【原创】Linux信号量机制分析
背景
Read the fucking source code!--By 鲁迅A picture is worth a thousand words.--By 高尔基
说明:
- Kernel版本:4.14
- ARM64处理器,Contex-A53,双核
- 使用工具:Source Insight 3.5, Visio
1. 概述
- 信号量
semaphore,是操作系统中一种常用的同步与互斥的机制; - 信号量允许多个进程(计数值>1)同时进入临界区;
- 如果信号量的计数值为1,一次只允许一个进程进入临界区,这种信号量叫二值信号量;
- 信号量可能会引起进程睡眠,开销较大,适用于保护较长的临界区;
- 与读写自旋锁类似,linux内核也提供了读写信号量的机制;
本文将分析信号量与读写信号量的机制,开始吧。
2. 信号量
2.1 流程分析
- 可以将信号量比喻成一个盒子,初始化时在盒子里放入N把钥匙,钥匙先到先得,当N把钥匙都被拿走完后,再来拿钥匙的人就需要等待了,只有等到有人将钥匙归还了,等待的人才能拿到钥匙;
信号量的实现很简单,先看一下数据结构:
struct semaphore {
raw_spinlock_t lock; //自旋锁,用于count值的互斥访问
unsigned int count; //计数值,能同时允许访问的数量,也就是上文中的N把锁
struct list_head wait_list; //不能立即获取到信号量的访问者,都会加入到等待列表中
};
struct semaphore_waiter {
struct list_head list; //用于添加到信号量的等待列表中
struct task_struct *task; //用于指向等待的进程,在实际实现中,指向current
bool up; //用于标识是否已经释放
};
流程如下:
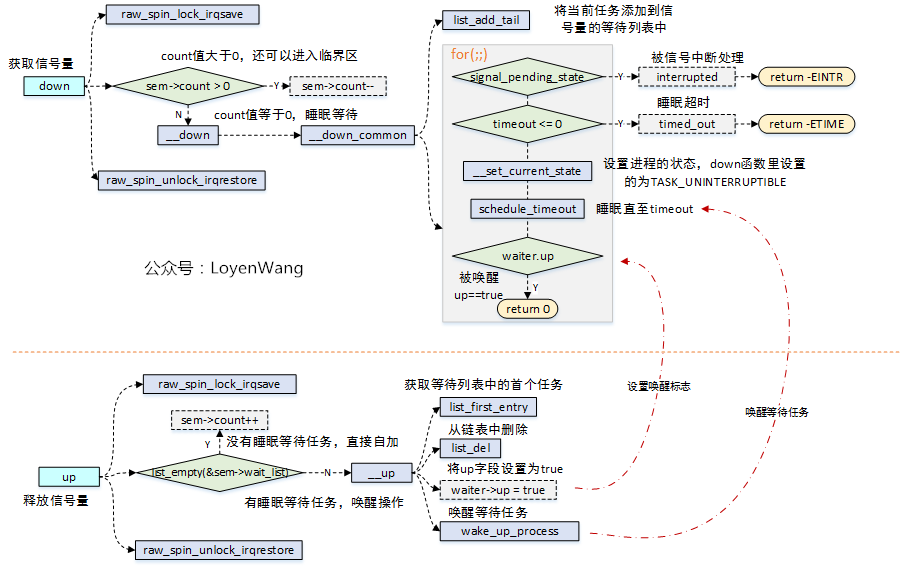
down接口用于获取信号量,up用于释放信号量;- 调用
down时,如果sem->count > 0时,也就是盒子里边还有多余的锁,直接自减并返回了,当sem->count == 0时,表明盒子里边的锁被用完了,当前任务会加入信号量的等待列表中,设置进程的状态,并调用schedule_timeout来睡眠指定时间,实际上这个时间设置的无限等待,也就是只能等着被唤醒,当前任务才能继续运行; - 调用
up时,如果等待列表为空,表明没有多余的任务在等待信号量,直接将sem->count自加即可。如果等待列表非空,表明有任务正在等待信号量,那就需要对等待列表中的第一个任务(等待时间最长)进行唤醒操作,并从等待列表中将需要被唤醒的任务进行删除操作;
2.2 信号量缺点
- 对比下
《Linux Mutex机制分析》说过的Mutex,Semaphore与Mutex在实现上有一个重大的区别:ownership。Mutex被持有后有一个明确的owner,而Semaphore并没有owner,当一个进程阻塞在某个信号量上时,它没法知道自己阻塞在哪个进程(线程)之上; - 没有
ownership会带来以下几个问题:- 在保护临界区的时候,无法进行优先级反转的处理;
- 系统无法对其进行跟踪断言处理,比如死锁检测等;
- 信号量的调试变得更加麻烦;
因此,在Mutex能满足要求的情况下,优先使用Mutex。
2.3 其他接口
信号量提供了多种不同的信号量获取的接口,介绍如下:
/* 未获取信号量时,进程轻度睡眠: TASK_INTERRUPTIBLE */
