spark系列-8、Spark Streaming
参考链接:http://spark.apache.org/docs/latest/streaming-programming-guide.html
一、Spark Streaming 介绍
Spark Streaming是核心Spark API的扩展,可实现实时数据流的可伸缩,高吞吐量,容错流处理。数据可以从Kafka、ZeroMQ等消息队列以及TCP sockets或者目录文件从数据源获取数据,并且可以使用map,reduce,join和window等高级函数进行复杂算法的处理。最后,可以将处理后的数据推送到文件系统,数据库和实时仪表板。

- 在内部,它的工作方式为:Spark Streaming接收实时输入数据流,并将数据分成批次,然后由Spark引擎进行处理,以生成批次的最终结果流。

- 对应的批数据,在Spark内核对应一个RDD实例,因此,对应流数据的DStream可以看成是一组RDDs,即RDD的一个序列。通俗点理解的话,在流数据分成一批一批后,通过一个先进先出的队列,然后 Spark Engine从该队列中依次取出一个个批数据,把批数据封装成一个RDD,然后进行处理,这是一个典型的生产者消费者模型,对应的就有生产者消费者模型的问题,即如何协调生产速率和消费速率。

Spark Streaming Wordcount:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Duration, Durations, StreamingContext} /**
* @author xiandongxie
*/
object SparkStreamingWordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setMaster("local[2]")
.setAppName("SparkStreamingWordCount")
// 设置批次时间5S
val duration: Duration = Durations.seconds(5)
val context: StreamingContext = new StreamingContext(conf,duration)
// 指定socket数据源
val sourceDStream: ReceiverInputDStream[String] = context.socketTextStream("localhost", 6666)
// 计算WordCount
val resultDStream: DStream[(String, Int)] = sourceDStream.flatMap(f => f.split("\t"))
.map((_, 1))
.reduceByKey(_ + _) resultDStream.print() context.start() // Start the computation
context.awaitTermination() // Wait for the computation to terminate
}
}
二、Spark Streaming 对比 Storm
- 处理模型以及延迟
- 虽然两框架都提供了可扩展性(scalability)和可容错性(fault tolerance),但是它们的处理模型从根本上说是不一样的。Storm可以实现亚秒级时延的处理,而每次只处理一条event,而Spark Streaming可以在一个短暂的时间窗口里面处理多条(batches)Event。所以说Storm可以实现亚秒级时延的处理,而Spark Streaming则有一定的时延。
- 容错和数据保证
- 然而两者的都有容错时候的数据保证,Spark Streaming的容错(通过血缘关系)为有状态的计算提供了更好的支持。在Storm中,每条记录在系统的移动过程中都需要被标记跟踪,所以Storm只能保证每条记录最少被处理一次,但是允许从错误状态恢复时被处理多次。这就意味着可变更的状态可能被更新两次从而导致结果不正确。
- Spark Streaming的容错:通过血缘关系,是粗粒度的,保证每个批处理记录仅仅被处理一次,即使是node节点挂掉
- Storm:细粒度的容错,每条记录在系统的移动过程中都需要被标记跟踪,缺点:允许从错误状态恢复时被处理多次。这就意味着可变更的状态可能被更新两次从而导致结果不正确。
- 批处理框架集成
- Spark Streaming的一个很棒的特性就是它是在Spark框架上运行的。这样你就可以使用spark的批处理代码一样来写Spark Streaming程序,或者是在Spark中交互查询比如spark-sql。这就减少了单独编写流处理程序和历史数据处理程序。
