如何看待微软新开源的LightGBM?
GBDT虽然是个强力的模型,但却有着一个致命的缺陷,不能用类似mini batch的方式来训练,需要对数据进行无数次的遍历。如果想要速度,就需要把数据都预加载在内存中,但这样数据就会受限于内存的大小;如果想要训练更多的数据,就要使用外存版本的决策树算法。虽然外存算法也有较多优化,SSD也在普及,但在频繁的IO下,速度还是比较慢的。
为了能让GBDT高效地用上更多的数据,我们把思路转向分布式GBDT,然后就有了LightGBM。设计的思路主要是两点,
1、 单个机器在不牺牲速度的情况下,尽可能多地用上更多的数据
2、 多机并行的时候,通信的代价尽可能地低,并且在计算机上可以做到线性加速
基于这两个需求,LightGBM选择了基于histogram的决策树算法。相比于另一个主流的算法pre-sorted(如xgboost中的exct算法),histogram在内存消耗和计算代价上都有不少优势。
Lightgbm算法
一、发展过程-why Lightgbm
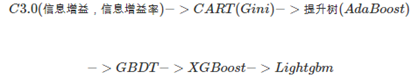
CART模型往往过于简单无法有效地进行预测,因此一个更加强力的模型叫做 tree ensemble
1、 Adaboost算法
Adaboost是一种提升树的方法,和三个臭皮匠,赛过一个诸葛亮的道理一样(类似于专家打分)
(1) 如何改变训练数据的权重和概率分布
提高前一轮被弱分类器错误分类的样本的权重,降低前一轮被分对的权重
(2) 如何将弱分类器组合成一个提升分类器,亦即,每个分类器,前面的权重如何设置
采取“多数表决”的方法,加大分类错误率小的弱分类器的权重,使其作用较大,而减小分类错误率大的弱分类器的权重,使其在表决中其较小的作用。
2、 GBDT算法以及优缺点
GBDT和Adaboost很类似,但是又有所不同。
GBDT和其他Boosting算法一样,通过将表现一般的数个模型(通常是深度固定的决策树)组合在一起来集成一个表现较好的模型。Adaboost是通过提升错分数据点的权重来定位模型的不足,Gradient Boosting通过负梯度来识别问题,通过计算负梯度来改进模型,即通过反复地选择一个指向负梯度方向的函数,该算法可被看作在函数空间里对目标函数进行优化。
因此可以说,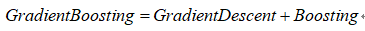
缺点:
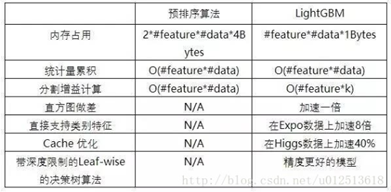
GBDT->预排序算法
(1) 空间消耗大。这样的算法需要保证数据的特征值,还保存了特征排序的结果(例如排序后的索引),这里需要消耗训练数据两倍的内存。
(2) 时间上也有较大的开销,在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗代价大
(3) 对cache优化不友好。在预排序后,特征对梯度的访问是一种随机访问,并且不同特征访问的顺序不一样,无法对cache进行优化。同时,在每一层长树的时候,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会在成较大的catch miss。
why?
常用的机器学习算法,例如神经网络等算法,都可以以mini-batch的方式训练,训练数据的大小不会受到内存限制。而GBDT在每一次迭代的时候,都需要遍历整个训练数据多次。如果把整个训练数据装进内存则会限制训练数据的大小;如果不装进内存,反复地读写训练数据又会消耗非常大的时间。尤其面对工业级的海量的数据,普通的GBDT算法是不能满足其需求的。
LightGBM提出的主要原因就是为了解决GBDT在海量数据遇到的问题,让GBDT可以更好的用于工业实践。
二、基本介绍
LightGBM是一个基于树学习的梯度提升框架,支持高效率的并行训练,他有以下优势:
1) 更快的训练效率
2) 低内存使用
3) 更好的准确率
4) 支持并行和GPU
5) 可处理大规模数据
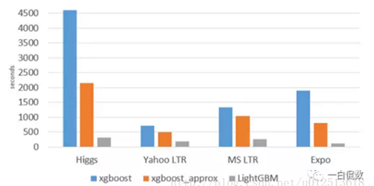
LightGBM主打的高效并行训练让其性能超越现有的其他boosting工具。一个实验表明,在Higgs数据集上LightGBM比XGBoost快将近10倍,内存占用率大约为XGBoost的1/6.
