Java 源码刨析 - HashMap 底层实现原理是什么?JDK8 做了哪些优化?
【基本结构】
在 JDK 1.7 中 HashMap 是以数组加链表的形式组成的;
JDK 1.8 之后新增了红黑树的组成结构,当链表大于 8 并且容量大于 64 时,链表结构会转换成红黑树结构,它的组成结构如下图所示:
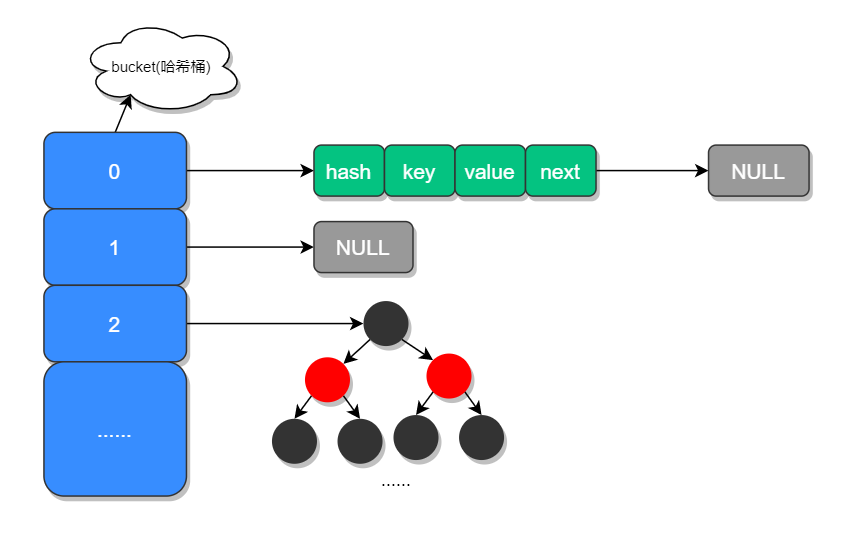
数组中的元素我们称之为哈希桶,它的定义如下:
|
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) { this.hash = hash; this.key = key; this.value = value; this.next = next; } public final K getKey() { return key; } public final V getValue() { return value; } public final String toString() { return key + "=" + value; } public final int hashCode() { return Objects.hashCode(key) ^ Objects.hashCode(value); } public final V setValue(V newValue) { V oldValue = value; value = newValue; return oldValue; } public final boolean equals(Object o) { if (o == this) return true; if (o instanceof Map.Entry) { Map.Entry<?,?> e = (Map.Entry<?,?>)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true; } return false; } } |
可以看出每个哈希桶中包含了四个字段:hash、key、value、next,其中 next 表示链表的下一个节点。
JDK 1.8 之所以添加红黑树是因为一旦链表过长,会严重影响 HashMap 的性能,而红黑树具有快速增删改查的特点,这样就可以有效的解决链表过长时操作比较慢的问题。
【HashMap 源码分析】
HashMap 源码中包含了以下几个属性:
|
// HashMap 初始化长度 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 // HashMap 最大长度 static final int MAXIMUM_CAPACITY = 1 << 30; // 1073741824 // 默认的加载因子 (扩容因子) static final float DEFAULT_LOAD_FACTOR = 0.75f; // 当链表长度大于此值且容量大于 64 时 static final int TREEIFY_THRESHOLD = 8; // 转换链表的临界值,当元素小于此值时,会将红黑树结构转换成链表结构 static final int UNTREEIFY_THRESHOLD = 6; // 最小树容量 static final int MIN_TREEIFY_CAPACITY = |
【什么是加载因子?加载因子为什么是 0.75?】
加载因子也叫扩容因子或负载因子,用来判断什么时候进行扩容的,假如加载因子是 0.5,HashMap 的初始化容量是 16,那么当 HashMap 中有 16*0.5=8 个元素时,HashMap 就会进行扩容。
那加载因子为什么是 0.75 而不是 0.5 或者 1.0 呢?
