etlpy: 并行爬虫和数据清洗工具(开源)
etlpy是python编写的网页数据抓取和清洗工具,核心文件etl.py不超过500行,具备如下特点
- 爬虫和清洗逻辑基于xml定义,不需手工编写
- 基于python生成器,流式处理,对内存无要求
- 内置线程池,支持串行和并行处理
- 内置正则解析,html转义,json转换等数据清洗功能,直接输出可用文件
- 插件式设计,能够非常方便地增加其他文件和数据库格式
- 能够支持几乎一切网站,能自动填入cookie
github地址: https://github.com/ferventdesert/etlpy, 欢迎star!
运行需要python3和lxml, 使用pip3 install lxml即可安装。内置的工程project.xml,包含了链家和大众点评两个爬虫的配置示例。
etlpy具有鲜明的函数式风格特征,使用了大量的动态类型,惰性求值,生成器和流式计算。
另外,github上有一个项目,里面有各种500行左右的代码实现的系统,看了几个非常赞https://github.com/aosabook/500lines
二.如何使用
当从网页和文件中抓取和处理数据时,我们总会被复杂的细节,比如编码,奇怪的Html和异步ajax请求所困扰。etlpy能够方便地处理这些问题。
etlpy的使用非常简单,先加载工程,之后即可返回一个生成器,返回所需数量即可。下面的代码,能够在20分钟内,获取大众点评网站上海的全部美食列表,总共16万条,30MB.
import etl;
etl.LoadProject('project.xml');
tool = etl.modules['大众点评门店'];
datas = tool.QueryDatas()
for r in datas:
print(r)
结果如下:
{'区域': '川沙', '标题': '胖哥俩肉蟹煲(川沙店)', '区县': '', '地址': '川沙镇川沙路5558弄绿地广场三号楼', '环境': '9.0', '介绍': '', '类型': '其他', '总店': '胖哥俩肉蟹煲', 'ID': '/shop/19815141', '口味': '9.1', '星级': '五星商户', '总店id': '19815141', '点评': '2205', '其他': '订座:本店支持在线订座', '均价': 67, '服务': '8.9'}
{'区域': '金杨地区', '标题': '上海小南国(金桥店)', '区县': '', '地址': '张杨路3611弄金桥国际商业广场6座2楼', '环境': '8.8', '类型': '本帮江浙菜', 'ID': '/shop/3525763', '口味': '8.6', '星级': '准五星商户', '点评': '1973', '其他': '', '均价': 190, '服务': '8.5'}
{'区域': '临沂/南码头', '标题': '新弘声酒家(临沂路店)', '区县': '', '地址': '临沂路8弄42号', '环境': '8.7', '介绍': '新弘声酒家!仅售85元!价值100元的午市代金券1份,全场通用,可叠加使用。', '类型': '本帮江浙菜', '总店': '新弘声酒家', 'ID': '/shop/19128637', '口味': '9.0', '星级': '五星商户', '总店id': '19128637', '点评': '621', '其他': '团购:新弘声酒家!仅售85元!价值100元的午市代金券1份,全场通用,可叠加使用。', '均价': 87, '服务': '8.8'}
