Hive(二)—— 架构设计
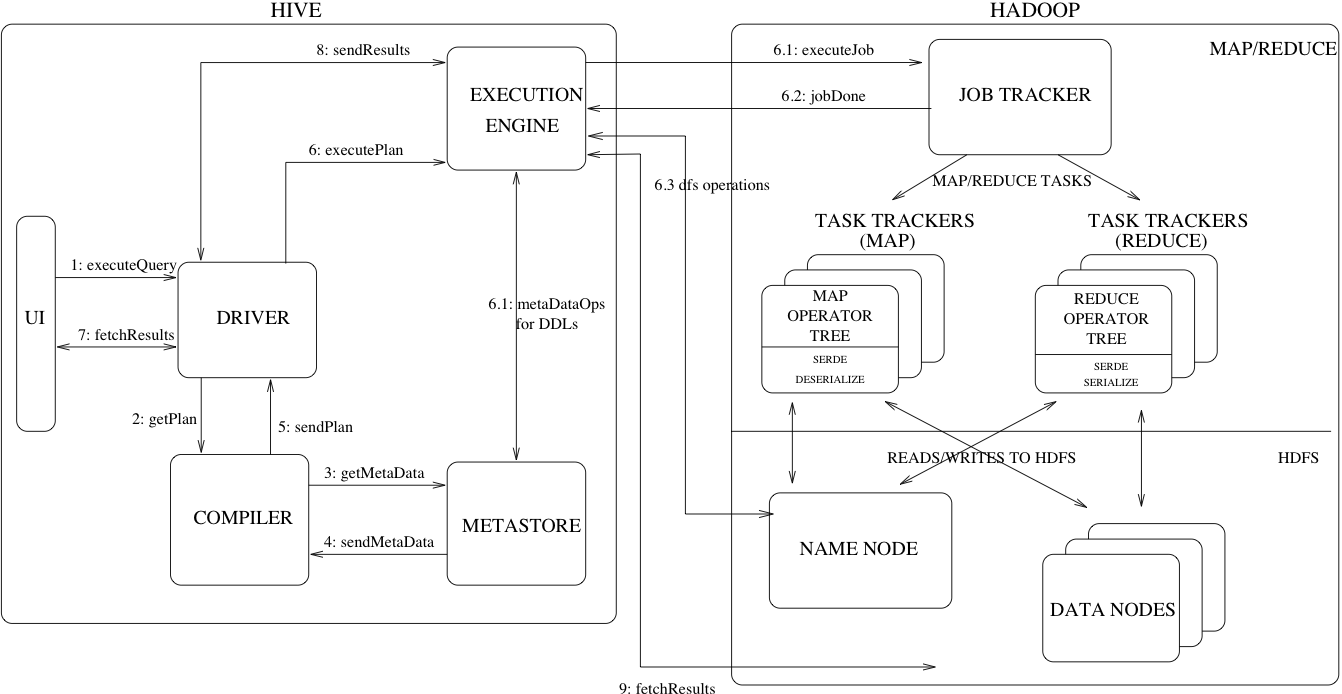
Hive架构
Figure 1 also shows how a typical query flows through the system.
图一显示一个普通的查询是如何流经Hive系统的。The UI calls the execute interface to the Driver (step 1 in Figure 1).
图中的第1步,UI向Driver调用执行接口The Driver creates a session handle for the query and sends the query to the compiler to generate an execution plan (step 2).
第2步,Driver为查询创建一个Session句柄,将查询发送到compiler编译器,生成一个执行计划(execution plan)。The compiler gets the necessary metadata from the metastore (steps 3 and 4).
第3-4步,编译器从metastore中获取必要的元数据信息。This metadata is used to typecheck the expressions in the query tree as well as to prune partitions based on query predicates.
元数据被用户对查询树中的表达式进行类型检查,以及基于查询谓词进行剪枝。The plan generated by the compiler (step 5) is a DAG of stages with each stage being either a map/reduce job, a metadata operation or an operation on HDFS.
第5步,编译器生成的计划是一个多个阶段的DAG,每个阶段都是一个MR任务,或者一个元数据操作、HDFS操作。For map/reduce stages, the plan contains map operator trees (operator trees that are executed on the mappers) and a reduce operator tree (for operations that need reducers). The execution engine submits these stages to appropriate components (steps 6, 6.1, 6.2 and 6.3).
对于MR阶段,这个计划包含map操作树和reduce操作树。这个执行引擎提交这些阶段到恰当的组件。In each task (mapper/reducer) the deserializer associated with the table or intermediate outputs is used to read the rows from HDFS files and these are passed through the associated operator tree. Once the output is generated, it is written to a temporary HDFS file though the serializer (this happens in the mapper in case the operation does not need a reduce).
The temporary files are used to provide data to subsequent map/reduce stages of the plan. For DML operations the final temporary file is moved to the table's location.
This scheme is used to ensure that dirty data is not read (file rename being an atomic operation in HDFS).
scheme被用来确保脏数据不会被读到。For queries, the contents of the temporary file are read by the execution engine directly from HDFS as part of the fetch call from the Driver (steps 7, 8 and 9).
