分布式 ES 操作流程解析
概念解析
CURD 操作
CURD 操作都是针对具体的某个或某些文档的操作,每个文档的 routing 都是确认的,所以其所在分片也是可以事先确定的。该过程对应 ES 的 Document API。
- 新建(C): 指对某个文档进行索引操作的过程。
- 检索(R): 指从 ES 中获取某个或多个特定文档的过程。
- 删除(D): 指从 ES 中删除某个文档让其不再可被搜索。
- 更新(U): 指在 ES 中更新某个文档的过程,其实质是删除+新建的过程。
搜索
搜索操作是指通过查询条件从 ES 中获取匹配的文档的过程,搜索前不知道哪个文档会匹配查询。该过程对应 ES 的 Search API。
路由和分片
分片
- 文档在索引的时候,需要确定文档存放到哪个分片上去。(通过把 _id 作为 routing 来计算 shard)
- 文档在检索的时候,需要确定文档处在具体哪个分片上。(通过把 _id 作为 routing 来计算 shard)
路由
分片的确定,都是由路由来完成的,具体计算公式如下:
shard = hash(routing) % number_of_primary_shards
- routing 值是一个任意字符串,它默认是 _id 但也可以自定义。
- routing 字符串通过哈希函数生成一个数字,然后除以主切片的数量得到一个余数(remainder),余数的范围永远是 0 到 number_of_primary_shards - 1 ,这个数字就是特定文档所
在的分片。 - 这也解释了为什么主分片的数量只能在创建索引时定义且不能修改:如果主分片的数量在未来改变了,所有先前的路由值就失效了,文档也就永远找不到了。
文档的新建、索引和删除
流程
新建、索引和删除请求都是写(write)操作,它们必须在主分片上成功完成才能复制到相关的复制分片上。并且要等所有复制分片完成后才向请求节点返回。

在主分片和复制分片上成功新建、索引或删除一个文档必要的顺序步骤:
- 1. 客户端给 Node 1 发送新建、索引或删除请求,Node 1 作为协调节点。
- 2. 协调节点使用文档的 _id 确定文档属于分片 0 (通过把 _id 作为 routing 来计算 shard)。它转发请求到 Node 3 (主分片位于这个节点上)。
- 3. Node 3 在主分片上执行请求,如果成功,它转发请求到相应的位于 Node 1 和 Node 2 的复制节点上。当所有的复制节点报告成功, Node 3 报告成功给协调节点。
- 4. 协调节点返回结果给客户端。
客户端接收到成功响应的时候,文档的修改已经被应用于主分片和所有的复制分片。
由于要主分片和复制分片都成功后才返回成功,所以写操作是比较耗时的。
优化
replication:
replication 默认为 sync。也就是要等所有复制分片都操作完后才返回。
设置为 async 运行在主分片操作完成后即返回。
文档的检索
流程
检索文档为读(read)操作,请求只需分片的任意一个副本返回操作结果即完成。
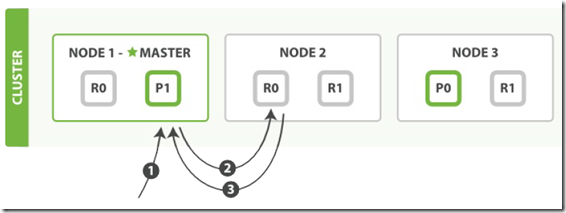
在主分片或复制分片上检索一个文档必要的顺序步骤:
- 1. 客户端给 Node1(主节点) 发送 get 请求,Node 1 作为协调节点。
- 2. 协调节点使用文档的 _id 确定文档属于分片 0(通过把 _id 作为 routing 来计算 shard) 。分片 0 对应的复制分片在三个节点上都有。此时,它转发请求到 Node 2 。
- 3. Node 2 返回执行结果给协调节点。
- 4. 协调节点返回结果给客户端。
对于读请求,为了平衡负载,协调节点会为每个分片的请求选择不同的副本——它会循环所有分片副本。
文档的更新
流程
更新过程整体流程就是 “读” + “写” 操作。
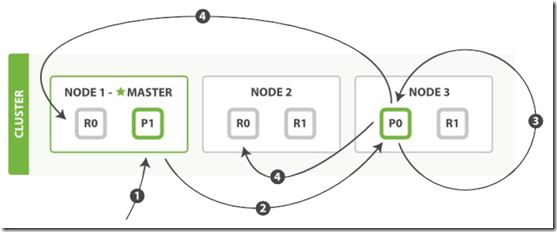
执行更新必要的顺序步骤:
- 1. 客户端给 Node 1 发送更新请求,Node 1 作为协调节点。
- 2. 协调节点转发请求到主分片所在节点 Node 3(主分片) 。
- 3. Node 3 从主分片检索出文档,修改 _source 字段的JSON,然后在主分片上重新索引。如果有其他进程修改了文档,它以 retry_on_conflict 设置的次数重复步骤3,都未成功则放弃。
- 4. 如果 Node 3 成功更新文档,它同时转发文档的新版本到 Node 1 和 Node 2 上的复制分片以重新索引。当所有节点报告成功, Node 3 返回成功给协调节点。
- 5. 协调节点返回结果给客户端。
批量文档操作
批量检索(mget)和批量新建、索引、更新、删除(bulk)操作和单个文档的操作过程类似。
区别在于协调节点知道所有文档所在的分片,并将请求的文档根据所在的分片来分组。然后同时请求需要的节点。
