Hadoop 系列(五)—— Hadoop 集群环境搭建
一、集群规划
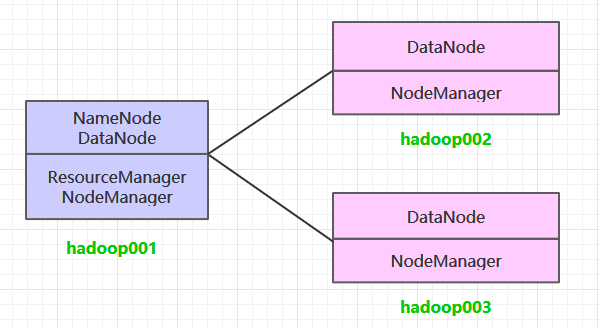
这里搭建一个 3 节点的 Hadoop 集群,其中三台主机均部署 DataNode 和 NodeManager 服务,但只有 hadoop001 上部署 NameNode 和 ResourceManager 服务。
二、前置条件
Hadoop 的运行依赖 JDK,需要预先安装。其安装步骤单独整理至:
三、配置免密登录
3.1 生成密匙
在每台主机上使用 ssh-keygen 命令生成公钥私钥对:
ssh-keygen3.2 免密登录
将 hadoop001 的公钥写到本机和远程机器的 ~/ .ssh/authorized_key 文件中:
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop001
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop002
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop0033.3 验证免密登录
ssh hadoop002
ssh hadoop003四、集群搭建
3.1 下载并解压
下载 Hadoop。这里我下载的是 CDH 版本 Hadoop,下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
# tar -zvxf hadoop-2.6.0-cdh5.15.2.tar.gz 3.2 配置环境变量
编辑 profile 文件:
# vim /etc/profile增加如下配置:
export HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
export PATH=${HADOOP_HOME}/bin:$PATH执行 source 命令,使得配置立即生效:
# source /etc/profile3.3 修改配置
进入 ${HADOOP_HOME}/etc/hadoop 目录下,修改配置文件。各个配置文件内容如下:
1. hadoop-env.sh
# 指定JDK的安装位置
export JAVA_HOME=/usr/java/jdk1.8.0_201/2. core-site.xml
<configuration>
<property>
<!--指定 namenode 的 hdfs 协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<!--指定 hadoop 集群存储临时文件的目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>3. hdfs-site.xml
<property>
<!--namenode 节点数据(即元数据)的存放位置,可以指定多个目录实现容错,多个目录用逗号分隔-->
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/namenode/data</value>
</property>
<property>
<!--datanode 节点数据(即数据块)的存放位置-->
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/datanode/data</value>
</property>4. yarn-site.xml
<configuration>
<property>
