卷积生成对抗网络(DCGAN)---生成手写数字
深度卷积生成对抗网络(DCGAN)
---- 生成 MNIST 手写图片
1、基本原理
生成对抗网络(GAN)由2个重要的部分构成:
- 生成器(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器
- 判别器(Discriminator):判断这张图像是真实的还是机器生成的,目的是找出生成器做的“假数据”
训练过程
- 固定判别器,让生成器不断生成假数据,给判别器判别,开始生成器很弱,但是随着不断的训练,生成器不断提升,最终骗过判别器。此时判别器判断假数据的概率为50%
- 固定生成器,训练判别器。判别器经过训练,提高鉴别能力,最终能准确判断虽有的假图片
- 循环上两个阶段,最终生成器和判别器都越来越强。然后就可以使用生成器来生成我们想要的图片了
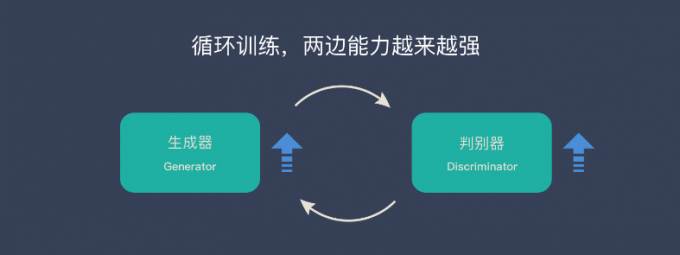
- 循环上两个阶段,最终生成器和判别器都越来越强。然后就可以使用生成器来生成我们想要的图片了
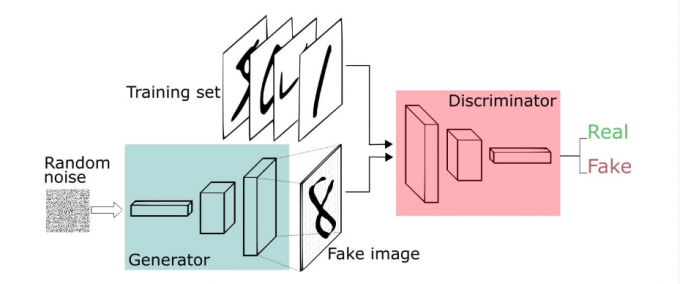
2、相关数学原理
- 判别器在这里是一种分类器,用于区分样本的真伪,因此我们常常使用交叉熵(cross entropy)来进行判别分布的相似性
\]
公式中 \(p_i\) 和 \(q_i\) 为真实的样本分布和生成器的生成分布
假定 \(y_1\) 为正确样本分布,那么对应的( \(1-y_1\) )就是生成样本的分布。\(D\) 表示判别器,则 \(D(x_1)\) 表示判别样本为正确的概率, \(1-D(x_1)\) 则对应着判别为错误样本的概率。则有如下式子(这里仅仅是对当前情况下的交叉熵损失的具体化)。
\]
对于GAN中的样本点 \(x_i\) ,对应于两个出处,要么来自于真实样本,要么来自于生成器生成的样本 $\tilde{x} - G(z) $ ( 这里的 \(z\) 是服从于投到生成器中噪声的分布)。
对于来自于真实的样本,我们要判别为正确的分布 \(y_i\) 。来自于生成的样本我们要判别其为错误分布( \(1-y_i\) )。将上面式子进一步使用概率分布的期望形式写出(为了表达无限的样本情况,相当于无限样本求和情况),并且让 \(y_i\) 为 1/2 且使用 \(G(z)\) 表示生成样本可以得到如下公式:
GAN损失函数期望形式
\]
对于论文中的公式
GAN损失函数的 min max表达
\]
其实是与上面公式一样的,下面做解释
- 这里的 \(V(D, G)\) 相当于表示真实样本和生成样本的差异程度。
- \(max_D V(D, G)\) 的意思是固定生成器 \(G\), 尽可能地让判别器能够最大化地判别出样本来自于真实数据还是生成的数据。
- 再将后面的 $L = max_D V(D, G) $ 看成整体,对于 \(min_G L\)这里是在固定判别器\(D\)的条件下得到生成器 \(G\),这个 \(G\) 要求能够最小化真实样本与生成样本的差异。
- 通过上述 \(min\) \(max\) 的博弈过程,理想情况下会收敛于生成分布拟合于真实分布。
3、卷积对抗生成网络
卷积对抗生成网络(DCGAN)是在GAN的基础上加入了CNN,主要是改进了网络结构,在训练过程中状态稳定,并且可以有效实现高质量图片的生成以及相关的生成模型应用。DCGAN的生成器网络结构如下图:
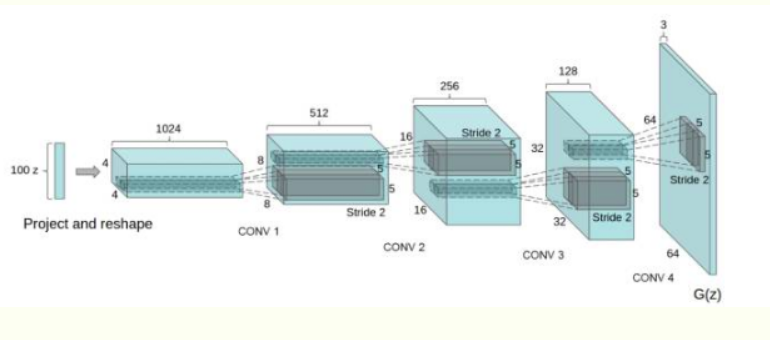
DCGAN的改进:
- 使用步长卷积代替上采样层,卷积在提取图像特征上具有很好的作用,并且使用卷积代替全连接层
- 生成器G和判别器D中几乎每一层都使用batchnorm层,将特征层的输出归一化到一起,加速了训练,提升了训练的稳定性。
- 在判别器中使用leakrelu激活函数,而不是RELU,防止梯度稀疏,生成器中仍然采用relu,但是输出层采用tanh。
4、DCGAN代码实现
shenduimport numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import optimizers, losses, layers, Sequential, Model
class DCGAN():
'''
实现深度对抗神经网络
生成 MNIST 手写数字图片
输入的噪声为服从正态分布均值为 0 方差为 1 的分布, shape:(None, 100)
生成器(G)输入 噪声, 输出为 (None, 28, 28, 1)的图片
分类器(D)输入为 (None, 28, 28, 1)的图片,输出图片的分类真假