这其实是出于容量和性能之间平衡的结果:
当加载因子设置比较大的时候,扩容的门槛就被提高了,扩容发生的频率比较低,占用的空间会比较小,但此时发生 Hash 冲突的几率就会提升,因此需要更复杂的数据结构来存储元素,这样对元素的操作时间就会增加,运行效率也会因此降低;
而当加载因子值比较小的时候,扩容的门槛会比较低,因此会占用更多的空间,此时元素的存储就比较稀疏,发生哈希冲突的可能性就比较小,因此操作性能会比较高。
所以综合了以上情况就取了一个 0.5 到 1.0 的平均数 0.75 作为加载因子。
【查询源码】
|
public V get(Object key) { Node<K,V> e; // 对 key 进行哈希操作 return (e = getNode(hash(key), key)) == null ? null : e.value; } final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; // 非空判断 if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { // 判断第一个元素是否是要查询的元素 if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; // 下一个节点非空判断 if ((e = first.next) != null) { // 如果第一节点是树结构,则使用 getTreeNode 直接获取相应的数据 if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); do { // 非树结构,循环节点判断 // hash 相等并且 key 相同,则返回此节点 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; } |
从以上源码可以看出,当哈希冲突时我们需要通过判断 key 值是否相等,才能确认此元素是不是我们想要的元素。
【新增源码】
|
public V put(K key, V value) { // 对 key 进行哈希操作 return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; // 哈希表为空则创建表 if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // 根据 key 的哈希值计算出要插入的数组索引 i if ((p = tab[i = (n - 1) & hash]) == null) // 如果 table[i] 等于 null,则直接插入 tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; // 如果 key 已经存在了,直接覆盖 value if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; // 如果 key 不存在,判断是否为红黑树 else if (p instanceof TreeNode) // 红黑树直接插入键值对 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { // 为链表结构,循环准备插入 for (int binCount = 0; ; ++binCount) { // 下一个元素为空时 if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); // 转换为红黑树进行处理 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } // key 已经存在直接覆盖 value if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; // 超过最大容量,扩容 if (++size > threshold) resize(); afterNodeInsertion(evict); return null; } |
