scrapy中间件之下载中间件使用(网易新闻爬取)
scrapy项目中的middlewarse.py中间件
爬虫中间件:目前先不介绍
下载中间件(需要在settings.py中开启)
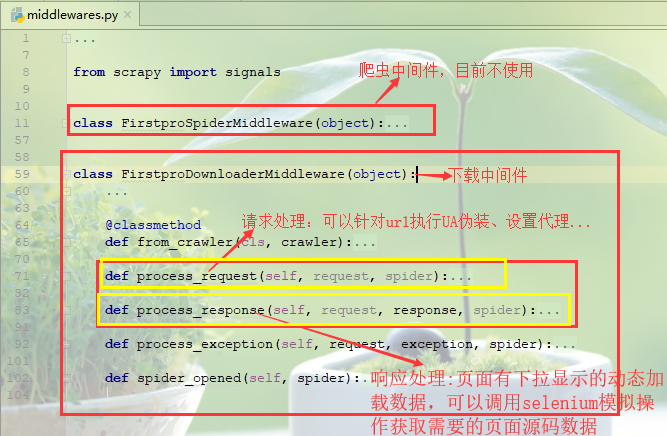
- (1)请求处理函数:process_request(self, request, spider)
可以针对url请求指定UA伪装、配置代理等功能(UA伪装可以在settings.py中进行全局配置,代理配置更倾向于在异常处理函数,大部分异常都是因为ip的问题)
- def process_request(self, request, spider):
- #UA伪装
- # request.headers['User-Agent']=random.choice(UA_list)
- #ip代理配置(一般更多的放在process_exception异常处理函数中)
- # request.meta['proxy']='http[s]://ip:port'
- return None
process_request
- (2)响应处理函数:process_response(self, request, response, spider)
对于一些网页请求,立即相应的数据可能不完全,页面部分内容是通过触发滚轮或者下拉操作才会动态加载的数据,因此获取的到数据并不是完整的,需要对响应对象进行篡改(比如通过selenium模拟浏览器操作获取到完整数据)后返回。
- (3)异常处理函数:process_exception(self, request, exception, spider)
对于请求异常处理,一般可以更换ip设置代理操作
- def process_exception(self, request, exception, spider):
- #对请求异常进行修正
- #更换代理(一定要 return request将请求返回以便再次发起)
- # request.meta['proxy']='http[s]://ip:port'
- # return request
- pass
process_exception
网易新闻爬取案例:
分析页面可以获知不同板块内容都是页面下拉动态加载的:国内、国际、军事、航空、无人机这几个板块内容都是标题都是在div中的一个a标签中,因此统一来进行爬取解析!
1.新建爬虫项目
- scrapy startproject firstPro
- cd firstPro
- scrapy genspider middlewareTest www.xxx.com
2.编写爬虫文件middlewareTest.py
- # -*- coding: utf-8 -*-
- import scrapy
- from firstPro.items import FirstproItem
- from selenium import webdriver
- class MiddlewaretestSpider(scrapy.Spider):
- name = 'middlewareTest'
- # allowed_domains = ['www.xxx.com']
- start_urls = ['https://news.163.com/']
- plate_urls=[]#存放板块的url,以便在下载中间件次改请求获取完整标题数据
- def __init__(self):
- self.bro=webdriver.Chrome(executable_path=r'E:\Python项目\爬虫\day110_20190809(全站爬取、分布式爬虫)\firstPro\firstPro\spiders\chromedriver.exe')#初始化浏览器实例
- def parse(self, response):
- #解析首页标题板块
- li_list=response.xpath('//div[@class="ns_area list"]/ul/li')
- print(len(li_list))
- #确定爬取的板块
- index_list=[4,5,7,8,9]
- for index in index_list:
- item=FirstproItem()
- plate=li_list[index-1].xpath('./a/text()').extract_first()
- url=li_list[index-1].xpath('./a/@href').extract_first()
- self.plate_urls.append(url)
- item['plate']=plate
- # 对每个板块进行发起请求,获取标题信息
- yield scrapy.Request(url,callback=self.parse_title,meta={"item":item})
- break
- #对每个板块的新闻标题进行解析,但是新闻标题都是动态加载的,因此直接的响应对象不完整,需要通过下载中间件对新闻板块标题获取进行处理
- #解决思路:为获取板块完整标题内容,需要模拟浏览器下拉操作,结合使用selenuim在下载中间件进行操作
