Adam和学习率衰减(learning learning decay)
本文先介绍一般的梯度下降法是如何更新参数的,然后介绍 Adam 如何更新参数,以及 Adam 如何和学习率衰减结合。
梯度下降法更新参数
梯度下降法参数更新公式:
\[
\theta_{t+1} = \theta_{t} - \eta \cdot \nabla J(\theta_t)
\]
其中,\(\eta\) 是学习率,\(\theta_t\) 是第 \(t\) 轮的参数,\(J(\theta_t)\) 是损失函数,\(\nabla J(\theta_t)\) 是梯度。
在最简单的梯度下降法中,学习率 \(\eta\) 是常数,是一个需要实现设定好的超参数,在每轮参数更新中都不变,在一轮更新中各个参数的学习率也都一样。
为了表示简便,令 \(g_t = \nabla J(\theta_t)\),所以梯度下降法可以表示为:
\[
\theta_{t+1} = \theta_{t} - \eta \cdot g_t
\]
Adam 更新参数
Adam,全称 Adaptive Moment Estimation,是一种优化器,是梯度下降法的变种,用来更新神经网络的权重。
Adam 更新公式:
\[
\begin{aligned}
m_{t} &=\beta_{1} m_{t-1}+\left(1-\beta_{1}\right) g_{t} \\
v_{t} &=\beta_{2} v_{t-1}+\left(1-\beta_{2}\right) g_{t}^{2} \\
\hat{m}_{t} &=\frac{m_{t}}{1-\beta_{1}^{t}} \\
\hat{v}_{t} &=\frac{v_{t}}{1-\beta_{2}^{t}} \\
\theta_{t+1}&=\theta_{t}-\frac{\eta}{\sqrt{\hat{v}_{t}}+\epsilon} \hat{m}_{t}
\end{aligned}
\]
在 Adam 原论文以及一些深度学习框架中,默认值为 \(\eta = 0.001\),\(\beta_1 = 0.9\),\(\beta_2 = 0.999\),\(\epsilon = 1e-8\)。其中,\(\beta_1\) 和 \(\beta_2\) 都是接近 1 的数,\(\epsilon\) 是为了防止除以 0。\(g_{t}\) 表示梯度。
咋一看很复杂,接下一一分解:
- 前两行:
\[
\begin{aligned}
m_{t} &=\beta_{1} m_{t-1}+\left(1-\beta_{1}\right) g_{t} \\
v_{t} &=\beta_{2} v_{t-1}+\left(1-\beta_{2}\right) g_{t}^{2}
\end{aligned}
\]
这是对梯度和梯度的平方进行滑动平均,即使得每次的更新都和历史值相关。
中间两行:
\[
\begin{aligned}
\hat{m}_{t} &=\frac{m_{t}}{1-\beta_{1}^{t}} \\
\hat{v}_{t} &=\frac{v_{t}}{1-\beta_{2}^{t}}
\end{aligned}
\]
这是对初期滑动平均偏差较大的一个修正,叫做 bias correction,当 \(t\) 越来越大时,\(1-\beta_{1}^{t}\) 和 \(1-\beta_{2}^{t}\) 都趋近于 1,这时 bias correction 的任务也就完成了。最后一行:
\[
\theta_{t+1}=\theta_{t}-\frac{\eta}{\sqrt{\hat{v}_{t}}+\epsilon} \hat{m}_{t}
\]
这是参数更新公式。
学习率为 \(\frac{\eta}{\sqrt{\hat{v}_{t}}+\epsilon}\),每轮的学习率不再保持不变,在一轮中,每个参数的学习率也不一样了,这是因为 \(\eta\) 除以了每个参数 \(\frac{1}{1- \beta_2} = 1000\) 轮梯度均方和的平方根,即 \(\sqrt{\frac{1}{1000}\sum_{k = t-999}^{t}g_k^2}\)。而每个参数的梯度都是不同的,所以每个参数的学习率即使在同一轮也就不一样了。(可能会有疑问,\(t\) 前面没有 999 轮更新怎么办,那就有多少轮就算多少轮,这个时候还有 bias correction 在。)
而参数更新的方向也不只是当前轮的梯度 \(g_t\) 了,而是当前轮和过去共 \(\frac{1}{1- \beta_1} = 10\) 轮梯度的平均。
有关滑动平均的理解,可以参考我之前的博客:理解滑动平均(exponential moving average)。
Adam + 学习率衰减
在 StackOverflow 上有一个问题 Should we do learning rate decay for adam optimizer - Stack Overflow,我也想过这个问题,对 Adam 这些自适应学习率的方法,还应不应该进行 learning rate decay?