三、lightgbm原理
1、 基于Histogram(直方图)的决策树算法
2、 带深度限制的Leaf-wise的叶子生长策略
3、 直方图做差加速
4、 直接支持类别特征
5、 Cache命中率优化
6、 基于直方图的系数特征优化
7、 多线程优化
1、 直方图算法
直方图算法的基本思想是先把连续的浮点特征值离散化成k个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累计统计量,当遍历一次数据后,直方图累计了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。

使用直方图算法有很多优点。首先,最明显就是内存消耗的降低,直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8

然后在计算上的代价也大幅降低,与排序算法每遍历一个特征值就需要计算一次分类的增益,而直方图只需要计算k次(k可以认为是常数),时间复杂度从O(data*feature)优化到O(k*feature).
当然,Histogram算法并不是完美的,由于特征被离散化后,找到的并不是很精确的分割点,所以会对结果产生影响。但在不同的数据集上结果表明,离散化的分割点对最终的精度影响并不是很大,甚至有时候会更好一点。原因是决策树本来就是弱模型,分割点是不是精确并不是太重要;较粗的分割点也是正则化的效果,可以优先防止过拟合;即使单颗树的训练误差比精确分割的算法稍大,但在梯度提升的框架下没有太大的影响。
2、 Lightgbm的Histogram(直方图)做差加速
一个容易观察到的现象:一个叶子的直方图可以由他的父亲节点的直方图与兄弟的直方图做差得到。通常构造直方图,需要遍历该叶子上的所有数据,但直方图做差仅需遍历直方图的k个桶(感觉类似于分块查找)。利用这个方法,LightGBM可以构造一个叶子的直方图后,可以用非常微小的代价得到他兄弟叶子的直方图,在速度上可以提升一倍。

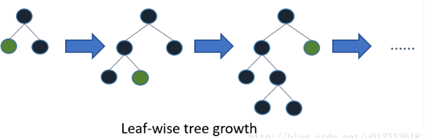
3、 带深度限制的Leaf-wise的叶子生长策略
Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。但实际上Level-wise是一种低效的算法,因为他不加区分的对待同一层的叶子,带来了很多没必要的开销,因为实际上很多叶子的分裂增益较低,没有必要进行搜索和分裂。
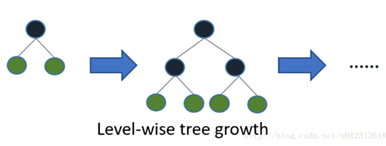
Leaf-wise则是一种更为高效的策略,每次从当前所有叶子中,找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-wise相比,在分裂次数相同的情况下,Leaf-wise可以降低更多的误差,得到更好的精度。leaf-wise的缺点是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度的限制,在保证高效率的同时防止过拟合。
直接支持类别特征
实际上大多数机器学习工具都无法直接支持类别特征,一般需要把类别特征转化到多维的0/1特征,降低了空间和时间的效率。而类别特征的使用是时间中很常用的。基于这个考虑,lightGBM优化了对类别特征的支持,可以直接输入类别特征,不需要额外的0/1展开。并在决策树算法上还增加了类别特征的决策树规则。在Expo数据集上实验,相比0/1展开的方法,训练速度可以加速8倍,并且精度一致。据我们所知,LightGBM是第一个支持类别特征的GBDT工具。
LightGBM的单机版本还有很多其他细节上的优化,比如cache访问优化,多线程优化,系数特征优化等等,
4、 直接支持高效并行
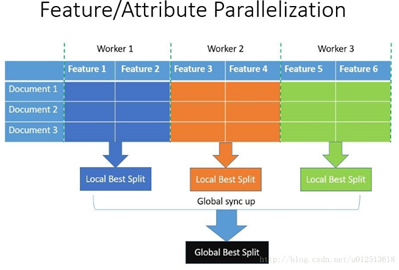
lightGBM还具有支持高效并行的优点。LightGBM原生支持并行学习,目前支持特征并行和数据并行两种。
特征并行的主要思想是在不同机器在不同的特征集合上分别寻找最优的分割点,然后在机器间同步最优的分割点。
数据并行则是让不同的机器先在本地构造直方图,然后进行全局的合并,最后在合并的直方图上面寻找最优的分割点。
LightGBM针对这两种并行方法都做了优化,在特征并行算法中,通过在本地保存全部数据避免对数据切分结果的通信;在数据并行中使用分散规约,把直方图合并的任务分摊到不同的机器,降低通信和计算,并利用直方图做差,进一步减小了一般的通信量。
基于投票的数据并行则进一步优化数据并行中的通信代价,使通信代价变成常数级别。在数据量很大的时候,使用投票并行可以得到非常好的加速效果。

如何看待微软新开源的LightGBM?的更多相关文章
- 工业级GBDT算法︱微软开源 的LightGBM(R包正在开发....)