{'区域': '张江', '标题': '阿拉人家上海菜(浦东长泰广场店)', '区县': '', '地址': '祖冲之路1239弄1号长泰广场10号楼203', '环境': '8.9', '介绍': '仅售42元,价值50元代金券', '类型': '本帮江浙菜', '总店': '阿拉人家上海菜', 'ID': '/shop/21994899', '口味': '8.8', '星级': '准五星商户', '总店id': '21994899', '点评': '1165', '其他': '团购:仅售42元,价值50元代金券', '均价': 113, '服务': '8.8'}
当然,以上方法是串行执行,你也可以选择并行执行以获取更快的速度:
tool.mThreadExecute(threadcount=20,execute=False,callback=lambda d:print(d))
可设置线程数,对获取的每个数据的回调方法,以及是否执行其中的执行器(下文有解释)。
etlpy的执行逻辑基于xml文件,不建议手工编写xml,而是使用笔者开发的另一款图形化爬虫工具,可以通过图形拖拽的方式设计并生成工程文件,这套工具也即将开源,因为暂时还没想到较好的名字。基于C#/WPF开发,通过这套工具,十分钟内就能完成大众点评的采集程序的编写,如果手工编码,一个熟练的python程序员可能得写一天。该工具生成的xml,即可被etlpy解析,生成跨平台的多线程爬虫。
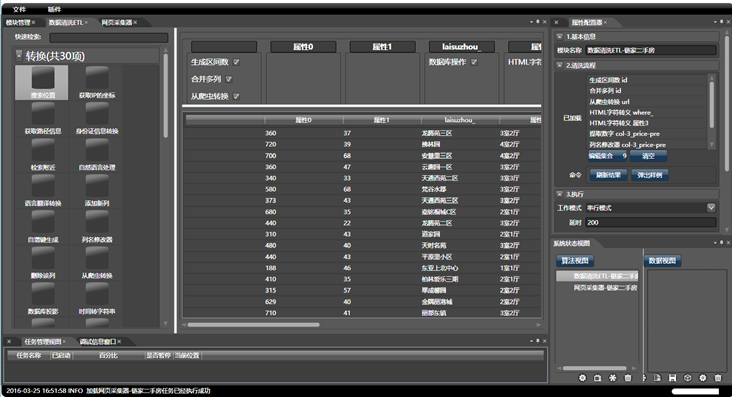
你可以选择手工修改xml,或是在代码中直接修改,来采集不同城市,或是输出到不同的文件:
tool.AllETLTools[0].arglists=[''] #修改城市,1为上海,2为北京,参考大众点评的网页定义
tool.AllETLTools[-1].NewTableName= 'D:\大众点评.txt' #修改导出的文件
三.原理
我们将每一步骤定义为独立的模块,将其串成一条链条(我们称之为流)。如下图所示:
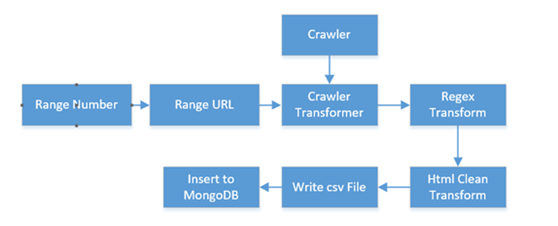
C#版本原理
鉴于博客园不少读者熟悉C#,我们不妨先用C#的例子来讲解:
其本质是动态组装Linq, 其数据链为IEnumerable<IFreeDocument>。 IFreeDocument是 IDictionary<string, object>接口的扩展。Linq的Select函数能够对流进行变换,在本例中,就是对字典不同列的操作(增删改),不同的模块定义了一个完整的Linq流:
result= source.Take(mount).where(d=>module0.func(d)).select(d=>Module1.func(d)).select(d=>Module2.func(d))….
Python版本原理
python的生成器类似于C#的Linq,是一种流式迭代。etlpy对生成器做了扩展,实现了生成器级联,并联和交叉(笛卡尔积)
def Append(a, b):
for r in a:
yield r;
for r in b:
yield r; def Cross(a, genefunc, tool):
for r1 in a:
for r2 in genefunc(tool, r1):
for key in r1:
r2[key] = r1[key]
yield r2;
那么,生成器生成的是什么呢?我们选用了Python的字典,这种键值对的结构很好用。可以将所有的模块分为四种类型:
生成器(GE):如生成100个字典,键为1-100,值为‘1’到‘100’
转换器(TF):如将地址列中的数字提取到电话列中
过滤器(FT):如过滤所有某一列的值为空的的字典
执行器(GE):如将所有的字典存储到MongoDB中。
我们如何将这些模块组合成完整链条呢?由于Python没有Linq,我们通过组合生成器来获取新的生成器,这个函数定义如下:
