request库
0x00 环境简介和安装
我这里使用的是python2.7版本,直接使用pycharm2018这款IDE。
首先在pycharm中配置一下virtualenv环境,virtualenv是一个创建独立Python运行环境的工具,为一个应用创建一套“隔离”的Python运行环境。
创建new project时选择创建新的环境,修改你们自己的目录,如果主机内有多个版本的python解释器可自行选择

创建完成后可以在项目中安装requests库,file-settings打开如下界面
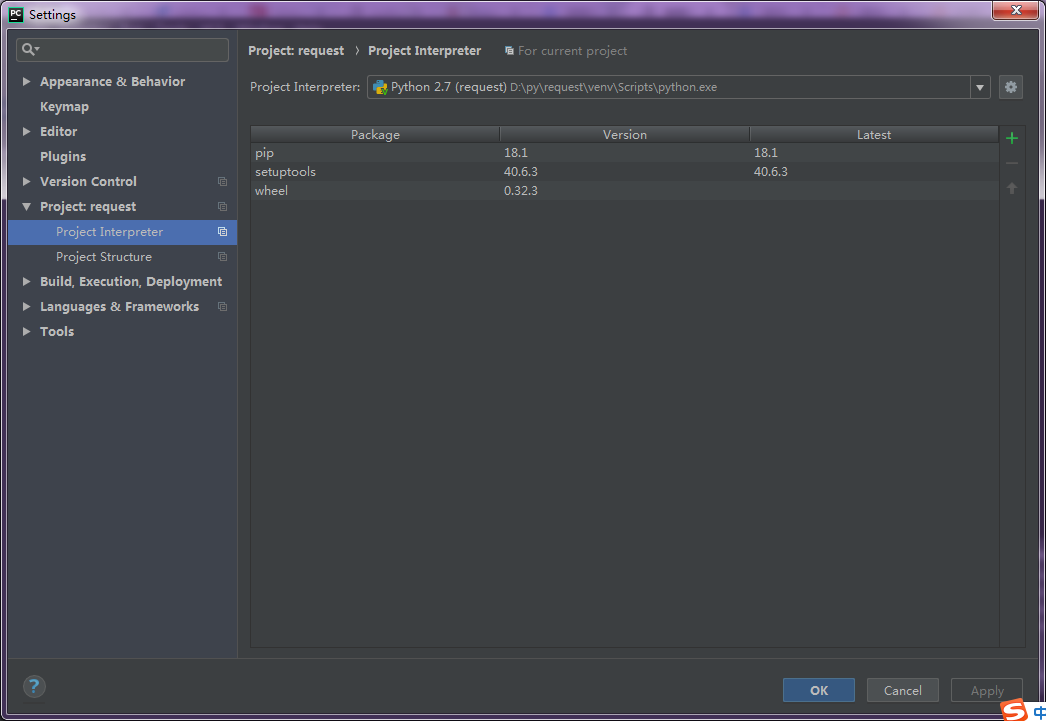
单击右上角绿色加号,搜索requests并install

这里如果你的pip版本大于等于10,安装的时候会报错,原因是由于新版pip的函数发生了变化,解决办法参考这个帖子
【Python】【亲测好用】安装第三方包报错:AttributeError:'module' object has no attribute 'main'
0x01 使用requests
请求方法
- GET: 查看资源
- POST: 增加资源
- PUT: 修改资源
- DELETE: 删除资源
- HEAD: 查看响应头
- patch: 局部更新url资源

基本用法:requests.[methon](url)
import requests
response = requests.get('https://www.cnblogs.com/Ragd0ll/p/10176258.html')
print(response.status_code) # 打印状态码
print(response.url) # 打印请求url
print(response.headers) # 打印头信息
print(response.cookies) # 打印cookie信息
print(response.text) #以文本形式打印网页源码
print(response.content) #以字节流形式打印
request的可选参数
1.param

2.data

3.json

4.headers

5.cookies、auth

6.files

7.timeout

8.proxies

9.allow_redirects、stream、verify、cert

带参数的get请求:
第一种直接将参数放在url内
import requests response = requests.get(http://httpbin.org/get?name=gemey&age=22)
print(response.text)
第二种是将参数放入字典,然后在请求时给params参数赋值
import requests
data = {
'name': 'tom',
'age': 20
}
response = requests.get('http://httpbin.org/get', params=data)
print(response.text)
两段代码的结果相同
基本POST请求:
import requests
data = {'name':'tom','age':''}
response = requests.post('http://httpbin.org/post', data=data)
简单保存一个二进制文件
import requests
response = requests.get('https://img2018.cnblogs.com/blog/1342178/201812/1342178-20181225201042109-1353349536.png')
b = response.content
with open('F://fengjing.jpg','wb') as f:
f.write(b)
为你的请求添加头信息
import requests
heads = {}
heads['User-Agent'] = 'Mozilla/5.0 ' \
'(Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 ' \
'(KHTML, like Gecko) Version/5.1 Safari/534.50'
response = requests.get('https://home.cnblogs.com/u/Ragd0ll/',headers=headers)
获取cookie
import requests
response = requests.get('https://home.cnblogs.com/u/Ragd0ll/')
print(response.cookies)
print(type(response.cookies))
for k,v in response.cookies.items():
print(k+':'+v)
会话维持
import requests session = requests.Session()
session.get('http://httpbin.org/cookies/set/number/12345')
response = session.get('http://httpbin.org/cookies')
print(response.text)
证书验证设置
import requests
from requests.packages import urllib3 urllib3.disable_warnings() #从urllib3中消除警告
response = requests.get('https://www.12306.cn',verify=False) #证书验证设为FALSE
print(response.status_code)
超时异常捕获
import requests
from requests.exceptions import ReadTimeout try:
res = requests.get('http://httpbin.org', timeout=0.1)
print(res.status_code)
except ReadTimeout:
print(timeout)
异常处理
import requests
from requests.exceptions import ReadTimeout,HTTPError,RequestException try:
response = requests.get('http://www.baidu.com',timeout=0.5)
print(response.status_code)
except ReadTimeout:
print('timeout')
except HTTPError:
print('httperror')
except RequestException:
print('reqerror')
Response的方法