int down_interruptible(struct semaphore *sem)
/* 未获取到信号量时,进程中度睡眠: TASK_KILLABLE */
int down_killable(struct semaphore *sem)
/* 非等待的方式去获取信号量 */
int down_trylock(struct semaphore *sem)
/* 获取信号量,并指定等待时间 */
int down_timeout(struct semaphore *sem, long timeout)
3. 读写信号量
【原创】linux spinlock/rwlock/seqlock原理剖析(基于ARM64)文章中,我们分析过读写自旋锁,读写信号量的功能类似,它能有效提高并发性,我们先明确下它的特点:
- 允许多个读者同时进入临界区;
- 读者与写者不能同时进入临界区(读者与写者互斥);
- 写者与写者不能同时进入临界区(写者与写者互斥);
3.1 数据结构
读写信号量的数据结构与信号量的结构比较相似:
struct rw_semaphore {
atomic_long_t count; //用于表示读写信号量的计数
struct list_head wait_list; //等待列表,用于管理在该信号量上睡眠的任务
raw_spinlock_t wait_lock; //锁,用于保护count值的操作
#ifdef CONFIG_RWSEM_SPIN_ON_OWNER
struct optimistic_spin_queue osq; /* spinner MCS lock */ //MCS锁,参考上一篇文章Mutex中的介绍
/*
* Write owner. Used as a speculative check to see
* if the owner is running on the cpu.
*/
struct task_struct *owner; //当写者成功获取锁时,owner会指向锁的持有者
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
- 最关键的需要看一下
count字段,掌握了这个字段的处理,才能比较好理解读写信号量的机制; - 【原创】linux spinlock/rwlock/seqlock原理剖析(基于ARM64)文章中提到过读写自旋锁,读写自旋锁中的
lock字段,bit[31]用于写锁的标记,bit[30:0]用于读锁的统计,而读写信号量的count字段也大体类似;

- 以32位的count值为例,高16bit代表的是
waiting part,低16bit代表的是active part; RWSEM_UNLOCKED_VALUE:值为0,表示锁未被持有,没有读者也没有写者;RWSEM_ACTIVE_BIAS:值为1,,该值用于定义RWSEM_ACTIVE_READ_BIAS和RWSEM_ACTIVE_WRITE_BIAS;RWSEM_WAITING_BIAS:值为-65536,当有任务需要加入到等待列表中时,count值需要加RWSEM_WAITING_BIAS,有任务需要从等待列表中移除时,count值需要减去RWSEM_WAITING_BIAS;RWSEM_ACTIVE_READ_BIAS:值为1,当有读者去获取锁的时候,count值将加RWSEM_ACTIVE_READ_BIAS,释放锁的时候,count值将减去RWSEM_ACTIVE_READ_BIAS;RWSEM_ACTIVE_WRITE_BIAS,值为-65535,当有写者去获取锁的时候,count值将加RWSEM_ACTIVE_WRITE_BIAS,释放锁的时候,count值需要减去RWSEM_ACTIVE_WRITE_BIAS;