一旦收到所有节点的响应,协调节点再将这多个节点的响应组合成一个响应结果返回给客户端。
流程
mget 操作
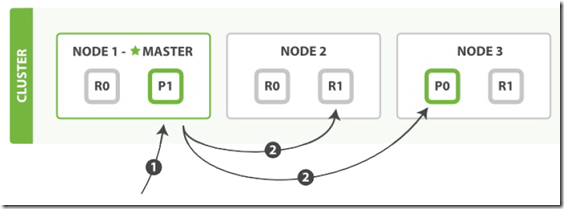
mget 操作过程基本步骤:
- 1. 客户端发送请求到 Node 1,Node 1 作为协调节点。
- 2. 协调节点确认每一个操作请求的目标分片,并根据需要请求的目标分片重新分组。
- 2. 协调节点同时转发每组请求到目标主分片或复制分片(检索操作任意分片都可以)。
- 3. 一旦所有请求的分片都返回,协调节点整理结果,并返回给客户端。
bulk操作

bulk 操作过程基本步骤:
- 1. 客户端发送请求到 Node 1,Node 1 作为协调节点。
- 2. 协调节点确认每一个操作请求的目标主分片,并根据目标主分片重新分组。
- 2. 协调节点同时请求包含这些主分片的节点(步骤2)。
- 3. 每一个主分片一个接一个的处理每一个文档请求——某个文档在主分片上请求成功了,主分片将请求发送给它所有的复制分片,然后就接着处理下一个文档请求。
- 4. 当所有的复制分片请求成功后,主分片所在节点就向协调节点报告成功。
- 5. 协调节点整理所有文档的结果,并返回给客户端。
搜索
文档的 CRUD 操作一次只处理一个单独的文档(批量操作也是单个执行)。CRUD 操作中,文档的唯一性由 _index , _type 和 routing (通常默认是该文档的 _id )的组合来确定。这意味着我们可以准确知道集群中的哪个分片有这个文档。
搜索过程,由于不知道哪个文档会匹配查询(文档可能存放在集群中的任意分片上),所以搜索需要一个更复杂的模型。搜索通过查询每一个我们感兴趣的索引的分片副本,来看是否含有任何匹配的文档。
搜索的执行过程分两个阶段,称为查询然后取回(query then fetch)。
查询阶段
GET /_search
{ "from": 90,
"size": 10
}
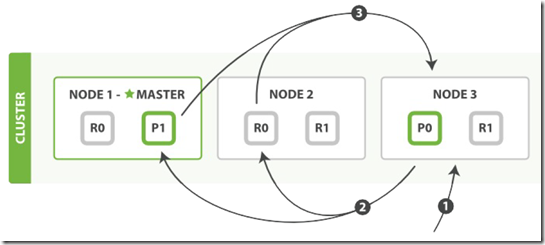
1. 客户端发送一个 search(搜索) 请求给 Node 3 , Node 3 创建了一个长度为 from+size 的空优先级队列。
2. Node 3 转发这个搜索请求到索引中每个分片的原本或副本。搜索请求可以被每个分片的原本或任意副本处理。
(并非所有副本都处理同样的请求,而是轮询处理不同的请求,所以多副本能够提高吞吐)
3. 每个分片在本地执行这个查询并且结果将结果到一个大小为 from+size 的有序本地优先队列里去。
4. 每个分片返回document的ID和它优先队列里的所有document的排序值给协调节点 Node 3 。 Node 3 把这些值合并到自己的优先队列里产生全局排序结果。
5. 对于多(multiple)或全部(all)索引的搜索的工作机制和这完全一致——仅仅是多了一些分片而已。
取回阶段
查询阶段辨别出那些满足搜索请求的document,但我们仍然需要取回那些document本身。这就是取回阶段的工作。

1. 协调节点(请求节点)辨别出哪个document需要取回(比如只取前100项),并且向相关分片发出 GET 请求。
2. 每个分片加载document并且根据需要丰富(enrich)它们,然后再将document返回协调节点。
3. 一旦所有的document都被取回,协调节点会将结果返回给客户端。
搜索选项
1. preference:
preference 参数允许你控制使用哪个分片或节点来处理搜索请求。她接受如下一些参数 _primary , _primary_first ,_local , _only_node:xyz , _prefer_node:xyz 和 _shards:2,3
2. timeout:
通常,协调节点会等待接收所有分片的回答。如果有一个节点遇到问题,它会拖慢整个搜索请求。timeout 参数告诉协调节点最多等待多久,就可以放弃等待而将已有结果返回。
3. routing:
指定一个或多个 routing 值来限制只搜索那些分片而不是搜索index里的全部分片。
4. search_type:
- count(计数):当不需要搜索结果只需要知道满足查询的document的数量时,可以使用这个查询类型。
- query_and_fetch:搜索类型将查询和取回阶段合并成一个步骤
- dfs_query_then_fetch 和 dfs_query_and_fetch
- scan:scan(扫描) 搜索类型是和 scroll(滚屏) API连在一起使用的,可以高效地取回巨大数量的结果。它是通过禁用排序来实现的。
分布式 ES 操作流程解析的更多相关文章
- CQRS+ES项目解析-Equinox
今天我们来分析另一个开源的CQRS+ES项目:Equinox.该项目可以在github上下载并直接本地运行,项目地址:https://github.com/EduardoPires/EquinoxPr ...
