阿里云高级技术专家空见: CDN的数据化之路
想要实现优质高速的互联网视频服务,一定离不开高质量的内容分发网络服务,就是我们常说的CDN,在10月13日云栖大会视频多媒体分论坛上,阿里云高级技术专家空见为大家讲解了CDN服务过程中,数据处理、安全监测、日志分析、智能分析是如何为CDN赋能的。下面是演讲主要内容提炼:
一、业务背景
目前阿里云CDN的节点的数量超过1200个,可承载的带宽能力超过80Tbps,基本能覆盖国内一半的分发要求,海外的部署也是十分广泛的。在产品方面,CDN包括PCDN、安全加速、全站加速等各种子产品,因为分析的场景不同,所以对数据平台的扩展性也提出了更高的要求。从业务规模来看,阿里云CDN现在线上跑着百万级的域名,每个域名的分析都要做,比传统CDN高了两个量级。如此庞大的业务,对于用户内容的分发是好事情,对数据的回收和分析,却是一个不小的挑战。

二、数据需求
CDN的数据有三个关键字:海量、可靠、实时。
海量,CDN目前每秒钟有大几千万的数据访问,每天会沉淀出来5PB的系统日志,所以离线数据通常在EB级别,这个对实时计算和离线分析都有很大的压力;在监控这块阿里云CDN每天达到千亿级别,而且每年CDN数据增长都在100%之上,所以系统必须要有很强的扩展性,并提前设计好各个环节。
可靠,CDN的数据一定要是准确的,不能有毛刺的数据。因为数据的应用场景是很苛刻的,比如计费和监控,不能出现纰漏,不能漏报误报。数据出来后,阿里云CDN还要在全球范围内调度流量,一丝一毫的不准确都可能导致很严重的后果,所以对于数据的准确性要求很高。第二是系统本身的稳定,系统各个环境不能有明显的瓶颈,系统要有足够强的容灾能力,系统的自动恢复方案也要是充分的。
实时,在从前,阿里云CDN是五分钟分析一次数据,不管是计量还是计费,都以这个为标准。现在,因为有了更多的业务场景,以直播为例,如果一个主播推流断掉了,不能马上发现的话,影响的可能就是几十、上百万的用户的观看体验。所以,在实时性上,阿里云CDN现在能做到分钟以及秒级的实时,也就是说,在整个数据的要求上来看,不仅吞吐量要大,延迟也要足够低。

如此大规模的数据,如此严苛的要求,阿里云CDN又如何应对呢?
三、数据收集
下面我们看看阿里云CDN在数据收集方面是怎么做的。现在整个系统数据量化的程度还是比较高的,不光是用户的访问数据,系统的操作数据也是可以量化的。下面是数据收集全貌图:
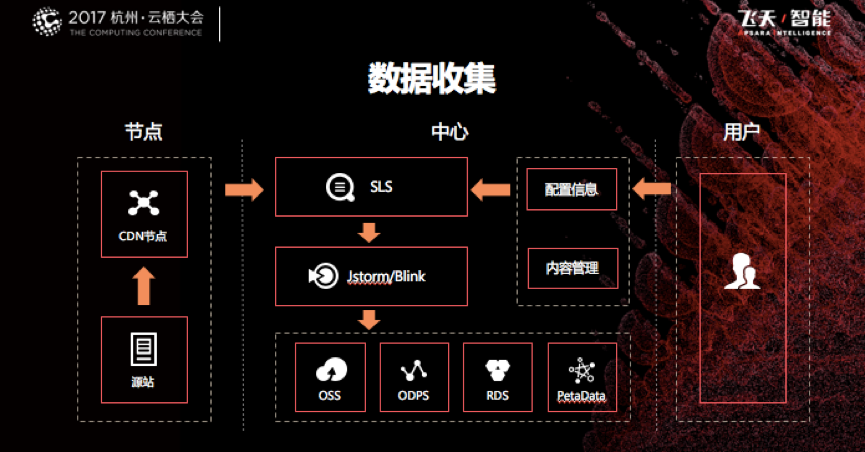
数据来源,有两个方面,一个是左边的节点,另一个是右边的用户。
先从从左边的边缘节点来看,它是从全球的边缘节点去采集和处理,上面的数据大部分都是访问、回源的日志,节点之间互相探测的日志等,在总数据中占比80%以上。这里的数据量级非常大,而且本身CDN就是分布式系统,所以阿里云CDN将一部分数据分析工作在节点上就先完成了,比如通用的流量、命中率、QPS等指标,会在节点上做预处理,同时,全量的数据也会通过流式传输往数据中心去走。
右面是用户数据,通过浏览器或SDK来访问我们内容的用户,还包括系统上的用户,包括管理员管理配置、业务人员在后台对线上资源进行调配等,一般这里的数据直接通过流式传输平台SLS客户端直接发出。