'''
def __init__(self):
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
optimizer = optimizers.Adam(0.0002)
# 构建编译分类器
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# 构建编译生成器
self.generator = self.build_generator()
self.generator.compile(loss='binary_crossentropy', optimizer=optimizer)
# 生成器输入为噪音,生成图片
z = layers.Input(shape=(100,))
img = self.generator(z)
# 对于整个对抗网络模型只优化生成器的参数
self.discriminator.trainable = False
# 用生成的图片输入分类器判断
valid = self.discriminator(img)
# 对于整个对抗网络 输入噪音 => 生成图片 => 决定图片是否有效
self.combined = Model(z, valid)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_generator(self):
'''
构建生成器
'''
noise_shape = (100,)
model = tf.keras.Sequential()
# 添加全连接层
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=noise_shape))
# 添加 BatchNormalization 层,对数据进行归一化
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
# 添加逆卷积层,卷积核大小为 5X5,数量 128, 步长为 1
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
# 添加逆卷积层,卷积核大小为 5X5,数量 64, 步长为 2
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
# 添加逆卷积层,卷积核大小为 5X5,数量 1, 步长为 2
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
model.summary()
noise = layers.Input(shape=noise_shape)
img = model(noise)
# 返回 Model 对象,输入为 噪声, 输出为 图像
return keras.Model(noise, img)
def build_discriminator(self):
'''
构建分类器
'''
img_shape = (self.img_rows, self.img_cols, self.channels)
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same',
input_shape=img_shape))
model.add(layers.LeakyReLU())
# 添加 Dropout 层,减少参数数量
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
# 把数据铺平
model.add(layers.Flatten())
model.add(layers.Dense(1))
model.summary()
img = layers.Input(shape=img_shape)
validity = model(img)
return keras.Model(img, validity)
def train(self, epochs, batch_size=128, save_interval=50):
'''
网络训练
'''
# 加载 数据集
(X_train, _), (_, _) = keras.datasets.mnist.load_data()
# 把数据缩放到 [-1, 1]
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
# 添加通道维度
X_train = np.expand_dims(X_train, axis=3)
half_batch = int(batch_size / 2)
