12 . Python3之网络编程
互联网的本质
两台计算机之间的通信与两个人打电话原理是一样的.
# 1. 首先要通过各种物理连接介质连接
# 2. 找准确对方计算机(准确到软件)的位置
# 3. 通过统一的标准(一般子协议)进行数据的转发
# 物理连接介质,这个是网络工程师所考虑的,后面也会给大家简单的讲到,咱们主要就是学习这统一的标准。
# 英语成为世界上所有人通信的统一标准,如果把计算机看成分布于世界各地的人,那么连接两台计算机之间的internet实际上就是一系列统一的标准,这些标准称之为互联网协议,互联网的本质就是一系列的协议,总称为‘互联网协议’(Internet Protocol Suite).
# 互联网协议的功能:定义计算机如何接入internet,以及接入internet的计算机通信的标准。
自从互联网诞生以来,现在基本上所有的程序都是网络程序,很少有单机版的程序了.
计算机网络就是把各个计算机连接到一起,让网络中的计算机可以互相通信。网络编程就是如何在程序中实现两台计算机的通信。
举个例子,当你使用浏览器访问新浪网时,你的计算机就和新浪的某台服务器通过互联网连接起来了,然后,新浪的服务器把网页内容作为数据通过互联网传输到你的电脑上。
由于你的电脑上可能不止浏览器,还有QQ、Skype、Dropbox、邮件客户端等,不同的程序连接的别的计算机也会不同,所以,更确切地说,网络通信是两台计算机上的两个进程之间的通信。比如,浏览器进程和新浪服务器上的某个Web服务进程在通信,而QQ进程是和腾讯的某个服务器上的某个进程在通信。
TCP/IP简介
虽然大家现在对互联网很熟悉,但是计算机网络的出现比互联网要早很多。
计算机为了联网,就必须规定通信协议,早期的计算机网络,都是由各厂商自己规定一套协议,IBM、Apple和Microsoft都有各自的网络协议,互不兼容,这就好比一群人有的说英语,有的说中文,有的说德语,说同一种语言的人可以交流,不同的语言之间就不行了。
为了把全世界的所有不同类型的计算机都连接起来,就必须规定一套全球通用的协议,为了实现互联网这个目标,互联网协议簇(Internet Protocol Suite)就是通用协议标准。Internet是由inter和net两个单词组合起来的,原意就是连接“网络”的网络,有了Internet,任何私有网络,只要支持这个协议,就可以联入互联网。
因为互联网协议包含了上百种协议标准,但是最重要的两个协议是TCP和IP协议,所以,大家把互联网的协议简称TCP/IP协议。
通信的时候,双方必须知道对方的标识,好比发邮件必须知道对方的邮件地址。互联网上每个计算机的唯一标识就是IP地址,类似
123.123.123.123。如果一台计算机同时接入到两个或更多的网络,比如路由器,它就会有两个或多个IP地址,所以,IP地址对应的实际上是计算机的网络接口,通常是网卡。
IP协议负责把数据从一台计算机通过网络发送到另一台计算机。数据被分割成一小块一小块,然后通过IP包发送出去。由于互联网链路复杂,两台计算机之间经常有多条线路,因此,路由器就负责决定如何把一个IP包转发出去。IP包的特点是按块发送,途径多个路由,但不保证能到达,也不保证顺序到达。
IP地址实际上是一个32位整数(称为IPv4),以字符串表示的IP地址如
192.168.0.1实际上是把32位整数按8位分组后的数字表示,目的是便于阅读。 IPv6地址实际上是一个128位整数,它是目前使用的IPv4的升级版,以字符串表示类似于
2001:0db8:85a3:0042:1000:8a2e:0370:7334。 TCP协议则是建立在IP协议之上的。TCP协议负责在两台计算机之间建立可靠连接,保证数据包按顺序到达。TCP协议会通过握手建立连接,然后,对每个IP包编号,确保对方按顺序收到,如果包丢掉了,就自动重发。
许多常用的更高级的协议都是建立在TCP协议基础上的,比如用于浏览器的HTTP协议、发送邮件的SMTP协议等。
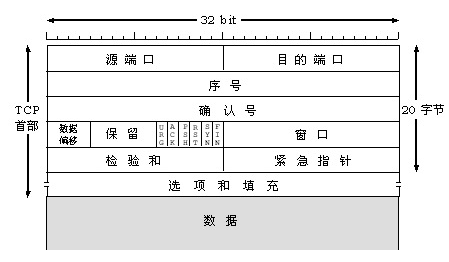
一个TCP报文除了包含要传输的数据外,还包含源IP地址和目标IP地址,源端口和目标端口。
端口有什么作用?在两台计算机通信时,只发IP地址是不够的,因为同一台计算机上跑着多个网络程序。一个TCP报文来了之后,到底是交给浏览器还是QQ,就需要端口号来区分。每个网络程序都向操作系统申请唯一的端口号,这样,两个进程在两台计算机之间建立网络连接就需要各自的IP地址和各自的端口号。
一个进程也可能与多个计算机建立链接,因此他会申请很多端口.
了解了TCP/IP协议的基本概念,IP地址和端口的概念,我们就可以开始进行网络编程了。
软件开发架构
CS架构,BS架构
客户端英文名称:Client,
浏览器英文名称:Browser.
服务端英文名称:Server.
C/S架构:基于客户端与用户端之间的架构。例如:QQ、微信、优酷、暴风影音等等。
- 优点:C/S架构的界面和操作非常丰富满足客户的个性化要求,安全性很容易保证,响应速度较快。
- 缺点:需要开发客户端和服务器两套程序,开发成本维护成本较高,兼容性差,用户群固定等。
B/S架构:基于C/S架构的一种特殊的C/S架构,浏览器与服务端之间的架构。
- 优点:分布性强,客户端几乎无需维护,开发简单,共享性强,维护简单方便。
- 缺点:个性化低,安全性以及响应速度需要花费巨大设计成本。
小结:CS响应速度快,安全性强,一般应用于局域网中,但是开发维护成本高;BS可以实现跨平台,客户端零维护,但是个性化能力低,响应速度较慢。所以有些单位日常办公应用BS,在实际生产中使用CS结构。
# C/S 架构
C: 客户端
S: 服务端
# B/S 架构
B: 浏览器
S: 服务端
# C/S架构: 需要安装一下才能使用
# client 客户端: 我们用的 需要安装的
# server 服务端
# B/S架构: 百度 博客园 谷歌 码云
# browser 浏览器
# server 服务器
# b/s和c/s什么关系?
# B/S架构是C/S架构的一种
# C/S架构的好处
# 可以离线使用/功能更完善/安全性更好
# B/S架构
# 不用安装就可以使用
# 统一PC端用户的入口
# 手机端: 好像C/S架构比较火,其实不然,微信小程序,支付宝第三方接口都类似于B/S架构
# 目的都在于统一接口: 聚集用户群
# PC端: BS比较火
# 本质: B/S架构本身也是C/S架构
客户端与服务端概念
# 服务端: 24小时不间断提供服务,谁来我就服务谁
# 客户端: 想体验服务的时候,就去找服务端体验服务
学习网络编程能干什么
# 开发C/S架构的软件
学习并发,数据库,前端能干什么
# 开发B/S架构的软件
网络编程技术起源
# 绝大部分先进技术的兴起基本来自于军事,网络编程这项技术来源于美国军事,为了实现数据的远程传输.
人类实现远程沟通交流的方式
# 插电话线的电话
# 插网线的大屁股电脑
# 插无线网卡的笔记本电脑
# 综上我们能够总结出第一个规律:要想实现远程通信第一个需要具备的条件就是: 物理连接介质
# 再来想人与人之间交流,中国人说中文,外国人说外语,
# 那如果想实现不同国家的人之间无障碍沟通交流是不是得规定一个大家都能听得懂的语言>>>英语
# 再回来看计算机领域,计算机之间要想实现远程通信除了需要有物理连接介质之外是不是也应该有一套公共的标准?这套标准就是
# >>>OSI七层协议(也叫OSI七层模型)
OSI七层协议(模型)
# 应用层
# 表示层
# 会话层
# 传输层
# 网络层
# 数据链路层
# 物理连接层
# 也有人将其归纳为五层
# 应用层
# 传输层
# 网络层
# 数据链路层
# 物理连接层
物理层
物理层由来: 上面提到,孤立的计算机之间要想一起玩,就必须接入internet,言外之意就是计算机之间必须完成组网.

