mysql分区介绍
http://www.cnblogs.com/chenmh/p/5644713.html
介绍
可以针对分区表的每个分区指定各自的存储路径,对于innodb存储引擎的表只能指定数据路径,因为数据和索引是存储在一个文件当中,对于MYISAM存储引擎可以分别指定数据文件和索引文件,一般也只有RANGE、LIST分区、sub子分区才有可能需要单独指定各个分区的路径,HASH和KEY分区的所有分区的路径都是一样。RANGE分区指定路径和LIST分区是一样的,这里就拿LIST分区来做讲解。
一、MYISAM存储引擎

CREATE TABLE th (id INT, adate DATE)
engine='MyISAM'
PARTITION BY LIST(YEAR(adate))
(
PARTITION p1999 VALUES IN (1995, 1999, 2003)
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx',
PARTITION p2000 VALUES IN (1996, 2000, 2004)
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx',
PARTITION p2001 VALUES IN (1997, 2001, 2005)
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx',
PARTITION p2002 VALUES IN (1998, 2002, 2006)
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx'
);
注意:MYISAM存储引擎的数据文件和索引文件是分库存储所以可以为数据文件和索引文件定义各自的路径,INNODB存储引擎只能定义数据路径。
二、INNODB存储引擎
CREATE TABLE thex (id INT, adate DATE)
engine='InnoDB'
PARTITION BY LIST(YEAR(adate))
(
PARTITION p1999 VALUES IN (1995, 1999, 2003)
DATA DIRECTORY = '/data/data', PARTITION p2000 VALUES IN (1996, 2000, 2004)
DATA DIRECTORY = '/data/data', PARTITION p2001 VALUES IN (1997, 2001, 2005)
DATA DIRECTORY = '/data/data', PARTITION p2002 VALUES IN (1998, 2002, 2006)
DATA DIRECTORY = '/data/data' );
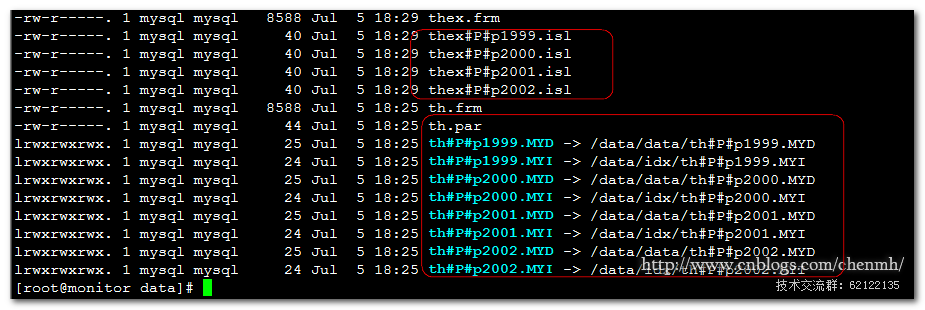
指定路径之后在原来的路径中innodb生成了4个指向数据存储的路径文件,myisam生成了一个th.par文件指明该表是分区表,同时数据文件和索引文件指向了实际的存储路径。
三、子分区
1.子分区
CREATE TABLE tb_sub_dir (id INT, purchased DATE)
ENGINE='MYISAM'
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) ) (
PARTITION p0 VALUES LESS THAN (1990)
(
SUBPARTITION s0
DATA DIRECTORY = '/data/data_sub1'
INDEX DIRECTORY = '/data/idx_sub1',
SUBPARTITION s1
DATA DIRECTORY = '/data/data_sub1'
INDEX DIRECTORY = '/data/idx_sub1'
),
PARTITION p1 VALUES LESS THAN (2000)
(
SUBPARTITION s2
DATA DIRECTORY = '/data/data_sub2'
INDEX DIRECTORY = '/data/idx_sub2',
SUBPARTITION s3
DATA DIRECTORY = '/data/data_sub2'
INDEX DIRECTORY = '/data/idx_sub2'
),
PARTITION p2 VALUES LESS THAN MAXVALUE
(
SUBPARTITION s4
DATA DIRECTORY = '/data/data_sub3'
