python_12(并发编程)
第1章 进程
1.1 队列Queue
1.2 Queue方法
1.2.1 q.get([block [,timeout]])
1.2.2 q.get_nowait()
1.2.3 q.put(item [, block [timeout]])
1.2.4 q.size()
1.2.5 q.empty()
1.2.6 q.full()
1.2.7 q.close()
1.2.8 q.cancel_join_thread()
1.2.9 q.join_thread()
1.2.10 例:相关参数应用
1.2.11 例2)
1.2.12 生产者消费者模型
1.3 进程小结
第2章 线程
2.1 理论
2.2 使用方法
2.3 创建线程
2.4 进程和线程
2.5 效率测试
2.6 缺点
2.7 get_ident
2.8 current_thread
2.9 enumerate
2.10 terminate
2.11 守护线程
2.12 使用面向对象方法开启线
2.13 线程锁
2.14 锁的方法及种类lock
2.14.1 同步锁的引用
2.14.2 互斥锁与join的区别
2.14.3 解释说明
2.14.4 死锁与递归锁
2.14.5 小结
2.15 线程队列queue()
2.15.1 调用方法
2.15.2 规则
第3章 池
3.1 进程池
3.1.1 multiprocess.Pool模块
3.1.2 例:进程池开启socket聊天
3.2 线程池
3.2.1 线程池模块
3.2.2 线程调用方法
3.2.3 查看cpu个数的方法:
3.2.4 规定线程数量用法
3.2.5 submit
3.2.6 map
3.2.7 shutdown
3.2.8 result
3.2.9 add_done_callback
3.2.10 小结
3.2.11 总例
第4章 协程
4.1 介绍
4.2 特点
4.3 Greenlet模块
4.3.1 greenlet实现状态切换
4.4 安装gevent模块
4.4.1 安装
4.4.2 介绍
4.4.3 用法
4.5 join
4.6 gevent.spawn
4.7 Gevent之同步与异步
4.8 Gevent之应用举例一(爬虫)
第5章 IO模型
5.1 介绍
5.2 阻塞IO模型
5.3 非阻塞IO
5.4 多路复用
5.5 selectors模块
5.6 selectors模块实现聊天
第1章 进程
1.1 队列Queue
创建共享的进程队列,Queue是多进程安全的队列,可以使用Queue实现多进程之间的数据传递。
Queue([maxsize])
创建共享的进程队列
参数:maxsize是队列中允许的最大项数,如果省略此参数,则无大小限制。底层队列使用管道和锁定实现。
1.2 Queue方法
1.2.1 q.get([block [,timeout]])
解释:返回q中的一个项目,q为空将阻塞,直到队列中有项目,
block用于控制阻塞行为,默认为true,如为false将引发queue.empty异常
timeout是可选超时时间,阻塞中如果没有西南股变为可用,引发Queue.Empty异常
1.2.2 q.get_nowait()
等同于q.get(False)
1.2.3 q.put(item [, block [timeout]])
解释:将item放入队列,如果队列已满,此方法将阻塞至有空间可用为止,block控制阻塞行为, 默认为True.如block为False,将引发Queue.Empty异常
timeout指定在阻塞模式中等待可用空间的时间长短,超时引发Queue.Full异常
1.2.4 q.size()
解释:返回队列中目前项目的正确数量,结果不可靠,因在返回结果过程中可能队列又增加了项目,在某些系统上可能引发NOT ImplementedError异常
1.2.5 q.empty()
如果调用方法时 q为空,返回True. 如果其他进程或者线程正在往队列中添加项目,结果是不可靠的。
1.2.6 q.full()
如果q已满,返回为True,由于线程的存在,结果也可能是不可靠的
1.2.7 q.close()
关闭队列,防止队列加入更多数据,调用此方法时,后台线程将继续写入那些已入队列但尚未写入的数据,但将在此方法完成时马上关闭,如果q被垃圾收集,将自动调用此方法。关闭队列不会在队列使用者中生成任何类型的数据结束信号或异常。例如,如果某个使用者正被阻塞在get()操作上,关闭生产者中的队列不会导致get()方法返回错误。
1.2.8 q.cancel_join_thread()
不会再进程退出时自动连接后台线程。这可以防止join_thread()方法阻塞。
1.2.9 q.join_thread()
连接队列的后台线程。此方法用于在调用q.close()方法后,等待所有队列项被消耗。默认情况下,此方法由不是q的原始创建者的所有进程调用。调用q.cancel_join_thread()方法可以禁止这种行为。
1.2.10 例:相关参数应用
import time
from multiprocessing import Process ,Queue
def f(q):
q.put([time.asctime(),'from Eva','hello'])
#调用主函数中p进程传递过来的参数 put函数为向队列中添加的一条数据
if __name__ == '__main__':
q = Queue()#创建一个队列对象
p = Process(target=f,args=(q,))#创建一个进程
p.start()
print(q.get())
p.join()
输出
C:\python3\python3.exe D:/python/untitled2/Course_selection_system/conf/lession.py
['Mon Aug 6 17:03:02 2018', 'from Eva', 'hello']
上面是一个queue的简单应用,使用队列q对象调用get函数来取得队列中最先进入的数据。 接下来看一个稍微复杂一些的例子:
1.2.11 例2)
批量生产数据放入队列再批量获取结果
import os
import time
import multiprocessing
# 向queue中输入数据的函数
def inputQ(queue):
info = str(os.getpid()) + '(put):' + str(time.asctime())
queue.put(info)
# 向queue中输出数据的函数
def outputQ(queue):
info = queue.get()
print ('%s%s\033[32m%s\033[0m'%(str(os.getpid()), '(get):',info))
# Main
if __name__ == '__main__':
multiprocessing.freeze_support()
record1 = [] # store input processes
record2 = [] # store output processes
queue = multiprocessing.Queue(3)
# 输入进程
for i in range(10):
process = multiprocessing.Process(target=inputQ,args=(queue,))
process.start()
record1.append(process)
# 输出进程
for i in range(10):
process = multiprocessing.Process(target=outputQ,args=(queue,))
process.start()
record2.append(process)
for p in record1:
p.join()
for p in record2:
p.join()
输出:
C:\python3\python3.exe D:/python/untitled2/Course_selection_system/conf/lession.py
5996(get):5740(put):Mon Aug 6 18:05:07 2018
4516(get):8144(put):Mon Aug 6 18:05:07 2018
6112(get):5064(put):Mon Aug 6 18:05:07 2018
5408(get):4340(put):Mon Aug 6 18:05:07 2018
5240(get):2768(put):Mon Aug 6 18:05:07 2018
2904(get):7720(put):Mon Aug 6 18:05:08 2018
7032(get):7316(put):Mon Aug 6 18:05:08 2018
6900(get):8032(put):Mon Aug 6 18:05:08 2018
4360(get):8036(put):Mon Aug 6 18:05:08 2018
2320(get):6360(put):Mon Aug 6 18:05:08 2018
Process finished with exit code 0
1.2.12 生产者消费者模型
生产者数据与消费者数据存在一种供需关系,当供大于需或需大于供,都会导致以防阻塞等待,解决这样的情况,应用了阻塞队列,就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
实例:
from multiprocessing import Process,Queue
import time,random,os
def consumer(q):
while True:
res=q.get()
time.sleep(random.randint(1,3))
print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res))
def producer(q):
for i in range(10):
time.sleep(random.randint(1,3))
res='包子%s' %i
q.put(res)
print('\033[44m%s 生产了 %s\033[0m' %(os.getpid(),res))
if __name__ == '__main__':
q=Queue()
#生产者
p1=Process(target=producer,args=(q,))
#消费
c1=Process(target=consumer,args=(q,))
p1.start()
c1.start()
print('主')
输出
C:\python3\python3.exe D:/python/untitled2/Course_selection_system/conf/lession.py
主
8080 生产了 包子0