物理层功能: 主要是基于电路特性发送高低电压(电信号),高电压对应数字1,低电压对应数字0
# 实现计算机之间物理连接,传输的数据都是010101的二进制
# 电信号工作原理: 点只有高低电平
光纤

双绞线

数据链路层
数据链路层由来: 单纯的电信号0和1没有任何意义,必须规定电信号多少位一组,每组什么意思.
数据链路层的功能: 定义了电信号的分组方式
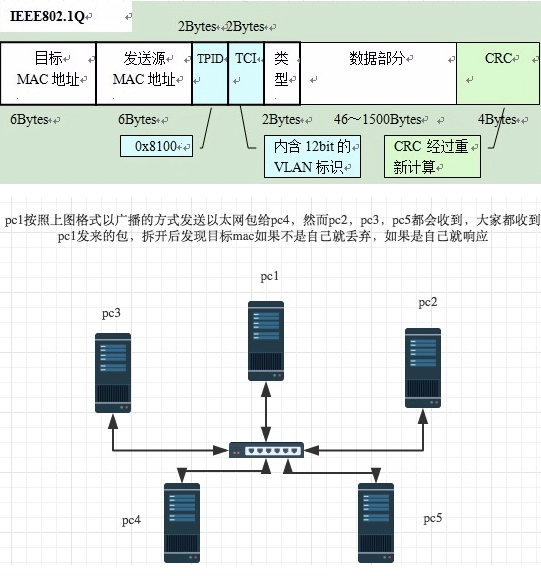
以太网协议
早期的时候各个公司都有自己的分组方式,后来形成了统一的标准,即以太网协议ethernet
ethernet规定
一组电信号构成一个数据豹,叫做‘帧’
每一数据帧分成:报头head和数据data两部分
| Head | Data |
|---|---|
| 报头 | 数据 |
# head包含:(固定18个字节)
# 发送者/源地址,6个字节
# 接收者/目标地址,6个字节
# 数据类型,6个字节
# data包含: (最短46字节,最长1500字节)
# 数据包的具体内容
# head长度 + data长度 = 最短64字节,最长1518字节,超过限制就分片发送
mac地址
head中包含的源和目标地址由来:ethernet规定接入internet的设备都必须具备网卡,发送端和接收端的地址便是指网卡的地址,即mac地址
mac地址:每块网卡出厂时都被烧制上一个世界唯一的mac地址,长度为48位2进制,通常由12位16进制数表示(前六位是厂商编号,后六位是流水线号)
广播
有了mac地址,同一网络内的两台主机就可以通信了(一台主机通过arp协议获取另外一台主机的mac地址)
ethernet采用最原始的方式,广播的方式进行通信,即计算机通信基本靠吼
# 1. 规定了二进制数据的分组方式
# 2. 规定了只要是接入互联网的计算机,都必须有一块网卡
# 网卡上刻有世界唯一的编号
# 每块网卡出厂时都会被烧制上一个世界上唯一的mac地址
# 长度为48位2进制,通常由12位16进制数表示(前六位是厂商编号,后六位是流水线号)
# 我们管网卡上刻有的编号叫电脑的>>>mac地址
# —–>上面的两个规定其实就是 “以太网协议”!
# 基于以太网协议通信: 通信基本靠吼!!! 弊端: 广播风暴
# 交换机: 如果没有交换机,你的电脑就变成了马蜂窝,有了交换机吼,所有的电脑只需要一个网卡连接交换机,即可实现多台电脑之间物理连接
网络层
网络层由来:有了ethernet、mac地址、广播的发送方式,世界上的计算机就可以彼此通信了,问题是世界范围的互联网是由
一个个彼此隔离的小的局域网组成的,那么如果所有的通信都采用以太网的广播方式,那么一台机器发送的包全世界都会收到,
这就不仅仅是效率低的问题了,这会是一种灾难
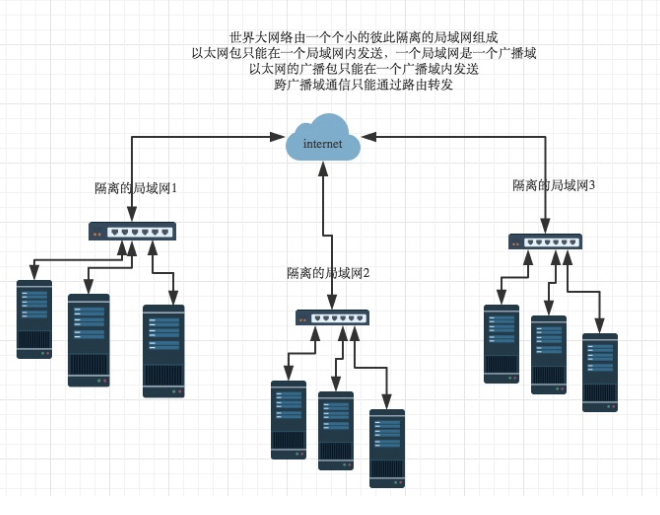
上图结论:必须找出一种方法来区分哪些计算机属于同一广播域,哪些不是,如果是就采用广播的方式发送,如果不是,
就采用路由的方式(向不同广播域/子网分发数据包),mac地址是无法区分的,它只跟厂商有关
网络层功能:引入一套新的地址用来区分不同的广播域/子网,这套地址即网络地址
IP协议:
- 规定网络地址的协议叫ip协议,它定义的地址称之为ip地址,广泛采用的v4版本即ipv4,它规定网络地址由32位2进制表示
- 范围0.0.0.0-255.255.255.255
- 一个ip地址通常写成四段十进制数,例:172.16.10.1
ip地址分成两部分
- 网络部分:标识子网
- 主机部分:标识主机
注意:单纯的ip地址段只是标识了ip地址的种类,从网络部分或主机部分都无法辨识一个ip所处的子网
例:172.16.10.1与172.16.10.2并不能确定二者处于同一子网
子网掩码
所谓”子网掩码”,就是表示子网络特征的一个参数。它在形式上等同于IP地址,也是一个32位二进制数字,它的网络部分全部为1,主机部分全部为0。比如,IP地址172.16.10.1,如果已知网络部分是前24位,主机部分是后8位,那么子网络掩码就是11111111.11111111.11111111.00000000,写成十进制就是255.255.255.0。
知道”子网掩码”,我们就能判断,任意两个IP地址是否处在同一个子网络。方法是将两个IP地址与子网掩码分别进行AND运算(两个数位都为1,运算结果为1,否则为0),然后比较结果是否相同,如果是的话,就表明它们在同一个子网络中,否则就不是。
比如,已知IP地址172.16.10.1和172.16.10.2的子网掩码都是255.255.255.0,请问它们是否在同一个子网络?两者与子网掩码分别进行AND运算,
172.16.10.1:10101100.00010000.00001010.000000001
255255.255.255.0:11111111.11111111.11111111.00000000
AND运算得网络地址结果:10101100.00010000.00001010.000000001->172.16.10.0
172.16.10.2:10101100.00010000.00001010.000000010
255255.255.255.0:11111111.11111111.11111111.00000000
AND运算得网络地址结果:10101100.00010000.00001010.000000001->172.16.10.0
结果都是172.16.10.0,因此它们在同一个子网络。
总结一下,IP协议的作用主要有两个,一个是为每一台计算机分配IP地址,另一个是确定哪些地址在同一个子网络。
ip数据包
ip数据包也分为head和data部分,无须为ip包定义单独的栏位,直接放入以太网包的data部分
head:长度为20到60字节
data:最长为65,515字节。
而以太网数据包的”数据”部分,最长只有1500字节。因此,如果IP数据包超过了1500字节,它就需要分割成几个以太网数据包,分开发送了。
| 以太网头 | ip 头 | ip数据 |
|---|---|---|
ARP协议
arp协议由来:计算机通信基本靠吼,即广播的方式,所有上层的包到最后都要封装上以太网头,然后通过以太网协议发送,在谈及以太网协议时候,我门了解到
通信是基于mac的广播方式实现,计算机在发包时,获取自身的mac是容易的,如何获取目标主机的mac,就需要通过arp协议
arp协议功能:广播的方式发送数据包,获取目标主机的mac地址
协议工作方式:每台主机ip都是已知的
例如:主机172.16.10.10/24访问172.16.10.11/24
一:首先通过ip地址和子网掩码区分出自己所处的子网
| 场景 | 数据包地址 |
|---|---|
| 同一子网 | 目标主机mac,目标主机ip |
| 不同子网 | 网关mac,目标主机ip |
二:分析172.16.10.10/24与172.16.10.11/24处于同一网络(如果不是同一网络,那么下表中目标ip为172.16.10.1,通过arp获取的是网关的mac)
