Boosting算法(一)
本章全部来自于李航的《统计学》以及他的博客和自己试验。仅供个人复习使用。
Boosting算法通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类性能。我们以AdaBoost为例。
它的自适应在于:前一个弱分类器分错的样本的权值(样本对应的权值)会得到加强,权值更新后的样本再次被用来训练下一个新的弱分类器。
在每轮训练中,用总体(样本总体)训练新的弱分类器,产生新的样本权值、该弱分类器的话语权,一直迭代直到达到预定的错误率或达到指定的最大迭代次数。
有两个问题需要回答:
1.每一轮如何改变训练数据的权重或者是概率分布
=>提高那些被前一轮若分类器错误分类样本的权重,而降低那些被正确分类样本的权重值,
so那些没有得到正确分类的数据由于其权重值加大而受到后一轮的弱分类器的更大关注。于是分类问题被一系列的弱分类器“分而治之”
2.如何将如分类器组合成一个强分类器
=>弱分类器的组合,adaboost采取加权多数的表决方法:加大分类误差小的分类器的权值,使其在表决中起较大的作用,减少分类误差率大的弱分类器的权值,使其在变绝种起较小的作用。
那我们总结一下:
(1)初始化训练数据(每个样本)的权值分布:如果有N个样本,则每一个训练的样本点最开始时都被赋予相同的权重:1/N。
(2)训练弱分类器。具体训练过程中,如果某个样本已经被准确地分类,那么在构造下一个训练集中,它的权重就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。
同时,得到弱分类器对应的话语权。然后,更新权值后的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
(3)将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,分类误差率小的弱分类器的话语权较大,其在最终的分类函数中起着较大的决定作用,
而分类误差率大的弱分类器的话语权较小,其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的比例较大,反之较小。



迭代过程1
对于m=1,在权值分布为D1(10个数据,每个数据的权值皆初始化为0.1)的训练数据上,经过计算可得:
阈值v取2.5时误差率为0.3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.3),
阈值v取5.5时误差率最低为0.4(x < 5.5时取1,x > 5.5时取-1,则3 4 5 6 7 8皆分错,误差率0.6大于0.5,不可取。故令x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.4),
阈值v取8.5时误差率为0.3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.3)。
可以看到,无论阈值v取2.5,还是8.5,总得分错3个样本,故可任取其中任意一个如2.5,弄成第一个基本分类器为:

上面说阈值v取2.5时则6 7 8分错,所以误差率为0.3,更加详细的解释是:因为样本集中
0 1 2对应的类(Y)是1,因它们本身都小于2.5,所以被G1(x)分在了相应的类“1”中,分对了。
3 4 5本身对应的类(Y)是-1,因它们本身都大于2.5,所以被G1(x)分在了相应的类“-1”中,分对了。
但6 7 8本身对应类(Y)是1,却因它们本身大于2.5而被G1(x)分在了类"-1"中,所以这3个样本被分错了。
9本身对应的类(Y)是-1,因它本身大于2.5,所以被G1(x)分在了相应的类“-1”中,分对了。
从而得到G1(x)在训练数据集上的误差率(被G1(x)误分类样本“6 7 8”的权值之和)e1=P(G1(xi)≠yi) = 3*0.1 = 0.3。
然后根据误差率e1计算G1的系数:
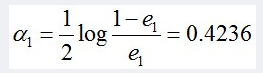
这个a1代表G1(x)在最终的分类函数中所占的权重,为0.4236。
接着更新训练数据的权值分布,用于下一轮迭代:
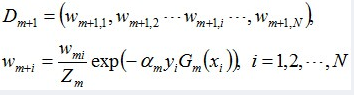
值得一提的是,由权值更新的公式可知,每个样本的新权值是变大还是变小,取决于它是被分错还是被分正确。
即如果某个样本被分错了,则yi * Gm(xi)为负,负负得正,结果使得整个式子变大(样本权值变大),否则变小。
