day16_7.18 常用模块
一。collections
collections模块中提供了除了dict,list,str等数据类型之外的其他数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
1.namedtuple具名元组
普通的元组不具有描述自己定义的数据的功能,而具名元组定义了一个可以描述元组的数据类型:
from collections import namedtuple
point = namedtuple('坐标',['x','y','z'])
p = point(1,2,5)
print(p)
print(type(p))
print(p.x)
print(p.y)
print(p.z)
#输出结果>>>坐标(x=1, y=2, z=5)
#<class '__main__.坐标'>
#
#
#
导入模块后,可以使用namedtuple调用函数,namedtuple可以传入两个参数,第一个是对元组的描述,第二个是可迭代对象,所以,除了列表,还可以写成这样:
point = namedtuple('坐标','x y z')
注意,参数与参数之间需要使用空格隔开。
定义好一个具名元组后,就可以对其进行传参了,传入的参数要与可迭代中的元素一样。
2.deque
补充:queue队列模块
# import queue
# q = queue.Queue()
# q.put('first')
# q.put('second')
# q.put('third')
# print(q.get())
# print(q.get())
# print(q.get())
# print(q.get())
#输出结果>>>first
#second
#third
使用queue模块创建一个队列q,再使用put方法对其传值,使用get对其取值,当值被取完时继续调用get方法,等待列表给值。
deque双端队列,是一个两边都可以取值和传值的队列。
from collections import deque
q = deque(['a','b','c'])
q.append('x')
print(q)
q.appendleft('y')
print(q)
q.pop()
print(q)
q.popleft()
print(q)
#输出结果>>>deque(['a', 'b', 'c', 'x'])
#deque(['y', 'a', 'b', 'c', 'x'])
#deque(['y', 'a', 'b', 'c'])
#deque(['a', 'b', 'c'])
在deque中可以使用append和appendleft对队列进行左右 的加值,pop和popleft对其进行左右的删值。deque传值是传可迭代对象。
在双端队列中可以使用insert对其进行索引取值,这是deque不合理的地方。
3.Ordereddict有序字典
在正常定义一个字典时,产生的字典是无序的,而使用ordereddict产生的字典是有序的。有序字典的定义方式是:
order_d = OrderedDict([('a',1),('b',2),('c',3)])
其输出也是这个,并不会以无序字典的方式打印,或者
order_d1 = OrderedDict()
order_d1['x'] = 1
order_d1['y'] = 2
order_d1['z'] = 3
print(order_d1)
for i in order_d1:
print(i)
print(order_d1)
这个字典是可以使用for循环遍历取值的。使用keys()对其进行取值时会按照插入顺序,而不是key本身的顺序。
4.defaultdict默认字典
当你需要把列表中的值进行判断大小(66),,并对其值放入字典中,字典的value是一个列表,不用defaultdict可以使用如下办法。
values = [11, 22, 33,44,55,66,77,88,99,90]
my_dict = {}
for value in values:
if value>66:
if my_dict.has_key('k1'):
my_dict['k1'].append(value)
else:
my_dict['k1'] = [value]
else:
if my_dict.has_key('k2'):
my_dict['k2'].append(value)
else:
my_dict['k2'] = [value]
而使用了defaultdict()方法后x,对其传入一个数据类型,当字典被创建后,其value会被自动转换成传入的那个数据类型,所以上述题目可以简化成:
from collections import defaultdict
values = [11, 22, 33,44,55,66,77,88,99,90]
my_dict = defaultdict(list)
for value in values:
if value>66:
my_dict['k1'].append(value)
else:
my_dict['k2'].append(value)
使用dict时,如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict:
>>> from collections import defaultdict
>>> dd = defaultdict(lambda: 'N/A')
>>> dd['key1'] = 'abc'
>>> dd['key1'] # key1存在
'abc'
>>> dd['key2'] # key2不存在,返回默认值
'N/A'
5.Counter计数
当你需要统计一个字符串中某个字符出现的次数时,如题
s='aaaaabbbbbbvcccccc'
dict1=dict({})
