(转) Oracle性能优化-读懂执行计划
Oracle的执行计划

得到执行计划的方式

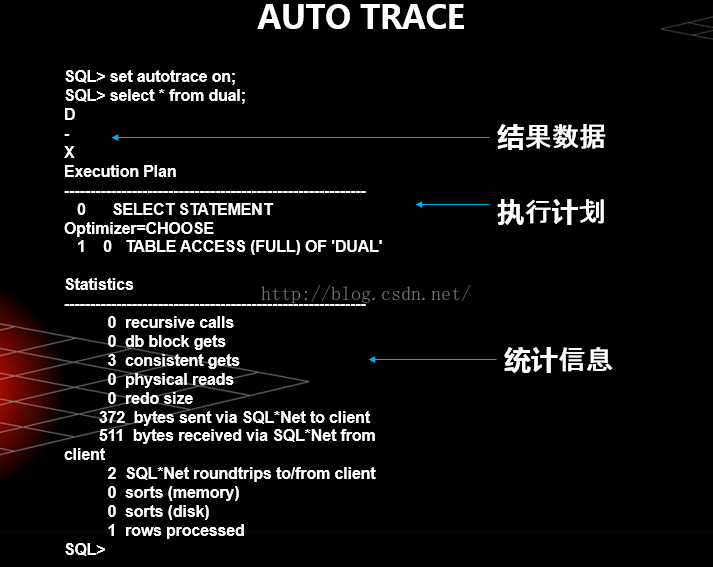
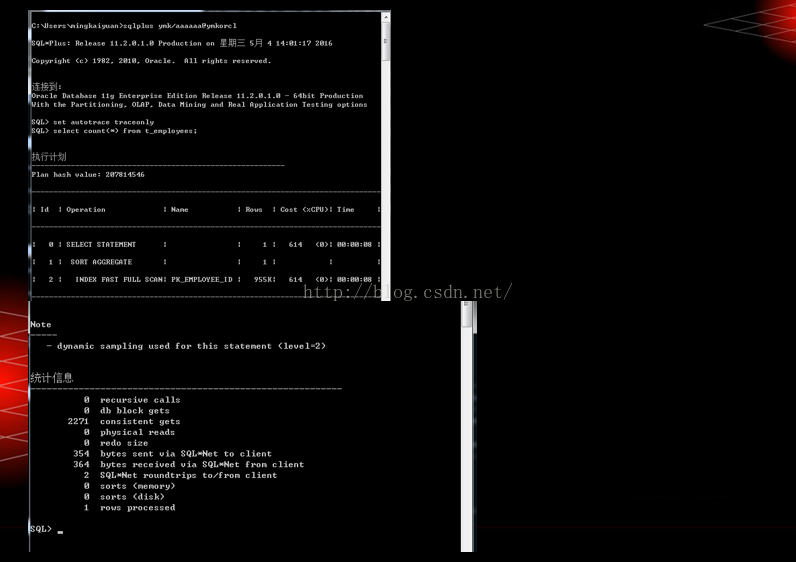
Autotrace例子
使用Explain

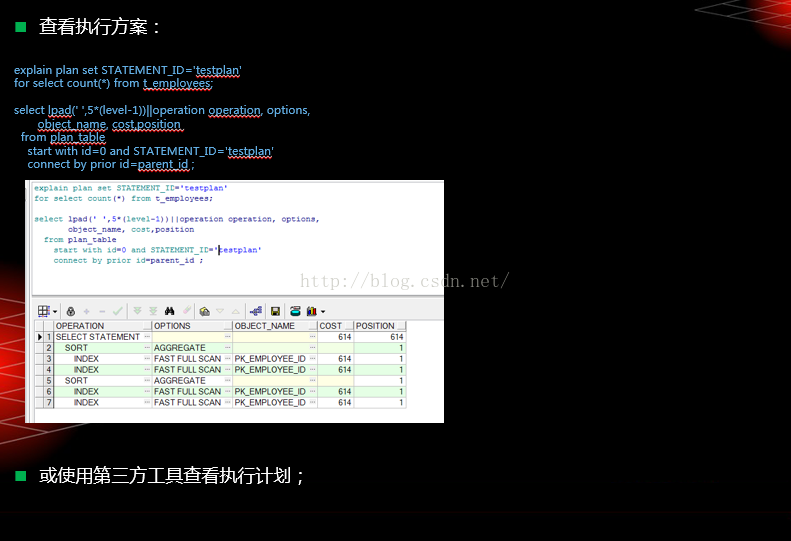
explain plan set STATEMENT_ID='testplan'
for select * from dual;
select lpad(' ',5*(level-1))||operation operation, options,
object_name, cost,position
from plan_table
start with id=0 and STATEMENT_ID='testplan'
connect by prior id=parent_id ;
怎样看执行计划