8080 生产了 包子1
8080 生产了 包子2
8592 吃 包子0
8592 吃 包子1
8592 吃 包子2
8080 生产了 包子3
8080 生产了 包子4
8592 吃 包子3
8592 吃 包子4
8080 生产了 包子5
8592 吃 包子5
8080 生产了 包子6
8592 吃 包子6
8080 生产了 包子7
8080 生产了 包子8
8592 吃 包子7
8080 生产了 包子9
8592 吃 包子8
8592 吃 包子9
爬虫
1.3 进程小结
注意事项:
n 多进程不适合做读写,多io型,因为多进程是用来解决计算用的
n 进程的开销是比较大的,多进程能够充分利用多核
特点:
l 进程开启的数量是有限的
密切的和CPU的个数相关,进程数 应该在cpu的1-2倍之间
l 进程的开启和销毁都需要比较大的时间开销
l 进程越多操作系统调度起来就消耗的资源多
l 实际上多进程主要就是 利用多个cpu,且同一时间最多只能执行和CPU相等的进程
CPU只能用来做计算,
高计算性的程序适用多进程
但高IO型的层序不适合多进程
第2章 线程
2.1 理论
l 进程源于多道程序出现
数据隔离
资源分配
进程是计算机中资源分配的最小单位
l 线程属于进程
是用来执行程序的
线程是计算机中cpu调度最小的单位
l 线程作用:
为了节省操作系统的资源
在实现并发的时候能减少时间开销
l 线程图示
2.2 使用方法
创建方式选择
l thread (底层)
l threading(推荐更高级)
2.3 创建线程
from threading import Thread
import time
def kk(name):
time.sleep(2)
print('%s say hello' %name)
if __name__ == '__main__':
t=Thread(target=kk,args=('huhu',))
t.start()
# t.join()
print('主线程')
输出:
C:\python3\python3.exe D:/python/untitled2/lianxi/10.py
huhu say hello
主线程
开启多线程也可以支持并发
import os
import time
from threading import Thread
def func(i):
time.sleep(1)
print(i,os.getpid())
print('main',os.getpid())
for i in range(10):
t = Thread(target=func,args=(i,))
t.start()
输出
main 6220
0 6220
1 6220
5 6220
2 6220
6 6220
9 6220
3 6220
4 6220
8 6220
7 6220
Process finished with exit code 0
2.4 进程和线程
l 进程和线程都实现了并发
l python阶段 进程和线程之间的区别
l 进程pid,多进程的时候每个子进程有自己的pid
l 多个线程共享一个进程id
l 数据隔离和共享,多进程之间数据隔离
l 线程之间全局变量都是共享的
l main:进程必须写if __name == '__main__'
l 线程由于共享进程的代码,不需要再执行文件中的代码
l 效率差:
线程的开启和销毁耗时远小于进程
import os
import time
from threading import Thread
n = 10
def func(i):
global n
n -= 1
time.sleep(1)
print(i,os.getpid())
print('main',os.getpid())
t_lst = []
for i in range(10):
t = Thread(target=func,args=(i,))
t.start()
print(t)
t_lst.append(t)
for t in t_lst:t.join()
print(n)
输出
C:\python3\python3.exe D:/python/untitled2/lianxi/10.py
main 6344
<Thread(Thread-1, started 7796)>
0 6344
<Thread(Thread-2, started 6704)>
1 6344
<Thread(Thread-3, started 7000)>
2 6344
<Thread(Thread-4, started 1508)>
3 6344
<Thread(Thread-5, started 7880)>
4 6344
<Thread(Thread-6, started 8068)>
5 6344
<Thread(Thread-7, started 4240)>
6 6344
<Thread(Thread-8, started 6292)>
7 6344
<Thread(Thread-9, started 3920)>
8 6344
<Thread(Thread-10, started 6664)>
9 6344
0
例:每个线程加join
import os
import time
from threading import Thread
n = 10
def func(i):
global n
n -= 1
time.sleep(1)
print(i,os.getpid())
print('main',os.getpid())
t_lst = []
for i in range(10):
t = Thread(target=func,args=(i,))
t.start()
print(t)
t_lst.append(t)
for t in t_lst:t.join()
print(n)
输出
C:\python3\python3.exe D:/python/untitled2/lianxi/10.py
main 6564
0 6564
1 6564
2 6564
3 6564
4 6564
5 6564
6 6564
7 6564
8 6564
2.5 效率测试
例:
from threading import Thread
from multiprocessing import Process
import time
import os
n = 10
def func(i):
# time.sleep(1)
global n
n -= 1
if __name__ == '__main__':
start = time.time()
t_lst = []
for i in range(100):
t = Thread(target=func,args=(i,))
t.start()
t_lst.append(t)
for t in t_lst:t.join()
print('线程',time.time()- start)
start = time.time()
p_lst = []
for i in range(100):
p = Process(target=func,args=(i,))
p.start()
p_lst.append(p)
for p in p_lst:p.join()
print('进程: ' ,time.time() - start)
输出:
C:\python3\python3.exe D:/python/untitled2/lianxi/10.py
线程 0.01700115203857422
进程: 5.134293556213379
2.6 缺点
GIL锁的是线程
cpython解释器的CIL:导致python不能有效利用多核
jpython pypy解释能够充分利用多核
即实现并发又实现多核的方法
多进程 + 多线程
2.7 get_ident
解释:查看线程id
from threading import Thread
from threading import get_ident
def func(arg1,arg2):
print(arg1,arg2,get_ident())
print(get_ident())
t = Thread(target=func,args=(1,2))
t.start()
输出
C:\python3\python3.exe D:/python/untitled2/lianxi/10.py
主进程ID号 6564
线程ID号: 1 2 7344
2.8 current_thread
解释:查看线程pid
from threading import Thread
from threading import get_ident,current_thread
def func(arg1,arg2):
print('线程ID号: ',arg1,arg2,get_ident(),current_thread().name)
print('主进程ID号',get_ident(),current_thread().ident)
t = Thread(target=func,args=(1,2))
t.start()
输出
C:\python3\python3.exe D:/python/untitled2/lianxi/10.py
主进程ID号 7184 7184
线程ID号: 1 2 7724 Thread-1
2.9 enumerate
解释:返回一个包含正在运行的线程list,正在运行指线程后台运行,结束前,不包含启动前和终止后
import time
from threading import Thread
from threading import get_ident,current_thread,enumerate
def func(arg1,arg2):
print('线程ID号: ',arg1,arg2,get_ident(),current_thread().name)
time.sleep(2)
for i in range(10):
t = Thread(target=func,args=(1,2))
t.start()
print(len(enumerate()))
输出:
C:\python3\python3.exe D:/python/untitled2/lianxi/10.py
线程ID号: 1 2 6416 Thread-1
线程ID号: 1 2 8052 Thread-2
线程ID号: 1 2 1688 Thread-3
线程ID号: 1 2 6920 Thread-4
线程ID号: 1 2 3548 Thread-5
线程ID号: 1 2 3560 Thread-6
线程ID号: 1 2 7720 Thread-7
线程ID号: 1 2 2020 Thread-8
线程ID号: 1 2 7680 Thread-9
线程ID号: 1 2 4048 Thread-10
2.10 terminate???