我简单的做了个实验,在 cifar-10 数据集上训练 LeNet-5 模型,一个采用学习率衰减 tf.keras.callbacks.ReduceLROnPlateau(patience=5),另一个不用。optimizer 为 Adam 并使用默认的参数,\(\eta = 0.001\)。结果如下:
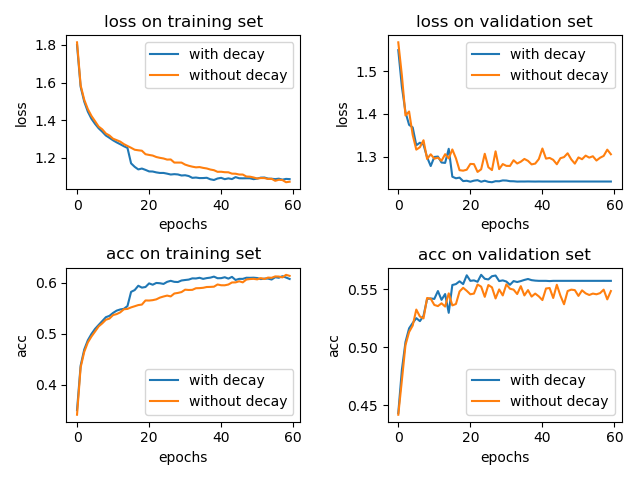
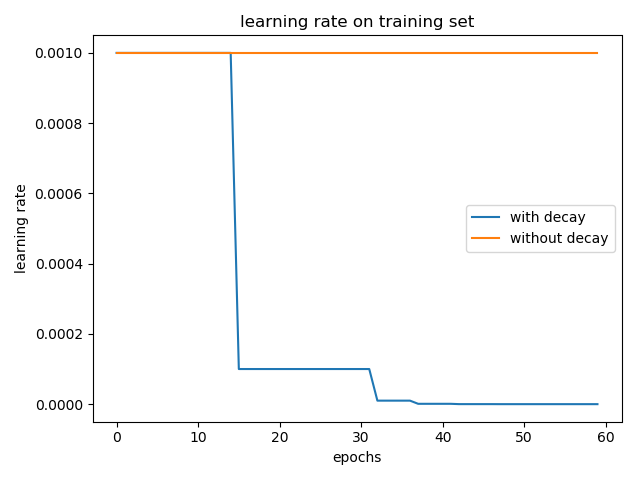
加入学习率衰减和不加两种情况在 test 集合上的 accuracy 分别为: 0.5617 和 0.5476。(实验结果取了两次的平均,实验结果的偶然性还是有的)
通过上面的小实验,我们可以知道,学习率衰减还是有用的。(当然,这里的小实验仅能代表一小部分情况,想要说明学习率衰减百分之百有效果,得有理论上的证明。)
当然,在设置超参数时就可以调低 \(\eta\) 的值,使得不用学习率衰减也可以达到不错的效果。
将学习率从默认的 0.001 改成 0.0001,epoch 增大到 120,实验结果如下所示:
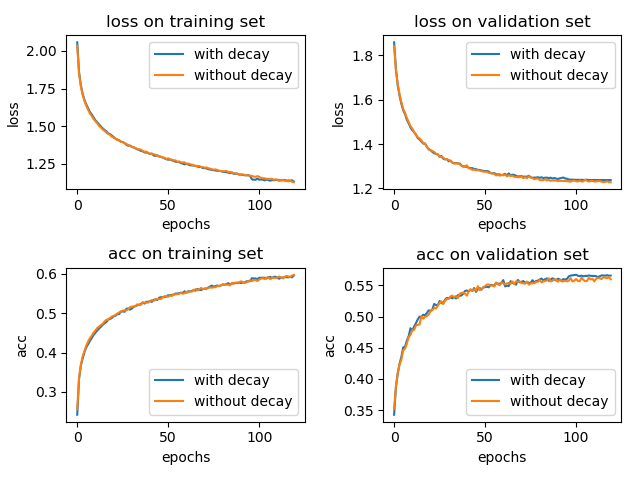
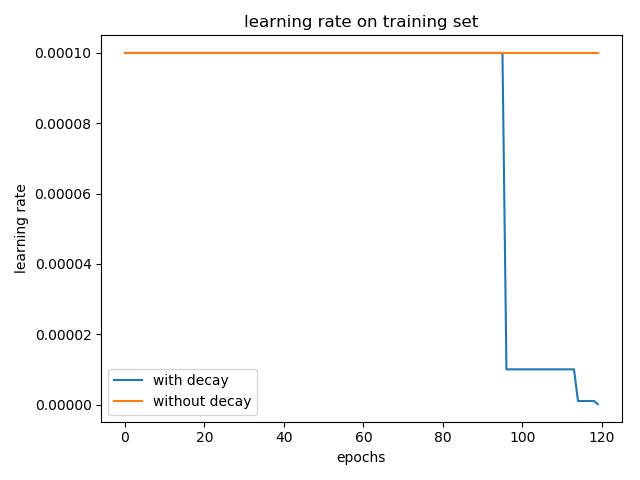
加入学习率衰减和不加两种情况在 test 集合上的 accuracy 分别为: 0.5636 和 0.5688。(三次实验平均,实验结果仍具有偶然性)
这个时候,使用学习率衰减带来的影响可能很小。
那么问题来了,Adam 做不做学习率衰减呢?
我个人会选择做学习率衰减。(仅供参考吧。)在初始学习率设置较大的时候,做学习率衰减比不做要好;而当初始学习率设置就比较小的时候,做学习率衰减似乎有点多余,但从 val set 上的效果看,做了学习率衰减还是可以有丁点提升的。
ReduceLROnPlateau 在 val_loss 正常下降的时候,对学习率是没有影响的,只有在 patience(默认为 10)个 epoch 内,val_loss 都不下降 1e-4 或者直接上升了,这个时候降低学习率确实是可以很明显提升模型训练效果的,在 val_acc 曲线上看到一个快速上升的过程。对于其它类型的学习率衰减,这里没有过多地介绍。
Adam 衰减的学习率
从上述学习率曲线来看,Adam 做学习率衰减,是对 \(\eta\) 进行,而不是对 \(\frac{\eta}{\sqrt{\hat{v}_{t}}+\epsilon}\) 进行,但有区别吗?
