L2范数归一化概念和优势
1 归一化处理
归一化是一种数理统计中常用的数据预处理手段,在机器学习中归一化通常将数据向量每个维度的数据映射到(0,1)或(-1,1)之间的区间或者将数据向量的某个范数映射为1,归一化好处有两个:
(1) 消除数据单位的影响:其一可以将有单位的数据转为无单位的标准数据,如成年人的身高150-200cm、成年人体重50-90Kg,身高的单位是厘米而体重的单位是千克,不同维度的数据单位不一样,造成原始数据不能直接代入机器学习中进行处理,所以这些数据经过特定方法统一都映射到(0,1)这个区间,这样所有数据的取值范围都在同一个区间里的。
(2) 可提深度学习模型收敛速度: 如果不进行归一化处理,假设深度学习模型接受的输入向量只有两个维度x1和x2,其中X1取值为0-2000,x2取值为0-3。这样数据在进行梯度下降计算时梯度时对应一个很扁的椭圆形,很容易在垂直等高线的方向上走大量的之字形路线,是的迭代计算量大且迭代的次数多,造成深度学习模型收敛慢。
2 L2范数归一化的概念
L2范数归一化处理操作是对向量X的每个维度数据x1, x2, …, xn都除以||x||2得到一个新向量,即
\[{{\bf{X}}_2} = \left( {\frac{{{x_1}}}{{{{\left\| {\bf{x}} \right\|}_2}}},\frac{{{x_2}}}{{{{\left\| {\bf{x}} \right\|}_2}}}, \cdots ,\frac{{{x_n}}}{{{{\left\| {\bf{x}} \right\|}_2}}}} \right) = \left( {\frac{{{x_1}}}{{\sqrt {x_1^2 + x_2^2 + \cdots + x_n^2} }},\frac{{{x_2}}}{{\sqrt {x_1^2 + x_2^2 + \cdots + x_n^2} }}, \cdots ,\frac{{{x_n}}}{{\sqrt {x_1^2 + x_2^2 + \cdots + x_n^2} }}} \right)\]
若向量A = (2, 3, 6),易得向量X的L2范数为
\[{\left\| {\bf{A}} \right\|_2} = \sqrt {{2^2} + {3^2} + {6^2}} = \sqrt {4 + 9 + 36} = \sqrt {49} = 7\]
所以向量A的L2范数归一化后得到向量为
\[{{\bf{A}}_2} = \left( {\frac{2}{7},\frac{3}{7},\frac{6}{7}} \right)\]
图1 L2范数可以看作是向量的长度
3 L2范数归一化的优势
L2范数有一大优势:经过L2范数归一化后,一组向量的欧式距离和它们的余弦相似度可以等价
一个向量X经过L2范数归一化得到向量X2,同时另一个向量Y经过L2范数归一化得到向量Y2。此时X2和Y2的欧式距离和余弦相似度是等价的,下面先给出严格的数学证明。
假设向量X = (x1, x2, …, xn),向量Y = (y1, y2, …, yn), X2和Y2的欧式距离是
\[\begin{array}{l}
D\left( {{{\bf{X}}_{\rm{2}}},{{\bf{Y}}_{\rm{2}}}} \right) = \sqrt {{{\left( {\frac{{{x_1}}}{{{{\left\| {\bf{X}} \right\|}_2}}} - \frac{{{y_1}}}{{{{\left\| {\bf{Y}} \right\|}_2}}}} \right)}^2} + {{\left( {\frac{{{x_2}}}{{{{\left\| {\bf{X}} \right\|}_2}}} - \frac{{{y_2}}}{{{{\left\| {\bf{Y}} \right\|}_2}}}} \right)}^2} + \cdots + {{\left( {\frac{{{x_n}}}{{{{\left\| {\bf{X}} \right\|}_2}}} - \frac{{{y_n}}}{{{{\left\| {\bf{Y}} \right\|}_2}}}} \right)}^2}} \\
\quad \quad \quad \quad \quad \;\;\; = \sqrt {\left( {\frac{{\bf{X}}}{{{{\left\| {\bf{X}} \right\|}_2}}} - \frac{{\bf{Y}}}{{{{\left\| {\bf{Y}} \right\|}_2}}}} \right){{\left( {\frac{{\bf{X}}}{{{{\left\| {\bf{X}} \right\|}_2}}} - \frac{{\bf{Y}}}{{{{\left\| {\bf{Y}} \right\|}_2}}}} \right)}^T}} \\