第一轮迭代后,最后得到各个数据新的权值分布D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)。由此可以看出,因为样本中是数据“6 7 8”被G1(x)分错了,所以它们的权值由之前的0.1增大到0.1666,反之,其它数据皆被分正确,所以它们的权值皆由之前的0.1减小到0.0715。
分类函数f1(x)= a1*G1(x) = 0.4236G1(x)。
此时,得到的第一个基本分类器sign(f1(x))在训练数据集上有3个误分类点(即6 7 8)。
从上述第一轮的整个迭代过程可以看出:被误分类样本的权值之和影响误差率,误差率影响基本分类器在最终分类器中所占的权重。
迭代过程2
对于m=2,在权值分布为D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715)的训练数据上,经过计算可得:
阈值v取2.5时误差率为0.1666*3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.1666*3),
阈值v取5.5时误差率最低为0.0715*4(x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.0715*3 + 0.0715),
阈值v取8.5时误差率为0.0715*3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.0715*3)。
所以,阈值v取8.5时误差率最低,故第二个基本分类器为:

面对的还是下述样本:

很明显,G2(x)把样本“3 4 5”分错了,根据D2可知它们的权值为0.0715, 0.0715, 0.0715,所以G2(x)在训练数据集上的误差率e2=P(G2(xi)≠yi) = 0.0715 * 3 = 0.2143。
计算G2的系数:
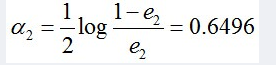
更新训练数据的权值分布:
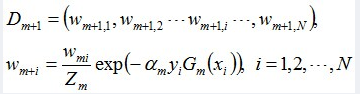
D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455)。被分错的样本“3 4 5”的权值变大,其它被分对的样本的权值变小。
f2(x)=0.4236G1(x) + 0.6496G2(x)
此时,得到的第二个基本分类器sign(f2(x))在训练数据集上有3个误分类点(即3 4 5)。
迭代过程3
对于m=3,在权值分布为D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455)的训练数据上,经过计算可得:
阈值v取2.5时误差率为0.1060*3(x < 2.5时取1,x > 2.5时取-1,则6 7 8分错,误差率为0.1060*3),
阈值v取5.5时误差率最低为0.0455*4(x > 5.5时取1,x < 5.5时取-1,则0 1 2 9分错,误差率为0.0455*3 + 0.0715),
阈值v取8.5时误差率为0.1667*3(x < 8.5时取1,x > 8.5时取-1,则3 4 5分错,误差率为0.1667*3)。
所以阈值v取5.5时误差率最低,故第三个基本分类器为:
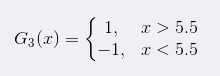
依然还是原样本:
此时,被误分类的样本是:0 1 2 9,这4个样本所对应的权值皆为0.0455,
所以G3(x)在训练数据集上的误差率e3 = P(G3(xi)≠yi) = 0.0455*4 = 0.1820。
计算G3的系数:
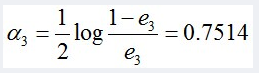
更新训练数据的权值分布:
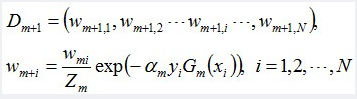
D4 = (0.125, 0.125, 0.125, 0.102, 0.102, 0.102, 0.065, 0.065, 0.065, 0.125)。被分错的样本“0 1 2 9”的权值变大,其它被分对的样本的权值变小。
f3(x)=0.4236G1(x) + 0.6496G2(x)+0.7514G3(x)
此时,得到的第三个基本分类器sign(f3(x))在训练数据集上有0个误分类点。至此,整个训练过程结束。
现在,咱们来总结下3轮迭代下来,各个样本权值和误差率的变化,如下所示(其中,样本权值D中加了下划线的表示在上一轮中被分错的样本的新权值):