学习率衰减一般如下:
exponential_decay:
decayed_learning_rate = learning_rate * decay_rate ^ (global_step / decay_steps)natural_exp_decay:
decayed_learning_rate = learning_rate * exp(-decay_rate * global_step / decay_steps)ReduceLROnPlateau
如果被监控的值(如‘val_loss’)在 patience 个 epoch 内都没有下降,那么学习率衰减,乘以一个 factor
decayed_learning_rate = learning_rate * factor
这些学习率衰减都是直接在原学习率上乘以一个 factor ,对 \(\eta\) 或对 \(\frac{\eta}{\sqrt{\hat{v}_{t}}+\epsilon}\) 操作,结果都是一样的。
References
An overview of gradient descent optimization algorithms -- Sebastian Ruder
Should we do learning rate decay for adam optimizer - Stack Overflow
Tensorflow中learning rate decay的奇技淫巧 -- Elevanth
Adam和学习率衰减(learning learning decay)的更多相关文章
- 权重衰减(weight decay)与学习率衰减(learning rate decay)
本文链接:https://blog.csdn.net/program_developer/article/details/80867468“微信公众号” 1. 权重衰减(weight decay)L2 ...
- 吴恩达深度学习笔记(五) —— 优化算法:Mini-Batch GD、Momentum、RMSprop、Adam、学习率衰减
主要内容: 一.Mini-Batch Gradient descent 二.Momentum 四.RMSprop 五.Adam 六.优化算法性能比较 七.学习率衰减 一.Mini-Batch Grad ...