\quad \quad \quad \quad \quad \;\;\; = \sqrt {\frac{{{\bf{X}}{{\bf{X}}^T}}}{{\left\| {\bf{X}} \right\|_2^2}} - \frac{{{\bf{X}}{{\bf{Y}}^T}}}{{{{\left\| {\bf{X}} \right\|}_2}{{\left\| {\bf{Y}} \right\|}_2}}} - \frac{{{\bf{Y}}{{\bf{X}}^T}}}{{{{\left\| {\bf{X}} \right\|}_2}{{\left\| {\bf{Y}} \right\|}_2}}} + \frac{{{\bf{Y}}{{\bf{Y}}^T}}}{{\left\| {\bf{Y}} \right\|_2^2}}} \\
\quad \quad \quad \quad \quad \;\;\; = \sqrt {\frac{{{\bf{X}}{{\bf{X}}^T}}}{{{\bf{X}}{{\bf{X}}^T}}} - \frac{{2{\bf{X}}{{\bf{Y}}^T}}}{{{{\left\| {\bf{X}} \right\|}_2}{{\left\| {\bf{Y}} \right\|}_2}}} + \frac{{{\bf{Y}}{{\bf{Y}}^T}}}{{{\bf{Y}}{{\bf{Y}}^T}}}} \\
\quad \quad \quad \quad \quad \;\;\; = \sqrt {2 - 2\frac{{{\bf{X}}{{\bf{Y}}^T}}}{{{{\left\| {\bf{X}} \right\|}_2}{{\left\| {\bf{Y}} \right\|}_2}}}} \\
\end{array}\]
X2和Y2的余弦相似度为
\[\begin{array}{l}
Sim\left( {{{\bf{X}}_{\rm{2}}},{{\bf{Y}}_{\rm{2}}}} \right) = \frac{{\frac{{{x_1}}}{{{{\left\| {\bf{X}} \right\|}_2}}} \cdot \frac{{{y_1}}}{{{{\left\| {\bf{Y}} \right\|}_2}}}{\rm{ + }}\frac{{{x_{\rm{2}}}}}{{{{\left\| {\bf{X}} \right\|}_2}}} \cdot \frac{{{y_{\rm{2}}}}}{{{{\left\| {\bf{Y}} \right\|}_2}}}{\rm{ + }} \cdots {\rm{ + }}\frac{{{x_n}}}{{{{\left\| {\bf{X}} \right\|}_2}}} \cdot \frac{{{y_n}}}{{{{\left\| {\bf{Y}} \right\|}_2}}}}}{{\sqrt {{{\left( {\frac{{{x_1}}}{{{{\left\| {\bf{X}} \right\|}_2}}}} \right)}^{\rm{2}}}{\rm{ + }}{{\left( {\frac{{{x_{\rm{2}}}}}{{{{\left\| {\bf{X}} \right\|}_2}}}} \right)}^{\rm{2}}}{\rm{ + }} \cdots {{\left( {\frac{{{x_{\rm{n}}}}}{{{{\left\| {\bf{X}} \right\|}_2}}}} \right)}^{\rm{2}}}} \cdot \sqrt {{{\left( {\frac{{{y_1}}}{{{{\left\| {\bf{Y}} \right\|}_2}}}} \right)}^{\rm{2}}}{\rm{ + }}{{\left( {\frac{{{y_{\rm{2}}}}}{{{{\left\| {\bf{Y}} \right\|}_2}}}} \right)}^{\rm{2}}}{\rm{ + }} \cdots {\rm{ + }}{{\left( {\frac{{{y_n}}}{{{{\left\| {\bf{Y}} \right\|}_2}}}} \right)}^{\rm{2}}}} }} \\
\quad \quad \quad \quad \quad \;\;\; = \frac{{\frac{{{x_1}{y_1} + {x_2}{y_2} + \cdots + {x_n}{y_n}}}{{{{\left\| {\bf{X}} \right\|}_2}{{\left\| {\bf{Y}} \right\|}_2}}}}}{{\sqrt {\frac{{x_1^2 + x_2^2 + \cdots + x_n^2}}{{\left\| {\bf{X}} \right\|_2^2}}} \cdot \sqrt {\frac{{y_1^2 + y_2^2 + \cdots y_n^2}}{{\left\| {\bf{Y}} \right\|_2^2}}} }} \\
