hdfs校验和
hdfs完整性:用户希望储存和处理数据的时候,不会有任何损失或者损坏。所以提供了两种校验:
1.校验和(常用循环冗余校验CRC-32)。
2.运行后台进程来检测数据块。
校验和:
a.写入数据节点验证
b.读取数据节点验证
c.恢复数据
d.Localfilesystem类
e.ChecksumfileSystem类
写入数据节点验证:
Hdfs会对写入的所有数据计算校验和,并在读取数据时验证校验和。
元数据节点负责在验证收到的数据后,储存数据及其校验和。在收到客户端数据或复制其他datanode的数据时执行。
正在写数据的客户端将数据及其校验和发送到一系列数据节点组成的管线,管线的最后一个数据节点负责验证校验和。
读取数据节点验证:
客户端读取数据节点数据也会验证校验和,将它们与数据节点中储存的校验和进行比较。
每个数据节点都持久化一个用于验证的校验和日志。 客户端成功验证一个数据块后,会告诉这个数据节点,数据节点由此更新日志。
恢复数据:
由于hdfs储存着每个数据块的备份,它可以通过复制完好的数据备份来修复损坏的数据块来恢复数据。
Localfilesystem类:
Hadoop的LocalFileSystem类是用来执行客户端的校验和验证。当写入一个名为filename的文件时文件系统客户端会在包含文件块校验和的同一目录内建立一个名为Filename.crc的隐藏文件。
ChecksumfileSystem类:
LocalFileSystem类通过ChecksumFileSystem类来完成自己的任务 FileSystem rawFs;
FileSystem checksummedFs=new ChecksumFileSystem(rawFS);
可以通过CheckFileSystem的getRawFileSystem()方法获取源文件系统。
当检测到错误,CheckFileSystem类会调用reportCheckSumFailure()方法报告错误,然后LocalFileSystem将这个出错的文件和校验和移到名为bad_files的文件夹内,管理员可以定期检查这个文件夹。
DatablockScanner:
数据节点后台有一个进程DataBlockScanner,定期验证储存在这个数据节点上的所有数据项,该项措施是为解决物理储存媒介上的损坏。DataBlockScanner是作为数据节点的一个后台线程工作的,跟着数据节点同时启动 它的工作流程如图:
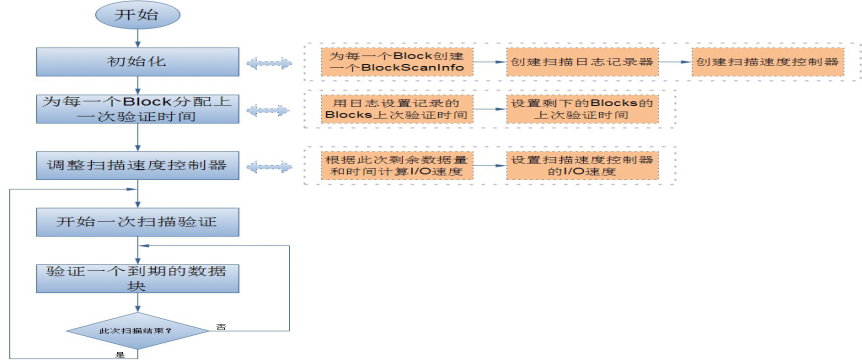
由于对数据节点上的每一个数据块扫描一遍要消耗较多系统资源,因此扫描周期的值一般比较大, 这就带来另一个问题,就是在一个扫描周期内可能出现数据节点重启的情况,所以为了提高系统性能,避免数据节点在启动后对还没有过期的数据块又扫描一遍, DataBlockScanner在其内部使用了日志记录器来持久化保存每一个数据块上一次扫描的时间 这样的话,数据节点可以在启动之后通过日志文件来恢复之前所有的数据块的有效时间。
hdfs校验和的更多相关文章
- Hbase学习02
第2章 Apache HBase配置 本章在“入门”一章中进行了扩展,以进一步解释Apache HBase的配置. 请仔细阅读本章,特别是基本先决条件,确保您的HBase测试和部署顺利进行,并防止数据 ...