| 源mac | 目标mac | 源ip | 目标ip | 数据部分 | |
|---|---|---|---|---|---|
| 发送端主机 | 发送端mac | FF:FF:FF:FF:FF:FF | 172.16.10.10/24 | 172.16.10.11/24 | 数据 |
三:这个包会以广播的方式在发送端所处的自网内传输,所有主机接收后拆开包,发现目标ip为自己的,就响应,返回自己的mac
# 规定了计算机都必须有一个ip地址
# ip地址特点:点分十进制
# 有两个版本ipv4和ipv6 为了能够兼容更多的计算机
# 最小:0.0.0.0
# 最大:255.255.255.255
# IP协议可以跨局域网传输
# ip地址能够唯一标识互联网中独一无二的一台机器!
# [http://14.215.177.39/](http://14.215.177.39/)
传输层(端口协议)
传输层的由来:网络层的ip帮我们区分子网,以太网层的mac帮我们找到主机,然后大家使用的都是应用程序,你的电脑上可能同时开启qq,暴风影音,等多个应用程序,
那么我们通过ip和mac找到了一台特定的主机,如何标识这台主机上的应用程序,答案就是端口,端口即应用程序与网卡关联的编号。
传输层功能:建立端口到端口的通信
补充:端口范围0-65535,0-1023为系统占用端口
tcp协议:
可靠传输,TCP数据包没有长度限制,理论上可以无限长,但是为了保证网络的效率,通常TCP数据包的长度不会超过IP数据包的长度,以确保单个TCP数据包不必再分割。
| 以太网头 | ip 头 | tcp头 | 数据 |
|---|---|---|---|
tcp报文
tcp三次握手和四次挥手
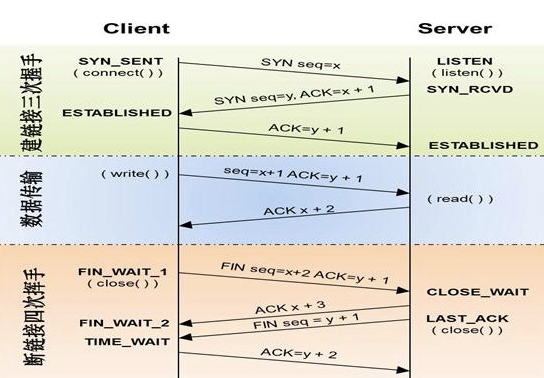
udp协议:
不可靠传输,”报头”部分一共只有8个字节,总长度不超过65,535字节,正好放进一个IP数据包。
| 以太网头 | ip头 | udp头 | 数据 |
|---|---|---|---|
# TCP,UDP基于端口工作的协议!
# 其实计算机之间通信其实是计算机上面的应用程序于应用之间的通信
# 端口(port):唯一标识一台计算机上某一个基于网络通信的应用程序
# 端口范围:0~~65535(动态分配)
# 注意:0~~1024通常是归操作系统分配的端口号
# 通常情况下,我们写的软件端口号建议起在8000之后
# flask框架默认端口5000
# django框架默认端口8000
# mysql数据库默认端口3306
# redis数据库默认端口6379
# 注意:一台计算机上同一时间一个端口号只能被一个应用程序占用
# 小总结:
# IP地址:唯一标识全世界接入互联网的独一无二的机器
# port端口号:唯一标识一台计算机上的某一个应用程序
# ip+port :能够唯一标识全世界上独一无二的一台计算机上的某一个应用程序
# 补充:
# arp协议:根据ip地址解析mac地址
应用层(HTTP协议,FTP协议)
应用层由来:用户使用的都是应用程序,均工作于应用层,互联网是开发的,大家都可以开发自己的应用程序,数据多种多样,必须规定好数据的组织形式
应用层功能:规定应用程序的数据格式。
例:TCP协议可以为各种各样的程序传递数据,比如Email、WWW、FTP等等。那么,必须有不同协议规定电子邮件、网页、FTP数据的格式,这些应用程序协议就构成了”应用层”。
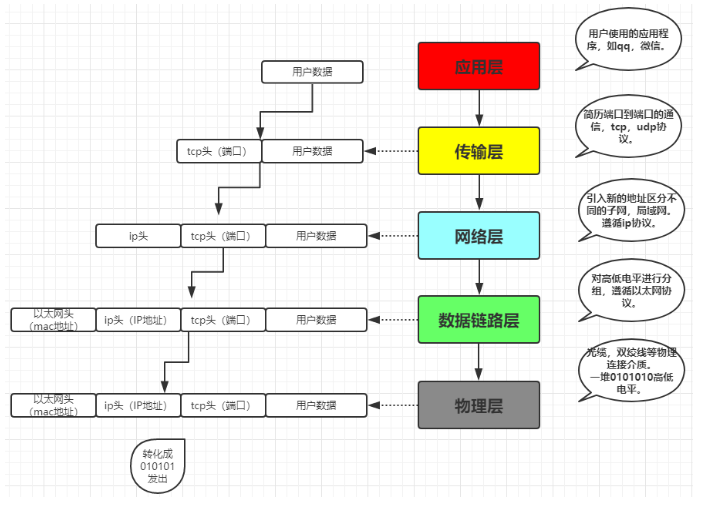
TCP\UDP协议(流式协议,可靠协议)
# 三次握手四次挥手
# 三次握手建连接
# 四次挥手断连接
# Tcp(语音聊天/视频聊天),线下缓存高强电影\QQ远程控制
# 需要先建立连接,然后才能通信
# 占用连接\可靠(消息不会丢失)\实时性高\慢
# UDP(发消息) - 在线播放视频\QQ发消息\微信消息
# 不需要建立连接,就可以通信
# 不占用连接\不可靠\消息因为网络不稳定丢失\快
网络通信实现
想实现网络通信,每台主机需具备四要素
- 本机的IP地址
- 子网掩码
- 网关的IP地址
- DNS的IP地址
获取这四要素分两种方式
1.静态获取
即手动配置
2.动态获取
通过dhcp获取
| 以太网头 | ip头 | udp头 | dhcp数据包 |
|---|---|---|---|
(1)最前面的”以太网标头”,设置发出方(本机)的MAC地址和接收方(DHCP服务器)的MAC地址。前者就是本机网卡的MAC地址,后者这时不知道,就填入一个广播地址:FF-FF-FF-FF-FF-FF。
(2)后面的”IP标头”,设置发出方的IP地址和接收方的IP地址。这时,对于这两者,本机都不知道。于是,发出方的IP地址就设为0.0.0.0,接收方的IP地址设为255.255.255.255。
(3)最后的”UDP标头”,设置发出方的端口和接收方的端口。这一部分是DHCP协议规定好的,发出方是68端口,接收方是67端口。
这个数据包构造完成后,就可以发出了。以太网是广播发送,同一个子网络的每台计算机都收到了这个包。因为接收方的MAC地址是FF-FF-FF-FF-FF-FF,看不出是发给谁的,所以每台收到这个包的计算机,还必须分析这个包的IP地址,才能确定是不是发给自己的。当看到发出方IP地址是0.0.0.0,接收方是255.255.255.255,于是DHCP服务器知道”这个包是发给我的”,而其他计算机就可以丢弃这个包。
接下来,DHCP服务器读出这个包的数据内容,分配好IP地址,发送回去一个”DHCP响应”数据包。这个响应包的结构也是类似的,以太网标头的MAC地址是双方的网卡地址,IP标头的IP地址是DHCP服务器的IP地址(发出方)和255.255.255.255(接收方),UDP标头的端口是67(发出方)和68(接收方),分配给请求端的IP地址和本网络的具体参数则包含在Data部分。
新加入的计算机收到这个响应包,于是就知道了自己的IP地址、子网掩码、网关地址、DNS服务器等等参数
网络通信流程
本机获取
- 本机的IP地址:192.168.1.100
- 子网掩码:255.255.255.0
- 网关的IP地址:192.168.1.1
- DNS的IP地址:8.8.8.8
4.2 打开浏览器,访问
想要访问Google,在地址栏输入了网址:www.google.com。
dns协议(基于udp协议)

13台根dns:
A.root-servers.net198.41.0.4美国
B.root-servers.net192.228.79.201美国(另支持IPv6)
C.root-servers.net192.33.4.12法国
D.root-servers.net128.8.10.90美国
E.root-servers.net192.203.230.10美国
F.root-servers.net192.5.5.241美国(另支持IPv6)
G.root-servers.net192.112.36.4美国
H.root-servers.net128.63.2.53美国(另支持IPv6)
I.root-servers.net192.36.148.17瑞典
J.root-servers.net192.58.128.30美国
K.root-servers.net193.0.14.129英国(另支持IPv6)
L.root-servers.net198.32.64.12美国
M.root-servers.net202.12.27.33日本(另支持IPv6)
