深度学习中正则化技术概述(附Python代码)
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习、深度学习的知识!
磐石
介绍
数据科学研究者们最常遇见的问题之一就是怎样避免过拟合。你也许在训练模型的时候也遇到过同样的问题–在训练数据上表现非同一般的好,却在测试集上表现很一般。或者是你曾在公开排行榜上名列前茅,却在最终的榜单排名中下降数百个名次这种情况。那这篇文章会很适合你。
去避免过拟合可以提高我们模型的性能。

在本文中,我们将解释过拟合的概念以及正则化如何帮助克服过拟合问题。随后,我们将介绍几种不同的正则化技术,并且最后实战一个Python实例以进一步巩固这些概念。
注意:本文假设你具备神经网络及其在keras中实现神经网络结构的基本知识。如果没有,你可以先参考下面的文章。
目录
- 什么是正则化?
- 正则化如何帮助减少过拟合?
- 深度学习中的不同正则化技术
L2和L1正则化
Dropout
数据增强(Data Augmentation)
早停(Early stopping)
- 使用Keras处理MNIST数据案例研究
一、什么是正则化?
深入探讨这个话题之前,请看一下这张图片:
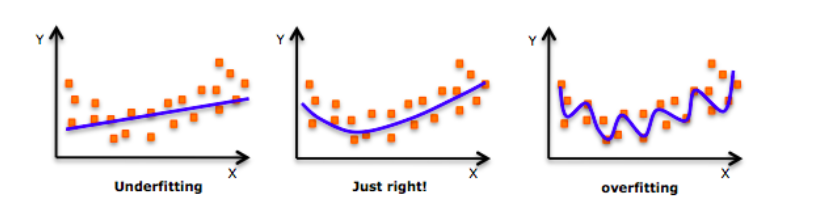
不知道你之前有么有看到过这张图片?当我们训练模型时,我们的模型甚至会试图学到训练数据中的噪声,最终导致在测试集上表现很差。
换句话说就是在模型学习过程中,虽然模型的复杂性增加、训练错误减少,但测试错误却一点也没有减少。这在下图中显示。
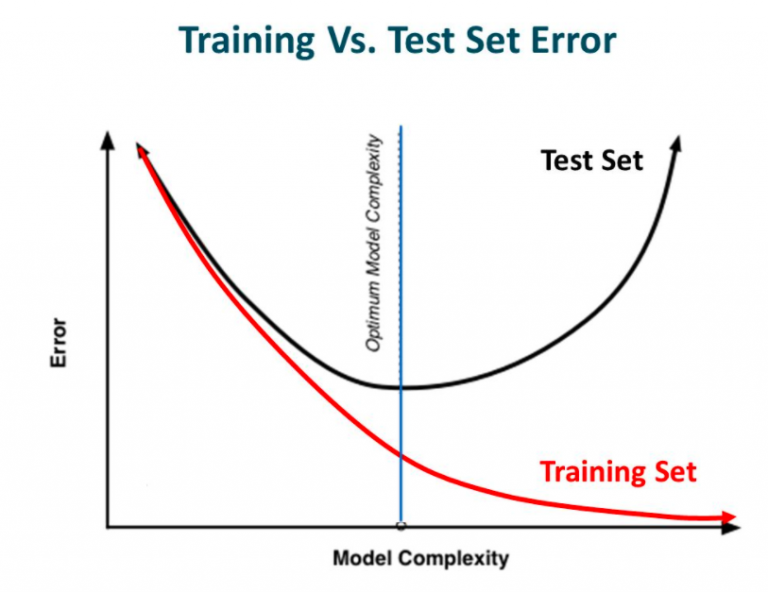
来源:Slideplayer
如果你有构建过神经网络的经验,你就知道它们是有多复杂。这使得更容易过拟合。

正则化是一种对学习算法进行微调来增加模型鲁棒性的一种技术。这同时也意味着会改善了模型在未知的数据上的表现。
二、正则化如何帮助减少过拟合?