def __generate__(self, tools, generator=None, execute=False):
for tool in tools:
if tool.Group == 'Generator':
if generator is None:
generator = tool.Func(tool, None);
else:
if tool.MergeType == 'Append':
generator = extends.Append(generator, tool.Func(tool, None));
elif tool.MergeType == 'Merge':
generator = extends.MergeAll(generator, tool.Func(tool, None));
elif tool.MergeType == 'Cross':
generator = extends.Cross(generator, tool.Func, tool)
elif tool.Group == 'Transformer':
generator = transform(tool, generator);
elif tool.Group == 'Filter':
generator = filter(tool, generator);
elif tool.Group == 'Executor' and execute:
generator = tool.Func(tool, generator);
return generator;
如何定义模块呢?如果是先定义基类,然后从基类继承,这种方式依然要写大量的代码,而且不够Pythonic(我C#版本的代码就是这样写的)。
以清除字符串中前后空白的字符为例(C#中的trim, Python中的strip),我们能够定义这样的函数:
def TrimTF(etl, data):
return data.strip();
之后,通过读取配置文件,运行时动态地为一个基础对象添加属性和方法,从一个简单的TrimTF函数,生成一个具备同样功能的类。 整个etlpy的编写思路,就是从函数生成类,再最后将类的对象(模块)组合成流。
至于爬虫获取HTML正文的信息,则使用了XPath,而非正则表达式,当然你也可以使用正则。XPath也是自动生成的,具体的原理将在之后的博文中讲解。etlpy本质上是重新定义了抓取和清洗的原语,是一种新的语言(DSL),从而大大降低了编写这类应用的成本和复杂度。
(串行模式的QueryDatas函数,有一个etlcount的可选参数,你可以分别将其值设为从1到n,观察数据是如何被一步步地组合出来的)
三.例子
采集链家
先以抓取链家地产为例,我们来讲解这种流的强大:如何采集所有二手房数据呢?这涉及到翻页。

翻页时,我们会看到页面是这样变换的:
http://bj.lianjia.com/ershoufang/pg2/
http://bj.lianjia.com/ershoufang/pg3/
…
因此,需要构造一串上面的url. 聪明的你肯定会想到,应当先生成一组序列,从1到100(假设我们只抓取前100页)。
再通过MergeTF函数,从1-100生成上面的url列表。现在总共是100个url.
再通过爬虫转换器CrawlerTF,每个页面能够生成30个二手房信息,因此能够生成100*30个页面,但由于是基于流的,所以这3000个信息是不断yield出来的,每生成一个,后续的流程,如去除乱码,提取数字,保存到文件,都会执行。这样我们就获取了所有的信息。
不同的流,可以组合为更高级的流。例如,想要获取所有房地产的数据,可以分别定义链家,我爱我家等地产公司的流,再通过流将多个流拼接起来。