解释:不能被强制终止
2.11 守护线程
l 守护进程会随着主进程的代码结束而结束
l 守护线程会随着主线程的结束而结束
而主线程也会等待子线程结束才结束,所以守护线程会等待包括子线程之内的所有线程都结束之后才结束
例
import time
from threading import Thread
def func1():
print('start func1')
time.sleep(0.5)
print('in func1' )
def func2():
print('start func2')
time.sleep(5)
print('end func2')
t = Thread(target=func1)
t.start()
t2 = Thread(target=func2)
t2.start()
输出:
C:\python3\python3.exe D:/python/untitled2/lianxi/10.py
start func1
start func2
in func1
end func2
守护线程后
import time
from threading import Thread
def func1():
print('start func1')
time.sleep(0.5)
print('in func1' )
def func2():
print('start func2')
time.sleep(5)
print('end func2')
t = Thread(target=func1)
t.start()
t2 = Thread(target=func2)
t2.daemon = True
t2.start()
输出
C:\python3\python3.exe D:/python/untitled2/lianxi/10.py
start func1
start func2
in func1
例2)
from threading import Thread
import time
def sayhi(name):
time.sleep(2)
print('%s say hello' %name)
if __name__ == '__main__':
t=Thread(target=sayhi,args=('egon',))
t.setDaemon(True) #必须在t.start()之前设置
t.start()
print('主线程')
print(t.is_alive())
输出
C:\python3\python3.exe D:/python/untitled2/lianxi/10.py
主线程
True
2.12 使用面向对象方法开启线程
例
import time
from threading import Thread
class MyThread(Thread):
def __init__(self,arg,arg2):
super().__init__()
self.arg = arg
self.arg2 = arg2
def run(self):
print('start func2',self.arg)
time.sleep(5)
print('end func2',self.arg2)
mt = MyThread('a','b')
mt.start()
2.13 线程锁
n 数据不安全
多个线程、进程同时操作一个数据
保证数据安全-------基于文件形式
线程中调用缓存的数据没有被及时释放或者数据被其他线程更改后调用时数据发生变化
GIL锁机制锁的是线程,没有锁住内存中的数据所以数据不安全和GIL没关系
n 避免数据不安全
就要对全局变量的修改必须要枷锁
并不能影响效率
不是必须共享的数据不要设置为全局变量
2.14 锁的方法及种类lock
调用方法:(互斥锁)
from threading import Lock
2.14.1 同步锁的引用
from threading import Thread,Lock
import os,time
def work():
global n
lock.acquire()
temp=n
time.sleep(0.1)
n=temp-1
lock.release()
if __name__ == '__main__':
lock=Lock()
n=100
l=[]
for i in range(100):
p=Thread(target=work)
l.append(p)
p.start()
for p in l:
p.join()
print(n) #结果肯定为0,由原来的并发执行变成串行,牺牲了执行效率保证了数据安全
2.14.2 互斥锁与join的区别
例1:不加锁:并发执行,速度快,数据不安全
from threading import current_thread,Thread,Lock
import os,time
def task():
global n
print('%s is running' %current_thread().getName())
temp=n
time.sleep(0.5)
n=temp-1
# n=5
# task()
if __name__ == '__main__':
n=100
lock=Lock()
threads=[]
start_time=time.time()
for i in range(100):
t=Thread(target=task)
threads.append(t)
t.start()
for t in threads:
t.join()
stop_time=time.time()
print('主:%s n:%s' %(stop_time - start_time,n))
输出
Thread-95 is running
Thread-96 is running
Thread-97 is running
Thread-98 is running
Thread-99 is running
Thread-100 is running
主:0.5180294513702393 n:99
例2:不加锁:未加锁部分并发执行,加锁部分串行执行,速度慢,数据安全
from threading import current_thread,Thread,Lock
import os,time
def task():
#未加锁的代码并发运行
time.sleep(3)
print('%s start to run' %current_thread().getName())
global n
#加锁的代码串行运行
lock.acquire()
temp=n
time.sleep(0.5)
n=temp-1
lock.release()
if __name__ == '__main__':
n=100
lock=Lock()
threads=[]
start_time=time.time()
for i in range(100):
t=Thread(target=task)
threads.append(t)
t.start()
for t in threads:
t.join()
stop_time=time.time()
print('主:%s n:%s' %(stop_time-start_time,n))
输出
'''
Thread-1 is running
Thread-2 is running
......
Thread-100 is running
主:53.294203758239746 n:0
例3:用jion不加锁
from threading import current_thread,Thread,Lock
import os,time
def task():
time.sleep(3)
print('%s start to run' %current_thread().getName())
global n
temp=n
time.sleep(0.5)
n=temp-1
if __name__ == '__main__':
n=100
lock=Lock()
start_time=time.time()
for i in range(100):
t=Thread(target=task)
t.start()
t.join()
stop_time=time.time()
print('主:%s n:%s' %(stop_time-start_time,n))
'''
Thread-1 start to run
Thread-2 start to run
......
Thread-100 start to run
主:350.6937336921692 n:0 #耗时是多么的恐怖
'''
2.14.3 解释说明
既然加锁会让运行变成串行,那么我在start之后立即使用join,就不用加锁了啊,也是串行的效果啊
#没错:在start之后立刻使用jion,肯定会将100个任务的执行变成串行,毫无疑问,最终n的结果也肯定是0,是安全的,但问题是
#start后立即join:任务内的所有代码都是串行执行的,而加锁,只是加锁的部分即修改共享数据的部分是串行的
#单从保证数据安全方面,二者都可以实现,但很明显是加锁的效率更高
2.14.4 死锁与递归锁
解释说明:
所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程,如下就是死锁
递归锁特点:
如果能在第一个acquire的地方通过,那么在一个线程中后面所有acquire都能通过
但是其他所有的线程都会在第一个acquire处阻塞
在这个线程中acquire了多少次,就必须release多少次
如果acquire的次数和release的次数不相等,那么其他线程也不能继续向下执行
解决方法:
递归锁,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。下面的例子如果使用RLock代替Lock,则不会发生死锁:
例:lock
from threading import Lock as Lock
import time
mutexA=Lock()
mutexA.acquire()
mutexA.acquire()
print(123)
mutexA.release()
mutexA.release()
例:Rlock
from threading import RLock as Lock
import time
mutexA=Lock()
mutexA.acquire()
mutexA.acquire()
print(123)
mutexA.release()
mutexA.release()
例1)科学家吃面
#科学家吃面
import time
from threading import Thread,Lock
noodle_lock = Lock()
fork_lock = Lock()
def eat1(name):
noodle_lock.acquire()
print('%s 抢到了面条' %name)
fork_lock.acquire()
print('%s 抢到了叉子' %name)
print('%s 吃面' %name )
fork_lock.release()
noodle_lock.release()
def eat2(name):
fork_lock.acquire()
print('%s 抢到了叉子' %name)
time.sleep(1)
noodle_lock.acquire()
print('%s 抢到了面条' %name)
print('%s 吃面' %name)
noodle_lock.release()