看懂执行计划前先需要了解的一些知识
伪列-ROWID
rowid是一个伪列,既然是伪列,那么这个列就不是用户定义,而是系统自己给加上的。对每个表都有一个rowid的伪列,但是表中并不物理存储ROWID列的值。不过你可以像使用其它列那样使用它,但是不能删除改列,也不能对该列的值进行修改、插入。一旦一行数据插入数据库,则rowid在该行的生命周期内是唯一的,即即使该行产生行迁移,行的rowid也不会改变。
Recursive SQL
有时为了执行用户发出的一个sql语句,Oracle必须执行一些额外的语句,我们将这些额外的语句称之为‘recursive calls’或‘recursive SQL statements’。如当一个DDL语句发出后,ORACLE总是隐含的发出一些recursive SQL语句,来修改数据字典信息,以便用户可以成功的执行该DDL语句。当需要的数据字典信息没有在共享内存中时,经常会发生Recursive calls,这些Recursive calls会将数据字典信息从硬盘读入内存中。用户不比关心这些recursive SQL语句的执行情况,在需要的时候,ORACLE会自动的在内部执行这些语句。当然DML语句也都可能引起recursive SQL。简单的说,我们可以将触发器视为recursive SQL。
Row Source and Predicate
Row Source(行源):用在查询中,由上一操作返回的符合条件的行的集合,即可以是表的全部行数据的集合;也可以是表的部分行数据的集合;也可以为对上2个row source进行连接操作(如join连接)后得到的行数据集合。
Predicate(谓词):一个查询中的WHERE限制条件
Driving Table
Driving Table(驱动表):该表又称为外层表(OUTER TABLE)。这个概念用于嵌套与HASH连接中。如果该row source返回较多的行数据,则对所有的后续操作有负面影响。注意此处虽然翻译为驱动表,但实际上翻译为驱动行源(driving row source)更为确切。一般说来a,是应用查询的限制条件后,返回较少行源的表作为驱动表,所以如果一个大表在WHERE条件有有限制条件(如等值限制),则该大表作为驱动表也是合适的,所以并不是只有较小的表可以作为驱动表,正确说法应该为应用查询的限制条件后,返回较少行源的表作为驱动表。在执行计划中,应该为靠上的那个row source,后面会给出具体说明。
Probed Table
Probed Table(被探查表):该表又称为内层表(INNER TABLE)。在我们从驱动表中得到具体一行的数据后,在该表中寻找符合连接条件的行。所以该表应当为大表(实际上应该为返回较大row source的表)且相应的列上应该有索引。
组合索引(concatenated index)
由多个列构成的索引,如create index idx_emp on emp(col1, col2, col3, ……),则我们称idx_emp索引为组合索引。在组合索引中有一个重要的概念:引导列(leading column),在上面的例子中,col1列为引导列。当我们进行查询时可以使用”where col1 = ? ”,也可以使用”where col1 = ? and col2 = ?”,这样的限制条件都会使用索引,但是”where col2 = ? ”查询就不会使用该索引。所以限制条件中包含先导列时,该限制条件才会使用该组合索引。
可选择性(selectivity)
比较一下列中唯一键的数量和表中的行数,就可以判断该列的可选择性。如果该列的”唯一键的数量/表中的行数”的比值越接近1,则该列的可选择性越高,该列就越适合创建索引,同样索引的可选择性也越高。在可选择性高的列上进行查询时,返回的数据就较少,比较适合使用索引查询。
oracle访问数据的存取方法(高实战)