域名定义:http://jingyan.baidu.com/article/1974b289a649daf4b1f774cb.html
顶级域名:以.com,.net,.org,.cn等等属于国际顶级域名,根据目前的国际互联网域名体系,国际顶级域名分为两类:类别顶级域名(gTLD)和地理顶级域名(ccTLD)两种。类别顶级域名是 以"COM"、"NET"、"ORG"、"BIZ"、"INFO"等结尾的域名,均由国外公司负责管理。地理顶级域名是以国家或地区代码为结尾的域名,如"CN"代表中国,"UK"代表英国。地理顶级域名一般由各个国家或地区负责管理。
二级域名:二级域名是以顶级域名为基础的地理域名,比喻中国的二级域有,.com.cn,.net.cn,.org.cn,.gd.cn等.子域名是其父域名的子域名,比喻父域名是abc.com,子域名就是www.abc.com或者.abc.com.
一般来说,二级域名是域名的一条记录,比如alidiedie.com是一个域名,www.alidiedie.com是其中比较常用的记录,一般默认是用这个,但是类似.alidiedie.com的域名全部称作是alidiedie.com的二级
Socket(套接字编程)
看socket之前,先来回顾一下五层通讯流程:
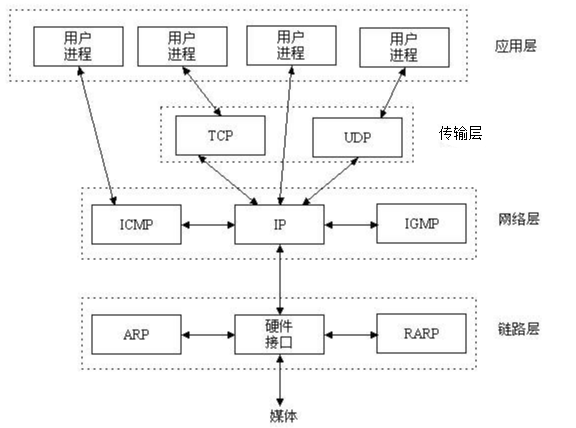
但实际上从传输层开始以及以下,都是操作系统帮咱们完成的,下面的各种包头封装的过程,用咱们去一个一个做么?NO!
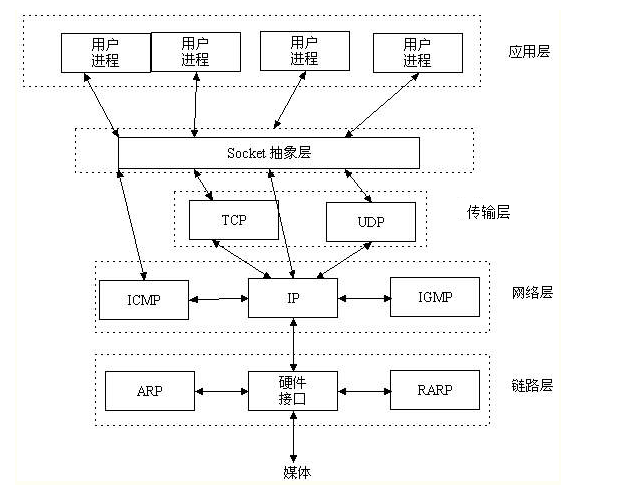
Socket又称为套接字,它是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。当我们使用不同的协议进行通信时就得使用不同的接口,还得处理不同协议的各种细节,这就增加了开发的难度,软件也不易于扩展(就像我们开发一套公司管理系统一样,报账、会议预定、请假等功能不需要单独写系统,而是一个系统上多个功能接口,不需要知道每个功能如何去实现的)。于是UNIX BSD就发明了socket这种东西,socket屏蔽了各个协议的通信细节,使得程序员无需关注协议本身,直接使用socket提供的接口来进行互联的不同主机间的进程的通信。这就好比操作系统给我们提供了使用底层硬件功能的系统调用,通过系统调用我们可以方便的使用磁盘(文件操作),使用内存,而无需自己去进行磁盘读写,内存管理。socket其实也是一样的东西,就是提供了tcp/ip协议的抽象,对外提供了一套接口,同过这个接口就可以统一、方便的使用tcp/ip协议的功能了。
其实站在你的角度上看,socket就是一个模块。我们通过调用模块中已经实现的方法建立两个进程之间的连接和通信。也有人将socket说成ip+port,因为ip是用来标识互联网中的一台主机的位置,而port是用来标识这台机器上的一个应用程序。 所以我们只要确立了ip和port就能找到一个应用程序,并且使用socket模块来与之通信。
Socket又称“套接字”,应用程序通常通过“套接字”向网络发出请求或者应答网络请求,使主机间或者一台计算机的进程间可以通讯
类似于操作系统将复杂丑陋的控制计算机硬件的操作封装成统一简单的接口,只需要使用者学会如何操作系统就可以简单快速的操作计算机硬件
套接字发展历史及分类
套接字起源于 20 世纪 70 年代加利福尼亚大学伯克利分校版本的 Unix,即人们所说的 BSD Unix。 因此,有时人们也把套接字称为“伯克利套接字”或“BSD 套接字”。一开始,套接字被设计用在同 一台主机上多个应用程序之间的通讯。这也被称进程间通讯,或 IPC。套接字有两种(或者称为有两个种族),分别是基于文件型的和基于网络型的。
基于文件类型的套接字家族
套接字家族的名字:AF_UNIX
unix一切皆文件,基于文件的套接字调用的就是底层的文件系统来取数据,两个套接字进程运行在同一机器,可以通过访问同一个文件系统间接完成通信
基于网络类型的套接字家族
套接字家族的名字:AF_INET
(还有AF_INET6被用于ipv6,还有一些其他的地址家族,不过,他们要么是只用于某个平台,要么就是已经被废弃,或者是很少被使用,或者是根本没有实现,所有地址家族中,AF_INET是使用最广泛的一个,python支持很多种地址家族,但是由于我们只关心网络编程,所以大部分时候我么只使用AF_INET)
TCP和UDP对比
TCP(Transmission Control Protocol)可靠的、面向连接的协议(eg:打电话)、传输效率低全双工通信(发送缓存&接收缓存)、面向字节流。使用TCP的应用:Web浏览器;文件传输程序。
UDP(User Datagram Protocol)不可靠的、无连接的服务,传输效率高(发送前时延小),一对一、一对多、多对一、多对多、面向报文(数据包),尽最大努力服务,无拥塞控制。使用UDP的应用:域名系统 (DNS);视频流;IP语音(VoIP)。
TCP协议下的socket
个生活中的场景。你要打电话给一个朋友,先拨号,朋友听到电话铃声后提起电话,这时你和你的朋友就建立起了连接,就可以讲话了。等交流结束,挂断电话结束此次交谈。 生活中的场景就解释了这工作原理。
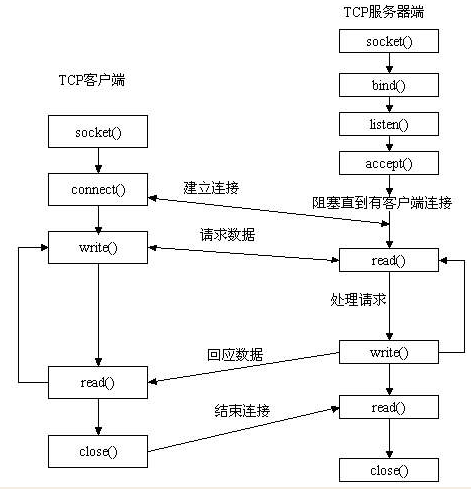
先从服务器端说起。服务器端先初始化Socket,然后与端口绑定(bind),对端口进行监听(listen),调用accept阻塞,等待客户端连接。在这时如果有个客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束
下面将介绍socket()模块函数用法
Python中,我们用socket()函数来创建套接字,语法格式如下:
socket.socket([family[,type[,proto]]])
import socket
socket.socket(socket_family,socket_type,protocal=0)
socket_family 可以是 AF_UNIX 或 AF_INET。socket_type 可以是 SOCK_STREAM 或 SOCK_DGRAM。protocol 一般不填,默认值为 0。
获取tcp/ip套接字
tcpSock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
获取udp/ip套接字
udpSock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
由于 socket 模块中有太多的属性。我们在这里破例使用了'from module import *'语句。使用 'from socket import *',我们就把 socket 模块里的所有属性都带到我们的命名空间里了,这样能 大幅减短我们的代码。
例如tcpSock = socket(AF_INET, SOCK_STREAM)
服务端套接字函数
s.bind() 绑定(主机,端口号)到套接字
s.listen() 开始TCP监听
s.accept() 被动接受TCP客户的连接,(阻塞式)等待连接的到来
客户端套接字函数
s.connect() 主动初始化TCP服务器连接
s.connect_ex() connect()函数的扩展版本,出错时返回出错码,而不是抛出异常
公共用途的套接字函数
s.recv() 接收TCP数据