看完一篇介绍文章后,第一个直觉就是这算法已经配得上工业级属性.日前看到微软已经公开了这一算法,而且已经发开python版本,本人觉得等hadoop+Spark这些平台配齐之后,就可以大规模宣传啦~如果 ...
- 在Windows Python3.5 安装LightGBM
LightGBM是微软旗下DMTK推出的Gradient Boosting框架,因为其快速高效,以后或许会成为数据挖掘竞赛中的又一个大杀器.地址:https://github.com/Microsof ...
- 开源|LightGBM:三天内收获GitHub 1000+ 星
原创 2017-01-05 LightGBM 微软研究院AI头条 [导读]不久前微软DMTK(分布式机器学习工具包)团队在GitHub上开源了性能超越其他boosting工具的LightGBM,在三天 ...
- LightGBM,面试会问到的都在这了(附代码)!
1. LightGBM是什么东东 不久前微软DMTK(分布式机器学习工具包)团队在GitHub上开源了性能超越其他boosting工具的LightGBM,在三天之内GitHub上被star了1000次 ...
- R︱Yandex的梯度提升CatBoost 算法(官方述:超越XGBoost/lightGBM/h2o)
俄罗斯搜索巨头 Yandex 昨日宣布开源 CatBoost ,这是一种支持类别特征,基于梯度提升决策树的机器学习方法. CatBoost 是由 Yandex 的研究人员和工程师开发的,是 Matri ...
- LightGBM的算法介绍
LightGBM算法的特别之处 自从微软推出了LightGBM,其在工业界表现的越来越好,很多比赛的Top选手也掏出LightGBM上分.所以,本文介绍下LightGBM的特别之处. LightGBM ...
- XGBoost、LightGBM、Catboost总结
sklearn集成方法 bagging 常见变体(按照样本采样方式的不同划分) Pasting:直接从样本集里随机抽取的到训练样本子集 Bagging:自助采样(有放回的抽样)得到训练子集 Rando ...
- 我眼中的ASP.NET Core之微服务
### 前言 前几天在博客园看到有园友在分享关于微软的一个微服务架构的示例程序,想必大家都已经知道了,那就是[eShopOnContainers](https://github.com/dotnet- ...
- 好文推荐:转载一篇别人kaggle的经验分享
转载:https://www.toutiao.com/i6435866304363627010/ 笔者参加了由Quora举办的Quora Question Pairs比赛,并且获得了前1%的成绩.这是 ...
随机推荐
- java 串口通信实现流程
1.下载64位rxtx for java 链接:http://fizzed.com/oss/rxtx-for-java 2.下载下来的包解压后按照说明放到JAVA_HOME即JAVA的安装路径下面去 ...
- netcat 详解
简介 netcat 是一款调试 TCP/UDP 网络连接的利器,常被称作网络调试的瑞士军刀,可见其功能强大. netcat 在 Linux, Windows 等各大操作系统上都有对应等发行版,以下以 ...
- JS encodeURIComponent函数
为了避免歧义,可以用JS 的encodeURIComponent函数 将有歧义的字符(?+=等)转换成对应的ASCII编码 for(var i=0;i<whichform.elements.l ...
- 动态规划专题(一)——状压DP
前言 最近,决定好好恶补一下我最不擅长的\(DP\). 动态规划的种类还是很多的,我就从 状压\(DP\) 开始讲起吧. 简介 状压\(DP\)应该是一个比较玄学的东西. 由于它的时间复杂度是指数级的 ...
- 使ListView控件中的选择项高亮显示
实现效果: 知识运用: ListView控件的SelectedItems属性 //获取在ListView控件中被选中数据项的集合 public ListView.SelectedListViewIte ...
- Winform导入Excel数据到数据库
public partial class ImportExcel : Form { AceessHelpers accessHelper = new AceessHelpers(); public I ...
- JavaScript 交换两个变量的值
方法一 let a = "a", b = "b"; console.log(a, b); let t = a; a = b; b = t; console.lo ...
- 你所不知道的js的小知识点(1)
1.js调试工具 debugger <div class="container"> <h3>debugger语句会产生一个断点,用于调试程序,并没有实际功能 ...
- 32-2题:LeetCode102. Binary Tree Level Order Traversal二叉树层次遍历/分行从上到下打印二叉树
题目 给定一个二叉树,返回其按层次遍历的节点值. (即逐层地,从左到右访问所有节点). 例如: 给定二叉树: [3,9,20,null,null,15,7], 3 / \ 9 20 / \ 15 7 ...
- JAVA JDBC 连接 Oracle
使用 Junit 测试类编写 public class JdbcTest { private Connection con = null;// 创建一个数据库连接 private PreparedSt ...