训练之前,各个样本的权值被初始化为D1 = (0.1, 0.1,0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1);
第一轮迭代中,样本“6 7 8”被分错,对应的误差率为e1=P(G1(xi)≠yi) = 3*0.1 = 0.3,此第一个基本分类器在最终的分类器中所占的权重为a1 = 0.4236。第一轮迭代过后,样本新的权值为D2 = (0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.0715, 0.1666, 0.1666, 0.1666, 0.0715);
第二轮迭代中,样本“3 4 5”被分错,对应的误差率为e2=P(G2(xi)≠yi) = 0.0715 * 3 = 0.2143,此第二个基本分类器在最终的分类器中所占的权重为a2 = 0.6496。第二轮迭代过后,样本新的权值为D3 = (0.0455, 0.0455, 0.0455, 0.1667, 0.1667, 0.01667, 0.1060, 0.1060, 0.1060, 0.0455);
第三轮迭代中,样本“0 1 2 9”被分错,对应的误差率为e3 = P(G3(xi)≠yi) = 0.0455*4 = 0.1820,此第三个基本分类器在最终的分类器中所占的权重为a3 = 0.7514。第三轮迭代过后,样本新的权值为D4 = (0.125, 0.125, 0.125, 0.102, 0.102, 0.102, 0.065, 0.065, 0.065, 0.125)。
从上述过程中可以发现,如果某些个样本被分错,它们在下一轮迭代中的权值将被增大,同时,其它被分对的样本在下一轮迭代中的权值将被减小。就这样,分错样本权值增大,分对样本权值变小,而在下一轮迭代中,总是选取让误差率最低的阈值来设计基本分类器,所以误差率e(所有被Gm(x)误分类样本的权值之和)不断降低。
综上,将上面计算得到的a1、a2、a3各值代入G(x)中,G(x) = sign[f3(x)] = sign[ a1 * G1(x) + a2 * G2(x) + a3 * G3(x) ],得到最终的分类器为:
G(x) = sign[f3(x)] = sign[ 0.4236G1(x) + 0.6496G2(x)+0.7514G3(x) ]。
其实上面还有一点我没有指出就是弱分类器的指定:

弱分类器是提前给出的,或者说是提前训练的。
adaboost中弱分类器的设计还是很重要的:我看了几篇博客和论文以下几点
1任何分类器都行,但要是弱分类器,记得一篇论文中说如果是强分类器会影响最终训练性能,但没有试过。简单点可以用decision stump,其实就是一个判断,如果特征符合某个条件则为a类,否则是b类。其他决策树也行,至于使用不同分类器是不是有很大区别,没有做过实验不敢妄言,但肯定会有性能差别的。
2AdaBoost算法里面 要求弱分类器正确率>50%并且各个弱分类器相互独立 可是如果弱分类器错误率均在50%以下,但不完全独立 会造成什么样的后果呢?,弱分类器用最小平方误差,最小平方误差的错误率应该是50%以下的,可是调整权值会使分类器不独立(也可能不是,因为弱分类器是重新调整权值后重新计算的,跟上一次应该不算线形相关。在AdaBoost算法描述本身,也是用的调整权值来做的 ,说明这样的权值调整,并不会使弱分类器变得相关,不然,AdaBoost算法这么大的漏洞,不可能被广泛应用的),有说会让组合后的分类器错误率>50%而退出~ 可是我觉得不会,迭代算法应该能保证其越来越优,只是可能一直到不了错误率<0附近的值的状态。
3参考博客《谈谈对Gentle Adaboost的一点理解》给到很多对弱分类器的设计思考
Boosting算法(一)的更多相关文章
- Boosting算法简介
一.Boosting算法的发展历史 Boosting算法是一种把若干个分类器整合为一个分类器的方法,在boosting算法产生之前,还出现过两种比较重要的将多个分类器整合为一个分类器的方法,即boos ...
- 【Supervised Learning】 集成学习Ensemble Learning & Boosting 算法(python实现)
零. Introduction 1.learn over a subset of data choose the subset uniformally randomly (均匀随机地选择子集) app ...