在中心传输这一层,阿里云CDN采用阿里云本身的SLS产品,SLS支持对数据进行抽取、转化、分发、检索等功能,本身比较灵活,满足了ETL的场景,并且可以在上面做一些客户定制化的处理。SLS下来后,再用Blink对数据进行流式处理,它有一个好处就是中间状态可以保存,不需要应用和外部的第三方存储再做交互,能够满足数据定制化分析的一些场景。原始的访问及分析后的业务数据,最终会沉淀存储在ODPS中。用户也可以选择其他存储方式,比如可以提供文件下载功能的对象存储OSS。另外,时序数据也会存在OTS数据库中,以备实时检索。
以上的数据收集,基本上都是采用阿里云的产品,阿里云CDN的技术专家们只需要把系统串联起来,保证整体可用性即可,如此,就能将更多精力集中在数据的分析和应用上了。
四、数据分析
在数据分析这块,离线方面会做的轻一点,做运营报表和数据挖掘。阿里云CDN更多的是做实时数据分析。这两个分析系统,会将数据最终汇集到专家系统,用于检测这些数据有没有异常,找到异常问题的定位。找到问题根源后,根据其他平台产生的数据,关联起来,用机器学习的算法做一个问题的分类。
数据分析的使用场景包括:
自动化运维,通过机器资源、线上问题的收敛,阿里云CDN目前只需要三个运维就足够了;
智能调度,实时根据大区、节点的情况,合理调度流量和进行节点建设;
用户画像,相当于给用户提供一个体检,给出当前服务的建议,优化业务;
事件中心,记录当前节点上正在发生的事件,关注网络抖动和发布情况。
五、数据应用
左边是官网的截图,用户可以根据自己想要的维度,关注各类报表,看到CDN使用的情况。
中间是内部的监控系统,分钟+秒级监控,用于问题的复排和打标。
右边是事件的数据,显示当前整个平台的流量、事件等级和汇集情况等。
除了业务层数据,阿里云CDN和阿里云IDST联合,对CDN上分发的文本、图片、视频等内容进行鉴定,筛查涉黄等违规内容,防止IP被封。
六、总结
整个CDN数据化为了驱动系统,形成下发、执行、采集、分析的闭环。
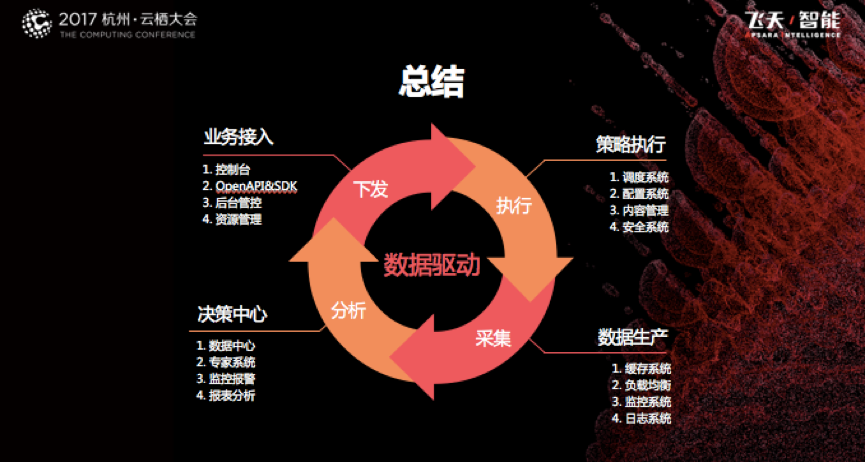
在分享的最后,空见总结道:“从业务接入层,我们可以提供方便、快捷的接入环境;在策略执行层,我们可以快速把操作发布到线上,达到秒级生效;在数据生产层,我们将把所有的系统都量化起来,采集到海量、有效的数据;在决策中心层,我们相应对数据进行收敛,只关注关键数据指标,整个是一个闭环的过程。有了数据化的系统,后面的自动化、智能化才有更多发挥的空间。”
阿里云高级技术专家空见: CDN的数据化之路的更多相关文章
- 阿里云高磊:API网关加速能力聚合与生态集成
导读:本文中,阿里云高级技术专家高磊(花名:埃兰)将聚焦API网关加速能力聚合与生态集成,讲述API如何实现系统间的衔接和API网关的产品升级进程,重点展示了一些新功能.新体验和新变化. 大家下午好, ...
- 专访阿里云资深技术专家黄省江:中国SaaS公司的成功之路
笔者采访中国SaaS厂商10多年,深感面对获客成本巨大.产品技术与功能成熟度不足.项目经营模式难以大规模复制.客户观念有待转变等诸多挑战,很多中国SaaS公司的经营状况都不容乐观. 7月26日,阿里云 ...