s.send() 发送TCP数据(send在待发送数据量大于己端缓存区剩余空间时,数据丢失,不会发完)
s.sendall() 发送完整的TCP数据(本质就是循环调用send,sendall在待发送数据量大于己端缓存区剩余空间时,数据不丢失,循环调用send直到发完)
s.recvfrom() 接收UDP数据
s.sendto() 发送UDP数据
s.getpeername() 连接到当前套接字的远端的地址
s.getsockname() 当前套接字的地址
s.getsockopt() 返回指定套接字的参数
s.setsockopt() 设置指定套接字的参数
s.close() 关闭套接字
面向锁的套接字方法
s.setblocking() 设置套接字的阻塞与非阻塞模式
s.settimeout() 设置阻塞套接字操作的超时时间
s.gettimeout() 得到阻塞套接字操作的超时时间
面向文件的套接字的函数
s.fileno() 套接字的文件描述符
s.makefile() 创建一个与该套接字相关的文件
参数
# family: 套接字家族可以使AF_UNIX或者FA_INET
# type: 套接字类型可以根据市面向连接的还是非连接氛围SOCK_STREAM或SOCK_DGRAM.
# protocol: 一般默认为0.
Socket对象(内建)方法
| 函数 | 描述 |
|---|---|
| 服务器端套接字 | |
| s.bind() | 绑定地址(host,port)到套接字, 在AF_INET下,以元组(host,port)的形式表示地址。 |
| s.listen() | 开始TCP监听。backlog指定在拒绝连接之前,操作系统可以挂起的最大连接数量。该值至少为1,大部分应用程序设为5就可以了。 |
| s.accept() | 被动接受TCP客户端连接,(阻塞式)等待连接的到来 |
| 客户端套接字 | |
| s.connect() | 主动初始化TCP服务器连接,。一般address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。 |
| s.connect_ex() | connect()函数的扩展版本,出错时返回出错码,而不是抛出异常 |
| 公共用途的套接字函数 | |
| s.recv() | 接收TCP数据,数据以字符串形式返回,bufsize指定要接收的最大数据量。flag提供有关消息的其他信息,通常可以忽略。 |
| s.send() | 发送TCP数据,将string中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于string的字节大小。 |
| s.sendall() | 完整发送TCP数据,完整发送TCP数据。将string中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回None,失败则抛出异常。 |
| s.recvfrom() | 接收UDP数据,与recv()类似,但返回值是(data,address)。其中data是包含接收数据的字符串,address是发送数据的套接字地址。 |
| s.sendto() | 发送UDP数据,将数据发送到套接字,address是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。 |
| s.close() | 关闭套接字 |
| s.getpeername() | 返回连接套接字的远程地址。返回值通常是元组(ipaddr,port)。 |
| s.getsockname() | 返回套接字自己的地址。通常是一个元组(ipaddr,port) |
| s.setsockopt(level,optname,value) | 设置给定套接字选项的值。 |
| s.getsockopt(level,optname[.buflen]) | 返回套接字选项的值。 |
| s.settimeout(timeout) | 设置套接字操作的超时期,timeout是一个浮点数,单位是秒。值为None表示没有超时期。一般,超时期应该在刚创建套接字时设置,因为它们可能用于连接的操作(如connect()) |
| s.gettimeout() | 返回当前超时期的值,单位是秒,如果没有设置超时期,则返回None。 |
| s.fileno() | 返回套接字的文件描述符。 |
| s.setblocking(flag) | 如果flag为0,则将套接字设为非阻塞模式,否则将套接字设为阻塞模式(默认值)。非阻塞模式下,如果调用recv()没有发现任何数据,或send()调用无法立即发送数据,那么将引起socket.error异常。 |
| s.makefile() | 创建一个与该套接字相关连的文件 |
Example1
# server.py
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',9000))
# 等着别人连我
sk.listen()
# 等待客户链接我,并且会有一个链接地址
conn,addr = sk.accept()
print(conn,"CCCCCCCCCOOO")
print(addr,"IPAIP")
conn.send(b'hello')
msg = conn.recv(1024)
print(msg)
# 最多接收1024字节数据
conn.recv(1024)
conn.close()
# 把他关掉,不让别人链接了
sk.close()
# client.py
import socket
sk = socket.socket()
sk.connect(('127.0.0.1',9000))
msg = sk.recv(1024)
print(msg)
sk.send(b'byebyte')
sk.close()
Example2
服务端
# 我们使用socket模块的socket函数来创建一个socket对象,socket对象可以通过调用其他函数来设置一个socket服务.
# 现在我们可以通过bind(hostname,port)函数来指定服务的port(端口)
# 接着,我们调用socket对象的acoepl方法,该方法等待客户端的连接,并返回connection对象,表示已连接客户端。
#!/usr/bin/python3
# 文件名:server.py
# 导入socket、sys模块
import socket
import sys
# 创建socket对象
serversocket = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# 获取本机主机名
host = socket.gethostname()
port = 9999
# 绑定端口号
serversocket.bind((host,port))
# 设置最大连接数,超过后排队
serversocket.listen(5)
while True:
# 建立客户端连接
clientsocket,addr = serversocket.accept()
print("连接地址: %s" % str(addr))
msg='欢迎访问YouMenDemo!'+ "\r\n"
clientsocket.send(msg.encode('utf-8'))
clientsocket.close()
