LinkedHashMap和hashMap和TreeMap的区别
推荐博客:https://www.jianshu.com/p/8f4f58b4b8ab
区别:
- LinkedHashMap是继承于HashMap,是基于HashMap和双向链表来实现的。
- HashMap无序;LinkedHashMap有序,可分为插入顺序和访问顺序两种。如果是访问顺序,那put和get操作已存在的Entry时,都会把Entry移动到双向链表的表尾(其实是先删除再插入)。
- LinkedHashMap存取数据,还是跟HashMap一样使用的Entry[]的方式,双向链表只是为了保证顺序。
- LinkedHashMap是线程不安全的。
LinkedHashMap应用场景
HashMap是无序的,当我们希望有顺序地去存储key-value时,就需要使用LinkedHashMap了。
Map<String, String> hashMap = new HashMap<String, String>();
hashMap.put("name1", "josan1");
hashMap.put("name2", "josan2");
hashMap.put("name3", "josan3");
Set<Entry<String, String>> set = hashMap.entrySet();
Iterator<Entry<String, String>> iterator = set.iterator();
while(iterator.hasNext()) {
Entry entry = iterator.next();
String key = (String) entry.getKey();
String value = (String) entry.getValue();
System.out.println("key:" + key + ",value:" + value);
}
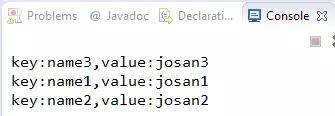
我们是按照xxx1、xxx2、xxx3的顺序插入的,但是输出结果并不是按照顺序的。
同样的数据,我们再试试LinkedHashMap
Map<String, String> linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("name1", "josan1");
linkedHashMap.put("name2", "josan2");
linkedHashMap.put("name3", "josan3");
Set<Entry<String, String>> set = linkedHashMap.entrySet();
Iterator<Entry<String, String>> iterator = set.iterator();
while(iterator.hasNext()) {
Entry entry = iterator.next();
String key = (String) entry.getKey();
String value = (String) entry.getValue();
System.out.println("key:" + key + ",value:" + value);
}
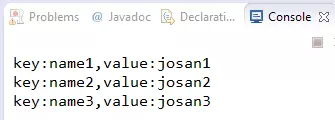
结果可知,LinkedHashMap是有序的,且默认为插入顺序。
插入顺序和访问顺序。
LinkedHashMap默认的构造参数是默认 插入顺序的,就是说你插入的是什么顺序,读出来的就是什么顺序,但是也有访问顺序,就是说你访问了一个key,这个key就跑到了最后面
// 第三个参数用于指定accessOrder值
Map<String, String> linkedHashMap = new LinkedHashMap<>(16, 0.75f, true);
linkedHashMap.put("name1", "josan1");
linkedHashMap.put("name2", "josan2");
linkedHashMap.put("name3", "josan3");
System.out.println("开始时顺序:");
Set<Entry<String, String>> set = linkedHashMap.entrySet();
Iterator<Entry<String, String>> iterator = set.iterator();
while(iterator.hasNext()) {
Entry entry = iterator.next();
String key = (String) entry.getKey();
String value = (String) entry.getValue();
System.out.println("key:" + key + ",value:" + value);
}
System.out.println("通过get方法,导致key为name1对应的Entry到表尾");
linkedHashMap.get("name1");
Set<Entry<String, String>> set2 = linkedHashMap.entrySet();
Iterator<Entry<String, String>> iterator2 = set2.iterator();
while(iterator2.hasNext()) {
Entry entry = iterator2.next();
String key = (String) entry.getKey();
String value = (String) entry.getValue();
System.out.println("key:" + key + ",value:" + value);
}
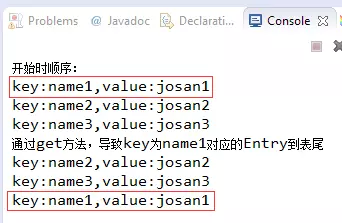
因为调用了get("name1")导致了name1对应的Entry移动到了最后,这里只要知道LinkedHashMap有插入顺序和访问顺序两种就可以
TreeMap的用法(主要是排序)
TreeMap中默认的排序为升序,如果要改变其排序可以自己写一个Comparator
import java.util.Comparator;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeMap; public class Compare {
public static void main(String[] args) {
TreeMap<String,Integer> map = new TreeMap<String,Integer>(new xbComparator());
map.put("key_1", 1);
map.put("key_2", 2);
map.put("key_3", 3);
Set<String> keys = map.keySet();
Iterator<String> iter = keys.iterator();
while(iter.hasNext())
{
String key = iter.next();
System.out.println(" "+key+":"+map.get(key));
}
}
}
class xbComparator implements Comparator
{
public int compare(Object o1,Object o2)
{
String i1=(String)o1;
String i2=(String)o2;
return -i1.compareTo(i2);
}
}

LinkedHashMap和hashMap和TreeMap的区别的更多相关文章
- HashMap与TreeMap的区别?
