HBase管理与监控——统计表行数
背景
HBase统计 RowCount 的方法有好几种,并且执行效率差别巨大,以下3种方法效率依次提高。
一、hbase-shell的count命令
这是最简单直接的操作,但是执行效率非常低,适用于百万级以下的小表RowCount统计。

此操作可能需要很长时间,来运行计数MapReduce作业。默认情况下每1000行显示当前计数,计数间隔可自行指定。
默认情况下在计数扫描上启用缓存,默认缓存大小为10行。
行数为 3000W 的表测试结果,在默认INTERVAL为1000行时花了80分钟左右
二、hbase.RowCounter包执行MR任务
这种方式效率非常高!利用了hbase jar中自带的统计行数的工具类!
通过 $HBASE_HOME/bin/hbase 命令执行:
hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'terminal_detail_data'

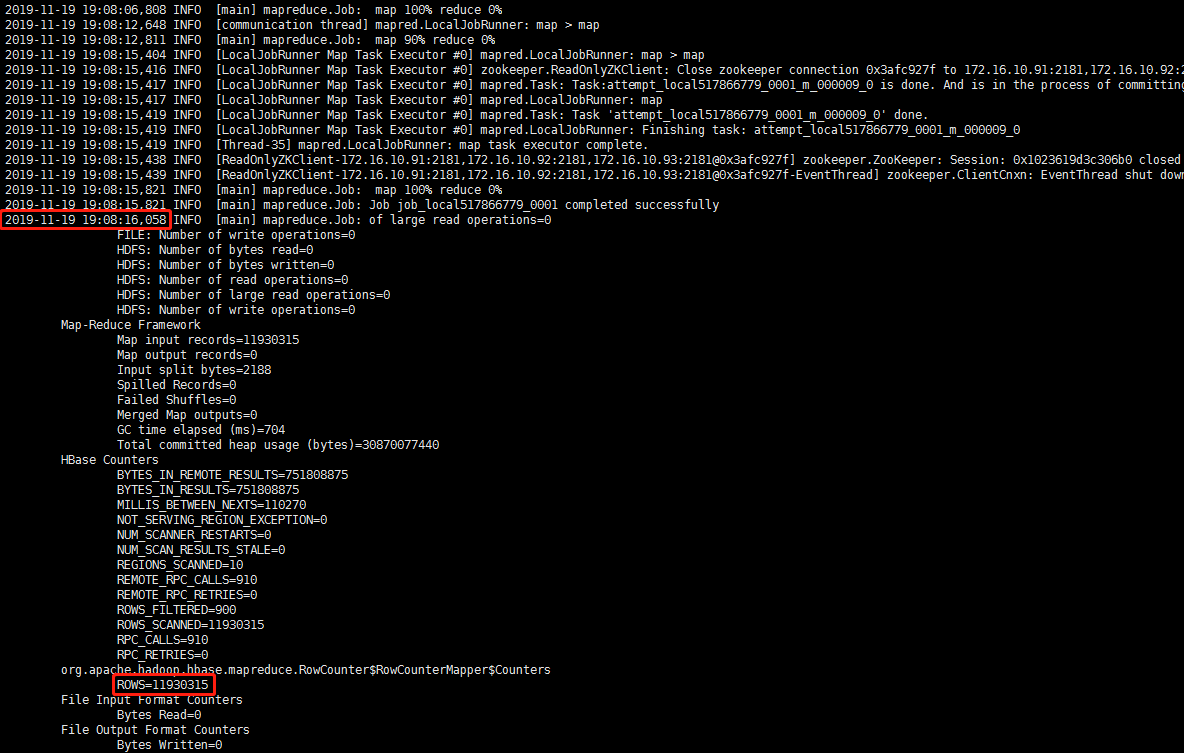
1200W的数据,耗时2分钟左右,速度较有了质的飞跃!
三、HBase协处理器Coprocessor(JAVA实现)
这是我目前发现效率最高的RowCount统计方式,利用了HBase高级特性:协处理器!
我们往往使用过滤器来减少服务器端通过网络返回到客户端的数据量。但HBase中还有一些特性让用户甚至可以把一部分计算也移动到数据的存放端,那就是协处理器 (coprocessor)。
协处理器简介:
(节选自《HBase权威指南》)
使用客户端API,配合筛选机制,例如,使用过滤器或限制列族的范围,都可以控制被返回到客户端的数据量。如果可以更进一步优化会更好,例如,数据的处理流程直接放到服务器端执行,然后仅返回一个小的处理结果集。这类似于一个小型的MapReduce框架,该框架将工作分发到整个集群。
协处理器 允许用户在region服务器上运行自己的代码,更准确地说是允许用户执行region级的操作,并且可以使用与RDBMS中触发器(trigger)类似的功能。在客户端,用户不用关心操作具体在哪里执行,HBase的分布式框架会帮助用户把这些工作变得透明。
实现代码:
public void rowCountByCoprocessor(String tablename){
try {
//提前创建connection和conf
Admin admin = connection.getAdmin();
TableName name=TableName.valueOf(tablename);
//先disable表,添加协处理器后再enable表
admin.disableTable(name);
HTableDescriptor descriptor = admin.getTableDescriptor(name);
String coprocessorClass = "org.apache.hadoop.hbase.coprocessor.AggregateImplementation";
if (! descriptor.hasCoprocessor(coprocessorClass)) {
descriptor.addCoprocessor(coprocessorClass);
}
admin.modifyTable(name, descriptor);
admin.enableTable(name);
//计时
StopWatch stopWatch = new StopWatch();
stopWatch.start();
Scan scan = new Scan();
AggregationClient aggregationClient = new AggregationClient(conf);
System.out.println("RowCount: " + aggregationClient.rowCount(name, new LongColumnInterpreter(), scan));
stopWatch.stop();
System.out.println("统计耗时:" +stopWatch.getTotalTimeMillis());
} catch (Throwable e) {
e.printStackTrace();
}
}
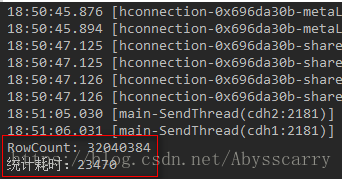
发现只花了 23秒 就统计完成!