索引扫描的细分(Index Scan)
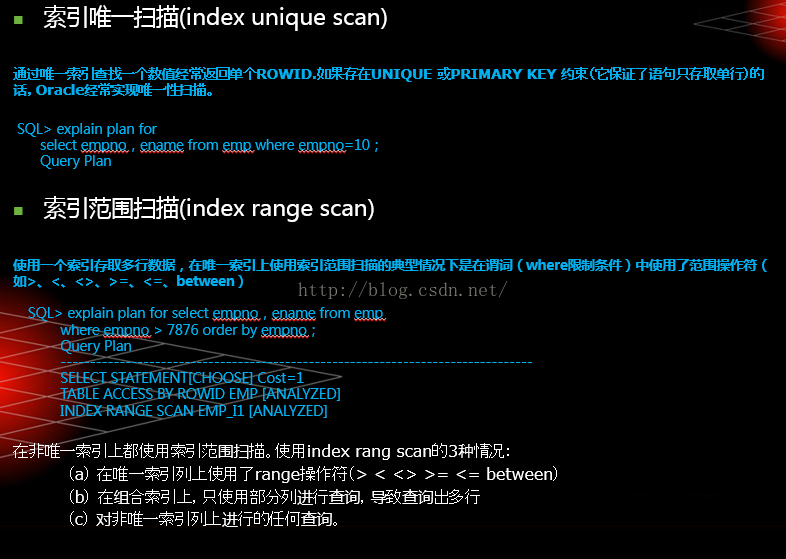
表连接(高实战1)

表连接(高实战2)

表连接(高实战3)
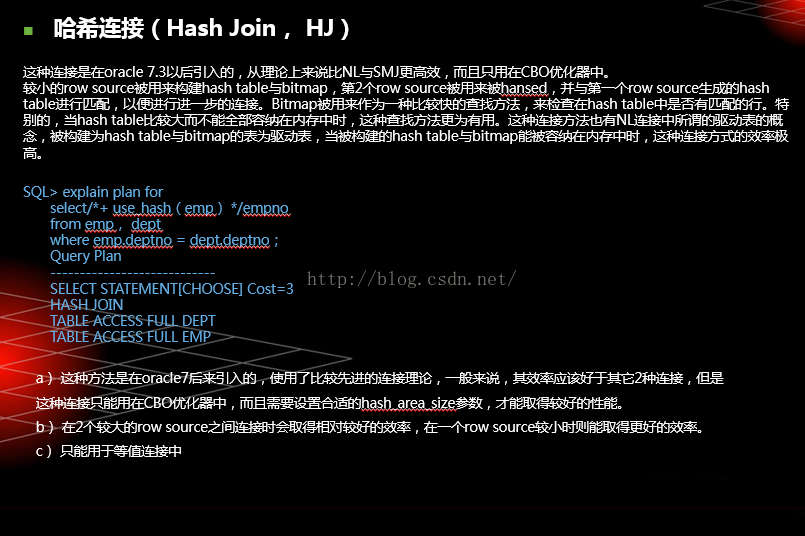
表连接(高实战4)

不同表连接的相对速度

一个简单的执行计划(在PLSQL-DEVELOPER里按F5,不是F4哈)
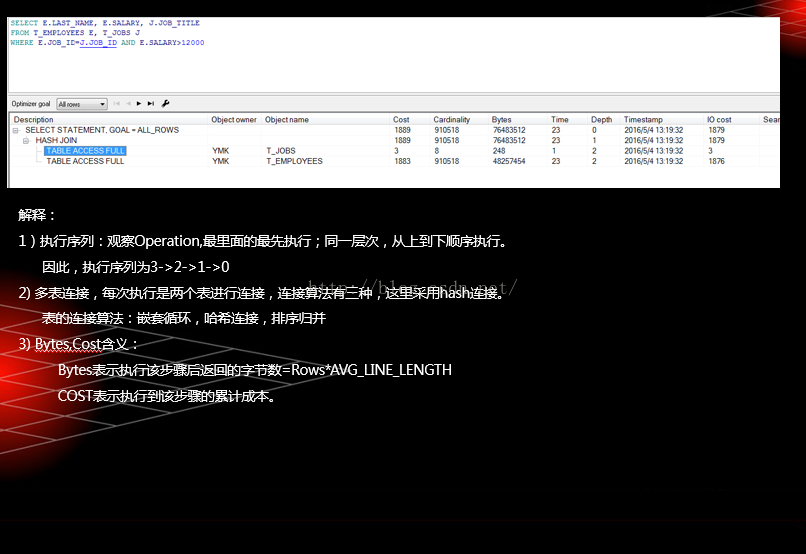
再来看2个执行计划(1)