采集大众点评
大众点评的采集难度更大,每种门类只能翻到第50页,因此想要获取全部数据就必须想办法。
以北京美食为例,如果按不同美食的门类(咖啡厅,火锅,小吃…)和区域(海淀,西城,东城…)区分,美食页面就没有五十页了。所以,首先生成北京所有区域的流(project中“大众点评区域”,感兴趣的读者可以试着获取这个流看看),再生成所有美食门类的流(大众点评门类)。然后再将这两个流做交叉(m*n),再组合获取了每个种类的url, 通过url获取页面,再通过XPath获取对应门类的门店数量:
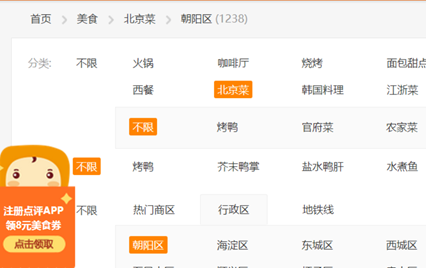
上文中的1238,也就是朝阳区的北京菜总共有1238家。
再通过python脚本计算要翻的页数,因为每页15个,那么有int(1238/15.0)+1页,记作q。 总共要抓取的页面数量,是一个(m,n,q)的异构立方体,不同的(m,n)都对应不同的q。 之后,就可以用类似于链家的方法,抓取所有页面了。
四.优化和细节
为了保证讲解的简单,我省略了大量实现的细节,其实在其中做了很多的优化。
1. 修改流,获取不同城市的信息
还以大众点评为例,我们希望只修改一个模块,就能切换北京,上海等美食的信息。
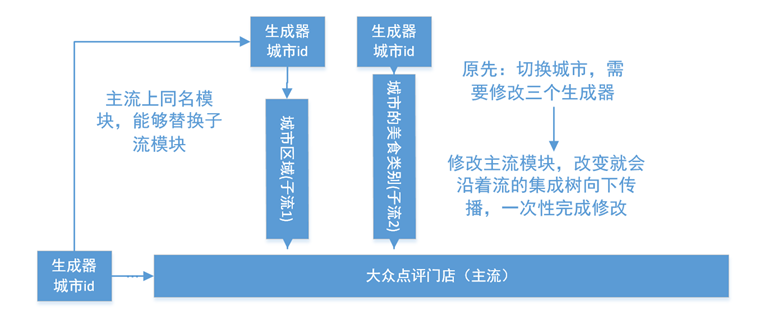
北京和上海的美食门类和区域列表都不一样,所以两个子流的队首的生成器,定义了城市的id。如果想修改城市,需要修改三个生成器。这太麻烦了,因此,etlpy采用了动态替换的方法。 如果主流中定义了与子流中同名的模块,只要修改了主流,主流就可以对子流完成修改。
2. 并行优化
最简单的并行化,应该从流的源头开始:
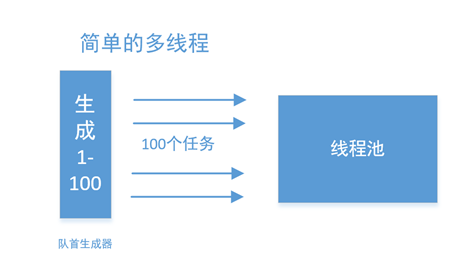
但如果队首只有一个元素,那么这种方法就非常低下了:
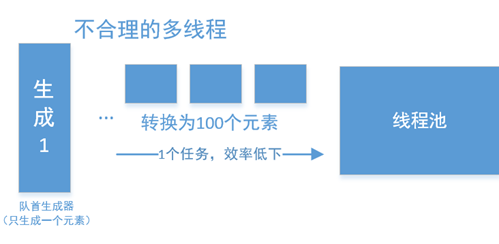
一种非常简单的思路,是将其切成两个流,并行在流中完成。
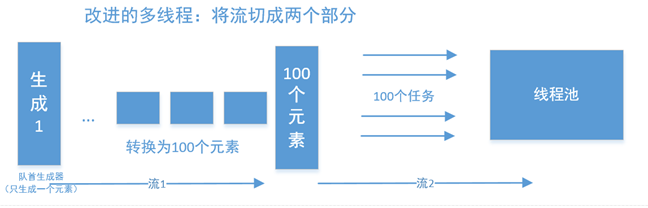
以大众点评为例, 北京有14个区县,有30种美食类型,那么先通过流1,获取420个元素,再以420个元素的基础上,进行并行,这样速度就快很多了。你也可以在14个区县之后插入并行化,那么就有14个子任务。etlpy通过一个ToListTF模块(它什么都不干)作为标识,作为流1和流2的分割符。
4.一些参数的说明
OneInput=True说明函数只需要字典中的一个值,此时传到函数里的只有dict[key],否则传递整个dict
OneOutput=True说明函数可能输出多个值,因此函数直接修改dict并返回null, 否则返回一个value,etlpy在函数外部修改dict.
IsMultiYield=True说明函数会返回生成器。
其他参数可具体参考python代码。
五.展望
使用xml作为工程的配置文件有显然的好处,因为能够被各种语言方便地读取,但是噪音太多,不易手工编写,如果能设计一个专用的数据清洗语言,那么应该会好很多。其实用图形化编程,效率会特别高。
etlpy的思想,来自于讲解Lisp的一本书《计算机程序的构造与解释》(SICP),书评在此:Lisp和SICP
可视化软件会在一个月内全部开源,解放程序员的大脑和双手,号称爬虫的终极武器。敬请期待。
有任何问题,欢迎留言交流,或在Github中讨论。
etlpy: 并行爬虫和数据清洗工具(开源)的更多相关文章
- day01_爬虫和数据
1.什么是爬虫 1.1.爬虫的定义 脚本,程序--->自动抓取万维网上信息的程序. 1.2.爬虫的分类 2.1.通用爬虫 通用网络爬虫 是 捜索引擎抓取系统(Baidu.Google ...