让我们来分析一个在训练中过拟合的神经网络模型,如下图所示。
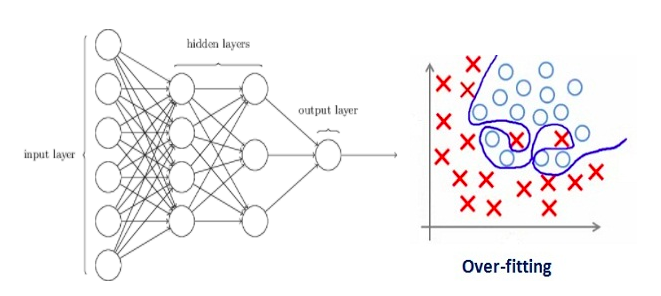
如果你了解过机器学习中正则化的概念,那你肯定了解正则项惩罚系数。在深度学习中,它实际上会惩罚节点的权重矩阵。
如果我们的正则项系数很高以至于一些权重矩阵几乎等于零。
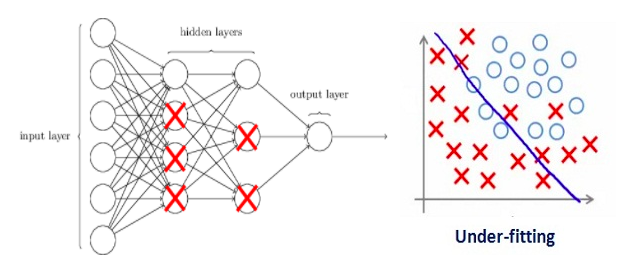
这将导致出现一个极其简单的线性网络结构和略微训练数据不足。
较大数值的正则项系数显然并不是那么有用。我们需要优化正则项系数的值。以便获得一个良好拟合的模型,如下图所示。
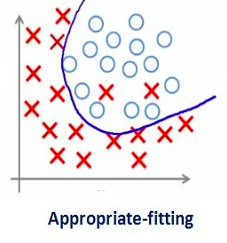
三、深度学习中的不同正则化技术
现在我们已经理解正则化如何帮助减少过拟合,为了将正则化应用于深度学习,我们将学习一些不同的技巧。
1.L2和L1正则化
L1和L2是最常见的正则化手段。通过添加正则项来更新代价函数。
代价函数=损失(比如二元交叉熵)+正则项
由于添加了正则项,使得加权矩阵的值减小–得益于它假定具有更小权重矩阵的神经网络产生更简单的模型,故它也会在一定程度上减少过拟合。
这个正则项在L1和L2中是不同的。
在L2中,我们有:
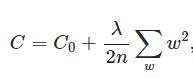
这里的lambda是正则项惩罚数。它是一个超参数。它的值可以被优化以获得更好的结果。L2正则化也称为权重衰减(weight decay),因为它使权重趋向零衰减(但不完全为零)。
在L1中,我们有:
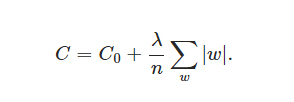