\quad \quad \quad \quad \quad \;\;\; = \frac{{\frac{{{x_1}{y_1} + {x_2}{y_2} + \cdots + {x_n}{y_n}}}{{{{\left\| {\bf{X}} \right\|}_2}{{\left\| {\bf{Y}} \right\|}_2}}}}}{{\sqrt {\frac{{x_1^2 + x_2^2 + \cdots + x_n^2}}{{x_1^2 + x_2^2 + \cdots + x_n^2}}} \cdot \sqrt {\frac{{y_1^2 + y_2^2 + \cdots y_n^2}}{{y_1^2 + y_2^2 + \cdots y_n^2}}} }} \\
\quad \quad \quad \quad \quad \;\;\; = \frac{{{x_1}{y_1} + {x_2}{y_2} + \cdots + {x_n}{y_n}}}{{{{\left\| {\bf{X}} \right\|}_2}{{\left\| {\bf{Y}} \right\|}_2}}} \\
\quad \quad \quad \quad \quad \;\;\; = \frac{{{\bf{X}}{{\bf{Y}}^T}}}{{{{\left\| {\bf{X}} \right\|}_2}{{\left\| {\bf{Y}} \right\|}_2}}} \\
\end{array}\]
结合两个表达式易得
\[D\left( {{{\bf{X}}_{\rm{2}}},{{\bf{Y}}_{\rm{2}}}} \right) = \sqrt {2 - 2sim\left( {{{\bf{X}}_{\rm{2}}},{{\bf{Y}}_{\rm{2}}}} \right)} \]
即L2范数归一化处理后两个向量欧式距离等于2减去2倍余弦相似度的算术平方根。如果你被上面令人昏头转向的数学公式搞晕,而不想看的话,这里还有一种仅需要中学知识的更简单证明方法证明两者的等价性:
假设一组二维数据,设经过L2范数归一化后向量X2 为 (p1, p2),向量Y2 为 (q1, q2)。向量X2是原点(0,0) 指向点P(p1,p2)的有向线段,向量Y2是原点(0,0)指向点Q(q1, q2)的有向线段。易得
X2和Y2的欧式距离为线段PQ长度
X2和Y2的余弦相似度为∠POQ的余弦值
根据余弦定理易得
\[\cos \angle POQ = \frac{{O{P^2} + O{Q^2} - P{Q^2}}}{{2 \cdot OP \cdot OQ}}\]
因为L2范数归一化向量的长度都是1,因为L2范数归一化向量的长度都是1,那么向量对应的点肯定都在单位圆上,所以OP=OQ=1
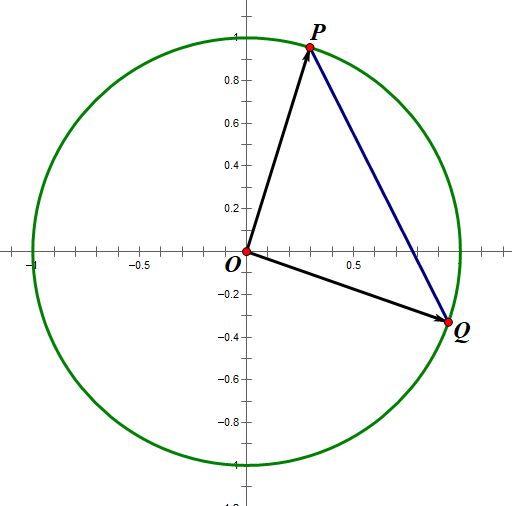
图2 L2范数归一化后向量对应的点都在单位圆上
因此
\[\cos \angle POQ = \frac{{{1^2} + {1^2} - P{Q^2}}}{2} = \frac{{2 - P{Q^2}}}{2}\]
即
\[sim\left( {{{\bf{X}}_{\rm{2}}},{{\bf{Y}}_{\rm{2}}}} \right) = \frac{{2 - D{{\left( {{{\bf{X}}_{\rm{2}}},{{\bf{Y}}_{\rm{2}}}} \right)}^2}}}{2} \Rightarrow D\left( {{{\bf{X}}_{\rm{2}}},{{\bf{Y}}_{\rm{2}}}} \right) = \sqrt {2 - 2sim\left( {{{\bf{X}}_{\rm{2}}},{{\bf{Y}}_{\rm{2}}}} \right)} \]
因此经L2范数归一化后,一组向量的欧式距离和它们的余弦相似度可等价。这一大优势是当你算得一组经过L2范数归一化后的向量的欧式距离后,又想计算它们的余弦相似度,可以根据公式在O(1)时间内直接计算得到;反过来也一样。
另外,在一些机器学习处理包中,只有欧式距离计算没有余弦相似度计算,如Sklearn的Kmeans聚类包,这个包只能处理欧式距离计算的数据聚类。
而在NLP领域,许多词语或文档的相似度定义为数据向量的余弦相似度,如果直接调用Sklearn的Kmeans聚类包则不能进行聚类处理。因此需要将词语对象的词向量或者文档对应的文本向量进行L2范数归一化处理。因为在L2范数归一化处理后的欧式距离和余弦相似度是等价的,所以此时可以放心大胆用Sklearn的Kmeans进行聚类处理。
L2范数归一化概念和优势的更多相关文章
- L0、L1与L2范数、核范数(转)
L0.L1与L2范数.核范数 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理解下常用的L0.L1.L2和核范数规则化.最后聊下规则化项参数的选择问题.这里因为篇幅比较庞大 ...
