MySQL——关于索引的总结
索引的优缺点
首先说说索引的优点:最大的好处无疑就是提高查询效率。有的索引还能保证数据的唯一性,比如唯一索引。
而它的坏处也很明显:索引也是文件,我们在创建索引时,也会创建额外的文件,所以会占用一些硬盘空间。其次,索引也需要维护,我们在增加删除数据的时候,索引也需要去变化维护。当一个表的索引多了以后,资源消耗是很大的,所以必须结合实际业务再去确定给哪些列加索引。
索引的结构
再说说索引的基本结构。一说到这里肯定会脱口而出:B+树!了解B+树前先要了解二叉查找树和二叉平衡树。二叉查找树:左节点比父节点小,右节点比父节点大,所以二叉查找树的中序遍历就是树的各个节点从小到大的排序。二叉平衡树:左右子树高度差不能大于1。B+树就是结合了它们的特点,当然,不一定是二叉树。
为什么要有二叉查找树的特点??因为查找效率快,二分查找在这种结构下,查找效率是很快的。那为什么要有平衡树的特点呢?试想,如果不维护一颗树的平衡性,当插入一些数据后,树的形态有可能变得很极端,比如左子树一个数据没有,而全在右子树上,这种情况下,二分查找和遍历有什么区别呢?而就是因为这些特点需要去维护,所以就有了上面提到的缺点,当索引很多后,反而增加了系统的负担。
接着说B+树。它的结构如下:
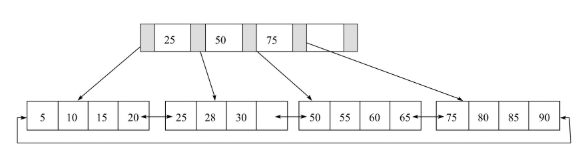
可以发现,叶子节点其实是一个双向循环链表,这种结构的好处就是,在范围查询的时候,我只用找到一个数据,就可以直接返回剩余的数据了。比如找小于30的,只用找到30,其余的直接通过叶子节点间的指针就可以找到。再说说其他特点:数据只存在于叶子节点。当叶子节点满了,如果再添加数据,就会拆分叶子节点,父节点就多了个子节点。如果父节点的位置也满了,就会扩充高度,就是拆分父节点,如25 50 75拆分成:25为左子树,75为右子树,50变成新的头节点,此时B+树的高度变成了3。它们的扩充的规律如下表,Leaf Page是叶子节点,index Page是非叶子节点。

再说说B树,B树相比较B+树,它所有节点都存放数据,所以在查找数据时,B树有可能没到达叶子节点就结束了。再者,B树的叶子节点间不存在指针。
最后说说Hash索引,相较于B+树,Hash索引最大的优点就是查找数据快。但是Hash索引最大的问题就是不支持范围查询。试想,如果查询小于30的数据,hash函数是根据数据的值找到其对应的位置,谁又知道小于30的有哪几个数据。而B+树正好相反,范围查询是它的强项。
附录:Hash到底是啥??哈希中文名散列,哈希只是它的音译。为啥都说Hash快??首先有一块哈希表(散列表),它的数据结构是个数组,一个任意长度的数据通过hash函数都可以变成一个固定长度的数据,叫hash值。然后通过hash值确定在数组中的位置,相同数据的hash值是相同的,所以我们存储一个数据以后,只需O(1)的时间复杂度就可以找到数据。那hash函数又是啥??算术运算或位运算,很多应用里都有hash函数,但实际运算过程大不一样。这是Java里String的hashCode方法:
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
还有一个问题,hash函数计算出来的hash值有可能存在碰撞,即两个不同的数据可能存在相同的hash值,在MySQL或其他的应用中,如Java的HashMap等,如果存在碰撞就会以当前数组位置为头节点,转变成一个链表。
说到这里也清楚了为啥Java中引用类型要同时重写hashCode和equals了。两个对象,实例就算一模一样,它们的hash值也不相等,为啥不相等??默认的Object的hashCode方法会根据对象来计算hash值的,实例相同,但它们还是两个不同的对象啊,所以我们重写hashCode时,最简单的方法就是调用Object的hashCode方法,然后传入该引用类型的属性,让hashCode方法只根据这几个属性来计算,那么实例相同的话,它们的hash值也会相等。等hashCode比较完后,如果相等再比较实例内容,也就是equals,确保不是hash碰撞。
索引的分类
主键索引:如果我们指定了一个主键,那么这个主键就是主键索引。如果我们没有指定,Mysql就会自动找一个非空的唯一索引当主键。如果没有这种字段,Mysql就会创建一个大小为6字节的自增主键。如果有多个非空的唯一索引,那么就让第一个定义为唯一索引的字段当主键,注意,是第一个定义,而不是建表时出现在前面的。
辅助索引:对于辅助索引来说,它们的B+树结构稍微有点特殊,它们的叶子节点存储的是主键,而不是整个数据。所以在大部分情况下,使用辅助索引查找数据,需要二次查找。但并不是所有情况都需要二次查找。比如查找的数据正好就是当前索引字段的值,那么直接返回就行。这里提一句,B+树的key就是对应索引字段的内容。
而辅助索引又有一些分类:唯一索引:不能出现重复的值,也算一种约束。普通索引:可以重复、可以为空,一般就是查询时用到。前缀索引:只适用于字符串类型数据,对字符串前几个字符创建索引。全文索引:作用是检测大文本数据中某个关键字,这也是搜索引擎的一种技术。
聚集索引:注意,聚集索引、非聚集索引和前面几个索引的分类并不是一个层面上的。上面的几个分类是从索引的作用来分析的。聚集、非聚集索引是从索引文件上区分的。主键索引就属于聚集索引,即索引和数据存放在一起,叶子节点存放的就是数据。数据表的.idb文件就是存放该表的索引和数据。
非聚集索引:辅助索引属于非聚集索引,说到这也就明白了。索引和数据不存放在一起的就是非聚集索引。在MYISAM引擎中,数据表的.MYI文件包含了表的索引, 该表的 叶子节点存储索引和索引对应数据的指针,指向.MYD文件的数据。
索引的几点使用经验
适合创建索引的字段:经常被查询的字段;经常作为条件查询的字段;经常用于外键连接或普通的连表查询时进行相等比较字段;不为null的字段;如果是多条件查询,最好创建联合索引,因为联合索引只有一个索引文件。
不适合创建索引的字段:经常被更新的字段、不经常被查询的字段、存在相同功能的字段
MySQL——关于索引的总结的更多相关文章
- 【夯实Mysql基础】MySQL性能优化的21个最佳实践 和 mysql使用索引
本文地址 分享提纲: 1.为查询缓存优化你的查询 2. EXPLAIN 你的 SELECT 查询 3. 当只要一行数据时使用 LIMIT 1 4. 为搜索字段建索引 5. 在Join表的时候使用相当类 ...