这里是惩罚权重的绝对值。与L2不同,这里的权重可以减少到零。因此,当我们试图压缩我们的模型时,它非常有用。其他的情况下,我们通常更喜欢L2。
在keras,我们可以对每一层进行正则化。
以下是将L2正则化应用于全连接层的示例代码。

注意:这里0.01是正则项系数的值,即lambda,其仍须进一步优化。我们可以使用网格搜索方法(grid-search)对其进行优化。
同样,我们也可以使用L1正则化。在本文后面的案例研究中,我们将更详细地研究这一点。
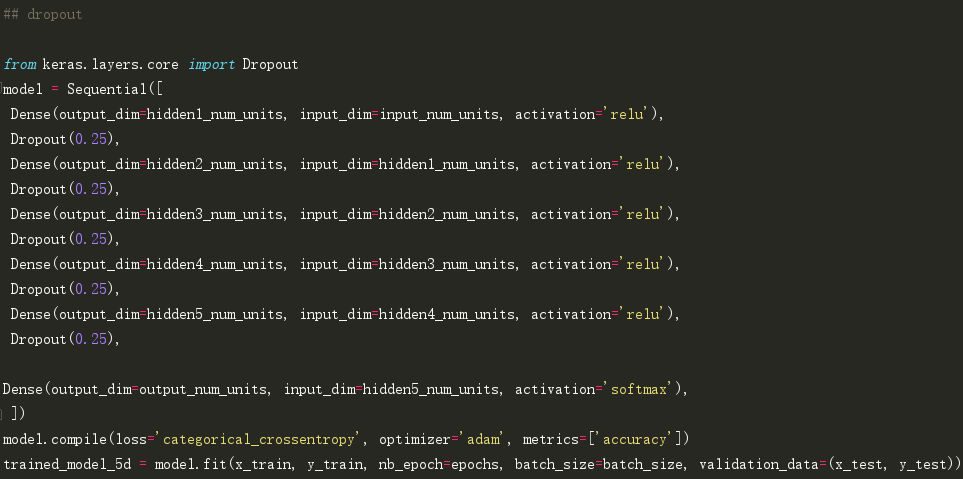
2.Dropout
Dropout是最有趣正则化手段之一。它同样会产生较好的结果,也是深度学习领域中最常用的正则化技术。
为了理解dropout,我们假设我们的神经网络结构类似于下面显示的那样:
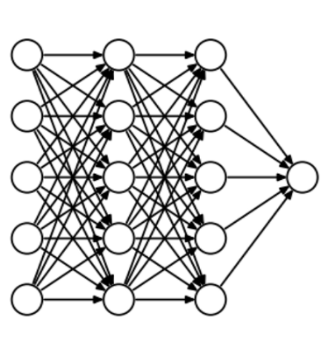
那么dropout是怎么工作的呢?在每次迭代中,它随机选择一些节点,并将它们连同它们的所有传入和传出连接一起删除,如下图所示。
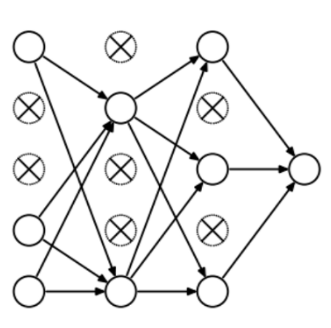
所以每次迭代都有一组不同的节点,这导致了一组不同的输出。它也可以被认为是机器学习中的集成技术(ensemble technique)。
集成模型通常比单一模型表现得更好,因为它们捕获更多的随机表达。类似地,dropout也比正常的神经网络模型表现得更好。
选择丢弃节点的比率是dropout函数中的超参数。如上图所示,dropout可以应用于隐藏层以及输入层。