fork_lock.release()
for name in ['a','b','c']:
t1 = Thread(target=eat1,args=(name,))
t2 = Thread(target=eat2,args=(name,))
t1.start()
t2.start()
输出:
C:\python3\python3.exe D:/python/untitled2/lianxi/11.py
a 抢到了面条
a 抢到了叉子
a 吃面
a 抢到了叉子
b 抢到了面条
例2):解决僵死情况办法
import time
from threading import Thread,RLock
# noodle_lock = Lock()
fork_lock = noodle_lock = RLock()
def eat1(name):
noodle_lock.acquire()
print('%s 抢到了面条' %name)
fork_lock.acquire()
print('%s 抢到了叉子' %name)
print('%s 吃面' %name )
fork_lock.release()
noodle_lock.release()
def eat2(name):
fork_lock.acquire()
print('%s 抢到了叉子' %name)
time.sleep(1)
noodle_lock.acquire()
print('%s 抢到了面条' %name)
print('%s 吃面' %name)
noodle_lock.release()
fork_lock.release()
for name in ['a','b','c']:
t1 = Thread(target=eat1,args=(name,))
t2 = Thread(target=eat2,args=(name,))
t1.start()
t2.start()
输出
C:\python3\python3.exe D:/python/untitled2/lianxi/11.py
a 抢到了面条
a 抢到了叉子
a 吃面
a 抢到了叉子
a 抢到了面条
a 吃面
b 抢到了面条
b 抢到了叉子
b 吃面
b 抢到了叉子
b 抢到了面条
b 吃面
c 抢到了面条
c 抢到了叉子
c 吃面
c 抢到了叉子
c 抢到了面条
c 吃面
2.14.5 小结
递归锁可以解决资源占用情况,但仍无法根本解决可以暂时解决问题后续再改进,做好的解决方法是在开发设计过程中就避免资源占用的情况发生
2.15 线程队列queue()
在数据安全中,线程队列是自带线程锁的容器
2.15.1 调用方法
import queue
2.15.2 规则
class queue.Queue(maxsize=0)
先进先出
import queue
q=queue.Queue()
q.put('first')
q.put('second')
q.put('third')
print(q.get())
print(q.get())
print(q.get())
'''
结果(先进先出):
first
second
third
'''
class queue.LifoQueue(maxsize=0) #last in fisrt out
后进先出
import queue
q=queue.LifoQueue()
q.put('first')
q.put('second')
q.put('third')
print(q.get())
print(q.get())
print(q.get())
'''
结果(后进先出):
third
second
first
存储数据时可设置优先级的队列
class queue.PriorityQueue(maxsize=0)
作用:可应用于识别网站会员
列1)PriorityQueue
import queue
q=queue.PriorityQueue()
#put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高
q.put((20,'a'))
q.put((10,'b'))
q.put((30,'c'))
print(q.get())
print(q.get())
print(q.get())
结果(数字越小优先级越高,优先级高的优先出队):
(10, 'b')
(20, 'a')
(30, 'c')
列2)
import queue
q= queue.PriorityQueue()
q.put(('a'))
q.put(('z'))
q.put(('h'))
print(q.get())
print(q.get())
print(q.get())
结果(字母ACSII数值越靠前,优先级高的优先出队):
C:\python3\python3.exe D:/python/untitled2/lianxi/lianxi.py
a
h
z
字符串和数字混在一起报错
import queue
q= queue.PriorityQueue()
q.put(('a'))
q.put((2))
q.put((3))
print(q.get())
print(q.get())
print(q.get())
print(q.get())
报错信息
File "D:/python/untitled2/lianxi/lianxi.py", line 877, in <module>
q.put((2))
File "C:\python3\lib\queue.py", line 143, in put
self._put(item)
File "C:\python3\lib\queue.py", line 227, in _put
heappush(self.queue, item)
TypeError: '<' not supported between instances of 'int' and 'str'
第3章 池
3.1 进程池
任务多的情况下,无限开启进程/线程,浪费很多的时间开启和销毁,还要占用系统的调度资源
为了开启有限的线程及进程,来完成无线的任务,这样能够最大化的保证并发维护操作系统资源协调
3.1.1 multiprocess.Pool模块
创建进程池
Pool([numprocess [,initializer [, initargs]]])
numprocess:要创建的进程数,如果省略将默认使用cpu_count()的值
inittializer:每个工作进程启动时要执行的可调用对象,默认为None
initargs:是要传给initializer的参数组
主要方法
p.apply(func [, args [, kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果。
'''需要强调的是:此操作并不会在所有池工作进程中并执行func函数。如果要通过不同参数并发地执行func函数,必须从不同线程调用p.apply()函数或者使用p.apply_async()'''
p.apply_async(func [, args [, kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果。
'''此方法的结果是AsyncResult类的实例,callback是可调用对象,接收输入参数。当func的结果变为可用时,将理解传递给callback。callback禁止执行任何阻塞操作,否则将接收其他异步操作中的结果。'''
p.close():关闭进程池,防止进一步操作。如果所有操作持续挂起,它们将在工作进程终止前完成
P.jion():等待所有工作进程退出。此方法只能在close()或teminate()之后调用
其他方法(了解)
方法apply_async()和map_async()的返回值是AsyncResul的实例obj。实例具有以下方法
obj.get():返回结果,如果有必要则等待结果到达。timeout是可选的。如果在指定时间内还没有到达,将引发一场。如果远程操作中引发了异常,它将在调用此方法时再次被引发。
obj.ready():如果调用完成,返回True
obj.successful():如果调用完成且没有引发异常,返回True,如果在结果就绪之前调用此方法,引发异常
obj.wait([timeout]):等待结果变为可用。
obj.terminate():立即终止所有工作进程,同时不执行任何清理或结束任何挂起工作。如果p被垃圾回收,将自动调用此函数
例:异步进程池
import os
import time
import random
from multiprocessing import Pool
def work(n):
print('%s run' %os.getpid())
time.sleep(random.random())
return n**2
if __name__ == '__main__':
p=Pool(3) #进程池中从无到有创建三个进程,以后一直是这三个进程在执行任务
res_l=[]
for i in range(10):
res=p.apply_async(work,args=(i,)) # 异步运行,根据进程池中有的进程数,每次最多3个子进程在异步执行
# 返回结果之后,将结果放入列表,归还进程,之后再执行新的任务
# 需要注意的是,进程池中的三个进程不会同时开启或者同时结束
# 而是执行完一个就释放一个进程,这个进程就去接收新的任务。
res_l.append(res)
# 异步apply_async用法:如果使用异步提交的任务,主进程需要使用jion,等待进程池内任务都处理完,然后可以用get收集结果
# 否则,主进程结束,进程池可能还没来得及执行,也就跟着一起结束了
p.close()
p.join()
for res in res_l:
print(res.get()) #使用get来获取apply_aync的结果,如果是apply,则没有get方法,因为apply是同步执行,立刻获取结果,也根本无需get
进程池的异步调用
3.1.2 例:进程池开启socket聊天
from multiprocessing import Process,Queue
import time,random,os
def consumer(q):
while True:
res=q.get()
time.sleep(random.randint(1,3))
print('\033[45m%s 吃 %s\033[0m' %(os.getpid(),res))
def producer(q):
for i in range(10):
time.sleep(random.randint(1,3))
res='包子%s' %i
q.put(res)
print('\033[44m%s 生产了 %s\033[0m' %(os.getpid(),res))
if __name__ == '__main__':
q=Queue()
#生产者
p1=Process(target=producer,args=(q,))
#消费
c1=Process(target=consumer,args=(q,))
p1.start()
c1.start()
print('主')
客户端
from socket import *
client=socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8081))
while True:
msg=input('>>: ').strip()
if not msg:continue
client.send(msg.encode('utf-8'))