Hive数据模型
Metastore
Hive Query Language
参考文档
Hive(二)—— 架构设计的更多相关文章
- 【HELLO WAKA】WAKA iOS客户端 之二 架构设计与实现篇
上一篇主要做了MAKA APP的需求分析,功能结构分解,架构分析,API分析,API数据结构分析. 这篇主要讲如何从零做iOS应用架构. 全系列 [HELLO WAKA]WAKA iOS客户端 之一 ...
- jquery源码分析(二)——架构设计
要学习一个库首先的理清它整体架构: 1.jQuery源码大致架构如下:(基于 jQuery 1.11 版本,共计8829行源码)(21,94) 定义了一些变量和函数jQu ...
- 苏宁OLAP架构设计
一. 功能综述 OLAP引擎为存储和计算二合一的引擎,自身内部涵盖了对数据的管理以及提供查询能力.底层数据完全规划在引擎内部,外部系统不允许直接操作底层数据,而是需要通过暴露出来的接口来读写引擎内部数 ...
- hive介绍及架构设计
hive介绍及架构设计 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 我们知道MapReduce和Spark它们提供了高度抽象的编程接口便于用户编写分布式程序,它们具有极好的扩展性 ...
- [原创].NET 分布式架构开发实战之二 草稿设计
原文:[原创].NET 分布式架构开发实战之二 草稿设计 .NET 分布式架构开发实战之二 草稿设计 前言:本篇之所以称为草稿设计,是因为设计的都是在纸上完成的.反映了一个思考的过程. 本篇的议题如下 ...
- Redis缓存项目应用架构设计二
一.概述 由于架构设计一里面如果多平台公用相同Key的缓存更改配置后需要多平台上传最新的缓存配置文件来更新,比较麻烦,更新了架构设计二实现了缓存配置的集中管理,不过这样有有了过于中心化的问题,后续在看 ...
- Nginx详解二十九:基于Nginx的中间件架构设计
基于Nginx的中间件架构 一:了解需求 1.定义Nginx在服务体系中的角色 1.静态资源服务 2.代理服务 3.动静分离 2.静态资源服务的功能设计 3.代理服务 二:设计评估 三:配置注意事项
- MySql(十二):MySql架构设计——可扩展设计的基本原则
一.前言 科技在发展,硬件设备的发展渐渐无法满足应用系统对处理能力的要求.不过,我们还是可以通过改造系统的架构体系,提升系统的扩展能力,通过组合多个低处理能力的硬件设备来达到一个高处理能力的系统,也就 ...
- APP和服务端-架构设计(二)
1. App架构设计经验谈:接口的设计 App与服务器的通信接口如何设计得好,需要考虑的地方挺多的,在此根据我的一些经验做一些总结分享,旨在抛砖引玉. 1.1 安全机制的设计 现在,大部分App的接口 ...
- Unity《ATD》塔防RPG类3D游戏架构设计(二)
目录 <ATD> 游戏模型 <ATD> 游戏逻辑 <ATD> UI/HUD/特效/音乐 结语 前篇:Unity<ATD>塔防RPG类3D游戏架构设计(一 ...
随机推荐
- Maven - 工作原理
章节 Maven – 简介 Maven – 工作原理 Maven – Repository(存储库) Maven – pom.xml 文件 Maven – 依赖管理 Maven – 构建生命周期.阶段 ...
- CF1217A Creating a Character
You play your favourite game yet another time. You chose the character you didn't play before. It ha ...
- 201771010123汪慧和《面向对象程序设计Java》第十四周实验总结
一.理论部分 1.Swing和MVC设计模式 (1)设计模式初识 (2)模式—试图—控制器模式 (3)Swing组件的模型—试图—控制器分析 2.Java组件有内容.外观.行为三个主要元素:这三个主要 ...
- windows FTP上传
TCHAR tcFileName[MAX_PATH * 4] = {L"visio2010永久安装密钥.txt"}; TCHAR tcName[MAX_PATH * 4] = {0 ...
- bash cheat
############################################################################### BASH CHEATSHEET (中文速 ...
- UVA 11732 链表+字典树
因为字符集比较大,所以就不能用简单字典树,在字典树里面,用链表进行存储.这个倒是不难,练了下手 统计的时候还是有点难搞,因为要算所有的两两比较的次数之和,对分叉处进行计算,注意细节 #include ...
- 18个Java8日期处理的实践,太有用了
专注于Java领域优质技术,欢迎关注 作者:胖先森 Java 8 推出了全新的日期时间API,在教程中我们将通过一些简单的实例来学习如何使用新API. Java处理日期.日历和时间的方式一直为社区所诟 ...
- PAT 2011 秋
A : World Cup Betting #include <cstdio> #include <iostream> #include <algorithm> u ...
- cafe-ssd數據集訓練
训练方式::https://blog.csdn.net/xiao_lxl/article/details/79106837 caffe-ssd训练自己的数据集 https://blog.csdn.ne ...
- java日志处理汇总
org.apache.commons.lang3.time.DateUtils https://blog.csdn.net/yihaoawang/article/details/50638199