<!--配置 NodeManager 上运行的附属服务。需要配置成 mapreduce_shuffle 后才可以在 Yarn 上运行 MapReduce 程序。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--resourcemanager 的主机名-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop001</value>
</property>
</configuration>
5. mapred-site.xml
<configuration>
<property>
<!--指定 mapreduce 作业运行在 yarn 上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>5. slaves
配置所有从属节点的主机名或 IP 地址,每行一个。所有从属节点上的 DataNode 服务和 NodeManager 服务都会被启动。
hadoop001
hadoop002
hadoop0033.4 分发程序
将 Hadoop 安装包分发到其他两台服务器,分发后建议在这两台服务器上也配置一下 Hadoop 的环境变量。
# 将安装包分发到hadoop002
scp -r /usr/app/hadoop-2.6.0-cdh5.15.2/ hadoop002:/usr/app/
# 将安装包分发到hadoop003
scp -r /usr/app/hadoop-2.6.0-cdh5.15.2/ hadoop003:/usr/app/3.5 初始化
在 Hadoop001 上执行 namenode 初始化命令:
hdfs namenode -format3.6 启动集群
进入到 Hadoop001 的 ${HADOOP_HOME}/sbin 目录下,启动 Hadoop。此时 hadoop002 和 hadoop003 上的相关服务也会被启动:
# 启动dfs服务
start-dfs.sh
# 启动yarn服务
start-yarn.sh3.7 查看集群
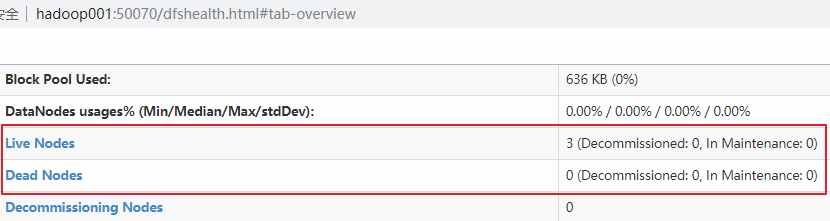
在每台服务器上使用 jps 命令查看服务进程,或直接进入 Web-UI 界面进行查看,端口为 50070。可以看到此时有三个可用的 Datanode:
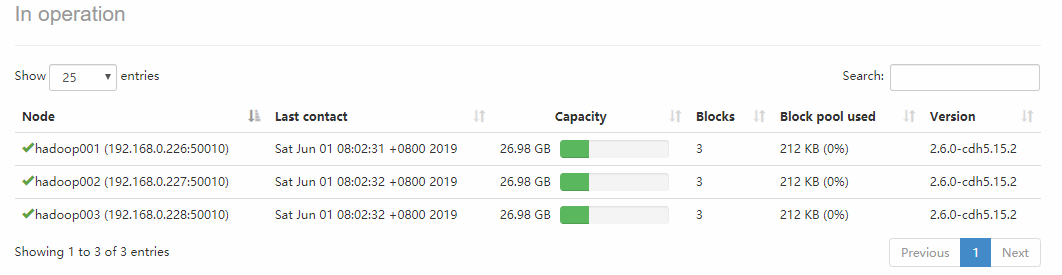
点击 Live Nodes 进入,可以看到每个 DataNode 的详细情况:
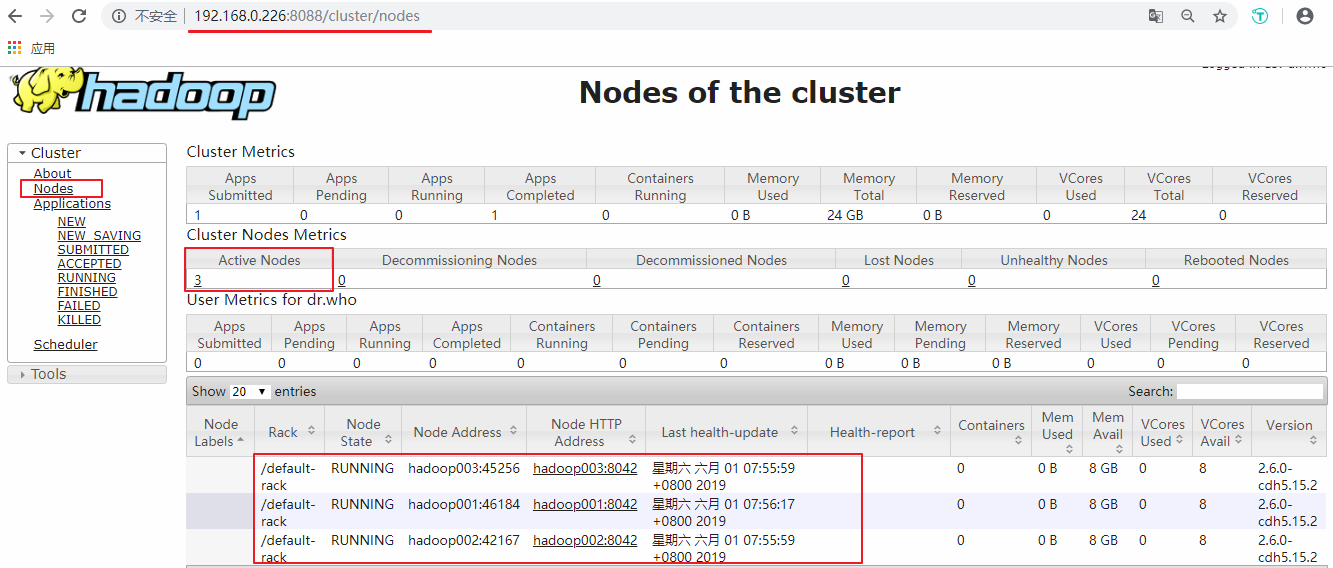
接着可以查看 Yarn 的情况,端口号为 8088 :
五、提交服务到集群
提交作业到集群的方式和单机环境完全一致,这里以提交 Hadoop 内置的计算 Pi 的示例程序为例,在任何一个节点上执行都可以,命令如下:
hadoop jar /usr/app/hadoop-2.6.0-cdh5.15.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.15.2.jar pi 3 3更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Hadoop 系列(五)—— Hadoop 集群环境搭建的更多相关文章
- Hadoop+HBase+ZooKeeper分布式集群环境搭建
一.环境说明 集群环境至少需要3个节点(也就是3台服务器设备):1个Master,2个Slave,节点之间局域网连接,可以相互ping通,下面举例说明,配置节点IP分配如下: Hostname IP ...