- 梯度下降法】三:学习率衰减因子(decay)的原理与Python
http://www.41443.com/HTML/Python/20161027/512492.html
- ubuntu之路——day8.5 学习率衰减learning rate decay
在mini-batch梯度下降法中,我们曾经说过因为分割了baby batch,所以迭代是有波动而且不能够精确收敛于最小值的 因此如果我们将学习率α逐渐变小,就可以使得在学习率α较大的时候加快模型训练 ...
- 跟我学算法-吴恩达老师(mini-batchsize,指数加权平均,Momentum 梯度下降法,RMS prop, Adam 优化算法, Learning rate decay)
1.mini-batch size 表示每次都只筛选一部分作为训练的样本,进行训练,遍历一次样本的次数为(样本数/单次样本数目) 当mini-batch size 的数量通常介于1,m 之间 当 ...
- TensorFlow之DNN(二):全连接神经网络的加速技巧(Xavier初始化、Adam、Batch Norm、学习率衰减与梯度截断)
在上一篇博客<TensorFlow之DNN(一):构建“裸机版”全连接神经网络>中,我整理了一个用TensorFlow实现的简单全连接神经网络模型,没有运用加速技巧(小批量梯度下降不算哦) ...
- 改善深层神经网络_优化算法_mini-batch梯度下降、指数加权平均、动量梯度下降、RMSprop、Adam优化、学习率衰减
1.mini-batch梯度下降 在前面学习向量化时,知道了可以将训练样本横向堆叠,形成一个输入矩阵和对应的输出矩阵: 当数据量不是太大时,这样做当然会充分利用向量化的优点,一次训练中就可以将所有训练 ...
- pytorch learning rate decay
关于learning rate decay的问题,pytorch 0.2以上的版本已经提供了torch.optim.lr_scheduler的一些函数来解决这个问题. 我在迭代的时候使用的是下面的方法 ...
- [深度学习] pytorch学习笔记(3)(visdom可视化、正则化、动量、学习率衰减、BN)
一.visdom可视化工具 安装:pip install visdom 启动:命令行直接运行visdom 打开WEB:在浏览器使用http://localhost:8097打开visdom界面 二.使 ...
随机推荐
- WebView 联系(要么button)至 Activity 跳跃在几个方面
第一 ,写一个 JavaScriptinterface 分类.内实现WebView至Activity 页面跳转 public class JavaScriptinterface { Activity ...
- 在Winform或WPF中System.Diagnostics.Process.Start的妙用
原文:在Winform或WPF中System.Diagnostics.Process.Start的妙用 我们经常会遇到在Winform或是WPF中点击链接或按钮打开某个指定的网址, 或者是需要打开电脑 ...
- 使用python3的base64编解码实现字符串的简易加密解密
import base64 copyright = 'Copyright (c) 2012 Doucube Inc. All rights reserved.' def main(): #转成byte ...
- windows常用cmd指令
打开命令行 1.在菜单栏中搜索命令行 2.在文件管理器的Path栏输入cmd,则在当前目录打开命令行 3.Windows+R,输入cmd,回车 ping(网络诊断工具) ping是Windows.Un ...
- C# IDisposable接口的使用
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- WPF Path.Data 后台代码赋值
Path path = new Path(); string sData = "M 250,40 L200,20 L200,60 Z"; var converter = TypeD ...
- Spring 中 CharacterEncodingFilter 失效?
# 问题 Spring 提供了CharcterEncodingFilter,专门解决字符串编码的问题. 诡异的是,在类 AbstractAnnotationConfigDispatcherServle ...
- HTTP协议学习 - 9 Method Definitions
# 前言 官方文档简略翻译.9 不是代表第九篇,而是在 RFC2616 中是第九篇.重要加粗,龟速翻译. # Method 9.3 GET The GET method means retrieve ...
- PHP获得指定日期所在月的第一天和最后一天
function getdays($day){ $firstday = date('Y-m-01',strtotime($day)); $lastday = date('Y-m-d',strtotim ...
- HTTP协议解析(格式和举例十分清楚)
掌握HTTP虽然不是必须的,但是如果你知道它的工作原理,那么在学习JSP开发中的某些知识就可以易如反掌了. 一,HTTP协议详解之URL篇 http(超文本传输协议)是一个基于请求与响应模式的.无状态 ...