List和Map集合详细分析
1.Java集合主要三种类型(两部分):
第一部分:Collection(存单个数据,只能存取引用类型)
(1).List :是一个有序集合,可以放重复的数据;(存顺序和取顺序相同)
(2).Set :是一个无序集合,不允许放置重复的数据;(存顺序和取顺序不一定相同)
(3).SortedSet:无序不可重复,存进去的元素可以按照元素的大小自动排序。
第二部分:Map(存成对数据)
(1).Map: 是一个无序集合,集合中包含一个键对象,一个值对象,键对象不允许重复,值对象可以重复(身份证号-姓名)。
2.Java集合存取数据类型及结构
2.1 常见集合的继承结构-Collection

2.1.1、集合中常用实现类的数据结构分析:
(1)List集合
List集合继承了Collection接口,因此包含了collection中所有的方法,此外,List接口还定义了以下两个非常重要的方法:
(a)get(int index):获得指定索引位置的元素
(b)set(int index,Object obj):将集合中指定索引位置的对象修改为指定对象。
(2)ArrayList
采用数组存储元素,适合查询,不适合随机增删元素。(常用)。是可变数组,允许保存所有的元素,包括null,并可以根据索引位置对集合进行快速的随机访问:缺点是指定的索引位置插入对象或删除对象的速度较慢。
(3)LinkedList
底层采用双向链表数据结构存储数据,适合频繁的增删元素,不适合查询元素。
(4)Vector
底层和ArrayList集合相同,但是 Vector是线程安全的,效率较低。(不常用)
(5)Set集合
Set集合中的元素不按特定的方式排序,只是简单地把对象加入集合,Set集合中不能包含重复对象。set集合有Set接口的实现类组成,set接口继承了Collection接口,因包含了Collction接口的所有方法。 Set的构造方法有一个约束条件,传入的Collection对象不能把有重复值,必须小心操作可变对象(Mutable Object)。如果一个Set中可变元素改变了自身状态导致Object。equals(Object) = true,则会出现一些问题。
(6)HashSet
哈希表/散列表,底层是一个HashMap。HashSet有以下特点:
a. 不能保证元素的排列顺序,顺序有可能发生变化
b.不是同步的
c. 集合元素可以是null,但只能放入一个null
当向HashSet结合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置。
简单的说,HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个对象的hashCode()方法返回值相 等。
注意,如果要把一个对象放入HashSet中,重写该对象对应类的equals方法,也应该重写其hashCode()方法。
其规则是如果两个对 象通过equals方法比较返回true时,其hashCode也应该相同。另外,对象中用作equals比较标准的属性,都应该用来计算 hashCode的值。
(5)TreeSet:
TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式, 自然排序 和定制排序,其中自然排序为默认的排序方式。向TreeSet中加入的应该是同一个类的对象。
自然排序使用要排序元素的CompareTo(Object obj)方法来比较元素之间大小关系,然后将元素按照升序排列。
Java提供了一个Comparable接口,该接口里定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现了该接口的对象就可以比较大小。
obj1.compareTo(obj2)方法如果返回0,则说明被比较的两个对象相等,如果返回一个正数,则表明obj1大于obj2,如果是 负数,则表明obj1小于obj2。
如果我们将两个对象的equals方法总是返回true,则这两个对象的compareTo方法返回应该返回0
b.定制排序
定制排序是根据集合元素的大小,以升序排列,如果要定制排序,应该使用Comparator接口,实现 int compare(T o1,T o2)方法
2.1.2、Collection接口中的方法分析:
(1).list集合
package list;
import java.util.*;
import java.util.ArrayList;
public class Gather { // 创建类Gather
public static void main(String[] args) { // 主方法
List<String> list = new ArrayList<>();//创建集合对象
list.add("a");
list.add("b");
list.add("c");
//获得0~2之间随机数
int i = (int)(Math.random()*(list.size() - 1));
System.out.println("随机数组中的元素: "+list.get(i));
list.remove(2);//将指定索引位置的元素从集合中移除
System.out.println("将索引是2的元素从数组中移除后数组中的元素是:");
for(int j = 0;j < list.size();j++){//循环遍历结合
System.out.println(list.get(j));
}
} }
/*
运行结果: 随机数组中的元素: a
将索引是2的元素从数组中移除后数组中的元素是:
a
b
*/
(2)set集合
import java.util.*;
/**
* 在项目中创建类UpdateStu,实现Comparable接口,重写该接口中的compareTo()方法。在主方法中
* 创建UpdateStu对象,创建集合,并将UpdataStu对象添加到集合中,遍历该集合中的全部元素,以及通过
* headSet(),subSet()方法获得的全部的部分集合。
* @author z
*
*/
public class UpdateStu implements Comparable<Object> {
String name;
long id;
public UpdateStu(String name, long id) {
this.id = id;
this.name = name;
}
public int compareTo(Object o) {
UpdateStu upstu = (UpdateStu) o;
int result = id > upstu.id ? 1 : (id == upstu.id ? 0 : -1);
return result;