for epoch in range(epochs):
# ---------------------
# 训练分类器
# ---------------------
# 随机的选择一半的 batch 数量图片
idx = np.random.randint(0, X_train.shape[0], half_batch)
imgs = X_train[idx]
noise = np.random.normal(0, 1, (half_batch, 100))
# 生成一半 batch 数量的 图片
gen_imgs = self.generator.predict(noise)
# 分类器损失
d_loss_real = self.discriminator.train_on_batch(imgs, np.ones((half_batch, 1)))
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, np.zeros((half_batch, 1)))
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# 训练生成器
# ---------------------
noise = np.random.normal(0, 1, (batch_size, 100))
# The generator wants the discriminator to label the generated samples
# as valid (ones)
# 对于生成器,希望分类器把更多的图片判为 有效 (用 1 表示)
valid_y = np.array([1] * batch_size)
# 训练生成器
g_loss = self.combined.train_on_batch(noise, valid_y)
# 打印训练进度
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
# 每个 save_interval 周期保存一张图片
if epoch % save_interval == 0:
self.save_imgs(epoch)
def save_imgs(self, epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, 100))
gen_imgs = self.generator.predict(noise)
# 把图片数据缩放到 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("dcgan/images/mnist_%d.png" % epoch)
plt.close()
if __name__ == '__main__':
dcgan = DCGAN()
dcgan.train(epochs=10000, batch_size=32, save_interval=200)
网络参数信息

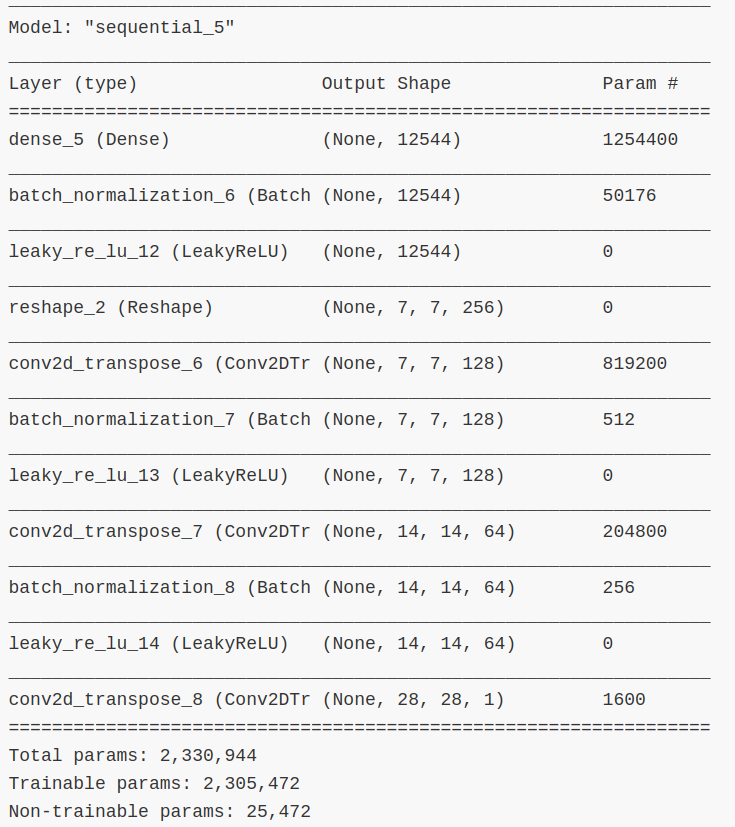
5、训练结果
下面是循环了 10000 次 epoch 后,从开始每隔 2000 个 epoch 生成器生成的图片
可以看到,刚开始全部都是噪声,随着训练的进行,图片逐渐清晰
生成的图片还是不太清晰,一方面的原因是我训练的 epoch 周期太少,因为自己电脑性能问题,太耗时间,所以训练的epoch 周期少,如果有条件后提高训练周期应该会好很多。另一方面或许因为我构建的网络还有不合理之,后期还需要改进。






卷积生成对抗网络(DCGAN)---生成手写数字的更多相关文章
- 使用TensorFlow的卷积神经网络识别自己的单个手写数字,填坑总结
折腾了几天,爬了大大小小若干的坑,特记录如下.代码在最后面. 环境: Python3.6.4 + TensorFlow 1.5.1 + Win7 64位 + I5 3570 CPU 方法: 先用MNI ...
- 图片训练:使用卷积神经网络(CNN)识别手写数字
这篇文章中,我们将使用CNN构建一个Tensorflow.js模型来分辨手写的数字.首先,我们通过使之“查看”数以千计的数字图片以及他们对应的标识来训练分辨器.然后我们再通过此模型从未“见到”过的测试 ...
- tensorflow学习之(十)使用卷积神经网络(CNN)分类手写数字0-9
#卷积神经网络cnn import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data #数据包,如 ...
