python 爬虫实例(三)
问题描述
爬取博客园的首页数据URL【https://home.cnblogs.com/blog/page/1/】,之后写到自己的Excel里面
环境:
OS:Window10
python:3.7
代码
import requests
import os
from bs4 import BeautifulSoup
import xlwt
import xlrd
from xlutils.copy import copy
import threading
import datetime class BlogHome: def __init__(self):
self.url = "https://home.cnblogs.com/blog/page/{}/"
self.path = r"C:\pythonProject\Blog" def request(self, param):
url= self.url.format(param)
r = requests.get(self.url)
return r.text def all_page(self, maxpage): # wbk = xlwt.Workbook()
# sheet = wbk.add_sheet("Data")
wbk = xlrd.open_workbook(r"C:\Users\peiqiang\Desktop\aaa.xls", formatting_info=True)
wbCopy = copy(wbk)
sheet = wbCopy.get_sheet(0)
row = 4
for page in range(1, maxpage):
thread_lock.acquire()
req = self.request(page)
reRow = self.getdata(req, sheet, row)
row = reRow
thread_lock.release() wbCopy.save(r"C:\Users\peiqiang\Desktop\aaa.xls")
print("書き込みました") def getdata(self, req, sheet, row):
soup = BeautifulSoup(req, "xml")
all_title = soup.find_all(class_="post_block")
for title in all_title:
col = 1
# title取得
title_blank = title.find(class_="entry_title").find_all("a")
print("user:", title_blank[0].string.replace("[", "").replace("]", ""))
sheet.write(row, col, title_blank[0].string.replace("[", "").replace("]", ""))
col += 1
print("title:", title_blank[1].string)
sheet.write(row, col, title_blank[1].string)
col += 1 # 評論個数
post_comment = title.find(class_="post_comment")
print("評論個数:", post_comment.string)
sheet.write(row, col, post_comment.string)
col += 1
# 読込個数
post_view = title.find(class_="post_view")
print("読込個数:", post_view.string) sheet.write(row, col, post_view.string)
col += 1 # 推奨個数
# susume = title.find(class_="entry_footer")
# print("推奨個数:", susume.string)
# 発表日付
postdate = title.find(class_="postdate")
print("発表日付:", postdate.string)
sheet.write(row, col, postdate.string)
col += 1
# 詳細取得
entry_summary = title.find(class_="entry_summary")
print("詳細取得:", entry_summary.string)
sheet.write(row, col, entry_summary.string)
col += 1
row += 1
return row def writeExcel(self, row, col, data):
wbk = xlwt.Workbook()
sheet = wbk.add_sheet("Data", cell_overwrite_ok=True)
sheet.write(row, col, data)
wbk.save(r"C:\Users\peiqiang\Desktop\aaa.xls")
print("書き込みました") def mkdir(self):
path = self.path.strip()
isExist = os.path.exists(path)
if not isExist:
print('创建名字叫做', path, '的文件夹')
os.makedirs(path)
print('创建成功!')
return True
else:
print(path, '文件夹已经存在了,不再创建')
return False def getBlog(self): startTime = datetime.datetime.now()