msg=client.recv(1024)
print(msg.decode('utf-8'))
3.2 线程池
n 使用进程池的条件:
任务数超过了CPU个数的两倍
进程的个数就不应和任务数相等
n 使用线程池的条件:
任务数超过了CPU个数的5倍
线程的个数就不应该和任务数相等
3.2.1 线程池模块
concurrent.futures模块提供了高度封装的异步调用接口
ThreadPoolExecutor:线程池,提供异步调用
ProcessPoolExecutor: 进程池,提供异步调用
3.2.2 线程调用方法
from concurrent.futures import ThreadPoolExecutor
进程池调用方法
from concurrent.futures import ProcessPoolExecutor
3.2.3 查看cpu个数的方法:
import os
print(os.cpu_count())
3.2.4 规定线程数量用法
import os
from concurrent.futures import ThreadPoolExecutor
# print(os.cpu_count())
ThreadPoolExecutor(os.cpu_count()*5)
3.2.5 submit
解释:异步提交任务
方法:submit(fn, *args, **kwargs)
3.2.6 map
方法:map(func, *iterables, timeout=None, chunksize=1)
解释:取代for循环submit的操作
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
import os,time,random
def task(n):
print('%s is runing' %os.getpid())
time.sleep(random.randint(1,3))
return n**2
if __name__ == '__main__':
executor=ThreadPoolExecutor(max_workers=3)
# for i in range(11):
# future=executor.submit(task,i)
executor.map(task,range(1,12)) #map取代了for+submit
map的用法
3.2.7 shutdown
方法:shutdown(wait=True)
解释:相当于进程池的pool.close()+pool.join()操作
l wait=True,等待池内所有任务执行完毕回收完资源后才继续
l wait=False,立即返回,并不会等待池内的任务执行完毕
l 但不管wait参数为何值,整个程序都会等到所有任务执行完毕
注:
submit和map必须在shutdown之前
例:
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
import os,time,random
def task(n):
print('%s is runing' %os.getpid())
time.sleep(random.randint(1,3))
return n**2
if __name__=='__main__':
executor=ProcessPoolExecutor(max_workers=3)
futures=[]
for i in range(11):
future=executor.submit(task,i)
futures.append(future)
executor.shutdown(True)
print('+++>')
for future in futures:
print(future.result())
输出
:\python3\python3.exe D:/python/untitled2/爬虫.py
2520 is runing
7600 is runing
8560 is runing
7600 is runing
8560 is runing
2520 is runing
7600 is runing
8560 is runing
2520 is runing
7600 is runing
8560 is runing
+++>
0
1
4
9
16
25
36
49
64
81
100
3.2.8 result
方法:result(timeout=None)
解释:取得结果,返回值
from threading import get_ident
from concurrent.futures import ThreadPoolExecutor
import os
import time
import random
def func(i):
time.sleep(random.randint(1,2))
print(get_ident(),i)
return '*'*i*i
def call_bak(ret):
print(get_ident(),len(ret.result()))
t_pool = ThreadPoolExecutor(os.cpu_count()*1)
for i in range(20):
t_pool.submit(func,i)
t_pool.shutdown() # 阻塞
获取并发返回值
ret_l = []
for i in range(20):
ret = t_pool.submit(func,i)
ret_l.append(ret)
for ret in ret_l:print(ret.result()) # 阻塞
3.2.9 add_done_callback
方法:add_done_callback(fn)
解释:回调函数,没有返回值
例
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
from multiprocessing import Pool
import requests
import json
import os
def get_page(url):
print('<进程%s> get %s' %(os.getpid(),url))
respone=requests.get(url)
if respone.status_code == 200:
return {'url':url,'text':respone.text}
def parse_page(res):
res=res.result()
print('<进程%s> parse %s' %(os.getpid(),res['url']))
parse_res='url:<%s> size:[%s]\n' %(res['url'],len(res['text']))
with open('db.txt','a') as f:
f.write(parse_res)
if __name__ == '__main__':
urls=[
'https://www.baidu.com',
'https://www.python.org',
'https://www.openstack.org',
'https://help.github.com/',
'http://www.sina.com.cn/'
]
# p=Pool(3)
# for url in urls:
# p.apply_async(get_page,args=(url,),callback=pasrse_page)
# p.close()
# p.join()
p=ProcessPoolExecutor(3)
for url in urls:
p.submit(get_page,url).add_done_callback(parse_page) #parse_page拿到的是一个future对象obj,需要用obj.result()拿到结果
3.2.10 小结
1)cpython解释器下
进程:利用多核一并行,数据不共享;开启和切换和销毁的开销大,数据不安全
线程:不能利用多核-并发,数据共享;开启和切换和销毁的开销小,数据不安全
进程的数量非常有限:cpu的个数 +1
线程的数量也要限制:cpu的个数*5
以上操作都由池来完成
2)4核计算机
5个进程
* 每个进程20个线程 =100 个并发
多进程能够利用多核:搞计算性应该开多进程
多线程能够实现并发:高IO型应该开多线
最后的选择还是要看测试环境的测试速度
3.2.11 总例
import os
import time
from concurrent.futures import ProcessPoolExecutor
def func(i):
time.sleep(1)
print(i,os.getpid())
return '*'*i
def wahaha(ret):
print(os.getpid(),ret.result())
if __name__ == '__main__':
#有两个任务需要同步执行需要回调函数
p = ProcessPoolExecutor(5)
# for i in
range(20):
#异步执行任务按每五个任务为一组执行
# p.submit(func,i)
#join整个任务列表:等待所有工作进程退出
# p.shutdown()
#相当于submit+for
# p.map(func,range(10))
# print('main process')
#获取结果
# ret_l = []
# for i in range(1,20):
# #异步执行任务
# ret = p.submit(func,i)
# ret_l.append(ret)
#
# for i in ret_l:
# print(i.result)
#回调函数-是由主进程执行的
for i in range(1,20):
# 两个任务要同步执行 需要用到回调函数
ret =
p.submit(func,i).add_done_callback(wahaha)
第4章 协程
4.1 介绍
协程:是单线程下的并发,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
l
一条线程分成几个任务执行
l
每个任务执行一会
l
再切到下一个任务
l
单纯的切换会浪费时间
l
切换任务是由程序来完成而不是有操作系统控制的
4.2 特点
总结协程特点:
l
必须在只有一个单线程里实现并发
l
修改共享数据不需加锁
l
用户程序里自己保存多个控制流的上下文栈
l
附加:一个协程遇到IO操作自动切换到其它协程(如何实现检测IO,yield、greenlet都无法实现,就用到了gevent模块(select机制))
优点如下:
#1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级
#2. 单线程内就可以实现并发的效果,最大限度地利用cpu
缺点如下:
#1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程
#2. 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
一:其中第二种情况并不能提升效率,只是为了让cpu能够雨露均沾,实现看起来所有任务都被“同时”执行的效果,如果多个任务都是纯计算的,这种切换反而会降低效率。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import time
def consumer(res):
'''