客户端
# 接下来我们写一个简单的客户端实例连接以上创建的服务,端口号为9999
# socket.connect(hostname,port)方法打开一个TCP连接到主机为hostname端口为port的服务商,
# 连接后我们就可以从服务端获取数据,记住,操作完成后需要关闭连接.
#!/usr/bin/python3
# 文件名:client.py
import socket
import sys
# 创建socket对象
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# 获取本地主机名
host = socket.gethostname()
# 设置端口号
port = 9999
# 连接服务,指定主机和端口
s.connect((host,port))
# 接受小于1024字节的数据
msg = s.recv(1024)
s.close()
print(msg.decode('utf-8'))
现在我们打开两个终端,执行server.py文件,另一个终端执行client.py文件,就会出现如下所示
# 欢迎访问YouMenDemo!
# 同时打开第一个终端,会出现以下信息输出:
# 连接地址: ('172.19.0.2', 51157)
Example3
TCP和多个客户端通信
# Server端
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',9005))
sk.listen()
while True:
conn,addr = sk.accept()
print("conn :" ,conn)
while True:
send_msg = input('>>>')
if send_msg.upper() == 'Q':
break
conn.send(send_msg.encode('utf-8'))
msg = conn.recv(1024).decode('utf-8')
if msg.upper() == 'Q':
break
print(msg)
conn.close()
sk.close()
# Client端
import socket
sk = socket.socket()
sk.connect(('127.0.0.1',9005))
while True:
msg = sk.recv(1024)
msg2 = msg.decode('utf-8')
if msg2.upper() == 'Q':break
print(msg,msg2)
send_msg = input('>>>')
if send_msg.upper() == 'Q':
break
sk.send(send_msg.encode('utf-8'))
sk.close()
Python Internet模块
以下列出了Python网络编程的一些重要模块
| 协议 | 功能用处 | 端口号 | Python 模块 |
|---|---|---|---|
| HTTP | 网页访问 | 80 | httplib, urllib, xmlrpclib |
| NNTP | 阅读和张贴新闻文章,俗称为"帖子" | 119 | nntplib |
| FTP | 文件传输 | 20 | ftplib, urllib |
| SMTP | 发送邮件 | 25 | smtplib |
| POP3 | 接收邮件 | 110 | poplib |
| IMAP4 | 获取邮件 | 143 | imaplib |
| Telnet | 命令行 | 23 | telnetlib |
| Gopher | 信息查找 | 70 | gopherlib, urllib |
Example2
TCP服务端
服务端结构
tcps = socket() #创建服务器套接字
tcps.bind() #把地址绑定到套接字
tcps.listen() #监听链接
while True: #服务器无限循环
tcpc = tcps.accept() #接受客户端链接
while True: #通讯循环
tcpc.recv()/tcpc.send() #对话(接收与发送)
tcpc.close() #关闭客户端套接字
tcps.close() #关闭服务器套接字(可选)
时间戳服务端实例
#!/usr/bin/python3
# -*-coding:utf-8 -*-
from socket import *
import time
COD = 'utf-8'
HOST = '192.168.164.141' # 主机ip
PORT = 21566 # 软件端口号
BUFSIZ = 1024
ADDR = (HOST, PORT)
SIZE = 10
tcpS = socket(AF_INET, SOCK_STREAM) # 创建socket对象
tcpS.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) #加入socket配置,重用ip和端口
tcpS.bind(ADDR) # 绑定ip端口号
tcpS.listen(SIZE) # 设置最大链接数
while True:
print("服务器启动,监听客户端链接")
conn, addr = tcpS.accept()
print("链接的客户端", addr)
while True:
try:
data = conn.recv(BUFSIZ) # 读取已链接客户的发送的消息
except Exception:
print("断开的客户端", addr)
break
print("客户端发送的内容:",data.decode(COD))
if not data:
break
msg = time.strftime("%Y-%m-%d %X") #获取结构化事件戳
msg1 = '[%s]:%s' % (msg, data.decode(COD))
conn.send(msg1.encode(COD)) #发送消息给已链接客户端
conn.close() #关闭客户端链接
tcpS.closel()
TCP客户端
客户端结构
tcpc = socket() # 创建客户端套接字
tcpc.connect() # 尝试连接服务器
while True: # 通讯循环
tcpc.send()/tcpc.recv() # 对话(发送/接收)
tcpc.close() # 关闭客户套接字
时间戳客户端实例
#!/usr/bin/python3
# -*-coding:utf-8 -*-
from socket import *
from time import ctime
HOST = '192.168.164.141' #服务端ip
PORT = 21566 #服务端端口号
BUFSIZ = 1024
ADDR = (HOST, PORT)
tcpCliSock = socket(AF_INET, SOCK_STREAM) #创建socket对象
tcpCliSock.connect(ADDR) #连接服务器
while True:
data = input('>>').strip()
if not data:
break
tcpCliSock.send(data.encode('utf-8')) #发送消息
data = tcpCliSock.recv(BUFSIZ) #读取消息
if not data:
break
print(data.decode('utf-8'))
tcpCliSock.close() #关闭客户端
粘包现象
讲粘包之前先看看socket缓冲区的问题:
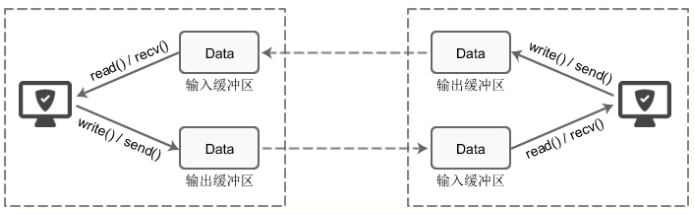
每个 socket 被创建后,都会分配两个缓冲区,输入缓冲区和输出缓冲区。
write()/send() 并不立即向网络中传输数据,而是先将数据写入缓冲区中,再由TCP协议将数据从缓冲区发送到目标机器。一旦将数据写入到缓冲区,函数就可以成功返回,不管它们有没有到达目标机器,也不管它们何时被发送到网络,这些都是TCP协议负责的事情。
TCP协议独立于 write()/send() 函数,数据有可能刚被写入缓冲区就发送到网络,也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络,这取决于当时的网络情况、当前线程是否空闲等诸多因素,不由程序员控制。
read()/recv() 函数也是如此,也从输入缓冲区中读取数据,而不是直接从网络中读取。
这些I/O缓冲区特性可整理如下:
1.I/O缓冲区在每个TCP套接字中单独存在;
2.I/O缓冲区在创建套接字时自动生成;
3.即使关闭套接字也会继续传送输出缓冲区中遗留的数据;
4.关闭套接字将丢失输入缓冲区中的数据。
输入输出缓冲区的默认大小一般都是 8K,可以通过 getsockopt() 函数获取:
1.unsigned optVal;
2.int optLen = sizeof(int);
3.getsockopt(servSock, SOL_SOCKET, SO_SNDBUF,(char*)&optVal, &optLen);
4.printf("Buffer length: %d\n", optVal);
socket缓冲区解释
socket缓存区的详细解释:
发送端可以是一K一K地发送数据,而接收端的应用程序可以两K两K地提走数据,当然也有可能一次提走3K或6K数据,或者一次只提走几个字节的数据,也就是说,应用程序所看到的数据是一个整体,或说是一个流(stream),一条消息有多少字节对应用程序是不可见的,因此TCP协议是面向流的协议,这也是容易出现粘包问题的原因。而UDP是面向消息的协议,每个UDP段都是一条消息,应用程序必须以消息为单位提取数据,不能一次提取任意字节的数据,这一点和TCP是很不同的。怎样定义消息呢?可以认为对方一次性write/send的数据为一个消息,需要明白的是当对方send一条信息的时候,无论底层怎样分段分片,TCP协议层会把构成整条消息的数据段排序完成后才呈现在内核缓冲区。
例如基于tcp的套接字客户端往服务端上传文件,发送时文件内容是按照一段一段的字节流发送的,在接收方看了,根本不知道该文件的字节流从何处开始,在何处结束
所谓粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
此外,发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。若连续几次需要send的数据都很少,通常TCP会根据优化算法把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据。
TCP(transport control protocol,传输控制协议)是面向连接的,面向流的,提供高可靠性服务。收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 即面向流的通信是无消息保护边界的。
UDP(user datagram protocol,用户数据报协议)是无连接的,面向消息的,提供高效率服务。不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息),这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。
tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住,而udp是基于数据报的,即便是你输入的是空内容(直接回车),那也不是空消息,udp协议会帮你封装上消息头,实验略
udp的recvfrom是阻塞的,一个recvfrom(x)必须对唯一一个sendinto(y),收完了x个字节的数据就算完成,若是y>x数据就丢失,这意味着udp根本不会粘包,但是会丢数据,不可靠