为什么利用协处理器后速度会如此之快?
Table注册了Coprocessor之后,在执行AggregationClient的时候,会将RowCount分散到Table的每一个Region上,Region内RowCount的计算,是通过RPC执行调用接口,由Region对应的RegionServer执行InternalScanner进行的。
参考链接:https://blog.csdn.net/abysscarry/article/details/82861425
HBase管理与监控——统计表行数的更多相关文章
- HBase统计表行数(RowCount)的四种方法
背景:对于其他数据存储系统来说,统计表的行数是再基本不过的操作了,一般实现都非常简单:但对于HBase这种key-value存储结构的列式数据库,统计 RowCount 的方法却有好几种不同的花样,并 ...
- Hbase 统计表行数的3种方式总结
有些时候需要我们去统计某一个Hbase表的行数,由于hbase本身不支持SQL语言,只能通过其他方式实现.可以通过一下几种方式实现hbase表的行数统计工作: 1.count命令 最直接的方式是在hb ...
- HBase管理与监控——WebUI
一.Region Server栏信息 Requests Per Second,每秒读或写请求次数,可以用来监控HBase请求是否均匀.如果不均匀需排查是否为建表的region划分不合理造成. Num. ...
- HBase管理与监控——强制删除表
在用phoenix创建Hbase表时,有时会提示创建失败,发现Hbase中又已创建成功, 但这些表在进行enable.disable.drop都无效,也无法删除: hbase(main)::> ...
- HBase管理与监控——HBase region is not online
发现有些regison程序操作失败,其他region 都是正常的,重启regionserver 后依然报同样的错误. 首先进入hbase的bin目录,执行下面命令检查表是否有存储一致性问题: hbas ...
- HBase管理与监控——内存调优
HMaster 没有处理过重的负载,并且实际的数据服务不经过 HMaster,它的主要任务有2个:一.管理Hbase Table的 DDL操作, 二.region的分配工作,任务不是很艰巨. 但是如果 ...
- SQL 统计表行数和空间大小
CREATE TABLE #tablespaceinfo ( nameinfo VARCHAR() , rowsinfo BIGINT , reserved VARCHAR() , datainfo ...
- hbase自带mapreduce计数表行数功能
$HBASE_HOME/bin/hbase org.apache.hadoop.hbase.mapreduce.RowCounter ‘tablename’ mapreduce来计数,很快的!!!
- HBase管理与监控——HMaster或HRegionServer自动停止挂掉
问题描述 HBase在运行一段时间后,会出现以下2种情况: 1.HMaster节点自动挂掉: 通过jps命令,发现HMaster进程没了,只剩下HRegionServer,此时应用还能正常往HBase ...
随机推荐
- Android.mk走读与Cmake配置
Android.mk认识: 在上一次[https://www.cnblogs.com/webor2006/p/9946061.html]中学会了用NDK提供的交叉编译工程编译成Android能运行的可 ...
- Procomm Plus 与ASPECT脚本语言在基于远程终端设备上的测试应用
产测 ---------------------------------------------------- 原文:http://www.bixuanzl.com/20180801/1084478. ...
- Selenium(三)webdriver的API与定位元素
在学习定位元素之前,应该要学会: 1.打开浏览器 2.打开网页 3.定位元素及操作 ①定位元素 可只此输入框的id是kw,name是wd,class是s_ipt ②在python编辑器中找到该元素 通 ...
- phpstudy如何配置域名
其他选项菜单=>站点域名管理=>站点管理填入信息后点击“新增”按钮=>点击“保存设置并生成配置文件”按钮=>打开hosts=>127.0.0.1 www.gohosts. ...
- [ES2019] Use JavaScript ES2019 flatMap to Map and Filter an Array
ES2019 introduces the Array.prototype.flatMap method. In this lesson, we'll investigate a common use ...
- java http 上传文件夹
用JAVA实现大文件上传及显示进度信息 ---解析HTTP MultiPart协议 (本文提供全部源码下载,请访问 https://github.com/1269085759/up6-jsp-mysq ...
- [Luogu] U18430 萌萌的大河
https://www.luogu.org/problemnew/show/U18430 思路比较好想 树链剖分 对于1操作 只需将以该点为根的子树打标记,将所有数存入数组排序 每次进行1操作时,判断 ...
- 2019CCPC-江西省赛C题 HDU6569 GCD预处理+二分
Trap Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)Total Subm ...
- 三十、CentOS 7之systemd
一.系统启动流程 POST --> bootloader --> MBR工作 --> kernel(initramfs/initrd) --> ro rootfs --> ...
- 使用Excel拼凑SQL语句
快速将一列多行数据合并到一个单元格 EXCEL如何快速将一列多行数据合并到一个单元格,并加分隔符?这是批量处理由一线业务员统计的数据时的常用方法,尤其是当一列数据是wher ...