- def parse_title(self, response):
- item=response.meta['item']
- #解析每个板块中的新闻标题
- div_list=response.xpath('//div[@class="ndi_main"]/div')
- for div in div_list:
- title=div.xpath('./div/div[1]/h3/a/text()').extract_first()
- url=div.xpath('./div/div[1]/h3/a/@href').extract_first()
- item["title"]=title
- #对每个标题详情发起请求
- yield scrapy.Request(url,callback=self.parse_detail,meta={"item":item})
- def parse_detail(self,response):
- item = response.meta['item']
- #解析每个标题对应的详细新闻内容
- content="".join(response.xpath('//*[@id="endText"]//text()').extract())
- item["content"]=content
- yield item
- # 程序全部结束的时候被调用
- def closed(self, spider):
- print('结束爬虫!!!')
- self.bro.quit()
爬虫脚本middlewareTest.py
3.定义items.py字段属性
- import scrapy
- class FirstproItem(scrapy.Item):
- # define the fields for your item here like:
- # name = scrapy.Field()
- #新闻板块
- plate=scrapy.Field()
- #新闻标题
- title=scrapy.Field()
- #新闻详情
- content=scrapy.Field()
- pass
items.py
4.管道pipelines.py持久化
- import redis
- class FirstproPipeline(object):
- #持久化存储在redis数据库中
- conn=None
- # def open_spider(self,spider):
- # self.conn=redis.Redis(host="127.0.0.1",port=6379)
- def process_item(self, item, spider):
- # self.conn.lpush('wangyi',dict(item))
- print(item)
- return item
pipelines.py
5.settings.py配置
- #UA伪装
- USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
- #robots协议
- ROBOTSTXT_OBEY = False
- #输出日志等级
- LOG_LEVEL="ERROR"
- #打开下载中间件
- DOWNLOADER_MIDDLEWARES = {
- 'firstPro.middlewares.FirstproDownloaderMiddleware': 543,
- }
- #打开管道
- ITEM_PIPELINES = {
- 'firstPro.pipelines.FirstproPipeline': 300,
- }
scrapy中间件之下载中间件使用(网易新闻爬取)的更多相关文章
- python爬虫---scrapy框架爬取图片,scrapy手动发送请求,发送post请求,提升爬取效率,请求传参(meta),五大核心组件,中间件
# settings 配置 UA USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, l ...
- scrapy架构与目录介绍、scrapy解析数据、配置相关、全站爬取cnblogs数据、存储数据、爬虫中间件、加代理、加header、集成selenium
今日内容概要 scrapy架构和目录介绍 scrapy解析数据 setting中相关配置 全站爬取cnblgos文章 存储数据 爬虫中间件和下载中间件 加代理,加header,集成selenium 内 ...
- Python 网络爬虫 006 (编程) 解决下载(或叫:爬取)到的网页乱码问题
解决下载(或叫:爬取)到的网页乱码问题 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 Python 的集成开发环境:PyCharm 20 ...
- Python 网络爬虫 005 (编程) 如何编写一个可以 下载(或叫:爬取)一个网页 的网络爬虫
如何编写一个可以 下载(或叫:爬取)一个网页 的网络爬虫 使用的系统:Windows 10 64位 Python 语言版本:Python 2.7.10 V 使用的编程 Python 的集成开发环境:P ...