再来看2个执行计划(2)

Oracle中的Hints(提示)
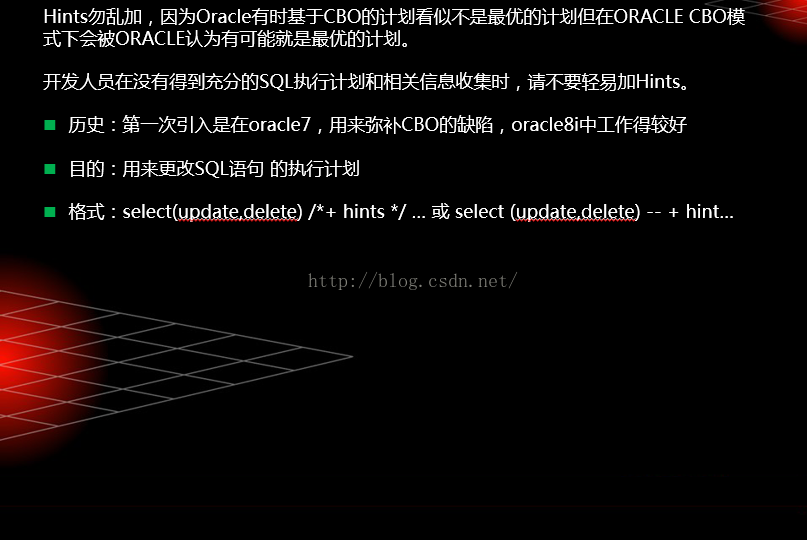
优化器提示
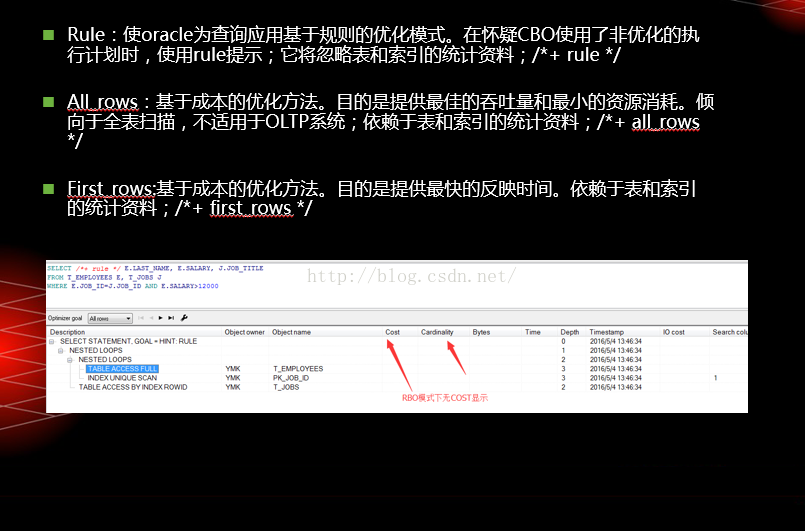
表连接提示