任务1:接收数据,处理数据
:param res:
:return:
'''
pass
def producer():
'''
任务2:生产数据
:return:
'''
res = []
for i in range(10000000):
res.append(i)
return res
start=time.time()
# res=producer()
#串行执行
res=producer()
consumer(res)
# consumer(producer())会降低执行效率
stop=time.time()
print(stop-start)
二:第一种情况的切换。在任务一遇到io情况下,切到任务二去执行,这样就可以利用任务一阻塞的时间完成任务二的计算,效率的提升就在于此。
import time
def consumer():
'''任务1:接收数据,处理数据'''
while True:
x=yield
def producer():
'''任务2:生产数据'''
g=consumer()
next(g)
for i in range(10000000):
g.send(i)
time.sleep(2)
start=time.time()
producer() #并发执行,但是任务producer遇到io就会阻塞住,并不会切到该线程内的其他任务去执行
stop=time.time()
print(stop-start)
yield无法做到遇到io阻塞
协程的本质就是在单线程下,由用户自己控制一个任务遇到io阻塞了就切换另外一个任务去执行,以此来提升效率。为了实现它,我们需要找寻一种可以同时满足以下条件的解决方案:
#1. 可以控制多个任务之间的切换,切换之前将任务的状态保存下来,以便重新运行时,可以基于暂停的位置继续执行。
#2. 作为1的补充:可以检测io操作,在遇到io操作的情况下才发生切换
4.3 Greenlet模块
pip3 install greenlet
4.3.1 greenlet实现状态切换
from greenlet import greenlet
def eat(name):
print('%s eat 1' %name)
g2.switch('egon')
print('%s eat 2' %name)
g2.switch()
def play(name):
print('%s play 1' %name)
g1.switch()
print('%s play 2' %name)
g1=greenlet(eat)
g2=greenlet(play)
g1.switch('egon')#可以在第一次switch时传入参数,以后都不需要
单纯的切换(在没有io的情况下或者没有重复开辟内存空间的操作),反而会降低程序的执行速度
#顺序执行
import time
def f1():
res=1
for i in
range(100000000):
res+=i
def f2():
res=1
for i in
range(100000000):
res*=i
start=time.time()
f1()
f2()
stop=time.time()
print('run time is %s' %(stop-start)) #10.985628366470337
#切换
from greenlet import greenlet
import time
def f1():
res=1
for i in
range(10000000):
res+=i
g2.switch()
def f2():
res=1
for i in
range(10000000):
res*=i
g1.switch()
start=time.time()
g1=greenlet(f1)
g2=greenlet(f2)
g1.switch()
stop=time.time()
print('run time is %s'
%(stop-start))
对比结果
C:\python3\python3.exe D:/python/untitled/123.py
run time is 13.106749773025513
run time is 7.793445825576782
greenlet只是提供了一种比generator更加便捷的切换方式,当切到一个任务执行时如果遇到io,那就原地阻塞,仍然是没有解决遇到IO自动切换来提升效率的问题
4.4 安装gevent模块
4.4.1 安装
pip3 install
gevent 注意python3.7还不支持gevent
4.4.2 介绍
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。
Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调
4.4.3 用法
g1=gevent.spawn(func,1,,2,3,x=4,y=5)创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的
g2=gevent.spawn(func2)
g1.join() #等待g1结束
g2.join() #等待g2结束
#或者上述两步合作一步:gevent.joinall([g1,g2])
g1.value#拿到func1的返回值
4.5 join
g1.join() #等待g1结束
g2.join() #等待g2结束
#或者上述两步合作一步:
gevent.joinall([g1,g2])
4.6 gevent.spawn
例:遇到io主动切换
import gevent
def eat(name):
print('%s eat 1' %name)
gevent.sleep(2)
print('%s eat 2' %name)
def play(name):
print('%s play 1' %name)
gevent.sleep(1)
print('%s play 2' %name)
g1=gevent.spawn(eat,'egon')
g2=gevent.spawn(play,name='egon')
g1.join()
g2.join()
#或者gevent.joinall([g1,g2])
print('主')
输出
C:\python3\python3.exe D:/python/untitled/123.py
egon eat 1
egon play 1
egon play 2
egon eat 2
主
上例gevent.sleep(2)模拟的是gevent可以识别的io阻塞,而time.sleep(2)或其他的阻塞,gevent是不能直接识别的需要用下面一行代码,打补丁,就可以识别了
from gevent import
monkey;monkey.patch_all()必须放到被打补丁者的前面,如time,socket模块之前
或者我们干脆记忆成:要用gevent,需要将from gevent import monkey;monkey.patch_all()放到文件的开头
from gevent import
monkey;monkey.patch_all()
import gevent
import time
def eat():
print('eat food 1')
time.sleep(2)
print('eat food 2')
def play():
print('play 1')
time.sleep(1)
print('play 2')
g1=gevent.spawn(eat)
g2=gevent.spawn(play)
gevent.joinall([g1,g2])
print('主')
4.7 Gevent之同步与异步
from gevent import spawn,joinall,monkey;monkey.patch_all()
import time
def task(pid):
"""
Some non-deterministic
task
"""
time.sleep(0.5)
print('Task %s done' %
pid)
def synchronous(): # 同步
for i in range(10):
task(i)
def asynchronous(): # 异步
g_l=[spawn(task,i) for i
in range(10)]
joinall(g_l)
print('DONE')
if __name__ == '__main__':
print('Synchronous:')
synchronous()
print('Asynchronous:')
asynchronous()
# 上面程序的重要部分是将task函数封装到Greenlet内部线程的gevent.spawn。
# 初始化的greenlet列表存放在数组threads中,此数组被传给gevent.joinall 函数,
# 后者阻塞当前流程,并执行所有给定的greenlet任务。执行流程只会在 所有greenlet执行完后才会继续向下走。
4.8 Gevent之应用举例一(爬虫)
from gevent import monkey;monkey.patch_all()
import gevent
import requests
import time
def get_page(url):
print('GET: %s' %url)
response=requests.get(url)
if response.status_code ==
200:
print('%d bytes
received from %s' %(len(response.text),url))
start_time=time.time()
gevent.joinall([
gevent.spawn(get_page,'https://www.python.org/'),
gevent.spawn(get_page,'https://www.yahoo.com/'),
gevent.spawn(get_page,'https://github.com/'),
])
stop_time=time.time()
print('run time is %s' %(stop_time-start_time))
第5章 IO模型
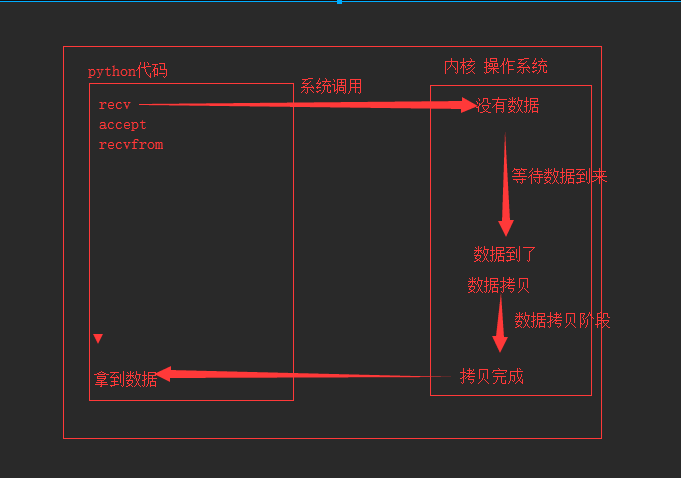
5.1 介绍
l
阻塞IO(blocking IO)
blocking IO的特点就是在IO执行的两个阶段(等待数据和拷贝数据两个阶段)都被block了
l
非阻塞IO(non-blocking IO)
在非阻塞式IO中,用户进程其实是需要不断的主动询问kernel数据准备好了没有。
l
多路复用IO(IO multiplexing)
l
异步IO(Asynchronous I/O)
对于一个network IO
(这里我们以read举例),它会涉及到两个系统对象,一个是调用这个IO的process (or
thread),另一个就是系统内核(kernel)。当一个read操作发生时,该操作会经历两个阶段
1)等待数据准备 (Waiting for the data to be ready)
2)将数据从内核拷贝到进程中(Copying the data from the kernel to the process)
5.2 阻塞IO模型
5.3 非阻塞IO
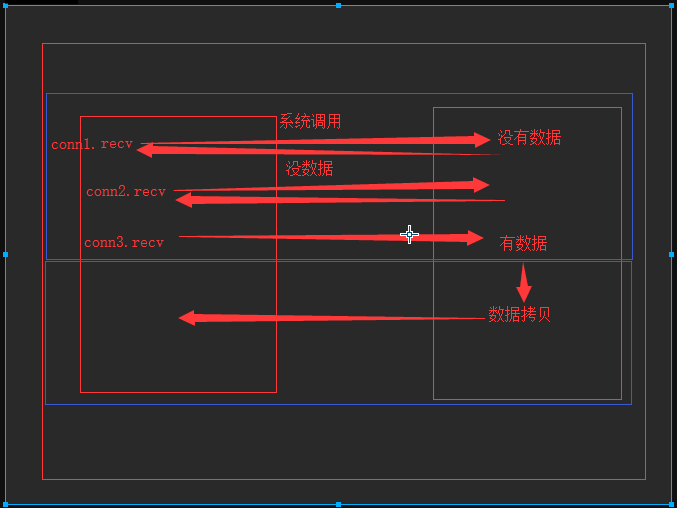
提高了cpu利用,但也增加了CPU的负载
非阻塞IO实例-服务端
from socket import *