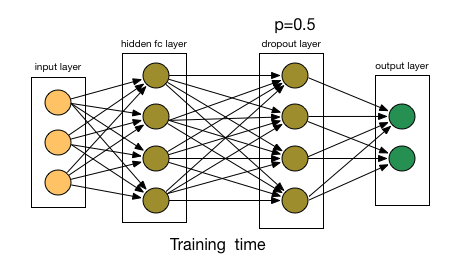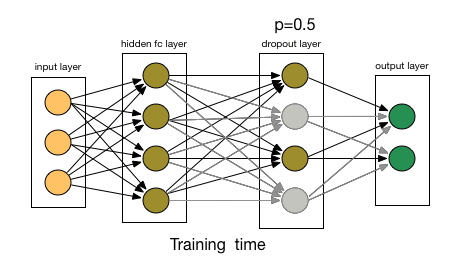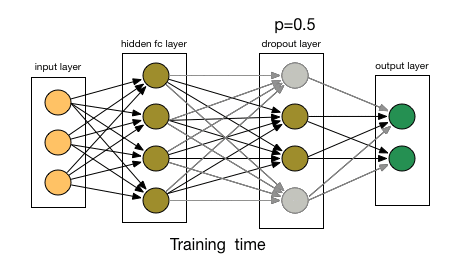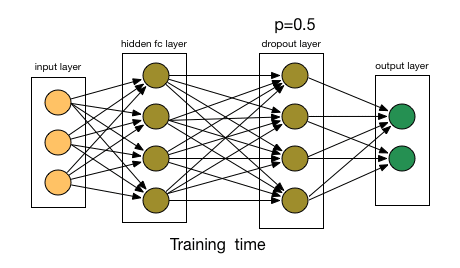
来源:chatbotslife
由于这些原因,当运用较大的神经网络结构时若想增加随机性,通常首选dropout。
在keras中,我们可以使用keras常用层(core layers)实现dropout。如下:
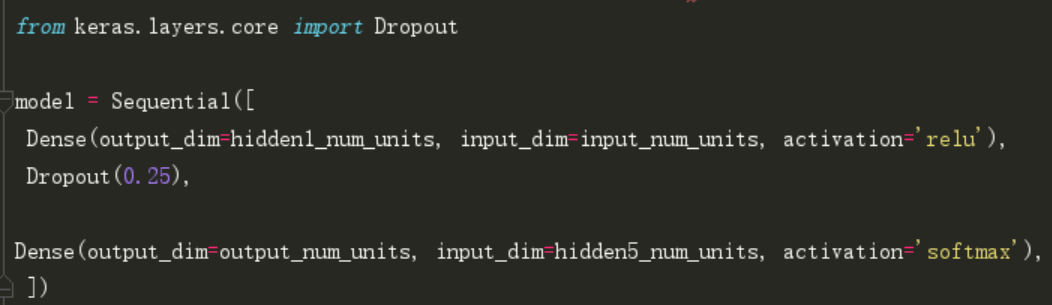
正如你所看到的,令丢弃率为0.25。也可以使用网格搜索方法进一步调优。
3.数据增强(Data Augmentation)
减少过拟合的最简单方法是增加训练数据的大小。在机器学习中,我们无法增加训练数据的大小,因为标记的数据成本太高。
但是,现在让我们考虑我们正在处理图像。在这种情况下,可以通过几种方法来增加训练数据的大小-旋转图像,翻转,缩放,移位等。下图是在手写数字数据集上进行的一些变换。

这种技术被称为数据增强。这通常会较大的提高模型的准确性。为了改进模型得的泛化能力,它可以被视为暴力技巧。
在keras中,我们可以使用ImageDataGenerator执行所有这些转换。它有一大堆你可以用来预处理训练数据的参数列表。
以下是实现它的示例代码。

4.早停(Early stopping)
早停是基于交叉验证策略–将一部分训练集作为验证集。一旦发现验证集的性能越来越差时,我们就立即停止对该模型的训练。这个过程被称为早停(Early stopping)。