- 爬虫爬数据时,post数据乱码解决办法
最近在写一个爬虫,目标网站是:http://zx.bjmemc.com.cn/,可能是为了防止被爬取数据,它给自身数据加了密.用谷歌自带的抓包工具也不能捕获到数据.于是下了Fiddler. F ...
- python实现并行爬虫
问题背景:指定爬虫depth.线程数, python实现并行爬虫 思路: 单线程 实现爬虫类Fetcher 多线程 threading.Thread去调Fet ...
- python 爬虫与数据可视化--python基础知识
摘要:偶然机会接触到python语音,感觉语法简单.功能强大,刚好朋友分享了一个网课<python 爬虫与数据可视化>,于是在工作与闲暇时间学习起来,并做如下课程笔记整理,整体大概分为4个 ...
- crawler4j多线程爬虫统计分析数据
该事例演示了如何在多线程中统计和分析数据: 首先建一个状态实体类CrawlStat: package com.demo.collectingData; /** * 爬虫状态实体类 统计爬虫信息 * @ ...
- 爬虫爬数据时,post数据乱码解决的方法
近期在写一个爬虫,目标站点是:http://zx.bjmemc.com.cn/.可能是为了防止被爬取数据,它给自身数据加了密. 用谷歌自带的抓包工具也不能捕获到数据. 于是下了Fiddler. ...
- 在我的新书里,尝试着用股票案例讲述Python爬虫大数据可视化等知识
我的新书,<基于股票大数据分析的Python入门实战>,预计将于2019年底在清华出版社出版. 如果大家对大数据分析有兴趣,又想学习Python,这本书是一本不错的选择.从知识体系上来看, ...
- python爬虫---爬虫的数据解析的流程和解析数据的几种方式
python爬虫---爬虫的数据解析的流程和解析数据的几种方式 一丶爬虫数据解析 概念:将一整张页面中的局部数据进行提取/解析 作用:用来实现聚焦爬虫的吧 实现方式: 正则 (针对字符串) bs4 x ...
- 从python爬虫以及数据可视化的角度来为大家呈现“227事件”后,肖战粉丝的数据图
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取t.cn ...
随机推荐
- Salesforce学习笔记(一)
Force平台简介 一.Force平台应用程序的优点1.以数据为中心的应用程序(一个对象就是一个数据库表) 由于该平台以数据库为中心,它让你能够编写以数据为中心的应用程序.以数据为中心的应用程序是基于 ...
- rinetd
1.安装 tar zxvf rinetd.tar.gz make make install 2.设置 vi /etc/rinetd.conf 0.0.0.0 8080 172.19.94. ...
- 最长下降子序列O(n^2)及O(n*log(n))解法
求最长下降子序列和LIS基本思路是完全一样的,都是很经典的DP题目. 问题大都类似于 有一个序列 a1,a2,a3...ak..an,求其最长下降子序列(或者求其最长不下降子序列)的长度. 以最长下降 ...
- *HDU3398 数学
String Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Subm ...
- JavaScript鼠标经过图片的放大镜效果
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- JeeSite学习笔记~代码生成原理
1.建立数据模型[单表,一对多表,树状结构表] 用ERMaster建立数据模型,并设定对应表,建立关联关系 2.系统获取对应表原理 1.怎样获取数据库的表 genTableForm.jsp: < ...
- DataTable转List(备忘)
public static List ToList(DataTable dt) { List<Dictionary<string, object>> list = new Li ...
- JS 怎么控制某个div的滚动条滚动到顶部? (已解决)
获取这个元素,然后设置它的滚动条的位置为初始位置(0,0). document.getElementById(..).scrollTop = 0;
- 用字符流实现每个文件夹中创建包含所有文件信息的readme.txt
package com.readme; import java.io.BufferedWriter; import java.io.File; import java.io.FileWriter; i ...
- 【实战Java高并发程序设计 4】数组也能无锁:AtomicIntegerArray
除了提供基本数据类型外,JDK还为我们准备了数组等复合结构.当前可用的原子数组有:AtomicIntegerArray.AtomicLongArray和AtomicReferenceArray,分别表 ...