【真相揭秘】requests获取网页编码乱码本质
有没有被网页编码抓狂,怎么转都是乱码。
通过查看requests源代码,才发现是库本身历史原因造成的。
作者是严格http协议标准写这个库的,《HTTP权威指南》里第16章国际化里提到,如果HTTP响应中Content-Type字段没有指定charset,则默认页面是'ISO-8859-1'编码。
这处理英文页面当然没有问题,但是中文页面,特别是那些不规范的页面,就会有乱码了!
比如分析jd.com 页面为gbk编码,问题就出在这里。
chardet库监测编码却是GB2312,两种编码虽然兼容的,但用GB2312解码gbk编码的网页字节串会运行错误!
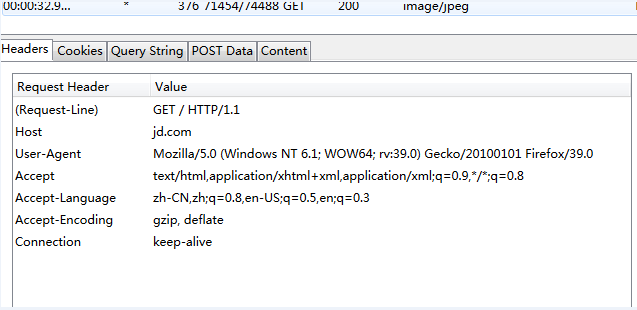

reqponse header只指定了type,但是没有指定编码(一般现在页面编码都直接在html页面中)。所有该函数就直接返回'ISO-8859-1'。
# test1
In [1]: r = requests.get('https://www.baidu.com/')
In [2]: r.encoding
Out[2]: 'ISO-8859-1'
In [3]: type(r.text)
Out[3]: unicode
In [4]: type(r.content)
Out[4]: str
In [5]: r.apparent_encoding
Out[5]: 'utf-8'
In [6]: chardet.detect(r.content)
Out[6]: {'confidence': 0.99, 'encoding': 'utf-8'}
在requests获取网页的编码格式时,有两种方式encoding和apparent_encoding,结果也不同,
推荐apparent_encoding,常规写法
url='xxx'
req =requests.get(url)
req.encoding=req.apparent_encoding
print(req.text)
总之一句话,遇到乱码加上apparent_encoding就完事了。
参考
https://www.cnblogs.com/emmm/p/9792832.html
https://www.cnblogs.com/bitpeng/p/4748872.html
【真相揭秘】requests获取网页编码乱码本质的更多相关文章
- python获取网页编码问题(encoding和apparent_encoding)
在requests获取网页的编码格式时,有两种方式,而结果也不同,通常用apparent_encoding更合适 注:推荐一个大佬写的关于获取网页编码格式以及requests中text()和conte ...
- Python 2.7.3 urllib2.urlopen 获取网页出现乱码解决方案
出现乱码的原因是,网页服务端有bug,它硬性使用使用某种特定的编码方案,而并没有按照客户端的请求头的编码要求来发送编码. 解决方案:使用chardet来猜测网页编码. 1.去chardet官网下载ch ...
- java根据URL获取网页编码
由于很多原因,我们要获取网页的编码(多半是写批量抓取的脚本吧...嘻嘻嘻) 注意: 如果你的目的是获取不乱码的网页内容(而不是根据网址发送post请求获取返回值),切记切记,移步这里 java根据UR ...
- asp.net 利用HttpWebRequest自动获取网页编码并获取网页源代码
/// <summary> /// 获取源代码 /// </summary> /// <param name="url"></param& ...
- 解决requests获取源代码时中文乱码问题
用requests获取源代码时,如果是中文网页,就可能会出现乱码,下面我以中关村的网站为例: import requests url = 'http://desk.zol.com.cn/meinv/' ...
- WebRequest 获取网页乱码
问题:在用WebRequest获取网页源码时得到的源码是乱码. 原因:1,编码不对 解决办法:设置对应编码 WebRequest request = WebRequest.Create(Url);We ...
- 爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,loads,dump,load方法介绍
爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,load ...
- 解决Chrome网页编码显示乱码的问题
解决Chrome网页编码显示乱码的问题 记得在没多久以前,Google Chrome上面出现编码显示问题时,可以手动来调整网页编码问题,可是好像在Chrome 55.0版以后就不再提供手动调整编码,所 ...
- node爬虫之gbk网页中文乱码解决方案
之前在用 node 做爬虫时碰到的中文乱码问题一直没有解决,今天整理下备忘.(PS:网上一些解决方案都已经不行了) 中文乱码具体是指用 node 请求 gbk 编码的网页,无法正确获取网页中的中文(需 ...
随机推荐
- Apache2.4 根目录修改
需要修改两个地方: 1.httpd.conf 中的 DocumentRoot 项 和 Directory 项 2.httpd-vhosts.conf 中的 DocumentRoot 项 网上找到的大部 ...
- celery的定时任务
定时任务 Celery 中启动定时任务有两种方式,(1)在配置文件中指定:(2)在程序中指定. # cele.py import celery app = celery.Celery('cele', ...
- Django model重写save方法及update踩坑记录
一个非常实用的小方法 试想一下,Django中如果我们想对保存进数据库的数据做校验,有哪些实现的方法? 我们可以在view中去处理,每当view接收请求,就对提交的数据做校验,校验不通过直接返回错误, ...
- windows脱密码总结
方式1:通过SAM数据库获得本地用户HASH sam文件:是用来存储本地用户账号密码的文件的数据库system文件:里面有对sam文件进行加密和加密的密钥 利用方式: 导出sam和system: re ...
- 学习vue第七节,filter过滤器如何的使用
vue 过滤器如何的使用 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> ...
- B. Math Show 暴力 C - Four Segments
B. Math Show 这个题目直接暴力,还是有点难想,我没有想出来,有点思维. #include <cstdio> #include <cstdlib> #include ...
- (三)Bean生命周期
1 Bean注册 应用启动实质是调用Spring容器启动方法扫描配置加载bean到Spring容器中.同时启动内置的Web容器的过程,具体分析如下: @SpringBootApplication注解在 ...
- 认识mysql3个基本库
一.3个基本库 数据库初始化安装完毕会有三个基本库mysql .information_schema.performace_schema.作为应用程序开发者,平时较少关注这些数据库尤其是后两者.但是通 ...
- Spring 中基于 AOP 的 @AspectJ注解实例
@AspectJ 作为通过 Java 5 注释注释的普通的 Java 类,它指的是声明 aspects 的一种风格.通过在你的基于架构的 XML 配置文件中包含以下元素,@AspectJ 支持是可用的 ...
- CF#637 C. Nastya and Strange Generator
C. Nastya and Strange Generator 题意 有一个随机全排列生成器,给出你一个全排列,让判断是否可以通过这个生成器产生. 生成器工作方式: 第i步为数字i寻找位置pos. 首 ...