- L0/L1/L2范数(转载)
一.首先说一下范数的概念: 向量的范数可以简单形象的理解为向量的长度,或者向量到零点的距离,或者相应的两个点之间的距离. 向量的范数定义:向量的范数是一个函数||x||,满足非负性||x|| > ...
- L0、L1及L2范数
L1归一化和L2归一化范数的详解和区别 https://blog.csdn.net/u014381600/article/details/54341317 深度学习——L0.L1及L2范数 https ...
- 机器学习中的范数规则化 L0、L1与L2范数 核范数与规则项参数选择
http://blog.csdn.net/zouxy09/article/details/24971995 机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http: ...
- 机器学习中的范数规则化之L0、L1与L2范数
今天看到一篇讲机器学习范数规则化的文章,讲得特别好,记录学习一下.原博客地址(http://blog.csdn.net/zouxy09). 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化. ...
- 机器学习中的范数规则化之 L0、L1与L2范数、核范数与规则项参数选择
装载自:https://blog.csdn.net/u012467880/article/details/52852242 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理 ...
- 《机器学习实战》学习笔记第八章 —— 线性回归、L1、L2范数正则项
相关笔记: 吴恩达机器学习笔记(一) —— 线性回归 吴恩达机器学习笔记(三) —— Regularization正则化 ( 问题遗留: 小可只知道引入正则项能降低参数的取值,但为什么能保证 Σθ2 ...
- L0、L1、L2范数正则化
一.范数的概念 向量范数是定义了向量的类似于长度的性质,满足正定,齐次,三角不等式的关系就称作范数. 一般分为L0.L1.L2与L_infinity范数. 二.范数正则化背景 1. 监督机器学习问题无 ...
- 正则化的L1范数和L2范数
范数介绍:https://www.zhihu.com/question/20473040?utm_campaign=rss&utm_medium=rss&utm_source=rss& ...
随机推荐
- 表观 | Enhancer | ChIP-seq | 转录因子 | 数据库专题
需要长期更新! 参考:生信修炼手册 enhancer的基本概念: 长度几十到几千bp,作用是提高靶基因活性,属于顺式作用原件,DNA作用到DNA,转录因子就是反式,是结合到DNA的蛋白. 1981年, ...
- qemu通过控制台向虚拟机输入组合键
ctrl+alt+2 开启控制台 ctrl+alt+1 关闭控制台 在控制台中输入 sendkey ctrl-alt-delete 发送指令
- Tosca user space 这是自己的空间,可以create module ,test case 等一大堆模块,五脏俱全
- Tomcat7/8/8.5三种版本的redis-session-manager的jar和xml配置均不同
chexagon/redis-session-manager: A tomcat8 session manager providing session replication via persiste ...
- MAC下快速打开指定目录(转)
使用了这么长时间MAC,打开文件查找目录总是感觉还是不如windows来的爽快 1.通过快捷键搜索 command + 空格,输入关键词 2.通过控制台打开 1) 跳转到指定路径 cd ...
- mac PHP安装imageMagic扩展
1. 安装:ImageMagick:命令:brew install ImageMagick这种方式安装下来的imageMagic,不缺少东西,报错较少.安装之后的位置:/usr/local/Cella ...
- Error-ASP.NET:由于未能找到 id 为“FileUpload1$gvFiles$ctl02$lnkBtnRemoveFile”的控件或在回发后将同一 ID 分配给另一个控件,导致发生错误。如果未分配 ID,请显式设置引发回发事件的控件的 ID 属性以避免此错误。
ylbtech-Error-ASP.NET:由于未能找到 id 为“FileUpload1$gvFiles$ctl02$lnkBtnRemoveFile”的控件或在回发后将同一 ID 分配给另一个控件 ...
- 【转载】 漫谈Code Review的错误实践
原文地址: https://www.cnblogs.com/chaosyang/p/code-review-wrong-practices.html ------------------------- ...
- spark sql插入表时的文件个数研究
spark sql执行insert overwrite table时,写到新表或者新分区的文件个数,有可能是200个,也有可能是任意个,为什么会有这种差别? 首先看一下spark sql执行inser ...
- .frm文件怎么导入到数据库
如题想搞个私服游戏,但是数据库文件按文档的操作方法行不通.只能自行导入. 其实.frm文件就是mysql表结构文件,你拷贝data那一块的文件到你电脑安装的mysql的data文件下就行了. 一.首先 ...