeans、密度聚类、层次聚类)的更多相关文章
- 聚类算法:K均值、凝聚层次聚类和DBSCAN
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 常见聚类算法——K均值、凝聚层次聚类和DBSCAN比较
聚类分析就仅根据在数据中发现的描述对象及其关系的信息,将数据对象分组(簇).其目标是,组内的对象相互之间是相似的,而不同组中的对象是不同的.组内相似性越大,组间差别越大,聚类就越好. 先介绍下聚类的不 ...
- 聚类算法与K-means实现
聚类算法与K-means实现 一.聚类算法的数学描述: 区别于监督学习的算法(回归,分类,预测等),无监督学习就是指训练样本的 label 未知,只能通过对无标记的训练样本的学习来揭示数据的内在规律和 ...
- 机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记
机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记 关键字:k-均值.kMeans.聚类.非监督学习作者:米仓山下时间: ...
- 机器学习聚类算法之K-means
一.概念 K-means是一种典型的聚类算法,它是基于距离的,是一种无监督的机器学习算法. K-means需要提前设置聚类数量,我们称之为簇,还要为之设置初始质心. 缺点: 1.循环计算点到质心的距离 ...
- 浅谈聚类算法(K-means)
聚类算法(K-means)目的是将n个对象根据它们各自属性分成k个不同的簇,使得簇内各个对象的相似度尽可能高,而各簇之间的相似度尽量小. 而如何评测相似度呢,采用的准则函数是误差平方和(因此也叫K-均 ...
- 机器学习十大算法之KNN(K最近邻,k-NearestNeighbor)算法
机器学习十大算法之KNN算法 前段时间一直在搞tkinter,机器学习荒废了一阵子.如今想重新写一个,发现遇到不少问题,不过最终还是解决了.希望与大家共同进步. 闲话少说,进入正题. KNN算法也称最 ...
- 机器学习十大算法 之 kNN(一)
机器学习十大算法 之 kNN(一) 最近在学习机器学习领域的十大经典算法,先从kNN开始吧. 简介 kNN是一种有监督学习方法,它的思想很简单,对于一个未分类的样本来说,通过距离它最近的k个" ...
- 机器学习算法总结(五)——聚类算法(K-means,密度聚类,层次聚类)
本文介绍无监督学习算法,无监督学习是在样本的标签未知的情况下,根据样本的内在规律对样本进行分类,常见的无监督学习就是聚类算法. 在监督学习中我们常根据模型的误差来衡量模型的好坏,通过优化损失函数来改善 ...
- [数据挖掘] - 聚类算法:K-means算法理解及SparkCore实现
聚类算法是机器学习中的一大重要算法,也是我们掌握机器学习的必须算法,下面对聚类算法中的K-means算法做一个简单的描述: 一.概述 K-means算法属于聚类算法中的直接聚类算法.给定一个对象(或记 ...
随机推荐
- 对图片清晰度问题,纠结了一晚上。清理了下Libray,瞬间变清晰了,泪奔
对图片清晰度问题,纠结了一晚上.清理了下Libray,瞬间变清晰了,泪奔
- 【c# 学习笔记】类实例化
类中可以定义的成员,包括字段.属性.构造函数.实例方法和析构函数等. 要访问这些实例成员,必须通过类的实例对象来完成.而要得到一个类的实例对象,就必须先声明一个该类类型的变量,然后使用new运算符后跟 ...
- 在C/C++中常用的符号
C++中&和*的用法一直是非常让人头疼的难点,课本博客上讲这些知识点一般都是分开讲其用法的,没有详细的总结,导致我在这方面的知识结构格外混乱,在网上找到了一篇英文文章简单总结了这两个符号的一些 ...
- C语言获取文件大小相关操作
C语言获取文件大小相关操作 声明:引用请注明出处http://blog.csdn.net/lg1259156776/ 说明 通常在希望从文件中把数据全都出来赋值给一个数组或者某一个指针,然后再进行相关 ...
- NET CORE与Spring Boot
NET CORE与Spring Boot 本文分别说明.NET CORE与Spring Boot 编写控制台程序应有的“正确”方法,以便.NET程序员.JAVA程序员可以相互学习与加深了解,注意本文只 ...
- docker 删除不用的镜像
1.删除悬空的镜像 docker image prune -a -f 2.删除悬空的镜像 docker container prune -f 3.定时清空镜像和脚本 [root@VM_0_42_cen ...
- eNSP——静态路由的基本配置
原理: 静态路由是指用户或网络管理员手工配置的路由信息.当网络的拓扑结构或链路状态发生改变时,需要网络管理人员手工修改静态路由信息. 相比于动态路由协议,静态路由无需频繁地交换各自的路由表,配置简单, ...
- tomcat性能优化参数
线上环境使用默认tomcat配置文件,性能很一般,为了满足大量用户的访问,需要对tomcat进行参数性能优化,具体优化的地方如下: Linux内核的优化 服务器资源JVM 配置的优化 Tomcat参数 ...
- [翻译向] 当flush privileges生效时
#前言: 最近频繁在mysql权限控制这里栽跟斗,在翻阅了一些资料之后,简单地翻译一下官网关于flush privileges的描述,抛砖引玉. #翻译正文: If the mysqld serv ...
- Jenkins+maven+gitlab自动化部署之gitLab搭建(二)
Gitlab我们这里采用docker方式部署,详细请参考:Docker部署Gitlab11.10.4