}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public static void main(String[] args) {
UpdateStu stu1 = new UpdateStu("李同学", 01011);
UpdateStu stu2 = new UpdateStu("陈同学", 01021);
UpdateStu stu3 = new UpdateStu("王同学", 01051);
UpdateStu stu4 = new UpdateStu("马同学", 01012);
TreeSet<UpdateStu> tree = new TreeSet<>();
tree.add(stu1);
tree.add(stu2);
tree.add(stu3);
tree.add(stu4);
Iterator<UpdateStu> it = tree.iterator();
System.out.println("Set集合中的所有元素:");
while (it.hasNext()) {
UpdateStu stu = (UpdateStu) it.next();
System.out.println(stu.getId() + " " + stu.getName());
}
it = tree.headSet(stu2).iterator();
System.out.println("截取前面部分的集合:");
while (it.hasNext()) {
UpdateStu stu = (UpdateStu) it.next();
System.out.println(stu.getId() + " " + stu.getName());
}
it = tree.subSet(stu2, stu3).iterator();
System.out.println("截取中间部分的集合");
while (it.hasNext()) {
UpdateStu stu = (UpdateStu) it.next();
System.out.println(stu.getId() + " " + stu.getName());
}
}
}
/*
运行结果: Set集合中的所有元素:
521 李同学
522 马同学
529 陈同学
553 王同学
截取前面部分的集合:
521 李同学
522 马同学
截取中间部分的集合
529 陈同学 分析:存入TreeSet类实现的Set集合必须实现Comparable接口,该接口中的compareTo(Object o)方法比较此对象与指定对象的顺序,如果该对象小于,等于,或大于指定对象,则分别返回负整数,0或正整数。
*/
(3)contains方法:boolean contains(object o);判断集合中是否包含某个元素
import java.util.*; class Collection01
{
//重写equals方法 public static void main(String[] args)
{
//创建集合
Collection c = new ArrayList();
//创建Integer类型对象
Integer i1 = new Integer(10);
//添加元素
c.add(i1);
//判断集合中是否包含i1
System.out.println(c.contains(i1));//true Integer i2= new Integer(10);
System.out.println(c.contains(i2));//true Manager m1=new Manager(100,"JACK");
c.add(m1);
//contasins方法调用底层的是equals方法,如果equals方法返回True,就是包含
System.out.println(c.contains(m1));//true Manager m2=new Manager(100,"JACK");
//重写equas方法之前返回false,(比较内存地址)
//System.out.println(c.contains(m2));//false
//重写equas方法之后返回True,集合中的对象都要重写equalos方法(比较内容)
System.out.println(c.contains(m2));//true }
}
class Manager
{
int no;
String name;
Manager(int no,String name)
{
this.no=no;
this.name=name;
}
public boolean equals(Object o)
{
if(this==o) return true;
if(o instanceof Manager)
{
Manager m = (Manager)o;
if(m.no == this.no && m.name.equals(this.name))
{
return true;
}
}
return false;
} }
(4)remove方法:boolean remove(object o);删除集合中的某个元素
import java.util.*;
/*
boolean remove(Object o)
集合中的元素都需要重写equals方法,在Object的equals方法比较内存地址,在解决实际问题的时候应该比较内容
*/ class Remove
{
public static void main(String[] args)
{
Collection c = new ArrayList();
Integer i1 = new Integer(10);
c.add(i1);
Integer i2=new Integer(10);
c.remove(i2);
System.out.println(c.size());//
Manager m2=new Manager(100,"ZHANG");
c.remove(m2);
System.out.println(c.size());//
}
}
class Manager
{
int no;
String name;
Manager(int no,String name)
{
this.no=no;
this.name=name;
} }
(5)两种remove方法的区别
a.迭代器的remove方法
import java.util.*; class Remove1
{
public static void main(String[] args)
{
Collection c = new ArrayList();
c.add(1);
c.add(2);
c.add(3);
Iterator it = c.iterator();
