Web Scraper 高级用法——抓取属性信息 | 简易数据分析 16

这是简易数据分析系列的第 16 篇文章。
这期课程我们讲一个用的较少的 Web Scraper 功能——抓取属性信息。
网页在展示信息的时候,除了我们看到的内容,其实还有很多隐藏的信息。我们拿豆瓣电影250举个例子:
电影图片正常显示的时候是这个样子:

如果网络异常,图片加载失败,就会显示图片的默认文案,这个文案其实就是这个图片的属性信息:

我们查看一下这个结构的 HTML(查看方法可见 CSS 选择器的使用的第一节内容),就会发现图片的默认文案其实就是这个 <img/> 标签的 alt 属性:

我们可以看一下 HTML 文档里对 alt 属性的描述:
alt 属性是一个必需的属性,它规定在图像无法显示时的替代文本
在 web scraper 里,我们可以利用 Element attribute 属性来抓取这种属性信息。
因为这次的内容比较简单,新建 sitemap 这一步我就先省略了,我们直接上来使用 Element attribute 抓取数据。
我们把 Type 选为 Element attribute,然后用 Selector 选中图片这个元素:
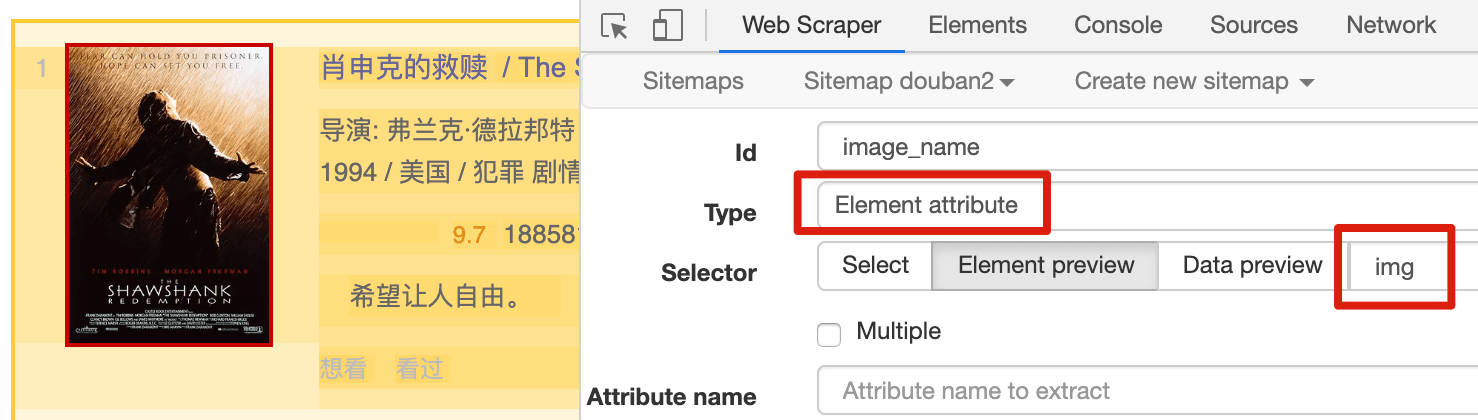
Element attribute 会多一个选项——Attribute name,我们在这个输入框里输入我们要抓取的属性名字。
观察一下这个 img 标签的属性,有 alt(替换文本)、width(图片宽度)和 src(图片链接)3 种:

这里我先输入 alt,表示抓取图片的替代文本:

还可以输入 src,表示抓取图片的链接:

也可以输入 width,抓取图片宽度:

通过 Element attribute 这个选择器,我们就可以抓取一些网页没有直接展示出来的数据信息,非常的方便。
sitemap 分享
{"_id":"douban2","startUrl":["https://movie.douban.com/top250?start=0&filter="],"selectors":[{"id":"ele","type":"SelectorElement","parentSelectors":["_root"],"selector":".grid_view li","multiple":true,"delay":0},{"id":"image_name","type":"SelectorElementAttribute","parentSelectors":["ele"],"selector":"img","multiple":false,"extractAttribute":"alt","delay":0}]}
推荐阅读
Web Scraper 高级用法——CSS 选择器的使用 | 简易数据分析 15
联系我
因为文章发在各大平台上,账号较多不能及时回复评论和私信,有问题可关注公众号 ——「卤蛋实验室」,(或 wx 搜索 egglabs)关注上车防失联。