- 分布式架构原理解析,Java开发必修课
1. 分布式术语 1.1. 异常 服务器宕机 内存错误.服务器停电等都会导致服务器宕机,此时节点无法正常工作,称为不可用. 服务器宕机会导致节点失去所有内存信息,因此需要将内存信息保存到持久化介质上. ...
- tcc分布式事务框架解析
前言碎语 楼主之前推荐过2pc的分布式事务框架LCN.今天来详细聊聊TCC事务协议. 2pc实现:https://github.com/codingapi/tx-lcn tcc实现:https://g ...
- CQRS+ES项目解析-Diary.CQRS
在<当我们在讨论CQRS时,我们在讨论些神马>中,我们讨论了当使用CQRS的过程中,需要关心的一些问题.其中与CQRS关联最为紧密的模式莫过于Event Sourcing了,CQRS与ES ...
- LCN解决分布式事务原理解析+项目实战(原创精华版)
写在前面: 原创不易,如果觉得不错推荐一下,谢谢! 由于工作需要,公司的微服务项目需解决分布式事务的问题,且由我进行分布式事务框架搭建和整合工作. 那么借此机会好好的将解决分布式事务的内容进行整理一下 ...
- MQ关于实现最终一致性分布式事务原理解析
本文讲述阿里云官方文档中关于通过MQ实现分布式事务最终一致性原理 概念介绍 事务消息:消息队列 MQ 提供类似 X/Open XA 的分布式事务功能,通过消息队列 MQ 事务消息能达到分布式事务的最终 ...
- #研发解决方案介绍#基于ES的搜索+筛选+排序解决方案
郑昀 基于胡耀华和王超的设计文档 最后更新于2014/12/3 关键词:ElasticSearch.Lucene.solr.搜索.facet.高可用.可伸缩.mongodb.SearchHub.商品中 ...
- OpenGL ES着色器语言之着色概览(官方文档)
OpenGL ES着色器语言之着色概览(官方文档第二章) 事实上,OpenGL ES着色语言是两种紧密关联的语言.这些语言用来在OpenGL ES处理管线的可编程处理器创建着色器. 在本文档中,除非另 ...
- 【ELK】4.spring boot 2.X集成ES spring-data-ES 进行CRUD操作 完整版+kibana管理ES的index操作
spring boot 2.X集成ES 进行CRUD操作 完整版 内容包括: ============================================================ ...
随机推荐
- 5.2 CUDA Histogram直方图
什么是Histogramming Histogramming是一种从大的数据集中提取典型特征和模式的方式. 在统计学中,直方图(英语:Histogram)是一种对数据分布情况的图形表示,是一种二维统计 ...
- Redhat常见问题
1.现象:hadoop用户启动startx时失败,报如下提示 Fatal server error: PAM authentication failed, cannot start X server. ...
- 【安全】requests和BeautifulSoup小试牛刀
web安全的题,为了找key随手写的程序,无处安放,姑且贴上来. # -*- coding: UTF-8 -*- __author__ = 'weimw' import requests from B ...
- leetcode@ [241] Different Ways to Add Parentheses (Divide and Conquer)
https://leetcode.com/problems/different-ways-to-add-parentheses/ Given a string of numbers and opera ...
- Spark的部署方式
1.Spark的应用程序部署 2.Spark的集群部署
- adb pull命令复制android数据库文件.db到电脑
1.win+r cmd进入命令行 2.cd 进入[sdk]/platform-tools目录下 3.执行下面命令行,复制xxx.db到F:/dest adb pull /data/data/[pack ...
- python 使用@property
在绑定属性时,如果我们直接把属性暴露出去,虽然写起来很简单,但是,没办法检查参数,导致可以把成绩随便改: s = Student() s.score = 9999 这显然不合逻辑.为了限制score的 ...
- void类型及void指针
1.概述 许多初学者对C/C 语言中的void及void指针类型不甚理解,因此在使用上出现了一些错误.本文将对void关键字的深刻含义进行解说,并 详述void及void指针类型的使用方法与技巧. 2 ...
- hdu 5533 Dancing Stars on Me
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5533 Dancing Stars on Me Time Limit: 2000/1000 MS (Ja ...
- nginx编译参数集合
http://www.ttlsa.com/nginx/nginx-configure-descriptions/ 标题是不是很欠揍,个人认为确实值得一看,如果你不了解nginx,或者你刚学nginx, ...