import time
s=socket(AF_INET,SOCK_STREAM)
s.bind(('127.0.0.1',8080))
s.listen(5)
s.setblocking(False) #设置socket的接口为非阻塞
conn_l=[]
del_l=[]
while True:
try:
conn,addr=s.accept()
conn_l.append(conn)
except BlockingIOError:
print(conn_l)
for conn in conn_l:
try:
data=conn.recv(1024)
if not data:
del_l.append(conn)
continue
conn.send(data.upper())
except
BlockingIOError:
pass
except ConnectionResetError:
del_l.append(conn)
for conn in del_l:
conn_l.remove(conn)
conn.close()
del_l=[]
#客户端
from socket import *
c=socket(AF_INET,SOCK_STREAM)
c.connect(('127.0.0.1',8080))
while True:
msg=input('>>: ')
if not msg:continue
c.send(msg.encode('utf-8'))
data=c.recv(1024)
print(data.decode('utf-8'))
5.4 多路复用
操作系统提供的
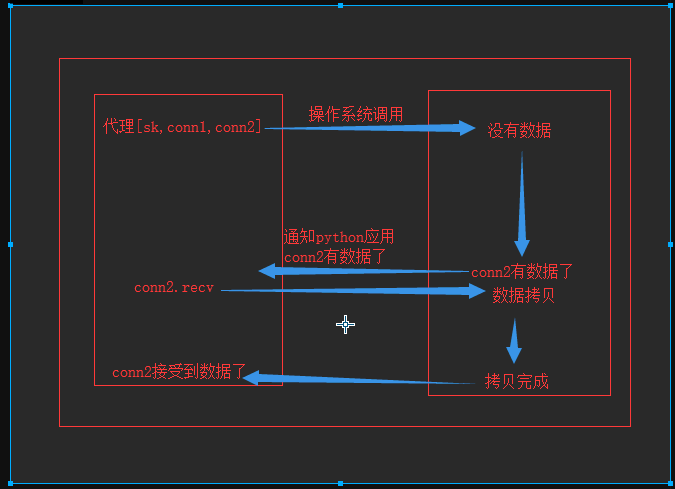
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
这个图和blocking IO的图其实并没有太大的不同,事实上还更差一些。因为这里需要使用两个系统调用(select和recvfrom),而blocking IO只调用了一个系统调用(recvfrom)。但是,用select的优势在于它可以同时处理多个connection。
强调:
1. 如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server性能更好,可能延迟还更大。select/epoll的优势并不是对于单个连接能处理得更快,而是在于能处理更多的连接。
2. 在多路复用模型中,对于每一个socket,一般都设置成为non-blocking,但是,如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。
结论: select的优势在于可以处理多个连接,不适用于单个连接
select网络IO模型-服务端
from socket import *
import select
s=socket(AF_INET,SOCK_STREAM)
s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
s.bind(('127.0.0.1',8081))
s.listen(5)
s.setblocking(False) #设置socket的接口为非阻塞
read_l=[s,]
while True:
r_l,w_l,x_l=select.select(read_l,[],[])
print(r_l)
for ready_obj in r_l:
if ready_obj == s:
conn,addr=ready_obj.accept() #此时的ready_obj等于s
read_l.append(conn)
else:
try:
data=ready_obj.recv(1024) #此时的ready_obj等于conn
if not data:
ready_obj.close()
read_l.remove(ready_obj)
continue
ready_obj.send(data.upper())
except ConnectionResetError:
ready_obj.close()
read_l.remove(ready_obj)
#客户端
from socket import *
c=socket(AF_INET,SOCK_STREAM)
c.connect(('127.0.0.1',8081))
while True:
msg=input('>>: ')
if not msg:continue
c.send(msg.encode('utf-8'))
data=c.recv(1024)
print(data.decode('utf-8'))
5.5 selectors模块
IO复用:为了解释这个名词,首先来理解下复用这个概念,复用也就是共用的意思,这样理解还是有些抽象,为此,咱们来理解下复用在通信领域的使用,在通信领域中为了充分利用网络连接的物理介质,往往在同一条网络链路上采用时分复用或频分复用的技术使其在同一链路上传输多路信号,到这里我们就基本上理解了复用的含义,即公用某个“介质”来尽可能多的做同一类(性质)的事,那IO复用的“介质”是什么呢?为此我们首先来看看服务器编程的模型,客户端发来的请求服务端会产生一个进程来对其进行服务,每当来一个客户请求就产生一个进程来服务,然而进程不可能无限制的产生,因此为了解决大量客户端访问的问题,引入了IO复用技术,即:一个进程可以同时对多个客户请求进行服务。也就是说IO复用的“介质”是进程(准确的说复用的是select和poll,因为进程也是靠调用select和poll来实现的),复用一个进程(select和poll)来对多个IO进行服务,虽然客户端发来的IO是并发的但是IO所需的读写数据多数情况下是没有准备好的,因此就可以利用一个函数(select和poll)来监听IO所需的这些数据的状态,一旦IO有数据可以进行读写了,进程就来对这样的IO进行服务。
理解完IO复用后,我们在来看下实现IO复用中的三个API(select、poll和epoll)的区别和联系
select,poll,epoll都是IO多路复用的机制,I/O多路复用就是通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知应用程序进行相应的读写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的,而异步I/O则无需自己负责进行读写,异步I/O的实现会负责把数据从内核拷贝到用户空间。三者的原型如下所示:
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set
*exceptfds, struct timeval *timeout);
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
int epoll_wait(int epfd, struct epoll_event *events, int maxevents,
int timeout);
1.select的第一个参数nfds为fdset集合中最大描述符值加1,fdset是一个位数组,其大小限制为__FD_SETSIZE(1024),位数组的每一位代表其对应的描述符是否需要被检查。第二三四参数表示需要关注读、写、错误事件的文件描述符位数组,这些参数既是输入参数也是输出参数,可能会被内核修改用于标示哪些描述符上发生了关注的事件,所以每次调用select前都需要重新初始化fdset。timeout参数为超时时间,该结构会被内核修改,其值为超时剩余的时间。
select的调用步骤如下:
(1)使用copy_from_user从用户空间拷贝fdset到内核空间
(2)注册回调函数__pollwait
(3)遍历所有fd,调用其对应的poll方法(对于socket,这个poll方法是sock_poll,sock_poll根据情况会调用到tcp_poll,udp_poll或者datagram_poll)
(4)以tcp_poll为例,其核心实现就是__pollwait,也就是上面注册的回调函数。
(5)__pollwait的主要工作就是把current(当前进程)挂到设备的等待队列中,不同的设备有不同的等待队列,对于tcp_poll
来说,其等待队列是sk->sk_sleep(注意把进程挂到等待队列中并不代表进程已经睡眠了)。在设备收到一条消息(网络设备)或填写完文件数 据(磁盘设备)后,会唤醒设备等待队列上睡眠的进程,这时current便被唤醒了。
(6)poll方法返回时会返回一个描述读写操作是否就绪的mask掩码,根据这个mask掩码给fd_set赋值。
(7)如果遍历完所有的fd,还没有返回一个可读写的mask掩码,则会调用schedule_timeout是调用select的进程(也就是 current)进入睡眠。当设备驱动发生自身资源可读写后,会唤醒其等待队列上睡眠的进程。如果超过一定的超时时间(schedule_timeout 指定),还是没人唤醒,则调用select的进程会重新被唤醒获得CPU,进而重新遍历fd,判断有没有就绪的fd。
(8)把fd_set从内核空间拷贝到用户空间。
总结下select的几大缺点:
(1)每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
(2)同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
(3)select支持的文件描述符数量太小了,默认是1024
2.
poll与select不同,通过一个pollfd数组向内核传递需要关注的事件,故没有描述符个数的限制,pollfd中的events字段和revents分别用于标示关注的事件和发生的事件,故pollfd数组只需要被初始化一次。
poll的实现机制与select类似,其对应内核中的sys_poll,只不过poll向内核传递pollfd数组,然后对pollfd中的每个描述符进行poll,相比处理fdset来说,poll效率更高。poll返回后,需要对pollfd中的每个元素检查其revents值,来得指事件是否发生。
3.直到Linux2.6才出现了由内核直接支持的实现方法,那就是epoll,被公认为Linux2.6下性能最好的多路I/O就绪通知方法。epoll可以同时支持水平触发和边缘触发(Edge Triggered,只告诉进程哪些文件描述符刚刚变为就绪状态,它只说一遍,如果我们没有采取行动,那么它将不会再次告知,这种方式称为边缘触发),理论上边缘触发的性能要更高一些,但是代码实现相当复杂。epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时,返回的不是实际的描述符,而是一个代表就绪描述符数量的值,你只需要去epoll指定的一个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射(mmap)技术,这样便彻底省掉了这些文件描述符在系统调用时复制的开销。另一个本质的改进在于epoll采用基于事件的就绪通知方式。在select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知。
epoll既然是对select和poll的改进,就应该能避免上述的三个缺点。那epoll都是怎么解决的呢?在此之前,我们先看一下epoll 和select和poll的调用接口上的不同,select和poll都只提供了一个函数——select或者poll函数。而epoll提供了三个函 数,epoll_create,epoll_ctl和epoll_wait,epoll_create是创建一个epoll句柄;epoll_ctl是注 册要监听的事件类型;epoll_wait则是等待事件的产生。