- 阿里技术分享:阿里自研金融级数据库OceanBase的艰辛成长之路
本文原始内容由作者“阳振坤”整理发布于OceanBase技术公众号. 1.引言 OceanBase 是蚂蚁金服自研的分布式数据库,在其 9 年的发展历程里,从艰难上线到找不到业务场景濒临解散,最后在双 ...
- 阿里云云盾抗下全球最大DDoS攻击(5亿次请求,95万QPS HTTPS CC攻击) ,阿里百万级QPS资源调度系统,一般的服务器qps多少? QPS/TPS/并发量/系统吞吐量
阿里云云盾抗下全球最大DDoS攻击(5亿次请求,95万QPS HTTPS CC攻击) 作者:用户 来源:互联网 时间:2016-03-30 13:32:40 安全流量事件https互联网资源 摘要: ...
- 读<阿里亿级日活网关通道架构演进>有感
读<阿里亿级日活网关通道架构演进>时对优化方法有些概念不理解,特意搜索了一下,拓展自己的思路. 其中的优化: 优化方法中1,2比较常见,3,4我知道的比较少,很感兴趣.就继续追踪下去: 于 ...
- 阿里PB级Kubernetes日志平台建设实践
干货分享 | 阿里PB级Kubernetes日志平台建设实践https://www.infoq.cn/article/HiIxh-8o0Lm4b3DWKvph 日志最主要的采集工具是 Agent,在 ...
- 阿里云资深技术专家黄省江:让天下没有难做的SaaS
导语:本文中,阿里云资深技术专家黄省江(花名禅笑)将聚焦“SaaS加速器——让天下没有难做的SaaS”,对伙伴来说,SaaS加速器帮助他们做好SaaS,卖好SaaS:对企业来说,SaaS加速器帮助他们 ...
- 阿里云oss对象存储配置CDN
阿里云oss对象存储配置CDN 1.打开阿里云CDN 2.填写信息,这个地方要注意,我的备案域名是www.ljwXXX.work,我们可以自定义一个域名,test.ljwXXX.work作为加速域名. ...
- 太细了!阿里十年技术专家联合打造“最新”Jetpack强化实战手册
前言 提到Android架构,我们首先想到的是MVC,MVP,MVVM.他们主要是针对视图和模型的.随着Android的发展,从原来的框架很少,全是自己动手撸.到现在框架越来越多,选型也越来越多,导致 ...
随机推荐
- JPA 分页处理
1.要实现jpa分页管理首先得要正确配置jpa环境,在spring环境中的配置如下: 开启注解功能 <bean class="org.springframework.orm.jpa.s ...
- Shell脚本定时监控
1.建立脚本文件 autostart.sh #!/bin/bashexport JAVA_HOME=/home/java/jdk1.8.0_191export JRE_HOME=$JAVA_HOME/ ...
- 轻松解决python异常处理,你值得拥有
目录 python中常见的异常信息+处理方法 常见异常类型 异常处理 python中常见的异常信息+处理方法 常见异常类型 异常类名 功能描述 Exception 所有异常的基类 ValueError ...
- DPDK LPM库(学习笔记)
1 LPM库 DPDK LPM库组件为32位的key实现了最长前缀匹配(LPM)表查找方法,该方法通常用于在IP转发应用程序中找到最佳路由匹配. 2 LPM API概述 LPM组件实例的主要配置参数是 ...
- DPDK开发环境搭建(学会了步骤适合各版本)
一.版本的选择 首先要说明的是,对于生产来说DPDK版本不是越高越好,如何选择合适的版本? 1.要选择长期支持的版本LTS(Long Term Support) 2.根据当前开发的系统环境选择 可以在 ...
- strom_hdfs与Sequence详解
这片博客主要是讲解storm-hdfs,Squence及它们的trident方法使用,不多说上代码: pom.xml <dependency> <groupId>org.apa ...
- 存储系列之 Linux ext2 概述
引言:学习经典永不过时. 我们之前介绍过存储介质主要是磁盘,先介绍过物理的,后又介绍了虚拟的.保存在磁盘上的信息一般采用文件(file)为单位,磁盘上的文件必须是持久的,同时文件是通过操作系统管理的, ...
- 实验十四 Swing图形界面组件
实验十四 Swing图形界面组件 实验时间 20178-11-29 1.实验目的与要求 (1) 掌握GUI布局管理器用法: (2) 掌握各类Java Swing组件用途及常用API: 2.实验内容和 ...
- Fabric进阶(三)—— 使用SDK动态增加组织
在fabric网络运行过程中动态追加新的组织是相当复杂的,网上的资料也十分匮乏,大多是基于first-network这样的简单示例,而且是使用启动cli容器的方法来增加组织,几乎没有针对实际应用的解决 ...
- 利用Jackson封装常用JsonUtil工具类
在日常的项目开发中,接口与接口之间.前后端之间的数据传输一般都是使用JSON格式,那必然会封装一些常用的Json数据转化的工具类,本文讲解下如何利用Jackson封装高复用性的Json转换工具类. 转 ...