- 机器学习相关知识整理系列之三:Boosting算法原理,GBDT&XGBoost
1. Boosting算法基本思路 提升方法思路:对于一个复杂的问题,将多个专家的判断进行适当的综合所得出的判断,要比任何一个专家单独判断好.每一步产生一个弱预测模型(如决策树),并加权累加到总模型中 ...
- Gradient Boosting算法简介
最近项目中涉及基于Gradient Boosting Regression 算法拟合时间序列曲线的内容,利用python机器学习包 scikit-learn 中的GradientBoostingReg ...
- 一步一步理解AdaBoosting(Adaptive Boosting)算法
最近学习<西瓜书>的集成学习之Boosting算法,看了一个很好的例子(https://zhuanlan.zhihu.com/p/27126737),为了方便以后理解,现在更详细描述一下步 ...
- Boosting算法总结(ada boosting、GBDT、XGBoost)
把之前学习xgb过程中查找的资料整理分享出来,方便有需要的朋友查看,求大家点赞支持,哈哈哈 作者:tangg, qq:577305810 一.Boosting算法 boosting算法有许多种具体算法 ...
- 集成学习算法汇总----Boosting和Bagging(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 集成学习算法总结----Boosting和Bagging
1.集成学习概述 1.1 集成学习概述 集成学习在机器学习算法中具有较高的准去率,不足之处就是模型的训练过程可能比较复杂,效率不是很高.目前接触较多的集成学习主要有2种:基于Boosting的和基于B ...
- 集成学习算法总结----Boosting和Bagging(转)
1.集成学习概述 1.1 集成学习概述 集成学习在机器学习算法中具有较高的准去率,不足之处就是模型的训练过程可能比较复杂,效率不是很高.目前接触较多的集成学习主要有2种:基于Boosting的和基于B ...
随机推荐
- solr后台操作Documents之增删改查
偶尔会用到solr后台操作一些数据,比如测试等一些情况.但具体用的时候可能会忘记,或者搜的时候结果不全,在此略详细的记一下. 1.添加 {"id":6,"title&qu ...
- Reactor系列(八)concatMap有序映射
#java#reactor#comcatMap# 有序映射 视频讲解:https://www.bilibili.com/video/av79705356/ FluxMonoTestCase.java ...
- 《鸟哥的Linux私房菜:基础学习篇》第二部分读书笔记
一.Linux的文件权限与目录配置 1. Linux用户身份与用户组记录的文件:默认情况下,/etc/passwd记录所有的系统账号与一般身份账号及root的相关信息,/etc/shadow记录个人的 ...
- AMD全新32核线程撕裂者GeekBench跑分曝光:超2950X近一倍
AMD全新32核线程撕裂者GeekBench跑分曝光:超2950X近一倍 2019年09月01日 09:36 1109 次阅读 稿源:快科技 1 条评论 https://www.cnbeta.com/ ...
- ffmpeg AVPacket结构体及其相关函数
0. 简介 AVPacket结构体并不是很复杂, 但是在ffmpeg中用的非常多. 与其相关的函数也是比较多. AVPacket保存了解复用之后, 解码之前的数据, 和这些数据相关的一些附加信息. 对 ...
- RabbitMQ快速开始
①:安装rabbitmq所需要的依赖包 yum install build-essential openssl openssl-devel unixODBC unixODBC-devel make g ...
- C++反汇编第五讲,认识C++中的Try catch语法,以及在反汇编中还原
我们以前讲SEH异常处理的时候已经说过了,C++中的Try catch语法只不过是对SEH做了一个封装. 如果不懂SEH异常处理,请点击博客链接熟悉一下,当然如果不想知道,也可以直接往下看.因为异常处 ...
- BASE64 Encode Decode
package com.humi.encryption; import java.io.IOException; import java.io.UnsupportedEncodingException ...
- MySQL下载安装图文
一. MySQL下载 1. 进入MySQL官网官网地址:https://www.mysql.com/ 2. 点击DOWNLOADS 3. 点击Community(GPL) Downloads 4. 找 ...
- cookie 和session的关联关系
session 1.1 数据存储,存服务器端, 浏览器解决http无状态问题的一种解决方案 登录,同一客户端访问服务端的时候,服务端都知道是这一个客户端 cookie 2.1 数据存储 , 存客户端 ...