- 生产支持
- 两者都可以在各自的集群框架中运行,但是Storm可以在Mesos上运行, 而Spark Streaming可以在YARN和Mesos上运行。

Spark Streaming优缺点:
- 优点:
- 吞吐量大、速度快。
- 容错:SparkStreaming在没有额外代码和配置的情况下可以恢复丢失的工作。checkpoint。
- 社区活跃度高。生态圈强大。因为后台是Spark
- 数据源广泛。
- 缺点:
- 延迟。500毫秒已经被广泛认为是最小批次大小。所以实际场景中应注意该问题,就像标题分类场景,设定的0.5s一批次,加上处理时间,分类接口会占用1s的响应时间。实时要求高的可选择使用其他框架。
三、架构与抽象
Spark Streaming使用“微批次”的架构,把流试计算当成一系列连接的小规模批处理来对待,Spark Streaming从各种输入源中读取数据,并把数据分成小组的批次,新的批次按均匀的时间间隔创建出来,在每个时间区间开始的时候,一个新的批次就创建出来,在该区间内收到的数据都会被添加到这个批次中,在时间区间结束时,批次停止增长。时间区间的大小是由批次间隔这个参数决定的,批次间隔一般设在500毫秒到几秒之间,由应用开发者配置,每个输出批次都会形成一个RDD,以Spark作业的方式处理并生成其他的RDD。并能将处理结果按批次的方式传给外部系统。

接受器(receive)会占用一个executor的一个cpu,所以在local[n]模式下,n > 要运行的接收器数
四、DStream 操作
- DStream 上的原语与 RDD 的类似,分为 Transformations(转换,惰性的)和 Output Operations(输出)两种,此外转换操作中还有一些比较特殊的原语,如:
- updateStateByKey()、transform() 以及各种 Window 相关的原语。
- UpdateStateByKey 返回一个新的“状态” DStream,在该DStream中,通过在键的先前状态和键的新值上应用给定函数来更新每个键的状态。这可用于维护每个键的任意状态数据。
- 如输入:hello world,结果则为:(hello,1)(world,1),然后输入 hello spark,结果则为 (hello,2)(spark,1)。会保留上一次数据处理的结果。
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext} /**
* @author xiandongxie
*/
object SparkStreamingSocketPortUpdateState {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName("sparkstreamingsocketportupdatestate")
.setMaster("local[2]")
val streamingContext = new StreamingContext(conf, Durations.seconds(5)) // 设置保存地址
streamingContext.checkpoint("/tmp/spark/sparkstreamingsocketportupdatestat") val sourceDStream: ReceiverInputDStream[String] = streamingContext.socketTextStream("localhost", 6666) val reduceDStream: DStream[(String, Int)] = sourceDStream.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _) val updateStateByKey: DStream[(String, Int)] = reduceDStream.updateStateByKey((newValues: Seq[Int], runningCount: Option[Int]) => {
var total: Int = 0
for (i <- newValues) {
total += i
}
println(newValues + "\t" + (if (runningCount.isDefined) runningCount.get else 0))
val last: Int = if (runningCount.isDefined) runningCount.get else 0
val now: Int = total + last
Some(now)