while(it.hasNext())
{
Object element = it.next();
it.remove();
}
System.out.println(c.size());
}
}
b.集合自身带的remove方法
import java.util.*; class Remove1
{
public static void main(String[] args)
{
Collection c = new ArrayList();
c.add(1);
c.add(2);
c.add(3);
Iterator it = c.iterator();
while(it.hasNext())
{
Object element = it.next();
c.remove(element);
//集合自身带的remove在将元素删除后,迭代器失效,需要重新获得迭代器,若不添加此语句,则会出现异常
it = c.iterator();
}
System.out.println(c.size());
}
}
2.1.3、List接口中的方法分析:(有序可重复)
(1).添加元素,遍历元素
import java.util.*; class Main //有序可重复
{
public static void main(String[] args)
{
List L = new ArrayList();
L.add(100);
L.add(200);
L.add(1300);
L.add(120);
L.add(100);
Iterator it = L.iterator();
while (it.hasNext())
{
Object element = it.next();
System.out.println(element);
} }
}
(2)ArrayList底层原理
package shili; import java.util.*;
/**
* ArrayList底层集合是数组
* ArrayList默认容量是10,扩容后的新容量是原容量的1.5倍
* vector集合底层默认初始容量是10,扩容后是原容量的2倍。
* 如果优化ArrayList和Vector?
* 尽量减少扩容操作,扩容需要拷贝数组,拷贝很消耗内存,一般在创建集合时指定初始化
*/
class Main
{
public static void main(String[] args)
{
//创建List集合
List l = new ArrayList();
l.add(10);
l.add(20);
l.add(30);
//在下标为1的位置上添加100
l.add(1,100);
//获取第一个元素
System.out.println(l.get(0));
//便利(List集合特有的便利方式)
System.out.println("--------------------");
for(int i=0;i<l.size();i++){
Object element= l.get(i);
System.out.println(element);
} }
}
(3)ArrayList与Vector的区别
a.Vector是线程安全的,Arrayliast是线程不安全的 。
b.ArrayList在底层数组不够用的时候扩展为原来的1.5倍,Vector默认扩展为你原来的2倍。
对于第一点可以通过原码来观察:
vector原码:
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
/**
* The array buffer into which the components of the vector are
* stored. The capacity of the vector is the length of this array buffer,
* and is at least large enough to contain all the vector's elements.
*
* <p>Any array elements following the last element in the Vector are null.
*
* @serial
*/
protected Object[] elementData;
Vector的add方法:
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
ArrayList的add方法
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
分析:从add方法中可以看到,vector的add方法中添加了synchronized关键字来保证vector的线程是安全的。
其实vector的其他方法中,也都加了synchronized关键字。
2.1.4 set接口中的方法分析:(无序不可重复)
(1).HasHset

/*
set集合中存储元素,该元素的hashCode和equals方法
HashMap中有一个put的方法,put(key,value) key是无序不可重复的
存储在hashSet集合或者HashMap集合Key部分的元素,需要同时重写hashCode方法和equals方法
*/
import java.util.*;
class SetTest
{
public static void main(String[] args)
{
//创建集合
Set es =new HashSet();
Employee e1 = new Employee("1000","u1");
Employee e2 = new Employee("1001","u2");
Employee e3 = new Employee("2000","u3");
Employee e4 = new Employee("2001","u4");
Employee e5 = new Employee("2001","u4"); es.add(e1);
es.add(e2);
es.add(e3);
es.add(e4);
es.add(e5);
System.out.println(es.size()); }
} //员工编号1000~9999
class Employee
{
String no;
String name;
Employee(String no,String name)
{
this.no=no;
this.name=name;
}
//重写equals方法,如果员工编号相同,并且名字相同,则是同一个对象
public boolean equals(Object o)
{
if(this == o) {
return true;
}
if(o instanceof Employee){