- 大数据hadoop入门学习之集群环境搭建集合
目录: 1.基本工作准备 1.虚拟机准备 2.java 虚拟机-jdk环境配置 3.ssh无密码登录 2.hadoop的安装与配置 3.hbase安装与配置(集成安装zookeeper) 4.zook ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- Hadoop完全分布式集群环境搭建
1. 在Apache官网下载Hadoop 下载地址:http://hadoop.apache.org/releases.html 选择对应版本的二进制文件进行下载 2.解压配置 以hadoop-2.6 ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
随机推荐
- HTML页面之间的参数传递
HTML 与 HTML 的跳转中如何在HTML之中实现参数的传递?主要代码如下:request为方法名称,params 为要获取的参数. function request(params) { var ...
- D3.js的v5版本入门教程(第十三章)—— 饼状图
D3.js的v5版本入门教程(第十三章) 这一章我们来绘制一个简单的饼状图,我们只绘制构成饼状图基本的元素——扇形.文字,从这一章开始,内容可能有点难理解,因为每一章都会引入比较多的难理解知识点,在这 ...
- 百度编辑器(ueditor)踩坑,图片转存无法使用
在使用 百度编辑器 的过程中碰到了一些问题,图片转存功能无法使用, 即便是疯狂地在官方 Demo.文档.论坛甚至是 GitHub 上也没找到理想的答案.(┗|`O′|┛) (真是日了狗) 问题描述 默 ...
- python 操作redis,存取为字节格式,避免转码加
这种情况连接数据库,对数据的存取都是字节类型,存取时还得转码一下 from redis import Redis # 实例化redis对象 rdb = Redis(host='localhost', ...
- SpringCloud Feign 常用代码
服务提供者 服务提供者,是位于其他项目里面的. 服务提供者提供的方法,在Controller层里面,有可访问的Url. @Controller @RequestMapping("/order ...
- NoSql数据库Redis系列(6)——Redis数据过期策略详解
本文对Redis的过期机制简单的讲解一下 讲解之前我们先抛出一个问题,我们知道很多时候服务器经常会用到redis作为缓存,有很多数据都是临时缓存一下,可能用过之后很久都不会再用到了(比如暂存sessi ...
- 2019_软工实践_Beta(3/5)
队名:955 组长博客:点这里! 作业博客:点这里! 组员情况 组员1(组长):庄锡荣 过去两天完成了哪些任务 文字/口头描述 ? 维持进度,检查需求 展示GitHub当日代码/文档签入记录 接下来的 ...
- 第10组 Beta冲刺(1/5)
链接部分 队名:女生都队 组长博客: 博客链接 作业博客:博客链接 小组内容 恩泽(组长) 过去两天完成了哪些任务 描述 tomcat的学习与实现 服务器后端部署,API接口的beta版实现 后端代码 ...
- 单细胞数据normalization方法 | SCTransform
SCTransform Normalization and variance stabilization of single-cell RNA-seq data using regularized n ...
- 【mybatis源码学习】mybatis的反射模块
一.重要的类和接口 org.apache.ibatis.reflection.MetaClass//对于javaBean的calss类进行反射操作的代理类(获取属性的类型,获取属性的get,set方法 ...