for i in s:
if i not in dict1:
dict1[i]=1
else:
dict1[i]+=1
print(dict1)
#输出结果>>>{'a': 5, 'b': 6, 'v': 1, 'c': 6}
而使用counter计数就可以直接生成字典:
from collections import Counter
s = 'abcdeabcdabcaba'
res = Counter(s)
print(res)
#输出结果>>>Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
二。time时间模块
时间模块有三种表现形式:
1.时间戳
2.格式化时间(用来展示给人看的)
3.结构化时间
1.time.time()
import time
print(time.time())
#输出结果>>>1563445995.928969
输出的是现在的时间距离1970-1-1的秒数,
2.strftime()
格式化时间输出的时间比较工整,它与%s差不多,不过有特定的符号接受年月日、
print(time.strftime('%Y-%m-%d'))
print(time.strftime('%Y-%m-%d %H:%M:%S'))
#输出结果>>>2019-07-18
#2019-07-18 18:43:16
如上,月和日的字符是小写,其他均为大写,使用%X可以代表时分秒。
在strftime中还有其他的特殊字符,日后用作翻阅如:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
3.结构化时间
使用time.local可以打印结构化时间,
print(time.localtime())
#输出结果>>>time.struct_time(tm_year=2019, tm_mon=7, tm_mday=18, tm_hour=18, tm_min=51, tm_sec=5, tm_wday=3, tm_yday=199, tm_isdst=0)
结构化时间中分别代表了以下值,用做以后索引:
| 索引(Index) | 属性(Attribute) | 值(Values) |
|---|---|---|
| 0 | tm_year(年) | 比如2011 |
| 1 | tm_mon(月) | 1 - 12 |
| 2 | tm_mday(日) | 1 - 31 |
| 3 | tm_hour(时) | 0 - 23 |
| 4 | tm_min(分) | 0 - 59 |
| 5 | tm_sec(秒) | 0 - 60 |
| 6 | tm_wday(weekday) | 0 - 6(0表示周一) |
| 7 | tm_yday(一年中的第几天) | 1 - 366 |
| 8 | tm_isdst(是否是夏令时) | 默认为0 |
初次之外,字符串时间,结构化时间,格式化时间之间是可以互相转换的:
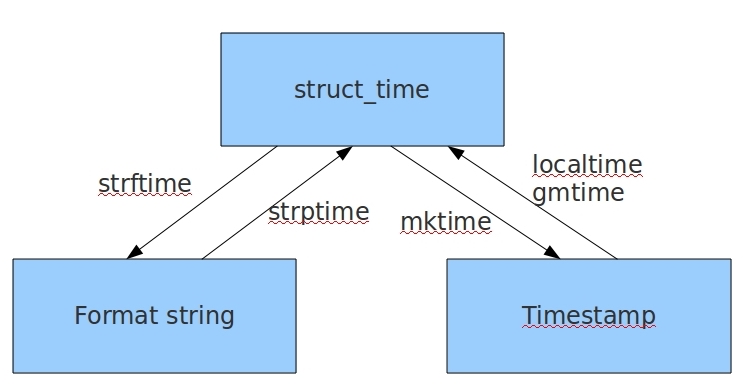
时间戳转化为结构化时间:
print(time.localtime(time.time()))
#输出结果>>>time.struct_time(tm_year=2019, tm_mon=7, tm_mday=18, tm_hour=19, tm_min=13, tm_sec=1, tm_wday=3, tm_yday=199, tm_isdst=0)
或者转换为伦敦时间:
print(time.gmtime(time.time()))
#输出结果>>>time.struct_time(tm_year=2019, tm_mon=7, tm_mday=18, tm_hour=11, tm_min=15, tm_sec=12, tm_wday=3, tm_yday=199, tm_isdst=0)
结构化时间转换为时间戳:
res = time.localtime(time.time())
print(time.time())
print(time.mktime(res))
#输出结果>>>1563448581.7627177
#1563448581.0
结构化时间转换为字符串时间:
print(time.strftime('%Y-%m',time.localtime()))
#输出结果>>>2019-07
字符串时间转换为结构化时间:
print(time.strptime(time.strftime('%Y-%m',time.localtime()),'%Y-%m'))
#输出结果>>>time.struct_time(tm_year=2019, tm_mon=7, tm_mday=1, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=0, tm_yday=182, tm_isdst=-1)
结构化时间转换成格式化串:
print(time.asctime(time.localtime(1500000000)))
print(time.asctime())
#输出结果>>>Fri Jul 14 10:40:00 2017
#Thu Jul 18 19:27:51 2019
如果不传值,显示的是当前时间
时间戳转化成格式化串
print(time.ctime())
print(time.ctime(1500000000))
#输出结果>>>Thu Jul 18 19:29:23 2019
#Fri Jul 14 10:40:00 2017
time.sleep(n)
将程序搁置n秒
datetime模块
显示年月日和年月日时分秒:
import datetime
print(datetime.date.today())
print(datetime.datetime.today())
#输出结果>>>2019-07-18