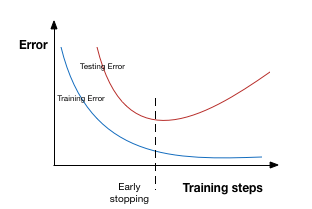
在上图中,我们将在虚线出停止训练,因为在此之后,我们的模型将在训练集上过拟合。
在keras中,我们可以使用回调函数(callback)实现早停。以下是它的示例代码。
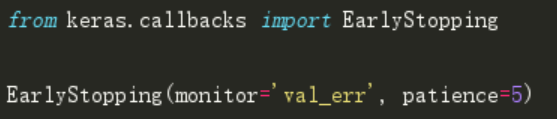
在这里,monitor表示需要监视的数量,’val_err‘表示验证错误。
Patience表示当early stopping被激活(如发现loss相比上一个epoch训练没有下降),则经过 patience 个epoch后停止训练。 为了更好地理解,让我们再看看上面的图片。在虚线之后每经历一个epoch都会导致更高的验证集错误率。因此,虚线后5个epoch(因为我们的patience等于5)后我们的模型将停止训练–由于不再进一步的提升。
注意:在5个epochs(这是为patience一般定义的值)之后,模型可能会再次开始改善,并且验证错误也开始减少。因此,我们需要在调整超参数时多加小心。
四、使用Keras处理MNIST数据集案例研究(A case study on MINIST data with keras)
到这里,你应该对不同的正则化技术有了一定的理论基础。我们现在将这些技术手段应用于我们的深度学习实践问题–手写体数字识别中(https://datahack.analyticsvidhya.com/contest/practice-problem-identify-the-digits/)。下载了数据集后,就可以开始下面的实践之旅了。首先,导入一些基本库。
加载数据集。