新增方法的执行流程,如下图所示:
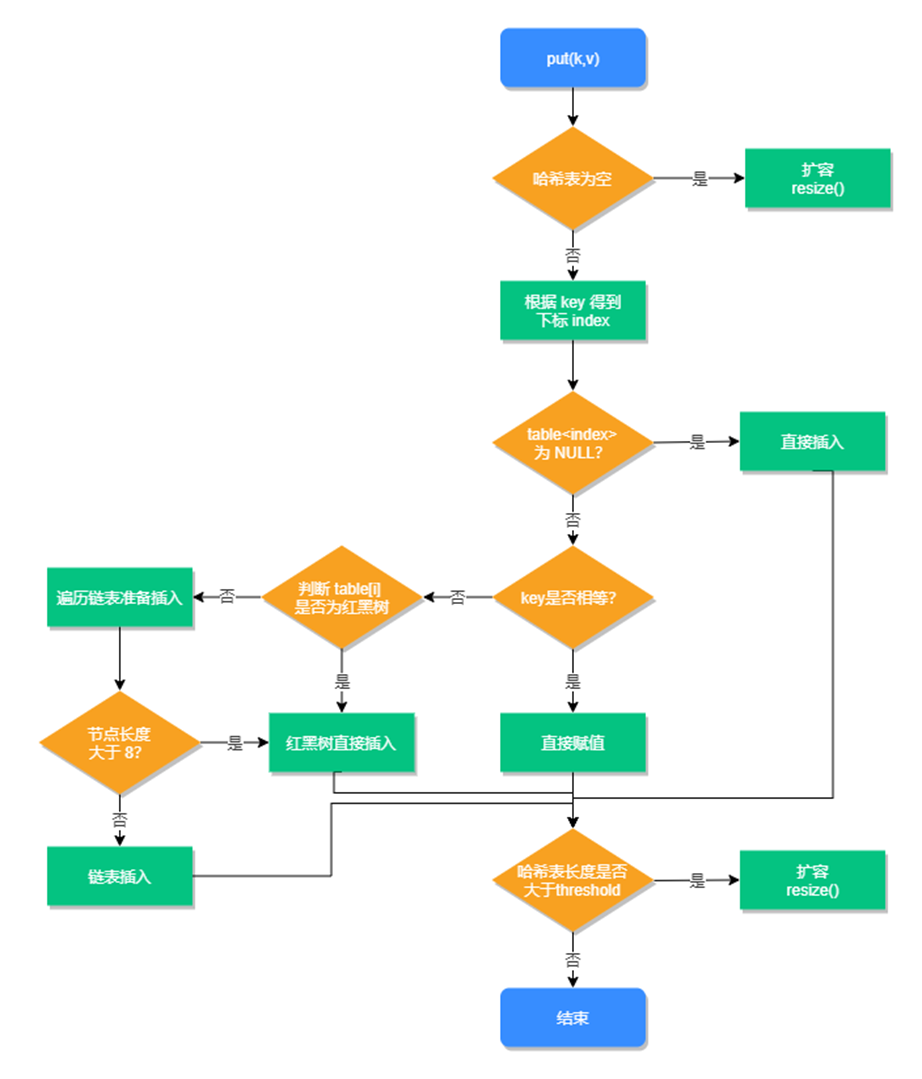
【扩容源码】
|
final Node<K,V>[] resize() { // 扩容前的数组 Node<K,V>[] oldTab = table; // 扩容前的数组的大小和阈值 int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; // 预定义新数组的大小和阈值 int newCap, newThr = 0; if (oldCap > 0) { // 超过最大值就不再扩容了 if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } // 扩大容量为当前容量的两倍,但不能超过 MAXIMUM_CAPACITY else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } // 当前数组没有数据,使用初始化的值 else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { // zero initial threshold signifies using defaults // 如果初始化的值为 0,则使用默认的初始化容量 newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } // 如果新的容量等于 0 if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; // 开始扩容,将新的容量赋值给 table table = newTab; // 原数据不为空,将原数据复制到新 table 中 if (oldTab != null) { // 根据容量循环数组,复制非空元素到新 table for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; // 如果链表只有一个,则进行直接赋值 if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) // 红黑树相关的操作 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order // 链表复制,JDK 1.8 扩容优化部分 Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; // 原索引 if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } // 原索引 + oldCap else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); // 将原索引放到哈希桶中 if (loTail != null) { loTail.next = null; newTab[j] = loHead; } // 将原索引 + oldCap 放到哈希桶中 if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; } |
从以上源码可以看出,JDK 1.8 在扩容时并没有像 JDK 1.7 那样,重新计算每个元素的哈希值,而是通过高位运算(e.hash & oldCap)来确定元素是否需要移动,比如 key1 的信息如下:
key1.hash = 10 0000 1010
oldCap = 16 0001 0000
使用 e.hash & oldCap 得到的结果,高一位为 0,当结果为 0 时表示元素在扩容时位置不会发生任何变化,而 key 2 信息如下:
key2.hash = 10 0001 0001
oldCap = 16 0001 0000