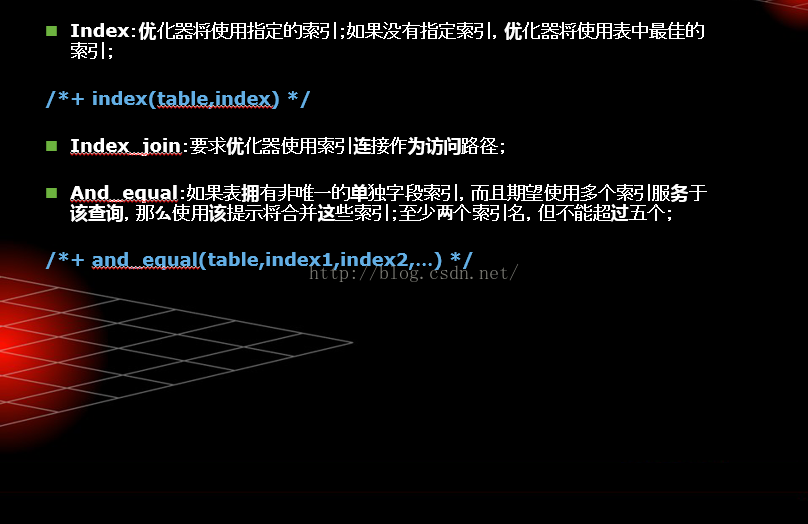
索引提示
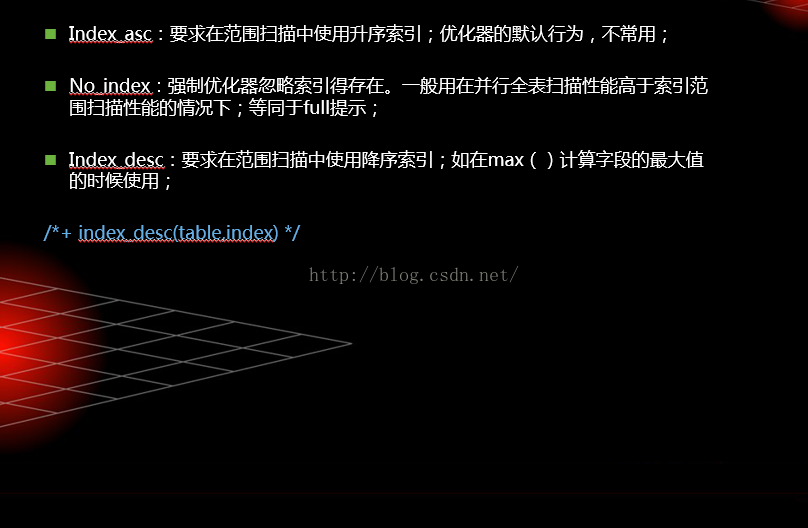

并行提示
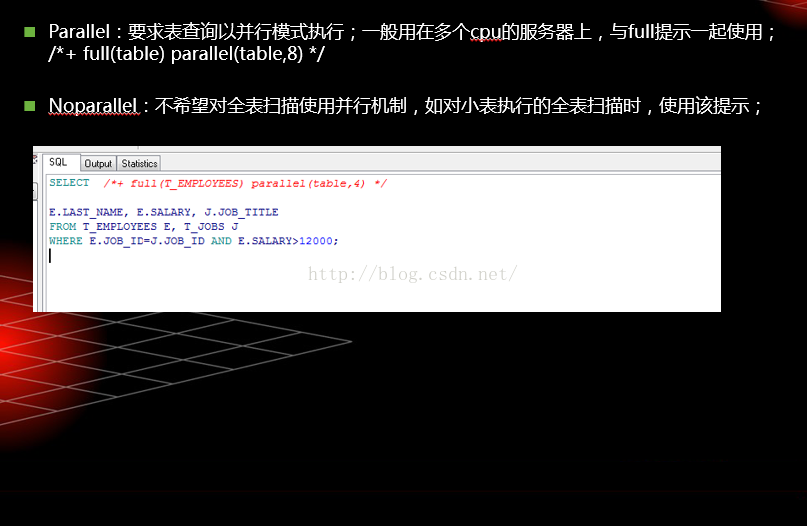
表访问提示

索引和SQL语句的正确使用
索引-参见《给PLSQL插上飞翔的翅膀-PLSQL优化》中的索引部分
SQL语句-参见《给PLSQL插上飞翔的翅膀-PLSQL优化》中的SQL WHERE和表连接部分
使用ORACLE自带的SQLPLUS
如何让SQLPLUS据有AUTOTRACE功能
以sys用户连接;
运行$ORACLE_HOME/sqlplus目录下的plustrace.sql脚本;
grant plustrace to public,对所有用户有效;
在sql*plus 中运行set autot on命令,将自动跟踪sql的执行计划并提供sql统计资料;
Consistent Gets