Employee e= (Employee)o;
if(e.no.equals(this.no) && e.name.equals(this.name)){
return true;
}
}
return false;
}
//重写hashCode方法
public int hashCode()
{
return no.hashCode();
} }
(2)SortedSet
/*
java.util.Set;
java.util.SortSet;无序不可重复,但是进去的元素可以按照元素的大小顺序自动进行排序
java.util.TreeSet;
*/
import java.util.*;
import java.text.*;
class SortSettest
{
public static void main(String[] args) throws ParseException
{
//创建集合
SortedSet ss = new TreeSet();
//天加元素 自动装箱
ss.add(30);
ss.add(20);
ss.add(33);
ss.add(10);
ss.add(60);
ss.add(8);
//遍历
Iterator it = ss.iterator();
while(it.hasNext()){
Object e = it.next();
System.out.println(e);
}
//String
SortedSet str = new TreeSet();
str.add("zhangsan");
str.add("lisi");
str.add("wangwu");
str.add("maliu");
str.add("liuba");
//遍历
it = str.iterator();
while(it.hasNext()){
Object e = it.next();
System.out.println(e);
}
//Date
SortedSet times = new TreeSet();
String t1 = "2009-10-01";
String t2 = "2012-01-01";
String t3 = "2014-06-08";
String t4 = "2018-07-01";
String t5 = "2008-08-08";
//设置格式
SimpleDateFormat def = new SimpleDateFormat("yyyy-MM-dd");
//日期格式化
Date ut1 = def.parse(t1);
Date ut2 = def.parse(t2);
Date ut3 = def.parse(t3);
Date ut4 = def.parse(t4);
Date ut5 = def.parse(t5);
//添加
times.add(ut1);
times.add(ut2);
times.add(ut3);
times.add(ut4);
times.add(ut5);
//遍历 it = times.iterator();
while(it.hasNext()){
Object e = it.next();
if(e instanceof Date){
Date d = (Date)e;
System.out.println(def.format(d));
} } }
}
(3)SortedSet内部的比较方法compareTo()
/*
SortedSet集合存储元素内部排序方法
sun编写TreeSe集合添加元素的时候,会调用compareTo方法完成比较
*/
import java.util.*;
class SortSet
{
public static void main(String[] args)
{
SortedSet users = new TreeSet();
User u1 = new User(10);
User u2 = new User(20);
User u3 = new User(13);
User u4 = new User(15);
User u5 = new User(2);
users.add(u1);
users.add(u2);
users.add(u3);
users.add(u4);
users.add(u5);
//遍历
Iterator it = users.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
}
}
class User implements Comparable //必须实现comparable接口
{
int age;
User(int age)
{
this.age=age;
}
public String toString(){
return "User[age="+age+"]";
}
//实现java.lang.Comparable;接口中的comparable方法
//按照user的age进行排序
@Override
public int compareTo(Object o) {
// TODO 自动生成的方法存根
int age1=this.age;
int age2=((User)o).age;
return age2-age1;
}
}
(4)SortedSet内部的比较方法Comparator
/*
SortedSet集合存储元素内部排序方法
*/
import java.util.*;
import java.util.Comparator;
class Main
{
public static void main(String[] args)
{
//创建TreeSet集合的时候提供一个比较器
SortedSet products = new TreeSet(new ProductComparator());
Product p1 = new Product(2.0);
Product p2 = new Product(3.0);
Product p3 = new Product(1.0);
Product p4 = new Product(6.0);
Product p5 = new Product(5.0);
//添加元素
products.add(p1);
products.add(p2);
products.add(p3);
products.add(p4);
products.add(p5);
//遍历
Iterator it = products.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
} class Product
{
double price;
Product(double price)
{
this.price=price;