tcp的协议数据不会丢,没有收完包,下次接收,会继续上次继续接收,己端总是在收到ack时才会清除缓冲区内容。数据是可靠的,但是会粘包。
只有TCP有粘包现象,UDP永远不会粘包
# 只出现在TCP协议中,因为TCP协议多条消息之间没有边界,并且还有一大堆优化算法.
# 两种情况会粘包:
# 发送端: 接收方没有及时接受缓冲区的包,造成多个包接受(客户端发送了一段数据,服务端只收了一部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
# 接受端: 发送端需要等缓冲区满才能发送出去,造成粘包(发送数据时间间隔很短,数据也很小,会合在一起,产生粘包)
UDP协议
数据报协议
# 1. udp协议客户端允许发空
# 2. udp协议不会粘包
# 3. udp协议服务端不存在的情况下,客户端照样不会报错
Example1
# Socket_Server_UDP.py
import socket
sk = socket.socket(type=socket.SOCK_DGRAM)
server = ('127.0.0.1',8089)
while True:
msg = input('>>>')
if msg.upper() == 'Q': break
sk.sendto(b'ip,port,server',server)
msg = sk.recv(1024)
if msg.upper() == 'Q': break
print(msg)
# Socket_Client_UDP.py
import socket
sk = socket.socket(type=socket.SOCK_DGRAM)
sk.bind(('127.0.0.1',8089))
while True:
msg,addr = sk.recvfrom(1024)
print(msg)
msg=input(">>>")
sk.sendto(msg.encode('utf-8'),addr)
Example2
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# 服务端
import socket
server = socket.socket(type=socket.SOCK_DGRAM)
server.bind(('127.0.0.1',8000))
msg,addr=server.recvfrom(1024)
print(msg.decode('utf-8'))
server.send(b'hello',addr)
server.close()
#!/usr/bin/env python3
#-*- coding:utf-8 -*-
# 客户端
import socket
client=socket.socket(type=socket.SOCK_DGRAM)
server_addr=('127.0.0.1',8000)
client.sendto(b'hello server baby!',server_addr)
msg,addr=client.recvfrom(1024)
print(msg,addr)
"""
# udp特点 >>> 无链接,类似于发短信,发了就行对方爱回不回,没有任何关系
# 将服务端关了,客户端起起来照样能够发数据。因为不需要考虑服务端能不能收到
"""
# 验证udp协议有无粘包问题
import socket
server = socket.socket(type=socket.SOCK_DGRAM)
server.bind(('127.0.0.1',8080))
print(server.recvfrom(1024))
print(server.recvfrom(1024))
print(server.recvfrom(1024))
import socket
client = socket.socket(type=socket.SOCK_DGRAM)
server_addr = ('127.0.0.1',8080)
client.sendto(b'hello',server_addr)
client.sendto(b'hello',server_addr)
client.sendto(b'hello',server_addr)
给予UDP实现简易版QQ
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# 服务端
import socket
server = socket.socket(type=socket.SOCK_DGRAM)
server.bind(('127.0.0.1',8000))
while True:
msg,addr=server.recvfrom(1024)
print(addr)
print(msg.decode('utf-8'))
info=input('>>>:').encode('utf-8')
server.sendto(info,addr)
server.close()
#!/usr/bin/env python3
#-*- coding:utf-8 -*-
# 客户端
import socket
client=socket.socket(type=socket.SOCK_DGRAM)
server_addr=('127.0.0.1',8000)
while True:
info=input('>>>:')
info=('来自客户端1的消息:%s'%info).encode('utf-8')
client.sendto(info,server_addr)
msg,addr=client.recvfrom(1024)
print(msg.decode('utf-8'),addr)
client.close()
总结:
TCP协议类似于打电话
UDP协议类似于发短信
TCP完成文件上传
server.py
import socket
import subprocess
import json
import struct
phone = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
phone.bind(('127.0.0.1', 8001))
phone.listen(5)
file_positon = r'd:\上传下载'
conn, client_addr = phone.accept()
# # 1,接收固定4个字节
ret = conn.recv(4)
#
# 2,利用struct模块将ret反解出head_dic_bytes的总字节数。
head_dic_bytes_size = struct.unpack('i',ret)[0]
#
# 3,接收 head_dic_bytes数据。
head_dic_bytes = conn.recv(head_dic_bytes_size)
# 4,将head_dic_bytes解码成json字符串格式。
head_dic_json = head_dic_bytes.decode('utf-8')
# 5,将json字符串还原成字典模式。
head_dic = json.loads(head_dic_json)
file_path = os.path.join(file_positon,head_dic['file_name'])
with open(file_path,mode='wb') as f1:
data_size = 0
while data_size < head_dic['file_size']:
data = conn.recv(1024)
f1.write(data)
data_size += len(data)
conn.close()
phone.close()
client.py
import socket
import struct
import json
import os
phone = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 买电话
phone.connect(('127.0.0.1', 8001)) # 与客户端建立连接, 拨号
# 1 制定file_info
file_info = {
'file_path': r'D:\lnh.python\pyproject\PythonReview\网络编程\08 文件的上传下载\low版\aaa.mp4',
'file_name': 'aaa.mp4',
'file_size': None,
}
# 2 获取并设置文件大小
file_info['file_size'] = os.path.getsize(file_info['file_path'])
# 2,利用json将head_dic 转化成字符串
head_dic_json = json.dumps(file_info)
# 3,将head_dic_json转化成bytes
head_dic_bytes = head_dic_json.encode('utf-8')
# 4,将head_dic_bytes的大小转化成固定的4个字节。
ret = struct.pack('i', len(head_dic_bytes)) # 固定四个字节
# 5, 发送固定四个字节
phone.send(ret)
# 6 发送head_dic_bytes
phone.send(head_dic_bytes)
# 发送文件:
with open(file_info['file_path'],mode='rb') as f1:
data_size = 0
while data_size < file_info['file_size']:
# f1.read() 不能全部读出来,而且也不能send全部,这样send如果过大,也会出问题,保险起见,每次至多send(1024字节)
every_data = f1.read(1024)
data_size += len(every_data)
phone.send(every_data)
phone.close()
验证文件合法性
server.py
import os
import socket
import hashlib
secret_key = b'alex_sb'
sk = socket.socket()
sk.bind(('127.0.0.1',9001))
sk.listen()
conn,addr = sk.accept()
# 创建一个随机的字符串
rand = os.urandom(32)
# 发送随机字符串
conn.send(rand)
# 根据发送的字符串 + secrete key 进行摘要
sha = hashlib.sha1(secret_key)
sha.update(rand)
res = sha.hexdigest()
# 等待接收客户端的摘要结果
res_client = conn.recv(1024).decode('utf-8')
# 做比对
if res_client == res:
print('是合法的客户端')
# 如果一致,就显示是合法的客户端
# 并可以继续操作
conn.send(b'hello')
else:
conn.close()
# 如果不一致,应立即关闭连接
client.py
import socket