- MySQL中索引和优化的用法总结
1.什么是数据库中的索引?索引有什么作用? 引入索引的目的是为了加快查询速度.如果数据量很大,大的查询要从硬盘加载数据到内存当中. 2.InnoDB中的索引原理是怎么样的? InnoDB是Mysql的 ...
- MySQL 联合索引详解
MySQL 联合索引详解 联合索引又叫复合索引.对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分.例如索引是key index (a,b,c ...
- Mysql复合索引
当Mysql使用索引字段作为条件时,如果该索引是复合索引,必须使用该索引中的第一个字段作为条件才能保证系统使用该索引,否则该索引不会被使用,并且应尽可能地让索引顺序和字段顺序一致
- 如何正确建立MYSQL数据库索引
索引是快速搜索的关键.MySQL索引的建立对于MySQL的高效运行是很重要的.下面介绍几种常见的MySQL索引类型. 在数据库表中,对字段建立索引可以大大提高查询速度.假如我们创建了一个 mytabl ...
- mysql高性能索引策略
转载说明:http://www.nyankosama.com/2014/12/19/high-performance-index/ 1. 引言 随着互联网时代地到来,各种各样的基于互联网的应用和服务进 ...
- MySQL创建索引语法
1.介绍: 所有mysql索引列类型都可以被索引,对来相关类使用索引可以提高select查询性能,根据mysql索引数,可以是最大索引与最小索引,每种存储引擎对每个表的至少支持16的索引.总索引长度为 ...
- mysql使用索引优化查询效率
索引的概念 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针.更通俗的说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度.在没 ...
- Mysql中索引的 创建,查看,删除,修改
创建索引 MySQL创建索引的语法如下: ? 1 2 3 CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name [USING index_type] ON ...
- mysql 联合索引(转)
http://blog.csdn.net/lmh12506/article/details/8879916 mysql 联合索引详解 联合索引又叫复合索引.对于复合索引:Mysql从左到右的使用索引中 ...
随机推荐
- 选择IT行业的自我心得,希望能帮助到各位!(二)
在前面说道的一,希望大家能喜欢,这也只是自己的一种经历,每个人都有年轻的时候,谁的年级都有自以为是,谁的年轻都有风华正茂,谁的年轻都让自己的内涵给我们自己摔了一个狠狠的道理,人外有人天外有天.我记得当 ...
- Linux 下迁移 Nexus3
Nexus3 的迁移过程还是非常简单,复制整个目录到新服务器,启动即可. 备份 在原来服务器上将 nexus3 整体目录备份即可. $ tar -zcvf nexus3.tar.gz nexus3/ ...
- sqli-labs通关教程----41~50关
第四十关 与前几关一样,闭合变成') 插入数据 ?id=1') ;insert into users(id,username,password) values('17','aaa','bbb'); % ...
- Spring Cloud 系列之 Gateway 服务网关(四)
本篇文章为系列文章,未读第一集的同学请猛戳这里: Spring Cloud 系列之 Gateway 服务网关(一) Spring Cloud 系列之 Gateway 服务网关(二) Spring Cl ...
- ASP.NET Core技术研究-全面认识Web服务器Kestrel
因为IIS不支持跨平台的原因,我们在升级到ASP.NET Core后,会接触到一个新的Web服务器Kestrel.相信大家刚接触这个Kestrel时,会有各种各样的疑问. 今天我们全面认识一下ASP. ...
- numpy+sklearn 手动实现逻辑回归【Python】
逻辑回归损失函数: from sklearn.datasets import load_iris,make_classification from sklearn.model_selection im ...
- MySQL之视图、触发器、函数、存储过程、索引
1.视图 把某个查询语句(临时表)设置别名,日后方便使用,视图是虚拟的(不要在数据库里使用视图) #创建: create view v1(视图名称) as SQL #修改: alter view v1 ...
- 宝塔利用git+ webhooks 实现git更新远程同步Linux服务器
参考: https://blog.csdn.net/alipea/article/details/83858177 https://www.bt.cn/bbs/thread-5348-1-1.html ...
- 前端日期时间处理建议使用Momen
使用方法 下载: http://momentjs.cn/downloads/moment.js 多语言版本:http://momentjs.cn/downloads/moment-with-local ...
- Makefile: missing separator(did you mean TAB instead of 8 spaces?). Stop.
通常我们会对vimrc文件加以配置(如将TAB键自动转换为4个空白键). 但正是由于将tab键转换为n个空白键,使得用vim编写的Makefile中不存在tab键(即“\t”)了.恰恰Makefile ...