Web Scraper 高级用法——抓取属性信息 | 简易数据分析 16的更多相关文章
- Web Scraper 高级用法——使用 CouchDB 存储数据 | 简易数据分析 18
这是简易数据分析系列的第 18 篇文章. 利用 web scraper 抓取数据的时候,大家一定会遇到一个问题:数据是乱序的.在之前的教程里,我建议大家利用 Excel 等工具对数据二次加工排序,但还 ...
- Web Scraper 翻页——控制链接批量抓取数据(Web Scraper 高级用法)| 简易数据分析 05
这是简易数据分析系列的第 5 篇文章. 上篇文章我们爬取了豆瓣电影 TOP250 前 25 个电影的数据,今天我们就要在原来的 Web Scraper 配置上做一些小改动,让爬虫把 250 条电影数据 ...
- 简易数据分析 12 | Web Scraper 翻页——抓取分页器翻页的网页
这是简易数据分析系列的第 12 篇文章. 前面几篇文章我们介绍了 Web Scraper 应对各种翻页的解决方法,比如说修改网页链接加载数据.点击"更多按钮"加载数据和下拉自动加载 ...
- Web Scraper 高级用法——利用正则表达式筛选文本信息 | 简易数据分析 17
这是简易数据分析系列的第 17 篇文章. 学习了这么多课,我想大家已经发现了,web scraper 主要是用来爬取文本信息的. 在爬取的过程中,我们经常会遇到一个问题:网页上的数据比较脏,我们只需要 ...
- 简易数据分析 15 | Web Scraper 高级用法——CSS 选择器的使用
这是简易数据分析系列的第 15 篇文章. 年末事情比较忙,很久不更新了,后台一直有读者催更,我看了一些读者给我的私信,发现一些通用的问题,所以单独写篇文章,介绍一些 Web Scraper 的进阶用法 ...
- 简易数据分析 10 | Web Scraper 翻页——抓取「滚动加载」类型网页
这是简易数据分析系列的第 10 篇文章. 友情提示:这一篇文章的内容较多,信息量比较大,希望大家学习的时候多看几遍. 我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏 ...
- Fiddler高级用法-抓取手机app数据包
在上一篇中介绍了Fiddler的基本使用方法.通过上一篇的操作我们可以直接抓取浏览器的数据包.但在APP测试中,我们需要抓取手机APP上的数据包,应该怎么操作呢? Andriod配置方法 1)确保手机 ...
- 简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
这是简易数据分析系列的第 4 篇文章. 今天我们开始数据抓取的第一课,完成我们的第一个爬虫.因为是刚刚开始,操作我会讲的非常详细,可能会有些啰嗦,希望各位不要嫌弃啊:) 有人之前可能学过一些爬虫知识, ...
- 网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(3): 抓取amazon.com价格
通过上一篇随笔的处理,我们已经拿到了书的书名和ISBN码.(网络爬虫: 从allitebooks.com抓取书籍信息并从amazon.com抓取价格(2): 抓取allitebooks.com书籍信息 ...
随机推荐
- unless|until|LABEL|{}|last|next|redo| || |//|i++|++i
#!/usr/bin/perl use strict; use warnings; $_ = 'oireqo````'; unless($_ =~ /^a/m){print "no matc ...
- Multiple alleles|an intuitive argument|
I.5 Multiple alleles. 由两个等位基因拓展到多个等位基因,可以得到更多种二倍体基因型: 所以单个等位基因的概率(用i代指某个基因,pi*是该基因的频率)是(以计数的方法表示) 所以 ...
- Python基础——类new方法与单例模式
介绍: new方法是类中魔术方法之一,他的作用是给类实例化开辟一个内存地址,并返回一个实例化,再由__init__对这个实例进行初始化,故它的执行肯定就是在初始化方法__init__之前了.new方法 ...
- centos 7 安装及配置vsftpd
一.防火墙开放21端口 二.创建FTP用户,创建完用户后在/etc/passwd里是这样呈现的:ftpuser:x:1008:1008::/var/www/html:/sbin/nologin 三.y ...
- 22)PHP,数组排序函数
详情见: 手册:函数参考-->变量和类型相关扩展-->数组--->对数组进行排序
- Qt LNK1112: 模块计算机类型“x64”与目标计算机类型“X86”冲突问题
解决方法:1.找到选项: 2.点击构建套件kit,选择x86_amd64,之后便不会出现类似问题了
- scala slick mysql utf8mb4 支持
语言 scala sql包 slick 3.2.0 数据库 mysql https://stackoverflow.com/questions/36741141/scala-slick-jdbc ...
- rest framework-restful介绍-长期维护
############### django框架-rest framework ############### # django rest framework 框架 # 为什么学习这个res ...
- UML Learning
在建筑业中,建模是一项经过检验并被广泛接受的工程技术,建立房屋和大厦的建筑模型,能帮助用户得到实际建筑物的印象.在软件建模中也具有同样的作用,建模提供了系统的蓝图. 建模是为了能够更好地理解正在开发的 ...
- getRandomInt getRandomString
import java.util.concurrent.ThreadLocalRandom; private static final String AB = "ABCDEFGHIJKLMN ...