print("開始", startTime)
self.all_page(10)
endTime = datetime.datetime.now()
print("実行時間:", (endTime - startTime).seconds)
print("開始", startTime)
print("終了", endTime) thread_lock = threading.BoundedSemaphore(value=10)
blogHome = BlogHome()
blogHome.getBlog()
执行上面的代码
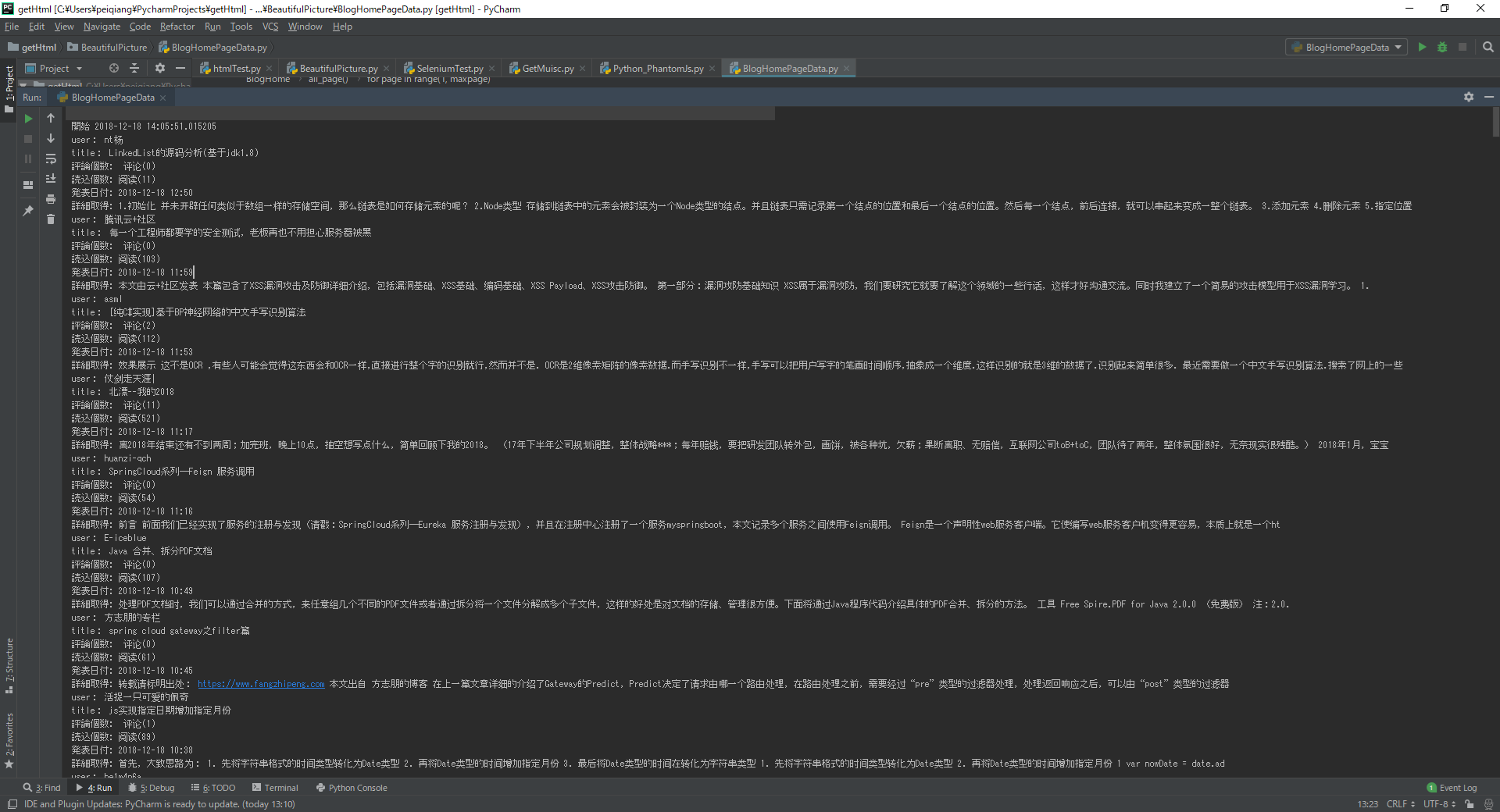
Excel上面的数据

python 爬虫实例(三)的更多相关文章
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- 3.Python爬虫入门三之Urllib和Urllib2库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
- 转 Python爬虫入门三之Urllib库的基本使用
静觅 » Python爬虫入门三之Urllib库的基本使用 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器 ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫进阶三之Scrapy框架安装配置
初级的爬虫我们利用urllib和urllib2库以及正则表达式就可以完成了,不过还有更加强大的工具,爬虫框架Scrapy,这安装过程也是煞费苦心哪,在此整理如下. Windows 平台: 我的系统是 ...
- Python爬虫实战三之实现山东大学无线网络掉线自动重连
综述 最近山大软件园校区QLSC_STU无线网掉线掉的厉害,连上之后平均十分钟左右掉线一次,很是让人心烦,还能不能愉快地上自习了?能忍吗?反正我是不能忍了,嗯,自己动手,丰衣足食!写个程序解决掉它! ...
- Python 爬虫实例
下面是我写的一个简单爬虫实例 1.定义函数读取html网页的源代码 2.从源代码通过正则表达式挑选出自己需要获取的内容 3.序列中的htm依次写到d盘 #!/usr/bin/python import ...
- Python爬虫实例:糗百
看了下python爬虫用法,正则匹配过滤对应字段,这里进行最强外功:copy大法实践 一开始是直接从参考链接复制粘贴的,发现由于糗百改版导致失败,这里对新版html分析后进行了简单改进,把整理过程记录 ...
- shell及Python爬虫实例展示
1.shell爬虫实例: [root@db01 ~]# vim pa.sh #!/bin/bash www_link=http://www.cnblogs.com/clsn/default.html? ...
随机推荐
- 《挑战30天C++入门极限》C++类静态数据成员与类静态成员函数
C++类静态数据成员与类静态成员函数 在没有讲述本章内容之前如果我们想要在一个范围内共享某一个数据,那么我们会设立全局对象,但面向对象的程序是由对象构成的,我们如何才能在类范围内共享数据呢? ...
- Beego没gin配置静态页面方便
上代码 腾讯这个例子还是很值得学习的,不轻有东西,单也不重到看着都蒙圈的样子. https://github.com/Tencent/bk-cmdb/blob/master/src/web_serve ...
- rapidxml学习
参考: 官网http://rapidxml.sourceforge.net/ https://blog.csdn.net/wqvbjhc/article/details/7662931 http:// ...
- Spring boot RSA 文件加密解密
github项目地址 rsa_demo ##测试 加密D:/hello/test.pdf 文件,生成加密后的文件 testNeedDecode.pdf 对testNeedDecode.pdf 文件进行 ...
- WEB传参调用EXE
WEB传参调用EXE 让浏览器运行本地的EXE程序.例如:点击浏览器的一个下载链接,就会打开本地的迅雷. 1)注册表注册 Windows Registry Editor Version 5.00 [H ...
- Java中JVM内存结构
Java中JVM内存结构 线程共享区 方法区: 又名静态成员区域,包含整个程序的 class.static 成员等,类本身的字节码是静态的:它会被所有的线程共享和是全区级别的: 属于共享内存区域,存储 ...
- python 设计模式之桥接模式 Bridge Pattern
#写在前面 前面写了那么设计模式了,有没有觉得有些模式之间很类似,甚至感觉作用重叠了,模式并不是完全隔离和独立的,有的模式内部其实用到了其他模式的技术,但是又有自己的创新点,如果一味地认为每个模式都是 ...
- 改变jupyter notebook的主题背景
https://study.163.com/provider/400000000398149/index.htm?share=2&shareId=400000000398149( 欢迎关注博 ...
- layer.msg 弹出不同的效果的样式
icon 1到6的不同效果 layer.msg(,time:, shift: });//一个勾 layer.msg(,time:, shift: });//一个叉 layer.msg(,time:, ...
- 搭建 Kafka 集群 (v2.12-2.3.0)
服务器:10.20.32.121,10.20.32.122,10.20.32.123 三台服务器都需要安装jdk.配置zookeeper.配置kafka 1.安装配置jdk1.8 [root@loca ...