在获取释放读锁和写锁的全过程中,
count值伴随着上述这几个宏定义的加减操作,用于标识不同的状态,可以罗列如下:
0x0000000X:活跃的读者和正在申请读锁的读者总共为X个,没有写者来干扰;0x00000000:没有读者和写者来操作,初始化状态;0xFFFF000X:分为以下几种情况:0xFFFF000X = RWSEM_WAITING_BIAS + X * RWSEM_ACTIVE_READ_BIAS,表示活跃的读者和正在申请读锁的读者总共有X个,并且还有一个写者在睡眠等待;0xFFFF000X = RWSEM_ACTIVE_WRITE_BIAS + (X - 1)* RWSEM_ACTIVE_READ_BIAS,表示有一个写者在尝试获取锁,活跃的读者和正在申请读锁的读者总共有X-1个;
0xFFFF0001:分为以下几种情况:0xFFFF0001 = RWSEM_ACTIVE_WRITE_BIAS,有一个活跃的写者,或者写者正在尝试获取锁,没有读者干扰;0xFFFF0001 = RWSEM_ACTIVE_READ_BIAS + RWSEM_WAITING_BIAS,有个写者正在睡眠等待,还有一个活跃或尝试获取锁的读者;
3.1 读信号量
3.1.1 读者获取锁

- 特点:读者与读者可以并发执行,读者与写者互斥执行,因此当有写者持有锁的时候,读者将进入睡眠状态;
- 当
sem->count加1后还是小于0,代表锁已经被写者持有了,读者获取锁失败,进入rwsem_down_read_failed函数; - 如果
sem->wait_list是空时,代表没有任务在等待列表中,首次加入时,sem->count值需要加上RWSEM_WAITING_BIAS,表示有任务在等待列表中; - 如果此时
sem->count == RWSEM_WAITING_BIAS或者count > RWSEM_WAITING_BIAS && adjustment != RWSEM_ACTIVE_READ_BIAS,表示此时写者将锁释放了,因此需要去唤醒在等待列表中的任务; - 如果写者没有释放锁,那就进入循环,并调用
schedule让出CPU,直到锁被释放了,那么从代码流程中看,只有!waiter.task时才会跳出循环,也就是waiter.task == NULL时,才是获取成功,这个操作是在__rwsem_mark_wake中通过smp_store_release(&waiter->task, NULL)实现的; - 在等待获取锁的循环中,需要对信号进行处理,如果对应的等待任务没被唤醒,那么直接跳转到
out_nolock处,接下来的处理就是一些逆操作了,包括从等待列表中删除,如果是等待列表中的首个任务,还需要减去RWSEM_WAITING_BIAS等;
总结一下:
读者获取锁的时候,如果没有写者持有,那就可以支持多个读者直接获取;而如果此时写者持有了锁,读者获取失败,它将把自己添加到等待列表中,(这个等待列表中可能已经存放了其他来获取锁的读者或者写者),在将读者真正睡眠等待前,还会再一次判断此时是否有写者释放了该锁,释放了的话,那就需要对睡眠等待在该锁的任务进行唤醒操作了
3.1.2 读者释放锁
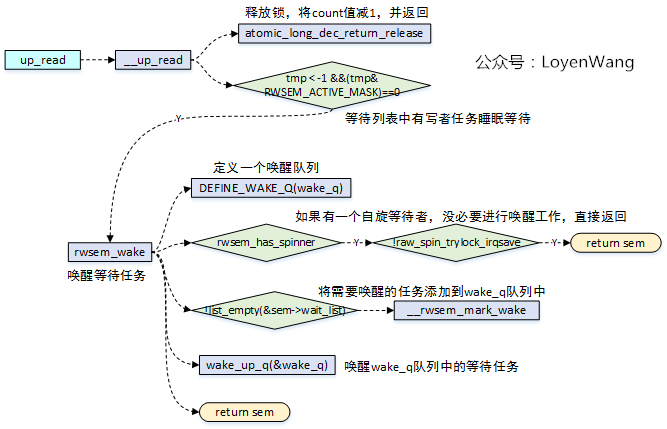
- 释放锁的时候