#2019-07-18 19:33:33.857248
下面还有一些获取时间相关的方法:
import datetime
print(datetime.date.today()) # date>>>:年月日
print(datetime.datetime.today()) # datetime>>>:年月日 时分秒
res = datetime.date.today()
res1 = datetime.datetime.today()
print(res.year)
print(res.month)
print(res.day)
print(res.weekday()) # 0-6表示星期 0表示周一
print(res.isoweekday())
#输出结果>>>2019-07-18
#2019-07-18 19:38:59.237848
#
#
#
#
#
其中,year获取年,month代表月,day代表日,weekday代表星期,但这里从0开始,代表星期一,isoweekday是代表真正的星期。
在这个模块可以对时间进行计算
timetel_t = datetime.timedelta(days=7) # timedelta对象
print(timetel_t)
#输出结果>>>7 days, 0:00:00
timedelta是一个时间增量,在进行时间运算时,遵循以下规则:
日期对象 = 日期对象 +/- timedelta对象
timedelta对象 = 日期对象 +/- 日期对象,如:
current_time = datetime.date.today() # 日期对象
timetel_t = datetime.timedelta(days=7) # timedelta对象
print(timetel_t)
res1 = current_time+timetel_t # 日期对象
print(current_time - timetel_t)
print(res1-current_time)
#输出结果>>>7 days, 0:00:00
#2019-07-11
#7 days, 0:00:00
utc时间
dt_today = datetime.datetime.today()
dt_now = datetime.datetime.now()
dt_utcnow = datetime.datetime.utcnow()
print(dt_today)
print(dt_now)
print(dt_utcnow)
#输出结果>>>2019-07-18 19:56:12.536702
#2019-07-18 19:56:12.536702
#2019-07-18 11:56:12.536702
三。random模块
random是获取随机数等随机项的模块
如:random.randint(x,y)随机生成x到y之间的数
random.random()随机生成0-1之间的小数。
random.shuffle()对一个列表进行随机打乱。
random.choice()对一个列表中的元素进行随机选择。
import random
print(random.randint(1,6)) # 随机取一个你提供的整数范围内的数字 包含首尾
print(random.random()) # 随机取0-1之间小数
print(random.choice([1,2,3,4,5,6])) # 摇号 随机从列表中取一个元素
res = [1,2,3,4,5,6]
random.shuffle(res) # 洗牌
print(res)
#输出结果>>>4
#0.394731321911586
#
#[2, 1, 5, 3, 6, 4]
小练习:生成n、位随机验证码,带有数字,大写字母和小写字母
def get_code(n):
code = ''
for i in range(n):
# 先生成随机的大写字母 小写字母 数字
upper_str = chr(random.randint(65,90))
lower_str = chr(random.randint(97,122))
random_int = str(random.randint(0,9))
# 从上面三个中随机选择一个作为随机验证码的某一位
code += random.choice([upper_str,lower_str,random_int])
return code
res = get_code(4)
print(res)
四。os模块
os模块是与操作系统进行对接的模块
os.path.dirname(__file__) 获取该文件的上一层文件名
os.path.join(x,y) 拼接地址
os.listdir() 将该文件夹下的所有文件读取出看来,成为一个列表。
os.mkdir('文件夹名'),生成一个文件夹,在当文件夹下
os.path.exists()判断文件夹是否存在
os.path.isfile(),判断文件是否存在,不能判断文件夹。
os.rmdir(''),删除文件夹,(只能删除空文件夹)。
os.chdir(''),切换到该目录里
os.getcwd(),查看当前目录
os.path.getsize(),获取文件大小,获取的是字节
其他可能用到的如下:
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command).read() 运行shell命令,获取执行结果
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.path
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
五。sys模块
sys模块是与python解释器打交道的
sys.path.append(),将某个路径添加到系统环境变量的。