}) updateStateByKey.foreachRDD((r, t) => {
println(s"count time:${t},${r.collect().toList}")
}) streamingContext.start()
streamingContext.awaitTermination() }
}
- Transform() 原语允许 DStream 上执行任意的 RDD-to-RDD 函数 代替原有的DStream 转换操作,必须返回一个RDD;通过该函数可以方便的扩展 Spark API。
普通的转换操作如下表所示:
|
转换 |
描述 |
|
map(func) |
源 DStream的每个元素通过函数func返回一个新的DStream。 |
|
flatMap(func) |
类似与map操作,不同的是每个输入元素可以被映射出0或者更多的输出元素。 |
|
filter(func) |
在源DSTREAM上选择Func函数返回仅为true的元素,最终返回一个新的DSTREAM 。 |
|
repartition(numPartitions) |
通过输入的参数numPartitions的值来改变DStream的分区大小。 |
|
union(otherStream) |
返回一个包含源DStream与其他 DStream的元素合并后的新DSTREAM。 |
|
count() |
对源DStream内部的所含有的RDD的元素数量进行计数,返回一个内部的RDD只包含一个元素的DStreaam。 |
|
reduce(func) |
使用函数func(有两个参数并返回一个结果)将源DStream 中每个RDD的元素进行聚 合操作,返回一个内部所包含的RDD只有一个元素的新DStream。 |
|
countByValue() |
计算DStream中每个RDD内的元素出现的频次并返回新的DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素出现的频次。 |
|
reduceByKey(func, [numTasks]) |
当一个类型为(K,V)键值对的DStream被调用的时候,返回类型为类型为(K,V)键值对的新 DStream,其中每个键的值V都是使用聚合函数func汇总。注意:默认情况下,使用 Spark的默认并行度提交任务(本地模式下并行度为2,集群模式下位8),可以通过配置numTasks设置不同的并行任务数。 |
|
join(otherStream, [numTasks]) |
当被调用类型分别为(K,V)和(K,W)键值对的2个DStream时,返回类型为(K,(V,W))键值对的一个新 DSTREAM。 |
|
cogroup(otherStream, [numTasks]) |
当被调用的两个DStream分别含有(K, V) 和(K, W)键值对时,返回一个(K, Seq[V], Seq[W])类型的新的DStream。 |
|
transform(func) |
通过对源DStream的每RDD应用RDD-to-RDD函数返回一个新的DStream,这可以用来在DStream做任意RDD操作。 |
|
updateStateByKey(func) |
返回一个新状态的DStream,其中每个键的状态是根据键的前一个状态和键的新值应用给定函数func后的更新。这个方法可以被用来维持每个键的任何状态数据。 |
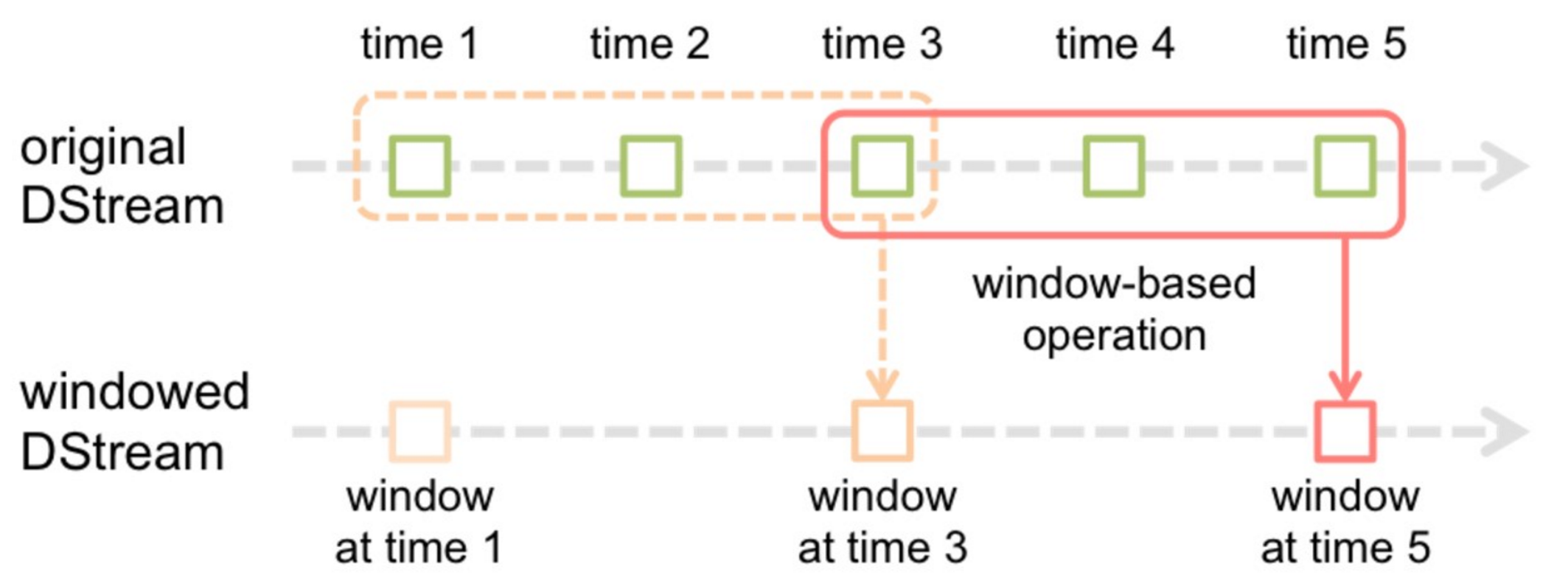
五、窗口转换操作
- 在Spark Streaming中,数据处理是按批进行的,而数据采集是逐条进行的,因此在Spark Streaming中会先设置好批处理间隔(batch duration),当超过批处理间隔的时候就会把采集到的数据汇总起来成为一批数据交给系统去处理。
- 对于窗口操作而言,在其窗口内部会有N个批处理数据,批处理数据的大小由窗口间隔(window duration)决定,而窗口间隔指的就是窗口的持续时间,在窗口操作中,只有窗口的长度满足了才会触发批数据的处理。除了窗口的长度,窗口操作还有另一个重要的参数就是滑动间隔(slide duration),它指的是经过多长时间窗口滑动一次形成新的窗口,滑动窗口默认情况下和批次间隔的相同,而窗口间隔一般设置的要比它们两个大。在这里必须注意的一点是滑动间隔和窗口间隔的大小一定得设置为批处理间隔的整数倍
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
窗口的计算:
Spark Streaming 还提供了窗口的计算,它允许你通过滑动窗口对数据进行转换,窗口转换操作如下:
|
转换 |
描述 |
|
window(windowLength窗口大小, slideInterval滑动间隔) |