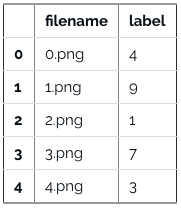
数据集可视化显示图片。

创建验证集(val),优化我们的模型以获得更好的分数。我们将用70:30的训练和验证数据比率。

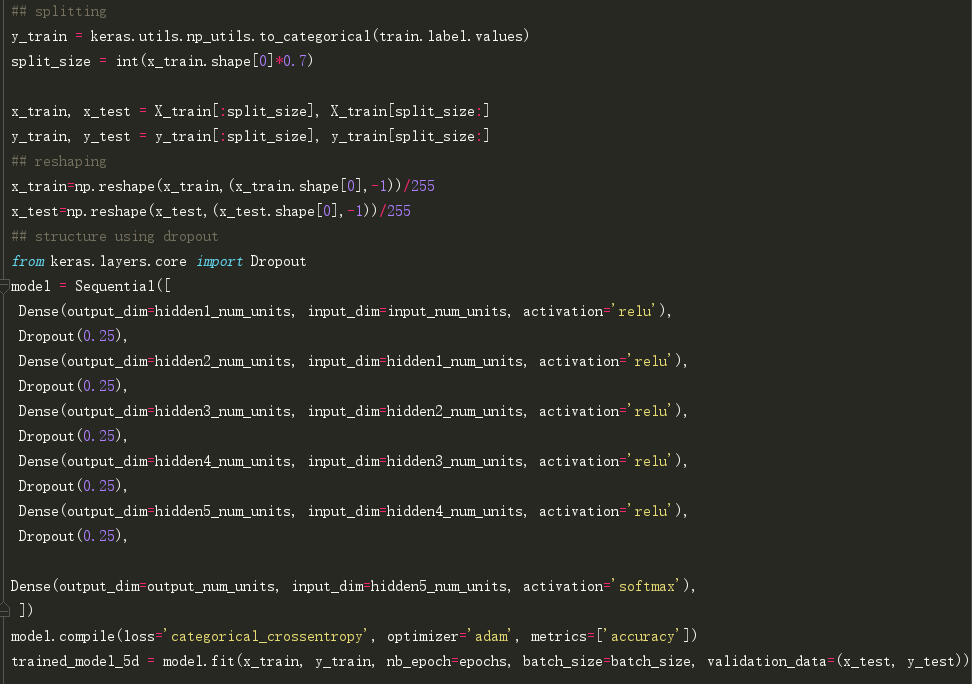
第一步,构建一个带有5个隐藏层的简单神经网络,每个层都有500个节点。
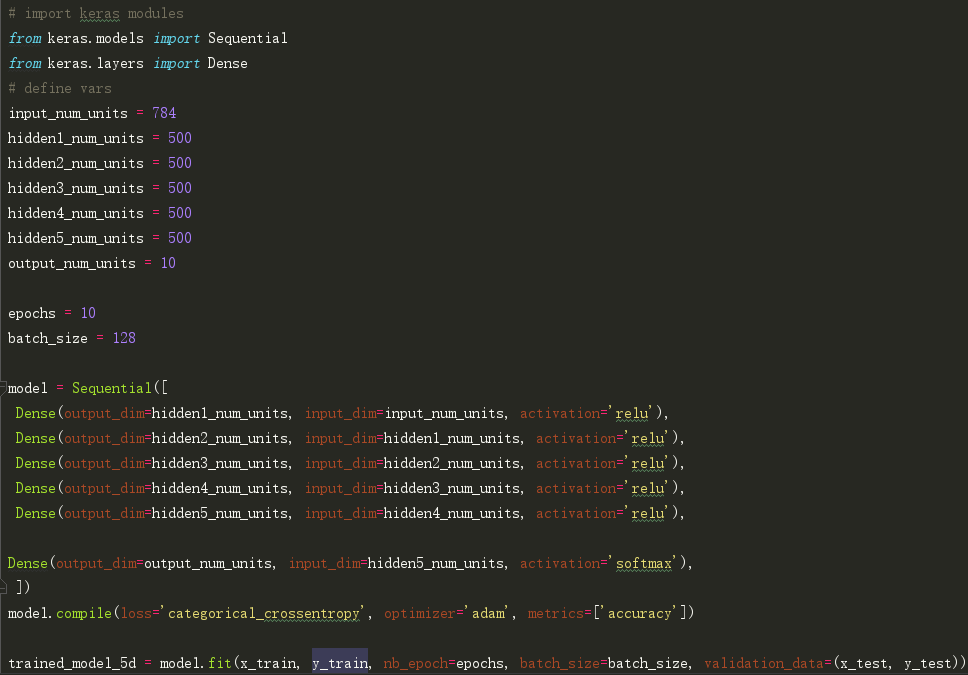
请注意,运行10个epoch。让我们看看它的实际表现。


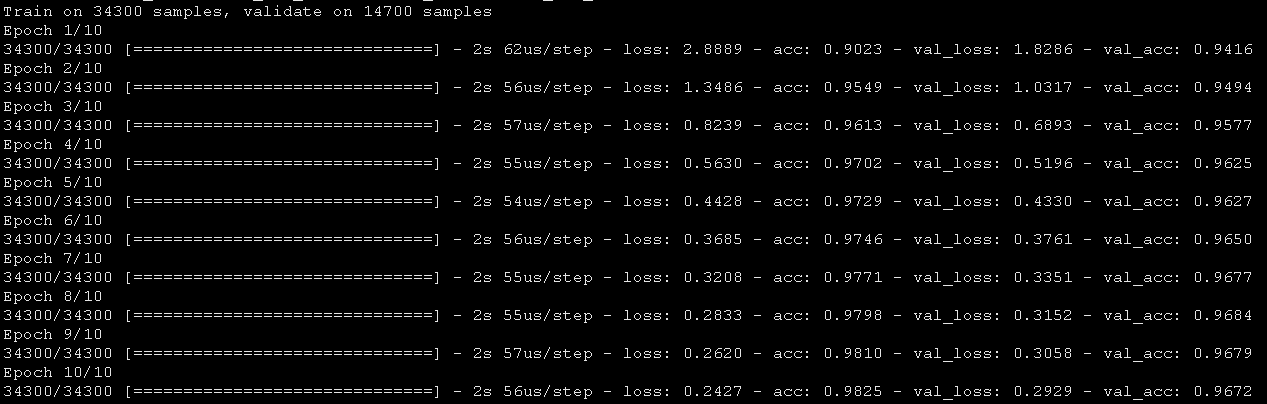
然后,让我们尝试使用L2正则化方法,并对比它是否比简单的神经网络模型有更好的结果。
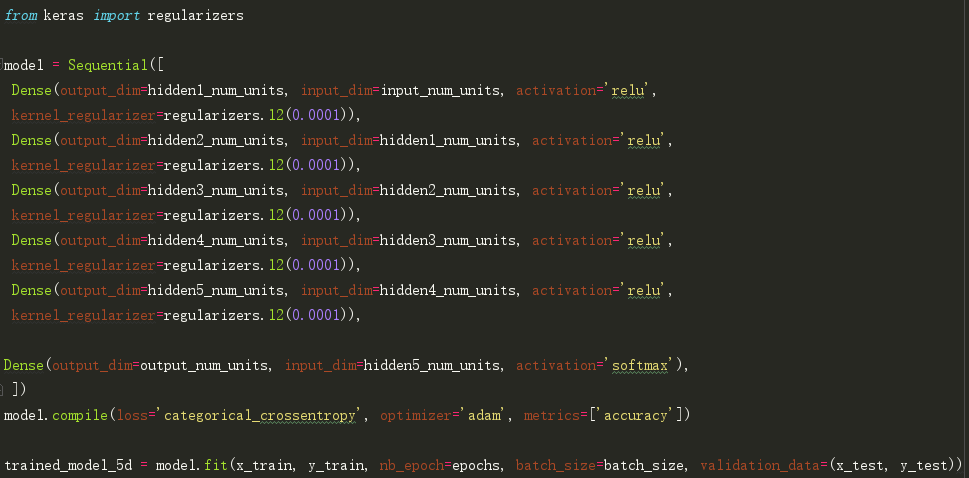
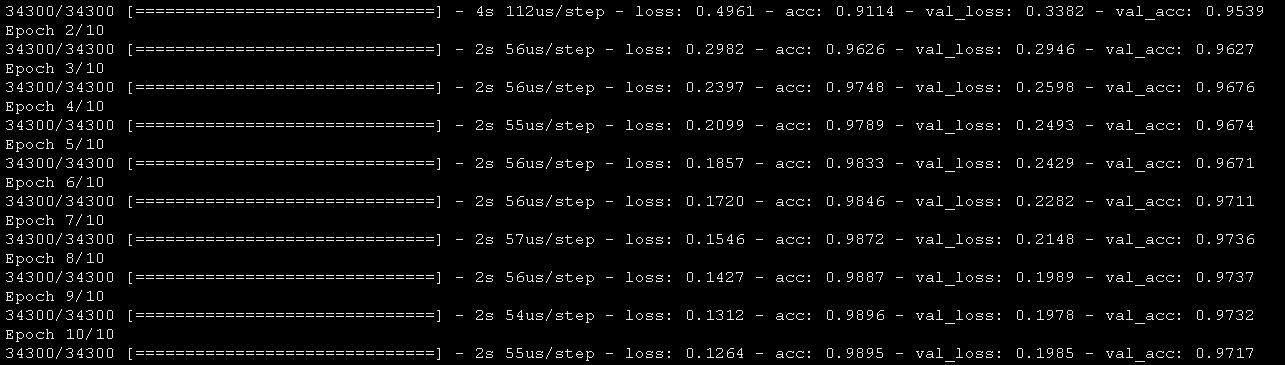
注意lambda的值等于0.0001。Cool,获得了比我们以前的NN模型更高的精度。
现在,我们来使用下L1正则化技术。

这对比之前未经过处理的神经网络结构来说没有任何改进,接下来试一下dropout技术。
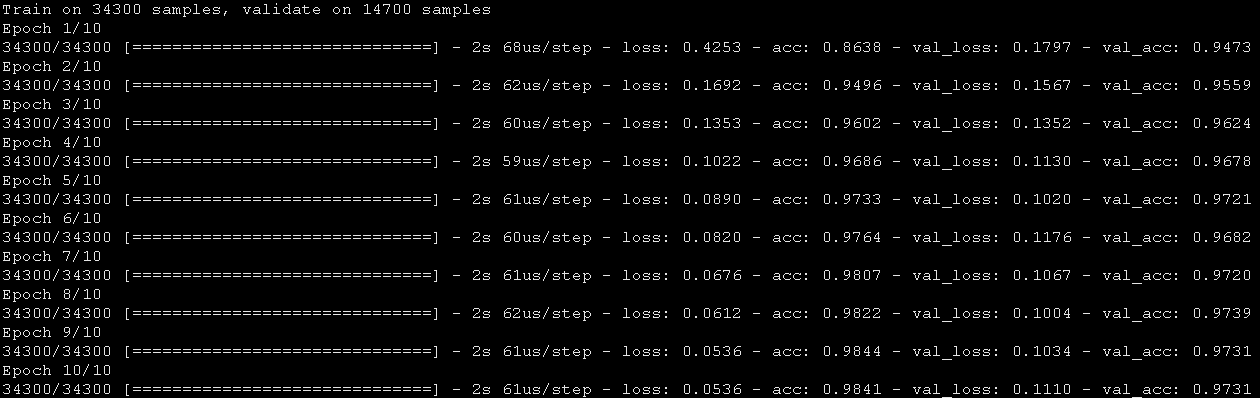
不错。dropout使我们对比原来未处理的NN模型有了一些改进。
现在,我们尝试数据增强(data augmentation)。
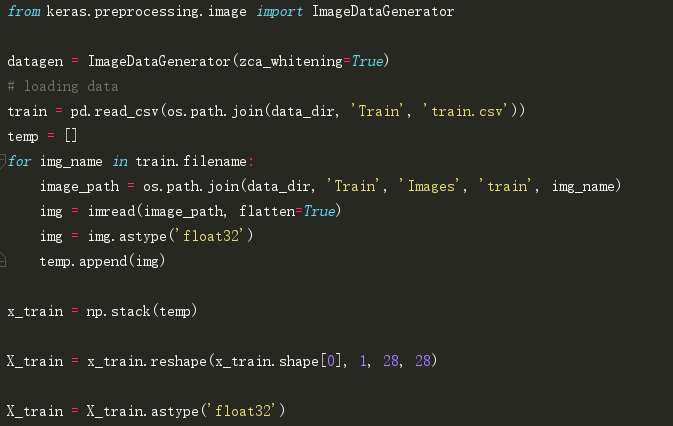
现在,为了增加训练数据
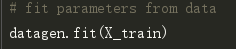