第1个不加order by的SQL肯定比第2个SQL效率高是毋庸置疑的。
但是为什么第2个SQL的consistent gets如此之少?
原因有如下两点:
通常情况下,不在logical RAM buffer中的数据要通过physical reads来读取,而physical reads后通常会紧跟着一个consistent gets。
因此一般情况下consistent gets是要比physical reads大的。但是有一个特例,如果physical reads得到的数据直接用于HASH或者SORT,
则只记为physical reads不记为consistent gets。所以加上order by后有可能physical reads多但consistent gets少。
不过这个原因不是我这里现象产生的原因,因为我这个实验里根本没有physical reads。arraysize的影响。
arraysize是指读取数据时一次读取得到的行数。这个值默认为15,
使用show arraysize命令可以查看。一个数据块例如有100条记录,那么并不是读取这个块一次就能取到所有数据,
以arraysize=15为例,就要有100/15=7次consistent gets。把arraysize设置得大一点可以降低consistent gets,
不过有时候可能会消耗更多的资源。如果我们做select count(0) from test;操作,
那么Oracle会把arraysize暂时设为test的行数,因此consistent gets会很少。很少:

AUTOTRACE的几个常用选项
set autotrace off : 不生成autotrace 报告,这是缺省模式
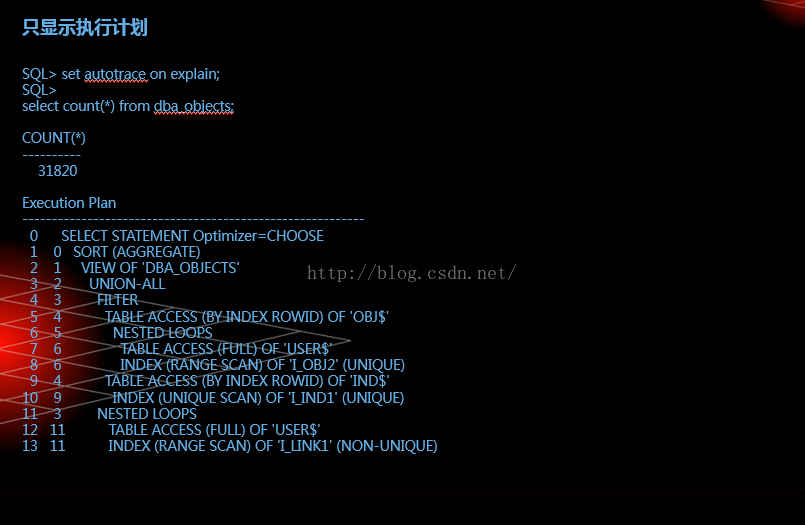
set autotrace on explain: autotrace只显示优化器执行路径报告
set autotrace on statistics: 只显示执行统计信息
set autotrace on: 包含执行计划和统计信息
set autotrace traceonly: 同set autotrace on,但是不显示查询输
set autotrace on explain
set autotrace on statistics