返回一个基于源DStream的窗口批次计算后得到新的DStream。 |
|
countByWindow(windowLength,slideInterval) |
返回基于滑动窗口的DStream中的元素的数量。 |
|
reduceByWindow(func, windowLength,slideInterval) |
基于滑动窗口对源DStream中的元素进行聚合操作,得到一个新的DStream。 |
|
reduceByKeyAndWindow(func,windowLength,slideInterval, [numTasks]) |
基于滑动窗口对(K,V)键值对类型的DStream中的值按K使用聚合函数func进行聚合操作,得到一个新的DStream。 |
|
reduceByKeyAndWindow(func,invFunc,windowLength, slideInterval, [numTasks]) |
一个更高效的reduceByKkeyAndWindow()的实现版本,先对滑动窗口中新的时间间隔内数据增量聚合并移去最早的与新增数据量的时间间隔内的数据统计量。例如,计算t+4秒这个时刻过去5秒窗口的WordCount,那么我们可以将t+3时刻过去5秒的统计量加上[t+3,t+4]的统计量,在减去[t-2,t-1]的统计量,这种方法可以复用中间三秒的统计量,提高统计的效率。 |
|
countByValueAndWindow(windowLength,slideInterval, [numTasks]) |
基于滑动窗口计算源DStream中每个RDD内每个元素出现的频次并返回DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素频次。与countByValue一样,reduce任务的数量可以通过一个可选参数进行配置。 |
七、输出操作
Spark Streaming允许DStream的数据被输出到外部系统,如数据库或文件系统。由于输出操作实际上使transformation操作后的数据可以通过外部系统被使用,同时输出操作触发所有DStream的transformation操作的实际执行(类似于RDD操作)。以下表列出了目前主要的输出操作:
|
转换 |
描述 |
|
print() |
在Driver中打印出DStream中数据的前10个元素。 |
|
saveAsTextFiles(prefix, [suffix]) |
将DStream中的内容以文本的形式保存为文本文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
|
saveAsObjectFiles(prefix, [suffix]) |
将DStream中的内容按对象序列化并且以SequenceFile的格式保存。其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
|
saveAsHadoopFiles(prefix, [suffix]) |
将DStream中的内容以文本的形式保存为Hadoop文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
|
foreachRDD(func) |
最基本的输出操作,将func函数应用于DStream中的RDD上,这个操作会输出数据到外部系统,比如保存RDD到文件或者网络数据库等。需要注意的是func函数是在运行该streaming应用的Driver进程里执行的。 |
dstream.foreachRDD是一个强大的原语,可以将数据发送到外部系统:
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}
八、checkpoint
流应用程序必须24*7全天候运行,因此必须对与应用程序逻辑无关的故障(例如,系统故障,JVM崩溃等)具有弹性。为此,Spark Streaming需要将足够的信息检查点指向容错存储系统,以便可以从故障中恢复。检查点有两种类型的数据。
- 元数据检查点 -将定义流计算的信息保存到HDFS等容错存储中。这用于从运行流应用程序的驱动程序的节点的故障中恢复。元数据包括:
- 配置 -用于创建流应用程序的配置。
- DStream操作 -定义流应用程序的DStream操作集。
- 不完整的批次 -作业排队但尚未完成的批次。
- 数据检查点 -将生成的RDD保存到可靠的存储中。在一些有状态转换中,这需要跨多个批次合并数据,这是必需的。在此类转换中,生成的RDD依赖于先前批次的RDD,这导致依赖项链的长度随时间不断增加。为了避免恢复时间的这种无限制的增加(与依赖关系链成比例),有状态转换的中间RDD定期 检查点到可靠的存储(例如HDFS)以切断依赖关系链。