- GAN实战笔记——第四章深度卷积生成对抗网络(DCGAN)
深度卷积生成对抗网络(DCGAN) 我们在第3章实现了一个GAN,其生成器和判别器是具有单个隐藏层的简单前馈神经网络.尽管很简单,但GAN的生成器充分训练后得到的手写数字图像的真实性有些还是很具说服力 ...
- 生成对抗网络(Generative Adversarial Networks,GAN)初探
1. 从纳什均衡(Nash equilibrium)说起 我们先来看看纳什均衡的经济学定义: 所谓纳什均衡,指的是参与人的这样一种策略组合,在该策略组合上,任何参与人单独改变策略都不会得到好处.换句话 ...
- 卷积神经网络CNN 手写数字识别
1. 知识点准备 在了解 CNN 网络神经之前有两个概念要理解,第一是二维图像上卷积的概念,第二是 pooling 的概念. a. 卷积 关于卷积的概念和细节可以参考这里,卷积运算有两个非常重要特性, ...
- TensorFlow实战之Softmax Regression识别手写数字
关于本文说明,本人原博客地址位于http://blog.csdn.net/qq_37608890,本文来自笔者于2018年02月21日 23:10:04所撰写内容(http://blog.c ...
- CNN 手写数字识别
1. 知识点准备 在了解 CNN 网络神经之前有两个概念要理解,第一是二维图像上卷积的概念,第二是 pooling 的概念. a. 卷积 关于卷积的概念和细节可以参考这里,卷积运算有两个非常重要特性, ...
- 07 训练Tensorflow识别手写数字
打开Python Shell,输入以下代码: import tensorflow as tf from tensorflow.examples.tutorials.mnist import input ...
随机推荐
- QQ恢复解散后的群聊或删除后的好友的方法
今天有一个群被一个管理员乱踢人,之后将群解散. 事后几分钟我在想有没有什么方法可以重新恢复的方法,之后进入了QQ的官网进行查找. 本来以为没希望了,但是奇迹发生了. 原来真的可以恢复! 恢复的详情: ...
- .net core BundlerMinifier.BundlerBuildTask 任务意外失败
BundlerMinifier.BundlerBuildTask : 捆绑和缩小CSS.JS和HTML文件 BundlerMinifier.BundlerBuildTask 任务意外失败处理: 1.在 ...
- MySQL事务操作
在 MySQL 命令行的默认设置下,事务都是自动提交的,即执行 SQL 语句后就会马上执行 COMMIT 操作.因此要显式地开启一个事务务须使用命令 BEGIN 或 START TRANSACTION ...
- GreenPlum-数据存储目录迁移及常用操作
一.环境介绍 Greenplum5 3节点集群,Centos7.2虚拟机, 二.需求 因为/home目录磁盘空间已满,需要将Greenplum的数据存储目录转移到新的分区/opt目录下,虚拟机磁盘管理 ...
- 用了这么多年的 Java 泛型,你对它到底有多了解?
作为一个 Java 程序员,日常编程早就离不开泛型.泛型自从 JDK1.5 引进之后,真的非常提高生产力.一个简单的泛型 T,寥寥几行代码, 就可以让我们在使用过程中动态替换成任何想要的类型,再也不用 ...
- HTML中id与name的通俗区别
转自:https://blog.csdn.net/qq_35038153/article/details/70215356 https://zhidao.baidu.com/question/7582 ...
- 201771010128王玉兰《面向对象与程序设计(Java)》第十七周学习总结
第一部分:理论基础 线程的同步 多线程并发运行不确定性问题解决方案:引入线 程同步机制,使得另一线程要使用该方法,就只 能等待. 在Java中解决多线程同步问题的方法有两种: - Java SE 5. ...
- 201771010128王玉兰《面向对象程序设计(Java)》第十六周学习总结
第一部分:理论基础 1.线程的概念 进程:进程是程序的一次动态执行,它对应了从代码加 载.执行至执行完毕的一个完整过程. 多线程:多线程是进程执行过程中产生的多条执行线索. 线程:线程是比进程执行 ...
- poj3694 连通无向图图加边后有多少桥
Network Time Limit: 5000MS Memory Limit: 65536K Total Submissions: 10261 Accepted: 3807 Descript ...
- vue过渡动画样式
在进入/离开的过渡中,会有 6 个 class 切换. v-enter:定义进入过渡的开始状态.在元素被插入之前生效,在元素被插入之后的下一帧移除. v-enter-active:定义进入过渡生效时的 ...