sys.argv:在终端运行该文件可以获取终端输入的内容。并生成列表。
其他内容:
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1)
sys.version 获取Python解释程序的版本信息
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
六。序列化模块
序列:字符串
序列化:其他数据类型转换成字符串的过程。
写入文件的数据必须是字符串,基于网络传输的数据必须是二进制
反序列化:字符串转化成其他数据类型。
在数据传输过程中都是以二进制传输,而且在不同语言之间需要进行序列和反序列,所有有一个模块可以进行之间的转化。
json模块
json是所有语言都支持的模块。
json支持的数据类型比较少,如:字符串,列表,字典,整型,元组(转成列表)
pickle模块
pickle与json不同的是它只支持python的转化,但能转化所有数字类型
在存数据如文件是,必须要经序列化。
json.encoder,可以查询json中支持哪些数据类型的序列化
+-------------------+---------------+
| Python | JSON |
+===================+===============+
| dict | object |
+-------------------+---------------+
| list, tuple | array |
+-------------------+---------------+
| str | string |
+-------------------+---------------+
| int, float | number |
+-------------------+---------------+
| True | true |
+-------------------+---------------+
| False | false |
+-------------------+---------------+
| None | null |
+-------------------+---------------+
除此之外其他都不支持,
d = {"name":"jason"}
print(d)
res = json.dumps(d)
print(res,type(res))
res1 = json.loads(res)
print(res1,type(res1))
#输出结果>>>{'name': 'jason'}
#{"name": "jason"} <class 'str'>
#{'name': 'jason'} <class 'dict'>
在json模块中,damps可以将字典转化成字典型的字符串,而loads可以将字典型的字符串转化成字典。
dump和load
import json
f = open('json_file','w')
dic = {'k1':'v1','k2':'v2','k3':'v3'}
json.dump(dic,f)
f.close()
f = open('json_file')
dic2 = json.load(f)
f.close()
print(type(dic2),dic2)
dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件,而load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回。
注意,在使用dump写入数据到文件中时,是不加空格的,所以要想写入多条数据可以使用dumps手动拼接回车符接在后面,在使用loads返回一行,循环。
d1 = {'name':'朱志坚'}
print(json.dumps(d1,ensure_ascii=False))
#输出结果>>>{"name": "朱志坚"}
当使用dumps序列化时,可能会把其中的ascii码进行二进制转化,为了避免这种情况,可以使用ensure_ascii取false值使得其不转码。
pickle模块
在pickle模块中dumps方法会直接将对象转换成二进制,loads将其转换成原类型。
在dump方法的使用中,文件的打开模式必须时b模式。
七。subprocess子进程
sub 子
process 进程
其中obj=subprocess.popen('文件名'shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
使用obj.stdout.read().decode("gbk')进行输出正确的指令进程
使用obj.stderr.read()输出错误的指令
while True:
cmd = input('cmd>>>:').strip()
import subprocess
obj = subprocess.Popen(cmd,shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
# print(obj)
print('正确命令返回的结果stdout',obj.stdout.read().decode('gbk'))
print('错误命令返回的提示信息stderr',obj.stderr.read().decode('gbk'))
其应用范围是可以全程连接其他电脑,使用这个模块获取用户命令,执行命令,就实现了远程操作。
day16_7.18 常用模块的更多相关文章
- 十八. Python基础(18)常用模块
十八. Python基础(18)常用模块 1 ● 常用模块及其用途 collections模块: 一些扩展的数据类型→Counter, deque, defaultdict, namedtuple, ...