}
public String toString(){
return price + "";
}
} class ProductComparator implements Comparator
{
@Override
public int compare(Object o1, Object o2) {
// TODO 自动生成的方法存根
double price1 = ((Product)o1).price;
double price2 = ((Product)o2).price;
if(price1 == price2){
return 0;
}
else if(price1>price2){
return 1;
}
else{
return -1;
}
}
}
2.2 常见集合的继承结构-Map

2.2.1 Map集合中常用实现类的数据结构及特点
(1)HashMap :
哈希表/散列表,底层是一个哈希表,HashMap中的Key等同一个Set集合(无序不重复,结构如下图),允许key或vaue为空,线程不安全。如果要使map线程安全,方法参考:http://www.cnblogs.com/cloudwind/archive/2012/08/30/2664003.html
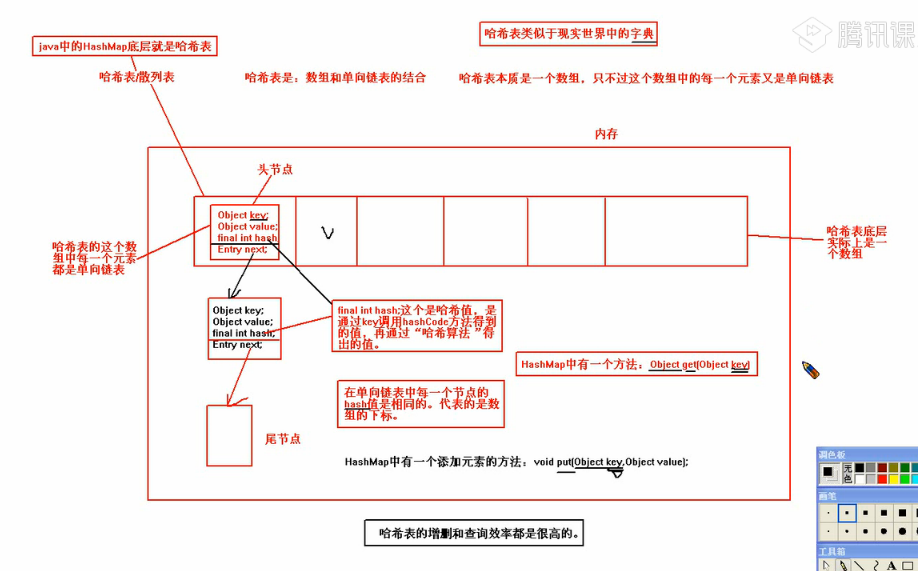
图. 哈希表/散列表
(2)Hashtable
线程安全的效率低。不允许key或vaue为空,线程安全。
(3)Properties
属性类,也可以是Key 和value的方式存储元素,但是Key 和value只能是字符串类型。Properties是HashTable的子类,不过Properties添加了两个方法,load()和store()可以直接导入或者将映射写入文件。
(4)SortedMap
SortedMap中的key存储元素的特点是:无序不可重复,但可以按照元素的大小进行自动排序,SortedMap中的key等同于SortedSet。
(5)TreeMap
TreeMap的Key就是一个TreeSet。
(6)LinkedHashMap
详解:http://www.cnblogs.com/chenpi/p/5294077.html
2.2.2、 Map集合中常用的方法分析

/*
Map中常用的方法举例
*存储在Map集合key部分的元素需要重写hashCode+equals方法
*/
import java.util.*;
class Maptest
{
public static void main(String[] args)
{
//创建Map集合
Map persons = new HashMap();//HashMap的默认初始化容量是16,默认加载因子是0.75
//存储键值对
persons.put("10000","lisi");
persons.put("10001","张三");
persons.put("10002","wangwu");
persons.put("10003","maliu");
persons.put("10004","zhaoqi");
//判断键值对你的个数,map中的key是无序不可重复的,和HashSet相同
System.out.println(persons.size()); System.out.println(persons.containsKey("10000")); System.out.println(persons.containsValue("张三")); System.out.println(persons.get("10000")); persons.remove("10004");
System.out.println(persons.size()); //获取所有的value
Collection value = persons.values();
Iterator it = value.iterator();
while(it.hasNext())
{
System.out.println(it.next());
}
//获取所有的Key
Set keys = persons.keySet();
Iterator it2 = keys.iterator();
while(it2.hasNext())
{
Object id = it2.next();
Object name = persons.get(id);
System.out.println(id+"->"+name);
}
//返回此映射中包含的映射关系的Set图
Set entrySet = persons.entrySet();
Iterator it3 = entrySet.iterator();
while(it3.hasNext())
{
System.out.println(it3.next());
}
/*
输出结果
10001=张三
10002=wangwu
10000=lisi
10003=maliu
*/
}
}
(1)Hashtable集合中常用的方法分析
/*
HashMap默认初始化容量是16,默认加载因子是0.75
Hashtable 默认初始化容量是11,默认家在因子是0.75
java.util.Properties,是由key和value都是字符串类型
*/
import java.util.Properties;
class MapProperties
{
public static void main(String[] args)
{
//创建属性类对象
Properties p = new Properties();
//存数据
p.setProperty("1000","z");
p.setProperty("1001","d");
p.setProperty("1002","s");
p.setProperty("1003","j");
//遍历,通过key获取value
String v1 = p.getProperty("1000");
String v2 = p.getProperty("1001");
String v3 = p.getProperty("1002");
String v4 = p.getProperty("1003"); System.out.println(v1);
System.out.println(v2);
System.out.println(v3);
System.out.println(v4);
}
}
/*
运行结果
z
d
s
j
*/
(2)SortedMap集合的用法
import java.util.*; /*
SortedMap中的key特点:无序不可重复,但存进去的元素可以按照大小自动排序
key的特点:1.实现Comparable接口2,,单独写一个比较器
*/