在这里,我使用了zca_whitening作为参数,它突出了每个数字的轮廓,如下图所示。
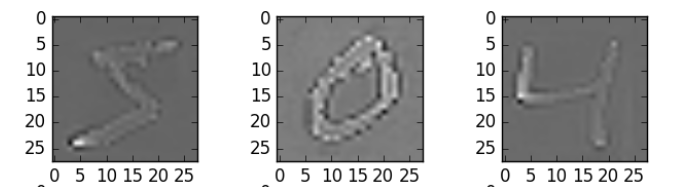
.png)
哇。我们在准确性得分上有了较大的提升。而好处是它每次都有效。我们只需根据数据集中的图像特点选择适当的参数。
最后,让我们尝试我们的最后一个方法-早停(early stopping)。

.png)
你可以看到,模型训练仅在5次迭代后就停止了–由于验证集准确率不再提高。如果设置更大的epoch运行,它也许不会有较好的结果。你可以说这是一种优化epoch数量的技术。
结语
希望现在你对正则化技术以及怎样在深度学习模型中实现它有了一定的了解。强烈建议在深度学习任务中应用它,它将可能会帮助提升你对模型的理解与认知。
是否觉得这篇文章会有帮助?欢迎下面的评论部分分享你的想法。
(编译自:https://www.analyticsvidhya.com/blog/2018/04/fundamentals-deep-learning-regularization-techniques/)
本篇文章出自http://www.tensorflownews.com,对深度学习感兴趣,热爱Tensorflow的小伙伴,欢迎关注我们的网站!
深度学习中正则化技术概述(附Python代码)的更多相关文章
- 医学图像 | 使用深度学习实现乳腺癌分类(附python演练)
乳腺癌是全球第二常见的女性癌症.2012年,它占所有新癌症病例的12%,占所有女性癌症病例的25%. 当乳腺细胞生长失控时,乳腺癌就开始了.这些细胞通常形成一个肿瘤,通常可以在x光片上直接看到或感觉到 ...