HashMap与TreeMap的区别? 解答:HashMap通过hashcode对其内容进行快速查找,而TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用Tre ...
- java面试题之HashMap和TreeMap的区别
HashMap和TreeMap的区别 相同点: 都是以key和value的形式存储: key不可以重复: 都是线程不安全的: 不同点: HashMap的key可以为空 TreeMap的key值是有序的 ...
- HashMap和TreeMap的区别
HashMap:数组方式存储key/value,线程非安全,允许null作为key和value,key不可以 重复,value允许重复,不保证元素迭代顺序是按照插入时的顺序,key的hash值是先计算 ...
- HashMap与TreeMap的区别
首先描述下什么是Map. 在数组中我们是通过数组的下标来对其内容进行索引的,而在Map中我们是通过对象对对象进行索引的,用来索引的对象叫做key,其对应的对象叫做value.这就是我们平常说的键值对. ...
- Java中HashMap和TreeMap的区别深入理解
首先介绍一下什么是Map.在数组中我们是通过数组下标来对其内容索引的,而在Map中我们通过对象来对对象进行索引,用来索引的对象叫做key,其对应的对象叫做value.这就是我们平时说的键值对. Has ...
- Java中HashMap和TreeMap的区别
什么是Map集合在数组中我们是通过数组下标来对其内容索引的,而在Map中我们通过对象来对对象进行索引,用来索引的对象叫做key,其对应的对象叫做value.这就是我们平时说的键值对. HashMap ...
- Java 中HashTable、HashMap、TreeMap三者区别,以及自定义对象是否相同比较,自定义排序等
/* Map集合:该集合存储键值对.一对一对往里存.而且要保证键的唯一性. Map |--Hashtable:底层是哈希表数据结构,不可以存入null键null值.该集合是线程同步的.效率低.基本已废 ...
- Java中HashMap,LinkedHashMap,TreeMap的区别[转]
原文:http://blog.csdn.net/xiyuan1999/article/details/6198394 java为数据结构中的映射定义了一个接口java.util.Map;它有四个实现类 ...
- HashMap,LinkedHashMap,TreeMap的区别(转)
Map主要用于存储健值对,根据键得到值,因此不允许键重复(重复了覆盖了),但允许值重复.Hashmap 是一个最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快 ...
随机推荐
- python内建函数和工厂函数的整理
内建函数参阅: https://www.cnblogs.com/pyyu/p/6702896.html 工厂函数: 本篇博文比较粗糙,后续会深入整理
- SpringBoot整合Gson(转)
第一步:移除jackson依赖 参考代码 <dependency> <groupId>org.springframework.boot</groupId> < ...
- SIGAI机器学习第二十二集 AdaBoost算法3
讲授Boosting算法的原理,AdaBoost算法的基本概念,训练算法,与随机森林的比较,训练误差分析,广义加法模型,指数损失函数,训练算法的推导,弱分类器的选择,样本权重削减,实际应用. AdaB ...
- Linux命令:awk求和、平均值、最大最小值
本文链接:https://blog.csdn.net/wyqwilliam/article/details/825600431.求和cat data|awk '{sum+=$1} END {print ...
- 06.volatile关键字
volatile volatile关键字的主要作用是使变量在多个线程间可见 使用方法: private volatile int number=0; 图示: 两个线程t1和t2共享一份数据,int a ...
- asp.net实现大文件上传分片上传断点续传
HTML部分 <%@ Page Language="C#" AutoEventWireup="true" CodeBehind="index.a ...
- UVA 1613 K度图染色
题目 \(dfs+\)证明. 对于题目描述,可以发现\(K\)其实就是大于等于原图中最大度数的最小奇数,因为如果原图度数最大为奇数,则最多颜色肯定为K,而如果原图最大度数为偶数,则\(K\)又是奇数, ...
- [mysql8]新坑哈 更改Mysql 表的大小转换设置lower_case_table_names=1
在安装了8.0.14之后,初始化的时候在my.cnf里设置了lower_case_table_names=1,安装好了之后,启动报错: 1 2 3 4 5 2019-01-28T13:24:24.91 ...
- warning insecure world writable dir ruby mode 040777,gem insstal sass error failed to build gem native extension
//1.删除原gem源 gem sources --remove https://rubygems.org/ //2.添加国内镜像 gem source -a https://gems.ruby-ch ...
- 2019.11.11 模拟赛 T2 乘积求和
昨天 ych 的膜你赛,这道题我 O ( n4 ) 暴力拿了 60 pts. 这道题的做法还挺妙的,我搞了将近一天呢qwq 题解 60 pts 根据题目给出的式子,四层 for 循环暴力枚举统计答案即 ...