- 18 常用模块 random shutil shevle logging sys.stdin/out/err
random:随机数 (0, 1) 小数:random.random() ***[1, 10] 整数:random.randint(1, 10) *****[1, 10) 整数:random.rand ...
- Day 18 常用模块(二)
一.随机数:RANDOM 1.(0,1)小数:random.random() 2.[1,10]整数:random.randint(1,10) 3.[1,10)整数:random.randrang(1, ...
- 进击的Python【第五章】:Python的高级应用(二)常用模块
Python的高级应用(二)常用模块学习 本章学习要点: Python模块的定义 time &datetime模块 random模块 os模块 sys模块 shutil模块 ConfigPar ...
- Python模块之常用模块,反射以及正则表达式
常用模块 1. OS模块 用于提供系统级别的操作,系统目录,文件,路径,环境变量等 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("di ...
- python学习笔记之常用模块(第五天)
参考老师的博客: 金角:http://www.cnblogs.com/alex3714/articles/5161349.html 银角:http://www.cnblogs.com/wupeiqi/ ...
- day--6_python常用模块
常用模块: time和datetime shutil模块 radom string shelve模块 xml处理 configparser处理 hashlib subprocess logging模块 ...
- Tengine 常用模块使用介绍
Tengine 和 Nginx Tengine简介 从2011年12月开始:Tengine是由淘宝网发起的Web服务器项目.它在Nginx的基础上,针对大访问量网站的需求,添加了很多高级功能 和特性. ...
- Ansible简介及常用模块
一.基础介绍 1.简介 ansible是新出现的自动化运维工具,基于Python开发,集合了众多运维工具(puppet.cfengine.chef.func.fabric)的优点,实现了批量系统配置. ...
随机推荐
- Conda和Python的国内安装源
Conda和Python的国内安装源 Windows系统: 更换python国内源的方法. 在"C:\Users[xxxx]\pip\pip.ini"文件中配置如下内容(没有则新建 ...
- Shell编程——运算符
1.declare命令: 声明变量的类型: -:给变量设定类型属性 +:给变量取消类型属性 -i:将变量声明为整数类型 -x:将变量声明为环境变量 -p:显示变量的类型 其中export是将num变为 ...
- <Math> 258 43
258. Add Digits class Solution { public int addDigits(int num) { if(num == 0) return 0; if(num % 9 = ...
- Phoenix |安装配置| 命令行操作| 与hbase的映射| spark对其读写
Phoenix Phoenix是HBase的开源SQL皮肤.可以使用标准JDBC API代替HBase客户端API来创建表,插入数据和查询HBase数据. 1.特点 1) 容易集成:如Spark,Hi ...
- zz错误集锦
1.csp-s模拟测试63 T1 2e8的数组开bitset会ce,开bool就可以了,bool一位占一个字节,不是四个字节 2.csp-s模拟测试65 T2 把用vector存图改成前向星,就A了, ...
- windows端口转发工具(LCX)
端口转发(Port forwarding),有时被叫做隧道,是安全壳(SSH) 为网络安全通信使用的一种方法.端口转发是转发一个网络端口从一个网络节点到另一个网络节点的行为,其使一个外部用户从外部经过 ...
- 第02组 Beta冲刺(3/5)
队名:無駄無駄 组长博客 作业博客 组员情况 张越洋 过去两天完成了哪些任务 数据库实践的报告 提交记录(全组共用) 接下来的计划 加快校园百科的进度 还剩下哪些任务 学习软工的理论课 学习代码评估. ...
- JVM&NIO&HashMap简单问
JVM&NIO&HashMap简单问 背景:前几天在网上看到关于JVM&NIO&HashMap的一些连环炮的面试题,整理下以备不时之需. 一.JVM Java的虚拟机的 ...
- JavaScript DOM 常用操作
1.理解DOM: DOM(Document Object Model ,文档对象模型)一种独立于语言,用于操作xml,html文档的应用编程接口. 怎么说,我从两个角度理解: 对于JavaScript ...
- C# 5.0 新特性之异步方法(AM)
Ø 前言 C# Asynchronous Programming(异步编程)有几种实现方式,其中 Asynchronous Method(异步方法)就是其中的一种.异步方法是 C#5.0 才有的新特 ...