class SortedMaptest02
{ public static void main(String[] args)
{
//Map,Key存储Product,value个数
SortedMap<Product, Double> product = new TreeMap<Product, Double>();
//准备对象
Product p1 = new Product("肉1",12.0);
Product p2 = new Product("肉2",10.0);
Product p3 = new Product("肉3",11.0);
Product p4 = new Product("肉4",15.0);
Product p5 = new Product("肉5",17.0); product.put(p1,2.0);
product.put(p2,2.0);
product.put(p3,2.0);
product.put(p4,2.0);
product.put(p5,2.0);
//遍历
Set keys = product.keySet();
Iterator it = keys.iterator();
while(it.hasNext())
{
Object k = it.next();
Object v = product.get(k);
System.out.println(k+"..."+v);
}
}
}
//实现Comparable接口
class Product implements Comparable
{
String name;
double price;
Product(String name,double price){
this.name = name;
this.price = price;
}
public String toString()
{
return "Product[name = "+name+",price = "+price+"]";
}
//实现compareo方法,按照商品价格进行排序
public int compareTo(Object o)
{
double price1 = this.price;
double price2 = ((Product)o).price;
if(price1>price2)
return 1;
else if(price2>price1)
return -1;
else return 0; }
}
2.3 Collections集合工具类的用法
package test; /*
1.集合工具类 java.util.Collections (类)
2.Java.util.Collection 接口
*/
import java.util.*;
class Main
{
@SuppressWarnings("unchecked")
public static void main(String[] args)
{
@SuppressWarnings("rawtypes")
List list = new ArrayList();
list.add("5");
list.add("9");
list.add("8");
list.add("4");
list.add("6");
@SuppressWarnings("rawtypes")
Iterator it = list.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
System.out.println(".........................");
Collections.sort(list);
it = list.iterator();
while(it.hasNext()){
System.out.println(it.next());
} //对set集合进行排序
Set s = new HashSet();
s.add("3");
s.add("1");
s.add("8");
s.add("4");
s.add("6");
System.out.println(".........................");
//不能更直接使用Collections。sort(s)进行排序
//将Set集合转换成List集合
List lists = new ArrayList(s);
Collections.sort(lists);
it = lists.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
//将ArrayList转换成线程安全的
List mylist = new ArrayList<>();
Collections.synchronizedList(mylist); }
}
3.泛型
泛型是Java SE 1.5的新特性,泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。这种参数类型可以用在类、接口和方法的创建中,分别称为泛型类、泛型接口、泛型方法。 JAVA语言引入泛型的好处是安全简单。在Java SE 1.5之前,没有泛型的情况的下,通过对类型Object的引用来实现参数的“任意化”,“任意化”带来的缺点是要做显式的强制类型转换,而这种转换是要求开发者对实际参数类型可以预知的情况下进行的。对于强制类型转换错误的情况,编译器可能不提示错误,在运行的时候才出现异常,这是一个安全隐患。
package test; /*
JDk5.0新特性:泛型(编译阶段的语法,在编译阶段同一集合中的类型)
1.语法实现
2.优点:使集合中的元素的类型统一,减少强制类型转换
3.缺点:只能存储一种数据类型
*/
import java.util.*;
class Main
{
public static void main(String[] args)
{
//创建一个List集合,只能存储字符串类型
List <String> str = new ArrayList<String>();
str.add("sd");
str.add("sfhj");
str.add("dsf");
str.add("hjk");
str.add("sdf");
Iterator <String> it = str.iterator();
while(it.hasNext()){
String s = it.next();
System.out.println(s);
}
}
}
List和Map集合详细分析的更多相关文章
- java Map集合对比分析
1.Map:Map是所有map集合的顶级父接口,用于key/value形式的键值对,其中每一个key都映射到一个值,key不能重复. 2.TreeMap:该map将存储的键值对进行默认排序,并且还能够 ...