set autotrace traceonly

set autotrace traceonly explain

另一种查看SQL计划的方式-Explain plan
说明:用以查看SQL语句的执行计划
准备:
运行$ORACLE_HOME/rdbms/admin目录下的utlxplan.sql脚本
建立plan_table表
执行方案:explain plan for SQL
Explain Plan-查看执行方案
作者:袁鸣凯
来源:CSDN
原文:https://blog.csdn.net/lifetragedy/article/details/51320192
版权声明:本文为博主原创文章,转载请附上博文链接!
(转) Oracle性能优化-读懂执行计划的更多相关文章
- [z]Oracle性能优化-读懂执行计划
http://blog.csdn.net/lifetragedy/article/details/51320192 Oracle的执行计划 得到执行计划的方式 Autotrace例子 ...
- Oracle性能优化-读懂执行计划
Oracle的执行计划 得到执行计划的方式 Autotrace例子 使用Explain explain plan set STATEMENT_ID='testplan' for select * fr ...
- SQL Server索引进阶:第九级,读懂执行计划
原文地址: Stairway to SQL Server Indexes: Level 9,Reading Query Plans 本文是SQL Server索引进阶系列(Stairway to SQ ...
- Oracle性能优化之Oracle里的执行计划
一.执行计划 执行计划是目标SQL在oracle数据库中具体的执行步骤,oracle用来执行目标SQL语句的具体执行步骤的组合被称为执行计划. 二.如何查看oracle数据库的执行计划 oracle数 ...
- Oracle 课程五之优化器和执行计划
课程目标 完成本课程的学习后,您应该能够: •优化器的作用 •优化器的类型 •优化器的优化步骤 •扫描的基本类型 •表连接的执行计划 •其他运算方式的执行计划 •如何看执行计划顺序 •如何获取执行计划 ...
- 【转载】我眼中的Oracle性能优化
我眼中的Oracle性能优化 大家对于一个业务系统的运行关心有如下几个方面:功能性.稳定性.效率.安全性.而一个系统的性能有包含了网络性能.应用性能.中间件性能.数据库性能等等. 今天从数据库性能的角 ...
- 我眼中的 Oracle 性能优化
恒生技术之眼 作者 林景忠 大家对于一个业务系统的运行关心有如下几个方面:功能性.稳定性.效率.安全性.而一个系统的性能有包含了网络性能.应用性能.中间件性能.数据库性能等等. 今天从数据库性能的角度 ...
- oracle性能优化之awr分析
oracle性能优化之awr分析 作者:bingjava 最近某证券公司系统在业务期间系统运行缓慢,初步排查怀疑是数据库存在性能问题,因此导出了oracle的awr报告进行分析,在此进行记录. 导致系 ...
- mysql之优化器、执行计划、简单优化
mysql之优化器.执行计划.简单优化 2018-12-12 15:11 烟雨楼人 阅读(794) 评论(0) 编辑 收藏 引用连接: https://blog.csdn.net/DrDanger/a ...
随机推荐
- python之pip使用技巧
pip 镜像临时使用:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspider永久:直接在user目录中创建一个pip目录:C: ...
- [机器学习理论] 降维算法PCA、SVD(部分内容,有待更新)
几个概念 正交矩阵 在矩阵论中,正交矩阵(orthogonal matrix)是一个方块矩阵,其元素为实数,而且行向量与列向量皆为正交的单位向量,使得该矩阵的转置矩阵为其逆矩阵: 其中,为单位矩阵. ...
- Web比赛4
广外2019-11-30 @广外-枯燥的抽奖 <?php #这不是抽奖程序的源代码!不许看! header("Content-Type: text/html;charset=utf-8 ...
- Kettle作业的自带定时任务
文章出处:https://blog.csdn.net/jianlong727/article/details/53966286 7.1.新建作业 7.2.部署作业 在“核心对象”中拖拽两个图标到执行区 ...
- char、varchar、nchar、nvarchar四种类型
char,nchar是定长,如果没达到指定的长度时将自动以英文空格在其后面填充.优势在于速度较高.varchar,nvarchar属于变长,如果没有达到指定的长度时,不会将自动以英文空格在其后面填充. ...
- 简单的GCC语法: 弄清gcc test.c 与 gcc -c test.c 的差别
转载于:http://cache.baiducontent.com/c?m=9d78d513d99610fe4fede5690d60c067690597634dc0d06368d5e31587231b ...
- vm下centos7 mini版 NAT模式下配置静态IP
1.查看虚拟机的默认网关和子网掩码 a.vm菜单栏点击编辑->虚拟网络编辑器 b.选择VMnet8,点击NAT设置,查看子网掩码.网关IP 2. 修改服务器的网络配 ...
- 我的第一个Java博客
1.2019 11.23 Alone in Beijing;
- Educational Codeforces Round 68 (Rated for Div. 2)补题
A. Remove a Progression 签到题,易知删去的为奇数,剩下的是正偶数数列. #include<iostream> using namespace std; int T; ...
- PAT B1027 打印沙漏(20)
思路: 使用数组保存每一行沙漏的最大符号数 输入一个正整数和一个符号 遍历数组,找到大于正整数的数组下标 j. 三角形底边的字符数为 (j - 1) * 2 - 1 打印沙漏 打印剩余字符:x - n ...