ggplot2(9) 数据操作
9.1 plyr包简介
ddply {plyr}: Split data frame, apply function, and return results in a data frame.
ddply(.data, .variables, .fun = NULL, ..., .progress = "none", .inform = FALSE, .drop = TRUE, .parallel = FALSE, .paropts = NULL)
- .data:用来作图的数据。
- .variables:对数据取子集的分组变量,形式是 .(var1, var2) ,为了与图形保持一致,该变量必须包含所有在画图过程中用到的分组变量和分面变量。
- .fun:要在各个子集上运行的统计汇总函数。
- .inform:产生信息丰富的错误消息?这在默认情况下是关闭的,因为它大大降低了处理速度,但是对于调试非常有用。
# 选取各个颜色里最小的钻石
ddply(diamonds, .(color), subset, carat == min(carat))
# 选取最小的两颗钻石
ddply(diamonds, .(color), subset, order(carat) <= 2)
# 选取每组里大小为前1%的钻石
ddply(diamonds, .(color), subset, carat > quantile(carat, 0.99))
# 选出所有比组平均值大的钻石
ddply(diamonds, .(color), subset, price > mean(price))
transform {base}: Transform an Object, for Example a Data Frame.
transform(`_data`, ...)
transform()是进行数据变换的函数,与ddply()结合可以计算分组统计量。
# 把每个颜色组里钻石的价格标准化,使其均值为0,方差为1
ddply(diamonds, .(color), transform, price = scale(price))
colwise {plyr}: Column-wise function.
colwise用来向量化一个函数,能把原本只接受向量输入的函数变成可以接受数据框输入的函数。
要注意colwise返回的是一个新的函数,而不是函数运行的结果。
下面例子中nmissing()计算向量里缺失值的数目,用colwise()向量化后,可以应用到数据框,计算数据框中各列的缺失值数目。
nmissing <- function(x) sum(is.na(x)) nmissing_df <- colwise(nmissing)
nmissing_df(msleep) # This is shorthand for the previous two steps
colwise(nmissing)(msleep)


numcolwise()和catcolwise()是colwise()的特殊版本,功能类似,但numcolwise()只对数值类型的列操作,catcolwise()只对分类类型的列操作。
我们也可以编写编写的函数,只要他能够接受、输出数据框就可以。下面的例子计算价格和克拉的秩相关关系。
my_summary <- function(df) {
with(df, data.frame(pc_cor = cor(price, carat, method = "spearman"), lpc_cor = cor(log(price),
log(carat))))
}
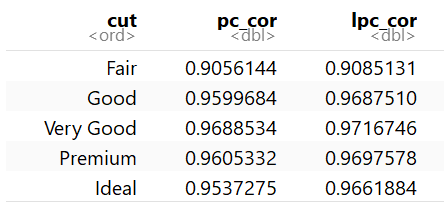
ddply(diamonds, .(cut), my_summary)
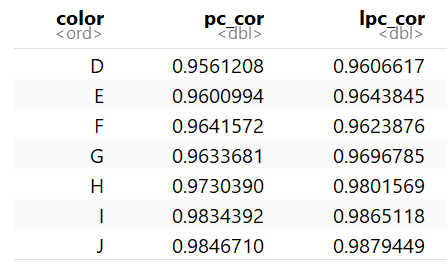
ddply(diamonds, .(color), my_summary)
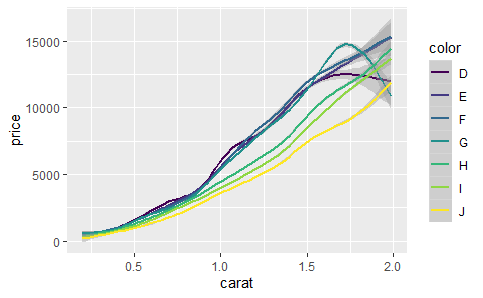
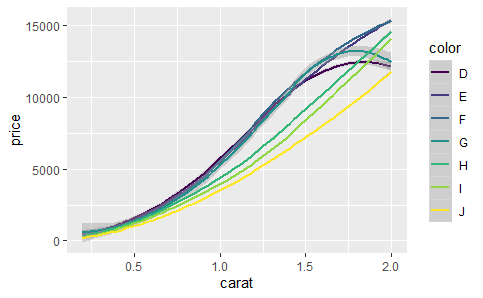
拟合多个模型:
dense <- subset(diamonds, carat < 2)
qplot(carat, price, data = dense, geom = "smooth", colour = color, fullrange = TRUE)
library(mgcv)
library(plyr)
smooth <- function(df) {
mod <- gam(price ~ s(carat, bs = "cs"), data = df)
grid <- data.frame(carat = seq(0.2, 2, length = 50))
pred <- predict(mod, grid, se = T)
grid$price <- pred$fit
grid$se <- pred$se.fit
grid
}
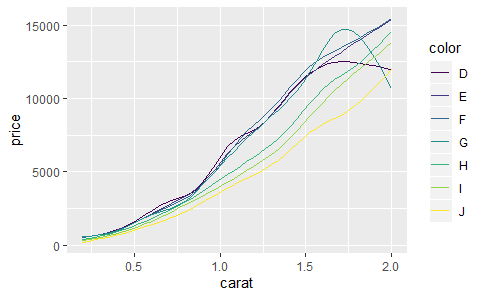
smoothes <- ddply(dense, .(color), smooth)
qplot(carat, price, data = smoothes, colour = color, geom = "line")
qplot(carat, price, data = smoothes, colour = color, geom = "smooth", ymax = price +
2 * se, ymin = price - 2 * se)
9.2 数据化“宽”为“长”
melt {reshape2}: Convert an object into a molten data frame.