总而言之,从驱动程序故障中恢复时,主要需要元数据检查点,而如果使用有状态转换,即使是基本功能,也需要数据或RDD检查点。
何时启用检查点:
必须为具有以下任一要求的应用程序启用检查点:
- 有状态转换的用法 -如果在应用程序中使用
updateStateByKey或reduceByKeyAndWindow(带有反函数),则必须提供检查点目录以允许定期进行RDD检查点。 - 从运行应用程序的驱动程序故障中恢复 -元数据检查点用于恢复进度信息。
注意,没有前述状态转换的简单流应用程序可以在不启用检查点的情况下运行。在这种情况下,从驱动程序故障中恢复也将是部分的(某些已接收但未处理的数据可能会丢失)。这通常是可以接受的,并且许多都以这种方式运行Spark Streaming应用程序。预计将来会改善对非Hadoop环境的支持。
如何配置检查点:
可以通过在容错,可靠的文件系统(例如,HDFS,S3等)中设置目录来启用检查点,将检查点信息保存到该目录中。这是通过使用完成的streamingContext.checkpoint(checkpointDirectory)。这将允许您使用前面提到的有状态转换。此外,如果要使应用程序从驱动程序故障中恢复,则应重写流应用程序以具有以下行为。
- 程序首次启动时,它将创建一个新的StreamingContext,设置所有流,然后调用start()。
- 失败后重新启动程序时,它将根据检查点目录中的检查点数据重新创建StreamingContext。
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext} /**
* @author xiandongxie
*/
object SparkStreamingSocketCheckPoint {
def main(args: Array[String]): Unit = {
val checkpointPath = "/tmp/spark/sparkStreamingSocketCheckPoint" val strc: StreamingContext = StreamingContext.getOrCreate(checkpointPath, () => {
val conf: SparkConf = new SparkConf()
.setAppName("SparkStreamingSocketCheckPoint")
.setMaster("local[2]")
val streamingContext = new StreamingContext(conf, Durations.seconds(5))
streamingContext.checkpoint(checkpointPath) val sourceDStream: ReceiverInputDStream[String] = streamingContext.socketTextStream("localhost", 6666) val reduceDStream: DStream[(String, Int)] = sourceDStream.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _) val updateStateByKey: DStream[(String, Int)] = reduceDStream.updateStateByKey((newValues: Seq[Int], runningCount: Option[Int]) => {
var total: Int = 0
for (i <- newValues) {
total += i
}
val last: Int = if (runningCount.isDefined) runningCount.get else 0
val now: Int = total + last
Some(now)
}) updateStateByKey.foreachRDD((r, t) => {
println(s"count time:${t},${r.collect().toList}")
})
streamingContext
}) strc.start()
strc.awaitTermination()
}
}
spark系列-8、Spark Streaming的更多相关文章
- Spark系列—01 Spark集群的安装
一.概述 关于Spark是什么.为什么学习Spark等等,在这就不说了,直接看这个:http://spark.apache.org, 我就直接说一下Spark的一些优势: 1.快 与Hadoop的Ma ...