INDEX DIRECTORY = '/data/idx_sub3',
SUBPARTITION s5
DATA DIRECTORY = '/data/data_sub3'
INDEX DIRECTORY = '/data/idx_sub3'
)
);
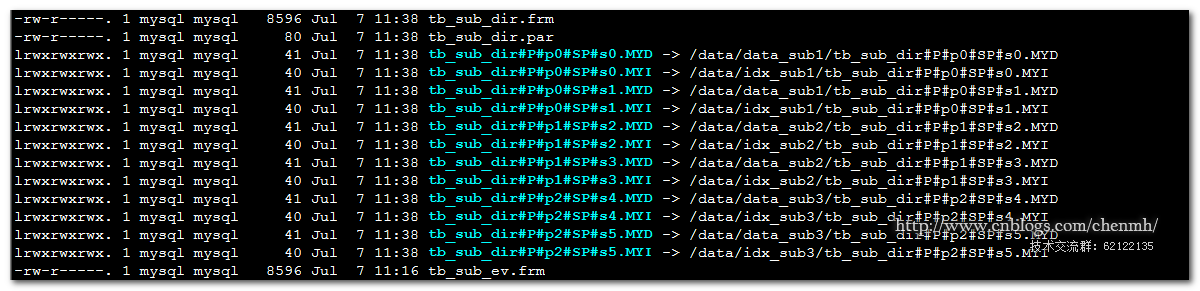
2.子分区再分
CREATE TABLE tb_sub_dirnew (id INT, purchased DATE)
ENGINE='MYISAM'
PARTITION BY RANGE( YEAR(purchased) )
SUBPARTITION BY HASH( TO_DAYS(purchased) ) (
PARTITION p0 VALUES LESS THAN (1990)
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx'
(
SUBPARTITION s0
DATA DIRECTORY = '/data/data_sub1'
INDEX DIRECTORY = '/data/idx_sub1',
SUBPARTITION s1
DATA DIRECTORY = '/data/data_sub1'
INDEX DIRECTORY = '/data/idx_sub1'
),
PARTITION p1 VALUES LESS THAN (2000)
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx'
(
SUBPARTITION s2
DATA DIRECTORY = '/data/data_sub2'
INDEX DIRECTORY = '/data/idx_sub2',
SUBPARTITION s3
DATA DIRECTORY = '/data/data_sub2'
INDEX DIRECTORY = '/data/idx_sub2'
),
PARTITION p2 VALUES LESS THAN MAXVALUE
DATA DIRECTORY = '/data/data'
INDEX DIRECTORY = '/data/idx'
(
SUBPARTITION s4
DATA DIRECTORY = '/data/data_sub3'
INDEX DIRECTORY = '/data/idx_sub3',
SUBPARTITION s5
DATA DIRECTORY = '/data/data_sub3'
INDEX DIRECTORY = '/data/idx_sub3'
)
);
也可以给个分区指定路径后再给子分区指定路径,但是这样没有意义,因为数据的存在都是由子分区决定的。
注意:
1.指定的路径必须存在,否则分区无法创建成功
2.MYISAM存储引擎的数据文件和索引文件是分库存储所以可以为数据文件和索引文件定义各自的路径,INNODB存储引擎只能定义数据路径
分区系列文章:
RANGE分区:http://www.cnblogs.com/chenmh/p/5627912.html
LIST分区:http://www.cnblogs.com/chenmh/p/5643174.html
COLUMN分区:http://www.cnblogs.com/chenmh/p/5630834.html
HASH分区:http://www.cnblogs.com/chenmh/p/5644496.html
KEY分区:http://www.cnblogs.com/chenmh/p/5647210.html
子分区:http://www.cnblogs.com/chenmh/p/5649447.html
分区建索引:http://www.cnblogs.com/chenmh/p/5761995.html
分区介绍总结:http://www.cnblogs.com/chenmh/p/5623474.html
总结
通过给各个分区指定各自的磁盘可以有效的提高读写性能,在条件允许的情况下是一个不错的方法。
mysql分区介绍的更多相关文章
- MySQL 分区介绍总结
200 ? "200px" : this.width)!important;} --> 介绍 分区是指根据一定的规则将一个大表分解成多个更小的部分,这里的规则一般就是利用分区 ...
- MySQL分区 (分区介绍与实际使用)
分区介绍: 一.什么是分区? 所谓分区,就是将一个表分成多个区块进行操作和保存,从而降低每次操作的数据,提高性能.而对于应用来说则是透明的,从逻辑上看只有一张表,但在物理上这个表可能是由多个物理分区组 ...