import hashlib
secret_key = b'alex_sb979'
sk = socket.socket()
sk.connect(('127.0.0.1',9001))
# 接收客户端发送的随机字符串
rand = sk.recv(32)
# 根据发送的字符串 + secret key 进行摘要
sha = hashlib.sha1(secret_key)
sha.update(rand)
res = sha.hexdigest()
# 摘要结果发送回server端
sk.send(res.encode('utf-8'))
# 继续和server端进行通信
msg = sk.recv(1024)
print(msg)
socketserver实现并发
为什么要用socketserver?我们之前写的tcp协议的socket是不是一次只能和一个客户端通信,如果用socketserver可以实现和多个客户端通信。它是在socket的基础上进行了一层封装,也就是说底层还是调用的socket,在py2.7里面叫做SocketServer也就是大写了两个S,在py3里面就小写了。后面我们要写的FTP作业,需要用它来实现并发,也就是同时可以和多个客户端进行通信,多个人可以同时进行上传下载等。
那么我们先看socketserver怎么用呢,然后在分析,先看下面的代码
import socketserver # 引入模块
class MyServer(socketserver.BaseRequestHandler): # 类名随便定义,但是必须继承socketserver.BaseRequestHandler此类
def handle(self): # 写一个handle方法,固定名字
while 1:
# self.request 相当于conn管道
from_client_data = self.request.recv(1024).decode('utf-8')
print(from_client_data)
to_client_data = input('服务端回信息:').strip()
self.request.send(to_client_data)
if __name__ == '__main__':
ip_port = ('127.0.0.1',8080)
# socketserver.TCPServer.allow_reuse_address = True # 允许端口重用
server = socketserver.ThreadingTCPServer(ip_port,MyServer)
# 对 socketserver.ThreadingTCPServer 类实例化对象,将ip地址,端口号以及自己定义的类名传入,并返回一个对象
server.serve_forever() # 对象执行serve_forever方法,开启服务端

具体流程分析:
# 在整个socketserver这个模块中,其实就干了两件事情:1、一个是循环建立链接的部分,每个客户链接都可以连接成功 2、一个通讯循环的部分,就是每个客户端链接成功之后,要循环的和客户端进行通信。
# 看代码中的:server=socketserver.ThreadingTCPServer(('127.0.0.1',8090),MyServer)
# 还记得面向对象的继承吗?来,大家自己尝试着看看源码:
# 查找属性的顺序:ThreadingTCPServer->ThreadingMixIn->TCPServer->BaseServer
# 实例化得到server,先找ThreadMinxIn中的__init__方法,发现没有init方法,然后找类ThreadingTCPServer的__init__,在TCPServer中找到,在里面创建了socket对象,进而执行server_bind(相当于bind),server_active(点进去看执行了listen)
# 找server下的serve_forever,在BaseServer中找到,进而执行self._handle_request_noblock(),该方法同样是在BaseServer中
# 执行self._handle_request_noblock()进而执行request, client_address = self.get_request()(就是TCPServer中的self.socket.accept()),然后执行self.process_request(request, client_address)
# 在ThreadingMixIn中找到process_request,开启多线程应对并发,进而执行process_request_thread,执行self.finish_request(request, client_address)
# 上述四部分完成了链接循环,本部分开始进入处理通讯部分,在BaseServer中找到finish_request,触发我们自己定义的类的实例化,去找__init__方法,而我们自己定义的类没有该方法,则去它的父类也就是BaseRequestHandler中找....
# 源码分析总结:
# 基于tcp的socketserver我们自己定义的类中的
self.server即套接字对象
self.request即一个链接
self.client_address即客户端地址
基于udp的socketserver我们自己定义的类中的
self.request是一个元组(第一个元素是客户端发来的数据,第二部分是服务端的udp套接字对象),如(b'adsf', <socket.socket fd=200, family=AddressFamily.AF_INET, type=SocketKind.SOCK_DGRAM, proto=0, laddr=('127.0.0.1', 8080)>)
self.client_address即客户端地址
```12 . Python3之网络编程的更多相关文章
- 2015/12/14 Python网络编程,TCP/IP客户端和服务器初探
一直不是很清楚服务器的定义,对于什么是服务器/客户端架构也只有一个模糊的感觉.最近开始学习,才明白一些什么服务器和客户端的关系. 所谓的服务器,就是提供服务的东西,它是一个硬件或者软件,可以向一个或者 ...
- Python3 socket网络编程(一)
Socket的定义 套接字是为特定网络协议(例如TCP/IP,ICMP/IP,UDP/IP等)套件对上的网络应用程序提供者提供当前可移植标准的对象.它们允许程序接受并进行连接,如发送和接受数据.为了建 ...
- Python3 Socket网络编程
Socket又称"套接字",应用程序通常通过"套接字"向网络发出请求或者应答网络请求,使主机间或者一台计算机上的进程间可以通讯. socket起源于UNIX,在 ...
- Python3常用网络编程模块介绍
一.socket模块 网络服务都是建立在socket基础之上的,socket是网络连接端点,是网络的基础:每个socket都被绑定到指定的IP和端口上: 1.首先使用socket(family=AF_ ...
- Linux网络编程学习路线
转载自:https://blog.csdn.net/lianghe_work/article 一.网络应用层编程 1.Linux网络编程01——网络协议入门 2.Linux网络编程02——无连接和 ...
- 多线程编程和Java网络编程
1. 线程概述 多任务处理有两种类型:基于进程.基于线程(进程是指一种“自包容”的运行程序,有自己的地址空间; 线程是进程内部单一的一个顺序控制流) 基于进程的特点是允许计算机同时运行两个或更多的程序 ...
- [转]12篇学通C#网络编程——第二篇 HTTP应用编程(上)
本文转自:http://www.cnblogs.com/huangxincheng/archive/2012/01/09/2316745.html 我们学习网络编程最熟悉的莫过于Http,好,我们就从 ...
- core java 10~12(多线程 & I/O & Network网络编程)
MODULE 10 Threads 多线程-------------------------------- 进程: 计算机在运行过程中的任务单元,CPU在一个时间点上只能执行一个进程,但在一个时间段上 ...
- 12篇学通C#网络编程
转自:http://www.cnblogs.com/huangxincheng/archive/2012/01/03/2310779.html 在C#的网络编程中,进程和线程是必备的基础知识,同时也是 ...
随机推荐
- python学习笔记-零碎知识点
1. 绝对值 abs(-4) 结果: 4 2.
- 某科学的PID算法学习笔记
最近,在某社团的要求下,自学了PID算法.学完后,深切地感受到PID算法之强大.PID算法应用广泛,比如加热器.平衡车.无人机等等,是自动控制理论中比较容易理解但十分重要的算法. 下面是博主学习过程中 ...
- hdu2336 (匈牙利最大匹配+二分)
Describe 这是一个简单的游戏,在一个n*n的矩阵中,找n个数使得这n个数都在不同的行和列里并且要求这n个数中的最大值和最小值的差值最小. Input 输入一个整数T表示T组数据. 对于每组数据 ...
- 2018-08-27 jq筛选选择器
筛选选择器:为了辅助选择器更简便.快速的找到元素: 1.过滤 eq(n) -> 第n个元素(从零开始) $('h1').eq(2) // 第三个h1 first() -> 第一个元素 la ...
- 在IntelliJ IDEA中创建和运行java/scala/spark程序
本文将分两部分来介绍如何在IntelliJ IDEA中运行Java/Scala/Spark程序: 基本概念介绍 在IntelliJ IDEA中创建和运行java/scala/spark程序 基本概念介 ...
- React 中使用sass
npm install node-sass-chokidar --save-dev package.json添加两行: "scripts": { 2 "build-css ...
- 用JetBrains PyCharm 开发工具写一个简单python案例
import urllib.request import re #解析html的内容 def getHtml(url): page=urllib.request.urlopen(url) html=p ...
- MySQL事务操作
在 MySQL 命令行的默认设置下,事务都是自动提交的,即执行 SQL 语句后就会马上执行 COMMIT 操作.因此要显式地开启一个事务务须使用命令 BEGIN 或 START TRANSACTION ...
- 8.3 Go channel
8.3 Go channel 在Go语言中,关键字go的引入使得Go语言并发编程更加简单而优雅,但是并发编程的复杂性,以及时刻关注并发编程容易出现的问题需要时刻警惕. 并发编程的难度在于协调,然而协调 ...
- 01 基础版web框架
01 基础版web框架 服务器server端python程序(基础版): import socket server=socket.socket() server.bind(("127.0.0 ...