- python 全栈开发,Day138(scrapy框架的下载中间件,settings配置)
昨日内容拾遗 打开昨天写的DianShang项目,查看items.py class AmazonItem(scrapy.Item): name = scrapy.Field() # 商品名 price ...
- scrapy框架4——下载中间件的使用
一.下载中间件 下载中间件是scrapy提供用于用于在爬虫过程中可修改Request和Response,用于扩展scrapy的功能:比如: 可以在请求被Download之前,请求头部加上某些信息(例如 ...
- scrapy框架之下载中间件
介绍 中间件是Scrapy里面的一个核心概念.使用中间件可以在爬虫的请求发起之前或者请求返回之后对数据进行定制化修改,从而开发出适应不同情况的爬虫. “中间件”这个中文名字和前面章节讲到的“中间人”只 ...
- Scrapy教程——搭建环境、创建项目、爬取内容、保存文件
1.创建项目 在开始爬取之前,您必须创建一个新的Scrapy项目.进入您打算存储代码的目录中,运行新建命令. 例如,我需要在D:\00Coding\Python\scrapy目录下存放该项目,打开命令 ...
- Scrapy分布式爬虫打造搜索引擎- (二)伯乐在线爬取所有文章
二.伯乐在线爬取所有文章 1. 初始化文件目录 基础环境 python 3.6.5 JetBrains PyCharm 2018.1 mysql+navicat 为了便于日后的部署:我们开发使用了虚拟 ...
随机推荐
- mysql查询添加
当表结构一样的情况下,insert into 想要插入的表 SELECT * from 查询的表; 此sql语句,适应于 1000万数据插入1000万数据中去,2000万数据的合并 .------ ...
- view-controller
有的时候我们只想根据一个请求地址跳转到一个页面中,中间并没有任何的处理流程,这个时候创建一个 Controller 类再编写方法来跳转就显得很繁琐.这个时候我们就可以使用 view-controlle ...
- Nmap详细用法
探测主机存活 (1)-sP :进行ping扫描 (2) -sn: ping探测扫描主机, 不进行端口扫描 (3)-sA 发送ACK探测存活 端口扫描 (1) -sS :半开放扫描 (2) sT ...
- windows server 2012 R2系统安装部署SQLserver2016企业版(转)
转自 https://blog.csdn.net/qq_35938548/article/details/80272288 安装sql server是一个很繁琐的事情,花了一下午时间倒腾,现记录下整 ...
- NFS共享设置
一.安装所需要的软件环境[root@fengling ~]# yum -y install rpcbind nfs-utils二.创建共享目录mkdir /web三.启动服务[root@fenglin ...
- ubuntu(物理机)连接ARM开发板
非虚拟机 ubuntu下连接开发板 首先安装超级终端minicom sudo apt-get install minicom 安装完minicom以后,需要将开发板和电脑进行物理连接.需要使用一条网线 ...
- Java阻塞队列四组API介绍
Java阻塞队列四组API介绍 通过前面几篇文章的学习,我们已经知道了Java中的队列分为阻塞队列和非阻塞队列以及常用的七个阻塞队列.如下图: 本文来源:凯哥Java(kaigejava)讲解Java ...
- 【JAVA基础】07 面向对象2
1. 代码块的概述和分类 面试的时候会问,开发不用或者很少用 代码块概述 在Java中,使用 {} 括起来的代码被称为代码块. 代码块分类 根据其位置和声明的不同,可以分为局部代码块,构造代码块,静态 ...
- telnet 636端口不通
今天发生了一件奇怪的事情,LDAP的636端口突然就不通了报错如下 [www@DC ~]$ telnet 10.219.90.173 636Trying10.219.90.173...Connecte ...
- HyperLeger Fabric开发(三)——HyperLeger Fabric架构
HyperLeger Fabric开发(三)--HyperLeger Fabric架构 一.HyperLeger Fabric逻辑架构 1.HyperLeger Fabric逻辑架构简介 Fabric ...