RMQ问题总结,标准RMQ算法的实现
RMQ问题:对于长度为N的序列,询问区间[L,R]中的最值
RMQ问题的几种解法:
- 普通遍历查询,O(1)-O(N)
- 线段树,O(N)-O(logN)
- DP,O(NlogN)-O(1)
- RMQ标准算法,O(N)-O(1)
简单介绍:
- 朴素的查询,不需要任何预处理,但结果是没有任何已知的信息可以利用,每次都需要从头遍历到尾。
- 线段树,区间问题的神器,用线段树做比起朴素的暴力查询要快得多,关键在于线段树使用了分治思想,利用了区间问题的可合并性。任何一个区间最多只需要logN个线段树上的区间来合并,线段树上的区间总数目为O(N)个,因此只需要O(N)的预处理就可以将查询复杂度降到O(logN)。同时线段树的树状结构使得修改时信息更容易维护。
- DP,又叫ST算法,也是利用了分治的思想。任何一个区间都可以由两个小于当前区间长度的最大的长度为2的幂的区间合并而来,于是预处理出每个点开始所有长度为2的幂的区间最值,那么查询时就可以由预处理的信息O(1)得到答案。
- RMQ标准算法,利用了神奇的数据结构--笛卡尔树,笛卡尔树将区间最值问题转化为树上两个点的LCA问题,而DFS可以将LCA问题转化为±1RMQ问题,±1RMQ问题又可以利用分块和动态规划的思想来解决。上述所有预处理,包括笛卡尔树的建立、DFS序以及±1RMQ的问题的求解都可以在线性时间内完成,查询时复杂度为O(1)。
标准算法的实现:
- 结构图:
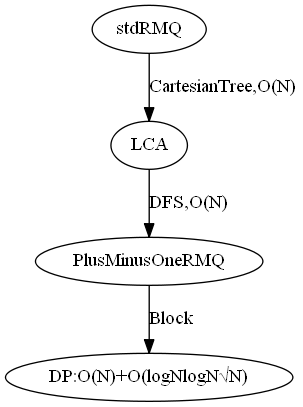
- 笛卡尔树的构造算方法:从左至右扫描原序列,并依次插入到笛卡尔树的右链中,使用单调栈复杂度为O(N)。建好树后,key是二查搜索树,value是小根堆。
- 最小值与LCA:建好树后,区间最小值问题便转化为了LCA问题,下面简单证明一下:
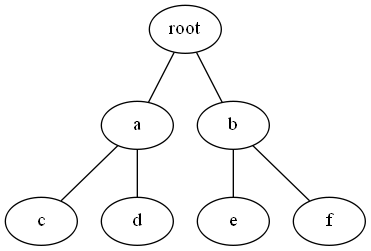
假设现在询问[d, f]的最小值,root为d和f的LCA,由笛卡尔树的性质可知,root是整棵树表示区间的最小值,而[d, f]是其子区间,所以root不可能比[d, f]中的数小,又因为d和f属于root的不同子树(LCA的性质),所以root一定在[d, f]中(笛卡尔树的性质),故对两个点a,b,LCA(a, b)就是[a, b]的最小值,证毕。
- ±1RMQ问题:相邻两个数相差1或者-1的序列的RMQ问题
- ±1RMQ问题解法:将原长度为N的序列分成2N/logN块,每块长度为logN/2,将原来的询问分解为块间询问和块内询问。用ST算法在O(N/logN*log(N/logN))=O(N)的时间内处理出块与块之间的区间最值信息,可以在O(1)的时间内解决块与块之间的询问。对于块内的询问,由于每块长度为logN/2,相邻两个数的差不是1就是-1,于是对于区间最值出现的位置,本质不同的状态只有2logN/2=√N个,加上边界,总共状态数为O(√N*logNlogN),利用递推在O(√N*logNlogN)的时间内求出所有状态来,以后可以在O(1)的时间内得到块内任意区间最值的位置。总复杂度为O(N + √N*logNlogN) ≈ O(N)。
- LCA与±1RMQ的经典转化就不细说了,详见代码
标准RMQ,O(N)-O(1)
1 |
struct PlusMinusOneRMQ {
|
RMQ问题总结,标准RMQ算法的实现的更多相关文章
- Bug2算法的实现(RobotBASIC环境中仿真)
移动机器人智能的一个重要标志就是自主导航,而实现机器人自主导航有个基本要求--避障.之前简单介绍过Bug避障算法,但仅仅了解大致理论而不亲自动手实现一遍很难有深刻的印象,只能说似懂非懂.我不是天才,不 ...