sem->count值进行减1操作; - 减1操作之后得到的
count值小于-1,并且active part是全零,代表等待列表中有写任务在睡眠等待,因此需要进行唤醒操作; - 唤醒操作中,如果有自旋等待的任务,那就可以直接返回了,毕竟人家在自旋呢,又没有睡眠;
- 没有自旋等待任务,那就去唤醒等待列表中的任务了;
3.2 写信号量
3.2.1 写者获取锁
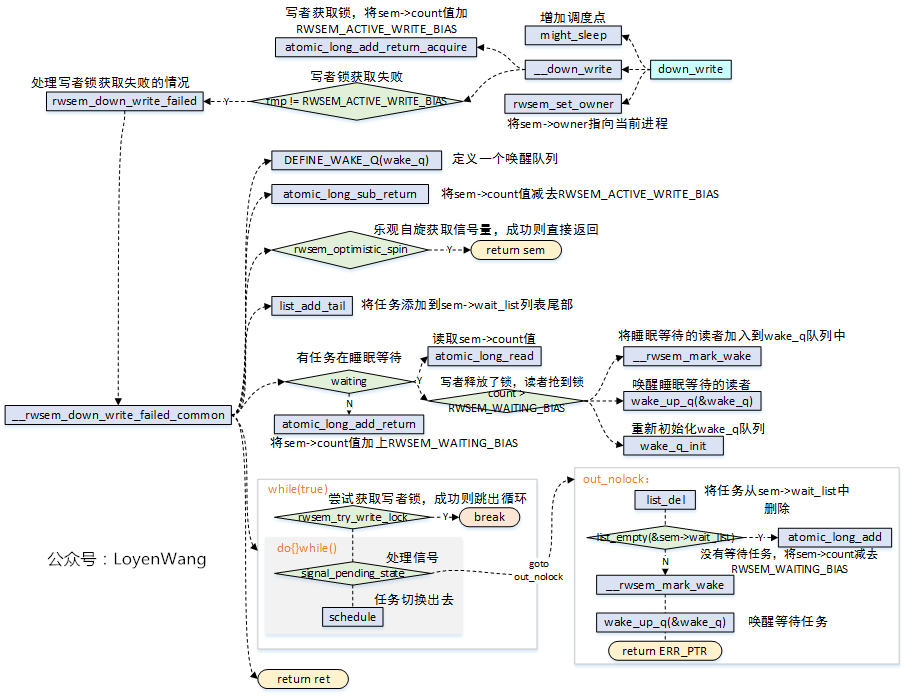
- 写者的特点:看谁都不顺眼,跟谁都互斥,有我没你。只要有一个写者在持有锁,其他的读者与写者都无法获取;
- 在写者获取锁的时候,将
sem->count值加上RWSEM_ACTIVE_WRITE_BIAS,如果这个值不等于RWSEM_ACTIVE_WRITE_BIAS,表示有其他的读者或写者持有锁,因此获取锁失败,调用rwsem_down_write_failed来处理; - 调用
rwsem_optimistic_spin进行乐观自旋去尝试获取锁,获取了的话,则直接返回,optimistic spin可以参考《Linux Mutex机制分析》文章中的分析,它的作用也是性能的优化,认为锁的持有者会很快释放,因此当前进程选择自旋而不是让出CPU,减少上下文切换带来的开销; - 如果等待列表中有读者任务在睡眠等待,此时假如写者释放了锁,那么需要先将读者任务都给唤醒了;如果等待列表中没有任务,也就意味着当前的写者是第一个任务,因此将
sem->count值加上RWSEM_WAITING_BIAS; - 循环等待获取锁,这个过程与
down_read是类似的;
总结
写者获取锁时,只要锁被其他读者或者写者持有了,则获取锁失败,然后进行失败情况处理。在失败情况下,它本身会尝试进行optimistic spin去尝试获取锁,如果获取成功了,那就是皆大欢喜了,否则还是需要进入慢速路径。慢速路径中去判断等待列表中是否有任务在睡眠等待,并且会再次尝试去查看是否已经有写者释放了锁,写者释放了锁,并且只有读者在睡眠等待,那么此时应该优先让这些先等待的任务唤醒
3.2.2 写者释放锁

- 写者释放锁的时候,有一个关键的操作,将
sem->owner进行清零操作,在写者获取锁的时候会将该值设置成持有锁的进程; - 释放锁的时候,需要减去
RWSEM_ACTIVE_WRITE_BIAS,然后再去判断值,如果此时还有任务在睡眠等待,那就进行唤醒操作;
3.3 总结
理解读写信号量有几个关键点:
- 读写信号量的特性可以与读写自旋锁进行类比(读者与读者并发、读者与写者互斥、写者与写者互斥),区别在于读写信号量可能会发生睡眠,进而带来进程切换的开销;
- 为了优化读写信号量的性能,引入了
MCS锁机制,进一步减少切换开销。第一个写者获取了锁后,第二个写者去获取时自旋等待,而读者去获取时则会进入睡眠; - 读写信号量的
count值很关键,代表着读写信号量不同状态的切换,因此也决定了执行流程; - 读者或写者释放锁的时候,去唤醒等待列表中的任务,需要分情况处理。等待列表中可能存放的是读者与写者的组合,如果第一个任务是写者,则直接唤醒该写者,否则将唤醒排在前边的连续几个读者;
参考
欢迎关注公众号,不定期分享内核机制文章

【原创】Linux信号量机制分析的更多相关文章
- 【原创】Linux Mutex机制分析
背景 Read the fucking source code! --By 鲁迅 A picture is worth a thousand words. --By 高尔基 说明: Kernel版本: ...