这时候得到的结果,高一位为 1,当结果为 1 时,表示元素在扩容时位置发生了变化,新的下标位置等于原下标位置 + 原数组长度,如下图所示:
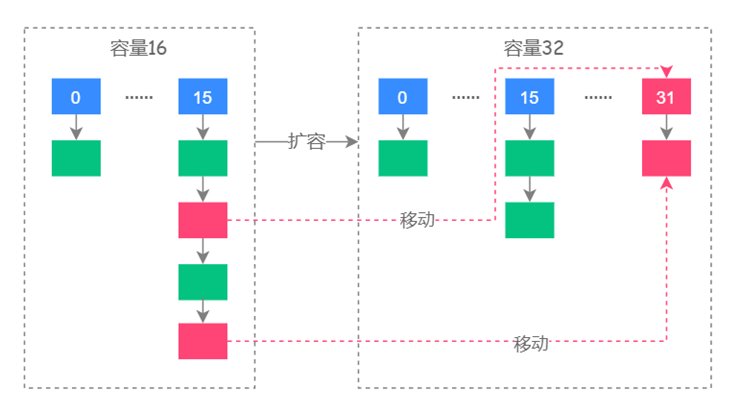
其中红色的虚线图代表了扩容时元素移动的位置。
【HashMap 死循环分析】
以 JDK 1.7 为例,假设 HashMap 默认大小为 2,原本 HashMap 中有一个元素 key(5);
我们再使用两个线程:t1 添加元素 key(3),t2 添加元素 key(7);
当元素 key(3) 和 key(7) 都添加到 HashMap 中之后,线程 t1 在执行到 Entry<K,V> next = e.next; 时,交出了 CPU 的使用权,源码如下:
|
void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry<K,V> e : table) { while(null != e) { Entry<K,V> next = e.next; // 线程一执行此处 if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } } } |
那么此时线程 t1 中的 e 指向了 key(3),而 next 指向了 key(7) ;之后线程 t2 重新 rehash 之后链表的顺序被反转,链表的位置变成了 key(5) → key(7) → key(3),其中 "→" 用来表示下一个元素。
当 t1 重新获得执行权之后,先执行 newTalbe[i] = e 把 key(3) 的 next 设置为 key(7),而下次循环时查询到 key(7) 的 next 元素为 key(3),于是就形成了 key(3) 和 key(7) 的循环引用,因此就导致了死循环的发生,如下图所示:

当然发生死循环的原因是 JDK 1.7 链表插入方式为首部倒序插入,这个问题在 JDK 1.8 得到了改善,变成了尾部正序插入。
有人曾经把这个问题反馈给了 Sun 公司,但 Sun 公司认为这不是一个问题,因为 HashMap 本身就是非线程安全的,如果要在多线程下,建议使用 ConcurrentHashMap 替代,但这个问题在面试中被问到的几率依然很大,所以在这里需要特别说明一下。
from:Java 源码剖析(https://kaiwu.lagou.com/course/courseInfo.htm?courseId=59#/detail/pc?id=1761)
Java 源码刨析 - HashMap 底层实现原理是什么?JDK8 做了哪些优化?的更多相关文章
- Java 源码刨析 - String
[String 是如何实现的?它有哪些重要的方法?] String 内部实际存储结构为 char 数组,源码如下: public final class String implements java. ...
- Java 源码刨析 - 线程的状态有哪些?它是如何工作的?
线程(Thread)是并发编程的基础,也是程序执行的最小单元,它依托进程而存在. 一个进程中可以包含多个线程,多线程可以共享一块内存空间和一组系统资源,因此线程之间的切换更加节省资源.更加轻量化,也因 ...
- Java源码系列2——HashMap
HashMap 的源码很多也很复杂,本文只是摘取简单常用的部分代码进行分析.能力有限,欢迎指正. HASH 值的计算 前置知识--位运算 按位异或操作符^:1^1=0, 0^0=0, 1^0=0, 值 ...
- 30s源码刨析系列之函数篇
前言 由浅入深.逐个击破 30SecondsOfCode 中函数系列所有源码片段,带你领略源码之美. 本系列是对名库 30SecondsOfCode 的深入刨析. 本篇是其中的函数篇,可以在极短的时间 ...
- Java源码解读(一)——HashMap
HashMap作为常用的一种数据结构,阅读源码去了解其底层的实现是十分有必要的.在这里也分享自己阅读源码遇到的困难以及自己的思考. HashMap的源码介绍已经有许许多多的博客,这里只记录了一些我看源 ...