- 深度学习中的Data Augmentation方法(转)基于keras
在深度学习中,当数据量不够大时候,常常采用下面4中方法: 1. 人工增加训练集的大小. 通过平移, 翻转, 加噪声等方法从已有数据中创造出一批"新"的数据.也就是Data Augm ...
- 深度学习中优化【Normalization】
深度学习中优化操作: dropout l1, l2正则化 momentum normalization 1.为什么Normalization? 深度神经网络模型的训练为什么会很困难?其中一个重 ...
- NLP&深度学习:近期趋势概述
NLP&深度学习:近期趋势概述 摘要:当NLP遇上深度学习,到底发生了什么样的变化呢? 在最近发表的论文中,Young及其同事汇总了基于深度学习的自然语言处理(NLP)系统和应用程序的一些最新 ...
- 深度学习中的Normalization模型
Batch Normalization(简称 BN)自从提出之后,因为效果特别好,很快被作为深度学习的标准工具应用在了各种场合.BN 大法虽然好,但是也存在一些局限和问题,诸如当 BatchSize ...
- [优化]深度学习中的 Normalization 模型
来源:https://www.chainnews.com/articles/504060702149.htm 机器之心专栏 作者:张俊林 Batch Normalization (简称 BN)自从提出 ...
- 深度学习中的序列模型演变及学习笔记(含RNN/LSTM/GRU/Seq2Seq/Attention机制)
[说在前面]本人博客新手一枚,象牙塔的老白,职业场的小白.以下内容仅为个人见解,欢迎批评指正,不喜勿喷![认真看图][认真看图] [补充说明]深度学习中的序列模型已经广泛应用于自然语言处理(例如机器翻 ...
- 深度学习中dropout策略的理解
现在有空整理一下关于深度学习中怎么加入dropout方法来防止测试过程的过拟合现象. 首先了解一下dropout的实现原理: 这些理论的解释在百度上有很多.... 这里重点记录一下怎么实现这一技术 参 ...
- 深度学习中Dropout原理解析
1. Dropout简介 1.1 Dropout出现的原因 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象. 在训练神经网络的时候经常会遇到过拟合的问题 ...
随机推荐
- Ueditor富文本编辑器--Ctrl V 粘贴后原有图片显示错误
最近负责将公司官网从静态网站改版成动态网站,方便公司推广营销人员修改增加文案,避免官网文案维护过于依赖技术人员.在做后台管理系统时用到了富文本编辑器Ueditor,因为公司有一个阿里云文件资源服务器, ...
- Tomcat生产环境应用
概要: Tomcat各核心组件认知 Tomcat server.xml 配置详解 Tomcat IO模型介绍 一.Tomcat各组件认知 Tomcat架构说明 Tomcat组件及关系详情介绍 Tomc ...
- MVC01
1.Controller 1) 添加: 在Controller目录右键进行添加,出现很多模式供选择,选择空的Controller,命名后新建.新建后Views 目录将同步生成相应名称的视图文件目录 均 ...
- 小程序自定义switch组件
如上图,小程序api中的switch组件只能自定义颜色,不能自定义宽高,所以就开始了自己写switch组件. 自定义组件样式 switch组件样式大致如图,样式思路:未选中时为一个长方形有圆角按钮,和 ...
- flask之三:视图高级
视图高级 app.route和app.add_url_rule app.add_url_rule app.add_url_rule('/list/',endpoint='myweb',view_fun ...
- ubuntu下载eclipse详细步骤
1.官网下载 Eclipse IDE for Java EE Developers: https://www.eclipse.org/downloads/packages/ 2.安装eclipse将其 ...
- 网站开发---js与java实现的一些小功能
记录一下网站开发过程中的一些小功能 1.js获取当前年份: <span>Copyright © 2017-<script>document.write( new Date(). ...
- python基本数据类型的操作
1 列表和元组 1.列表基本操作 1. 列表赋值 a = [1,2,3,4,5,6,7,8] a[0] = 100 #the result : [100, 2, 3, 4, 5, 6, 7, 8] 2 ...
- windows7免费永久激活方法分享
前言 我相信,这里肯定有看过我上一篇博客的同学. 我说了,为解决windows7激活问题,我会找一个比较好的方法. 首先先让大家看一看激活前windows7的计算机属性: 显示是未激活的.下面就是方法 ...
- Java反射之对JavaBean的内省操作
上一篇我们说了Java反射之数组的反射应用 这篇我们来模拟实现那些javabean的框架(BeanUtils)的基本操作. [一] 什么是JavaBean JavaBean 是一种JAVA语言写成的可 ...