request库的更多相关文章
- Python3 urllib.request库的基本使用
Python3 urllib.request库的基本使用 所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地. 在Python中有很多库可以用来抓取网页,我们先学习urlli ...
- Python request库与爬虫框架
Requests库的7个主要方法 requests.request():构造一个请求,支持以下各方法的基础方法 requests.get():获取HTML网页的主要方法,对应于HTTP的GET ...
- Request库使用response.text返回乱码问题
我们日常使用Request库获取response.text,这种调用方式返回的text通常会有乱码显示: import requests res = requests.get("https: ...
- 爬虫——urllib.request库的基本使用
所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地.在Python中有很多库可以用来抓取网页,我们先学习urllib.request.(在python2.x中为urllib2 ...
- 爬虫request库规则与实例
Request库的7个主要方法: requests.request(method,url,**kwargs) method:请求方式,对应get/put/post等7种: r = reques ...
- Python网络爬虫与信息提取[request库的应用](单元一)
---恢复内容开始--- 注:学习中国大学mooc 嵩天课程 的学习笔记 request的七个主要方法 request.request() 构造一个请求用以支撑其他基本方法 request.get(u ...
- Request库的安装与使用
Request库的安装与使用 安装 pip install reqeusts Requests库的7个主要使用方法 requests.request() 构造一个请求,支撑以下各方法的基础方法 req ...
- python网络爬虫学习笔记(一)Request库
一.Requests库的基本说明 引入Rquests库的代码如下 import requests 库中支持REQUEST, GET, HEAD, POST, PUT, PATCH, DELETE共7个 ...
- Request库学习
0x00前言 这库让我爱上了python 碉堡! 开心去学了一些python,然后就来学这个时候神库~~ 资料来源:http://cn.python-requests.org/en/latest/u ...
- 爬虫入门【1】urllib.request库用法简介
urlopen方法 打开指定的URL urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, ca ...
随机推荐
- Linux dmidecode命令
1.linux系统自带的dmidecode工具查询服务器硬件信息 dmidecode 用于获取服务器的硬件信息,通常是在不打开计算机机箱的情况下使用该命令来查找硬件详细信息 这个命令可以查看内存的几乎 ...
- jsp中的文件上传
首先需要有以下的jar包 jsp代码如下: <!-- ${pageContext.request.contextPath}为: "/" + 当前项目名 --> < ...
- ZendFramework-2.4 源代码 - 关于服务管理器
// ------ 决定“服务管理器”配置的位置 ------ // 1.在模块的入口类/data/www/www.domain.com/www/module/Module1/Module.php中实 ...
- [译]The Python Tutorial#3. An Informal Introduction to Python
3. An Informal Introduction to Python 在以下示例中,输入和输出以提示符(>>>和...)的出现和消失来标注:如果想要重现示例,提示符出现时,必须 ...
- CMSIS-DAP仿真器_学习(转载)
先给大家普及一下,哈哈.CMSIS-DAP仿真器,是ARM官方做的开源仿真器,没有版权,自由制作.官方给的源代码,使用的是NXP的单片机LPC4320做的.这个源代码,只要你安装了KEIL5,就可以找 ...
- linux lvm扩容
1.分区, 查看磁盘使用:fdisk -l 对磁盘分区:fdisk /dev/sdb 2.创建pv pvcreate /dev/sdb1 查看pv: pvdisplay 3.查看vg vgdisp ...
- MVC中Spring.net 对基类控制器无效 过滤器控制器无效
比如现在我又一个BaseController作为基类控制器,用于过滤权限.登录判断等作用,其它控制由原本的继承Controller,改为继承BaseController.然后BaseControlle ...
- proguaid 混淆代码
注意:这里有一个坑.就是-ignorewarnings 他老是混淆不了,告诉你不行.其实加上这句话,就可以了. 下面贴一下代码: -injars c:/ceb_lib.jar -outjars c:/ ...
- TCP/IP网络编程之套接字类型与协议设置
套接字与协议 如果相隔很远的两人要进行通话,必须先决定对话方式.如果一方使用电话,另一方也必须使用电话,而不是书信.可以说,电话就是两人对话的协议.协议是对话中使用的通信规则,扩展到计算机领域可整理为 ...
- jQuery+Asp.net 实现简单的下拉加载更多功能
原来做过的商城项目现在需要增加下拉加载的功能,简单的实现了一下.大概可以整理一下思路跟代码. 把需要下拉加载的内容进行转为JSON处理存在当前页面: <script type="tex ...