- 【java集合框架源码剖析系列】java源码剖析之HashMap
前言:之所以打算写java集合框架源码剖析系列博客是因为自己反思了一下阿里内推一面的失败(估计没过,因为写此博客已距阿里巴巴一面一个星期),当时面试完之后感觉自己回答的挺好的,而且据面试官最后说的这几 ...
- Java面试必问之Hashmap底层实现原理(JDK1.7)
1. 前言 Hashmap可以说是Java面试必问的,一般的面试题会问: Hashmap有哪些特性? Hashmap底层实现原理(get\put\resize) Hashmap怎么解决hash冲突? ...
- HashMap源码刨析(面试必看)
目录 1.Hash的计算规则? 2.HashMap是怎么形成环形链表的(即为什么不是线程安全)?(1.7中的问题) 3.JDK1.7和1.8的HashMap不同点? 4.HashMap和HashTab ...
- MapReduce源码刨析
MapReduce编程刨析: Map map函数是对一些独立元素组成的概念列表(如单词计数中每行数据形成的列表)的每一个元素进行指定的操作(如把每行数据拆分成不同单词,并把每个单词计数为1),用户可以 ...
随机推荐
- 聊聊UDP、TCP和实现一个简单的JAVA UDP小Demo
最近真的比较忙,很久就想写了,可是一直苦于写点什么,今天脑袋灵光一闪,觉得自己再UDP方面还有些不了解的地方,所以要给自己扫盲. 好了,咱们进入今天的主题,先列一下提纲: 1. UDP是什么,UDP适 ...
- 转 vue过滤器使用
简单介绍一下过滤器,顾名思义,过滤就是一个数据经过了这个过滤之后出来另一样东西,可以是从中取得你想要的,或者给那个数据添加点什么装饰,那么过滤器则是过滤的工具.例如,从['abc','abd','ad ...
- PHP cookie基本操作
PHP中Cookie的使用---添加/更新/删除/获取Cookie 及 自动填写该用户的用户名和密码和判断是否第一次登陆 什么是cookie 服务器在客户端保存用户的信息,比如登录名,密码等 这些数据 ...
- rocketmq初识
概念说明 通常一个消息队列需要掌握的知识点有Topic(主体).Producer(生产者).Consumer(消费者).Queue(队列).Delivery Semantics(消息传递范式) 蛋疼的 ...
- Matlab矩阵学习三 矩阵的运算
Matlab矩阵的运算 一.矩阵的加减 在matlab中,矩阵的加减和数的加减符号一样,都是"+"和”-“,不同的是两个进行运算的矩阵维度必须相同 二.数乘 三.乘法 矩阵乘法 ...
- .net remoting(一)
一.远程对象 ①RemoteHello.csproj 类库项目,程序集名称 RemoteHello ,默认命名空间 Wrox.ProCSharp.Remoting: ②派生自System.Marssh ...
- Rocket - interrupts - Parameters
https://mp.weixin.qq.com/s/eD1_hG0n8W2Wodk25N5KnA 简单介绍interrupts相关的Parameters. 1. IntRange 定义一个中断号区间 ...
- Java实现 LeetCode 787 K 站中转内最便宜的航班(两种DP)
787. K 站中转内最便宜的航班 有 n 个城市通过 m 个航班连接.每个航班都从城市 u 开始,以价格 w 抵达 v. 现在给定所有的城市和航班,以及出发城市 src 和目的地 dst,你的任务是 ...
- Java实现 LeetCode 643 子数组最大平均数 I(滑动窗口)
643. 子数组最大平均数 I 给定 n 个整数,找出平均数最大且长度为 k 的连续子数组,并输出该最大平均数. 示例 1: 输入: [1,12,-5,-6,50,3], k = 4 输出: 12.7 ...
- Java实现 蓝桥杯 算法训练 Torry的困惑(基本型)
算法训练 Torry的困惑(基本型) 时间限制:1.0s 内存限制:512.0MB 问题描述 Torry从小喜爱数学.一天,老师告诉他,像2.3.5.7--这样的数叫做质数.Torry突然想到一个问题 ...