melt(data, ..., na.rm = FALSE, value.name = "value")
- data:待变形的原数据;
- id.vars:依旧放在列上、位置保持不变的变量;
- measure.vars:需要被放进同一列的变量。
示例:
https://www.cnblogs.com/dingdangsunny/p/12482067.html#_label3
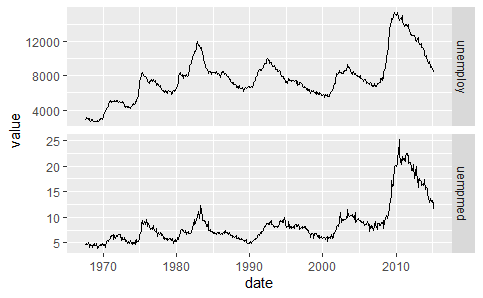
多重时间序列:
emp <- melt(economics, id = "date", measure = c("unemploy", "uempmed"))
qplot(date, value, data = emp, geom = "line") + facet_grid(variable ~ ., scales = "free_y")
ggplot2不允许绘制带有两个不同坐标轴的图,因为这样的图具有误导性。可以使用自由标度的分面图形表达有量级差的变量。
总结
ggplot2(9) 数据操作的更多相关文章
- StackExchange.Redis帮助类解决方案RedisRepository封装(字符串类型数据操作)
本文版权归博客园和作者本人共同所有,转载和爬虫请注明原文链接 http://www.cnblogs.com/tdws/tag/NoSql/ 目录 一.基础配置封装 二.String字符串类型数据操作封 ...
- hive数据操作
mdl是数据操作类的语言,包括向数据表加载文件,写查询结果等操作 hive有四种导入数据的方式 >从本地加载数据 LOAD DATA LOCAL INPATH './examples/files ...
- Dapper 数据操作框架
数据操作DapperFrom NuGet:Install-Package DapperorInstall-Package Dapper.StrongName微型ORM:PetaPoco获得PetaPo ...
- Django数据操作F和Q、model多对多操作、Django中间件、信号、读数据库里的数据实现分页
models.tb.objects.all().using('default'),根据using来指定在哪个库里查询,default是settings中配置的数据库的连接名称. 外话:django中引 ...
- coreData数据操作
// 1. 建立模型文件// 2. 建立CoreDataStack// 3. 设置AppDelegate 接着 // // CoreDataStack.swift // CoreDataStackDe ...
- Entity Framework 5.0系列之数据操作
Entity Framework将概念模型中定义的实体和关系映射到数据源,利用实体框架可以将数据源返回的数据具体化为对象:跟踪对象所做的更改:并发处理:将对象更改传播到数据源等.今天我们就一起讨论如何 ...
- 数据操作语言DML与运算符
数据操作语言DML(添加,修改,删除) 1.添加数据 insert into insert into 表名 (字段列表) values (值列表),值列表要和字段列表按顺序匹配. insert int ...
- SQL不同服务器数据库之间的数据操作整理(完整版)
---------------------------------------------------------------------------------- -- Author : htl25 ...
- C#利用SqlDataAdapte对DataTable进行批量数据操作
C#利用SqlDataAdapte对DataTable进行批量数据操作,可以让我们大大简化操作数据的代码量,我们几乎不需要循环和不关心用户到底是新增还是修改,更不用编写新增和修改以及删除的SQL语句, ...
- 使用Hive或Impala执行SQL语句,对存储在HBase中的数据操作
CSSDesk body { background-color: #2574b0; } /*! zybuluo */ article,aside,details,figcaption,figure,f ...
随机推荐
- vue element 关闭当前tab 跳转到上一路由
方法一 this.$store.dispatch('delVisitedViews', this.$route); this.$router.go(-1); 方法二 this.$store.state ...
- marry|psych up|make it|Fireworks|be to blame for|
同位语从句 ADJ 结婚的;已婚的If you are married, you have a husband or wife. We have been married for 14 years.. ...
- Heartbeat(注意iptables和selinux的问题)
安装 yum –y install heartbeat libnet配置 通过yum安装配置文件目录/etc/ha.d目录下没有配置文件需要从doc目录中复制三个文件.ha.cf.authkeys.h ...
- java增强型for循环
http://blog.csdn.net/itmyhome1990/article/details/8797005
- js 实现数据结构 -- 散列(HashTable)
原文: 在Javascript 中学习数据结构与算法. 概念: HashTable 类, 也叫 HashMap 类,是 Dictionary 类的一种散列表实现方式. 散列算法的作用是尽可能快地在数据 ...
- SVN图标含义说明
最经都在用Svn,对他上面的很多状态图标不是很理解,看了看它的帮助文档,说的很清楚,特地截张图. Svn不同状态图标及说明 - 简单 - 简单 Normal A fresh checked ...
- django Highcharts制作图表--显示CPU使用率
Highcharts 是一个用纯JavaScript编写的一个图表库. Highcharts 能够很简单便捷的在web网站或是web应用程序添加有交互性的图表 Highcharts 免费提供给个人学习 ...
- 4 Values whose Sum is 0 (二分+排序)
题目: The SUM problem can be formulated as follows: given four lists A, B, C, D of integer values, com ...
- mac电脑终端使用scp上传/下载文件/文件夹
1.从服务器下载文件到本地电脑 1 scp -r remote_username@remote_ip:remote_folder local_folder 例如: 1 scp -r root@106. ...
- Linux用户与用户组的关系
一.用户和用户组文件 1. /etc/passwd:所创建的用户账号和信息均存放在次文件中,所有用户可读取: 最后一个字段的值一般为/sbin/nologin,表示该账号不能用来登陆linux系统: ...