- Canny边缘检测算法的实现
图像边缘信息主要集中在高频段,通常说图像锐化或检测边缘,实质就是高频滤波.我们知道微分运算是求信号的变化率,具有加强高频分量的作用.在空域运算中来说,对图像的锐化就是计算微分.由于数字图像的离散信号, ...
- C++基础代码--20余种数据结构和算法的实现
C++基础代码--20余种数据结构和算法的实现 过年了,闲来无事,翻阅起以前写的代码,无意间找到了大学时写的一套C++工具集,主要是关于数据结构和算法.以及语言层面的工具类.过去好几年了,现在几乎已经 ...
- java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现
java基础解析系列(四)---LinkedHashMap的原理及LRU算法的实现 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析 ...
- SSE图像算法优化系列十三:超高速BoxBlur算法的实现和优化(Opencv的速度的五倍)
在SSE图像算法优化系列五:超高速指数模糊算法的实现和优化(10000*10000在100ms左右实现) 一文中,我曾经说过优化后的ExpBlur比BoxBlur还要快,那个时候我比较的BoxBlur ...
- 详解Linux内核红黑树算法的实现
转自:https://blog.csdn.net/npy_lp/article/details/7420689 内核源码:linux-2.6.38.8.tar.bz2 关于二叉查找树的概念请参考博文& ...
- 详细MATLAB 中BP神经网络算法的实现
MATLAB 中BP神经网络算法的实现 BP神经网络算法提供了一种普遍并且实用的方法从样例中学习值为实数.离散值或者向量的函数,这里就简单介绍一下如何用MATLAB编程实现该算法. 具体步骤 这里 ...
- Python学习(三) 八大排序算法的实现(下)
本文Python实现了插入排序.基数排序.希尔排序.冒泡排序.高速排序.直接选择排序.堆排序.归并排序的后面四种. 上篇:Python学习(三) 八大排序算法的实现(上) 1.高速排序 描写叙述 通过 ...
- Python八大算法的实现,插入排序、希尔排序、冒泡排序、快速排序、直接选择排序、堆排序、归并排序、基数排序。
Python八大算法的实现,插入排序.希尔排序.冒泡排序.快速排序.直接选择排序.堆排序.归并排序.基数排序. 1.插入排序 描述 插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得 ...
随机推荐
- 【JAVA】并发-基础IO
一.java.io包支持.java的IO流有输入.输出两种,每种输入.输出流又可分为字节流.字符流两大类,字节流以字节为单位处理IO操作,字符流以字符为单位处理IO操作 JDK 1.4以后有java. ...
- Dom节点操作总结
Dom 一:Dom的概念 Dom的简介: 全称为 document object model 文档对象模型,是操作文档的一整套方法 - 文档 - html,document时一个对象,是dom ...
- 2.hover的使用
1. 自身的hover div :hover{ :hover前要有空格 } 2.hover指向子元素 father:hover .childer { :hover前不能有空格 } 3.ho ...
- 牛客网 - vivo2020届春季
牛客网 - vivo2020届春季 1.[编程题]手机屏幕解锁模式 时间限制:C/C++ 1秒,其他语言2秒 空间限制:C/C++ 256M,其他语言512M 现有一个 3x3 规格的 Android ...
- SpringCloud(二)笔记之Eureka
Eureka包含两个组件:Eureka Server和Eureka Client Eureka Server:提供服务注册服务,各个节点启动后,会在Eureka Server中进行注册 Eureka ...
- Thymeleaf+SpringBoot+Mybatis实现的齐贤易游网旅游信息管理系统
项目简介 项目来源于:https://github.com/liuyongfei-1998/root 本系统是基于Thymeleaf+SpringBoot+Mybatis.是非常标准的SSM三大框架( ...
- HTTPS之密钥知识与密钥工具Keytool和Keystore-Explorer
1 简介 之前文章<Springboot整合https原来这么简单>讲解过一些基础的密码学知识和Springboot整合HTTPS.本文将更深入讲解密钥知识和密钥工具. 2 密钥知识-非对 ...
- 【vue】nextTick源码解析
1.整体入手 阅读代码和画画是一样的,忌讳一开始就从细节下手(比如一行一行读),我们先将细节代码折叠起来,整体观察nextTick源码的几大块. 折叠后代码如下图 整体观察代码结构 上图中,可以看到: ...
- 为什么要你们现在要学习python
说学习python之前,我们先来聊聊其他的.我们都认为成功靠的是勤奋和努力,但是事实是只靠勤奋和努力是不一定会成功的,而且很大一部分都不会成功. 你有没有想过,同样是做企业,有些公司年收入百万,而腾讯 ...
- springmvc返回不带引号的字符串
springmvc返回不带引号的字符串项目使用springboot开发的,大部分出参为json,使用的fastJson,现在有的接口需要返回一个success字符串,发现返回结果为“success”, ...