- mysql分区
<?php /* 分区 目录 18.1. MySQL中的分区概述 18.2. 分区类型 18.2.1. RANGE分区 18.2.2. LIST分区 18.2.3. HASH分区 18.2.4. ...
- MySQL分区技术 (一)
4:MySQL 分区技术(是mysql 5.1以版本号后開始用->是甲骨文mysql技术团队维护人员以插件形式插入到mysql里面的技术) 眼下,针对海量数据的优化主要有2中方法: 1:大表拆成 ...
- MySQL 分区建索引
200 ? "200px" : this.width)!important;} --> 介绍 mysql分区后每个分区成了独立的文件,虽然从逻辑上还是一张表其实已经分成了多张 ...
- MySQL入门介绍(mysql-8.0.13)
MySQL入门介绍(mysql-8.0.13单机部署) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MySQL数据库介绍 1>.MySQL是一种开放源代码的关系型数据库 ...
- mysql分区表之三:MySQL分区建索引[转]
介绍 mysql分区后每个分区成了独立的文件,虽然从逻辑上还是一张表其实已经分成了多张独立的表,从“information_schema.INNODB_SYS_TABLES”系统表可以看到每个分区都存 ...
- mysql分区 详解
第18章:分区 目录 18.1. MySQL中的分区概述 18.2. 分区类型 18.2.1. RANGE分区 18.2.2. LIST分区 18.2.3. HASH分区 18.2.4. KEY分区 ...
- 由mysql分区想到的分表分库的方案
在分区分库分表前一定要了解分区分库分表的动机. 对实时性要求比较高的场景,使用数据库的分区分表分库. 对实时性要求不高的场景,可以考虑使用索引库(es/solr)或者大数据hadoop平台来解决(如数 ...
随机推荐
- HDU1875 畅通工程再续
相信大家都听说一个“百岛湖”的地方吧,百岛湖的居民生活在不同的小岛中,当他们想去其他的小岛时都要通过划小船来实现.现在政府决定大力发展百岛湖,发展首先要解决的问题当然是交通问题,政府决定实现百岛湖的全 ...
- Educational Codeforces Round 81 (Rated for Div. 2)
A 0~9需要多少笔画,自取7和1,判奇偶 #include<bits/stdc++.h> using namespace std; #define ll long long #defin ...
- Mac下MyEclipse安装及破解
一.安装MyEclipse 去 官网下载MyEclipse ,我这里下载的是最新版MyEclipse 2017 CI 5,安装之后不要立即打开,不然会导致后面破解失败. 二.破解 1.下载破解文件,亲 ...
- php 基础知识 常见面试题
1.echo.print_r.print.var_dump之间的区别 * echo.print是php语句,var_dump和print_r是函数 * echo 输出一个或多个字符串,中间以逗号隔开, ...
- Python 基础之文件操作与文件的相关函数
一.文件操作 fp =open("文件名",mode="采用的模式",encoding="使用什么编码集")fp 这个变量接受到open的返 ...
- 五年C语言程序员,是深耕技术还是走管理?
从进入程序员行列开始(2013年6月),到现在为止(2019年2月),已经有五年半了. 一路波折,已经从无知菜鸟走到了意识觉醒的老鸟了. 薪资变化情况如下: 2013年:2000元/月 ( ...
- golang的io.copy使用
net/http 下载 在golang中,如果我们要下载一个文件,最简单的就是先用http.get()方法创建一个远程的请求后,后面可使用ioutil.WriteFile()等将请求内容直接写到文件中 ...
- Python 爬取 热词并进行分类数据分析-[解释修复+热词引用]
日期:2020.02.02 博客期:141 星期日 [本博客的代码如若要使用,请在下方评论区留言,之后再用(就是跟我说一声)] 所有相关跳转: a.[简单准备] b.[云图制作+数据导入] c.[拓扑 ...
- selenium webdriver 执行Javascript
@Test public void testElementByID() { //通过JS获取页面元素 driver.get(url); driver.manage().window().maximiz ...
- nginx 加工上游服务器返回的内容,并返回给客户端
禁用上游响应头部功能 Syntax: proxy_ignore_headers field ...; Default: — Context: http, server, location 功能介绍:某 ...