对于第一个缺点,epoll的解决方案在epoll_ctl函数中。每次注册新的事件到epoll句柄中时(在epoll_ctl中指定 EPOLL_CTL_ADD),会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝 一次。
对于第二个缺点,epoll的解决方案不像select或poll一样每次都把current轮流加入fd对应的设备等待队列中,而只在
epoll_ctl时把current挂一遍(这一遍必不可少)并为每个fd指定一个回调函数,当设备就绪,唤醒等待队列上的等待者时,就会调用这个回调 函数,而这个回调函数会把就绪的fd加入一个就绪链表)。epoll_wait的工作实际上就是在这个就绪链表中查看有没有就绪的fd(利用 schedule_timeout()实现睡一会,判断一会的效果,和select实现中的第7步是类似的)。
对于第三个缺点,epoll没有这个限制,它所支持的FD上限是最大可以打开文件的数目,这个数字一般远大于2048,举个例子, 在1GB内存的机器上大约是10万左右,具体数目可以cat /proc/sys/fs/file-max察看,一般来说这个数目和系统内存关系很大。
总结:
(1)select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll其实也需要调用
epoll_wait不断轮询就绪链表,期间也可能多次睡眠和唤醒交替,但是它是设备就绪时,调用回调函数,把就绪fd放入就绪链表中,并唤醒在
epoll_wait中进入睡眠的进程。虽然都要睡眠和交替,但是select和poll在“醒着”的时候要遍历整个fd集合,而epoll在“醒着”的 时候只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间,这就是回调机制带来的性能提升。
(2)select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把current往设备等待队列中挂一次,而epoll只要 一次拷贝,而且把current往等待队列上挂也只挂一次(在epoll_wait的开始,注意这里的等待队列并不是设备等待队列,只是一个epoll内 部定义的等待队列),这也能节省不少的开销。
select,poll,epoll
这三种IO多路复用模型在不同的平台有着不同的支持,而epoll在windows下就不支持,好在我们有selectors模块,帮我们默认选择当前平台下最合适的
5.6 selectors模块实现聊天
基于selectors模块实现聊天-服务端
from socket import *
import selectors
sel=selectors.DefaultSelector()
def accept(server_fileobj,mask):
conn,addr=server_fileobj.accept()
sel.register(conn,selectors.EVENT_READ,read)
def read(conn,mask):
try:
data=conn.recv(1024)
if not data:
print('closing',conn)
sel.unregister(conn)
conn.close()
return
conn.send(data.upper()+b'_SB')
except Exception:
print('closing', conn)
sel.unregister(conn)
conn.close()
server_fileobj=socket(AF_INET,SOCK_STREAM)
server_fileobj.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
server_fileobj.bind(('127.0.0.1',8088))
server_fileobj.listen(5)
server_fileobj.setblocking(False) #设置socket的接口为非阻塞
sel.register(server_fileobj,selectors.EVENT_READ,accept) #相当于网select的读列表里append了一个文件句柄server_fileobj,并且绑定了一个回调函数accept
while True:
events=sel.select() #检测所有的fileobj,是否有完成wait data的
for sel_obj,mask in
events:
callback=sel_obj.data
#callback=accpet
callback(sel_obj.fileobj,mask) #accpet(server_fileobj,1)
#客户端
from socket import *
c=socket(AF_INET,SOCK_STREAM)
c.connect(('127.0.0.1',8088))
while True:
msg=input('>>: ')
if not msg:continue
c.send(msg.encode('utf-8'))
data=c.recv(1024)
print(data.decode('utf-8'))
python_12(并发编程)的更多相关文章
- [ 高并发]Java高并发编程系列第二篇--线程同步
高并发,听起来高大上的一个词汇,在身处于互联网潮的社会大趋势下,高并发赋予了更多的传奇色彩.首先,我们可以看到很多招聘中,会提到有高并发项目者优先.高并发,意味着,你的前雇主,有很大的业务层面的需求, ...
- 伪共享(false sharing),并发编程无声的性能杀手
在并发编程过程中,我们大部分的焦点都放在如何控制共享变量的访问控制上(代码层面),但是很少人会关注系统硬件及 JVM 底层相关的影响因素.前段时间学习了一个牛X的高性能异步处理框架 Disruptor ...
- 【Java并发编程实战】----- AQS(四):CLH同步队列
在[Java并发编程实战]-–"J.U.C":CLH队列锁提过,AQS里面的CLH队列是CLH同步锁的一种变形.其主要从两方面进行了改造:节点的结构与节点等待机制.在结构上引入了头 ...
- 【Java并发编程实战】----- AQS(三):阻塞、唤醒:LockSupport
在上篇博客([Java并发编程实战]----- AQS(二):获取锁.释放锁)中提到,当一个线程加入到CLH队列中时,如果不是头节点是需要判断该节点是否需要挂起:在释放锁后,需要唤醒该线程的继任节点 ...
- 【Java并发编程实战】----- AQS(二):获取锁、释放锁
上篇博客稍微介绍了一下AQS,下面我们来关注下AQS的所获取和锁释放. AQS锁获取 AQS包含如下几个方法: acquire(int arg):以独占模式获取对象,忽略中断. acquireInte ...
- 【Java并发编程实战】-----“J.U.C”:CLH队列锁
在前面介绍的几篇博客中总是提到CLH队列,在AQS中CLH队列是维护一组线程的严格按照FIFO的队列.他能够确保无饥饿,严格的先来先服务的公平性.下图是CLH队列节点的示意图: 在CLH队列的节点QN ...
- 【Java并发编程实战】-----“J.U.C”:Exchanger
前面介绍了三个同步辅助类:CyclicBarrier.Barrier.Phaser,这篇博客介绍最后一个:Exchanger.JDK API是这样介绍的:可以在对中对元素进行配对和交换的线程的同步点. ...
- 【Java并发编程实战】-----“J.U.C”:CountDownlatch
上篇博文([Java并发编程实战]-----"J.U.C":CyclicBarrier)LZ介绍了CyclicBarrier.CyclicBarrier所描述的是"允许一 ...
- 【Java并发编程实战】-----“J.U.C”:CyclicBarrier
在上篇博客([Java并发编程实战]-----"J.U.C":Semaphore)中,LZ介绍了Semaphore,下面LZ介绍CyclicBarrier.在JDK API中是这么 ...
随机推荐
- mysql优化20条原则
今天,数据库的操作越来越成为整个应用的性能瓶颈了,这点对于Web应用尤其明显.关于数据库的性能,这并不只是DBA才需要担心的事,而这更是我们程序员需要去关注的事情.当我们去设计数据库表结构,对操作数据 ...
- 未知USB设备 端口重置失败
1.开启手机中USB调试 进入“设置”->“应用程序”->“开发”勾选“USB调试程序”.这样设备才可以通过USB连线时被PC识别到. 2.安装驱动 要将Android手机连接到PC需要安 ...
- 使用media来加载css
默认的,css被当做渲染时候必须加载的资源. 设备类型和设备询问允许我们设置一些css资源编程可选的 对于所有的css资源,无论是必须的还是可选的,都会被浏览器加载 The New York Time ...
- Asterisk func group
Synopsis Gets, sets or clears the channel group. Each channel can only be member of exactly one grou ...
- HDU3666 THE MATRIX PROBLEM (差分约束+取对数去系数)(对退出情况存疑)
You have been given a matrix C N*M, each element E of C N*M is positive and no more than 1000, The p ...
- python 基础之第十天(闭包,装饰器,生成器,tarfile与hashlib模块使用)
局部变量与全局变量 局部变量:在函数里面定义的,只有当函数活动时才生效 全局变量:不在函数里面的 In [1]: x=10 In [2]: def bar(): ...: x=20 ...: prin ...
- Win7点击文件夹右键可打开cmd控制台,并获取当前目录
当我们用cmd时,有时要切换到某个文件夹的目录,可以在当前目录下,按住shift单击右键打开控制台,也可以在鼠标右键中添加cmd启动命令: 1.在开始搜索框输入regedit,打开注册表: 2.打开 ...
- Paint Tree
题意: 给定一棵n个点的树,给定平面上n个点,将n个点用线段连起来画成树的形状,使得不存在不在端点相交的线段,构造出一种情况. 解法: 首先观察我们常规画出来的树形图可知,树的子树是根据极角分开的,这 ...
- URI is not registered (Settings | Languages & Frameworks | Schemas and DTDs)
URI is not registered (Settings | Languages & Frameworks | Schemas and DTDs) 有时候在IDEA中配置spring文件 ...
- shell的split生成的文件按规律命名及添加扩展名
可以参考 用shell切分文件--split shell下的split命令主要用于分割一些大文件用的,比如经常要用到将一个几十万行的TXT分割为多少行一个的文件,非常有用,唯一坑爹的是,切割后的文件不 ...