- Spark系列—02 Spark程序牛刀小试
一.执行第一个Spark程序 1.执行程序 我们执行一下Spark自带的一个例子,利用蒙特·卡罗算法求PI: 启动Spark集群后,可以在集群的任何一台机器上执行一下命令: /home/spark/s ...
- Spark入门实战系列--7.Spark Streaming(上)--实时流计算Spark Streaming原理介绍
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark Streaming简介 1.1 概述 Spark Streaming 是Spa ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- 初步了解Spark生态系统及Spark Streaming
一. 场景 ◆ Spark[4]: Scope: a MapReduce-like cluster computing framework designed for low-laten ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- Spark 实践——基于 Spark Streaming 的实时日志分析系统
本文基于<Spark 最佳实践>第6章 Spark 流式计算. 我们知道网站用户访问流量是不间断的,基于网站的访问日志,即 Web log 分析是典型的流式实时计算应用场景.比如百度统计, ...
- Spark系列-核心概念
Spark系列-初体验(数据准备篇) Spark系列-核心概念 一. Spark核心概念 Master,也就是架构图中的Cluster Manager.Spark的Master和Workder节点分别 ...
- Spark系列-初体验(数据准备篇)
Spark系列-初体验(数据准备篇) Spark系列-核心概念 在Spark体验开始前需要准备环境和数据,环境的准备可以自己按照Spark官方文档安装.笔者选择使用CDH集群安装,可以参考笔者之前的文 ...
随机推荐
- python--->相对和绝对路径
绝对路径(absolute path):从根开始找 eg:c:\file\01.txt 相对路径(relative path):相对当前文件内找 ../ # 当前文件的上一级 os.path ...
- 有关google的guava工具包详细说明
Guava 中文是石榴的意思,该项目是 Google 的一个开源项目,包含许多 Google 核心的 Java 常用库. 目前主要包含: com.google.common.annotations c ...
- 反射----获取class对象的五种方法
反射Reflection 配合注解使用会格外强大,反射注解,天生一对 类如何加载? 动态语言和静态语言.我知道是什么,不用总结了. 由于反射,Java可以称为准动态语言. 允许通过反射获得类的全部信息 ...
- 009-数组-C语言笔记
009-数组-C语言笔记 学习目标 1.[掌握]数组的声明 2.[掌握]数组元素的赋值和调用 3.[掌握]数组的初始化 4.[掌握]数组的遍历 5.[掌握]数组在内存中的存储 6.[掌握]数组长度计算 ...
- 如何从零开始学Python?会玩游戏就行,在玩的过程就能掌握编程
现在学习编程的人很多,尤其是python编程,都列入高考了,而且因为人工智能时代的到来,编程也将是一门越来越重要的技能. 但是怎么从零开始学python比较好呢?其实,你会玩游戏就行. 从零基础开始教 ...
- 03-css3中的3D转换
一.CSS3-3D转换 1.3D 特点:近大远小,物体和面遮挡不可见 1.1三维坐标系 x 轴:水平向右 -- x 轴右边是正值,左边是负值 y 轴:垂直向下 -- y 轴下面是正值,上面是负值 z ...
- 13. 罗马数字转整数----LeetCode
13. 罗马数字转整数 罗马数字包含以下七种字符: I, V, X, L,C,D 和 M. 字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 M 1000 例如, 罗马数字 2 ...
- 刚从一道题发现的一些东西,PHP笔记,关于extract和null 空字符串
队友发给我的一道extract变量的最基础的题目,他发现了一些问题,当传入shiyan=&flag=0时出flag,当传入shiyan=0&flag=0时不出flag,传入shiyan ...
- pytorch 中LSTM模型获取最后一层的输出结果,单向或双向
单向LSTM import torch.nn as nn import torch seq_len = 20 batch_size = 64 embedding_dim = 100 num_embed ...
- python爬虫-User-Agent的伪造
某些网站会识别python爬虫程序并阻断,通过构造User_Agent可以抵抗某些反爬虫机制 用fake-useragent这个库就能很好的实现 pycharm中安装步骤 产生随机的User-Agen ...