- Java容器 | 基于源码分析Map集合体系
一.容器之Map集合 集合体系的源码中,Map中的HashMap的设计堪称最经典,涉及数据结构.编程思想.哈希计算等等,在日常开发中对于一些源码的思想进行参考借鉴还是很有必要的. 基础:元素增查删.容 ...
- ZIP压缩算法详细分析及解压实例解释
最近自己实现了一个ZIP压缩数据的解压程序,觉得有必要把ZIP压缩格式进行一下详细总结,数据压缩是一门通信原理和计算机科学都会涉及到的学科,在通信原理中,一般称为信源编码,在计算机科学里,一般称为数据 ...
- Http Pipeline详细分析(下)
Http Pipeline详细分析(下) 文章内容 接上面的章节,我们这篇要讲解的是Pipeline是执行的各种事件,我们知道,在自定义的HttpModule的Init方法里,我们可以添加自己的事件, ...
- Java实现Map集合二级联动
Map集合可以保存键值映射关系,这非常适合本实例所需要的数据结构,所有省份信息可以保存为Map集合的键,而每个键可以保存对应的城市信息,本实例就是利用Map集合实现了省市级联选择框,当选择省份信息时, ...
- HashMap 源码详细分析(JDK1.8)
一.概述 本篇文章我们来聊聊大家日常开发中常用的一个集合类 - HashMap.HashMap 最早出现在 JDK 1.2中,底层基于散列算法实现.HashMap 允许 null 键和 null 值, ...
- LinkedHashMap 源码详细分析(JDK1.8)
1. 概述 LinkedHashMap 继承自 HashMap,在 HashMap 基础上,通过维护一条双向链表,解决了 HashMap 不能随时保持遍历顺序和插入顺序一致的问题.除此之外,Linke ...
- zip压缩详细分析
该文章转自:http://www.cnblogs.com/esingchan/p/3958962.html (文章写得很详细,让我对zip压缩有了了解,感谢博主,贴在这是为了防止忘了有这么好的文章,侵 ...
- java读源码 之 map源码分析(HashMap)二
在上篇文章中,我已经向大家介绍了HashMap的一些基础结构,相信看过文章的同学们,应该对其有一个大致了了解了,这篇文章我们继续探究它的一些内部机制,包括构造函数,字段等等~ 字段分析: // 默 ...
随机推荐
- 019-PHP创建目录函数
<?php if (mkdir("myDir1", 0777)) //创建目录的函数 { print("目录创建成功"); //目录建立成功 } else ...
- 157-PHP strrchr函数输出最后一次出现字母p的位置到字符串结尾的所有字符串
<?php $str='PHP is a very good programming language!'; //定义一个字符串 echo strrchr($str,'o'); //输出最后一次 ...
- IDE一直在indexing, 造成系统卡死解决方法
点击箭头指向,重启idea
- Centos 7 x86_64 环境Python2.7升级Python3.7.4
升级Python3.7.4 #安装补丁包yum install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel read ...
- Day 17:缓冲输出字符流和用缓冲输入输出实现登录、装饰者设计模式
输出字符流 Writer 所有输出字符流的基类, 抽象类. FileWriter 向文件输出字符数据的输出字符流. BufferedWriter 缓冲输出字符流 缓冲输出字符流作用: ...
- C语言拾遗——sscanf
今天写题用到了sscanf,怕忘赶紧记录一下 去百度了一下这玩意的函数原型好像是长这样的,微软上扣下来的 int sscanf( const char *buffer, const char *fo ...
- HDU 1003:Max Sum
Max Sum Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Su ...
- 线程与进程 queue模块
queue模块的基本用法 https://www.cnblogs.com/chengd/articles/7778506.html 模块实现了3种类型的队列,区别在于队列中条目检索的顺序不同.在FIF ...
- 十、CI框架之通过参数的办法输出URI路径
一.代码如下,index函数有2个参数 二.效果如下: 不忘初心,如果您认为这篇文章有价值,认同作者的付出,可以微信二维码打赏任意金额给作者(微信号:382477247)哦,谢谢.
- Hour of Code|京东云邀您一起,“码”上行动
"如果我并不希望成为一名程序员,那么为什么需要学习编程呢?" 相信很多人对于现在鼓励从小就学习编程的趋势都在心里问过这样的一个问题.在回答这个问题前,先和大家分享一个小故事吧. 1 ...