- 【转】Linux Writeback机制分析
1. bdi是什么? bdi,即是backing device info的缩写,顾名思义它描述备用存储设备相关描述信息,这在内核代码里用一个结构体backing_dev_info来表示. bdi,备用 ...
- linux dpm机制分析(上)【转】
转自:http://blog.csdn.net/lixiaojie1012/article/details/23707681 1 DPM介绍 1.1 Dpm: 设备电源管理, ...
- linux dpm机制分析(下)【转】
转自:http://blog.csdn.net/lixiaojie1012/article/details/23707901 1 设备注册到dpm_list路径 (Platform_devi ...
- Linux高级调试与优化——信号量机制与应用程序崩溃
背景介绍 Linux分为内核态和用户态,用户态通过系统调用(syscall)进入内核态执行. 用户空间的glibc库将Linux内核系统调用封装成GNU C Library库文件(兼容ANSI &am ...
- Linux内核态抢占机制分析(转)
Linux内核态抢占机制分析 http://blog.sina.com.cn/s/blog_502c8cc401012pxj.html 摘 要]本文首先介绍非抢占式内核(Non-Preemptive ...
- linux内核剖析(六)Linux系统调用详解(实现机制分析)
本文介绍了系统调用的一些实现细节.首先分析了系统调用的意义,它们与库函数和应用程序接口(API)有怎样的关系.然后,我们考察了Linux内核如何实现系统调用,以及执行系统调用的连锁反应:陷入内核,传递 ...
- Linux内核抢占实现机制分析【转】
Linux内核抢占实现机制分析 转自:http://blog.chinaunix.net/uid-24227137-id-3050754.html [摘要]本文详解了Linux内核抢占实现机制.首先介 ...
- Linux mips64r2 PCI中断路由机制分析
Linux mips64r2 PCI中断路由机制分析 本文主要分析mips64r2 PCI设备中断路由原理和irq号分配实现方法,并尝试回答如下问题: PCI设备驱动中断注册(request_irq) ...
随机推荐
- Java中基础类基础方法(学生类)(手机类)
学生类: //这是我的学生类class Student { //定义变量 //姓名 String name; //null //年龄 int age; //0 //地址 String address; ...
- Redis分布式锁的正确姿势
1. 核心代码: import redis.clients.jedis.Jedis; import java.util.Collections; /** * @Author: qijigui * @C ...
- pytorch中tensor的属性 类型转换 形状变换 转置 最大值
import torch import numpy as np a = torch.tensor([[[1]]]) #只有一个数据的时候,获取其数值 print(a.item()) #tensor转化 ...
- 在Thinkphp中微信公众号JsApi支付
由于网站使用的微信Native扫码支付,现在公众号需要接入功能,怎么办呢,看这官方文档,参考着demo进行写吧.直接进入正题 进入公众号(服务号)设置--->功能设置--->网页授权域名配 ...
- c++使用cin、cout与c中使用scanf、printf进行输入输出的效率问题
在c++中,我们使用cin和cout进行输入输出会比用scanf和printf更加简洁和方便,但是当程序有大量IO的时候,使用cin和cout进行输入输出会比用scanf和printf更加耗时, 在数 ...
- android位运算简单讲解
一.前言 在查看源码中,经常会看到很多这样的符号“&”.“|”.“-”,咋一看挺高大上:仔细一看,有点懵:再看看,其实就是大学学过的再普通不过的与.或.非.今天小盆友就以简单的形式分享下,同时 ...
- CG-CTF(6)
CG-CTF https://cgctf.nuptsast.com/challenges#Web 续上~ 第三十一题:综合题2 查看本CMS说明: 分析: ①数据库表名为admin:字段名为usern ...
- CentOS+Subversion 配置Linux 下 SVN服务器
1.安装#yum install subversion测试安装是否成功:#svnserve –version 回车显示版本说明安装成功 2.配置 ·建立版本库 #mkdir /opt/svnd ...
- db2 锁表
2019独角兽企业重金招聘Python工程师标准>>> 查询锁表情况 db2 => get snapshot for locks on databasename 可以看到什么表 ...
- Soldiers Sortie
这部2006年上映的作品豆瓣评分9.3,时至今日仍然有人乐此不疲地讨论剧情和启发,我想称之为经典应该不算过分. 这部剧我至少完整看过3遍,随着阅历增加,对某些角色的体会也变得更深刻. 许三多 许三多是 ...