- 何为HDFS?
该文来自百度百科,自我收藏. Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点.但同时, ...
- HDFS DataNode 设计实现解析
前文分析了 NameNode,本文进一步解析 DataNode 的设计和实现要点. 文件存储 DataNode 正如其名是负责存储文件数据的节点.HDFS 中文件的存储方式是将文件按块(block)切 ...
- hdfs的读写数据流
hdfs的读: 首先客户端通过调用fileSystem对象中的open()函数读取他需要的的数据,fileSystem是DistributedFileSystem的一个实例, Distrib ...
- Hadoop官方文档翻译——HDFS Architecture 2.7.3
HDFS Architecture HDFS Architecture(HDFS 架构) Introduction(简介) Assumptions and Goals(假设和目标) Hardware ...
- HDFS原理介绍
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表的论文翻版的.论文为GFS(Google File System)Googl ...
- Hbase写入hdfs源码分析
版权声明:本文由熊训德原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/258 来源:腾云阁 https://www.qclo ...
- HDFS文件读写过程
参考自<Hadoop权威指南> [http://www.cnblogs.com/swanspouse/p/5137308.html] HDFS读文件过程: 客户端通过调用FileSyste ...
- HDFS 原理、架构与特性介绍--转载
原文地址:http://www.uml.org.cn/sjjm/201309044.asp 本文主要讲述 HDFS原理-架构.副本机制.HDFS负载均衡.机架感知.健壮性.文件删除恢复机制 1:当前H ...
随机推荐
- Struts2返回JSON数据的具体应用范…
Struts2返回JSON数据的具体应用范例 博客分类: Struts2 Struts2JSON 早在我刚学Struts2之初的时候,就想写一篇文章来阐述Struts2如何返回JSON数据的原理和具 ...
- 《Java多线程编程核心技术》读后感(十)
一生产一消费:操作栈 本实例是使生产者向堆栈List对象中放入数据,使消费者从List堆栈中取出数据.List最大容量是1 package Third; import java.util.ArrayL ...
- js关于为DOM对象添加自定义属性的方式和区别
DOM对象的三种在添加自定义属性的方式 一是 通过 “.”+“属性名” 二是 setAttribute()(getAttribute()获取) 三是 直接在元素标签上加属性 如:<div n ...
- SQL 分组获取产品 前两条记录
select * from ( select *, ROW_NUMBER() over(partition by IPAddress order by recordtime desc) as rowN ...
- JSP 标准标签库(JSTL)(菜鸟教程)
菜鸟教程 JSTL 1.1 与 JSTL 1.2 之间的区别?如何下载 JSTL 1.2? JSTL 1.2 中不要求 standard.jar 包. 您可以在 Maven 中央仓库中找到它们. ht ...
- MYSQL数据库设计规范11111
MYSQL数据库设计规范 1.数据库命名规范 采用26个英文字母(区分大小写)和0-9的自然数(经常不需要)加上下划线'_'组成; 命名简洁明确(长度不能超 ...
- Scipy实现图片去噪
先贴要处理的图片如下 由图片显示可知: # 图片中存在噪声点,白色的圆环# 圆环上的数据和圆环里面和外面不同,所以可以显示出肉眼可识别的图片# 波动# 存在噪声的地方,波动比较大 # 傅里叶变换可以将 ...
- [转]PBFT 算法详解
https://www.cnblogs.com/mafeng/p/8405375.html
- c语言的小问题
在c语言编程中要注意一个小问题,如果你编写scanf("%d",&n);printf("%d",n)这个你输入几就输出几,毫无疑问.但是现在问题来了?如 ...
- 黑马学习Ajax 跨域资源共享 jQuery+jsonp实现